In diesem Artikel wird beschrieben, wie ein Entwicklungsteam Metriken verwendet, um Engpässe zu ermitteln und die Leistung eines verteilten Systems zu verbessern. Der Artikel basiert auf den tatsächlichen Auslastungstests, die wir für eine Beispielanwendung durchgeführt haben.
Dieser Artikel ist Teil einer Serie. Lesen Sie hier den ersten Teil.
Szenario: Verarbeiten eines Ereignisdatenstroms mit Azure Functions.

In diesem Szenario sendet eine Flotte von Drohnen Positionsdaten in Echtzeit an Azure IoT Hub. Eine Azure Functions-App empfängt die Ereignisse, transformiert die Daten in das GeoJSON-Format und schreibt die transformierten Daten in Azure Cosmos DB. Azure Cosmos DB bietet native Unterstützung für räumliche Daten, und Azure Cosmos DB-Sammlungen können für effiziente räumliche Abfragen indiziert werden. Beispielsweise könnte eine Clientanwendung alle Drohnen im Umkreis von 1 km eines bestimmten Standorts abfragen oder alle Drohnen innerhalb eines bestimmten Bereichs suchen.
Diese Verarbeitungsanforderungen sind so einfach, dass sie keine vollständige Streamverarbeitungs-Engine benötigen. Insbesondere führt die Verarbeitung keine Datenströme zusammen, aggregiert keine Daten und führt keine Zeitfenster übergreifende Verarbeitung durch. Basierend auf diesen Anforderungen ist Azure Functions für die Verarbeitung der Nachrichten gut geeignet. Azure Cosmos DB kann auch zur Unterstützung eines sehr hohen Schreibdurchsatzes skaliert werden.
Überwachen des Durchsatzes
Dieses Szenario stellt eine interessante Leistungsherausforderung dar. Die Datenrate pro Gerät ist bekannt, aber die Anzahl der Geräte kann schwanken. Für dieses Geschäftsszenario sind die Latenzanforderungen nicht besonders streng. Die gemeldete Position einer Drohne muss nur innerhalb einer Minute genau sein. Dies bedeutet, dass die Funktions-App mit der durchschnittlichen Erfassungsrate im Zeitverlauf Schritt halten muss.
IoT Hub speichert Nachrichten in einem Protokolldatenstrom. Eingehende Nachrichten werden am Ende des Streams angehängt. Ein Leser des Datenstroms – in diesem Fall die Funktions-App – liest den Datenstrom mit selbstbestimmter Rate. Diese Entkopplung von Lese- und Schreibpfaden macht IoT Hub sehr effizient, bedeutet aber auch, dass ein langsamer Leser in den Rückstand geraten kann. Um diese Bedingung zu erkennen, hat das Entwicklungsteam eine benutzerdefinierte Metrik hinzugefügt, um die Nachrichtenlatenz zu messen. Mit dieser Metrik wird das Delta zwischen dem Zeitpunkt des Eintreffens einer Nachricht bei IoT Hub und dem Zeitpunkt des Empfangs der Nachricht für die Verarbeitung durch die Funktion aufgezeichnet.
var ticksUTCNow = DateTimeOffset.UtcNow;
// Track whether messages are arriving at the function late.
DateTime? firstMsgEnqueuedTicksUtc = messages[0]?.EnqueuedTimeUtc;
if (firstMsgEnqueuedTicksUtc.HasValue)
{
CustomTelemetry.TrackMetric(
context,
"IoTHubMessagesReceivedFreshnessMsec",
(ticksUTCNow - firstMsgEnqueuedTicksUtc.Value).TotalMilliseconds);
}
Die TrackMetric-Methode schreibt eine benutzerdefinierte Metrik in Application Insights. Informationen zur Verwendung von TrackMetric innerhalb einer Azure-Funktion finden Sie unter Benutzerdefinierte Telemetrie in C#-Funktionen.
Wenn die Funktion mit der Menge der Nachrichten Schritt hält, sollte diese Metrik in einem niedrigen stabilen Zustand bleiben. Eine gewisse Latenz ist unvermeidlich, sodass der Wert nie 0 (null) ist. Wenn die Funktion jedoch zurückfällt, steigt das Delta zwischen dem Zeitpunkt der Einreihung in die Warteschlange und dem Zeitpunkt der Verarbeitung an.
Test 1: Grundwert
Der erste Auslastungstest hat ein unmittelbares Problem aufgezeigt: Die Funktions-APP hat konsistent HTTP 429-Fehler von Azure Cosmos DB empfangen, was darauf hinweist, dass Azure Cosmos DB die Schreibanforderungen drosselt.
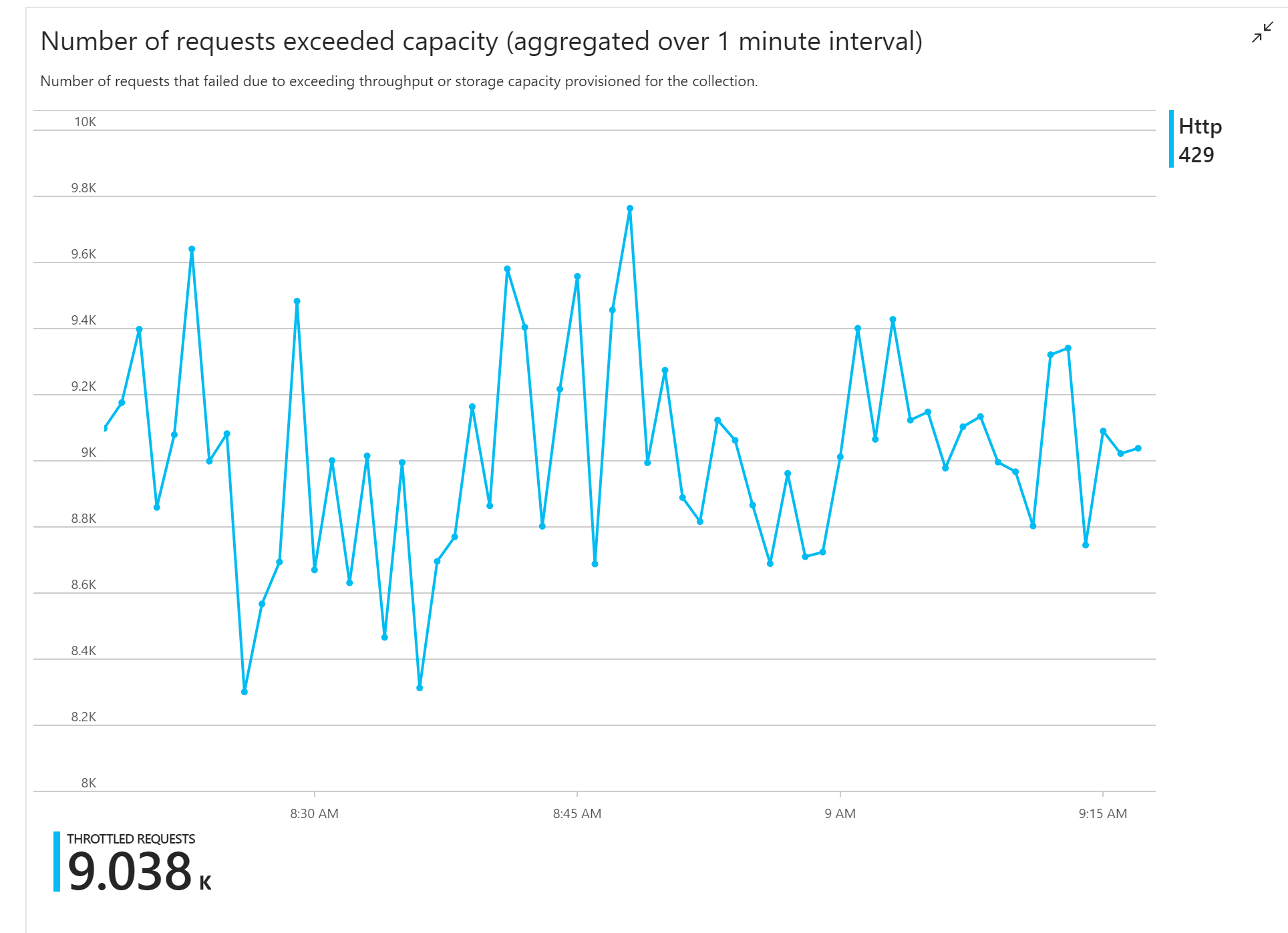
Als Reaktion hat das Team Azure Cosmos DB durch Erhöhen der Anzahl der RUs, die der Sammlung zugeordnet sind, skaliert, aber die Fehler traten weiterhin auf. Dies erschien seltsam, weil die Überschlagsrechnung zeigte, dass es für Azure Cosmos DB kein Problem sein sollte, mit der Menge der Schreibanforderungen Schritt zu halten.
Im weiteren Verlauf des Tags sendete einer der Entwickler die folgende E-Mail an das Team:
Ich habe in Azure Cosmos DB nach dem warmen Pfad gesucht. Eines verstehe ich nicht. Der Partitionsschlüssel ist deliveryId, aber wir senden deliveryId nicht an Azure Cosmos DB. Habe ich etwas übersehen?
Das war des Rätsels Lösung. Bei der Betrachtung des Wärmebilds der Partition stellte sich heraus, dass alle Dokumente in derselben Partition landeten.
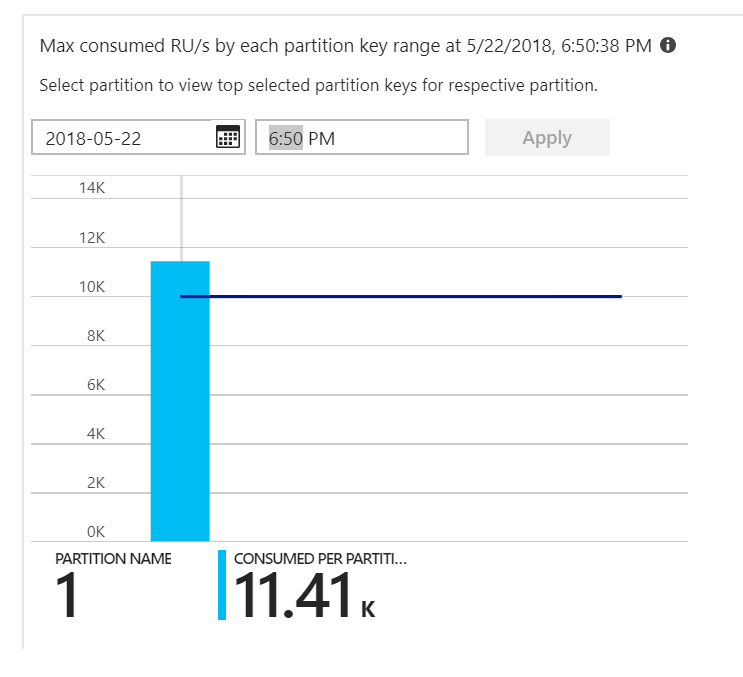
Was Sie im Wärmebild sehen möchten, ist eine gleichmäßige Verteilung über alle Partitionen hinweg. Da in diesem Fall jedes Dokument in dieselbe Partition geschrieben wurde, war das Hinzufügen von RUs nicht hilfreich. Das Problem erwies sich als Fehler im Code. Obwohl die Azure Cosmos DB-Sammlung einen Partitionsschlüssel enthielt, bezog die Azure-Funktion den Partitionsschlüssel nicht in das Dokument ein. Weitere Informationen zum Partitionswärmebild finden Sie unter Ermitteln der partitionsübergreifenden Durchsatzverteilung.
Test 2: Beheben von Partitionierungsproblemen
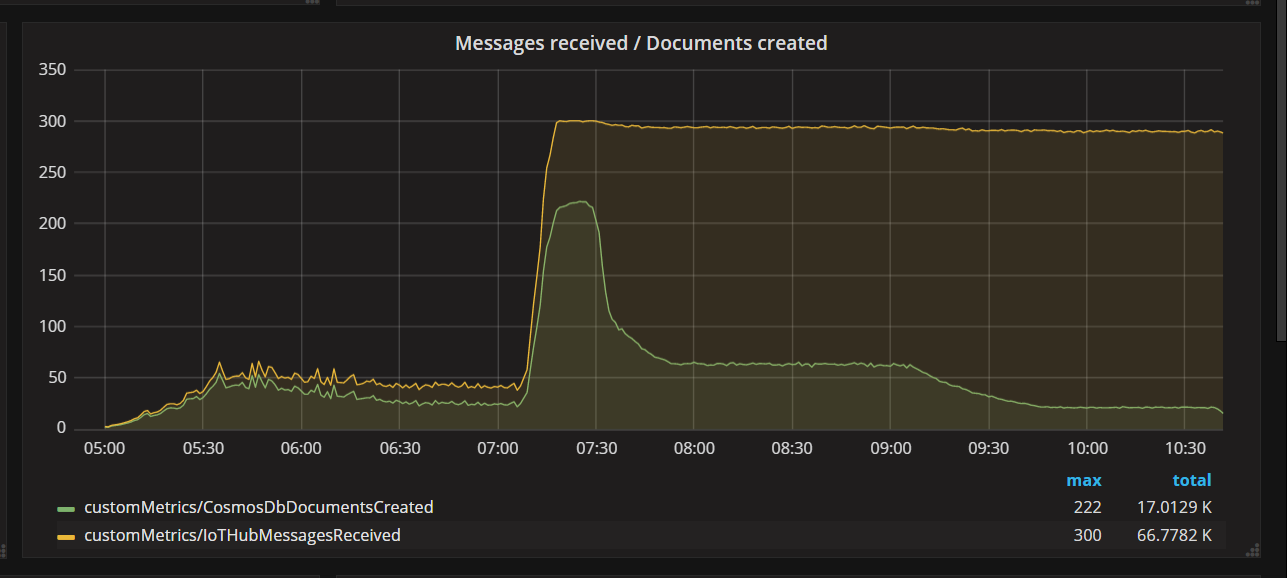
Als das Team eine Codekorrektur bereitstellte und den Test erneut ausführte, beendete Azure Cosmos DB die Drosselung. Für eine Weile sah alles gut aus. Doch bei einer bestimmten Auslastung zeigte die Telemetrie, dass die Funktion weniger Dokumente schrieb als sie sollte. Das folgende Diagramm zeigt von IoT Hub empfangene Nachrichten im Vergleich zu in Azure Cosmos DB geschriebenen Dokumenten. Die gelbe Linie zeigt die Anzahl pro Batch empfangener Nachrichten und die grüne die Anzahl pro Batch geschriebener Dokumente. Diese sollten proportional sein. Stattdessen sinkt die Anzahl der Datenbank-Schreibvorgänge pro Batch erheblich bei 07:30.
Das nächste Diagramm zeigt die Latenz zwischen dem Eintreffen einer Nachricht von einem Gerät bei IoT Hub und der Verarbeitung dieser Nachricht durch die Funktions-App. Sie sehen, dass die Verspätung zum selben Zeitpunkt drastisch zum Spitzenwert ansteigt, abflacht und sinkt.
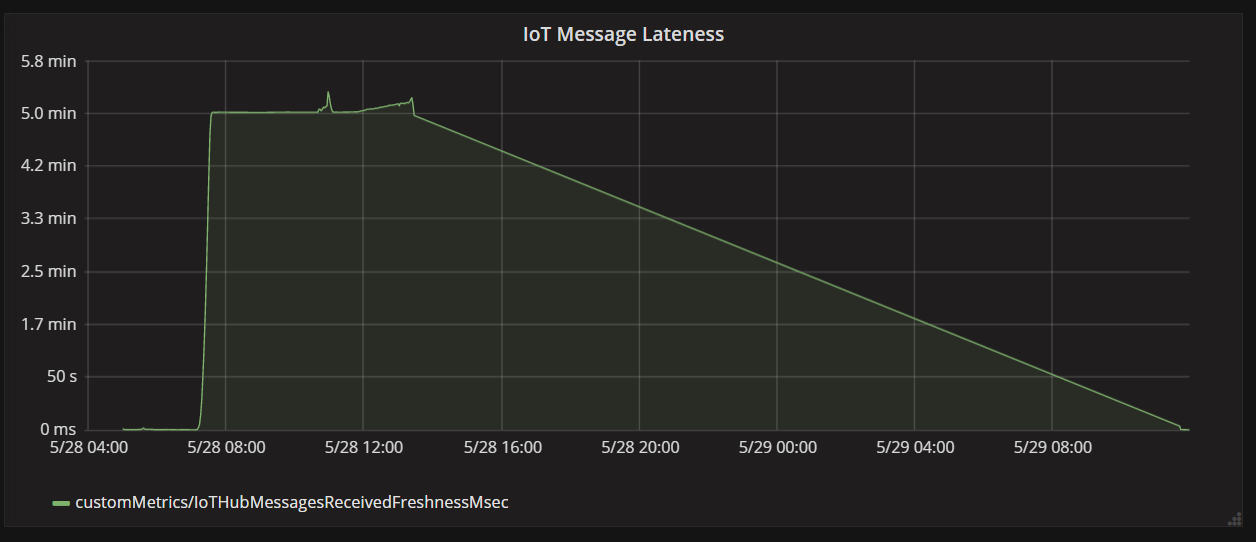
Der Grund dafür, dass der Spitzenwert bei 5 Minuten erreicht wird und der Wert dann auf null (0) abfällt ist, dass die Funktions-App Nachrichten verwirft, die mehr als 5 Minuten verspätet sind:
foreach (var message in messages)
{
// Drop stale messages,
if (message.EnqueuedTimeUtc < cutoffTime)
{
log.Info($"Dropping late message batch. Enqueued time = {message.EnqueuedTimeUtc}, Cutoff = {cutoffTime}");
droppedMessages++;
continue;
}
}
Sie sehen dies im Diagramm, wenn die Verspätungsmetrik auf null (0) zurückfällt. In der Zwischenzeit gingen Daten verloren, da die Funktion Nachrichten verwarf.
Was war passiert? Für diesen speziellen Auslastungstest verfügte die Azure Cosmos DB-Sammlung über RU-Reserven, sodass der Engpass nicht in der Datenbank aufgetreten war. Stattdessen lag das Problem in der Nachrichtenverarbeitungsschleife. Einfach ausgedrückt: Die Funktion schrieb Dokumente nicht schnell genug, um mit der eingehenden Menge an Nachrichten Schritt halten zu können. Im Laufe der Zeit fiel sie immer weiter zurück.
Test 3: Parallele Schreibvorgänge
Wenn die Zeit zum Verarbeiten einer Nachricht der Engpass ist, besteht eine Lösung darin, mehr Nachrichten parallel zu verarbeiten. Szenario:
- Erhöhen Sie die Anzahl der IoT Hub-Partitionen. Jede IoT Hub-Partition wird jeweils einer Funktionsinstanz zugewiesen, sodass zu erwarten ist, dass der Durchsatz linear zur Anzahl der Partitionen skaliert wird.
- Parallelisieren Sie die Dokumentschreibvorgänge innerhalb der Funktion.
Zum Erforschen der zweiten Option hat das Team die Funktion so geändert, dass parallele Schreibvorgänge unterstützt werden. Die ursprüngliche Version der Funktion hat die Ausgabebindung von Azure Cosmos DB verwendet. Die optimierte Version ruft den Azure Cosmos DB-Client direkt auf und führt die Schreibvorgänge mithilfe von Task.WhenAll parallel aus:
private async Task<(long documentsUpserted,
long droppedMessages,
long cosmosDbTotalMilliseconds)>
ProcessMessagesFromEventHub(
int taskCount,
int numberOfDocumentsToUpsertPerTask,
EventData[] messages,
TraceWriter log)
{
DateTimeOffset cutoffTime = DateTimeOffset.UtcNow.AddMinutes(-5);
var tasks = new List<Task>();
for (var i = 0; i < taskCount; i++)
{
var docsToUpsert = messages
.Skip(i * numberOfDocumentsToUpsertPerTask)
.Take(numberOfDocumentsToUpsertPerTask);
// client will attempt to create connections to the data
// nodes on Azure Cosmos DB clusters on a range of port numbers
tasks.Add(UpsertDocuments(i, docsToUpsert, cutoffTime, log));
}
await Task.WhenAll(tasks);
return (this.UpsertedDocuments,
this.DroppedMessages,
this.CosmosDbTotalMilliseconds);
}
Beachten Sie, dass Racebedingungen bei der Herangehensweise möglich sind. Nehmen wir an, dass zwei Nachrichten von derselben Drohne im gleichen Nachrichtenbatch eintreffen. Wenn sie parallel geschrieben werden, könnte die frühere Nachricht die spätere Nachricht überschreiben. In diesem speziellen Szenario kann die Anwendung tolerieren, dass gelegentlich eine Nachricht verloren geht. Drohnen senden alle 5 Sekunden neue Positionsdaten, sodass die Daten in Azure Cosmos DB ständig aktualisiert werden. In anderen Szenarien kann es jedoch wichtig sein, Nachrichten streng in der richtigen Reihenfolge zu verarbeiten.
Nach der Bereitstellung dieser Codeänderung konnte die Anwendung mithilfe einer IoT Hub-Instanz mit 32 Partitionen mehr als 2.500 Anforderungen/Sekunde erfassen.
Clientseitige Überlegungen
Die Gesamtleistung des Clients kann durch aggressive Parallelisierung auf Serverseite beeinträchtigt werden. Sie sollten die Verwendung der Bibliothek BulkExecutor von Azure Cosmos DB in Erwägung ziehen (in dieser Implementierung nicht dargestellt), wodurch die clientseitigen Computeressourcen erheblich reduziert werden, die für die vollständige Nutzung des einem Azure Cosmos DB-Container zugeordneten Durchsatzes erforderlich sind. Eine Singlethreadanwendung, die Daten über die Massenimport-API schreibt, erzielt einen nahezu zehnmal höheren Schreibdurchsatz im Vergleich zu einer Multithreadanwendung, die Daten parallel schreibt und gleichzeitig die CPU des Clientcomputers vollständig nutzt.
Zusammenfassung
In diesem Szenario wurden die folgenden Engpässe identifiziert:
- Heiße Schreibpartition, weil in den geschriebenen Dokumenten ein Partitionsschlüsselwert fehlte.
- Serielles Schreiben von Dokumenten pro IoT Hub-Partition.
Um diese Probleme zu diagnostizieren, stützte sich das Entwicklungsteam auf die folgenden Metriken:
- Gedrosselte Anforderungen in Azure Cosmos DB.
- Partitionswärmebild – maximal verbrauchte RUs pro Partition
- Empfangene Nachrichten im Vergleich zu erstellten Dokumenten.
- Nachrichtenverspätung.
Nächste Schritte
Lesen Sie Leistungsbezogene Antimuster für Cloudanwendungen.