Dieser Artikel enthält eine Liste der Elemente, die Sie beim Verschieben einer IoT-Lösung in eine Produktionsumgebung berücksichtigen sollten.
Verwenden von Bereitstellungsstempeln
Stempel sind eigenständige Einheiten von Kernlösungskomponenten, die eine definierte Anzahl von Geräten unterstützen. Jede Kopie wird als Stempel oder Skalierungseinheit bezeichnet. Ein Stempel könnte beispielsweise aus einer festgelegten Gerätepopulation, einem IoT Hub, einem Event Hub oder einem anderen Routingendpunkt und einer Verarbeitungskomponente bestehen. Jeder Stempel unterstützt eine definierte Gerätepopulation. Sie wählen die maximale Anzahl von Geräten aus, die der Stempel enthalten kann. Während die Gerätepopulation wächst, fügen Sie Stempelinstanzen hinzu, statt verschiedene Teile der Lösung unabhängig voneinander hochzuskalieren.
Wenn Sie keine Stempel hinzufügen, sondern eine einzelne Instanz Ihrer IoT-Lösung in die Produktion verschieben, könnten die folgenden Einschränkungen auftreten:
Skalierungsgrenzwerte: Ihre Einzelinstanz kann Skalierungsgrenzwerte erreichen. So könnte Ihre Lösung beispielsweise Dienste nutzen, bei denen es Grenzwerte für die Anzahl von eingehenden Verbindungen, Hostnamen, TCP-Sockets oder anderen Ressourcen gibt.
Nichtlineare Skalierung oder Kosten: Ihre Lösungskomponenten werden möglicherweise mit der Anzahl der Anforderungen oder der Menge der erfassten Daten nicht linear skaliert. Stattdessen könnte es bei einigen Komponenten zu einer Verringerung der Leistung oder einer Erhöhung der Kosten kommen, sobald ein Schwellenwert erreicht wurde. Das Hochskalieren mit mehr Kapazität ist möglicherweise keine so gute Strategie wie das horizontale Skalieren durch Hinzufügen von Stempeln.
Trennung von Kunden: Möglicherweise müssen Sie die Daten bestimmter Kunden von denen anderer Kunden isolieren. Ebenso ist es möglich, dass einige Ihrer Kunden mehr Systemressourcen benötigen als andere und Sie deshalb erwägen, sie auf verschiedenen Stempeln zu gruppieren.
Einzelinstanzen und mehrinstanzenfähige Instanzen: Möglicherweise haben Sie einige große Kunden, die ihre eigenen unabhängigen Instanzen Ihrer Lösung benötigen. Vielleicht haben Sie außerdem einen Pool kleinerer Kunden, die eine mehrinstanzenfähige Bereitstellung gemeinsam nutzen können.
Komplexe Bereitstellungsanforderungen: Möglicherweise müssen Sie Updates für Ihren Dienst kontrolliert und zu unterschiedlichen Zeiten auf verschiedenen Stempeln bereitstellen.
Aktualisierungshäufigkeit: Bei einigen Ihrer Kunden könnten häufige Updates Ihres Systems akzeptabel sein, während andere die damit verbundenen Risiken scheuen und seltene Aktualisierungen Ihres Dienstes wünschen.
Geografische oder geopolitische Einschränkungen: Um die Latenz zu verringern oder die Anforderungen an die Datenhoheit zu erfüllen, können Sie einige Ihrer Kunden in bestimmten Regionen bereitstellen.
Zur Vermeidung der vorstehenden Probleme sollten Sie Ihren Dienst in mehrere Stempel gruppieren. Stempel arbeiten unabhängig voneinander und können unabhängig voneinander bereitgestellt und aktualisiert werden. Eine einzelne geografische Region kann einen einzelnen Stempel oder mehrere Stempel enthalten, um eine horizontale Skalierung innerhalb der Region zu ermöglichen. Jeder Stempel enthält eine Teilmenge Ihrer Kunden.
Verwenden von Backoff bei Auftreten eines vorübergehenden Fehlers
Alle Anwendungen, die mit Remotediensten und Ressourcen kommunizieren, müssen gegenüber vorübergehenden Fehlern empfindlich sein. Dies gilt insbesondere für Anwendungen, die in der Cloud ausgeführt werden und bei denen die Art der Umgebung und Konnektivität über das Internet bedeutet, dass diese Arten von Fehlern wahrscheinlich häufiger auftreten können. Vorübergehende Fehler sind z. B.:
- Kurzzeitiger Verlust der Netzwerkkonnektivität mit Komponenten und Diensten
- Vorübergehende Nichtverfügbarkeit eines Dienstes
- Timeouts, die auftreten, wenn ein Dienst ausgelastet ist
- Kollisionen, die verursacht werden, wenn Geräte gleichzeitig übertragen
Diese Fehler werden häufig automatisch behoben und wenn die Aktion nach einer angemessenen Verzögerung wiederholt wird, wird sie wahrscheinlich erfolgreich ausgeführt werden. Das Ermitteln der geeigneten Intervalle zwischen Wiederholungen ist jedoch schwierig. Typische Strategien verwenden die folgenden Arten von Wiederholungsintervallen:
- Exponentielles Backoff. Die Anwendung wartet vor dem ersten Wiederholungsversuch kurz und verlängert dann exponentiell die Abstände zwischen jedem nachfolgenden Wiederholungsintervall. Z. B. wird der Vorgang nach 3 Sekunden, 12 Sekunden, 30 Sekunden, usw. wiederholt.
- Regelmäßige Intervalle. Die Anwendung wartet zwischen jedem Versuch gleich lang. Beispielsweise wird der Vorgang alle 3 Sekunden wiederholt.
- Sofortiger Wiederholungsversuch. Manchmal ist ein vorübergehender Fehler kurz, vielleicht durch ein Ereignis wie z.B. einen Netzwerkpaket-Konflikt oder einen Spike in einer Hardwarekomponente verursacht. In diesem Fall ist das sofortige Wiederholen des Vorgangs geeignet, da dies erfolgreich sein kann, wenn der Fehler in der Zeit behoben wurde, die die Anwendung benötigt, um die nächste Anforderung zusammenzustellen und zu senden. Allerdings sollte nie mehr als ein sofortiger Wiederholungsversuch unternommen werden, und Sie sollten auf alternative Strategien zurückgreifen, wie z.B. exponentielles Backoff oder Fallback-Aktionen, wenn die sofortige Wiederholung fehlschlägt.
- Zufällige Anordnung. Jede der vorstehenden Wiederholungsstrategien kann ein Element zufälliger Anordnung enthalten, um zu verhindern, dass mehrere Instanzen des Clients aufeinanderfolgende Wiederholungsversuche gleichzeitig senden.
Vermeiden Sie außerdem die folgenden Antimuster:
- Implementierungen sollten keine duplizierten Ebenen von Wiederholungscode enthalten.
- Implementieren Sie niemals einen endlosen Wiederholungsmechanismus.
- Führen Sie nie öfter als einmal eine sofortige Wiederholung durch.
- Vermeiden Sie die Verwendung eines regelmäßigen Wiederholungsintervalls.
- Vermeiden Sie, dass mehrere Instanzen desselben Client oder mehrere Instanzen verschiedener Clients zur gleichen Zeit Wiederholungen senden.
Verwenden der Bereitstellung ohne Benutzereingreifen (Zero Touch)
Bereitstellung ist das Anmelden eines Geräts bei Azure IoT Hub. Durch die Bereitstellung wird IoT Hub auf das Gerät und den vom Gerät verwendeten Nachweismechanismus hingewiesen. Sie können den Azure IoT Hub Device Provisioning Service (DPS) nutzen oder über IoT Hub Registrierungs-Manager-APIs direkt bereitstellen. Die Verwendung von DPS hat den Vorteil der späten Bindung, über die Sie Feldgeräte von IoT Hub entfernen und erneut bereitstellen können, ohne die Gerätesoftware zu ändern.
Im folgenden Beispiel wird gezeigt, wie ein Übergangsworkflow von der Test- in die Produktionsumgebung mithilfe von DPS implementiert wird.
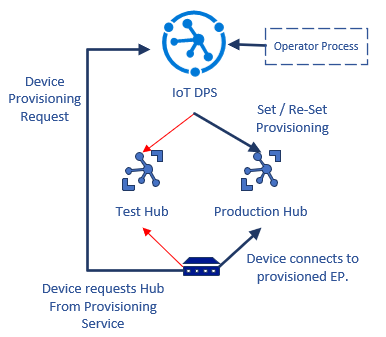
- Der Lösungsentwickler verknüpft die Test- und Produktions-IoT-Clouds mit dem Bereitstellungsdienst.
- Das Gerät implementiert das DPS-Protokoll, um den IoT-Hub zu finden, wenn es nicht mehr bereitgestellt wird. Das Gerät wird anfänglich in der Testumgebung bereitgestellt.
- Da das Gerät bei der Testumgebung registriert ist, wird dort eine Verbindung hergestellt, und ein Test erfolgt.
- Der Entwickler stellt das Gerät neu in der Produktionsumgebung bereit und entfernt es aus dem Testhub. Der Testhub lehnt das Gerät beim nächsten Herstellen einer Verbindung ab.
- Das Gerät stellt eine Verbindung her und verhandelt den Bereitstellungsflow neu. DPS leitet das Gerät nun an die Produktionsumgebung weiter, und das Gerät stellt dort eine Verbindung her und authentifiziert sich.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautoren:
- Matthew Cosner | Principal Software Engineering Manager
- Ansley Yeo | Principal Program Manager
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.