Rollen und Aufgaben im Team Data Science-Prozess
Der Team Data Science-Prozess (TDSP) ist ein von Microsoft entwickeltes Framework, mit dem eine strukturierte Methodik zum effizienten Erstellen von Predictive Analytics-Lösungen und von intelligenten Anwendungen bereitgestellt wird. In diesem Artikel finden Sie eine Übersicht über die wichtigsten Mitarbeiterrollen und die zugeordneten Aufgaben für ein Data Science-Team, das diesen Prozess standardmäßig einsetzt.
Zur Ergänzung der in Azure Machine Learning gespeicherten MLflow-Artefakte wird eine Git-kompatible Umgebung empfohlen. Azure Machine Learning kann in Git-Repositorys integriert werden. Daher können Sie zahlreiche Git-kompatible Dienste verwenden, wie GitHub, GitLab, Bitbucket, Azure DevOps oder andere Git-kompatible Dienste.
Struktur von Data Science-Gruppen und -Teams
Data Science-Funktionen werden in Unternehmen häufig gemäß der folgenden Hierarchie strukturiert:
- Data Science-Gruppe
- Data Science-Teams innerhalb der Gruppe
In einer Struktur dieser Art gibt es Gruppen- und Teamleiter. In der Regel führt ein Data Science-Team ein Data Science-Projekt aus. Data Science-Teams verfügen über Projektleiter für Projektmanagement und Governancetasks und über einzelne Data Scientists und Techniker, die die Data Science- und Data Engineering-Aufgaben des Projekts durchführen. Die Gruppe, das Team oder die Projektleiter*innen sind für die anfängliche Einrichtung des Projekts und die Governance verantwortlich.
Definition und Aufgaben für die vier TDSP-Rollen
Falls die Data Science-Einheit aus Teams innerhalb einer Gruppe besteht, gibt es für TDSP-Mitarbeiter vier Rollen:
Gruppenleiter*innen: Leitung der gesamten Data Science-Einheit im Unternehmen. Eine Data Science-Einheit kann aus mehreren Teams bestehen, die jeweils an verschiedenen Data Science-Projekten in unterschiedlichen geschäftlichen Bereichen arbeiten. Gruppenleiter*innen können ihre Aufgaben zwar an Stellvertreter*innen delegieren, die mit der Rolle verbundenen Aufgaben bleiben jedoch unverändert.
Teamleiter*innen: Leitung eines Teams in der Data Science-Einheit des Unternehmens. Ein Team besteht aus Data Scientists. In einer kleineren Data Science-Einheit kann es sich bei Gruppenleiter*innen und Teamleiter*innen um dieselben Personen handeln.
Projektleiter*innen: Leitung der täglichen Aktivitäten der einzelnen Datenanalyst*innen in einem bestimmten Data Science-Projekt.
Projektmitwirkende: Data Scientists, Business Analysts, Datentechniker*innen, Architekt*innen und andere Personen, die ein Data Science-Projekt ausführen.
Hinweis
Abhängig von Struktur und Größe eines Unternehmens kann eine einzelne Person mehrere Rollen innehaben oder eine einzelne Rolle kann von mehreren Personen ausgeübt werden.
Aufgaben der vier Rollen
Das folgende Diagramm zeigt die Aufgaben der einzelnen TDSP-Rollen auf der obersten Ebene. Diese Übersicht und die folgende detaillierte Beschreibung der Aufgaben der einzelnen TDSP-Rollen kann Ihnen helfen, das richtige Tutorial entsprechend Ihren Zuständigkeiten auszuwählen.
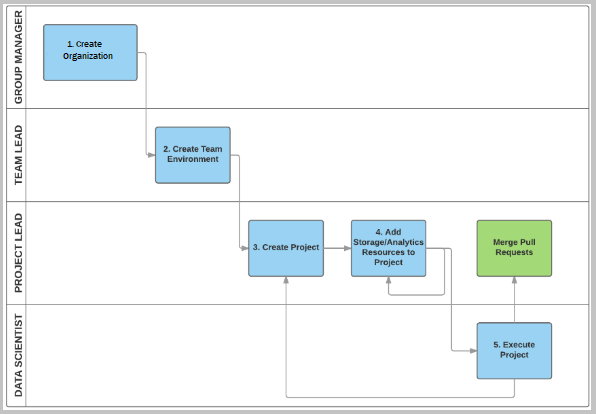
Aufgaben von Gruppenleiter*innen
Gruppenleiter*innen oder festgelegte TDSP-Systemadministrator*innen führen die folgenden Aufgaben aus, um den TDSP einzuführen:
Erstellt eine Azure DevOps-Organisation und anschließend darin ein Gruppenprojekt.
Erstellt im Azure DevOps-Gruppenprojekt ein Projektvorlagenrepository und führt dafür über das vom Microsoft TDSP-Team entwickelte Projektvorlagenrepository das Seeding durch. Das Microsoft TDSP-Projektvorlagenrepository enthält Folgendes:
- Eine standardisierte Verzeichnisstruktur mit Verzeichnissen für Daten, Code und Dokumente.
- Eine Gruppe von standardisierten Dokumentvorlagen zur Sicherstellung eines effizienten Data Science-Prozesses.
Erstellt ein Hilfsprogrammrepository und führt dafür über das vom Microsoft TDSP-Team entwickelte Hilfsprogrammrepository das Seeding durch. Das TDSP-Hilfsprogrammrepository von Microsoft enthält einige nützliche Hilfsprogramme, um die Arbeit von Data Scientists effizienter zu machen. Das Microsoft-Hilfsprogrammrepository enthält Hilfsprogramme für die interaktive Datenuntersuchung, Analyse, Berichterstellung und Basismodellierung/-berichterstattung.
Richtet die Sicherheitskontrollrichtlinie für das Organisationskonto ein.
Weitere Informationen finden Sie unter Aufgaben von Gruppenleiter*innen für Data Science-Teams.
Aufgaben von Teamleiter*innen
Teamleiter*innen oder festgelegte Projektadministrator*innen führen die folgenden Aufgaben aus, um den TDSP einzuführen:
Erstellt in der Azure DevOps-Organisation der Gruppe ein Teamprojekt.
Erstellung des Projektvorlagenrepositorys im Projekt und dessen Verteilung über das Projektvorlagenrepository der Gruppe, das vom/von der Gruppenleiter*in oder dem/der Stellvertreter*in eingerichtet wurde.
Erstellt das Hilfsprogrammrepository für das Team, führt über das Hilfsprogrammrepository der Gruppe das Seeding durch und fügt dem Repository teamspezifische Hilfsprogramme hinzu.
Erstellt optional Azure-Dateispeicher, in dem die hilfreichen Datenressourcen des Teams gespeichert werden. Die anderen Teammitglieder können diesen freigegebenen Cloud-Dateispeicher auf ihren Analysedesktops bereitstellen.
Optionale Bereitstellung des Azure-Dateispeichers in der Data Science Virtual Machine (DSVM) des Teams und Hinzufügung von Datenressourcen des Teams zur DSVM.
Richtet eine Sicherheitskontrolle ein, indem Teammitglieder hinzugefügt und die zugehörigen Berechtigungen konfiguriert werden.
Weitere Informationen finden Sie unter Aufgaben von Teamleiter*innen für Data Science-Teams.
Aufgaben von Projektleiter*innen
Projektleiter*innen führen die folgenden Aufgaben aus, um den TDSP einzuführen:
Erstellt im Teamprojekt ein Projektrepository und führt dafür über das Projektvorlagenrepository das Seeding durch.
Erstellt optional Azure-Dateispeicher, in dem die Datenressourcen des Projekts gespeichert werden.
Optionale Bereitstellung des Azure-Dateispeichers in der Data Science Virtual Machine (DSVM) und Hinzufügung von Datenressourcen des Projekts zur DSVM.
Richtet eine Sicherheitskontrolle ein, indem Projektmitglieder hinzugefügt und die zugehörigen Berechtigungen konfiguriert werden.
Weitere Informationen finden Sie unter Aufgaben von Projektleiter*innen für Data Science-Teams.
Aufgaben von Projektmitwirkenden
Projektmitwirkende, in der Regel Data Scientists, führen folgende Aufgaben mittels des TDSP aus:
Klont das Projektrepository, das vom Projektleiter eingerichtet wurde.
Optionale Bereitstellung des geteilten Azure-Dateispeichers für das Team und das Projekt in der Data Science Virtual Machine (DSVM).
Führt das Projekt aus.
Weitere Informationen finden Sie unter Aufgaben von Projektmitwirkenden für Data Science-Teams.
Ausführungsworkflow des Data Science-Projekts
Data Scientists, Projektleiter*innen und Teamleiter*innen können Arbeitselemente erstellen, um alle Aufgaben und Phasen eines Projekts durchgängig nachzuverfolgen. In der folgenden Abbildung ist der TDSP-Workflow für die Projektausführung dargestellt:
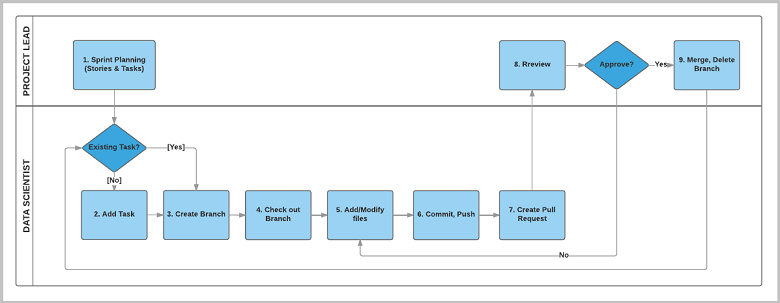
Die Workflowschritte können nach drei Aktivitäten gruppiert werden:
Projektleiter*innen führen die Planung von Sprints aus.
Data Scientists entwickeln Artefakte in
git-Branches, um Arbeitselemente zu berücksichtigen.Projektleiter*innen oder andere Teammitglieder führen Codeüberprüfungen durch und führen Arbeitsbranches mit dem primären Branch zusammen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Mark Tabladillo | Senior Cloud Solution Architect
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Zugehörige Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für