Künstliche Intelligenz bietet die Möglichkeit, den Einzelhandel, wie wir ihn heute kennen, zu transformieren. Wir können durchaus annehmen, dass Einzelhändler eine von künstlicher Intelligenz (KI) unterstützte Architektur für das Kundeneinkaufserlebnis entwickeln werden. Es werden Erwartungen geäußert, dass eine mit KI verbesserte Plattform aufgrund von Hyperpersonalisierung einen Umsatzanstieg ermöglicht. Der digitale Handel erhöht weiterhin die Erwartungen, Einstellungen und das Verhalten der Kunden. Anforderungen wie Echtzeit-Engagement, relevante Empfehlungen und Hyperpersonalisierung sorgen für mehr Geschwindigkeit und Benutzerfreundlichkeit mit nur einem Mausklick. Wir ermöglichen Intelligenz in Anwendungen durch natürliche Sprache, Sehen usw. Diese Intelligenz ermöglicht Verbesserungen im Einzelhandel, die den Wert steigern und gleichzeitig die Kaufgewohnheiten der Kunden durchbrechen.
Dieses Dokument konzentriert sich auf das KI-Konzept der visuellen Suche und nennt einige wichtige Aspekte für die Implementierung. Es enthält ein Workflowbeispiel und ordnet die jeweiligen Phasen den relevanten Azure-Technologien zu. Das Konzept basiert darauf, dass ein Kunde in der Lage ist, ein mit seinem mobilen Gerät aufgenommenes oder im Internet befindliches Bild zu nutzen. Je nach Absicht des Erlebnisses führt der Kunde eine Suche nach relevanten und ähnlichen Artikeln durch. So verbessert die visuelle Suche die Geschwindigkeit von der Texteingabe bis zu einem Bild mit mehreren Metadatenpunkten, um alle verfügbaren anwendbaren Elemente schnell anzuzeigen.
Visuelle Suchmaschinen
Visuelle Suchmaschinen rufen Informationen mithilfe von Bildern als Eingabe und oft – jedoch nicht ausschließlich – auch als Ausgabe ab.
Suchmaschinen werden im Einzelhandel immer häufiger eingesetzt, und das aus sehr guten Gründen:
- Laut einem 2017 von eMarketer veröffentlichten Bericht suchen ca. 75 % der Internetbenutzer nach Bildern oder Videos eines Produkts, bevor Sie einen Kauf tätigen.
- Aus einem Bericht, der 2015 von Slyce (einem Unternehmen für die visuelle Suche) veröffentlicht wurde, geht hervor, dass 74 Prozent der Verbraucher auch die Textsuche als ineffizient erachten.
Einer Studie von Markets & Markets zufolge wird daher der Markt für Bilderkennung bis 2019 mehr als 25 Milliarden US-Dollar wert sein.
Die Technologie hat sich bereits bei führenden E-Commerce-Marken etabliert, die auch erheblich zu ihrer Entwicklung beigetragen haben. Die wohl bekanntesten Early Adopters sind:
- eBay mit den Tools „Bildersuche“ und „Find It On eBay“ (Finde es bei eBay) in der App (derzeit nur in einer mobilen Umgebung verfügbar).
- Pinterest mit dem visuellen Suchtool Pinterest Lens.
- Microsoft mit der visuellen Bing-Suche.
Übernehmen und Anpassen
Glücklicherweise benötigen Sie keine große Rechenleistung, um von der visuellen Suche profitieren zu können. Jedes Unternehmen mit einem Bilderkatalog kann die Vorteile der KI-Kompetenz von Microsoft nutzen, die in die Azure-Dienste integriert ist.
Die API für die visuelle Bing-Suche bietet eine Möglichkeit zum Extrahieren von Kontextinformationen aus Bildern, um z. B. Möbel, Mode, verschiedene Arten von Produkten usw. zu identifizieren.
Sie gibt auch visuell ähnliche Bilder aus ihrem eigenen Katalog, Produkte mit entsprechenden Einkaufsquellen und verwandte Suchvorgänge zurück. Obwohl das interessant ist, wird es nur von begrenztem Nutzen sein, wenn Ihr Unternehmen nicht zu diesen Quellen gehört.
Bing bietet auch Folgendes:
- Tags, mit denen Sie im Bild gefundene Objekte oder Konzepte analysieren können.
- Begrenzungsrahmen für Bereiche, die im Bild von Interesse sind (z. B. für Kleidung oder Möbelstücke).
Anhand dieser Informationen können Sie den Suchbereich (und die Zeit) im Produktkatalog des Unternehmens erheblich reduzieren und ihn auf Objekte wie jene im relevanten Bereich und in der relevanten Kategorie beschränken.
Implementieren Ihrer eigenen Lösung
Bei der Implementierung der visuellen Suche sind einige wichtige Komponenten zu berücksichtigen:
- Erfassen und Filtern von Bildern
- Techniken zum Speichern und Abrufen
- Featurebereitstellung, Codierung oder „Hashing“
- Ähnlichkeitsmessungen oder Abstände und Rangfolge
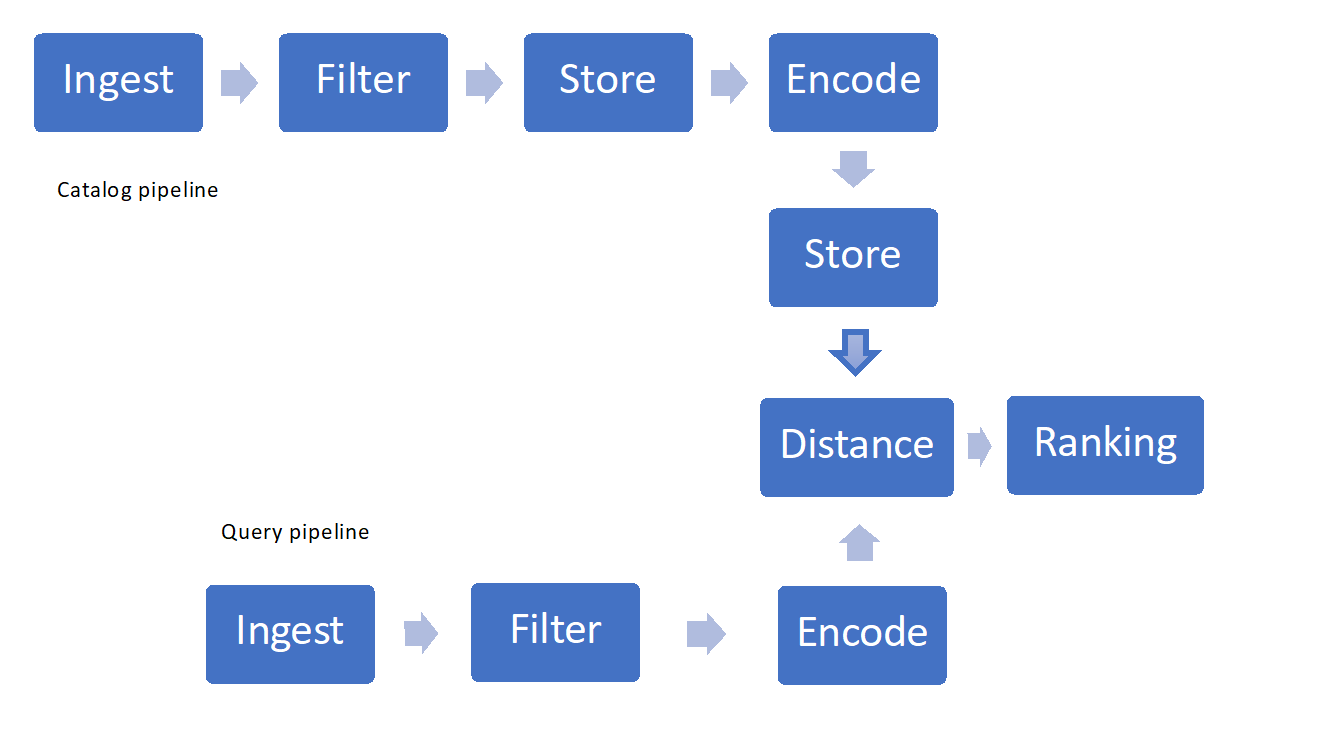
Abbildung 1: Beispiel für die Pipeline der visuellen Suche
Sourcing der Bilder
Wenn Sie keinen Bildkatalog besitzen, müssen Sie möglicherweise die Algorithmen auf öffentlich verfügbare Datasets wie Fashion-MNIST, DeepFashion usw. trainieren. Sie enthalten mehrere Kategorien von Produkten und werden häufig für Vergleichstests von Bildkategorisierungen und Suchalgorithmen verwendet.

Abbildung 2: Ein Beispiel aus dem DeepFashion-Dataset
Filtern der Bilder
Die meisten Benchmark-Datasets (etwa die zuvor erwähnten) wurden bereits vorab verarbeitet.
Wenn Sie eine eigene Benchmark erstellen, sollten zumindest alle Bilder dieselbe Größe aufweisen, die größtenteils durch die Eingabe vorgegeben ist, für die Ihr Modell trainiert wurde.
In vielen Fällen empfiehlt es sich auch, die Helligkeit der Bilder zu normalisieren. Abhängig von der Detailstufe der Suche kann auch Farbe eine redundante Information sein, sodass Sie durch die Reduzierung auf Schwarzweiß die Verarbeitungszeiten optimieren können.
Und nicht zuletzt sollte das Bild-Dataset in Bezug auf die verschiedenen Klassen, die es darstellt, ausgeglichen sein.
Bilddatenbank
Die Datenschicht ist eine besonders wichtige Komponente Ihrer Architektur. Sie enthält Folgendes:
- Bilder
- Alle Metadaten zu den Bildern (Größe, Tags, Produkt-SKUs, Beschreibung)
- Vom Machine Learning-Modell generierte Daten (z. B. einen numerischen Vektor mit 4.096 Elementen pro Bild)
Wenn Sie Bilder aus verschiedenen Quellen abrufen oder mehrere Machine Learning-Modelle verwenden, um eine optimale Leistung zu erzielen, ändert sich die Struktur der Daten. Daher ist es wichtig, eine Technologie oder eine Kombination auszuwählen, die teilweise strukturierte Daten und Daten ohne festes Schema verarbeiten kann.
Möglicherweise soll auch eine Mindestanzahl nützlicher Datenpunkte (wie ein Bildbezeichner oder -schlüssel, eine Produkt-SKU, eine Beschreibung oder ein Tagfeld) erforderlich sein.
Azure Cosmos DB bietet die erforderliche Flexibilität und eine Vielzahl von Zugriffsmechanismen für Anwendungen, die darauf basieren (und dies unterstützt die Katalogsuche). Allerdings ist darauf zu achten, das bestmögliche Preis-Leistungs-Verhältnis zu erzielen. Azure Cosmos DB ermöglicht das Speichern von Dokumentanlagen, es gilt jedoch ein Gesamtlimit pro Konto, und möglicherweise ist das eine kostspielige Angelegenheit. Es ist üblich, die eigentlichen Bilddateien in Blobs zu speichern und einen Link zu diesen in der Datenbank einzufügen. Im Fall von Azure Cosmos DB impliziert dies das Erstellen eines Dokuments, das die dem Bild zugeordneten Katalogeigenschaften (etwa SKU, Tag usw.) und eine Anlage enthält, die wiederum die URL der Bilddatei (z. B. für Azure Blob Storage, OneDrive usw.) enthält.
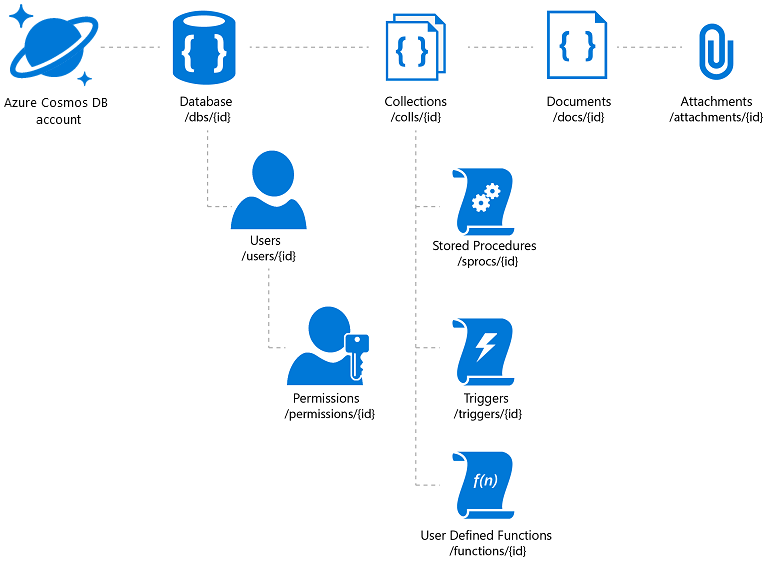
Abbildung 3: hierarchisches Azure Cosmos DB-Ressourcenmodell
Wenn Sie die globale Verteilung von Azure Cosmos DB nutzen möchten, beachten Sie, dass dabei die Dokumente und Anlagen, jedoch nicht die verknüpften Dateien repliziert werden. Sie können dafür die Verwendung eines Inhaltsverteilungsnetzwerks (Content Distribution Network, CDN) in Betracht ziehen.
Bei anderen geeigneten Technologien handelt es sich um eine Kombination aus Azure SQL-Datenbank (wenn ein festes Schema zulässig ist) und Blobs oder auch aus Azure-Tabellen und Blobs für kostengünstiges und schnelles Speichern und Abrufen.
Merkmalsextraktion und -codierung
Beim Codierungsvorgang werden aus Bildern in der Datenbank markante Merkmale extrahiert und jeweils einem „Merkmalsvektor“ mit geringer Dichte (Vektor mit vielen Nullen) zugeordnet, der Tausende von Komponenten enthalten kann. Dieser Vektor ist eine numerische Darstellung der Merkmale (etwa Kanten und Formen), die das Bild charakterisieren, ähnlich einem Code.
Merkmalsextraktionstechniken verwenden in der Regel Transfer Learning-Mechanismen. Dies geschieht, wenn Sie ein vortrainiertes neuronales Netzwerk auswählen, jedes Bild darin ausführen und den erzeugten Merkmalsvektor in Ihrer Bilddatenbank speichern. Auf diese Weise „transferieren“ Sie das Lernen von der Person, die das Netzwerk trainiert hat. Microsoft hat mehrere vortrainierte Netzwerke entwickelt und veröffentlicht, die häufig für Bilderkennungsaufgaben verwendet werden, beispielsweise ResNet50.
Abhängig vom neuronalen Netzwerk ist der Merkmalsvektor mehr oder weniger lang und mit geringer Dichte, daher variieren die Arbeitsspeicher- und Speicheranforderungen.
Außerdem werden Sie vielleicht feststellen, dass verschiedene Netzwerke auf verschiedene Kategorien anwendbar sind, sodass eine Implementierung der visuellen Suche tatsächlich zu Merkmalsvektoren unterschiedlicher Größe führen kann.
Vortrainierte neuronale Netzwerke sind relativ benutzerfreundlich, aber möglicherweise nicht so effizient wie ein benutzerdefiniertes Modell, das mit Ihrem Bildkatalog trainiert ist. Diese vortrainierten Netzwerke sind in der Regel für die Klassifizierung von Benchmark-Datasets und nicht für das Durchsuchen Ihrer spezifischen Bildersammlung konzipiert.
Möglicherweise möchten Sie diese ändern und erneut trainieren, sodass sie eine Kategorievorhersage und einen Vektor mit hoher Dichte (d. h. einen kleineren, nicht einen mit geringer Dichte) erzeugen. Dies ist sehr nützlich, um den Suchbereich einzuschränken und die Arbeitsspeicher- und Speicheranforderungen zu reduzieren. Es können binäre Vektoren verwendet werden, die oft als „semantischer Hash“ bezeichnet werden. Dieser Begriff wird von Dokumentencodierungs- und Abruftechniken abgeleitet. Die binäre Darstellung vereinfacht weitere Berechnungen.
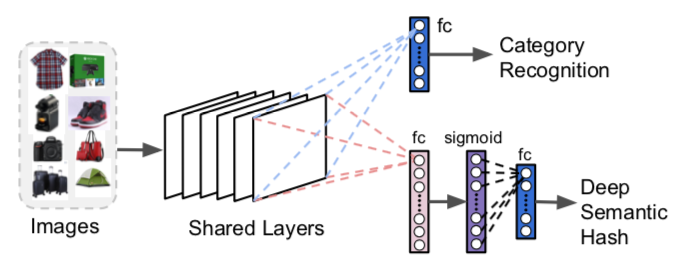
Abbildung 4: Änderungen an ResNet für die visuelle Suche – F. Yang et al. (2017)
Ob Sie nun vortrainierte Modelle auswählen oder Ihr eigenes entwickeln, Sie müssen in jedem Fall entscheiden, wo die Featurisierung und/oder das Trainieren des Modells selbst ausgeführt werden soll.
Azure bietet mehrere Optionen: VMs, Azure Batch, Batch KI und Databricks-Cluster. In allen Fällen wird das beste Preis-Leistungs-Verhältnis jedoch durch die Verwendung von GPUs erzielt.
Vor Kurzem hat Microsoft auch die Verfügbarkeit von FPGAs für schnelle Berechnungen zu einem Bruchteil der GPU-Kosten angekündigt (Projekt Brainwave). Zum Zeitpunkt der Verfassung ist dieses Angebot jedoch auf bestimmte Netzwerkarchitekturen beschränkt, daher müssen Sie die jeweilige Leistung gründlich evaluieren.
Ähnlichkeitsmaß oder Abstand
Wenn die Bilder im Merkmalsvektorraum dargestellt werden, wird das Ermitteln von Ähnlichkeiten zu einer Frage der Definition eines Abstandsmaßes zwischen Punkten in diesem Raum. Sobald ein Abstand definiert ist, können Sie Cluster mit ähnlichen Bildern berechnen und/oder Ähnlichkeitsmatrizen definieren. Abhängig von der ausgewählten Abstandsmetrik können die Ergebnisse variieren. Die gängigste euklidische Abstandsmessung über Realzahlenvektoren ist beispielsweise leicht zu verstehen: Sie erfasst die Größe des Abstands. Sie ist jedoch in Bezug auf die Berechnung ineffizient.
Der Kosinusabstand wird häufig verwendet, um die Ausrichtung des Vektors und nicht dessen Größe zu erfassen.
Alternativen wie der Hamming-Abstand über binäre Darstellungen erfordern eine gewisse Genauigkeit für Effizienz und Geschwindigkeit.
Die Kombination aus Vektorgröße und Abstandsmessung bestimmt, wie rechen- und arbeitsspeicherintensiv die Suche sein wird.
Suche und Rangfolge
Nachdem die Ähnlichkeit definiert wurde, müssen wir eine effiziente Methode entwickeln, um die nächstgelegenen N Elemente zu demjenigen zu finden, das als Eingabe übergeben wird, und dann eine Liste von Bezeichnern zurückgeben. Dies wird auch als „Bildrangfolge“ bezeichnet. Bei einer großen Datenmenge ist die Zeit zur Berechnung jedes Abstands inakzeptabel. Daher verwenden wir Algorithmen für ungefähre nächste Nachbarn (Nearest-Neighbor-Algorithmus). Für diese sind mehrere Open-Source-Bibliotheken vorhanden, sodass Sie sie nicht von Grund auf neu codieren müssen.
Schließlich bestimmten die Arbeitsspeicher- und Berechnungsanforderungen die Auswahl der Bereitstellungstechnologie für das trainierte Modell – sowie die Hochverfügbarkeit. In der Regel wird der Suchbereich partitioniert, und mehrere Instanzen des Rangfolgenalgorithmus werden parallel ausgeführt. Azure Kubernetes-Cluster stellen eine Option dar, die Skalierbarkeit und Verfügbarkeit ermöglicht. In diesem Fall empfiehlt es sich, das Rangfolgemodell über mehrere Container (für jeweils eine Partition des Suchbereichs) und mehrere Knoten (für Hochverfügbarkeit) bereitzustellen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautoren:
- Giovanni Marchetti | Manager, Azure Solution Architects
- Mariya Zorotovich | Head of Customer Experience, HLS Emerging Technology
Andere Mitwirkende:
- Scott Seely | Software Architect
Nächste Schritte
Die Implementierung der visuellen Suche muss nicht komplex sein. Sie können Bing verwenden oder Ihre eigene Lösung mit Azure-Diensten erstellen und gleichzeitig die KI-Forschung und -Tools von Microsoft nutzen.
Entwickeln
- Informationen zum Erstellen eines benutzerdefinierten Diensts finden Sie unter Übersicht über die API für die visuelle Bing-Suche.
- Informationen zum Erstellen Ihrer ersten Abfrage finden Sie in den Schnellstartanleitungen: C# | Java | node.js | Python.
- Machen Sie sich mit der Visual Search API Reference (API-Referenz für die visuelle Suche) vertraut.
Hintergrund
- Deep Learning-Bildsegmentierung: In diesem Microsoft-Artikel wird der Prozess des Trennens von Bildern von Hintergründen beschrieben.
- Visuelle Suche bei eBay: Untersuchung der Cornell University
- Visuelle Suche bei Pinterest: Untersuchung der Cornell University
- Semantisches Hashing Untersuchung der University of Toronto