Diese Referenzarchitektur bietet Strategien für das Partitionierungsmodell, das von Ereigniserfassungsdiensten verwendet wird. Da Ereigniserfassungsdienste Lösungen für das hochskalierbare Ereignisstreaming bereitstellen, müssen sie Ereignisse parallel verarbeiten und die Ereignisreihenfolge beibehalten können. Außerdem müssen Sie einen Lastenausgleich ausführen und die Skalierbarkeit gewährleisten. Partitionierungsmodelle erfüllen alle diese Anforderungen.
Aufbau

In der Mitte des Diagramms befindet sich ein Feld für den Kafka-Cluster oder Event Hub-Namespace. In diesem Feld befinden sich drei kleinere Felder. Jedes ist mit „Topic“ (Thema) oder „Event Hub“ bezeichnet und enthält mehrere Rechtecke mit der Bezeichnung „Partition“. Oberhalb des Hauptfelds sind Rechtecke mit „Producer“ bezeichnet. Pfeile zeigen von den Producern zum Hauptfeld. Unter dem Hauptfeld sind Rechtecke mit „Consumer“ bezeichnet. Pfeile mit verschiedenen Offsetwerten zeigen vom Hauptfeld zu den Consumern. Ein einzelner blauer Rahmen mit der Bezeichnung „Consumer Group“ (Consumergruppe) schließt zwei der Consumer ein und fasst diese in einer Gruppe zusammen.
Laden Sie eine Visio-Datei dieser Architektur herunter.
Datenfluss
Producer veröffentlichen Daten im Erfassungsdienst oder der Pipeline. Event Hubs-Pipelines bestehen aus Namespaces. Die Kafka-Entsprechungen sind Cluster.
Die Pipeline verteilt die eingehenden Ereignisse auf Partitionen. Innerhalb jeder Partition behalten die Ereignisse die Reihenfolge ihrer Generierung bei. Die Ereignisse bleiben zwischen den Partitionen jedoch nicht in ihrer ursprünglichen Reihenfolge. Die Anzahl der Partitionen kann sich auf den Durchsatz oder die Menge der Daten auswirken, die das System innerhalb eines festgelegten Zeitraums durchlaufen. Pipelines messen den Durchsatz in der Regel in Bits pro Sekunde (Bit/s) und manchmal in Datenpaketen pro Sekunde (P/s).
Partitionen befinden sich in benannten Datenströmen von Ereignissen. In Event Hubs werden diese Datenströme als Event Hubs bezeichnet. In Kafka heißen sie Themen.
Consumer sind Prozesse oder Anwendungen, die Themen abonnieren. Jeder Consumer liest eine bestimmte Teilmenge des Ereignisdatenstroms. Diese Teilmenge kann mehrere Partitionen umfassen. Allerdings kann die Pipeline jede Partition jeweils nur einem Consumer pro Consumergruppe zuweisen.
Mehrere Consumer können eine Consumergruppe bilden. Wenn eine Gruppe ein Thema abonniert, erhält jeder Consumer in der Gruppe eine separate Ansicht des Ereignisdatenstroms. Die Anwendungen arbeiten unabhängig voneinander und in ihrem eigenen Tempo. Die Pipeline kann die Consumergruppen auch für die Lastverteilung nutzen.
Consumer verarbeiten den Feed der veröffentlichten Ereignisse, die sie abonniert haben. Außerdem wenden Consumer auch Prüfpunkte an. Dadurch können Abonnenten Offsets nutzen, um ihre Position innerhalb einer Partitionsereignissequenz zu kennzeichnen. Ein Offset ist ein Platzhalter, der wie ein Lesezeichen funktioniert. Er kennzeichnet das letzte Ereignis, das der Consumer gelesen hat.
Szenariodetails
In diesem Dokument werden insbesondere die folgenden Strategien erläutert:
- Zuweisen von Ereignissen zu Partitionen
- Bestimmen der Anzahl der zu verwendenden Partitionen
- Zuweisen von Partitionen zu Abonnenten bei einer Umverteilung
Es gibt zahlreiche Technologien zur Erfassung von Ereignissen, einschließlich:
- Azure Event Hubs: Eine vollständig verwaltete Big Data-Streamingplattform
- Apache Kafka: Eine Open-Source-Plattform zur Datenstromverarbeitung
- Event Hubs mit Kafka: Eine Alternative zum Ausführen eines eigenen Kafka-Clusters. Dieses Event Hubs-Feature bietet einen Endpunkt, der mit den Kafka-APIs kompatibel ist.
Neben Partitionierungsstrategien werden in diesem Dokument auch die Unterschiede zwischen der Partitionierung in Event Hubs und Kafka veranschaulicht.
Empfehlungen
Beachten Sie bei der Entwicklung einer Partitionierungsstrategie die folgenden Empfehlungen.
Verteilen der Ereignisse auf Partitionen
Ein Aspekt jeder Partitionierungsstrategie ist die Zuweisungsrichtlinie. Ein Ereignis, das bei einem Erfassungsdienst eingeht, wird einer Partition zugewiesen. Diese Partition wird durch die Zuweisungsrichtlinie festgelegt.
Jedes Ereignis speichert seinen Inhalt im eigenen Wert. Neben dem Wert enthält jedes Ereignis auch einen Schlüssel, wie im folgenden Diagramm gezeigt:

In der Mitte des Diagramms sehen Sie mehrere Feldpaare. Eine Bezeichnung unter den Feldern zeigt an, dass jedes Paar eine Meldung darstellt. Jede Meldung enthält ein blaues Feld mit der Bezeichnung „Key“ (Schlüssel) und ein schwarzes Feld mit der Bezeichnung „Value“ (Wert). Die Meldungen sind horizontal angeordnet. Pfeile zwischen den Meldungen, die von links nach rechts zeigen, verdeutlichen, dass die Meldungen eine Sequenz bilden. Oberhalb der Meldungen steht die Bezeichnung „Stream“ (Datenstrom). Die Klammern zeigen an, dass die Sequenz einen Datenstrom bildet.
Laden Sie eine Visio-Datei dieser Architektur herunter.
Der Schlüssel enthält Daten über das Ereignis und kann auch für die Zuweisungsrichtlinie verwendet werden.
Es gibt verschiedene Ansätze für das Zuweisen von Ereignissen zu Partitionen:
- Standardmäßig verteilen Dienste die Ereignisse im Roundrobin-Prinzip auf Partitionen.
- Producer können für ein Ereignis auch eine Partitions-ID angeben. Das Ereignis wird dann der Partition mit dieser ID zugewiesen.
- Producer können einen Wert für den Ereignisschlüssel bereitstellen. In diesem Fall bestimmt ein hashbasierter Partitionierer einen Hashwert aus dem Schlüssel. Das Ereignis wird dann der Partition mit diesem Hashwert zugewiesen.
Beachten Sie bei der Auswahl einer Zuweisungsrichtlinie die folgenden Empfehlungen:
- Verwenden Sie Partitions-IDs, wenn die Consumer nur bestimmte Ereignisse erhalten sollen. Wenn diese Ereignisse nur an eine Partition weitergeleitet werden, kann der Consumer sie problemlos durch Abonnieren dieser Partition empfangen.
- Verwenden Sie Schlüssel, wenn Consumer die Ereignisse in der Reihenfolge ihrer Generierung empfangen müssen. Da alle Ereignisse mit demselben Schlüssel auch derselben Partition zugewiesen werden, kann mithilfe von Schlüsselwerten auch während der Verarbeitung die Reihenfolge der Ereignisse beibehalten werden. Die Consumer erhalten sie dann in dieser Reihenfolge.
- Wenn bei Kafka keine Ereignisgruppierung oder -reihenfolge erforderlich ist, sollten Sie keine Schlüssel verwenden. Der Producer kennt den Status der Zielpartition in Kafka nicht. Wenn ein Schlüssel ein Ereignis an eine Partition weiterleitet, die offline ist, kann dies zu Verzögerungen oder dem Verlust von Ereignissen führen. In Event Hubs passieren Ereignisse mit Schlüsseln zunächst ein Gateway, bevor sie an eine Partition weitergeleitet werden. Damit wird verhindert, dass Ereignisse an nicht verfügbare Partitionen weitergeleitet werden.
- Die Form der Daten kann Einfluss auf den Partitionierungsansatz haben. Berücksichtigen Sie bei der Auswahl der Zuweisung, wie die Downstreamarchitektur die Daten verteilt.
- Wenn Consumer Daten nach einem bestimmten Attribut aggregieren, sollten Sie dieses Attribut auch für die Partitionierung verwenden.
- Wenn eine effiziente Speicherung wichtig ist, partitionieren Sie nach einem Attribut, das die Daten berücksichtigt, um Speichervorgänge zu beschleunigen.
- Erfassungspipelines führen manchmal eine horizontale Partitionierung der Daten durch, um Probleme mit Ressourcenengpässen zu umgehen. Passen Sie in solchen Umgebungen die Partitionierung an die Aufteilung der Shards in der Datenbank an.
Bestimmen der Anzahl von Partitionen
Wenden Sie beim Festlegen der Anzahl der zu verwendenden Partitionen die folgenden Richtlinien an:
- Verwenden Sie mehr Partitionen, um einen höheren Durchsatz zu erzielen. Jeder Consumer liest aus der ihm zugewiesenen Partition. Wenn Sie also mehr Partitionen haben, können mehr Consumer gleichzeitig Ereignisse eines Themas empfangen.
- Verwenden Sie mindestens so viele Partitionen wie Ihr Zieldurchsatz in Megabyte beträgt.
- Um ungenutzte Consumer zu vermeiden, verwenden Sie mindestens so viele Partitionen wie Consumer. Nehmen Sie beispielsweise an, dass acht Consumern acht Partitionen zugewiesen wurden. Alle weiteren Consumer, die Ereignisse abonnieren, müssen warten. Alternativ dazu können Sie einen oder zwei Consumer in Wartestellung halten, damit sie Ereignisse empfangen, wenn ein vorhandener Consumer ausfällt.
- Verwenden Sie mehr Schlüssel als Partitionen. Andernfalls empfangen einige Partitionen keine Ereignisse, sodass die Partitionsauslastung unausgeglichen ist.
- In Kafka und Event Hubs können Sie auf der Dienstebene „Dedicated“ die Anzahl der Partitionen in einem Betriebssystem ändern. Vermeiden Sie diese Anpassung jedoch, wenn Sie Schlüssel nutzen, um die Ereignisreihenfolge beizubehalten. Dazu gehören die folgende Gründe:
- Consumer verlassen sich auf bestimmte Partitionen und die Reihenfolge der empfangenen Ereignisse.
- Wenn die Anzahl der Partitionen geändert wird, kann sich auch die Zuordnung der Ereignisse zu Partitionen ändern. Wenn sich beispielsweise die Anzahl der Partitionen ändert, kann folgende Formel zu einer geänderten Zuweisung führen:
partition assignment = hash key % number of partitions - Kafka und Event Hubs versuchen nicht, Ereignisse, die vor dem Mischen eingehen, neu zu verteilen. Daher kann nicht mehr garantiert werden, dass Ereignisse in der Reihenfolge ihrer Veröffentlichung bei einer bestimmten Partition eintreffen.
Neben diesen Richtlinien können Sie für die Bestimmung der Anzahl der Partitionen auch diese grobe Formel verwenden:
max(t/p, t/c)
Sie verwendet die folgenden Werte:
t: Der Zieldurchsatzp: Der Produktionsdurchsatz einer einzelnen Partitionc: Der Verbrauchsdurchsatz einer einzelnen Partition
Stellen Sie sich z. B. folgende Situation vor:
- Der ideale Durchsatz beträgt 2 MBit/s. Für die Formel hat
tden Wert 2 MBit/s. - Ein Producer sendet Ereignisse mit einer Rate von 1.000 Ereignissen pro Sekunde,
pbeträgt also 1 MBit/s. - Ein Consumer empfängt Ereignisse mit einer Rate von 500 Ereignissen pro Sekunde, sodass
cden Wert 0,5 MBit/s annimmt.
Bei diesen Werten beträgt die Anzahl der Partitionen 4:
max(t/p, t/c) = max(2/1, 2/0.5) = max(2, 4) = 4
Beachten Sie beim Messen des Durchsatzes Folgendes:
Der langsamste Consumer bestimmt den Verbrauchsdurchsatz. Manchmal sind jedoch keine Informationen zu Downstreamanwendungen von Consumern verfügbar. In diesem Fall schätzen Sie den Durchsatz, indem Sie mit einer Partition als Baseline beginnen. (Verwenden Sie dieses Setup nur in Testumgebungen, nicht für Produktionssysteme). Mit Event Hubs im Tarif „Standard“ mit einer Partition sollten Sie einen Durchsatz zwischen 1 MBit/s und 20 MBit/s erzielen.
Consumer können Ereignisse aus einer Erfassungspipeline nur dann mit einer hohen Rate nutzen, wenn die Producer die Ereignisse auch mit einer vergleichbaren Rate senden. Um die erforderliche Gesamtkapazität der Erfassungspipeline zu ermitteln, messen Sie den Durchsatz des Producers (nicht nur den des Consumers).
Zuweisen von Partitionen zu Consumern bei einer Umverteilung
Wenn Consumer ein Abonnement einrichten oder kündigen, passt die Pipeline die Zuweisung von Partitionen zu Consumern an. Standardmäßig verwenden Event Hubs und Kafka einen Roundrobin-Ansatz für die Umverteilung. Dabei werden die Partitionen gleichmäßig auf die Mitglieder verteilt.
Wenn Sie bei Kafka nicht möchten, dass die Pipeline die Zuweisungen automatisch umverteilt, können Sie den Consumern Partitionen statisch zuweisen. Sie müssen jedoch sicherstellen, dass alle Partitionen über Abonnenten verfügen und dass ein Lastenausgleich erfolgt.
Neben der standardmäßigen Roundrobin-Strategie bietet Kafka zwei weitere Strategien für die automatische Umverteilung:
- Bereichszuweisungen: Verwenden Sie diesen Ansatz, um Partitionen aus verschiedenen Themen zusammenzuführen. Bei dieser Form der Zuweisung werden Themen identifiziert, die dieselbe Anzahl von Partitionen und dieselbe Partitionierungslogik anhand von Schlüsseln verwenden. Anschließend werden die Partitionen aus diesen Themen bei den Zuweisungen zu Consumern zusammengeführt.
- Feste Zuweisung: Wenden Sie diese Zuweisungsform an, um die Wechsel zwischen Partitionen zu minimieren. Wie beim Roundrobin-Ansatz sorgt diese Strategie für eine einheitliche Verteilung. Allerdings werden während der Umverteilung auch die vorhandenen Zuweisungen beibehalten.
Überlegungen
Beachten Sie bei der Verwendung eines Partitionierungsmodells die folgenden Punkte.
Skalierbarkeit
Die Verwendung einer großen Anzahl von Partitionen kann die Skalierbarkeit einschränken:
In Kafka speichern Broker Ereignisdaten und Offsets in Dateien. Je mehr Partitionen Sie verwenden, desto größer ist auch die Anzahl geöffneter Dateihandles. Wenn das Betriebssystem die Anzahl geöffneter Dateien einschränkt, müssen Sie diese Einstellung möglicherweise neu konfigurieren.
In Event Hubs gelten für die Benutzer keine Dateisystemeinschränkungen. Jede Partition verwaltet jedoch ihre eigenen Azure-Blobdateien und optimiert sie im Hintergrund. Bei einer großen Anzahl von Partitionen ist die Verwaltung der Prüfpunktdaten sehr aufwendig. Der Grund hierfür ist, dass E/A-Vorgänge zeitaufwendig sein können und dass sich die Aufrufe der Storage-API proportional zur Anzahl der Partitionen verhalten.
Jeder Producer für Kafka und Event Hubs speichert Ereignisse in einem Puffer, bis ein Batch einer bestimmten Größe verfügbar ist oder bis eine bestimmte Zeit verstrichen ist. Erst dann sendet der Producer die Ereignisse an die Erfassungspipeline. Der Producer verwaltet für jede Partition einen Puffer. Nimmt die Anzahl der Partitionen zu, steigen auch die Arbeitsspeicheranforderungen des Clients. Wenn Consumer Ereignisse in Batches empfangen, kann bei ihnen dasselbe Problem auftreten. Abonnieren Consumer eine große Anzahl von Partitionen, während ihnen aber nur begrenzt Arbeitsspeicher für die Pufferung zur Verfügung steht, können Probleme auftreten.
Verfügbarkeit
Eine große Anzahl von Partitionen kann sich auch auf die Verfügbarkeit negativ auswirken:
Kafka positioniert Partitionen in der Regel in unterschiedlichen Brokern. Wenn ein Broker ausfällt, verteilt Kafka die Partitionen um, damit keine Ereignisse verloren gehen. Je mehr Partitionen umverteilt werden müssen, desto länger dauert das Failover. Dies kann die Verfügbarkeit beeinträchtigen. Begrenzen Sie die Anzahl der Partitionen auf eine niedrige vierstellige Zahl, um dieses Problem zu vermeiden.
Je mehr Partitionen Sie verwenden, desto mehr physische Ressourcen werden in Betrieb genommen. Abhängig von der Clientantwort können dann auch mehr Fehler auftreten.
Bei mehr Partitionen muss der Lastenausgleichsprozess mehr Komponenten koordinieren und hat damit mehr Arbeit. Vorübergehende Ausnahmen können die Folge sein. Diese Fehler können bei temporären Störungen auftreten, z. B. Netzwerkproblemen oder zeitweiligen Ausfällen des Internetdiensts. Sie können auch während eines Upgrades oder Lastenausgleichs auftreten, bei dem Event Hubs manchmal Partitionen auf andere Knoten verschiebt. Sie können dieses vorübergehende Verhalten behandeln, indem Sie Wiederholungsversuche einschließen, um Ausfälle zu minimieren. Nutzen Sie den EventProcessorClient in .NET und Java-SDKs oder den EventHubConsumerClient in Python und JavaScript-SDKs, um diesen Prozess zu vereinfachen.
Leistung
In Kafka werden Ereignisse committet, nachdem sie von der Pipeline in allen in die Synchronisierung eingeschlossenen Replikaten repliziert wurden. Dieser Ansatz sorgt für Hochverfügbarkeit von Ereignissen. Da Consumer nur committete Ereignisse empfangen, erhöht der Replikationsprozess die Latenz. In Erfassungspipelines bezieht sich dieser Begriff auf die Zeit zwischen dem Veröffentlichen eines Ereignisses durch einen Producer und dem Lesen durch einen Consumer. Aus Experimenten von Confluent ging hervor, dass das Replizieren von 1.000 Partitionen von einem Broker zu einem anderen ungefähr 20 Millisekunden dauern kann. Die Gesamtlatenz beträgt dann mindestens 20 Millisekunden. Wenn sich die Anzahl der Partitionen weiter erhöht, steigt auch die Latenz. Dieser Nachteil trifft auf Event Hubs nicht zu.
Sicherheit
In Event Hubs verwenden Producer ein SAS-Token (Shared Access Signature), um sich selbst zu identifizieren. Consumer stellen eine Verbindung über eine AMQP 1.0-Sitzung her. Dieser zustandsbehaftete bidirektionale Kommunikationskanal ermöglicht eine sichere Übertragung der Meldungen. Kafka bietet auch Features zum Verschlüsseln, Autorisieren und Authentifizieren, die Sie jedoch selbst implementieren müssen.
Bereitstellen dieses Szenarios
Die folgenden Codebeispiele veranschaulichen das Verwalten des Durchsatzes, das Verteilen an eine bestimmte Partition und das Beibehalten der Ereignisreihenfolge.
Verwalten des Durchsatzes
Dieses Beispiel umfasst eine Protokollaggregation. Ziel ist nicht, die Ereignisse in der richtigen Reihenfolge zu verarbeiten, sondern einen bestimmten Durchsatz zu erzielen.
Ein Kafka-Client implementiert die Producer- und Consumermethoden. Da die Reihenfolge nicht wichtig ist, sendet der Code keine Meldungen an bestimmte Partitionen. Stattdessen wird die Standardzuweisung der Partitionen verwendet:
public static void RunProducer(string broker, string connectionString, string topic)
{
// Set the configuration values of the producer.
var producerConfig = new ProducerConfig
{
BootstrapServers = broker,
SecurityProtocol = SecurityProtocol.SaslSsl,
SaslMechanism = SaslMechanism.Plain,
SaslUsername = "$ConnectionString",
SaslPassword = connectionString,
};
// Set the message key to Null since the code does not use it.
using (var p = new ProducerBuilder<Null, string>(producerConfig).Build())
{
try
{
// Send a fixed number of messages. Use the Produce method to generate
// many messages in rapid succession instead of the ProduceAsync method.
for (int i=0; i < NumOfMessages; i++)
{
string value = "message-" + i;
Console.WriteLine($"Sending message with key: not-specified," +
$"value: {value}, partition-id: not-specified");
p.Produce(topic, new Message<Null, string> { Value = value });
}
// Wait up to 10 seconds for any in-flight messages to be sent.
p.Flush(TimeSpan.FromSeconds(10));
}
catch (ProduceException<Null, string> e)
{
Console.WriteLine($"Delivery failed with error: {e.Error.Reason}");
}
}
}
public static void RunConsumer(string broker, string connectionString, string consumerGroup, string topic)
{
var consumerConfig = new ConsumerConfig
{
BootstrapServers = broker,
SecurityProtocol = SecurityProtocol.SaslSsl,
SocketTimeoutMs = 60000,
SessionTimeoutMs = 30000,
SaslMechanism = SaslMechanism.Plain,
SaslUsername = "$ConnectionString",
SaslPassword = connectionString,
GroupId = consumerGroup,
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var c = new ConsumerBuilder<string, string>(consumerConfig).Build())
{
c.Subscribe(topic);
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (_, e) =>
{
e.Cancel = true;
cts.Cancel();
};
try
{
while (true)
{
try
{
var message = c.Consume(cts.Token);
Console.WriteLine($"Consumed - key: {message.Message.Key}, "+
$"value: {message.Message.Value}, " +
$"partition-id: {message.Partition}," +
$"offset: {message.Offset}");
}
catch (ConsumeException e)
{
Console.WriteLine($"Error occured: {e.Error.Reason}");
}
}
}
catch(OperationCanceledException)
{
// Close the consumer to ensure that it leaves the group cleanly
// and that final offsets are committed.
c.Close();
}
}
}
Dieses Codebeispiel generiert folgende Ergebnisse:
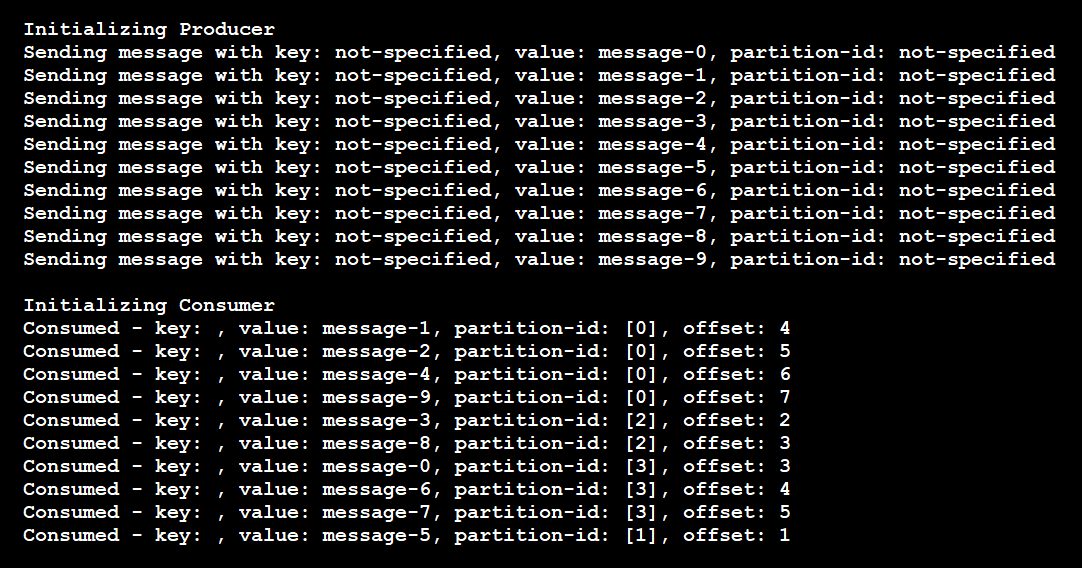
In diesem Fall umfasst das Thema vier Partitionen. Die folgenden Ereignisse sind eingetreten:
- Der Producer sendete 10 Meldungen, jeweils ohne Partitionsschlüssel.
- Die Meldungen sind in zufälliger Reihenfolge bei den Partitionen eingetroffen.
- Ein einzelner Consumer hat an allen vier Partitionen gelauscht und die Meldungen in unbestimmter Reihenfolge empfangen.
Wenn im Code zwei Instanzen des Consumers verwendet worden wären, hätte jede Instanz zwei der vier Partitionen abonniert.
Verteilen an eine bestimmte Partition
Dieses Beispiel umfasst Fehlermeldungen. Angenommen, bestimmte Anwendungen müssen Fehlermeldungen verarbeiten, während alle anderen Nachrichten an einen gemeinsamen Consumer weitergeleitet werden können. In diesem Fall sendet der Producer Fehlermeldungen an eine bestimmte Partition. Consumer, die Fehlermeldungen empfangen sollen, lauschen an dieser Partition. Im folgenden Codebeispiel wird die Implementierung dieses Szenarios veranschaulicht:
// Producer code.
var topicPartition = new TopicPartition(topic, partition);
...
p.Produce(topicPartition, new Message<Null, string> { Value = value });
// Consumer code.
// Subscribe to one partition.
c.Assign(new TopicPartition(topic, partition));
// Use this code to subscribe to a list of partitions.
c.Assign(new List<TopicPartition> {
new TopicPartition(topic, partition1),
new TopicPartition(topic, partition2)
});
Wie die Ergebnisse zeigen, sendet der Producer alle Meldungen an Partition 2, und der Consumer liest nur Meldungen aus Partition 2:
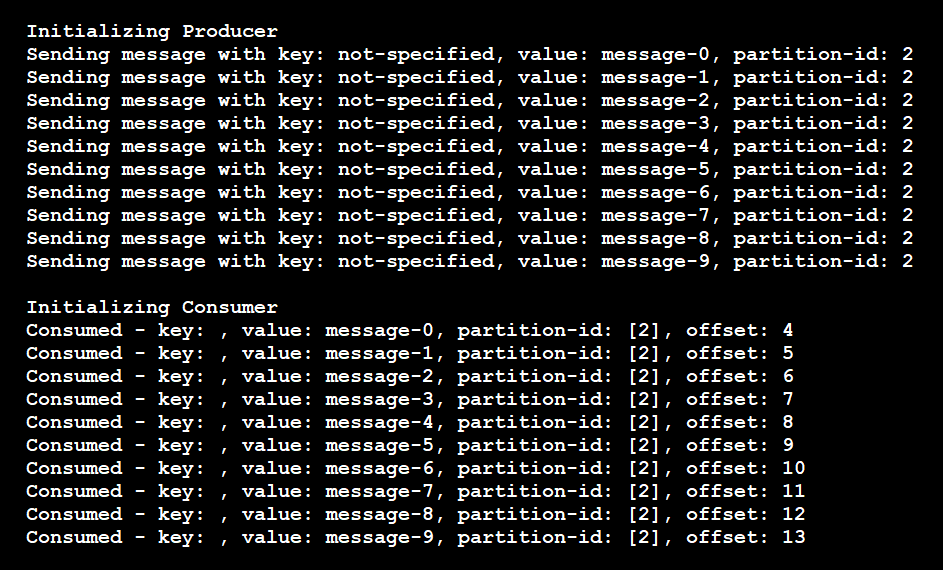
Wenn Sie in diesem Szenario eine weitere Consumerinstanz zum Lauschen auf dieses Thema hinzufügen, weist die Pipeline dieser keine Partitionen zu. Der neue Consumer bleibt so lange im Leerlauf, bis der vorhandene Consumer heruntergefahren wird. Die Pipeline weist dann einen anderen aktiven Consumer zu, der aus der Partition liest. Diese Zuweisung wird von der Pipeline jedoch nur dann vorgenommen, wenn der neue Consumer keiner anderen Partition zugeordnet ist.
Beibehalten der Ereignisreihenfolge
Dieses Beispiel zeigt Banktransaktionen, die von einem Consumer in der richtigen Reihenfolge verarbeitet werden müssen. In diesem Szenario können Sie die Kunden-ID jedes Ereignisses als Schlüssel verwenden. Verwenden Sie für den Ereigniswert die Details der Transaktion. Im folgenden Codebeispiel wird eine vereinfachte Implementierung dieses Falls veranschaulicht:
Producer code
// This code assigns the key an integer value. You can also assign it any other valid key value.
using (var p = new ProducerBuilder<int, string>(producerConfig).Build())
...
p.Produce(topic, new Message<int, string> { Key = i % 2, Value = value });
Der Code führt zu folgenden Ergebnissen:
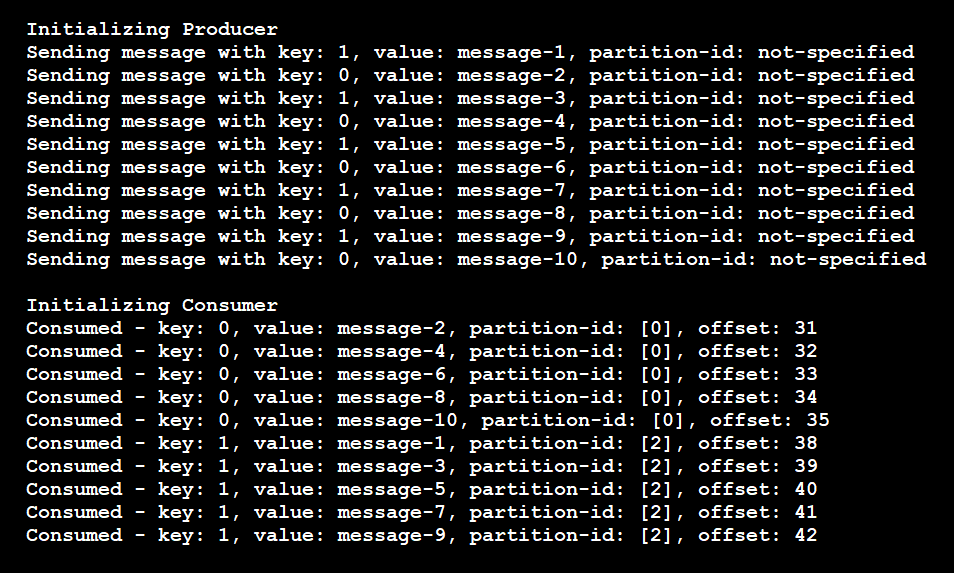
Aus den Ergebnissen wird deutlich, dass der Producer nur zwei eindeutige Schlüssel verwendet hat. Die Meldungen wurden dann nur an zwei Partitionen und nicht an alle vier Partitionen weitergeleitet. Die Pipeline stellt sicher, dass Meldungen mit demselben Schlüssel immer an dieselbe Partition gesendet werden.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Rajasa Savant | Senior Software Engineer
Melden Sie sich bei LinkedIn an, um nicht öffentliche LinkedIn-Profile anzuzeigen.
Nächste Schritte
- Verwenden von Azure Event Hubs aus Apache Kafka-Anwendungen
- Apache Kafka-Entwicklerleitfaden für Azure Event Hubs
- Schnellstart: Datenstreaming mit Event Hubs mithilfe des Kafka-Protokolls
- Senden oder Empfangen von Ereignissen an und von Azure Event Hubs: .NET (Azure.Messaging.EventHubs)
- Ausgleichen der Partitionsauslastung über mehrere Instanzen der Anwendung hinweg
- Dynamisches Hinzufügen von Partitionen zu einem Event Hub (Apache Kafka-Thema) in Azure Event Hubs
- Verfügbarkeit und Konsistenz in Event Hubs
- Azure Event Hubs-Clientbibliothek für die Ereignisverarbeitung für .NET
- Effective Strategies for Kafka Topic Partitioning (Effektive Strategien für die Partitionierung von Kafka-Themen)
- Blogbeitrag von Confluent: „How to choose the number of topics/partitions in a Kafka cluster?“ (Auswählen der Anzahl von Themen/Partitionen in einem Kafka-Cluster)
Zugehörige Ressourcen
- Integrieren von Event Hubs in serverlose Funktionen in Azure
- Leistung und Skalierung für Event Hubs und Azure Functions
- Ereignisgesteuerter Architekturstil
- Streamverarbeitung mit vollständig verwalteten Open-Source-Daten-Engines
- Herausgeber-Abonnent-Muster
- Apache-Open-Source-Szenarien in Azure – Apache Kafka