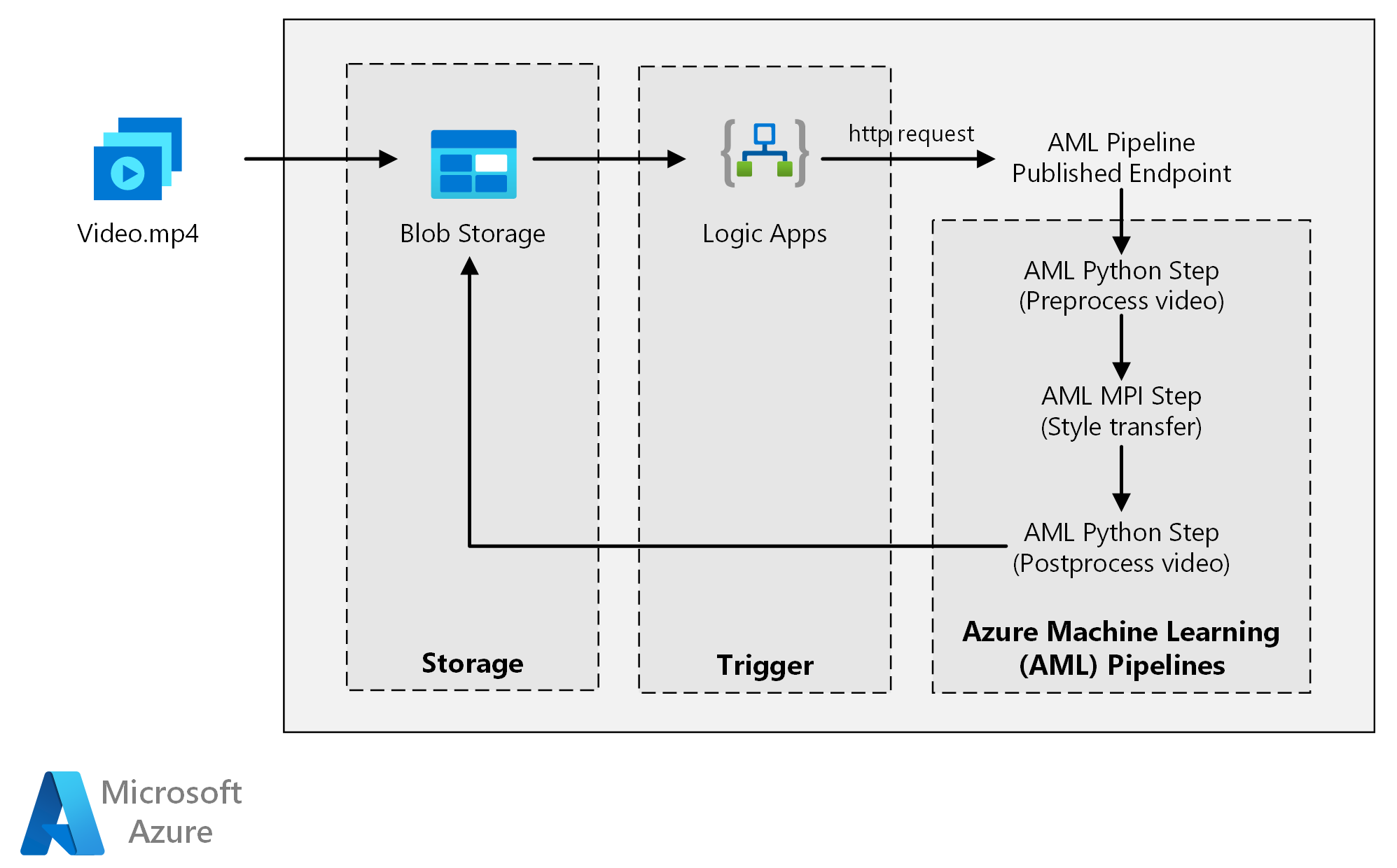
Diese Referenzarchitektur zeigt, wie Sie mit Azure Machine Learning die neuronale Stilübertragung auf ein Video anwenden. Stilübertragung ist eine Deep Learning-Technik, bei der ein vorhandenes Bild im Stil eines anderen Bildes erstellt wird. Sie können diese Architektur für jedes Szenario generalisieren, in dem die Batchbewertung mit Deep Learning verwendet wird.
Aufbau
Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
Diese Architektur umfasst die folgenden Komponenten.
Compute
Für Azure Machine Learning werden Pipelines verwendet, um reproduzierbare und einfach zu verwaltende Berechnungssequenzen zu erstellen. Darüber hinaus ist ein verwaltetes Computeziel mit dem Namen Azure Machine Learning Compute (auf dem eine Pipelineberechnung durchgeführt werden kann) verfügbar, mit dem Machine Learning-Modelle trainiert, bereitgestellt und bewertet werden können.
Storage
Azure Blob Storage speichert alle Bilder (Eingabebilder, Stilbilder und Ausgabebilder). Azure Machine Learning ist in Blob Storage integriert, damit Benutzer Daten nicht manuell über Computeplattformen und Blobspeicher hinweg verschieben müssen. Blob Storage ist zudem eine kostengünstige Option für die Leistung, die diese Workload erfordert.
Trigger
Azure Logic Apps löst den Workflow aus. Wenn die Logik-App erkennt, dass dem Container ein Blob hinzugefügt wurde, löst sie die Azure Machine Learning-Pipeline aus. Logic Apps passt gut zu dieser Referenzarchitektur, da mit dem Dienst Änderungen an Blob Storage einfach erkannt und Trigger leicht geändert werden können.
Vorverarbeitung und Nachverarbeitung der Daten
Diese Referenzarchitektur verwendet Videomaterial von einem Orang-Utan auf einem Baum.
- Verwenden Sie FFmpeg, um die Audiodatei aus dem Videomaterial zu extrahieren, damit sie später wieder mit dem Ausgabevideo zusammengefügt werden kann.
- Teilen Sie das Video mithilfe von FFmpeg in einzelne Frames auf. Die Frames werden unabhängig voneinander parallel verarbeitet.
- An diesem Punkt können Sie die neuronale Stilübertragung parallel auf die einzelnen Frames anwenden.
- Nachdem die einzelnen Frames verarbeitet wurden, müssen Sie FFmpeg verwenden, um die Frames wieder zusammenzufügen.
- Abschließend fügen Sie die Audiodatei wieder an das zusammengefügte Material an.
Komponenten
Details zur Lösung
Diese Referenzarchitektur ist für Workloads konzipiert, die durch das Vorhandensein neuer Medien in Azure Storage ausgelöst werden.
Die Verarbeitung umfasst die folgenden Schritte:
- Laden Sie eine Videodatei in Azure Blob Storage hoch.
- Die Videodatei löst in Azure Logic Apps das Senden einer Anforderung an den Endpunkt aus, der von der Azure Machine Learning-Pipeline veröffentlicht wird.
- Die Pipeline verarbeitet das Video, wendet die Stilübertragung mit MPI an und führt die Nachbearbeitung des Videos durch.
- Die Ausgabe wird wieder im Blobspeicher gespeichert, nachdem die Pipeline abgeschlossen wurde.
Mögliche Anwendungsfälle
Ein Medienunternehmen möchte den Stil eines Videos so ändern, dass er dem eines bestimmten Gemäldes entspricht. Das Unternehmen möchte diesen Stil schnell und automatisiert auf alle Videoframes anwenden. Weitere Informationen zu Algorithmen für die neuronale Stilübertragung finden Sie unter Image Style Transfer Using Convolutional Neural Networks (Bildstilübertragung mit Convolutional Neural Networks, PDF).
Überlegungen
Diese Überlegungen beruhen auf den Säulen des Azure Well-Architected Frameworks, d. h. einer Reihe von Grundsätzen, mit denen die Qualität von Workloads verbessert werden kann. Weitere Informationen finden Sie unter Microsoft Azure Well-Architected Framework.
Effiziente Leistung
Leistungseffizienz ist die Fähigkeit Ihrer Workload, auf effiziente Weise eine den Anforderungen der Benutzer entsprechende Skalierung auszuführen. Weitere Informationen finden Sie unter Übersicht über die Säule „Leistungseffizienz“.
Vergleich von GPU und CPU
Bei Deep Learning-Workloads bieten GPUs eine deutlich bessere Leistung als CPUs, sodass in der Regel ein großer Cluster von CPUs benötigt wird, um eine vergleichbare Leistung zu erzielen. Obwohl Sie in dieser Architektur nur CPUs verwenden können, bieten GPUs ein viel besseres Preis-Leistungs-Verhältnis. Es wird empfohlen, die neueste GPU-optimierte VM-Größe NCv3-Serie zu verwenden.
GPUs sind nicht in allen Regionen standardmäßig aktiviert. Wählen Sie deshalb eine Region aus, in der GPUs aktiviert sind. Darüber hinaus haben Abonnements ein Standardkontingent von null Kernen für GPU-optimierte VMs. Sie können dieses Kontingent erhöhen, indem Sie eine Supportanfrage stellen. Stellen Sie sicher, dass Ihr Abonnement über ausreichend Kontingent verfügt, um Ihre Workload auszuführen.
Vergleich des Parallelisierens auf VMs und Kernen
Wenn eine Stilübertragung als Batchauftrag ausgeführt wird, müssen die Aufträge, die hauptsächlich auf GPUs ausgeführt werden, über VMs hinweg parallelisiert werden. Zwei Ansätze sind möglich: Sie können einen größeren Cluster aus virtuellen Computern mit einer einzelnen GPU oder einen kleineren Cluster aus virtuellen Computern mit vielen GPUs erstellen.
Die beiden Optionen bieten für diese Workload eine vergleichbare Leistung. Die Verwendung von weniger VMs mit mehr GPUs pro VM kann dazu beitragen, die Datenverschiebung zu reduzieren. Das Datenvolumen pro Auftrag für diese Workload ist jedoch nicht groß, sodass Blob Storage keine umfangreiche Drosselung vornehmen wird.
MPI-Schritt
Beim Erstellen der Pipeline in Azure Machine Learning ist einer der Schritte zum Durchführen einer parallelen Berechnung der MPI (Message Processing Interface)-Schritt. Im MPI-Schritt werden die Daten gleichmäßig auf die verfügbaren Knoten aufgeteilt. Der MPI-Schritt wird erst ausgeführt, wenn alle angeforderten Knoten bereit sind. Falls ein Knoten ausfällt oder vorzeitig entfernt wird (bei einem virtuellen Computer mit niedriger Priorität), muss der MPI-Schritt erneut ausgeführt werden.
Sicherheit
Sicherheit bietet Schutz vor vorsätzlichen Angriffen und dem Missbrauch Ihrer wertvollen Daten und Systeme. Weitere Informationen finden Sie unter Übersicht über die Säule „Sicherheit“. Dieser Abschnitt enthält Überlegungen zum Erstellen sicherer Lösungen.
Beschränken des Zugriffs auf Azure Blob Storage
In dieser Referenzarchitektur ist Azure Blob Storage die wichtigste Speicherkomponente, die geschützt werden muss. Die im GitHub-Repository angezeigte Baselinebereitstellung verwendet Speicherkontoschlüssel für den Zugriff auf Blob Storage. Für noch mehr Kontrolle und Schutz sollten Sie stattdessen Shared Access Signature (SAS) verwenden. Dadurch wird eingeschränkter Zugriff auf die gespeicherten Objekte gewährt, ohne dass die Kontoschlüssel hartcodiert oder im Klartext gespeichert werden müssen. Dieser Ansatz ist besonders nützlich, weil Kontoschlüssel im Klartext der Logik-App-Designerschnittstelle sichtbar sind. Mit SAS können Sie außerdem sicherstellen, dass das Speicherkonto über eine ordnungsgemäße Governance verfügt und der Zugriff nur ausgewählten Personen gewährt wird.
Stellen Sie in Szenarien mit sensibleren Daten sicher, dass alle Ihre Speicherschlüssel geschützt sind, weil diese Schlüssel den Vollzugriff auf alle Ein- und Ausgabedaten der Workload ermöglichen.
Datenverschlüsselung und Datenverschiebung
Diese Referenzarchitektur verwendet Stilübertragung als Beispiel für einen Batchbewertungsvorgang. Für Szenarien mit noch sensibleren Daten sollten die gespeicherten Daten im Ruhezustand verschlüsselt werden. Bei sämtlichen Datenübertragungen müssen die Daten mithilfe von Transport Layer Security (TLS) geschützt werden. Weitere Informationen finden Sie im Azure Storage-Sicherheitsleitfaden.
Schützen Ihres Berechnungsergebnisses in einem virtuellen Netzwerk
Beim Bereitstellen Ihres Machine Learning Compute-Clusters können Sie diesen so konfigurieren, dass er im Subnetz eines virtuellen Netzwerks bereitgestellt wird. Über dieses Subnetz können die Computerknoten im Cluster sicher mit anderen virtuellen Computern kommunizieren.
Schützen vor schädlichen Aktivitäten
Stellen Sie in Szenarien mit mehreren Benutzern sicher, dass sensible Daten vor schädlichen Aktivitäten geschützt sind. Wenn Sie anderen Benutzern Zugriff auf diese Bereitstellung gewähren, um die Eingabedaten anzupassen, beachten Sie die folgenden Vorsichtsmaßnahmen und Überlegungen:
- Verwenden Sie die rollenbasierte Zugriffssteuerung in Azure (RBAC), um den Zugriff von Benutzern auf die Ressourcen zu beschränken, die sie benötigen.
- Stellen Sie zwei separate Speicherkonten bereit. Speichern Sie Eingabe-und Ausgabedaten im ersten Konto. Externen Benutzern kann Zugriff auf dieses Konto gewährt werden. Speichern Sie ausführbare Skripts und ausgegebene Protokolldateien im anderen Konto. Externe Benutzer sollten keinen Zugriff auf dieses Konto haben. Durch diese Trennung wird sichergestellt, dass externe Benutzer keine ausführbaren Dateien ändern (um schädlichen Code einzufügen) und keinen Zugriff auf Protokolldateien haben, die eventuell vertrauliche Informationen enthalten.
- Böswillige Benutzer können einen DDoS-Angriff auf die Auftragswarteschlange durchführen oder ungültige, nicht verarbeitbare Nachrichten in die Auftragswarteschlange einfügen und dadurch Systemsperren und Fehler beim Entfernen aus der Warteschlange verursachen.
Kostenoptimierung
Bei der Kostenoptimierung geht es um die Suche nach Möglichkeiten, unnötige Ausgaben zu reduzieren und die Betriebseffizienz zu verbessern. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“.
Im Vergleich zu den Speicher- und Planungskomponenten fallen für die in dieser Referenzarchitektur verwendeten Computeressourcen bei Weitem die meisten Kosten an. Eine der größten Herausforderungen besteht darin, Aufträge über ein Cluster von GPU-fähigen VMs hinweg effektiv zu parallelisieren.
Die Größe des Azure Machine Learning Compute-Clusters kann je nach Auftrag in der Warteschlange automatisch hoch- und herunterskaliert werden. Sie können die automatische Skalierung programmgesteuert aktivieren, indem Sie die minimalen und maximalen Knoten festlegen.
Konfigurieren Sie für Aufträge, die nicht direkt verarbeitet werden müssen, die automatische Skalierung so, dass der Standardzustand (Minimum) ein Cluster mit null Knoten ist. Bei dieser Konfiguration hat der Cluster anfangs null Knoten. Er skaliert nur dann zentral hoch, wenn er Aufträge in der Warteschlange erkennt. Wenn die Batchbewertung maximal einige Male am Tag ausgeführt wird, erzielt diese Einstellung eine erhebliche Kosteneinsparung.
Die automatische Skalierung ist möglicherweise nicht für Batchaufträge geeignet, die zeitlich zu nahe beieinander liegen. Für die benötigte Zeit zum Erstellen und Entfernen eines Cluster fallen ebenfalls Kosten an. Das heißt, wenn eine Batchworkload nur wenige Minuten nach dem Ende des vorherigen Auftrags startet, ist es ggf. kostengünstiger den Cluster permanent, also auch zwischen den Aufträgen, auszuführen.
Azure Machine Learning Compute unterstützt auch virtuelle Computer mit niedriger Priorität. Auf diese Weise können Sie Ihre Berechnung auf virtuellen Computern ausführen, für die ein Rabatt gilt. Der Nachteil ist jedoch, dass diese jederzeit vorzeitig entfernt werden könnten. Virtuelle Computer mit niedriger Priorität sind für nicht kritische Batchbewertungsworkloads ideal geeignet.
Überwachen von Batchaufträgen
Beim Ausführen Ihres Auftrags ist es wichtig, den Fortschritt zu überwachen und zu überprüfen, dass der Auftrag wie erwartet funktioniert. Es kann jedoch eine Herausforderung sein, über einen Cluster von aktiven Knoten hinweg zu überwachen.
Um den Gesamtzustand des Clusters zu überprüfen, können Sie im Azure-Portal zum Machine Learning Service navigieren und den Zustand der Knoten im Cluster überprüfen. Wenn ein Knoten inaktiv oder ein Auftrag fehlerhaft ist, werden die Fehlerprotokolle in Blob Storage gespeichert und sind auch im Azure-Portal verfügbar.
Die Überwachung kann durch das Verbinden von Protokollen mit Application Insights oder durch das Ausführen separater Prozesse zum Abrufen des Zustands des Clusters und seiner Aufträge verbessert werden.
Protokolle mit Azure Machine Learning
Azure Machine Learning protokolliert automatisch alle stdout/stderr-Ereignisse im entsprechenden Blob Storage-Konto. Sofern nicht anders angegeben, stellt Ihr Azure Machine Learning-Arbeitsbereich automatisch ein Speicherkonto bereit und legt darin eine Sicherung Ihrer Protokolle an. Sie können auch ein Speichernavigationstool wie Azure Storage-Explorer verwenden. Diese Methode vereinfacht das Navigieren in Protokolldateien.
Bereitstellen dieses Szenarios
Befolgen Sie die Schritte im GitHub-Repository, um diese Referenzarchitektur bereitzustellen.
Sie können auch eine Batchbewertungsarchitektur für Deep Learning-Modelle bereitstellen, indem Sie den Azure Kubernetes Service verwenden. Führen Sie die in diesem GitHub-Repository beschriebenen Schritte aus.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Jian Tang | Program Manager II
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Batchbewertung von Spark-Modellen in Azure Databricks
- Batchbewertung von Python-Modellen in Azure
- Batchbewertung mit R-Modellen zur Vorhersage des Umsatzes