Untersuchen der Integrität von Knoten und Pods
Dieser Artikel ist Teil einer Serie. Beginnen Sie mit der Übersicht.
Wenn bei den Clusterüberprüfungen, die Sie im vorherigen Schritt ausgeführt haben, keine Probleme gefunden wurden, überprüfen Sie die Integrität der AKS-Workerknoten (Azure Kubernetes Service). Führen Sie die sechs Schritte in diesem Artikel aus, um die Integrität von Knoten zu überprüfen, die Ursache für einen fehlerhaften Knoten zu ermitteln und das Problem zu beheben.
Schritt 1: Überprüfen der Integrität von Workerknoten
Verschiedene Faktoren können zu fehlerhaften Knoten in einem AKS-Cluster beitragen. Eine häufige Ursache ist der Zusammenbruch der Kommunikation zwischen der Steuerungsebene und den Knoten. Dieses Kommunikationsproblem wird häufig durch Fehlkonfigurationen in Routing- und Firewallregeln verursacht.
Wenn Sie Ihren AKS-Cluster für benutzerdefiniertes Routing konfigurieren, müssen Sie Ausgangspfade über ein virtuelles Netzwerkgerät (Network Virtual Appliance, NVA) oder über eine Firewall (beispielsweise Azure Firewall) konfigurieren. Zur Behebung eines Problems im Zusammenhang mit einer Fehlkonfiguration empfiehlt es sich, die Firewall so zu konfigurieren, dass die erforderlichen Ports und vollqualifizierten Domänennamen (Fully Qualified Domain Names, FQDNs) gemäß der Anleitung für ausgehenden Datenverkehr aus AKS zugelassen werden.
Ein weiterer Grund für fehlerhafte Knoten können unzureichende Compute-, Arbeitsspeicher- oder Speicherressourcen sein, die zur Auslastung von Kubelet führen. In solchen Fällen lässt sich das Problem durch Hochskalieren der Ressourcen wirksam beheben.
In einem privaten AKS-Cluster können DNS-Auflösungsprobleme (Domain Name System) zu Kommunikationsproblemen zwischen der Steuerungsebene und den Knoten führen. Vergewissern Sie sich, dass der DNS-Name des Kubernetes-API-Servers zur privaten IP-Adresse des API-Servers aufgelöst wird. Ein falsch konfigurierter benutzerdefinierter DNS-Server ist eine häufige Ursache für DNS-Auflösungsfehler. Achten Sie bei Verwendung benutzerdefinierter DNS-Server darauf, sie ordnungsgemäß als DNS-Server in dem virtuellen Netzwerk anzugeben, in dem Knoten bereitgestellt werden. Stellen Sie außerdem sicher, dass der private AKS-API-Server über den benutzerdefinierten DNS-Server aufgelöst werden kann.
Nachdem Sie diese potenziellen Probleme bei der Kommunikation mit der Steuerungsebene und bei der DNS-Auflösung behoben haben, können Sie Probleme mit der Knotenintegrität innerhalb Ihres AKS-Clusters effektiv angehen und beheben.
Sie können die Integrität Ihrer Knoten mithilfe einer der folgenden Methoden auswerten:
Containerintegritätsansicht in Azure Monitor
Führen Sie die folgenden Schritte aus, um die Integrität von Knoten, Benutzerpods und Systempods in Ihrem AKS-Cluster anzuzeigen:
- Navigieren Sie im Azure-Portal zu Azure Monitor.
- Wählen Sie im Navigationsbereich im Abschnitt Erkenntnisse die Option Container aus.
- Wählen Sie Überwachten Cluster aus, um eine Liste der überwachten AKS-Cluster anzuzeigen.
- Wählen Sie einen AKS-Cluster aus der Liste aus, um die Integrität der Knoten, Benutzerpods und Systempods anzuzeigen.

AKS-Knotenansicht
Führen Sie die folgenden Schritte aus, um sicherzustellen, dass sich alle Knoten in Ihrem AKS-Cluster im Zustand „Bereit“ befinden:
- Navigieren Sie im Azure-Portal zu Ihrem AKS-Cluster.
- Wählen Sie im Navigationsbereich im Abschnitt Einstellungen die Option Knotenpools aus.
- Wählen Sie Knoten aus.
- Vergewissern Sie sich, dass sich alle Knoten im Zustand „Bereit“ befinden.

Clusterinterne Überwachung mit Prometheus und Grafana
Wenn Sie Prometheus und Grafana in Ihrem AKS-Cluster bereitgestellt haben, können Sie das K8-Dashboard mit Clusterdetails verwenden, um Erkenntnisse zu gewinnen. Dieses Dashboard zeigt Prometheus-Clustermetriken an und präsentiert wichtige Informationen wie CPU-Auslastung, Arbeitsspeicherauslastung, Netzwerkaktivität und Dateisystemnutzung. Außerdem werden hier detaillierte Statistiken zu einzelnen Pods, Containern und Diensten vom Typ systemd angezeigt.
Wählen Sie auf dem Dashboard die Option Knotenbedingungen aus, um Metriken zur Integrität und Leistung Ihres Clusters anzuzeigen. Sie können Knoten nachverfolgen, bei denen möglicherweise Probleme vorliegen – beispielsweise mit dem Zeitplan, dem Netzwerk, der Datenträgerauslastung, der Arbeitsspeicherauslastung, der PID-Auslastung (Proportional Integral Derivative) oder dem Speicherplatz. Überwachen Sie diese Metriken, damit Sie potenzielle Probleme, die sich auf die Verfügbarkeit und Leistung Ihres AKS-Clusters auswirken, proaktiv identifizieren und beheben können.

Überwachen des verwalteten Diensts für Prometheus sowie von Azure Managed Grafana
Sie können vordefinierte Dashboards verwenden, um Prometheus-Metriken zu visualisieren und zu analysieren. Dazu müssen Sie Ihren AKS-Cluster so einrichten, dass Prometheus-Metriken im verwalteten Azure Monitor-Dienst für Prometheus gesammelt werden, und Ihren Monitor-Arbeitsbereich mit einem Azure Managed Grafana-Arbeitsbereich verbinden. Diese Dashboards bieten einen umfassenden Einblick in die Leistung und Integrität Ihres Kubernetes-Clusters.
Die Dashboards werden in der angegebenen Azure Managed Grafana-Instanz im Ordner Managed Prometheus bereitgestellt. Es folgen einige Beispiele für Dashboards:
- Kubernetes/Computeressourcen/Cluster
- Kubernetes/Computeressourcen/Namespace (Pods)
- Kubernetes/Computeressourcen/Knoten (Pods)
- Kubernetes/Computeressourcen/Pod
- Kubernetes/Computeressourcen/Namespace (Workloads)
- Kubernetes/Computeressourcen/Workload
- Kubernetes/Kubelet
- Knoten-Exporter/USE-Methode/Knoten
- Knoten-Exporter/Knoten
- Kubernetes/Computeressourcen/Cluster (Windows)
- Kubernetes/Computeressourcen/Namespace (Windows)
- Kubernetes/Computeressourcen/Pod (Windows)
- Kubernetes/USE-Methode/Cluster (Windows)
- Kubernetes/USE-Methode/Knoten (Windows)
Diese integrierten Dashboards werden von der Open-Source-Community gerne zum Überwachen von Kubernetes-Clustern mit Prometheus und Grafana verwendet. Verwenden Sie diese Dashboards, um Metriken wie Ressourceneinsatz, Podintegrität und Netzwerkaktivität anzuzeigen. Sie können auch benutzerdefinierte Dashboards erstellen, die auf Ihre Überwachungsanforderungen zugeschnitten sind. Dashboards ermöglichen eine effektive Überwachung und Analyse von Prometheus-Metriken in Ihrem AKS-Cluster, um die Leistung optimieren, Probleme beheben und einen reibungslosen Betrieb Ihrer Kubernetes-Workloads gewährleisten zu können.
Mit dem Dashboard Kubernetes/Computeressourcen/Knoten (Pods) können Sie Metriken für Ihre Linux-Agent-Knoten anzeigen. Sie können die CPU-Auslastung, das CPU-Kontingent, die Arbeitsspeicherauslastung und das Arbeitsspeicherkontingent für jeden Pod visualisieren.

Wenn Ihr Cluster Windows-Agent-Knoten enthält, können Sie das Dashboard Kubernetes/USE-Methode/Knoten (Windows) verwenden, um die Prometheus-Metriken zu visualisieren, die von diesen Knoten gesammelt werden. Dieses Dashboard bietet einen umfassenden Überblick über den Ressourcenverbrauch und die Leistung für Windows-Knoten innerhalb Ihres Clusters.
Nutzen Sie diese dedizierten Dashboards, um mühelos wichtige Metriken im Zusammenhang mit CPU, Arbeitsspeicher und anderen Ressourcen sowohl für Linux- als auch für Windows-Agent-Knoten überwachen und analysieren zu können. Diese Transparenz ermöglicht es Ihnen, potenzielle Engpässe zu identifizieren, die Ressourcenzuordnung zu optimieren und einen effizienten Betrieb in Ihrem AKS-Cluster sicherzustellen.
Schritt 2: Überprüfen der Konnektivität zwischen Steuerungsebene und Workerknoten
Wenn die Workerknoten fehlerfrei sind, sollten Sie die Konnektivität zwischen der verwalteten AKS-Steuerungsebene und den Cluster-Workerknoten untersuchen. AKS ermöglicht die Kommunikation zwischen dem Kubernetes-API-Server und einzelnen Knoten-Kubelets über eine sichere Tunnelkommunikationsmethode. Diese Komponenten können kommunizieren, auch wenn sie sich in verschiedenen virtuellen Netzwerken befinden. Der Tunnel wird durch mTLS-Verschlüsselung (Mutual Transport Layer Security) geschützt. Der primäre Tunnel, den AKS verwendet, wird Konnectivity genannt. (Früher wurde er als apiserver-network-proxy bezeichnet.) Achten Sie darauf, dass alle Netzwerkregeln und FQDNs den erforderlichen Azure-Netzwerkregeln entsprechen.
Um die Konnektivität zwischen der verwalteten AKS-Steuerungsebene und den Cluster-Workerknoten eines AKS-Clusters zu überprüfen, können Sie das Befehlszeilentool kubectl verwenden.
Führen Sie den folgenden Befehl aus, um sicherzustellen, dass die Konnectivity-Agent-Pods ordnungsgemäß funktionieren:
kubectl get deploy konnectivity-agent -n kube-system
Stellen Sie sicher, dass die Pods bereit sind.
Sollte ein Problem mit der Verbindung zwischen der Steuerungsebene und den Workerknoten bestehen, stellen Sie die Verbindung her, nachdem Sie sichergestellt haben, dass die erforderlichen Regeln für ausgehenden AKS-Datenverkehrsregeln zulässig sind.
Führen Sie den folgenden Befehl aus, um die konnectivity-agent-Pods neu zu starten:
kubectl rollout restart deploy konnectivity-agent -n kube-system
Wenn das Neustarten der Pods das Verbindungsproblem nicht behebt, überprüfen Sie die Protokolle auf Anomalien. Führen Sie den folgenden Befehl aus, um die Protokolle der konnectivity-agent-Pods anzuzeigen:
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
Die Protokolle sollten die folgende Ausgabe liefern:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
Hinweis
Wenn ein AKS-Cluster mit einer API-Server-VNet-Integration sowie entweder mit einer Azure-Containernetzwerkschnittstelle (Container Networking Interface, CNI) oder mit einer Azure-CNI mit dynamischer Pod-IP-Zuweisung eingerichtet ist, müssen keine Konnectivity-Agents bereitgestellt werden. Die integrierten API-Server-Pods können über ein privates Netzwerk eine direkte Kommunikation mit den Cluster-Workerknoten ermöglichen.
Wenn Sie allerdings eine API-Server-VNet-Integration mit Azure-CNI-Überlagerung oder aber Ihre eigene CNI verwenden (Bring Your Own CNI, BYOCNI), wird Konnectivity bereitgestellt, um die Kommunikation zwischen den API-Servern und Pod-IPs zu erleichtern. Die Kommunikation zwischen den API-Servern und den Workerknoten bleibt direkt.
Sie können auch die Containerprotokolle im Protokollierungs- und Überwachungsdienst durchsuchen, um die Protokolle abzurufen. Ein Beispiel, in dem nach Konnektivitätsfehlern vom Typ aks-link gesucht wird, finden Sie unter Abfrageprotokolle aus Container Insights.
Führen Sie die folgende Abfrage aus, um die Protokolle abzurufen:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
Führen Sie die folgende Abfrage aus, um Containerprotokolle nach einem fehlerhaften Pod in einem bestimmten Namespace zu durchsuchen:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
Wenn Sie die Protokolle nicht mithilfe von Abfragen oder über das kubectl-Tool abrufen können, verwenden Sie die SSH-Authentifizierung (Secure Shell). In diesem Beispiel wird nach dem Herstellen einer Verbindung mit dem Knoten über SSH der Pod für tunnelfront gefunden.
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
Schritt 3: Überprüfen der DNS-Auflösung beim Einschränken des ausgehenden Datenverkehrs
Die DNS-Auflösung ist ein wichtiger Aspekt Ihres AKS-Clusters. Wenn die DNS-Auflösung nicht ordnungsgemäß funktioniert, treten möglicherweise Fehler auf der Steuerungsebene oder beim Pullen von Containerimages auf. Führen Sie die folgenden Schritte aus, um sicherzustellen, dass die DNS-Auflösung auf dem Kubernetes-API-Server ordnungsgemäß funktioniert:
Führen Sie den Befehl kubectl exec aus, um eine Befehlsshell im Container zu öffnen, der in dem Pod ausgeführt wird.
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashÜberprüfen Sie, ob das Tool nslookup oder dig im Container installiert ist.
Ist keines der Tools im Pod installiert, führen Sie den folgenden Befehl aus, um einen Hilfs-Pod im gleichen Namespace zu erstellen:
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shSie können die API-Serveradresse über die Übersichtsseite Ihres AKS-Clusters im Azure-Portal abrufen oder den folgenden Befehl ausführen:
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsvFühren Sie den folgenden Befehl aus, um zu versuchen, den AKS-API-Server aufzulösen. Weitere Informationen finden Sie unter Behandeln von DNS-Auflösungsfehlern innerhalb des Pods, aber nicht vom Workerknoten aus.
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioÜberprüfen Sie im Pod den Upstream-DNS-Server, um zu ermitteln, ob die DNS-Auflösung ordnungsgemäß funktioniert. Führen Sie beispielsweise für Azure DNS den folgenden Befehl
nslookupaus.nslookup microsoft.com 168.63.129.16Wenn die vorherigen Schritte keine Einblicke liefern, stellen Sie eine Verbindung mit einem der Workerknoten her, und versuchen Sie, die DNS-Auflösung vom Knoten aus durchzuführen. Mit diesem Schritt können Sie ermitteln, ob das Problem mit AKS oder mit der Netzwerkkonfiguration zusammenhängt.
Wenn die DNS-Auflösung vom Knoten aus erfolgreich ist, vom Pod aus aber nicht, handelt es sich möglicherweise um ein Problem im Zusammenhang mit Kubernetes-DNS. Schritte zum Debuggen der DNS-Auflösung über das Pod finden Sie unter Behandeln von DNS-Auflösungsfehlern innerhalb des Pods, aber nicht vom Workerknoten aus.
Wenn die DNS-Auflösung vom Knoten aus nicht erfolgreich ist, überprüfen Sie das Netzwerksetup, um sicherzustellen, dass die entsprechenden Routingpfade und Ports geöffnet sind, um die DNS-Auflösung zu ermöglichen.
Schritt 4: Überprüfen auf Kubelet-Fehler
Überprüfen Sie den Zustand des Kubelet-Prozesses, der auf den einzelnen Workerknoten ausgeführt wird, und stellen Sie sicher, dass er nicht zu stark ausgelastet ist. Dies kann sich auf die CPU, auf den Arbeitsspeicher oder auf den Speicherplatz beziehen. Der Status einzelner Knoten-Kubelets kann mithilfe einer der folgenden Methoden überprüft werden:
AKS-Kubelet-Arbeitsmappe
Führen Sie die folgenden Schritte aus, um sicherzustellen, dass die Agent-Knoten-Kubelets ordnungsgemäß funktionieren:
Navigieren Sie im Azure-Portal zu Ihrem AKS-Cluster.
Wählen Sie im Abschnitt Überwachung des Navigationsbereichs die Option Arbeitsmappen aus.
Wählen Sie die Arbeitsmappe Kubelet aus.

Wählen Sie Vorgänge aus, und stellen Sie sicher, dass die Vorgänge für alle Workerknoten abgeschlossen sind.
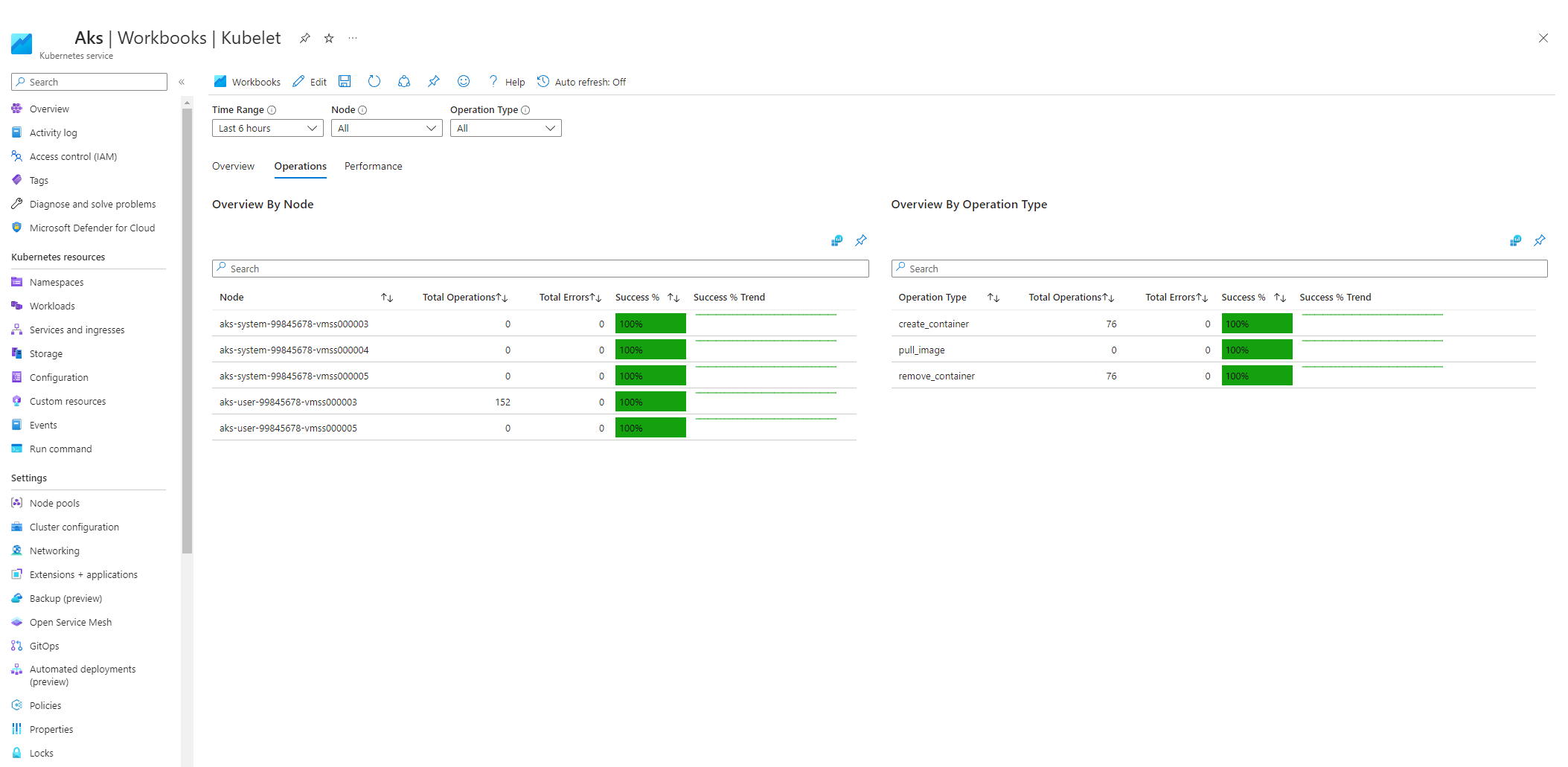


Clusterinterne Überwachung mit Prometheus und Grafana
Wenn Sie Prometheus und Grafana in Ihrem AKS-Cluster bereitgestellt haben, können Sie das Dashboard Kubernetes/Kubelet verwenden, um Erkenntnisse zur Integrität und Leistung einzelner Knoten-Kubelets zu gewinnen.

Überwachen des verwalteten Diensts für Prometheus sowie von Azure Managed Grafana
Sie können das vordefinierte Dashboard Kubernetes/Kubelet verwenden, um die Prometheus-Metriken für die Workerknoten-Kubelets zu visualisieren und zu analysieren. Dazu müssen Sie Ihren AKS-Cluster so einrichten, dass Prometheus-Metriken im verwalteten Azure Monitor-Dienst für Prometheus gesammelt werden, und Ihren Monitor-Arbeitsbereich mit einem Azure Managed Grafana-Arbeitsbereich verbinden.

Die Ressourcenauslastung erhöht sich, wenn ein Kubelet neu gestartet wird, was zu sporadischem, unvorhersehbarem Verhalten führt. Stellen Sie sicher, dass die Fehleranzahl nicht stetig zunimmt. Ein gelegentlicher Fehler ist akzeptabel, aber eine konstante Zunahme deutet auf ein zugrunde liegendes Problem hin, das untersucht und behoben werden muss.
Schritt 5: Verwenden des NPD-Tools (Node Problem Detector, Knotenproblemerkennung) zum Überprüfen der Knotenintegrität
NPD ist ein Kubernetes-Tool, mit dem Sie knotenbezogene Probleme identifizieren und melden können. Es arbeitet als systemd-Dienst auf jedem Knoten innerhalb des Clusters. Es sammelt Metriken und Systeminformationen wie CPU-Auslastung, Datenträgerauslastung und Netzwerkkonnektivitätsstatus. Wenn ein Problem erkannt wird, generiert das NPD-Tool einen Bericht zu den Ereignissen und zum Knotenzustand. In AKS wird das NPD-Tool verwendet, um Knoten in einem in der Azure-Cloud gehosteten Kubernetes-Cluster zu überwachen und zu verwalten. Weitere Informationen finden Sie unter Knotenproblemerkennung (NPD) in Azure Kubernetes Service(AKS)-Knoten.
Schritt 6: Überprüfen von Datenträger-E/A-Vorgängen pro Sekunde (I/O Operations per Second, IOPS) auf Drosselung
Um sicherzustellen, dass IOPS nicht gedrosselt und Dienste und Workloads innerhalb Ihres AKS-Clusters nicht beeinträchtigt werden, können Sie eine der folgenden Methoden verwenden:
AKS-Arbeitsmappe für Knotendatenträger-E/A
Sie können die Arbeitsmappe Knotendatenträger-E/A verwenden, um die Datenträger-E/A-bezogenen Metriken der Workerknoten in Ihrem AKS-Cluster zu überwachen. Führen Sie die folgenden Schritte aus, um auf die Arbeitsmappe zuzugreifen:
Navigieren Sie im Azure-Portal zu Ihrem AKS-Cluster.
Wählen Sie im Abschnitt Überwachung des Navigationsbereichs die Option Arbeitsmappen aus.
Wählen Sie die Arbeitsmappe Knotendatenträger-E/A aus.
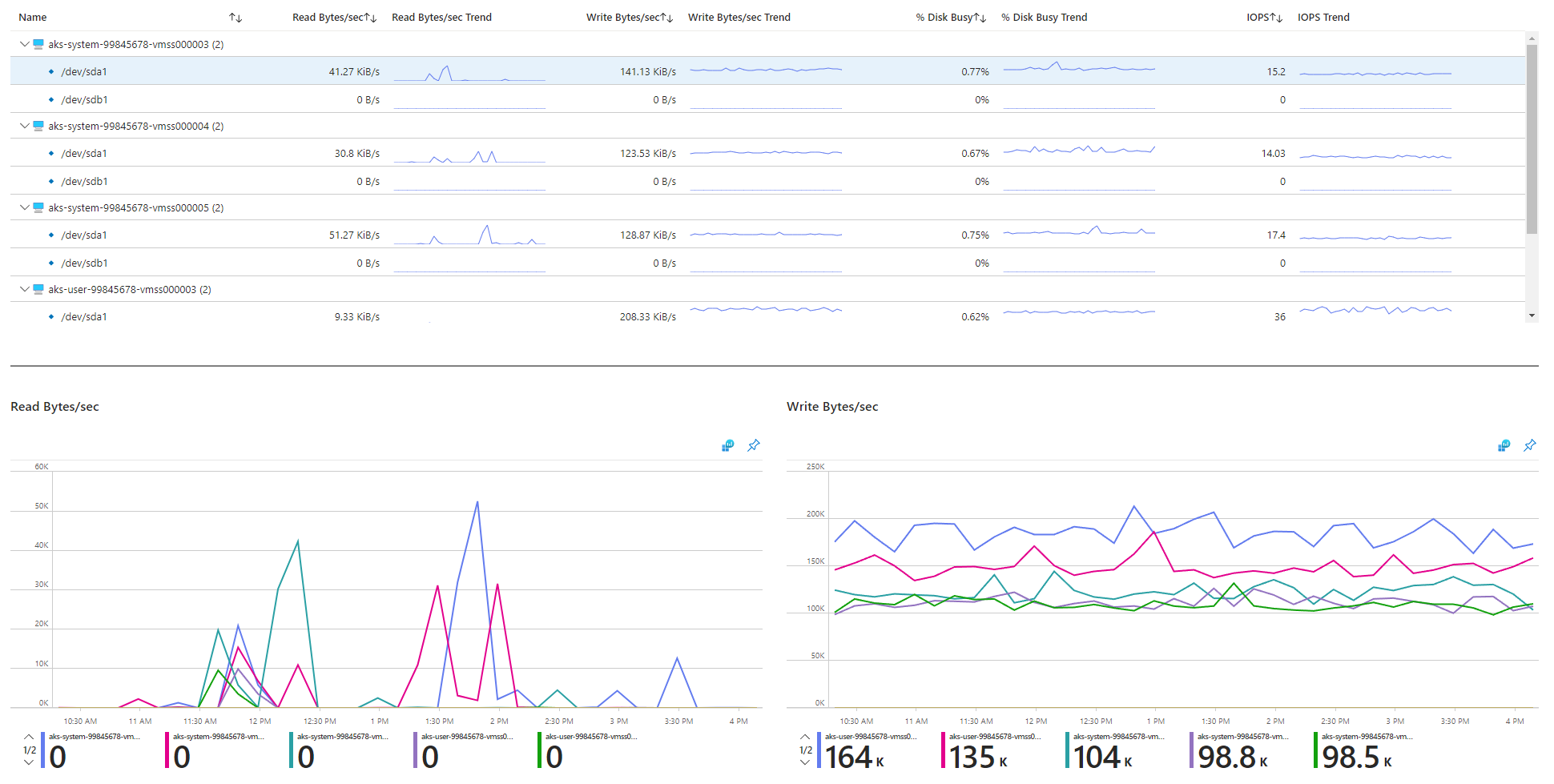
Überprüfen Sie die E/A-bezogenen Metriken.


Clusterinterne Überwachung mit Prometheus und Grafana
Wenn Sie Prometheus und Grafana in Ihrem AKS-Cluster bereitgestellt haben, können Sie das Dashboard USE-Methode/Knoten verwenden, um Erkenntnisse zu Datenträger-E/A für die Workerknoten des Clusters zu gewinnen.

Überwachen des verwalteten Diensts für Prometheus sowie von Azure Managed Grafana
Sie können das vordefinierte Dashboard Knoten-Exporter/Knoten verwenden, um Datenträger-E/A-bezogene Metriken der Workerknoten zu visualisieren und zu analysieren. Dazu müssen Sie Ihren AKS-Cluster so einrichten, dass Prometheus-Metriken im verwalteten Azure Monitor-Dienst für Prometheus gesammelt werden, und Ihren Monitor-Arbeitsbereich mit einem Azure Managed Grafana-Arbeitsbereich verbinden.

IOPS und Azure-Datenträger
Für physische Speichergeräte gelten prinzipienbedingte Einschränkungen hinsichtlich der Bandbreite und der maximalen Anzahl von Dateivorgängen, die sie verarbeiten können. Azure-Datenträger werden verwendet, um das Betriebssystem zu speichern, das auf AKS-Knoten ausgeführt wird. Die Datenträger unterliegen den gleichen physischen Speichereinschränkungen wie das Betriebssystem.
Beachten Sie das Konzept des Durchsatzes. Sie können die durchschnittliche E/A-Größe mit den IOPS multiplizieren, um den Durchsatz in Megabytes pro Sekunde (MB/s) zu ermitteln. Größere E/A-Vorgänge führen aufgrund des festen Durchsatzes des Datenträgers zu niedrigeren IOPS.
Wenn eine Workload die maximalen IOPS-Dienstgrenzwerte übersteigt, die den Azure-Datenträgern zugewiesen sind, reagiert der Cluster möglicherweise nicht mehr und wird in einen E/A-Wartezustand versetzt. In Linux-basierten Systemen werden viele Komponenten als Dateien behandelt – beispielsweise Netzwerksockets, CNI, Docker und andere Dienste, die auf Netzwerk-E/A angewiesen sind. Wenn der Datenträger also nicht gelesen werden kann, weitet sich der Fehler auf alle diese Dateien aus.
Eine IOPS-Drosselung kann durch verschiedene Ereignisse und Szenarien ausgelöst werden. Hierzu zählen unter anderem folgende:
Eine erhebliche Anzahl von Containern, die auf Knoten ausgeführt werden, da für Docker-I/O der gleiche Betriebssystemdatenträger verwendet wird
Verwendung von benutzerdefinierten Tools oder Drittanbietertools für Sicherheit, Überwachung und Protokollierung, die möglicherweise zusätzliche E/A-Vorgänge auf dem Betriebssystemdatenträger generieren
Knotenfailoverereignisse und regelmäßige Aufträge, die die Arbeitsauslastung intensivieren oder die Anzahl von Pods skalieren. Diese höhere Auslastung erhöht die Wahrscheinlichkeit von Drosselungen, was dazu führen kann, dass alle Knoten bis zum Abschluss der E/A-Vorgänge in einen nicht bereiten Zustand versetzt werden.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautoren:
- Paolo Salvatori | Principal Customer Engineer
- Francis Simy Nazareth | Senior Technical Specialist
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
Zugehörige Ressourcen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für