CQRS steht für Command and Query Responsibility Segregation, ein Muster, das Lese- und Aktualisierungsvorgänge für einen Datenspeicher trennt. Das Implementieren von CQRS in Ihrer Anwendung kann die Leistung, Skalierbarkeit und Sicherheit maximieren. Die durch die Migration zu CQRS gewonnene Flexibilität ermöglicht es einem System, sich im Laufe der Zeit besser weiterzuentwickeln, und verhindert, dass Aktualisierungsbefehle auf Domänenebene Mergekonflikte verursachen.
Kontext und Problem
In herkömmlichen Architekturen wird zum Abfragen und Aktualisieren einer Datenbank das gleiche Datenmodell verwendet. Dies ist eine einfache Vorgehensweise, die für grundlegende CRUD-Vorgänge gut geeignet ist. Bei komplexeren Anwendungen kann dieser Ansatz aber zu Problemen führen. Beispielsweise werden von der Anwendung auf Leseseite unter Umständen unterschiedliche Abfragen durchgeführt und Datenübertragungsobjekte (Data Transfer Objects, DTOs) mit uneinheitlichen Formen zurückgegeben. Die Objektzuordnung kann kompliziert werden. Auf der Schreibseite werden für das Modell ggf. eine komplexe Überprüfung und Geschäftslogik implementiert. Hieraus kann sich ein Modell mit zu hoher Komplexität ergeben, das überdimensioniert ist.
Lese- und Schreibworkloads sind häufig asymmetrisch und verfügen über sehr unterschiedliche Leistungs- und Skalierungsanforderungen.

Dies führt häufig zu einem Konflikt zwischen den Lese- und Schreibdarstellungen der Daten, beispielsweise aufgrund zusätzlicher Spalten oder Eigenschaften, die ordnungsgemäß aktualisiert werden müssen, auch wenn sie im Rahmen eines Vorgangs nicht erforderlich sind.
Datenkonflikte können auftreten, wenn Vorgänge parallel für denselben Datensatz ausgeführt werden.
Die konventionelle Vorgehensweise kann sich negativ auf die Leistung auswirken, was auf die Auslastung im Datenspeicher und der Datenzugriffsschicht sowie die Komplexität der zum Abrufen von Informationen erforderlichen Abfragen zurückzuführen ist.
Die Verwaltung von Sicherheitsfeatures und Berechtigungen kann kompliziert werden, weil jede Entität sowohl Lese- als auch Schreibvorgängen unterworfen ist. Hierdurch werden Daten möglicherweise im falschen Kontext verfügbar gemacht.
Lösung
CQRS unterteilt Lese- und Schreibvorgänge in verschiedene Modelle und verwendet dafür Befehle zum Aktualisieren von Daten sowie Abfragen zum Lesen von Daten.
- Die Befehle sollten nicht datenzentriert, sondern aufgabenbasiert sein. („Book hotel room“, nicht „set ReservationStatus to Reserved“). Dies erfordert möglicherweise einige entsprechende Änderungen am Benutzerinteraktionsstil. Der andere Teil davon besteht darin, die Geschäftslogik, die diese Befehle verarbeitet, häufiger zu ändern. Eine Technik, die dies unterstützt, besteht darin, einige Gültigkeitsprüfungsregeln auf dem Client auszuführen, bevor sie den Befehl senden, möglicherweise Schaltflächen deaktivieren und erläutern, warum auf der Benutzeroberfläche („keine Räume verbleiben“). Auf diese Weise kann die Ursache für serverseitige Befehlsfehler auf Racebedingungen beschränkt werden (zwei Benutzer versuchen, den letzten Raum zu buchen), und sogar solche können manchmal mit einigen weiteren Daten und Logik behoben werden (einen Gast in eine Warteliste setzen).
- Befehle können für die asynchrone Verarbeitung in einer Warteschlange platziert werden, anstatt sie synchron zu verarbeiten.
- Mit Abfragen wird die Datenbank niemals geändert. Eine Abfrage gibt ein DTO zurück, in dem kein Domänenwissen gekapselt ist.
Die Modelle können dann isoliert werden, wie im folgenden Diagramm dargestellt. Dies ist aber keine absolute Anforderung.
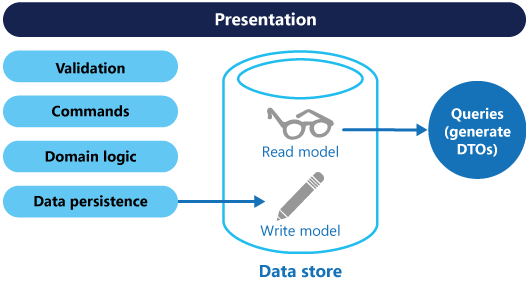
Ein separates Abfrage- und Aktualisierungsmodell vereinfacht den Entwurf und die Implementierung. Ein Nachteil ist jedoch, dass sich CQRS-Code nicht automatisch mithilfe von Gerüstbaumechanismen wie O/RM-Tools aus einem Datenbankschema generieren lässt. (Sie können jedoch Anpassung auf der Grundlage von generiertem Code erstellen.)
Eine stärkere Isolation erzielen Sie, indem Sie die Lesedaten physisch von den Schreibdaten trennen. In diesem Fall kann die Lesedatenbank ihr eigenes Datenschema verwenden, das für Abfragen optimiert ist. Beispielsweise kann eine materialisierte Sicht der Daten gespeichert werden, um komplexe Verknüpfungen oder O/RM-Zuordnungen zu vermeiden. Es kann sogar ein anderer Typ von Datenspeicher verwendet werden. Die Schreibdatenbank kann beispielsweise relational sein, während es sich bei der Lesedatenbank um eine Dokumentdatenbank handelt.
Wenn separate Lese- und Schreibdatenbanken verwendet werden, müssen sie synchron gehalten werden. Dies wird normalerweise erreicht, indem das Schreibmodell jeweils ein Ereignis veröffentlicht, wenn es die Datenbank aktualisiert. Weitere Informationen zum Verwenden von Ereignissen finden Sie unter Ereignisgesteuerter Architekturstil. Da Nachrichtenbroker und Datenbanken in der Regel nicht in eine einzelne verteilte Transaktion eingetragen werden können, kann es schwierig sein, beim Aktualisieren der Datenbank und beim Veröffentlichen von Ereignissen Konsistenz zu gewährleisten. Weitere Informationen finden Sie unter Idempotente Nachrichtenverarbeitung.
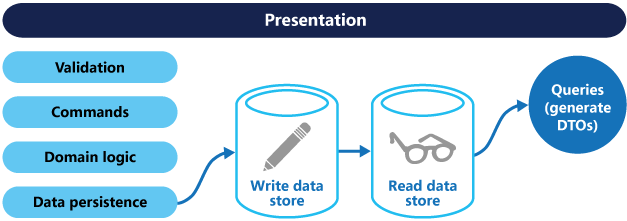
Beim Speicher für Lesevorgänge kann es sich um ein schreibgeschütztes Replikat des Speichers für Schreibvorgänge handeln. Anderenfalls können Speicher für Lese- und Schreibvorgänge grundlegend verschiedene Strukturen aufweisen. Die Verwendung mehrerer schreibgeschützter Replikate kann die Abfrageleistung erhöhen – insbesondere in verteilten Szenarien, in denen sich schreibgeschützte Replikate in der Nähe der Anwendungsinstanzen befinden.
Durch die Trennung von Speichern für Lese- und Schreibvorgänge kann können beide Speicher entsprechend der Auslastung skaliert werden. Beispielsweise ist in Speichern für Lesevorgänge in der Regel eine weitaus höhere Auslastung anzutreffen als bei Speichern für Schreibvorgänge.
Für einige Implementierungen von CQRS wird das Muster „Event Sourcing“ verwendet. Bei diesem Muster wird der Anwendungsstatus als Ereignissequenz gespeichert. Jedes Ereignis umfasst eine Reihe von Änderungen der Daten. Der aktuelle Zustand wird hergestellt, indem die Ereignisse erneut durchgeführt werden. In einem CQRS-Kontext besteht ein Vorteil der Ereignisherkunftsermittlung darin, dass dieselben Ereignisse verwendet werden können, um andere Komponenten zu benachrichtigen, vor allem das Lesemodell. Im Lesemodell werden die Ereignisse genutzt, um eine Momentaufnahme des aktuellen Zustands zu erstellen, da dies für Abfragen effizienter ist. Mit der Ereignisherkunftsermittlung erhöht sich aber auch die Komplexität des Designs.
Zu den Vorteilen von CQRS gehören folgende:
- Unabhängige Skalierung. CQRS ermöglicht das unabhängige Skalieren der Lese- und Schreibworkloads und kann zu einer Verringerung von Sperrkonflikten führen.
- Optimierte Datenschemas: Auf der Leseseite kann ein Schema verwendet werden, das für Abfragen optimiert ist, während auf der Schreibseite ein Schema verwendet wird, das für Updates optimiert ist.
- Sicherheit: Es ist einfacher sicherzustellen, dass nur die richtigen Domänenentitäten Schreibvorgänge für die Daten durchführen.
- Trennung von Zuständigkeiten: Das Trennen der Lese- und Schreibseite kann zu Modellen führen, die besser gewartet werden können und flexibler sind. Der größte Teil der komplexen Geschäftslogik betrifft das Schreibmodell. Das Lesemodell kann relativ einfach gestaltet sein.
- Einfachere Abfragen: Indem eine materialisierte Sicht in der Lesedatenbank gespeichert wird, kann die Anwendung beim Durchführen von Abfragen komplexe Verknüpfungen vermeiden.
Probleme und Überlegungen bei der Implementierung
Bei der Implementierung dieses Musters gibt es u.a. folgende Herausforderungen:
Komplexität. Die Grundidee von CQRS ist einfach. Es kann sich aber auch ein komplexeres Anwendungsdesign ergeben, z.B. bei Verwendung des Musters für die Ereignisherkunftsermittlung.
Messaging: Für CQRS wird zwar kein Messaging benötigt, aber es wird trotzdem häufig genutzt, um Befehle zu verarbeiten und Aktualisierungsereignisse zu veröffentlichen. In diesem Fall muss die Anwendung Nachrichtenfehler oder doppelte Nachrichten verarbeiten können. Sehen Sie sich die Anleitung zu den Prioritätswarteschlangen an, um zu erfahren, wie Sie mit Befehlen mit unterschiedlichen Prioritäten umgehen.
Letztliche Konsistenz: Wenn Sie die Lese- und Schreibdatenbanken trennen, kann es sein, dass die Lesedaten veraltet sind. Der Speicher mit dem Lesemodell muss aktualisiert werden, damit Änderungen am Speicher mit dem Schreibmodell übernommen werden. Außerdem kann es schwierig sein, basierend auf veralteten Lesedaten festzustellen, wann ein Benutzer eine Anforderung gestellt hat.
Wann das Muster „CQRS“ verwendet werden sollte:
Ziehen Sie CQRS für die folgenden Szenarios in Erwägung:
Kollaborative Domänen, bei denen viele Benutzer parallel auf dieselben Daten zugreifen. Mithilfe von CQRS können Sie Befehle mit ausreichender Granularität definieren, um Zusammenführungskonflikte auf Domänenebene zu minimieren, und auftretende Konflikte können per Befehl zusammengeführt werden.
Bei taskbasierten Benutzeroberflächen, bei denen Benutzer in mehreren Schritten oder mit komplexen Domänenmodellen durch einen komplizierten Prozess geführt werden. Das Schreibmodell verfügt über einen vollständigen Befehlsverarbeitungsstapel mit Geschäftslogik, Eingabeüberprüfung und Geschäftsvalidierung. Das Schreibmodell behandelt möglicherweise einen Satz zugeordneter Objekte als einzelne Einheit für Datenänderungen (ein „Aggregat“ in der DDD-Terminologie) und stellt sicher, dass sich diese Objekte immer in einem konsistenten Zustand befinden. Das Lesemodell weist weder eine Geschäftslogik noch einen Validierungsstapel auf und gibt nur ein DTO zur Verwendung in einem Anzeigemodell zurück. Das Lesemodell ist letztlich konsistent mit dem Schreibmodell.
Szenarios, in denen die Leistung von Datenlesevorgängen separat von der Leistung von Datenschreibvorgängen optimiert werden muss – insbesondere dann, wenn die Anzahl der Lesevorgänge wesentlich größer ist als die Anzahl der Schreibvorgänge ist. In diesem Szenario können Sie das Lesemodell horizontal hochskalieren, das Schreibmodell aber nur auf einigen wenigen Instanzen ausführen. Die Verwendung einer kleinen Anzahl von Schreibmodellinstanzen kann auch das Auftreten von Zusammenführungskonflikten minimieren.
In Szenarien, in denen sich ein Entwicklerteam auf das komplexe Domänenmodell als Teil des Schreibmodells konzentrieren kann, während sich ein anderes Team auf das Lesemodell und die Benutzeroberflächen konzentrieren kann.
In Szenarien, in denen das System voraussichtlich im Laufe der Zeit weiterentwickelt wird und mehrere Versionen des Modells enthalten kann oder in denen sich Geschäftsregeln regelmäßig ändern.
Bei der Integration in andere Systeme, insbesondere in Kombination mit Ereignisquellen, bei denen der vorübergehende Ausfall eines Subsystems nicht die Verfügbarkeit der anderen Systeme beeinträchtigen soll.
Verwenden Sie dieses Muster in folgenden Fällen nicht:
Die Domäne oder die Geschäftsregeln sind einfach.
Eine einfache Benutzeroberfläche im CRUD-Stil und Datenzugriffsvorgänge reichen aus.
Es wird empfohlen, CQRS auf bestimmte Bereiche Ihres Systems anzuwenden, wo es den größten Nutzen bietet.
Workloadentwurf
Ein Architekt sollte evaluieren, wie das CQRS-Muster im Design seines Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Säulen des Azure Well-Architected Framework behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Die Leistungseffizienz hilft Ihrer Workload, Anforderungen effizient durch Optimierungen in Skalierung, Daten und Code zu erfüllen. | Die Trennung von Lese- und Schreibvorgängen bei hohen Lese-Schreib-Workloads ermöglicht gezielte Leistungs- und Skalierungsoptimierungen für den spezifischen Zweck jedes Vorgangs. - PE:05 Skalierung und Partitionierung - PE:08 Datenleistung |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Muster „Ereignisherkunftsermittlung und CQRS“
Das Muster „CQRS“ wird häufig zusammen mit dem Muster „Ereignisherkunftsermittlung“ verwendet. CQRS-basierte Systeme verwenden getrennte Lese- und Schreibdatenmodelle, die auf ihre jeweiligen Tasks zugeschnitten sind und sich häufig in räumlich getrennten Speichern befinden. Bei Verwendung mit dem Muster Ereignisherkunftsermittlung ist der Ereignisspeicher das Schreibmodell und stellt die offizielle Informationsquelle dar. Das Lesemodell eines CQRS-basierten Systems bietet materialisierte Sichten der Daten, üblicherweise in Form von hochgradig denormalisierten Sichten. Diese Sichten sind auf die Schnittstellen und die Anzeigeanforderungen der Anwendung zugeschnitten, wodurch sowohl die Anzeige- als auch die Abfrageleistung maximiert werden können.
Durch die Verwendung des Ereignisdatenstroms als Speicher für Schreibvorgänge anstelle der eigentlichen Daten zu einem bestimmten Zeitpunkt werden Aktualisierungskonflikte in einem einzigen Aggregat vermieden und die Leistung sowie Skalierbarkeit maximiert. Mit den Ereignissen können materialisierte Sichten der Daten asynchron generiert werden, mit denen Speicher für Lesevorgänge aufgefüllt werden.
Da der Ereignisspeicher die offizielle Informationsquelle darstellt, ist es möglich, die materialisierten Sichten zu löschen und alle vergangenen Ereignisse erneut wiederzugeben, um eine neue Darstellung des aktuellen Zustands zu erstellen, wenn das System weiterentwickelt wird oder das Lesemodell geändert werden muss. Bei den materialisierten Sichten handelt es sich praktisch um einen zuverlässigen schreibgeschützten Datencache.
Bei der Verwendung von CQRS in Kombination mit dem Muster „Ereignisherkunftsermittlung“ sollten Sie Folgendes beachten:
Wie bei jedem System, bei dem die Speicher für Lese- und Schreibvorgänge getrennt sind, sind die Systeme, die auf diesem Muster basieren, nur letztlich konsistent. Zwischen der Generierung des Ereignisses und der Aktualisierung des Datenspeichers wird eine gewisse Verzögerung auftreten.
Das Muster erhöht die Komplexität, da Codes erstellt werden müssen, um Ereignisse zu initiieren und zu verarbeiten und die entsprechenden Ansichten oder Objekte, die für das Abfrage- oder Lesemodell erforderlich sind, zusammenzustellen oder zu aktualisieren. Die Komplexität des Musters „CQRS“ in Verbindung mit dem Muster für die Ereignisherkunftsermittlung kann eine erfolgreiche Implementierung erschweren und erfordert eine andere Herangehensweise beim Entwurf von Systemen. Die Ereignisherkunftsermittlung kann jedoch die Modellierung der Domäne vereinfachen. Zudem vereinfacht es das erneute Generieren von Ansichten oder Erstellen neuer Ansichten, da die Änderungsabsicht in den Daten erhalten bleibt.
Die Generierung materialisierter Sichten für die Verwendung im Lesemodell oder in Projektionen der Daten durch Wiedergabe und Verarbeitung der Ereignisse für bestimmte Entitäten oder Sammlungen von Entitäten kann eine enorme Verarbeitungszeit und einen immensen Ressourcenverbrauch zur Folge haben. Dies gilt insbesondere dann, wenn Werte über lange Zeiträume zu summieren oder zu analysieren sind, da eventuell alle zugehörigen Ereignisse untersucht werden müssen. Dies lässt sich durch die Implementierung von Momentaufnahmen der Daten in geplanten Intervallen lösen, wie etwa der Gesamtzahl aufgetretener Aktionen oder des aktuellen Zustands einer Entität.
Beispiel für ein CQRS-Muster
Der folgende Code zeigt einige Auszüge aus einem Beispiel einer CQRS-Implementierung, in der unterschiedliche Definitionen für das Lese- und das Schreibmodell verwendet werden. Die Modellschnittstellen legen keine Features der zugrundeliegenden Datenspeicher fest und können unabhängig voneinander weiterentwickelt und angepasst werden, da diese Schnittstellen getrennt sind.
Der folgende Code zeigt die Definition des Lesemodells.
// Query interface
namespace ReadModel
{
public interface ProductsDao
{
ProductDisplay FindById(int productId);
ICollection<ProductDisplay> FindByName(string name);
ICollection<ProductInventory> FindOutOfStockProducts();
ICollection<ProductDisplay> FindRelatedProducts(int productId);
}
public class ProductDisplay
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal UnitPrice { get; set; }
public bool IsOutOfStock { get; set; }
public double UserRating { get; set; }
}
public class ProductInventory
{
public int Id { get; set; }
public string Name { get; set; }
public int CurrentStock { get; set; }
}
}
Das System ermöglicht den Benutzern, Produkte zu bewerten. Hierfür wird im Anwendungscode der Befehl RateProduct verwendet, wie im folgenden Code zu sehen ist.
public interface ICommand
{
Guid Id { get; }
}
public class RateProduct : ICommand
{
public RateProduct()
{
this.Id = Guid.NewGuid();
}
public Guid Id { get; set; }
public int ProductId { get; set; }
public int Rating { get; set; }
public int UserId {get; set; }
}
Das System verwendet die Klasse ProductsCommandHandler, um die von der Anwendung gesendeten Befehle zu verarbeiten. Clients senden Befehle üblicherweise über ein Messagingsystem wie eine Warteschlange an die Domäne. Der Befehlshandler akzeptiert diese Befehle und ruft Methoden der Domänenschnittstelle auf. Die Granularität der einzelnen Befehle ist darauf ausgelegt, die Wahrscheinlichkeit von in Konflikt stehenden Anforderungen zu verringern. Der folgende Code zeigt eine Gliederung der Klasse ProductsCommandHandler.
public class ProductsCommandHandler :
ICommandHandler<AddNewProduct>,
ICommandHandler<RateProduct>,
ICommandHandler<AddToInventory>,
ICommandHandler<ConfirmItemShipped>,
ICommandHandler<UpdateStockFromInventoryRecount>
{
private readonly IRepository<Product> repository;
public ProductsCommandHandler (IRepository<Product> repository)
{
this.repository = repository;
}
void Handle (AddNewProduct command)
{
...
}
void Handle (RateProduct command)
{
var product = repository.Find(command.ProductId);
if (product != null)
{
product.RateProduct(command.UserId, command.Rating);
repository.Save(product);
}
}
void Handle (AddToInventory command)
{
...
}
void Handle (ConfirmItemsShipped command)
{
...
}
void Handle (UpdateStockFromInventoryRecount command)
{
...
}
}
Nächste Schritte
Die folgenden Muster und Anweisungen könnten für die Implementierung dieses Musters relevant sein:
Data Consistency Primer (Grundlagen der Datenkonsistenz). In diesem Artikel werden die Probleme, die typischerweise aufgrund von letztlicher Konsistenz zwischen den Speichern für Lese- und Schreibvorgänge bei der Verwendung des Musters „CQRS“ auftreten, sowie Möglichkeiten zur Behandlung dieser Probleme erklärt.
Horizontale, vertikale und funktionale Datenpartitionierung. Beschreibt bewährte Methoden für das Aufteilen von Daten in Partitionen, die separat verwaltet und aufgerufen werden können, um die Skalierbarkeit zu verbessern, Konflikte zu reduzieren und die Leistung zu optimieren.
Muster und Vorgehensweisen zu CQRS: Unter Reference 2: Introducing the Command Query Responsibility Segregation Pattern (Referenz 2: Einführung in das Muster „Command and Query Responsibility Segregation“) wird insbesondere das Muster beschrieben und außerdem erläutert, wann die Nutzung sinnvoll ist. Unter Epilogue: Lessons Learned (Epilog: Erkenntnisse) werden einige Probleme beschrieben, die bei Verwendung dieses Musters auftreten können.
Blogbeiträge von Martin Fowler:
Zugehörige Ressourcen
Muster für Ereignisherkunftsermittlung. In diesem Artikel wird ausführlich beschrieben, wie das Muster „CQRS“ mithilfe der Ereignisherkunftsermittlung eingesetzt werden kann, um Tasks in komplexen Domänen zu vereinfachen und gleichzeitig die Leistung, Skalierbarkeit und Reaktionsfähigkeit zu verbessern. Außerdem erfahren Sie, wie Sie die Konsistenz von Transaktionsdaten sicherstellen und gleichzeitig vollständige Audit-Trails und Überwachungsverläufe erstellen können, die kompensierende Maßnahmen ermöglichen.
Muster „Materialisierte Sichten“: Das Lesemodell einer CQRS-Implementierung kann materialisierte Sichten der Daten des Schreibmodells enthalten. Das Modell kann alternativ auch zur Generierung materialisierter Sichten verwendet werden.
Präsentation zu besseren CQRS durch asynchrone Benutzerinteraktionsmuster