Antimuster für ungeeignete Instanziierung
Manchmal werden ständig neue Instanzen einer Klasse erstellt, wenn eigentlich eine Instanz erstellt und dann freigegeben werden sollte. Dieses Verhalten kann die Leistung beeinträchtigen und wird als Antimuster für ungeeignete Instanziierung bezeichnet. Ein Antimuster ist eine häufige Reaktion auf ein wiederkehrendes Problem, die in der Regel ineffektiv ist und sogar kontraproduktiv sein kann.
Problembeschreibung
Viele Bibliotheken stellen Abstraktionen von externen Ressourcen bereit. Intern verwalten diese Klassen in der Regel ihre eigenen Verbindungen mit der Ressource. Dabei fungieren sie als Broker, mit denen Clients auf die Ressource zugreifen können. Im Folgenden werden einige Beispiele für Brokerklassen aufgeführt, die für Azure-Anwendungen relevant sind:
System.Net.Http.HttpClient. Kommuniziert über HTTP mit einem Webdienst.Microsoft.ServiceBus.Messaging.QueueClient. Stellt Nachrichten für eine Service Bus-Warteschlange bereit, und empfängt diese.Microsoft.Azure.Documents.Client.DocumentClient. Stellt eine Verbindung mit einer Azure Cosmos DB-Instanz her.StackExchange.Redis.ConnectionMultiplexer. Stellt eine Verbindung mit Redis, einschließlich Azure Cache für Redis, her.
Diese Klassen sind dafür gedacht, einmal instanziiert und über die gesamte Lebensdauer einer Anwendung hinweg wiederverwendet zu werden. Es ist jedoch ein weit verbreiteter Irrtum, dass diese Klassen nur bei Bedarf erworben und schnell freigegeben werden sollen. (Die hier aufgelisteten Klassen beziehen sich zufälligerweise auf .NET-Bibliotheken, aber das Muster ist nicht eindeutig für .NET.) Im folgenden ASP.NET-Beispiel wird eine Instanz von HttpClient für die Kommunikation mit einem Remotedienst erstellt. Das vollständige Beispiel finden Sie hier.
public class NewHttpClientInstancePerRequestController : ApiController
{
// This method creates a new instance of HttpClient and disposes it for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
using (var httpClient = new HttpClient())
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
}
In einer Webanwendung ist diese Methode nicht skalierbar. Für jede Benutzeranforderung wird ein neues HttpClient-Objekt erstellt. Bei hoher Auslastung kann durch den Webserver die Anzahl der verfügbaren Sockets ausgeschöpft werden, was zu SocketException-Fehlern führt.
Dieses Problem ist nicht auf die HttpClient-Klasse beschränkt. Andere Klassen, die Ressourcen umschließen oder deren Erstellung kostspielig ist, können ähnliche Probleme verursachen. Im folgenden Beispiel wird eine Instanz der ExpensiveToCreateService-Klasse erstellt. Hier ist die Erschöpfung von Sockets nicht unbedingt problematisch, sondern lediglich die Dauer für die Erstellung der einzelnen Instanzen. Das kontinuierliche Erstellen und Zerstören von Instanzen dieser Klasse kann die Skalierbarkeit des Systems beeinträchtigen.
public class NewServiceInstancePerRequestController : ApiController
{
public async Task<Product> GetProductAsync(string id)
{
var expensiveToCreateService = new ExpensiveToCreateService();
return await expensiveToCreateService.GetProductByIdAsync(id);
}
}
public class ExpensiveToCreateService
{
public ExpensiveToCreateService()
{
// Simulate delay due to setup and configuration of ExpensiveToCreateService
Thread.SpinWait(Int32.MaxValue / 100);
}
...
}
Korrigieren des Antimusters für ungeeignete Instanziierung
Wenn die Klasse, die die externe Ressource umschließt, gemeinsam nutzbar und threadsicher ist, erstellen Sie eine gemeinsame Singletoninstanz oder einen Pool von wiederverwendbaren Instanzen der Klasse.
Im folgenden Beispiel wird eine statische HttpClient-Instanz verwendet. Dadurch wird die Verbindung für alle Anforderungen freigegeben.
public class SingleHttpClientInstanceController : ApiController
{
private static readonly HttpClient httpClient;
static SingleHttpClientInstanceController()
{
httpClient = new HttpClient();
}
// This method uses the shared instance of HttpClient for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
Überlegungen
Das Schlüsselelement dieses Antimusters ist das wiederholte Erstellen und Zerstören von Instanzen eines gemeinsam nutzbaren Objekts. Wenn eine Klasse nicht gemeinsam nutzbar (nicht threadsicher) ist, dann wird dieses Antimuster nicht angewendet.
Der Typ der freigegebenen Ressource kann darüber entscheiden, ob Sie ein Singleton verwenden oder einen Pool erstellen sollten. Die
HttpClient-Klasse ist für die gemeinsame Verwendung konzipiert, nicht für das Zusammenfassen in einem Pool. Andere Objekte können das Pooling unterstützen, sodass das System die Workload auf mehrere Instanzen verteilen kann.Objekte, die Sie über mehrere Anforderungen hinweg freigeben, müssen threadsicher sein. Die
HttpClient-Klasse ist zwar für diese Art der Verwendung konzipiert, allerdings kann es sein, dass andere Klassen keine gleichzeitigen Anforderungen unterstützen. Sehen Sie daher in der verfügbaren Dokumentation nach.Gehen Sie beim Festlegen von Eigenschaften für freigegebene Objekte mit Vorsicht vor, da dies zu Racebedingungen führen kann. Beispiel: Wenn in der
HttpClient-Klasse vor jeder AnforderungDefaultRequestHeadersfestgelegt wird, kann eine Racebedingung entstehen. Legen Sie solche Eigenschaften einmal fest (z.B. während des Starts), und erstellen Sie separate Instanzen, wenn Sie andere Einstellungen konfigurieren müssen.Einige Ressourcentypen sind knapp und sollten nicht beibehalten werden. Dies gilt beispielsweise für Datenbankverbindungen. Das Aufrechterhalten einer offenen Datenbankverbindung, die nicht erforderlich ist, kann andere gleichzeitige Benutzer daran hindern, auf die Datenbank zuzugreifen.
Im .NET Framework werden viele Objekte, die Verbindungen mit externen Ressourcen herstellen, mit statischen Factorymethoden anderer Klassen erstellt, die diese Verbindungen verwalten. Diese Objekte sind für die Speicherung und Wiederverwendung bestimmt, nicht für die Löschung und Wiederherstellung. Beispielsweise wird im Azure Service Bus das
QueueClient-Objekt durch einMessagingFactory-Objekt erstellt. Intern verwaltetMessagingFactoryVerbindungen. Weitere Informationen finden Sie unter Bewährte Methoden für Leistungsoptimierungen mithilfe von Service Bus-Messaging.
Erkennen eines Antimusters für ungeeignete Instanziierung
Zu den Symptomen dieses Problems zählen neben einem Rückgang des Durchsatzes oder einer erhöhten Fehlerrate einer oder mehrere der folgenden Punkte:
- Eine Zunahme von Ausnahmen, die auf die Erschöpfung von Ressourcen wie Sockets, Datenbankverbindungen, Dateihandles usw. hinweist
- Erhöhter Speicherverbrauch und Garbage Collection
- Eine Zunahme der Netzwerk-, Festplatten- oder Datenbankaktivität
Sie können die folgenden Schritte durchführen, um dieses Problem zu identifizieren:
- Führen Sie eine Prozessüberwachung des Produktionssystems durch, um Punkte zu identifizieren, an denen Antwortzeiten verlangsamt werden oder aufgrund mangelnder Ressourcen ein Fehler im System auftritt.
- Untersuchen Sie die an diesen Punkten erfassten Telemetriedaten, um festzustellen, welche Vorgänge ressourcenverbrauchende Objekte erstellen und zerstören könnten.
- Führen Sie für jeden vermuteten Vorgang in einer kontrollierten Testumgebung einen Auslastungstest durch (nicht im Produktionssystem).
- Überprüfen Sie den Quellcode, und untersuchen Sie, wie Brokerobjekte verwaltet werden.
Schauen Sie sich Stapelüberwachungen für Vorgänge an, die langsam ablaufen oder Ausnahmen erzeugen, wenn das System ausgelastet ist. Anhand dieser Informationen können Sie erkennen, wie Ressourcen von diesen Vorgängen verwendet werden. Mithilfe von Ausnahmen kann festgestellt werden, ob Fehler dadurch verursacht werden, dass die gemeinsam genutzten Ressourcen ausgeschöpft sind.
Beispieldiagnose
In den folgenden Abschnitten werden diese Schritte auf die zuvor beschriebene Beispielanwendung angewendet.
Identifizieren der Punkte der Verlangsamung oder des Ausfalls
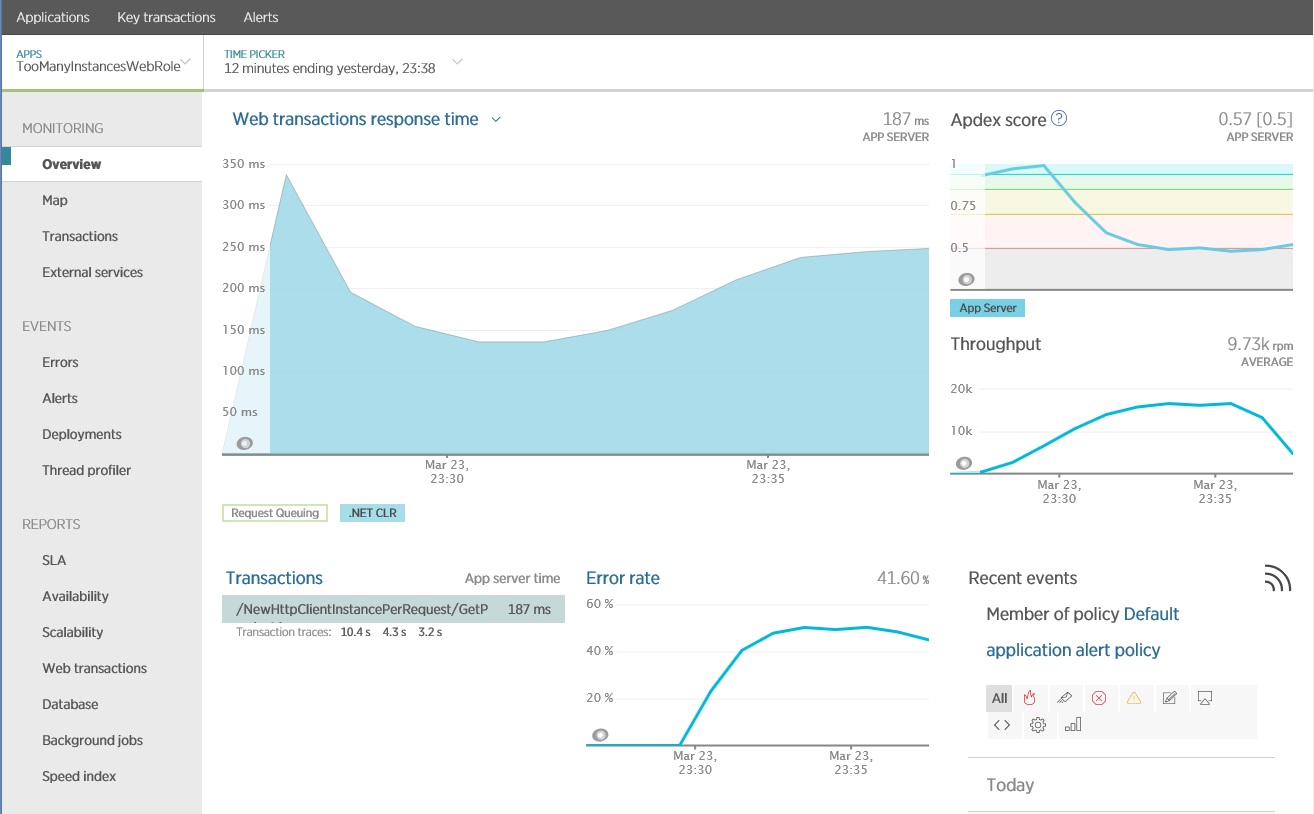
Die folgende Abbildung zeigt mit New Relic APM erzeugte Ergebnisse, die Vorgänge mit einer schlechten Antwortzeit zeigen. In diesem Fall lohnt es sich, sich mit der GetProductAsync-Methode im NewHttpClientInstancePerRequest-Controller näher auseinanderzusetzen. Beachten Sie, dass sich auch die Fehlerrate erhöht, wenn diese Vorgänge ausgeführt werden.
Untersuchen der Telemetriedaten und Ermitteln von Korrelationen
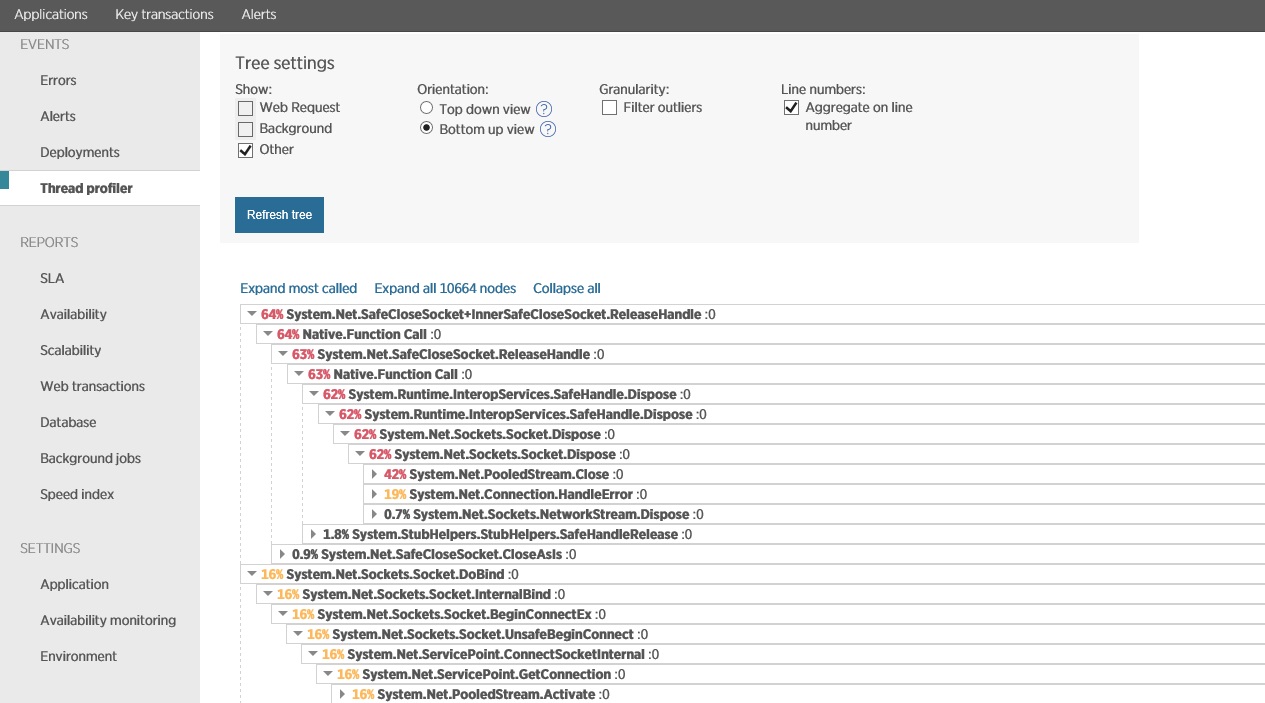
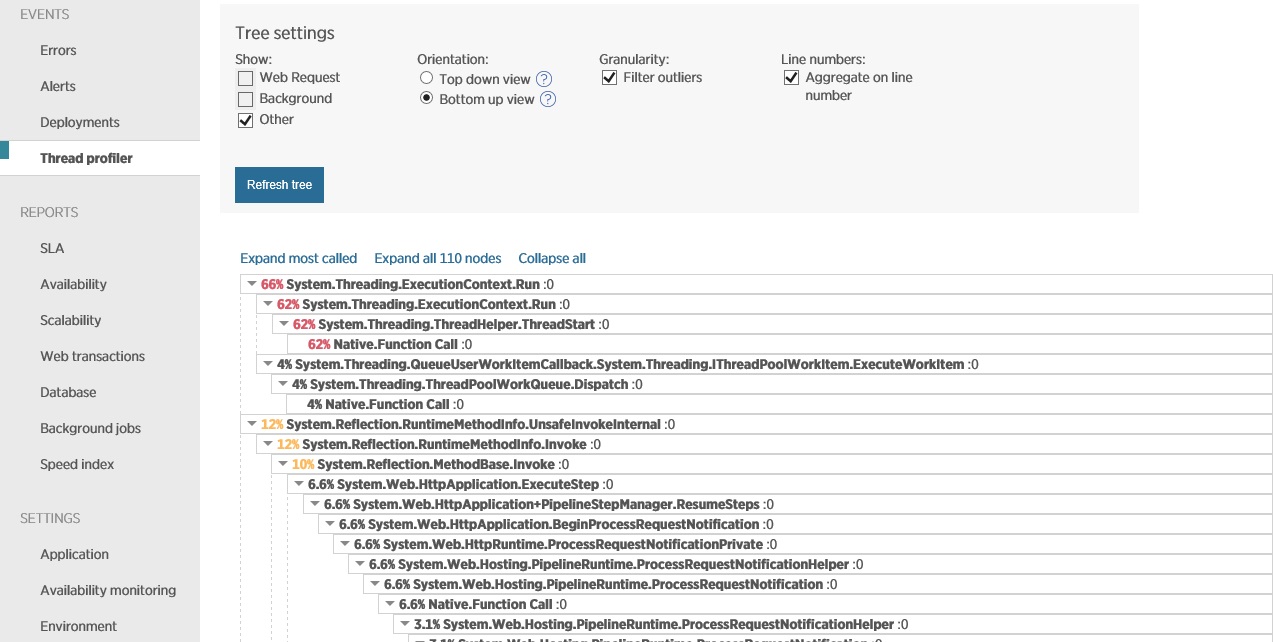
Die nächste Abbildung zeigt Daten, die über denselben Zeitraum wie bei der vorherigen Abbildung mit der Threadprofilerstellung erfasst wurden. Das Öffnen von Socketverbindungen durch das System dauert sehr lange. Das Schließen und Verarbeiten von Socketausnahmen dauert sogar noch länger.
Durchführen von Auslastungstests
Simulieren Sie mithilfe von Auslastungstests typische Vorgänge, die von Benutzern ausgeführt werden könnten. Hierdurch können besser die Teile eines Systems ermittelt werden, bei denen unter wechselnder Belastung Ressourcenauslastung auftritt. Führen Sie diese Tests in einer kontrollierten Umgebung und nicht im Produktionssystem durch. Das folgende Diagramm zeigt den Durchsatz der Anforderungen, die vom NewHttpClientInstancePerRequest-Controller bearbeitet werden, wenn die Benutzerauslastung auf 100 gleichzeitige Benutzer steigt.
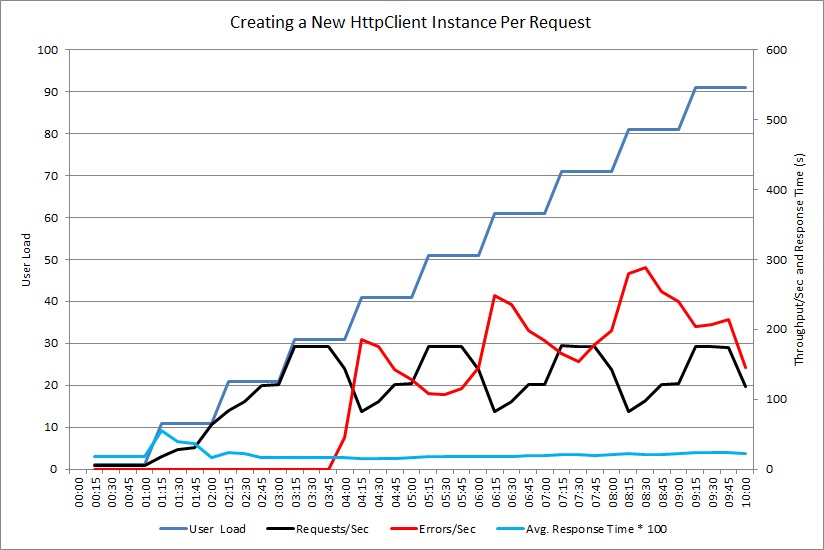
Die Anzahl der pro Sekunde bearbeiteten Anforderungen steigt zunächst mit zunehmender Workloadanzahl. Bei ca. 30 Benutzern erreicht die Anzahl der erfolgreichen Anforderungen jedoch eine Begrenzung, und das System beginnt, Ausnahmen zu generieren. Von da an nimmt die Anzahl der Ausnahmen mit der Benutzerauslastung allmählich zu.
Beim Auslastungstest wurden diese Fehler als „HTTP 500 (Interner Serverfehler)“-Fehler gemeldet. Die Überprüfung der Telemetriedaten ergab, dass diese Fehler dadurch verursacht wurden, dass die Socketressourcen durch das System ausgeschöpft wurden, je mehr HttpClient-Objekte erstellt wurden.
Das nächste Diagramm zeigt einen ähnlichen Test für einen Controller, der das benutzerdefinierte ExpensiveToCreateService-Objekt erstellt.
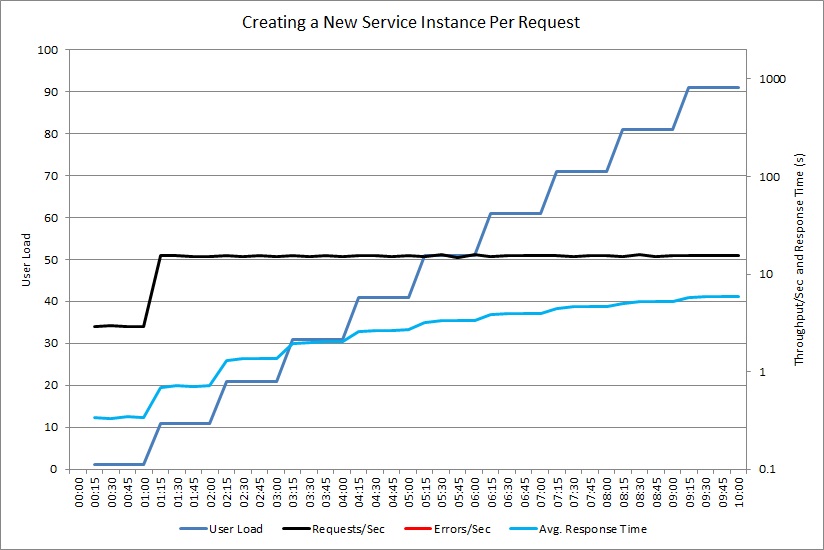
Dieses Mal generiert der Controller keine Ausnahmen, aber der Durchsatz befindet sich nach wie vor im Stillstand, während die durchschnittliche Reaktionszeit um den Faktor 20 zunimmt. (Das Diagramm verwendet eine logarithmische Skalierung für die Antwortzeit und den Durchsatz.) Die Telemetriedaten zeigen, dass die Erstellung neuer ExpensiveToCreateService-Instanzen die Hauptursache des Problems war.
Implementieren der Lösung und Überprüfen des Ergebnisses
Nach dem Wechsel der GetProductAsync-Methode zur Freigabe einer einzelnen HttpClient-Instanz zeigte ein zweiter Auslastungstest, dass die Leistung verbessert wurde. Es wurden keine Fehler gemeldet, und das System war in der Lage, eine steigende Last von bis zu 500 Anforderungen pro Sekunde zu bewältigen. Die durchschnittliche Antwortzeit wurde im Vergleich zum vorherigen Test halbiert.
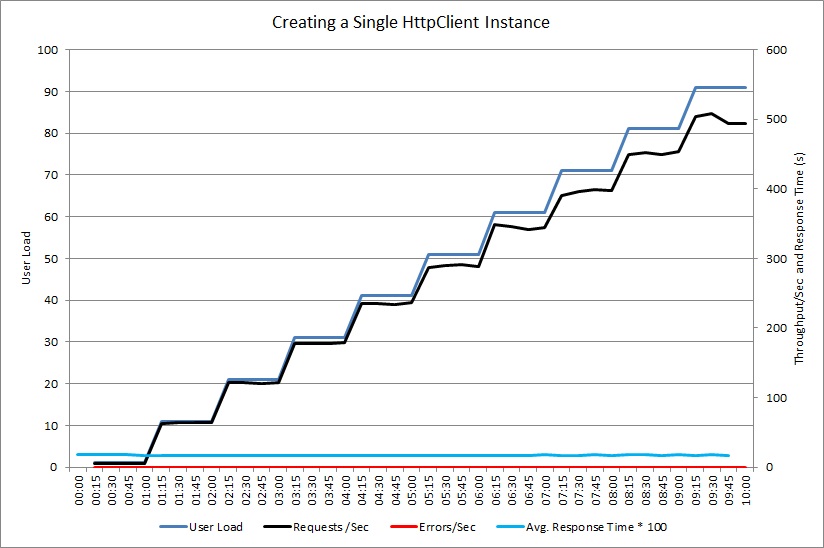
Zum Vergleich: Die folgende Abbildung zeigt die Telemetriedaten der Stapelüberwachung. Dieses Mal wendet das System den Großteil der Zeit für die Durchführung realer Aufgaben statt für das Öffnen und Schließen von Sockets.
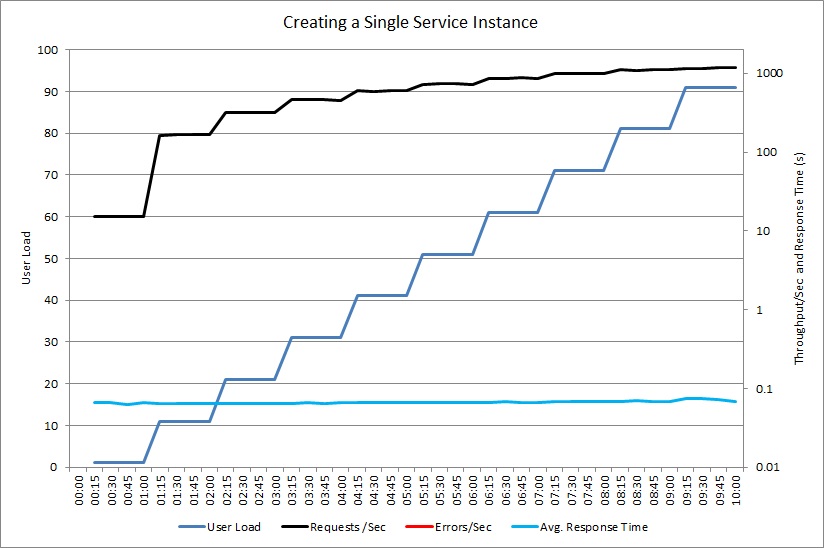
Das nächste Diagramm zeigt einen ähnlichen Auslastungstest mit einer freigegebenen Instanz des ExpensiveToCreateService-Objekts. Auch hier steigt die Anzahl der bearbeiteten Anforderungen mit der Benutzerauslastung, während die durchschnittliche Antwortzeit gering bleibt.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für