Bereitstellungsphase des Team Data Science-Prozesslebenszyklus
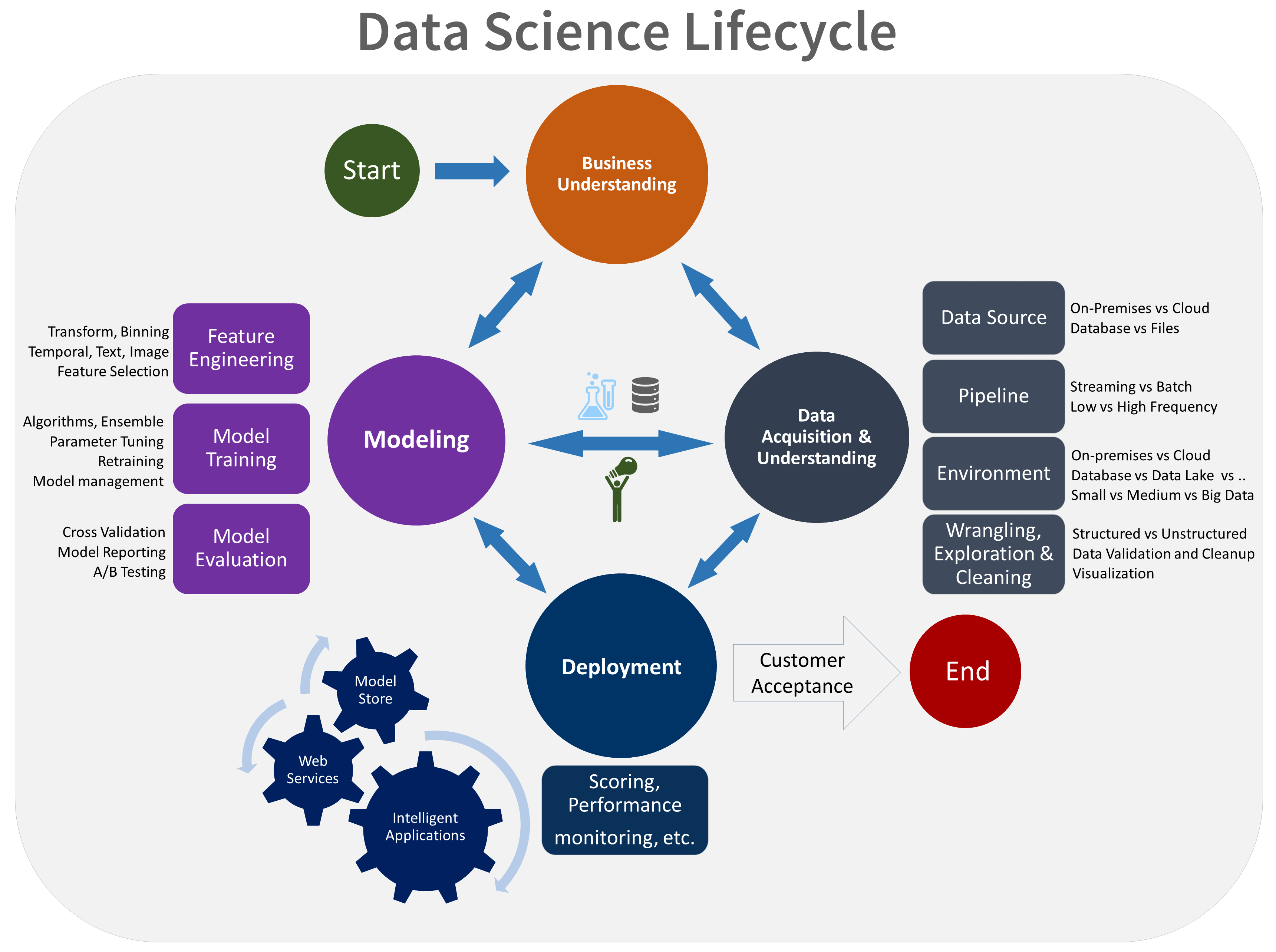
In diesem Artikel werden die Ziele, Aufgaben und Projektleistungen im Zusammenhang mit der Bereitstellung des Team Data Science-Prozesses (TDSP) behandelt. Dieser Prozess stellt einen empfohlenen Lebenszyklus bereit, mit dem Ihr Team Ihre Data Science-Projekte strukturieren kann. Der Lebenszyklus beschreibt die wesentlichen Projektphasen, an denen Ihr Team arbeitet, häufig auf iterative Weise:
- Geschäftliche Aspekte
- Datenerfassung und -auswertung
- Modellierung
- Bereitstellung
- Kundenakzeptanz
Dies ist eine visuelle Darstellung des TDSP-Lebenszyklus:
Ziel
Das Ziel der Bereitstellungsphase besteht darin, Modelle mit einer Datenpipeline in einer Produktions- oder produktionsähnlichen Umgebung bereitzustellen, um die endgültige Annahme durch den Kunden zu erhalten.
Ausführung der Aufgabe
Die Hauptaufgabe in dieser Phase besteht in der Operationalisierung des Modells. Stellen Sie das Modell und die Pipeline in einer Produktionsumgebung oder produktionsähnlichen Umgebung zur Nutzung der Anwendung bereit.
Operationalisieren eines Modells
Nach der Erstellung eines Satzes gut funktionierender Modelle kann Ihr Team diese Modelle operationalisieren, damit sie von anderen Anwendungen genutzt werden können. Abhängig von den Geschäftsanforderungen erfolgen Vorhersagen entweder in Echtzeit oder auf Batchbasis. Um Modelle bereitzustellen, machen Sie diese über eine offene API-Schnittstelle verfügbar. Über diese Schnittstelle können Benutzer*innen das Modell auf einfache Weise über verschiedene Anwendungen nutzen, z. B.
- Websites
- Kalkulationstabellen
- Dashboards
- Branchenanwendungen
- Back-End-Anwendungen
Beispiele für die Operationalisierung von Modellen mit Azure Machine Learning finden Sie unter Bereitstellen von Machine Learning-Modellen in Azure. Die Integration von Überwachungsfunktionen in das bereitgestellte Produktionsmodell und die bereitgestellte Datenpipeline gilt als bewährte Methode. Diese Vorgehensweise erleichtert nachfolgende Systemstatus-Berichtserstellung und Problembehandlung.
Integration in MLflow
Zur Unterstützung dieser Phase können Sie die folgenden Azure Machine Learning-Funktionen integrieren:
Modellverwaltung: Sie platzieren ein Modell in einer Produktions- oder Betriebsumgebung, um eine Bereitstellung vorzubereiten. MLflow verwaltet und versioniert bereitstellungsfähige Modelle. Dies trägt zur Verbesserung der Operationalisierung bei.
Modellbereitstellung: Die Modellfunktionen von MLflow unterstützen den Bereitstellungsprozess, sodass Sie Modelle problemlos in verschiedenen Umgebungen bereitstellen können.
Artifacts
In dieser Phase erzielt Ihr Team die folgenden Ergebnisse:
Statusdashboard mit Anzeige von Systemzustand und wichtigen Metriken. Sie sollten Power BI zum Erstellen des Dashboards verwenden.
Abschließender Bericht zur Modellierung mit Details zur Bereitstellung.
Dokument mit einer Beschreibung der endgültigen Lösungsarchitektur.
Peer-geprüfte Literatur
Forscher*innen veröffentlichen Studien zum TDSP in Peer-geprüfter Literatur. Die Referenzen bieten eine Möglichkeit, andere Anwendungen oder dem TDSP vergleichbare Ansätze zu untersuchen, die ebenfalls eine Bereitstellungsphase umfassen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Mark Tabladillo | Senior Cloud Solution Architect
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Zugehörige Ressourcen
Diese Artikel beschreiben die übrigen Phasen des TDSP-Lebenszyklus:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für