In diesem Artikel wird beschrieben, wie ein Entwicklungsteam Metriken verwendet, um Engpässe zu ermitteln und die Leistung eines verteilten Systems zu verbessern. Der Artikel basiert auf den tatsächlichen Auslastungstests, die wir für eine Beispielanwendung durchgeführt haben. Die Anwendung stammt aus der Azure Kubernetes Service-Baseline (AKS) für Microservices.
Dieser Artikel ist Teil einer Serie. Lesen Sie hier den ersten Teil.
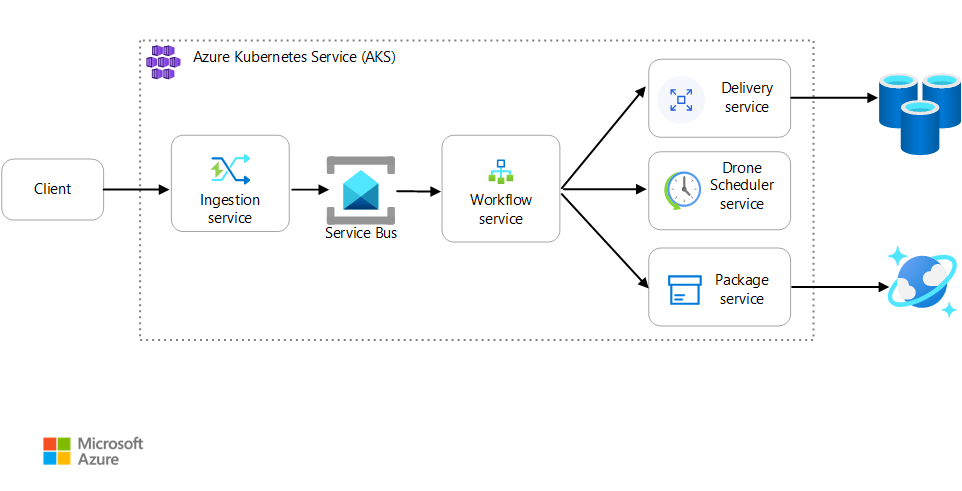
Szenario: Eine Clientanwendung initiiert eine Geschäftstransaktion, die mehrere Schritte umfasst.
Dieses Szenario umfasst eine Drohnenlieferungsanwendung, die in AKS ausgeführt wird. Kunden verwenden eine Web-App, um Lieferungen per Drohne zu planen. Für jede Transaktion sind mehrere Schritte erforderlich, die von separaten Microservices auf dem Back-End ausgeführt werden:
- Der Dienst Delivery verwaltet die Lieferungen.
- Der Dienst Drone Scheduler plant Drohnen für die Abholung ein.
- Der Dienst Package verwaltet Pakete.
Es gibt zwei weitere Dienste: Ein Dienst Ingestion, der Clientanforderungen empfängt und zur Verarbeitung in eine Warteschlange einfügt, sowie einen Dienst Workflow, der die Schritte im Workflow koordiniert.
Weitere Informationen zu diesem Szenario finden Sie unter Entwerfen einer Microservices-Architektur.
Test 1: Grundwert
Für den ersten Auslastungstest hat das Team einen AKS-Cluster mit sechs Knoten erstellt und drei Replikate der einzelnen Microservices bereitgestellt. Der Auslastungstest war ein Schrittauslastungstest, beginnend mit zwei simulierten Benutzern und bis zu 40 simulierten Benutzern ansteigend.
| Einstellung | Wert |
|---|---|
| Clusterknoten | 6 |
| Pods | 3 pro Dienst |
Das folgende Diagramm zeigt die Ergebnisse des Auslastungstests wie in Visual Studio gezeigt. Die violette Linie stellt die Benutzerauslastung und die orangefarbene Linie die Gesamtzahl der Anforderungen dar.
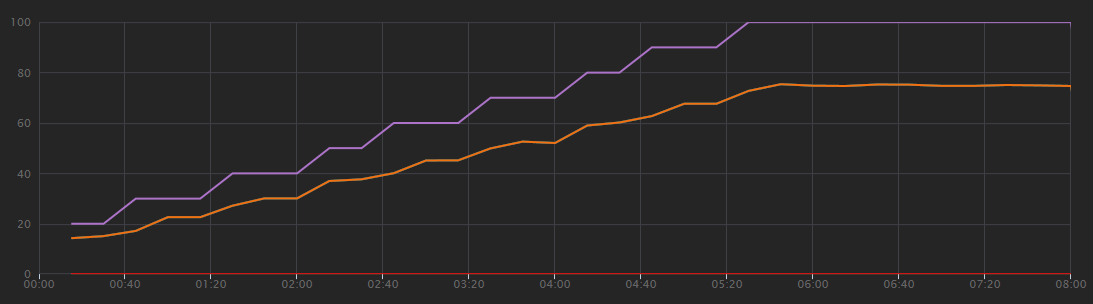
In diesem Szenario ist gleich zu erkennen, dass Clientanforderungen pro Sekunde keine nützliche Leistungsmetrik ist. Das liegt daran, dass die Anwendung Anforderungen asynchron verarbeitet, sodass der Client sofort eine Antwort erhält. Der Antwortcode lautet immer HTTP 202 (akzeptiert), was bedeutet, dass die Anforderung akzeptiert wurde, die Verarbeitung jedoch nicht abgeschlossen ist.
Wir möchten eigentlich wissen, ob das Back-End mit der Anforderungsrate Schritt hält. Die Service Bus-Warteschlange kann Spitzenwerte absorbieren, aber wenn das Back-End keine dauerhafte Last verarbeiten kann, fällt die Verarbeitung immer mehr zurück.
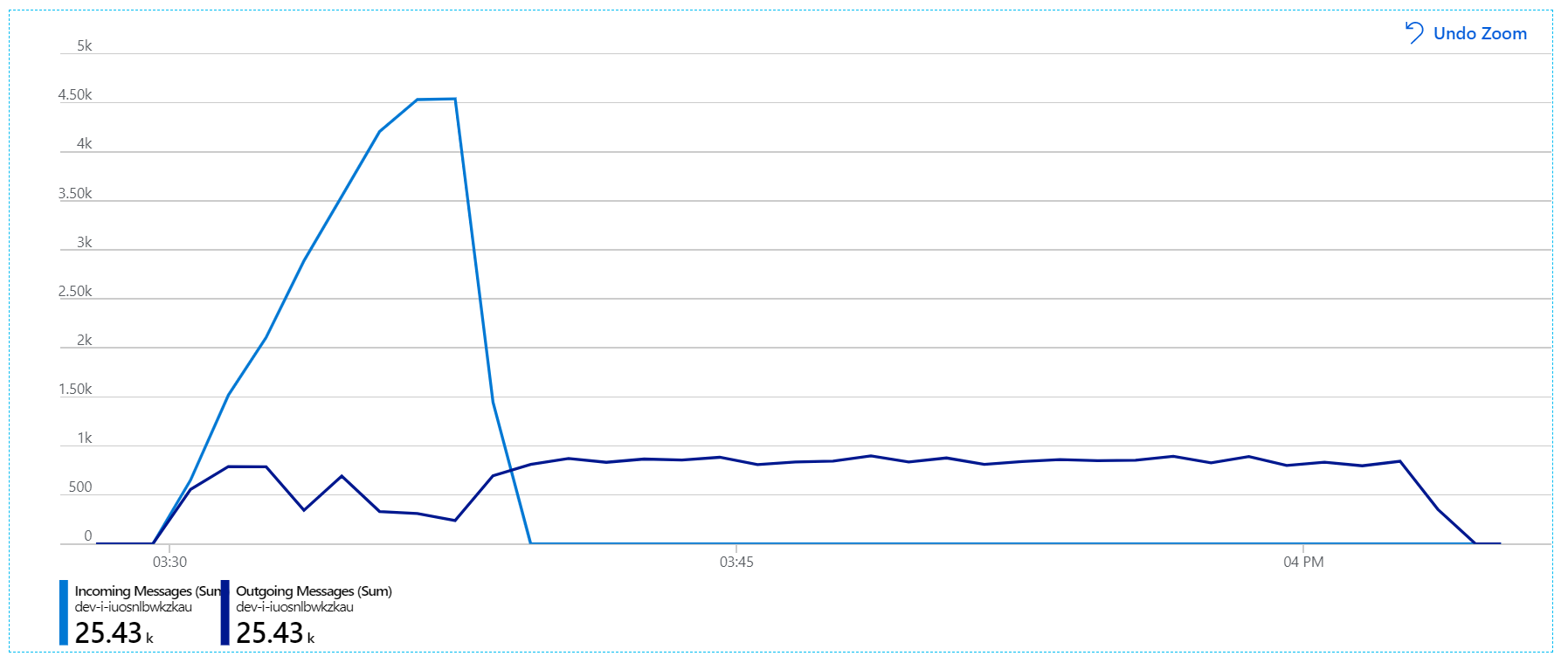
Hier ist ein informativeres Diagramm. Die Zahl der in der Service Bus-Warteschlange eingehenden und ausgehenden Nachrichten wird dargestellt. Eingehende Nachrichten werden hellblau und ausgehende Nachrichten dunkelblau angezeigt:
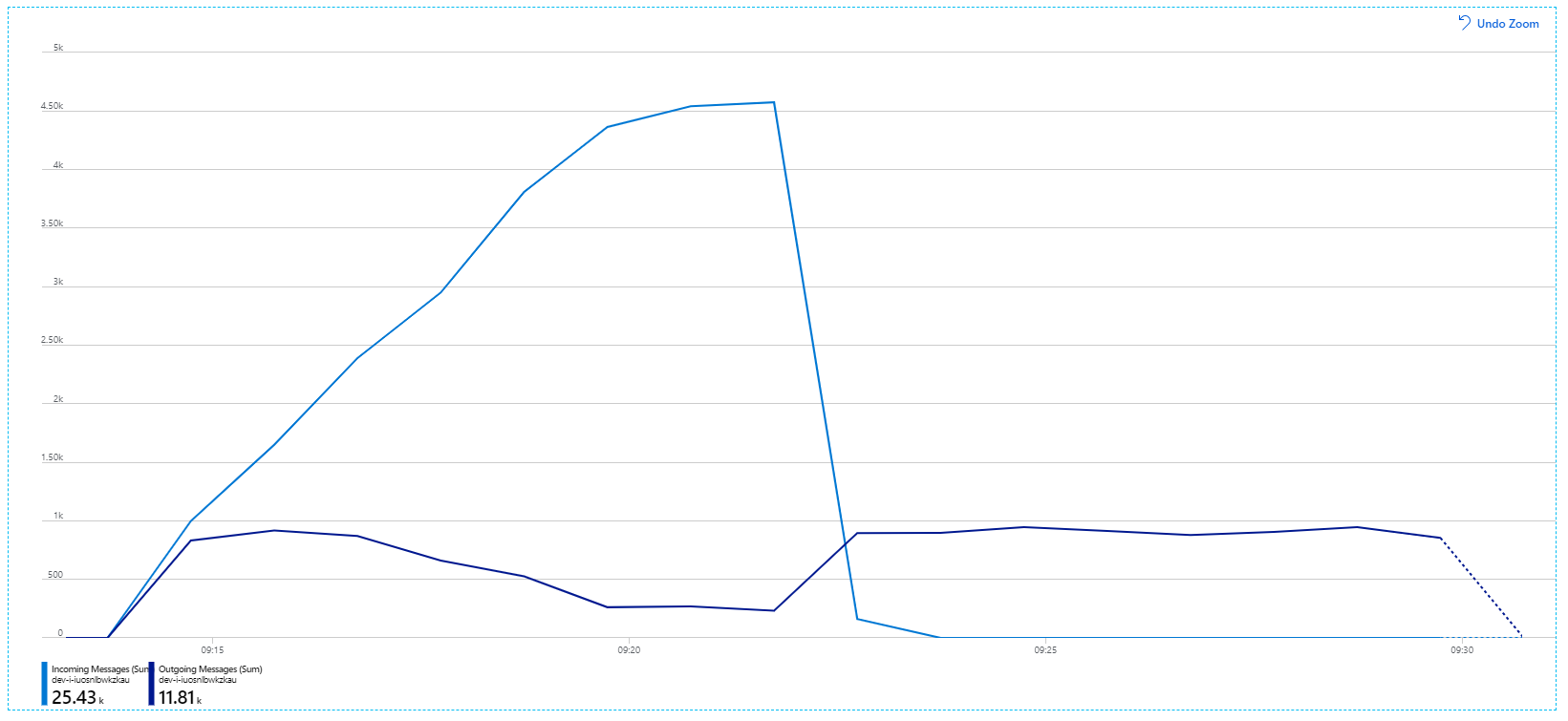
Dieses Diagramm zeigt, dass die Rate eingehender Nachrichten zunimmt, eine Spitze erreicht und dann am Ende des Auslastungstests auf null (0) zurückfällt. Die Anzahl der ausgehenden Nachrichten erreicht jedoch früh im Test eine Spitze und fällt dann ab. Dies bedeutet, dass der Workflow-Dienst, der die Anforderungen verarbeitet, nicht Schritt hält. Auch nach dem Ende des Auslastungstests (etwa 9:22 im Diagramm) werden noch Nachrichten verarbeitet, da der Workflow-Dienst die Warteschlange weiterhin leert.
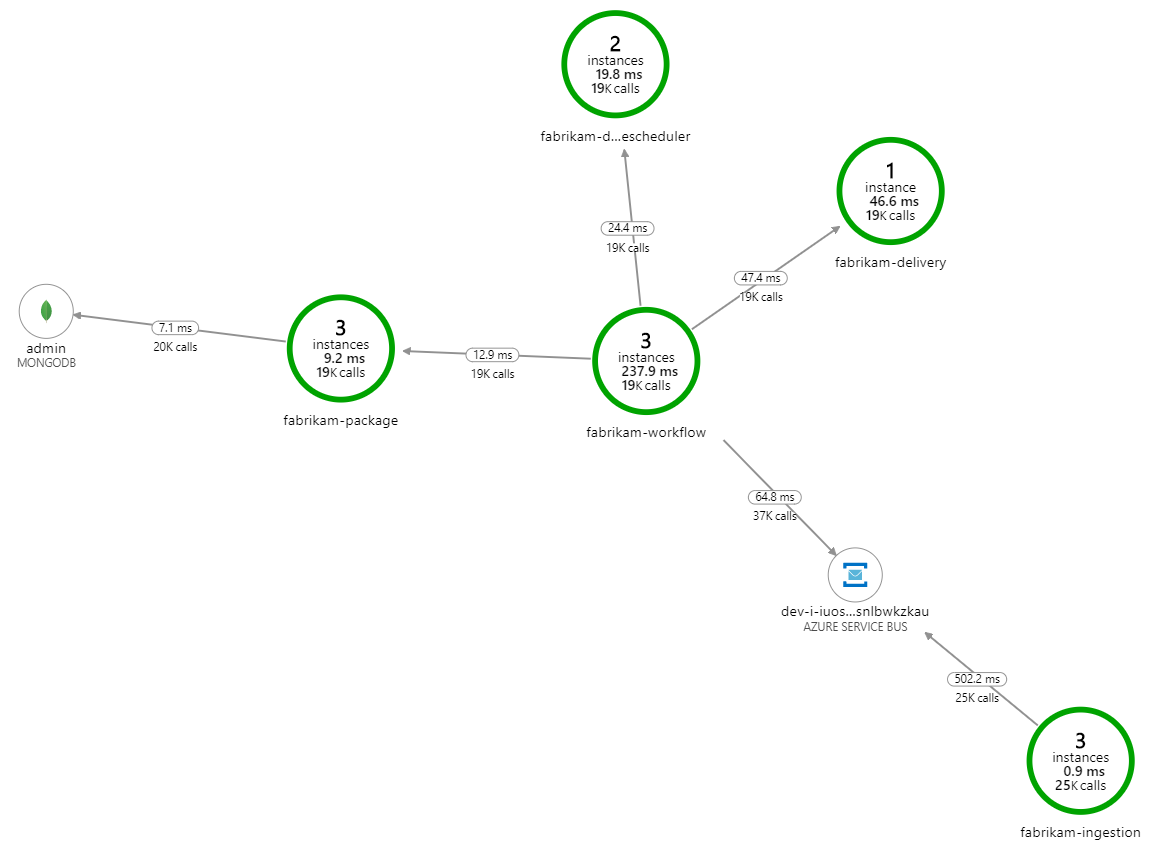
Was verlangsamt die Verarbeitung? Der erste Punkt, nach dem gesucht wird, sind Fehler oder Ausnahmen, die auf ein systematisches Problem hindeuten könnten. Die Anwendungsübersicht in Azure Monitor zeigt das Diagramm der Aufrufe zwischen Komponenten an und ist eine schnelle Möglichkeit, Probleme zu erkennen und dann durchzuklicken, um weitere Details zu erfahren.
Die Anwendungsübersicht zeigt klar, dass der Workflow-Dienst Fehlermeldungen vom Delivery-Dienst erhält:
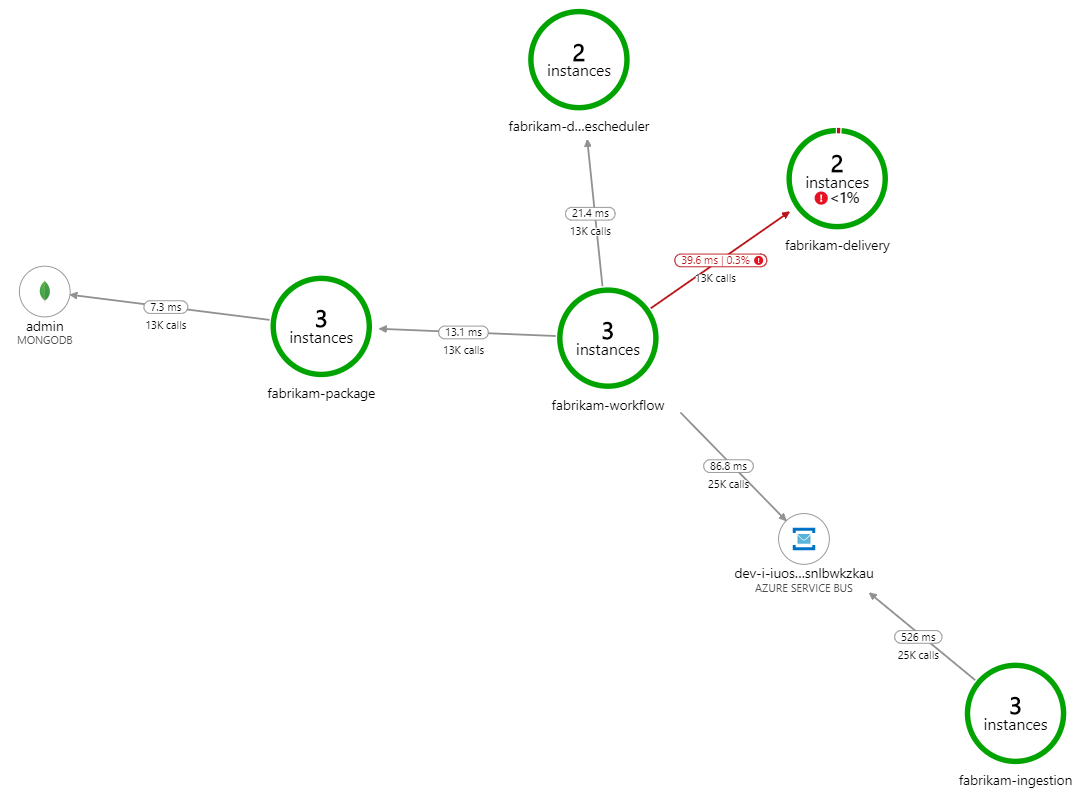
Wenn Sie weitere Details anzeigen möchten, können Sie einen Knoten im Diagramm auswählen und in die Ansicht einer End-to-End-Transaktion klicken. In diesem Fall wird angezeigt, dass der Delivery-Dienst HTTP 500-Fehlermeldungen zurückgibt. Die Fehlermeldungen weisen darauf hin, dass eine Ausnahme aufgrund von Arbeitsspeicherlimits in Azure-Cache für Redis ausgelöst wird.
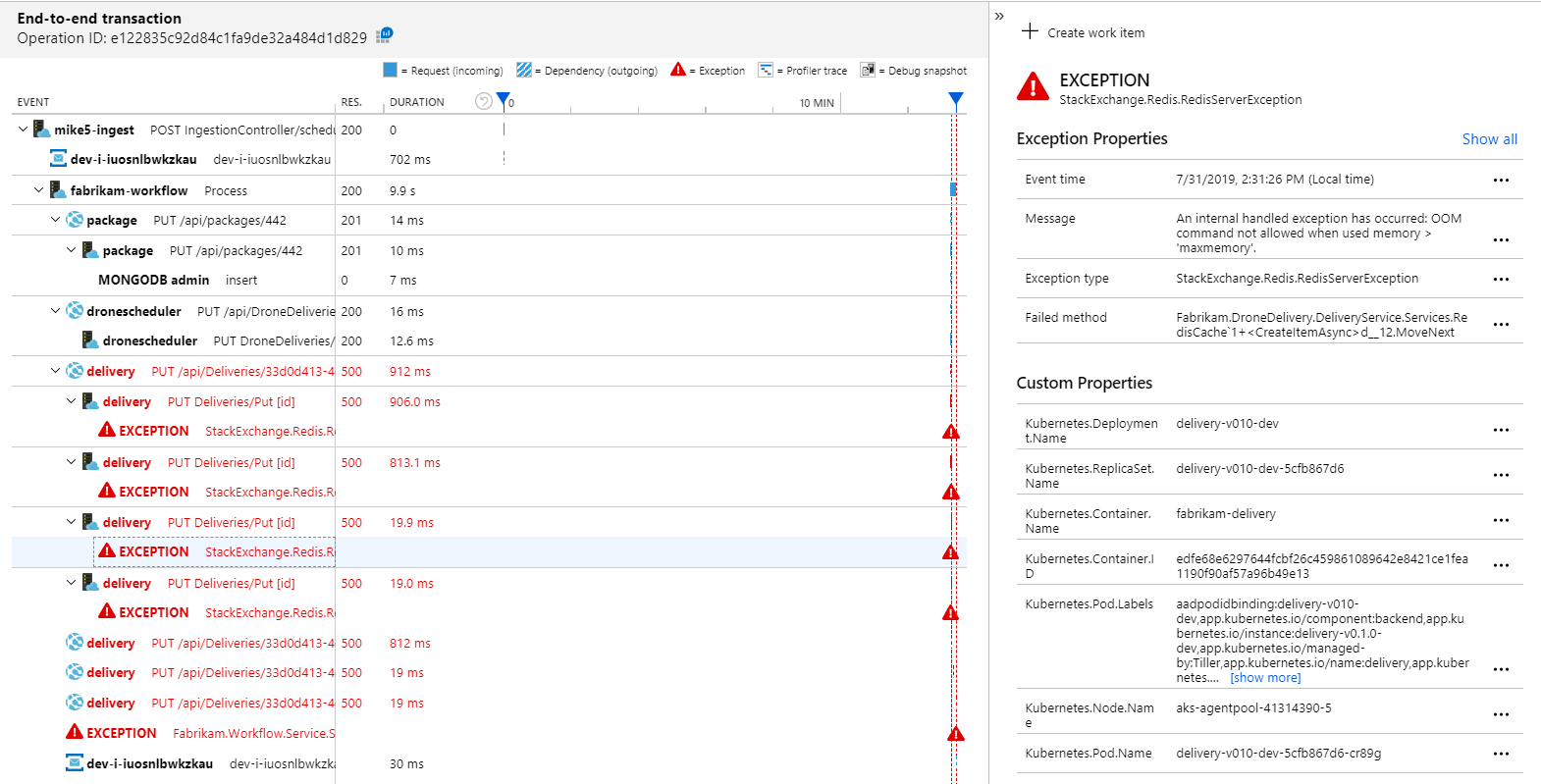
Sie bemerken möglicherweise, dass diese Aufrufe an Redis nicht in der Anwendungsübersicht angezeigt werden. Dies liegt daran, dass die .NET-Bibliothek für Application Insights nicht über eine integrierte Unterstützung für die Nachverfolgung von Redis als Abhängigkeit verfügt. (Eine Liste dessen, was standardmäßig unterstützt wird, finden Sie unter Automatisches Sammeln von Abhängigkeiten.) Als Fallback können Sie die TrackDependency-API verwenden, um jede Abhängigkeit nachzuverfolgen. Bei Auslastungstests werden Lücken dieser Art, die wiederhergestellt werden können, häufig in der Telemetrie angezeigt.
Test 2: Gesteigerte Cachegröße
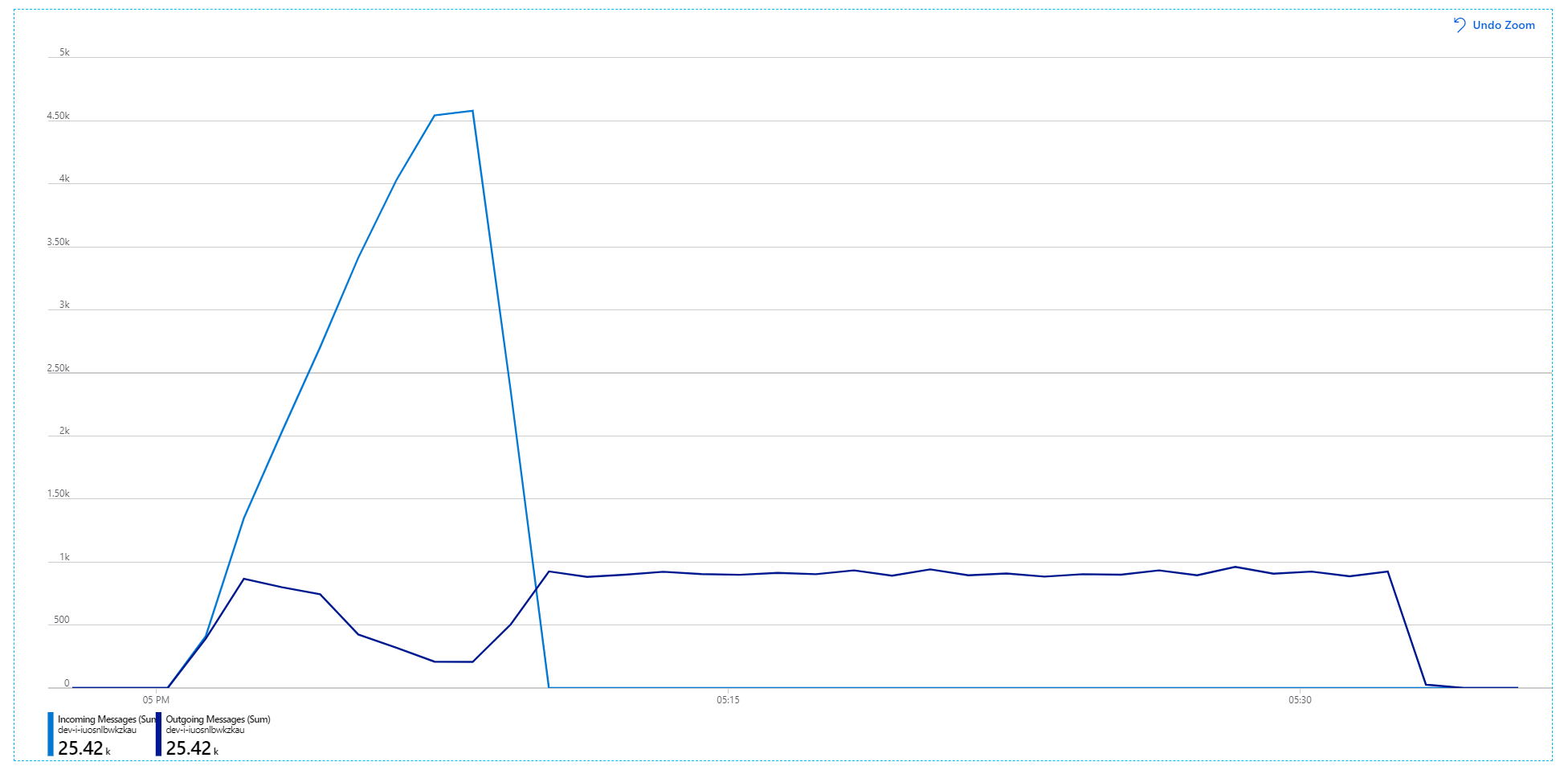
Für den zweiten Auslastungstest hat das Entwicklungsteam die Cachegröße in Azure-Cache für Redis gesteigert. (Siehe Skalieren von Azure-Cache für Redis.) Durch diese Änderung wurden die auf Arbeitsspeichermangel basierenden Ausnahmen aufgelöst, und die Anwendungsübersicht zeigt nun keine Fehler an:
Es gibt jedoch immer noch eine deutliche Verzögerung bei der Verarbeitung von Nachrichten. Auf der Spitze des Auslastungstests ist die Rate der eingehenden Nachrichten mehr als 5× so hoch wie die Rate der ausgehenden Nachrichten:
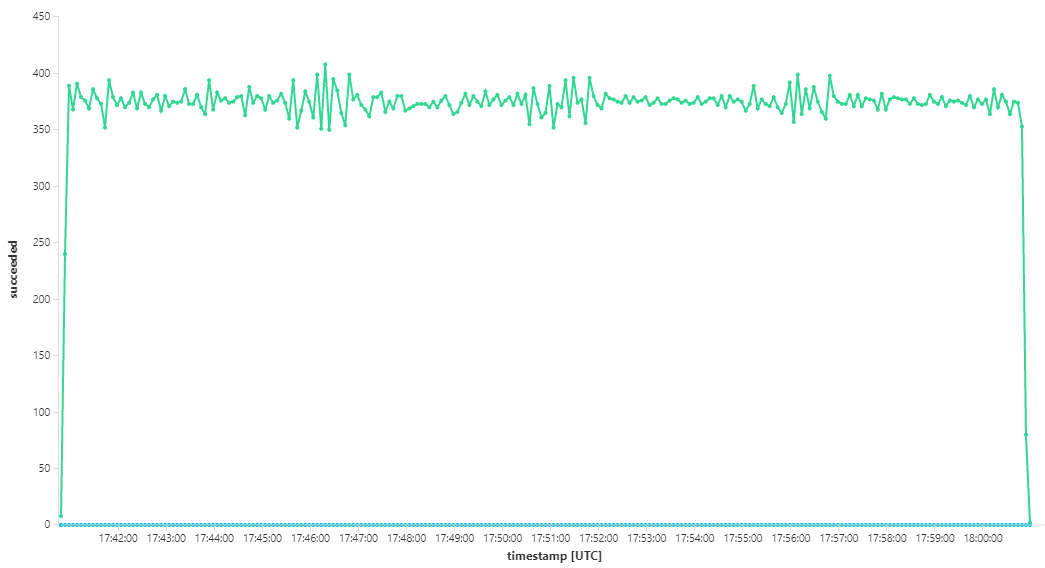
Im folgenden Graph wird der Durchsatz im Hinblick auf den Abschluss der Nachrichtenverarbeitung gemessen – d. h., die Rate, mit der der Workflow-Dienst die Verarbeitung der Service Bus-Nachrichten als abgeschlossen markiert. Jeder Punkt im Diagramm stellt 5 Sekunden Daten dar und zeigt einen maximalen Durchsatz von ~16/Sekunde.

Dieses Diagramm wurde durch Ausführen einer Abfrage im Log Analytics-Arbeitsbereich mithilfe der Kusto-Abfragesprache generiert:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Test 3: Aufskalieren der Back-End-Dienste
Das Back-End scheint der Engpass zu sein. Ein einfacher nächster Schritt besteht darin, die Unternehmensdienste (Package, Delivery und Drone Scheduler) aufzuskalieren und festzustellen, ob der Durchsatz verbessert wird. Für den nächsten Auslastungstest hat das Team diese Dienste von drei Replikaten auf sechs Replikate horizontal hochskaliert.
| Einstellung | Wert |
|---|---|
| Clusterknoten | 6 |
| Ingestion-Dienst | 3 Replikate |
| Workflow-Dienst | 3 Replikate |
| Package-, Drone Scheduler- und Delivery-Dienst | jeweils 6 Replikate |
Leider zeigt dieser Auslastungstest nur eine geringfügige Verbesserung. Ausgehende Nachrichten halten immer noch nicht mit eingehenden Nachrichten Schritt:
Der Durchsatz ist konsistenter, aber der maximal erreichte Wert ist ungefähr identisch mit dem vorherigen Test:

Außerdem zeigt ein Blick in Azure Monitor Container Insights, dass das Problem wohl nicht durch Ressourcenauslastung innerhalb des Clusters verursacht wird. Zunächst zeigen die Metriken auf Knotenebene an, dass die CPU-Nutzung auch im 95. Perzentil unter 40 % bleibt und die Arbeitsspeichernutzung ungefähr 20 % beträgt.
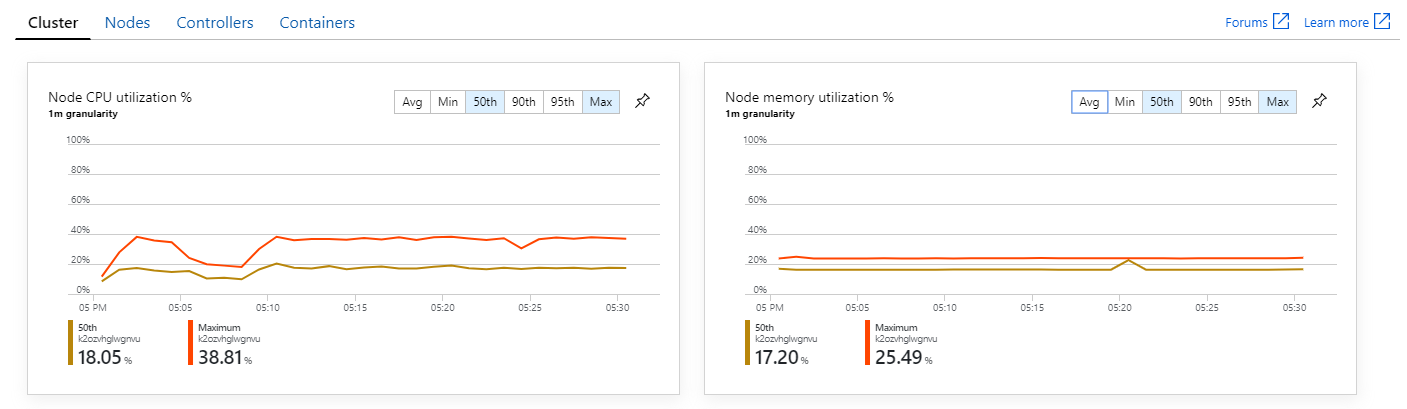
In einer Kubernetes-Umgebung können die Ressourcen für einzelne Pods auch dann eingeschränkt werden, wenn dies für die Knoten nicht der Fall ist. Die Ansicht auf Podebene zeigt jedoch, dass alle Pods fehlerfrei sind.
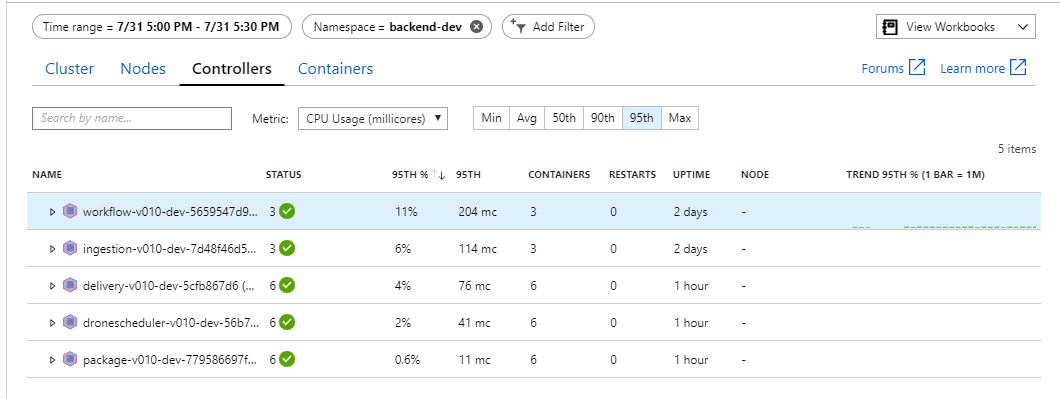
Diesem Test zufolge scheint es keine Hilfe zu sein, dem Back-End einfach mehr Pods hinzuzufügen. Der nächste Schritt besteht darin, den Workflow-Dienst genauer zu betrachten, um nachzuvollziehen, was passiert, wenn er Nachrichten verarbeitet. Application Insights zeigt, dass die durchschnittliche Dauer des Process-Vorgangs des Workflow-Diensts 246 ms beträgt.

Wir können auch eine Abfrage ausführen, um Metriken zu den einzelnen Vorgängen innerhalb der einzelnen Transaktionen zu erhalten:
| target | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86,66950203 | 283,4255578 |
| bereitstellung | 37 | 57 |
| Paket | 12 | 17 |
| dronescheduler | 21 | 41 |
Die erste Zeile in dieser Tabelle stellt die Service Bus-Warteschlange dar. Die anderen Zeilen sind die Aufrufe der Back-End-Dienste. Im Folgenden finden Sie die Log Analytics-Abfrage für diese Tabelle:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
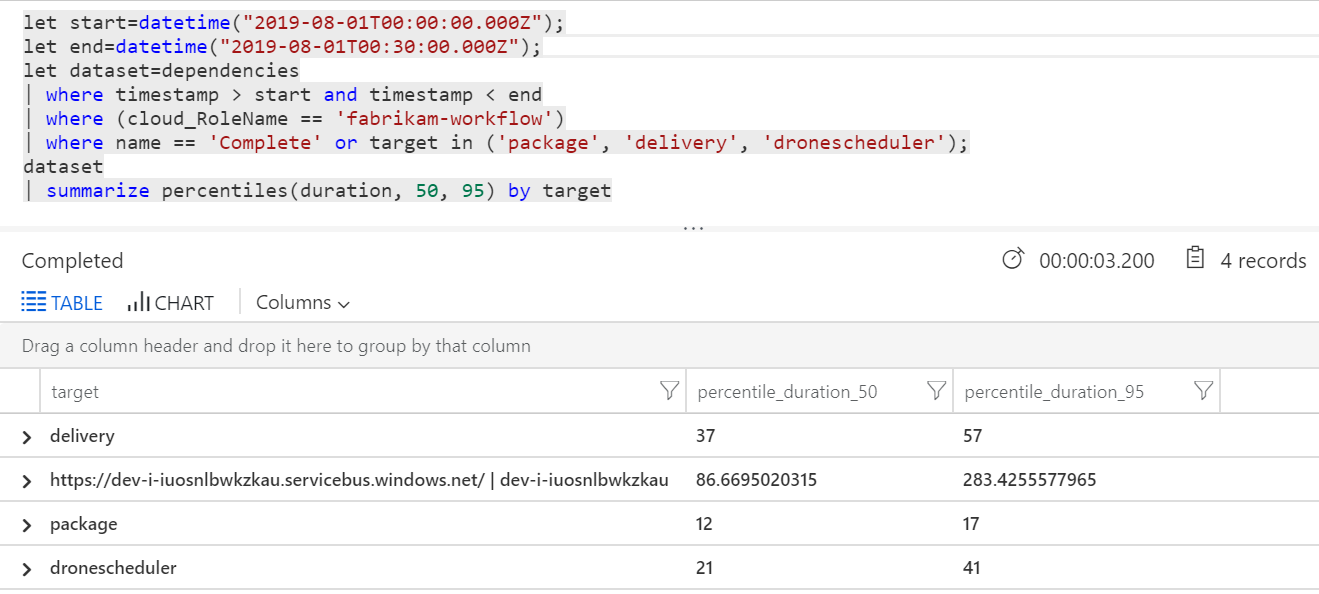
Diese Latenzen sehen vernünftig aus. Doch hier ist der wichtigste Einblick: Wenn die Gesamtdauer des Vorgangs ungefähr 250 ms beträgt, wird eine strikte Obergrenze für die Geschwindigkeit der seriellen Verarbeitung von Nachrichten festgesetzt. Der Schlüssel zur Verbesserung des Durchsatzes ist daher eine größere Parallelität.
Dies sollte in diesem Szenario aus zwei Gründen möglich sein:
- Dabei handelt es sich um Netzwerkaufrufe, sodass die meiste Zeit für das Warten auf den E/A-Abschluss aufgewendet wird.
- Die Nachrichten sind unabhängig und müssen nicht in einer bestimmten Reihenfolge verarbeitet werden.
Test 4: Erhöhen der Parallelität
Für diesen Test konzentrierte sich das Team auf die Erhöhung der Parallelität. Zu diesem Zweck wurden zwei Einstellungen auf dem Service Bus-Client angepasst, der vom Workflow-Dienst verwendet wird:
| Einstellung | BESCHREIBUNG | Standard | Neuer Wert |
|---|---|---|---|
MaxConcurrentCalls |
Die maximale Anzahl von Nachrichten, die gleichzeitig verarbeitet werden sollen. | 1 | 20 |
PrefetchCount |
Die Anzahl der Nachrichten, die der Client im Voraus in seinen lokalen Cache abruft. | 0 | 3000 |
Weitere Informationen zu diesen Einstellungen finden Sie unter Bewährte Methoden für Leistungsoptimierungen mithilfe von Service Bus-Messaging. Aus der Ausführung des Tests mit diesen Einstellungen resultierte dieses Diagramm:
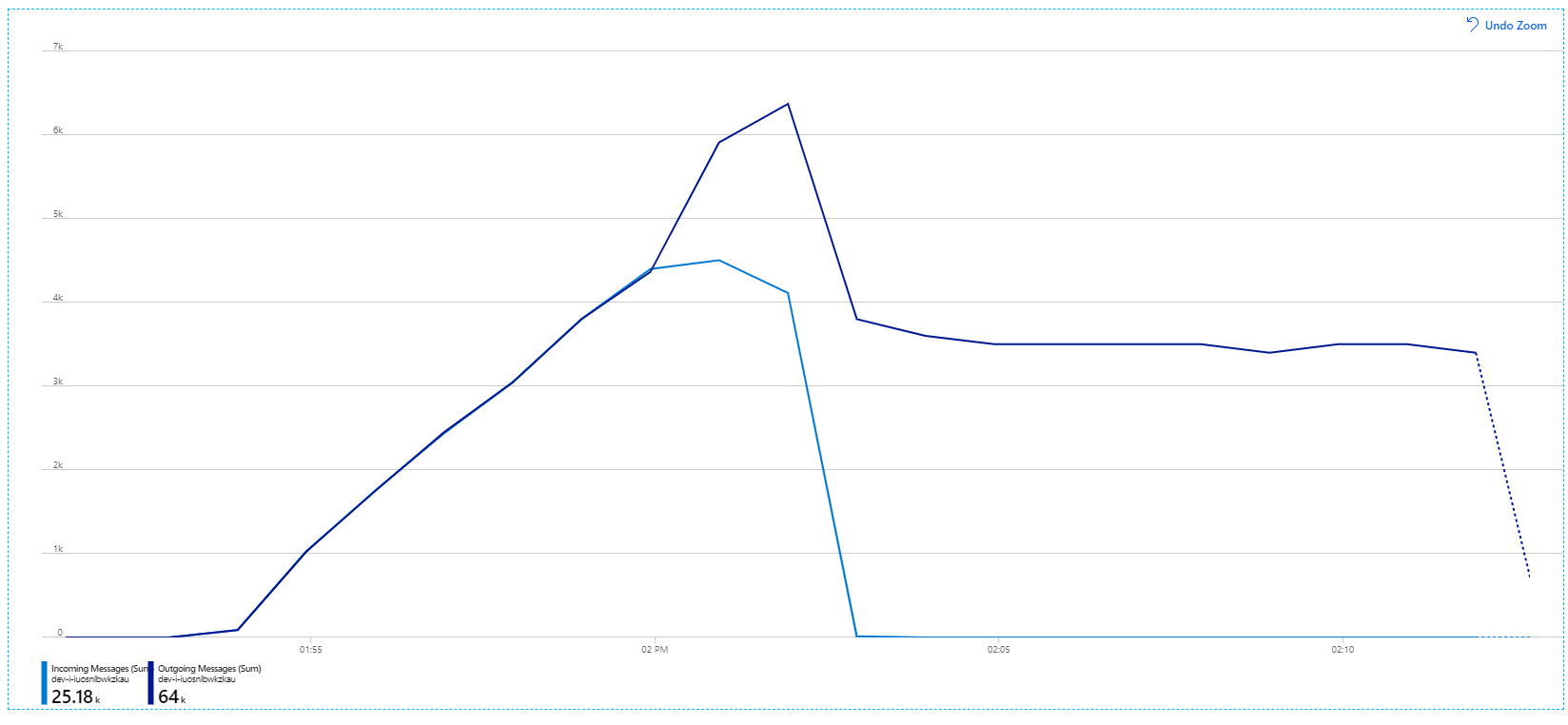
Erinnern Sie sich: Eingehende Nachrichten werden hellblau und ausgehende Nachrichten dunkelblau angezeigt.
Auf den ersten Blick ist dies ein sehr merkwürdiges Diagramm. Für eine Weile folgt die Rate der ausgehenden Nachrichten genau der Rate der eingehenden Nachrichten. Doch dann, etwa bei der 2:03-Marke, flacht die Rate eingehender Nachrichten ab, während die Anzahl der ausgehenden Nachrichten weiterhin zunimmt und die Gesamtzahl eingehender Nachrichten tatsächlich überschreitet. Das scheint unmöglich zu sein.
Des Rätsels Lösung finden Sie in der Ansicht Abhängigkeiten in Application Insights. In diesem Diagramm werden alle Aufrufe des Workflow-Diensts an Service Bus zusammengefasst:
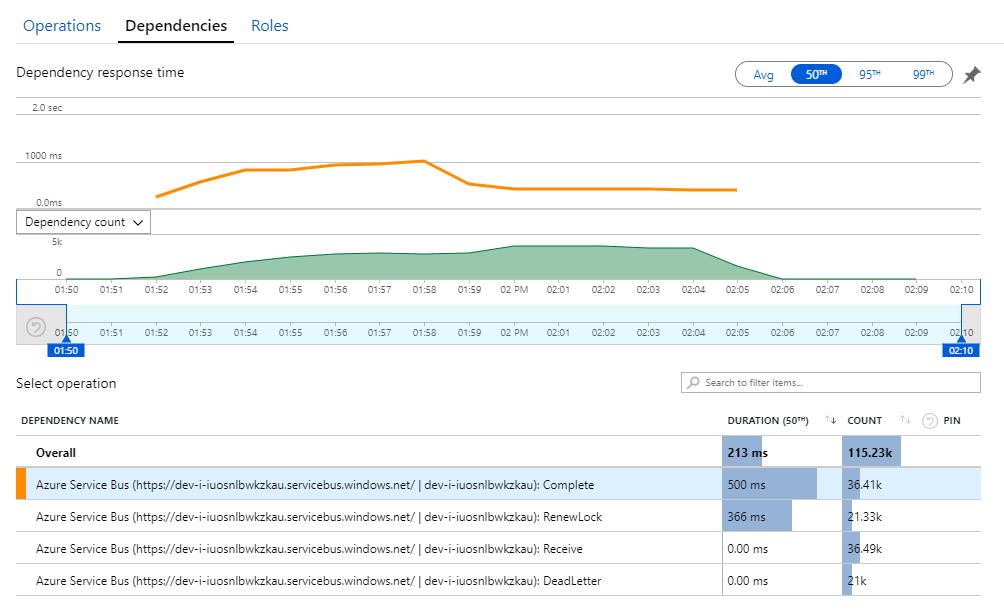
Beachten Sie den Eintrag für DeadLetter. Diese Aufrufe deuten darauf hin, dass Nachrichten in der Warteschlange für unzustellbare Nachrichten von Service Bus abgelegt werden.
Um zu verstehen, was passiert, müssen Sie die Peek-Lock-Semantik in Service Bus verstehen. Wenn ein Client Peek-Lock verwendet, ruft Service Bus atomisch eine Nachricht ab und sperrt sie. Während die Sperre aufrechterhalten wird, wird die Nachricht garantiert nicht an andere Empfänger übermittelt. Wenn die Sperre abläuft, wird die Nachricht für andere Empfänger verfügbar. Nach einer (konfigurierbaren) maximalen Anzahl von Zustellversuchen werden die Nachrichten von Service Bus in eine Warteschlange für unzustellbare Nachrichten eingereiht, wo sie später überprüft werden können.
Beachten Sie, dass der Workflow-Dienst große Batches von Nachrichten vorab abruft – 3000 Nachrichten gleichzeitig. Dies bedeutet, dass die Gesamtzeit für die Verarbeitung der einzelnen Nachrichten länger ist, was dazu führt, dass für Nachrichten ein Timeout eintritt, sie in die Warteschlange zurückkehren und schließlich in die Warteschlange für unzustellbare Nachrichten eingereiht werden.
Dieses Verhalten können Sie auch in den Ausnahmen beobachten, in denen zahlreiche MessageLostLockException-Ausnahmen aufgezeichnet werden:

Test 5: Erhöhen der Sperrdauer
Für diesen Auslastungstest wurde die Dauer der Nachrichtensperre auf 5 Minuten festgelegt, um Sperrtimeouts zu verhindern. Das Diagramm der eingehenden und ausgehenden Nachrichten zeigt nun, dass das System mit der Rate eingehender Nachrichten Schritt hält:
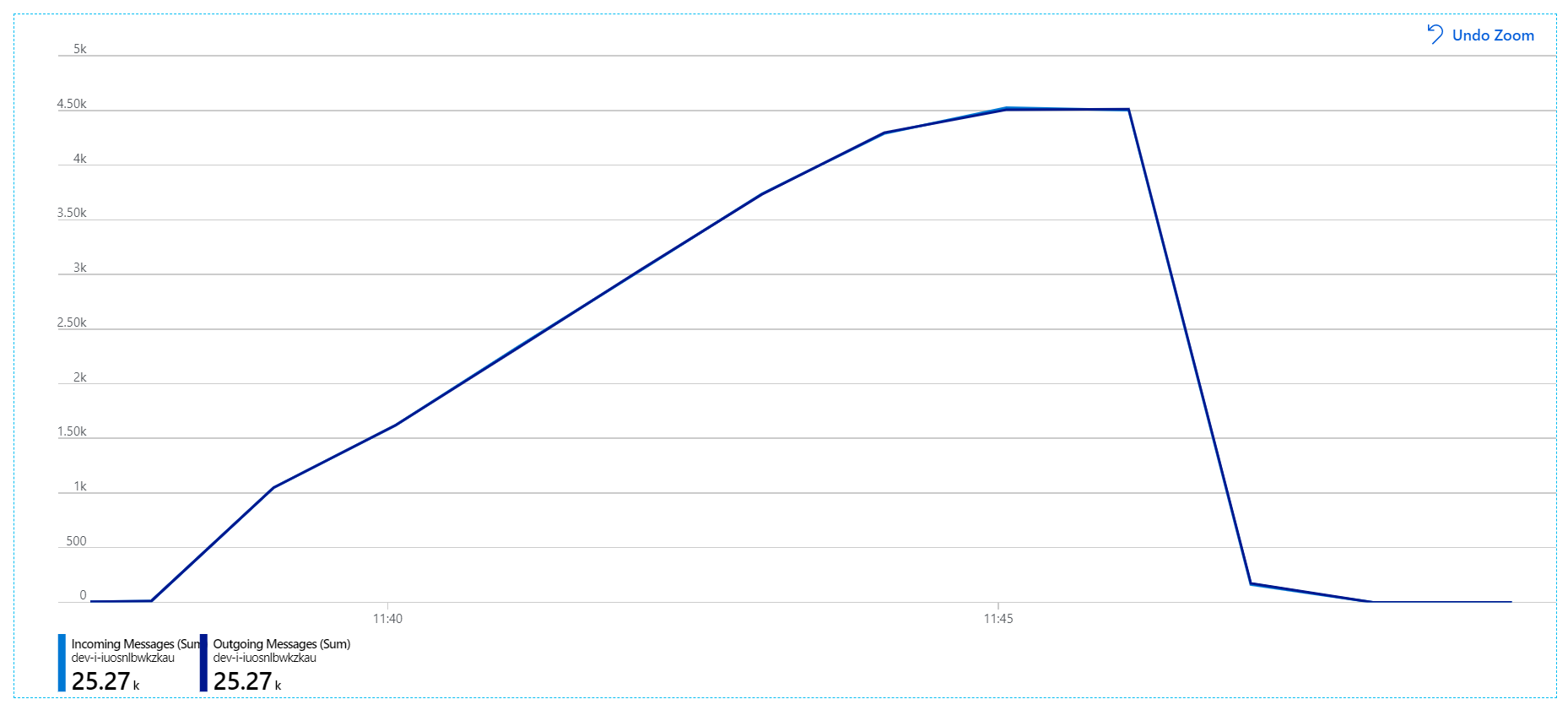
Während der gesamten Dauer des 8-minütigen Auslastungstests hat die Anwendung 25 Tsd. Vorgänge mit einem Spitzendurchsatz von 72 Vorgängen/Sekunde abgeschlossen, was einer Erhöhung des maximalen Durchsatzes um 400 % entspricht.
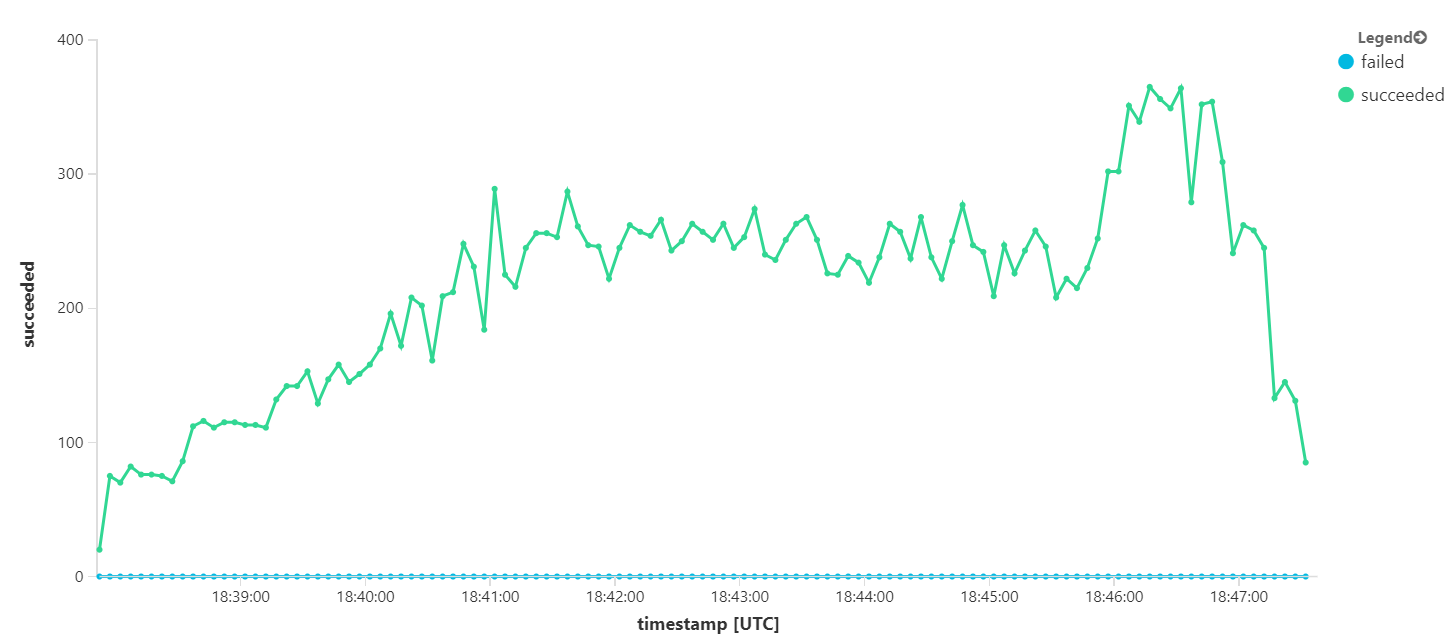
Das Ausführen desselben Tests mit einer längeren Dauer hat jedoch ergeben, dass die Anwendung diese Rate nicht aufrechterhalten konnte:
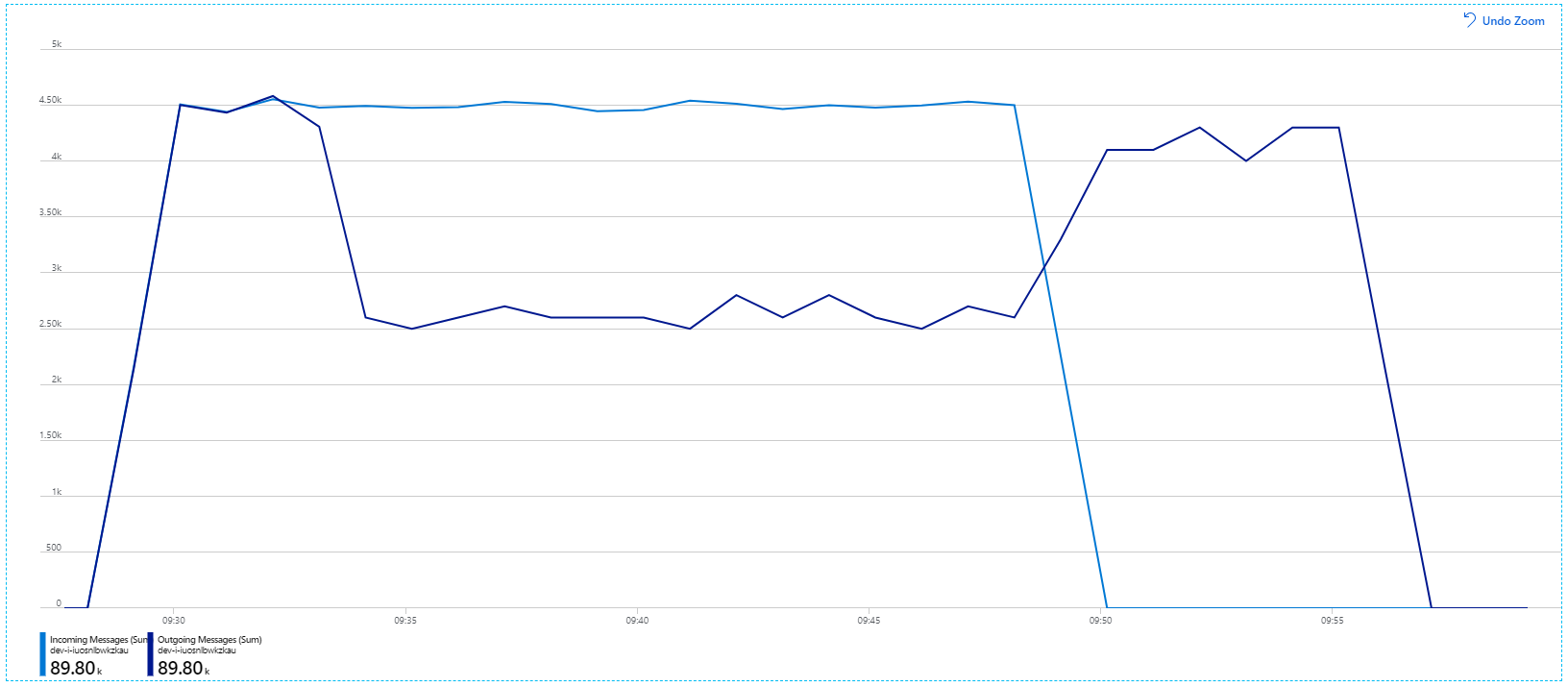
Die Containermetrik zeigt, dass die maximale CPU-Auslastung nahezu bei 100 % lag. An diesem Punkt scheint die Anwendung CPU-abhängig zu sein. Das Skalieren des Clusters könnte die Leistung nun im Gegensatz zum vorherigen Versuch einer horizontalen Hochskalierung verbessern.
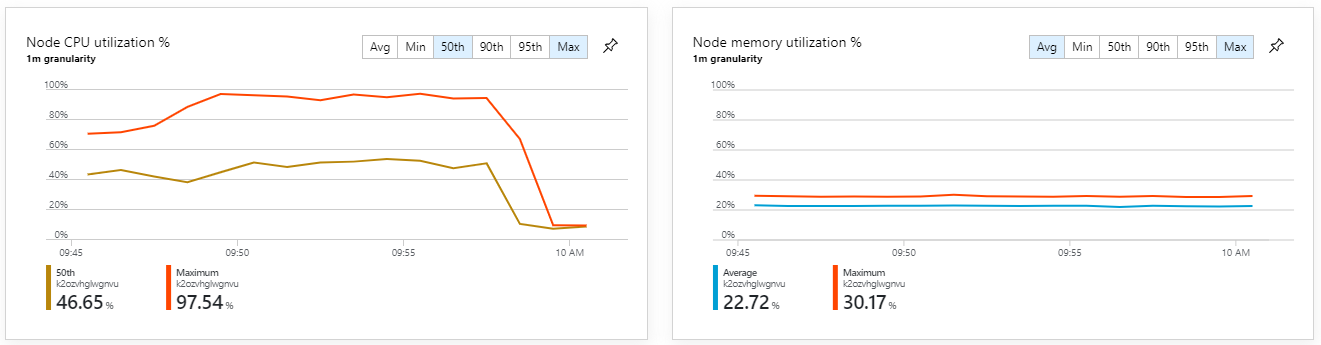
Test 6: Aufskalieren der Back-End-Dienste (erneut)
Für den letzten Auslastungstest in der Reihe hat das Team den Kubernetes-Cluster und die Pods wie folgt horizontal hochskaliert:
| Einstellung | Wert |
|---|---|
| Clusterknoten | 12 |
| Ingestion-Dienst | 3 Replikate |
| Workflow-Dienst | 6 Replikate |
| Package-, Drone Scheduler- und Delivery-Dienst | jeweils 9 Replikate |
Dieser Test führte zu einem höheren kontinuierlichen Durchsatz ohne erhebliche Verzögerungen der Verarbeitung von Nachrichten. Außerdem blieb die Knoten-CPU-Auslastung unter 80 %.
Zusammenfassung
In diesem Szenario wurden die folgenden Engpässe identifiziert:
- Ausnahmen wegen nicht ausreichendem Arbeitsspeicher in Azure Cache für Redis.
- Fehlende Parallelität bei der Nachrichtenverarbeitung.
- Unzureichende Dauer der Nachrichtensperre, was zu Sperrtimeouts und zum Einreihen von Nachrichten in der Warteschlange für unzustellbare Nachrichten führte.
- CPU-Auslastung.
Um diese Probleme zu diagnostizieren, stützte sich das Entwicklungsteam auf die folgenden Metriken:
- Die Rate der eingehenden und ausgehenden Service Bus-Nachrichten.
- Anwendungsübersicht in Application Insights.
- Fehler und Ausnahmen.
- Benutzerdefinierte Log Analytics-Abfragen.
- CPU- und Arbeitsspeicherauslastung in Azure Monitor Container Insights
Nächste Schritte
Weitere Informationen zum Entwurf dieses Szenarios finden Sie unter Entwerfen einer Microservices-Architektur.