Antimuster der monolithischen Persistenz
Das Speichern sämtlicher Daten einer Anwendung in einem einzigen Datenspeicher kann die Leistung beeinträchtigen, weil es entweder zu Ressourcenkonflikten führt oder weil der Datenspeicher sich für einige Daten nicht gut eignet.
Problembeschreibung
Früher verwendeten Anwendungen häufig einen einzigen Datenspeicher, unabhängig von den unterschiedlichen Datentypen, die eine Anwendung speichern muss. Der Grund dafür war üblicherweise, dass der Anwendungsentwurf vereinfacht werden sollte. Eine andere Ursache waren häufig die technischen Fähigkeiten des Entwicklungsteams.
Moderne cloudbasierte Systeme weisen meist zusätzliche funktionelle und nicht funktionelle Anforderungen auf und müssen viele heterogene Arten von Daten speichern – z. B. Dokumente, Bilder, zwischengespeicherte Daten, Nachrichten in Warteschlangen, Anwendungsprotokolle und Telemetriedaten. Das Verfolgen des herkömmlichen Ansatzes und Speichern all dieser Informationen im gleichen Datenspeicher kann hauptsächlich aus zwei Gründen die Leistung beeinträchtigen:
- Das Speichern und Abrufen großer Mengen nicht in Zusammenhang stehender Daten im gleichen Datenspeicher kann zu Konflikten führen, was wiederum lange Antwortzeiten und Verbindungsfehler zur Folge hat.
- Unabhängig davon, welcher Datenspeicher ausgewählt wird, er wird sich vermutlich nicht ideal für all die verschiedenen Arten von Daten eignen oder nicht für die Vorgänge optimiert sein, die von der Anwendung ausgeführt werden.
Das folgende Beispiel zeigt einen ASP.NET-Web-API-Controller, der einen neuen Datensatz zu einer Datenbank hinzufügt und das Ergebnis in einem Protokoll aufzeichnet. Das Protokoll wird in der gleichen Datenbank gespeichert wie die Geschäftsdaten. Das vollständige Beispiel finden Sie hier.
public class MonoController : ApiController
{
private static readonly string ProductionDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
await DataAccess.LogAsync(ProductionDb, LogTableName);
return Ok();
}
}
Die Geschwindigkeit, mit der Protokollzeilen generiert werden, wird sich wahrscheinlich auf die Leistung der Geschäftsvorgänge auswirken. Und wenn eine andere Komponente, z.B. ein Anwendungsprozessmonitor, die Protokolldaten regelmäßig liest und verarbeitet, kann dies die Geschäftsvorgänge ebenfalls beeinträchtigen.
Beheben des Problems
Trennen Sie die Daten je nach Verwendung. Wählen Sie für jedes Dataset den Datenspeicher aus, der sich am besten für den Verwendungszweck des jeweiligen Datasets eignet. Im vorherigen Beispiel sollte die Anwendung die Protokollierung in einem anderen Speicher ausführen als in der Datenbank, die die Geschäftsdaten enthält:
public class PolyController : ApiController
{
private static readonly string ProductionDb = ...;
private static readonly string LogDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
// Log to a different data store.
await DataAccess.LogAsync(LogDb, LogTableName);
return Ok();
}
}
Überlegungen
Trennen Sie die Daten nach der Art der Verwendung und des Zugriffs. Speichern Sie beispielsweise Protokollinformationen und Geschäftsdaten nicht im gleichen Datenspeicher. Diese Datentypen weisen sehr unterschiedliche Anforderungen und Zugriffsmuster auf. Protokolleinträge sind von Natur aus sequenziell, während Geschäftsdaten wahrscheinlich einen zufallsbasierten Zugriff erfordern und häufig relational sind.
Berücksichtigen Sie die Datenzugriffsmuster für jeden Datentyp. Speichern Sie beispielsweise formatierte Berichte und Dokumente in einer Dokumentdatenbank wie Azure Cosmos DB, und verwenden Sie Azure Cache for Redis zum Zwischenspeichern temporärer Daten.
Wenn Sie diese Leitlinien befolgen, die Datenbank aber dennoch ihre Grenze erreicht, müssen Sie die Datenbank möglicherweise hochskalieren. Erwägen Sie auch, die Datenbank horizontal zu skalieren und die Last auf verschiedenen Datenbankserver zu partitionieren. Für die Partitionierung muss jedoch möglicherweise der Anwendungsentwurf geändert werden. Weitere Informationen finden Sie unter Datenpartitionierung.
Erkennen des Problems
Das System wird sich wahrscheinlich erheblich verlangsamen und letztendlich ausfallen, da nicht genügend Ressourcen wie z.B. Datenbankverbindungen vorhanden sind.
Sie können die folgenden Schritte ausführen, um die Ursache zu ermitteln.
- Instrumentieren Sie das System, um die wichtigsten Leistungsstatistiken aufzuzeichnen. Erfassen Sie Zeitinformationen für jeden Vorgang sowie die Punkte, an denen die Anwendung Daten liest und schreibt.
- Überwachen Sie nach Möglichkeit das ausgeführte System einige Tage lang in einer Produktionsumgebung, um herauszufinden, wie das System in der Praxis verwendet wird. Wenn dies nicht möglich ist, führen Sie skriptbasierte Auslastungstests mit einer realistischen Menge an virtuellen Benutzern durch, die eine typische Reihe von Vorgängen ausführen.
- Verwenden Sie die Telemetriedaten, um Zeiträume unzureichender Leistung zu identifizieren.
- Ermitteln Sie, auf welche Datenspeicher während dieser Zeiträume zugegriffen wurde.
- Identifizieren Sie die Datenspeicherressourcen, bei denen möglicherweise Konflikte auftreten.
Beispieldiagnose
In den folgenden Abschnitten werden diese Schritte auf die zuvor beschriebene Beispielanwendung angewendet.
Instrumentieren und Überwachen des Systems
Das folgende Diagramm zeigt die Ergebnisse des Auslastungstests der oben beschriebenen Beispielanwendung. Bei diesem Test wurde eine Schrittauslastung von bis zu 1.000 gleichzeitigen Benutzern verwendet.
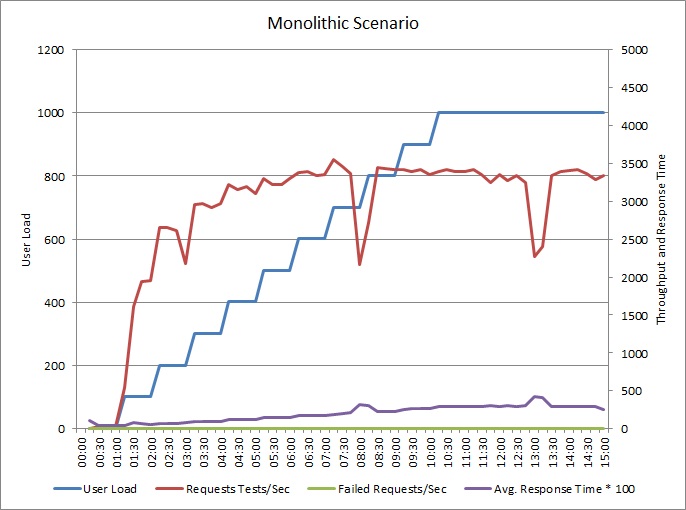
Wenn die Auslastung auf 700 Benutzer steigt, steigt auch der Durchsatz. An diesem Punkt sinkt der Durchsatz, und das System wird anscheinend mit maximaler Kapazität ausgeführt. Die durchschnittliche Antwortzeit steigt langsam mit der Benutzerauslastung, was zeigt, dass das System mit den Anforderungen nicht mithalten kann.
Identifizieren von Zeiträumen unzureichender Leistung
Wenn Sie das Produktionssystem überwachen, stellen Sie möglicherweise Muster fest. Möglicherweise sinken Antwortzeiten zu jeder Tageszeit erheblich. Dies könnte durch eine regelmäßige Workload oder einen geplanten Batchauftrag verursacht werden oder einfach daran liegen, dass sich zu bestimmten Zeiten mehr Benutzer im System befinden. Sie sollten sich auf die Telemetriedaten für diese Ereignisse konzentrieren.
Suchen Sie nach Zusammenhängen zwischen erhöhten Antwortzeiten und vermehrten Datenbankaktivitäten oder E/A-Vorgängen in gemeinsam genutzten Ressourcen. Wenn solche Zusammenhänge zu erkennen sind, kann dies bedeuten, dass die Datenbank einen Engpass darstellt.
Ermitteln, auf welche Datenspeicher während dieser Zeiträume zugegriffen wurde
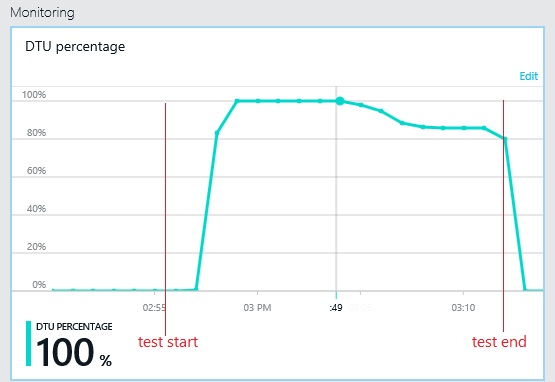
Das nächste Diagramm zeigt die DTU-Nutzung (Database Throughput Units, Datenbankdurchsatzeinheiten) während des Auslastungstests. (Eine DTU ist ein Maß der verfügbaren Kapazität und setzt sich aus CPU-Auslastung, Arbeitsspeicherzuweisung und E/A-Rate zusammen.) Die Auslastung der DTUs erreichte schnell 100 %. Dies ist ungefähr der Punkt, an dem der Durchsatz im vorherigen Diagramm den Spitzenwert erreichte. Die Datenbankauslastung blieb bis zum Ende des Tests sehr hoch. Gegen Ende ist ein leichtes Abfallen zu beobachten, das durch Drosselung, konkurrierende Datenbankverbindungen oder andere Faktoren entstanden sein kann.
Untersuchen der Telemetrie für die Datenspeicher
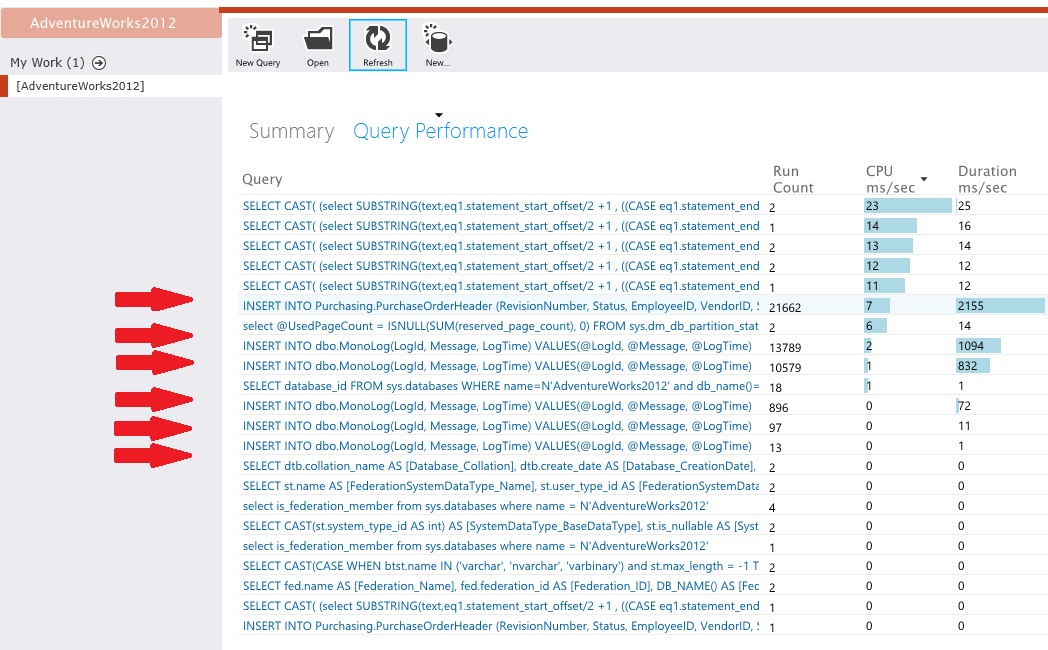
Instrumentieren Sie die Datenspeicher, um die Details der Aktivität auf niedriger Ebene zu erfassen. In der Beispielanwendung zeigten die Datenzugriffsstatistiken eine große Menge an Einfügevorgängen, die sowohl für die Tabelle PurchaseOrderHeader als auch für die Tabelle MonoLog ausgeführt wurden.
Identifizieren von Ressourcenkonflikten
An diesem Punkt können Sie den Quellcode überprüfen, und sich dabei auf die Punkte konzentrieren, an denen die Anwendung auf Ressourcen mit Konflikten zugegriffen hat. Suchen Sie nach Situationen wie etwa den folgenden:
- Daten, die logisch getrennt sind, werden in den gleichen Speicher geschrieben. Daten wie Protokolle, Berichte und Nachrichten in Warteschlangen sollten nicht in der gleichen Datenbank gespeichert werden wie Geschäftsdaten.
- Der Datenspeicher und die Art der Daten, die darin gespeichert werden sollen, stimmen nicht überein, beispielsweise werden große Blobs oder XML-Dokumente in einer relationalen Datenbank gespeichert.
- Daten mit erheblich unterschiedlichen Nutzungsmustern befinden sich im gleichen Speicher, z.B. werden Daten mit hohen Schreib-, aber geringen Leseanforderungen zusammen mit Daten mit geringen Schreib-, aber hohen Leseanforderungen gespeichert.
Implementieren der Lösung und Überprüfen des Ergebnisses
Die Anwendung wurde geändert und schreibt Protokolle jetzt in einen separaten Datenspeicher. Hier sind die Ergebnisse des Auslastungstests:
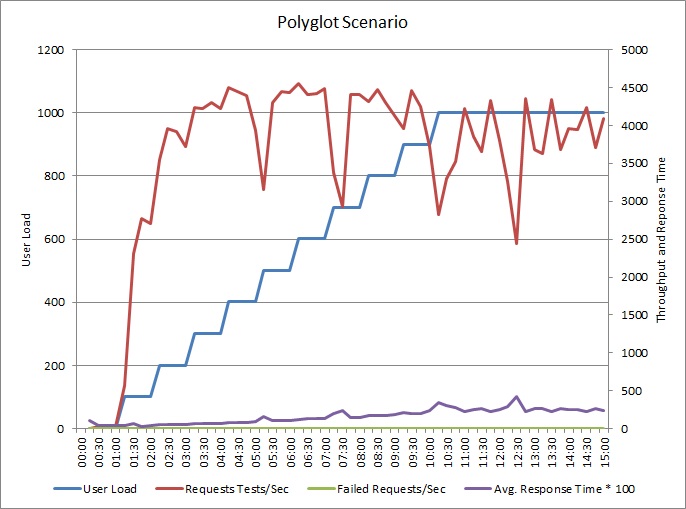
Das Durchsatzmuster ähnelt dem vorherigen Diagramm, aber der Punkt, an dem die Leistung ihren Spitzenwert erreicht, liegt etwa 500 Anforderungen pro Sekunde höher. Die durchschnittliche Antwortzeit ist geringfügig geringer. Diese Statistiken erzählen jedoch nicht die ganze Geschichte. Die Telemetrie für die Geschäftsdatenbank zeigt, dass die DTU-Auslastung ihren Spitzenwert bei etwa 75 % erreicht, nicht bei 100 %.
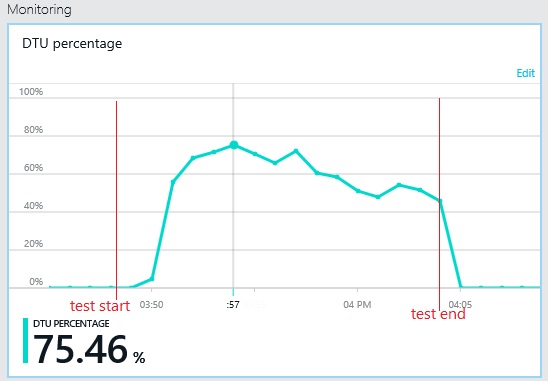
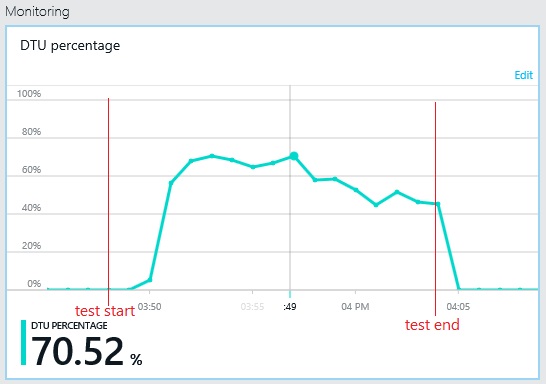
Ebenso erreicht die maximale DTU-Auslastung der Protokolldatenbank nur etwa 70 %. Die Datenbanken sind nicht mehr der Faktor, der die Leistung des Systems einschränkt.
Zugehörige Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für