Berechnete Tabellenszenarien und Anwendungsfälle
Es gibt Vorteile für die Verwendung berechneter Tabellen in einem Dataflow. In diesem Artikel werden Anwendungsfälle für berechnete Tabellen beschrieben und erklärt, wie sie hinter den Kulissen funktionieren.
Was ist eine berechnete Tabelle?
Eine Tabelle stellt die Datenausgabe einer Abfrage dar, die in einem Dataflow nach der Aktualisierung des Dataflows erstellt wurde. Sie stellt Daten aus einer Quelle und optional die Transformationen dar, die darauf angewendet wurden. Manchmal möchten Sie möglicherweise neue Tabellen erstellen, die eine Funktion einer zuvor erfassten Tabelle sind.
Obwohl es möglich ist, die Abfragen, die eine Tabelle erstellt haben, zu wiederholen und neue Transformationen darauf anzuwenden, hat dieser Ansatz Nachteile: Daten werden zweimal erfasst, und die Auslastung der Datenquelle wird verdoppelt.
Berechnete Tabellen lösen beide Probleme. Berechnete Tabellen ähneln anderen Tabellen darin, dass sie Daten aus einer Quelle abrufen, und Sie können weitere Transformationen anwenden, um sie zu erstellen. Ihre Daten stammen jedoch aus dem verwendeten Speicher-Dataflow und nicht aus der ursprünglichen Datenquelle. Das heißt, sie wurden zuvor durch einen Dataflow erstellt und dann wiederverwendet.
Berechnete Tabellen können durch Verweisen auf eine Tabelle im gleichen Dataflow oder durch Verweisen auf eine Tabelle erstellt werden, die in einem anderen Dataflow erstellt wurde.

Warum sollte eine berechnete Tabelle verwendet werden?
Das Ausführen aller Transformationsschritte in einer Tabelle kann langsam sein. Es kann viele Gründe für diese Verlangsamung geben – die Datenquelle ist möglicherweise langsam, oder die Transformationen, die Sie ausführen, müssen in zwei oder mehr Abfragen repliziert werden. Es kann vorteilhaft sein, zuerst die Daten aus der Quelle zu erfassen und dann in einer oder mehreren Tabellen wiederzuverwenden. In solchen Fällen können Sie zwei Tabellen erstellen: eine Tabelle, die Daten aus der Datenquelle abruft, und eine andere – eine berechnete Tabelle – die zusätzliche Transformationen auf Daten anwendet, die bereits in den von einem Dataflow verwendeten Data Lake geschrieben wurden. Diese Änderung kann die Leistung und Wiederverwendbarkeit von Daten erhöhen und Zeit und Ressourcen sparen.
Wenn beispielsweise zwei Tabellen sogar einen Teil ihrer Transformationslogik gemeinsam nutzen, ohne dass eine berechnete Tabelle vorhanden ist, muss die Transformation zweimal durchgeführt werden.

Wenn jedoch eine berechnete Tabelle verwendet wird, wird der gemeinsame (freigegebene) Teil der Transformation einmal verarbeitet und in Azure Data Lake Storage gespeichert. Die verbleibenden Transformationen werden dann aus der Ausgabe der gemeinsamen Transformation verarbeitet. Insgesamt ist diese Verarbeitung viel schneller.
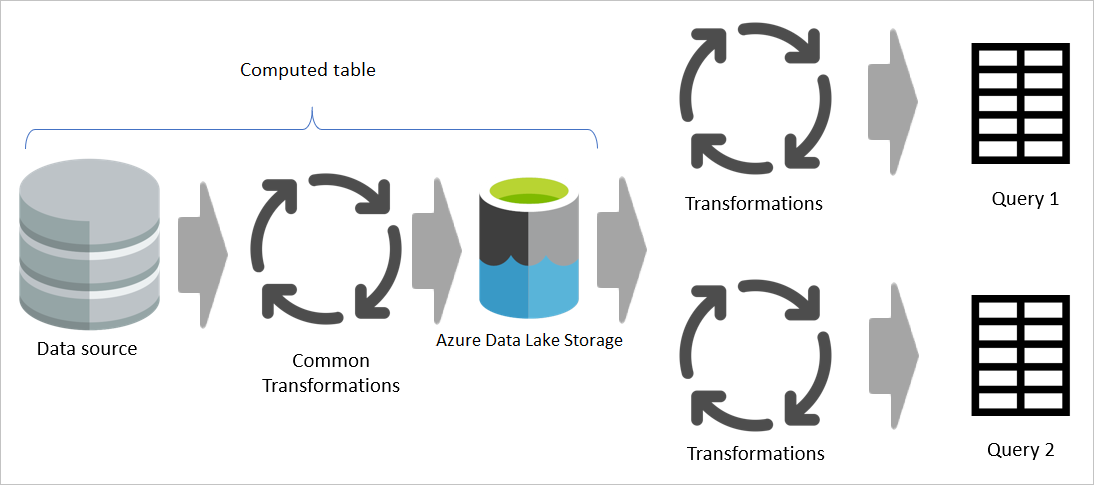
Eine berechnete Tabelle stellt einen Ort als Quellcode für die Transformation bereit und beschleunigt die Transformation, da sie nur einmal statt mehrmals ausgeführt werden muss. Die Auslastung der Datenquelle wird ebenfalls reduziert.
Beispielszenario für die Verwendung einer berechneten Tabelle
Wenn Sie eine aggregierte Tabelle in Power BI erstellen, um das Datenmodell zu beschleunigen, können Sie die aggregierte Tabelle erstellen, indem Sie auf die ursprüngliche Tabelle verweisen und zusätzliche Transformationen darauf anwenden. Mit diesem Ansatz müssen Sie Ihre Transformation nicht aus der Quelle replizieren (der Teil aus der ursprünglichen Tabelle).
Die folgende Abbildung zeigt z. B. die Tabelle „Aufträge“.

Mithilfe eines Verweises aus dieser Tabelle können Sie eine berechnete Tabelle erstellen.
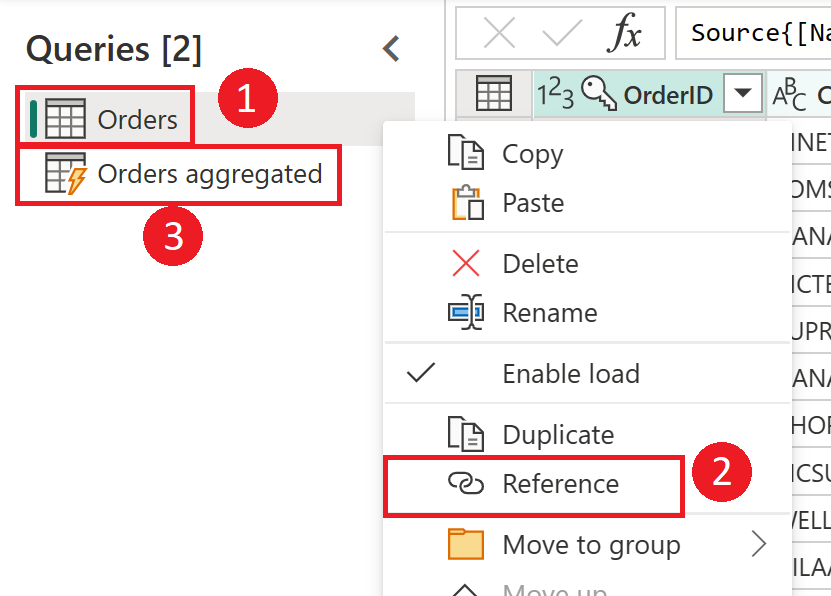
Screenshot, der zeigt, wie Sie eine berechnete Tabelle aus der Tabelle „Aufträge“ erstellen. Klicken Sie zuerst im Bereich „Abfragen“ mit der rechten Maustaste auf die Tabelle „Aufträge“, und wählen Sie im Dropdownmenü die Option „Verweis“ aus. Diese Aktion erstellt die berechnete Tabelle, die hier in „Aggregierte Aufträge“ umbenannt wird.
Die berechnete Tabelle kann weitere Transformationen aufweisen. Sie können beispielsweise Gruppieren nach verwenden, um die Daten auf Kundenebene zu aggregieren.
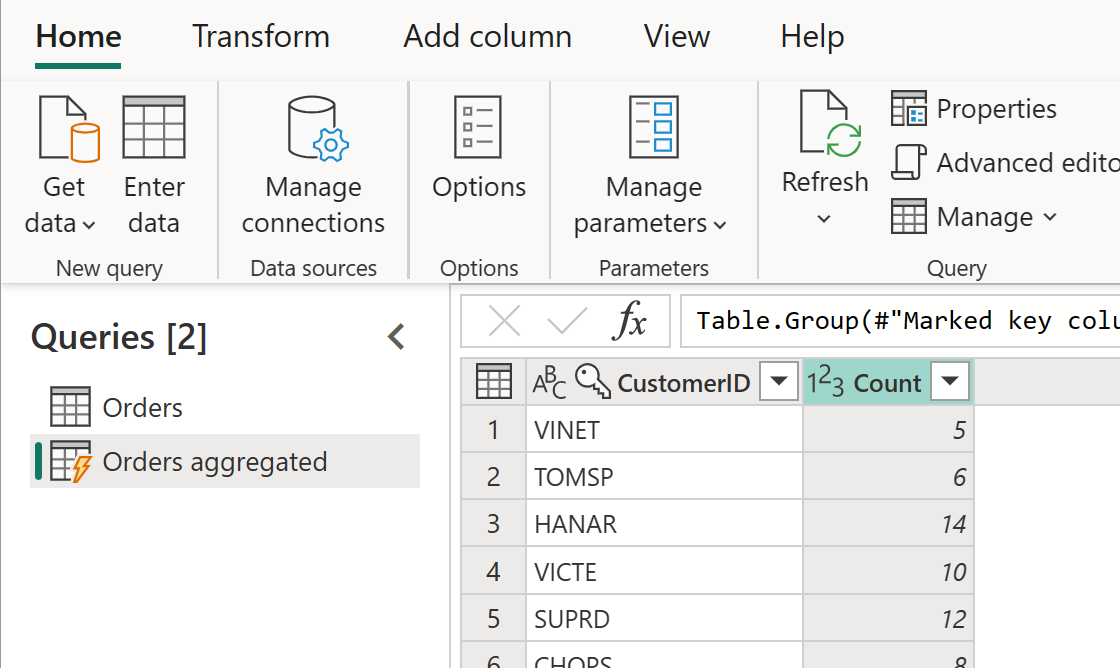
Dies bedeutet, dass die Tabelle „Aggregierte Aufträge“ Daten aus der Tabelle „Aufträge“ und nicht erneut aus der Datenquelle abruft. Da einige der Transformationen, die durchgeführt werden müssen, bereits in der Tabelle „Aufträge“ durchgeführt wurden, ist die Leistung besser und die Datentransformation ist schneller.
Berechnete Tabelle in anderen Dataflows
Sie können auch eine berechnete Tabelle in anderen Dataflows erstellen. Sie kann durch Abrufen von Daten aus einem Dataflow mit dem Microsoft Power Platform-Dataflow-Connector erstellt werden.
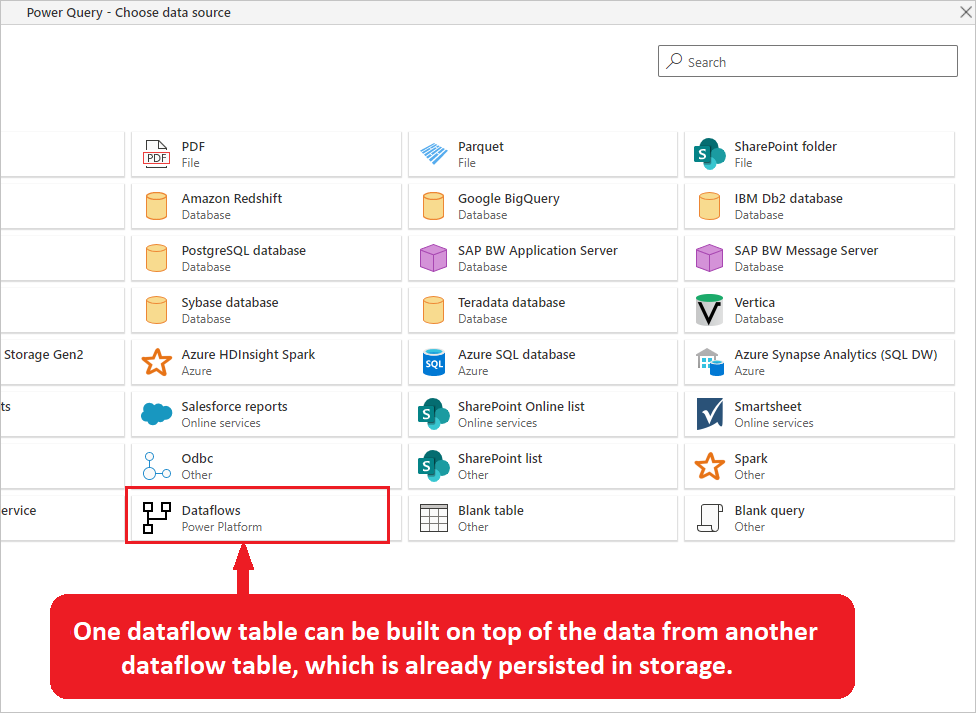
Das Bild hebt den Power Platform-Dataflow-Connector aus dem Power Query-Datenquellenfenster hervor. Außerdem ist eine Beschreibung enthalten, die besagt, dass eine Dataflow-Tabelle auf den Daten aus einer anderen Dataflow-Tabelle aufgebaut werden kann, die bereits im Speicher gespeichert ist.
Das Konzept der berechneten Tabelle besteht darin, eine Tabelle im Speicher zu behalten und andere Tabellen daraus zu beziehen, sodass Sie die Lesezeit aus der Datenquelle verkürzen und einige der allgemeinen Transformationen gemeinsam nutzen können. Diese Reduzierung kann erreicht werden, indem Daten aus anderen Dataflows über den Dataflow-Connector abgerufen oder auf eine andere Abfrage im gleichen Dataflow verwiesen wird.
Berechnete Tabelle: Mit Transformationen oder ohne?
Da Sie nun wissen, dass berechnete Tabellen sich hervorragend zur Verbesserung der Leistung der Datentransformation eignen, stellt sich die Frage, ob Transformationen immer auf die berechnete Tabelle verschoben oder auf die Quelltabelle angewendet werden sollten. Sollten Daten also immer in einer Tabelle erfasst und dann in einer berechneten Tabelle transformiert werden? Was sind die Vor- und Nachteile?
Daten ohne Transformation für Text-/CSV-Dateien laden
Wenn eine Datenquelle die Abfragefaltung nicht unterstützt (z. B. Text-/CSV-Dateien), bietet die Anwendung von Transformationen beim Abrufen von Daten aus der Quelle kaum Vorteile, insbesondere wenn die Datenmengen groß sind. Die Quelltabelle sollte nur Daten aus der Text-/CSV-Datei laden, ohne Transformationen anzuwenden. Anschließend können berechnete Tabellen Daten von der Quelltabelle abrufen und die Transformation zusätzlich zu den erfassten Daten durchführen.
Sie fragen sich vielleicht: Welchen Wert hat es, eine Quelltabelle zu erstellen, die nur Daten erfasst? Eine solche Tabelle kann dennoch nützlich sein, denn wenn die Daten aus der Quelle in mehr als einer Tabelle verwendet werden, verringert sich die Belastung der Datenquelle. Darüber hinaus können Daten jetzt von anderen Personen und Dataflows wiederverwendet werden. Berechnete Tabellen sind besonders nützlich in Szenarien, in denen das Datenvolumen groß ist oder wenn über ein lokales Datengateway auf eine Datenquelle zugegriffen wird, da sie den Datenverkehr vom Gateway und die Belastung der dahinter liegenden Datenquellen reduzieren.
Einige gängige Transformationen für eine SQL-Tabelle ausführen
Wenn Ihre Datenquelle die Abfragefaltung unterstützt, empfiehlt es sich, einige der Transformationen in der Quelltabelle durchzuführen, da die Abfrage in die Datenquelle integriert wird und nur die transformierten Daten von dieser abgerufen werden. Diese Änderungen verbessern die Gesamtleistung. Der Satz von Transformationen, die in nachgelagerten berechneten Tabellen üblich sind, sollte in der Quelltabelle angewendet werden, damit sie auf die Quelle übertragen werden können. Andere Transformationen, die nur für nachgeschaltete Tabellen gelten, sollten in berechneten Tabellen erfolgen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für