Diagnose in Durable Functions in Azure
Es gibt mehrere Möglichkeiten, um Probleme mithilfe von Durable Functions zu diagnostizieren. Einige dieser Optionen sind für reguläre Funktionen identisch, und andere gelten nur für Durable Functions.
Application Insights
Es wird empfohlen, Application Insights zum Durchführen der Diagnose und Überwachung in Azure Functions zu verwenden. Dasselbe gilt für Durable Functions. Eine Übersicht darüber, wie Sie Application Insights in Ihrer Funktionen-App nutzen, finden Sie unter Überwachen von Azure Functions.
Die Erweiterung „Durable Functions“ von Azure Functions gibt auch Nachverfolgungsereignisse aus, mit denen Sie die End-to-End-Ausführung einer Orchestrierung verfolgen können. Diese Nachverfolgungsereignisse können Sie ermitteln und abfragen, indem Sie im Azure-Portal das Tool Application Insights Analytics verwenden.
Nachverfolgungsdaten
Jedes Lebenszyklusereignis einer Orchestrierungsinstanz bewirkt, dass in Application Insights ein Nachverfolgungsereignis in die Sammlung traces geschrieben wird. Dieses Ereignis enthält die Nutzlast customDimensions mit mehreren Feldern. Feldnamen wird immer prop__ vorangestellt.
- hubName: Der Name des Aufgabenhubs, unter dem Ihre Orchestrierungen ausgeführt werden.
- appName: Der Name der Funktions-App Dieses Feld ist nützlich, wenn mehrere Funktions-Apps dieselbe Application Insights-Instanz gemeinsam nutzen.
- slotName: Der Bereitstellungsslot, in dem die aktuelle Funktions-App ausgeführt wird. Dieses Feld ist nützlich, wenn Sie Bereitstellungsslots nutzen, um Ihre Orchestrierungen mit einer Version zu versehen.
- functionName: Der Name der Orchestrator- oder Aktivitätsfunktion.
- functionType: Der Typ der Funktion, z. B. Orchestrator oder Activity.
- instanceId: Die eindeutige ID der Orchestrierungsinstanz.
- state: Der Lebenszyklus-Ausführungsstatus der Instanz. Gültige Werte:
- Scheduled: Die Ausführung der Funktion wurde geplant, aber noch nicht gestartet.
- Started: Die Ausführung der Funktion wurde gestartet, sie wurde aber noch nicht erwartet oder abgeschlossen.
- Awaited: Der Orchestrator hat Arbeit geplant und wartet darauf, dass sie abgeschlossen wird.
- Listening: Der Orchestrator lauscht auf eine externe Ereignisbenachrichtigung.
- Completed: Die Funktion wurde erfolgreich abgeschlossen.
- Fehler: Bei der Funktion ist ein Fehler aufgetreten.
- reason: Zusätzliche Daten zum Nachverfolgungsereignis. Wenn eine Instanz beispielsweise auf eine externe Ereignisbenachrichtigung wartet, wird in diesem Feld der Name des Ereignisses angegeben, auf das gewartet wird. Wenn eine Funktion fehlgeschlagen ist, enthält dieses Feld die Fehlerdetails.
- isReplay: Ein boolescher Wert, der angibt, ob das Nachverfolgungsereignis für die wiedergegebene Ausführung bestimmt ist.
- extensionVersion: Die Version der Durable Task-Erweiterung. Diese Versionsinformationen sind besonders wichtig, wenn mögliche Fehler der Erweiterung gemeldet werden. Instanzen mit langer Ausführungsdauer melden unter Umständen mehrere Versionen, wenn während der Ausführung ein Update durchgeführt wird.
- sequenceNumber: Die Ausführungssequenznummer für ein Ereignis. In Kombination mit dem Zeitstempel können die Ereignisse dadurch nach Ausführungszeit sortiert werden. Beachten Sie, dass diese Zahl auf null zurückgesetzt wird, wenn der Host neu gestartet wird, während die Instanz ausgeführt wird. Daher ist es wichtig, immer zuerst nach dem Zeitstempel zu sortieren, dann nach „sequenceNumber“.
Der Ausführlichkeitsgrad der Nachverfolgungsdaten, die an Application Insights ausgegeben werden, kann im Abschnitt logger (Functions 1.x) oder logging (Functions 2.0) der Datei host.json konfiguriert werden.
Functions 1.0
{
"logger": {
"categoryFilter": {
"categoryLevels": {
"Host.Triggers.DurableTask": "Information"
}
}
}
}
Functions 2.0
{
"logging": {
"logLevel": {
"Host.Triggers.DurableTask": "Information",
},
}
}
Standardmäßig werden alle ohne Wiedergabe definierten Nachverfolgungsereignisse ausgegeben. Die Datenmenge kann reduziert werden, indem Host.Triggers.DurableTask auf "Warning" oder "Error" festgelegt wird. In diesem Fall werden Nachverfolgungsereignisse nur für außergewöhnliche Situationen ausgegeben. Zum Aktivieren der Ausgabe der Wiedergabeereignisse mit ausführlicher Orchestrierung legen Sie logReplayEvents in der Konfigurationsdatei host.json auf true fest.
Hinweis
Standardmäßig werden für die Application Insights-Telemetriedaten von der Azure Functions-Laufzeit Stichproben erstellt, um zu verhindern, dass Daten zu häufig ausgegeben werden. Dies kann dazu führen, dass Nachverfolgungsinformationen verloren gehen, wenn viele Lebenszyklusereignisse in kurzer Zeit auftreten. Im Artikel zur Azure Functions-Überwachung wird beschrieben, wie Sie dieses Verhalten konfigurieren.
Eingaben und Ausgaben von Orchestrator-, Aktivitäts- und Entitätsfunktionen werden standardmäßig nicht protokolliert. Dieses Standardverhalten wird empfohlen, da die Protokollierung von Eingaben und Ausgaben die Application Insights-Kosten erhöhen kann. Eingabe- und Ausgabenutzdaten von Funktionen können außerdem vertrauliche Informationen enthalten. Anstelle der tatsächlichen Nutzdaten wird stattdessen die Anzahl von Bytes für Funktionseingaben und -ausgaben protokolliert. Wenn von der Durable Functions-Erweiterung die vollständigen Eingabe- und Ausgabenutzdaten protokolliert werden sollen, legen Sie die Eigenschaft traceInputsAndOutputs in der Konfigurationsdatei host.json auf true fest.
Abfrage für einzelne Instanzen
Mit der folgenden Abfrage werden Verlaufsdaten für die Nachverfolgung einer Einzelinstanz der Hello Sequence-Funktionsorchestrierung angezeigt. Es ist mit der Kusto-Abfragesprache geschrieben. Die Wiedergabeausführung wird herausgefiltert, sodass nur der logische Ausführungspfad angezeigt wird. Ereignisse können angeordnet werden, indem nach timestamp und sequenceNumber sortiert wird, wie in der folgenden Abfrage gezeigt:
let targetInstanceId = "ddd1aaa685034059b545eb004b15d4eb";
let start = datetime(2018-03-25T09:20:00);
traces
| where timestamp > start and timestamp < start + 30m
| where customDimensions.Category == "Host.Triggers.DurableTask"
| extend functionName = customDimensions["prop__functionName"]
| extend instanceId = customDimensions["prop__instanceId"]
| extend state = customDimensions["prop__state"]
| extend isReplay = tobool(tolower(customDimensions["prop__isReplay"]))
| extend sequenceNumber = tolong(customDimensions["prop__sequenceNumber"])
| where isReplay != true
| where instanceId == targetInstanceId
| sort by timestamp asc, sequenceNumber asc
| project timestamp, functionName, state, instanceId, sequenceNumber, appName = cloud_RoleName
Das Ergebnis ist eine Liste mit Nachverfolgungsereignissen, die den Ausführungspfad der Orchestrierung anzeigt, z.B. alle Aktivitätsfunktionen, in aufsteigender Reihenfolge nach Ausführungszeit sortiert.
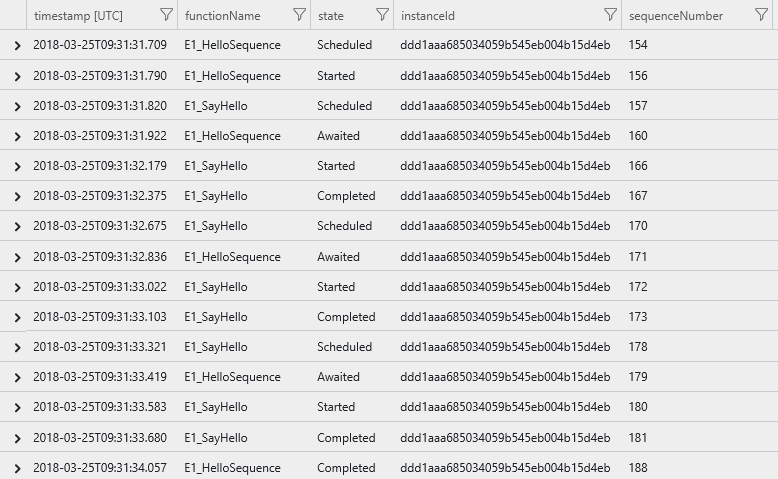
Instanz-Zusammenfassungsabfrage
Mit der folgenden Abfrage wird der Status aller Orchestrierungsinstanzen angezeigt, die in einem angegebenen Zeitraum ausgeführt wurden.
let start = datetime(2017-09-30T04:30:00);
traces
| where timestamp > start and timestamp < start + 1h
| where customDimensions.Category == "Host.Triggers.DurableTask"
| extend functionName = tostring(customDimensions["prop__functionName"])
| extend instanceId = tostring(customDimensions["prop__instanceId"])
| extend state = tostring(customDimensions["prop__state"])
| extend isReplay = tobool(tolower(customDimensions["prop__isReplay"]))
| extend output = tostring(customDimensions["prop__output"])
| where isReplay != true
| summarize arg_max(timestamp, *) by instanceId
| project timestamp, instanceId, functionName, state, output, appName = cloud_RoleName
| order by timestamp asc
Das Ergebnis ist eine Liste mit Instanz-IDs und dem aktuellen Laufzeitstatus.
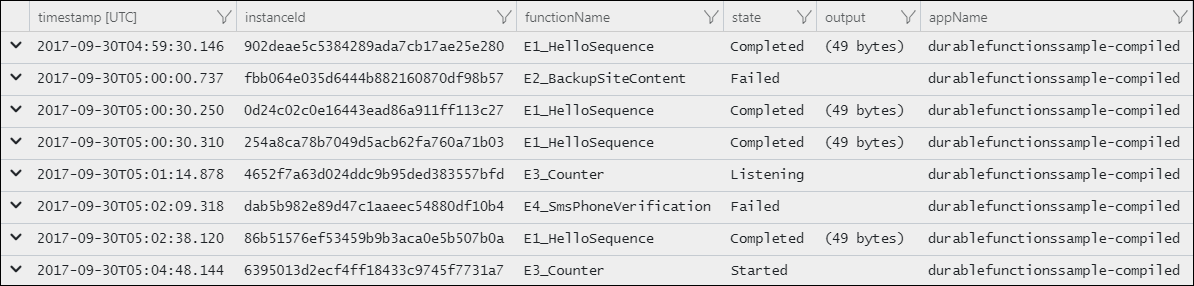
Durable Task Framework-Protokollierung
Die Durable-Erweiterungsprotokolle sind nützlich, um das Verhalten Ihrer Orchestrierungslogik zu verstehen. Diese Protokolle enthalten jedoch nicht immer genügend Informationen, um Probleme hinsichtlich Leistung und Zuverlässigkeit auf Frameworkebene zu debuggen. Ab v2.3.0 der Durable-Erweiterung stehen auch Protokolle, die vom zugrunde liegenden Durable Task Framework (DTFx) ausgegeben werden, zur Erfassung bereit.
Beim Betrachten der vom DTFx ausgegebenen Protokolle ist es wichtig zu verstehen, dass sich die DTFx-Engine aus zwei Komponenten zusammensetzt: aus der Kern-Dispatch-Engine (DurableTask.Core) und aus einem von vielen unterstützten Speicheranbietern (Durable Functions verwendet standardmäßig DurableTask.AzureStorage, es sind jedoch auch andere Optionen verfügbar).
- DurableTask.Core: zentrale Orchestrierungsausführung und Planungsprotokolle sowie Telemetrie auf niedriger Ebene
- DurableTask.AzureStorage: Back-End-Protokolle des jeweiligen Azure Storage-Zustandsanbieters. Diese Protokolle enthalten ausführliche Informationen mit den internen Warteschlangen, Blobs und Speichertabellen, die zum Speichern und Abrufen des internen Orchestrierungszustands verwendet wurden.
- DurableTask.Netherite: Back-End-Protokolle des jeweiligen Netherite-Speicheranbieters, sofern aktiviert
- DurableTask.SqlServer: Back-End-Protokolle des jeweiligen Microsoft SQL-Speicheranbieters (MSSQL), sofern aktiviert
Sie können diese Protokolle aktivieren, indem Sie den Abschnitt logging/logLevel in der Datei host.json Ihrer Funktions-App aktualisieren. Das folgende Beispiel zeigt, wie Warn- und Fehlerprotokolle sowohl von DurableTask.Core als auch von DurableTask.AzureStorage aktiviert werden können:
{
"version": "2.0",
"logging": {
"logLevel": {
"DurableTask.AzureStorage": "Warning",
"DurableTask.Core": "Warning"
}
}
}
Wenn Sie Application Insights aktiviert haben, werden diese Protokolle automatisch der trace-Sammlung hinzugefügt. Sie können sie auf dieselbe Weise durchsuchen wie andere trace-Protokolle mit Kusto-Abfragen.
Hinweis
Für Produktionsanwendungen wird empfohlen, DurableTask.Core und die entsprechenden Protokolle des Speicheranbieters (z. B. DurableTask.AzureStorage) mithilfe des "Warning"-Filters zu aktivieren. Höhere Ausführlichkeitsfilter wie "Information" sind sehr nützlich für die Fehlersuche bei Leistungsproblemen. Diese Protokollereignisse können jedoch ein hohes Volumen aufweisen und die Kosten für die Datenspeicherung von Application Insights erheblich erhöhen.
Die folgende Kusto-Abfrage zeigt, wie DTFx-Protokolle abgefragt werden. Der wichtigste Teil der Abfrage ist where customerDimensions.Category startswith "DurableTask", da dies die Ergebnisse nach Protokollen in den Kategorien DurableTask.Core und DurableTask.AzureStorage filtert.
traces
| where customDimensions.Category startswith "DurableTask"
| project
timestamp,
severityLevel,
Category = customDimensions.Category,
EventId = customDimensions.EventId,
message,
customDimensions
| order by timestamp asc
Das Ergebnis ist eine Reihe von Protokollen, die von den Anbietern von Durable Task Framework-Protokollen geschrieben wurden.
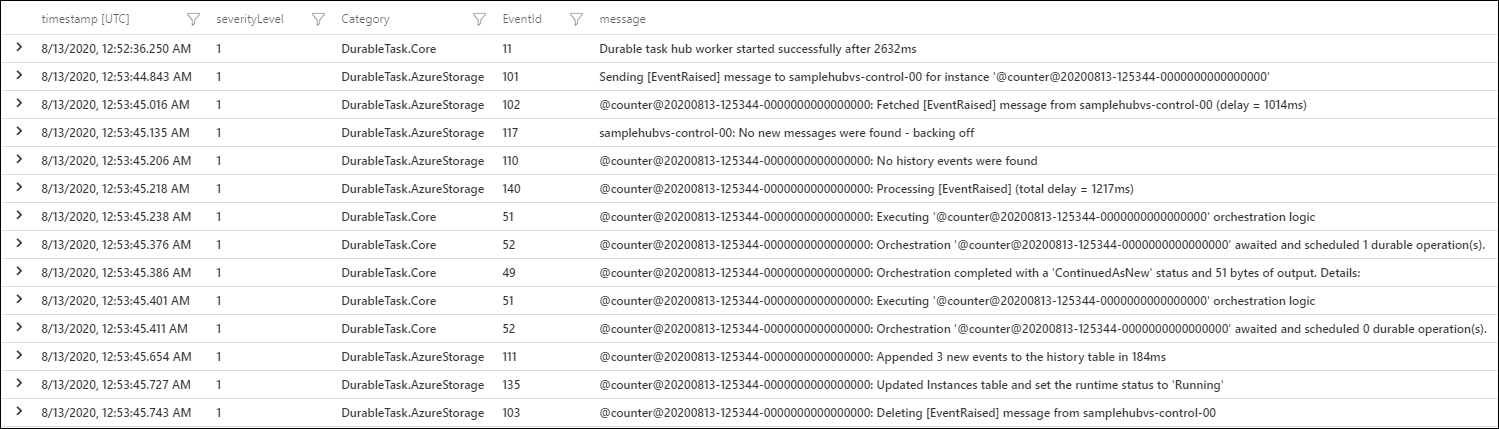
Weitere Informationen über die verfügbaren Protokollereignisse finden Sie in der Durable Task Framework-Dokumentation zur strukturierten Protokollierung auf GitHub.
App-Protokollierung
Es ist wichtig, das Wiedergabeverhalten von Orchestratoren zu beachten, wenn Protokolle direkt über eine Orchestratorfunktion geschrieben werden. Sehen Sie sich beispielsweise die folgende Orchestratorfunktion an:
[FunctionName("FunctionChain")]
public static async Task Run(
[OrchestrationTrigger] IDurableOrchestrationContext context,
ILogger log)
{
log.LogInformation("Calling F1.");
await context.CallActivityAsync("F1");
log.LogInformation("Calling F2.");
await context.CallActivityAsync("F2");
log.LogInformation("Calling F3");
await context.CallActivityAsync("F3");
log.LogInformation("Done!");
}
Die sich ergebenden Protokolldaten sehen dann in etwa wie die folgende Beispielausgabe aus:
Calling F1.
Calling F1.
Calling F2.
Calling F1.
Calling F2.
Calling F3.
Calling F1.
Calling F2.
Calling F3.
Done!
Hinweis
Beachten Sie Folgendes: In den Protokollen ist zwar angegeben, dass F1, F2 und F3 aufgerufen werden, aber diese Funktionen werden nur beim ersten Auftreten aufgerufen. Nachfolgende Aufrufe während der Wiedergabe werden übersprungen, und die Ausgaben werden für die Orchestratorlogik wiedergegeben.
Wenn Sie nur bei der Ausführung ohne Wiedergabe Protokolle schreiben möchten, können Sie einen bedingten Ausdruck zum Protokollieren nur dann schreiben, wenn das Flag „Wird wiedergegeben“ den Wert false aufweist. Hier ist das obige Beispiel angegeben, aber es enthält jetzt Wiedergabeprüfungen.
[FunctionName("FunctionChain")]
public static async Task Run(
[OrchestrationTrigger] IDurableOrchestrationContext context,
ILogger log)
{
if (!context.IsReplaying) log.LogInformation("Calling F1.");
await context.CallActivityAsync("F1");
if (!context.IsReplaying) log.LogInformation("Calling F2.");
await context.CallActivityAsync("F2");
if (!context.IsReplaying) log.LogInformation("Calling F3");
await context.CallActivityAsync("F3");
log.LogInformation("Done!");
}
Ab Durable Functions 2.0 besteht für .NET-Orchestratorfunktionen auch die Option, ein ILogger-Element zu erstellen, mit dem Protokollanweisungen während der Wiedergabe automatisch herausgefiltert werden. Diese automatische Filterung erfolgt mithilfe der API IDurableOrchestrationContext.CreateReplaySafeLogger(ILogger).
[FunctionName("FunctionChain")]
public static async Task Run(
[OrchestrationTrigger] IDurableOrchestrationContext context,
ILogger log)
{
log = context.CreateReplaySafeLogger(log);
log.LogInformation("Calling F1.");
await context.CallActivityAsync("F1");
log.LogInformation("Calling F2.");
await context.CallActivityAsync("F2");
log.LogInformation("Calling F3");
await context.CallActivityAsync("F3");
log.LogInformation("Done!");
}
Hinweis
Die vorherigen C#-Beispiele gelten für Durable Functions 2.x. Für Durable Functions 1.x müssen Sie DurableOrchestrationContext anstelle von IDurableOrchestrationContext verwenden. Weitere Informationen zu den Unterschieden zwischen den Versionen finden Sie im Artikel Durable Functions-Versionen.
Mit den zuvor erwähnten Änderungen sieht die Protokollausgabe wie folgt aus:
Calling F1.
Calling F2.
Calling F3.
Done!
Benutzerdefinierter Status
Mit dem benutzerdefinierten Orchestrierungsstatus können Sie einen benutzerdefinierten Statuswert für Ihre Orchestratorfunktion festlegen. Dieser benutzerdefinierte Status ist dann für externe Clients über die HTTP-Statusabfrage-API oder über sprachspezifische API-Aufrufe sichtbar. Der benutzerdefinierte Orchestrierungsstatus ermöglicht eine umfassendere Überwachung für Orchestratorfunktionen. Beispielsweise kann der Funktionscode des Orchestrators die API „Set Custom Status“ (Benutzerdefinierten Status festlegen) aufrufen, um den Fortschritt einer zeitintensiven Operation zu aktualisieren. Ein Client, z.B. eine Webseite oder ein anderes externes System, kann dann für die HTTP-Statusabfrage-APIs in regelmäßigen Abständen eine Abfrage nach umfangreicheren Statusinformationen durchführen. Nachstehend finden Sie Beispielcode für das Festlegen eines benutzerdefinierten Statuswerts in einer Orchestratorfunktion:
[FunctionName("SetStatusTest")]
public static async Task SetStatusTest([OrchestrationTrigger] IDurableOrchestrationContext context)
{
// ...do work...
// update the status of the orchestration with some arbitrary data
var customStatus = new { completionPercentage = 90.0, status = "Updating database records" };
context.SetCustomStatus(customStatus);
// ...do more work...
}
Hinweis
Das vorherige C#-Beispiel gilt für Durable Functions 2.x. Für Durable Functions 1.x müssen Sie DurableOrchestrationContext anstelle von IDurableOrchestrationContext verwenden. Weitere Informationen zu den Unterschieden zwischen den Versionen finden Sie im Artikel Durable Functions-Versionen.
Während der Ausführung der Orchestrierung können externe Clients diesen benutzerdefinierten Status abrufen:
GET /runtime/webhooks/durabletask/instances/instance123?code=XYZ
Clients erhalten folgende Antwort:
{
"runtimeStatus": "Running",
"input": null,
"customStatus": { "completionPercentage": 90.0, "status": "Updating database records" },
"output": null,
"createdTime": "2017-10-06T18:30:24Z",
"lastUpdatedTime": "2017-10-06T19:40:30Z"
}
Warnung
Die Nutzlast des benutzerdefinierten Status ist auf UTF-16-JSON-Text mit einer Größe von 16 KB beschränkt, da dieser in eine Azure Table Storage-Spalte passen muss. Für eine größere Nutzlast können Sie externen Speicher verwenden.
Verteilte Ablaufverfolgung
Verteilte Ablaufverfolgung verfolgt Anforderungen und zeigt, wie verschiedene Dienste miteinander interagieren. In Durable Functions korreliert sie auch Orchestrierungen und Aktivitäten zusammen. Dies ist hilfreich, um zu verstehen, wie viel Zeit die Orchestrierung im Verhältnis zur gesamten Orchestrierung benötigt. Es ist auch hilfreich zu verstehen, wo eine Anwendung ein Problem hat oder wo eine Ausnahme ausgelöst wurde. Dieses Feature wird für alle Sprachen und Speicheranbieter unterstützt.
Hinweis
Verteilte Ablaufverfolgung V2 erfordert Durable Functions v2.12.0 oder höher. Außerdem befindet sich verteilte Ablaufverfolgung V2 im Vorschauzustand und daher sind einige Muster für Durable Functions nicht instrumentiert. Beispielsweise werden Durable Entities nicht instrumentiert, und Ablaufverfolgungen werden in Application Insights nicht angezeigt.
Einrichten der verteilten Ablaufverfolgung
Um die verteilte Ablaufverfolgung einzurichten, aktualisieren Sie die host.json, und richten Sie eine Application Insights-Ressource ein.
host.json
"durableTask": {
"tracing": {
"distributedTracingEnabled": true,
"Version": "V2"
}
}
Application Insights
Wenn die Funktions-App nicht mit einer Application Insights-Ressource konfiguriert ist, konfigurieren Sie sie nach der Anleitung hier.
Überprüfen der Ablaufverfolgungen
Navigieren Sie in der Application Insights-Ressource zur Transaktionssuche. Suchen Sie in den Ergebnissen nach Request- und Dependency-Ereignissen, die mit bestimmten Präfixen für dauerhafte Funktionen beginnen (z. B. orchestration:, activity:usw.). Wenn Sie eines dieser Ereignisse auswählen, wird ein Gantt-Diagramm geöffnet, welches das Ende der verteilten Ablaufverfolgung anzeigt.

Problembehandlung
Wenn die Ablaufverfolgungen in Application Insights nicht angezeigt werden, stellen Sie sicher, dass Sie bis ungefähr fünf Minuten nach dem Ausführen der Anwendung warten, um sicherzustellen, dass alle Daten an die Application Insights-Ressource weitergegeben werden.
Debuggen
Azure Functions unterstützt das direkte Debuggen des Funktionscodes, und diese Unterstützung gilt auch für Durable Functions – unabhängig davon, ob die Ausführung in Azure oder lokal erfolgt. Beim Debuggen sollten aber einige Verhaltensweisen beachtet werden:
- Wiedergabe: Für Orchestratorfunktionen wird regelmäßig ein Replay ausgeführt, wenn neue Eingaben empfangen werden. Dieses Verhalten bedeutet Folgendes: Eine einzelne logische Ausführung einer Orchestratorfunktion kann dazu führen, dass derselbe Breakpoint mehrfach erreicht wird. Dies gilt vor allem, wenn er sich im Anfangsbereich des Funktionscodes befindet.
- Await: Bei jedem
await-Ausdruck in einer Orchestratorfunktion wird die Steuerung an den Durable Task Framework-Verteiler zurückgegeben. Wenn es das erste Mal ist, dass ein bestimmtesawait-Element auftritt, wird die zugeordnete Aufgabe nie fortgesetzt. Aus diesem Grund ist das Überspringen des Wartezustands (F10 in Visual Studio) nicht möglich. Das Überspringen funktioniert nur, wenn eine Aufgabe wiedergegeben wird. - Messagingtimeouts: In Durable Functions werden intern Warteschlangennachrichten für die Ausführung von Orchestrator-, Aktivitäts- und Entitätsfunktionen verwendet. In einer Umgebung mit mehreren VMs kann das Unterbrechen des Debuggens über längere Zeiträume dazu führen, dass eine andere VM die Nachricht aufnimmt. Das Ergebnis wäre dann eine doppelte Ausführung. Dieses Verhalten tritt auch für reguläre Warteschlangentriggerfunktionen auf, aber es ist wichtig, dies in diesem Zusammenhang zu erwähnen, da es sich bei den Warteschlangen um ein Implementierungsdetail handelt.
- Beenden und Starten: Nachrichten in Durable Functions werden zwischen Debugsitzungen persistent gespeichert. Wenn Sie das Debuggen beenden und den lokalen Hostprozess beenden, während eine permanente Funktion ausgeführt wird, kann diese Funktion in einer zukünftigen Debugsitzung automatisch erneut ausgeführt werden. Dieses Verhalten kann verwirrend sein, wenn es nicht erwartet wird. Die Verwendung eines neuen Aufgabenhubs oder das Löschen des Aufgabenhubinhalts zwischen Debugsitzungen ist eine Methode, um dieses Verhalten zu vermeiden.
Tipp
Gehen Sie wie folgt vor, wenn Sie beim Festlegen von Breakpoints in Orchestratorfunktionen erreichen möchten, dass nur bei Nichtwiedergabeausführungen eine Unterbrechung erfolgt: Legen Sie einen bedingten Breakpoint fest, bei dem nur eine Unterbrechung auftritt, wenn „Wird wiedergegeben“ den Wert false aufweist.
Storage
Durable Functions speichert den Status standardmäßig in Azure Storage. Dieses Verhalten bedeutet, dass Sie den Status Ihrer Orchestrierungen mit Tools wie Microsoft Azure Storage-Explorer untersuchen können.
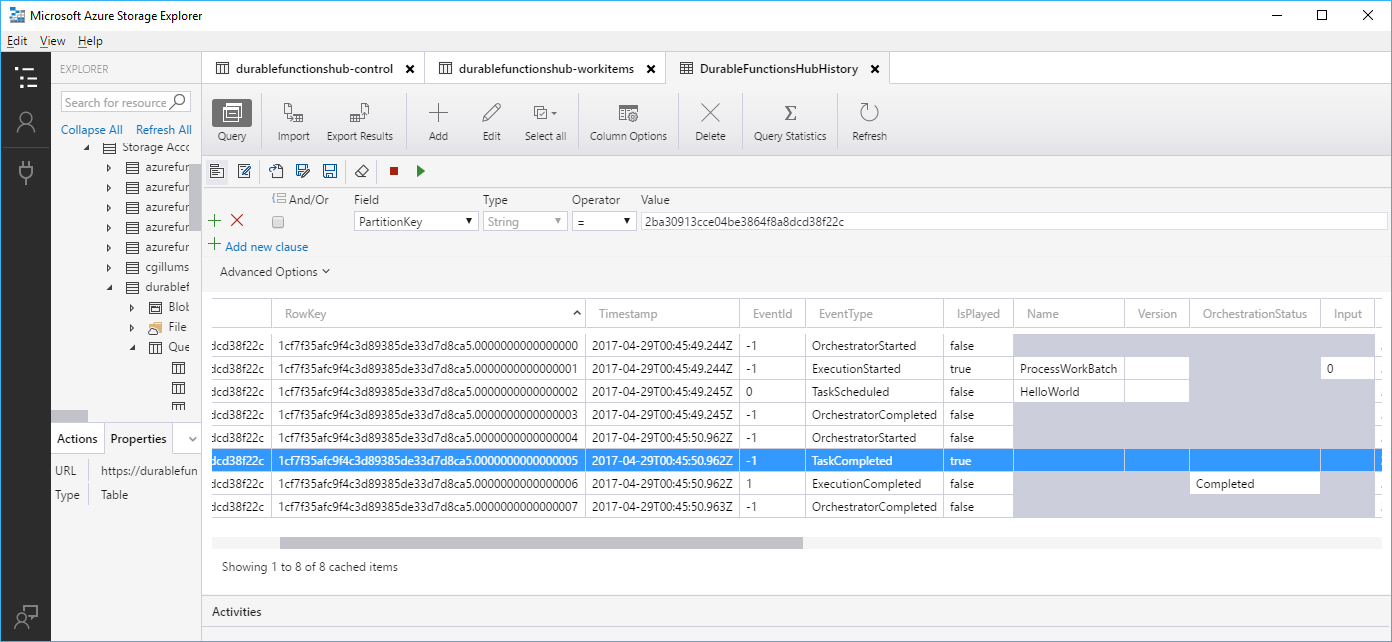
Dies ist hilfreich beim Debuggen, da Sie genau sehen, in welchem Zustand sich eine Orchestrierung befindet. Nachrichten in den Warteschlangen können ebenfalls untersucht werden, um zu ermitteln, welche Arbeitsschritte ausstehen (oder ggf. hängen).
Warnung
Es ist zwar bequem, den Ausführungsverlauf im Tabellenspeicher angezeigt zu bekommen, aber Sie sollten es vermeiden, Abhängigkeiten von dieser Tabelle einzurichten. Dies kann sich im Rahmen der Weiterentwicklung der Erweiterung Durable Functions ändern.
Hinweis
Anstelle des Azure Storage-Standardanbieters können andere Speicheranbieter konfiguriert werden. Je nach dem für Ihre App konfigurierten Speicheranbieter müssen Sie möglicherweise verschiedene Tools verwenden, um den zugrunde liegenden Zustand zu überprüfen. Weitere Informationen finden Sie in der Dokumentation zu Durable Functions-Speicheranbietern.
Durable Functions: Leitfaden zur Problembehandlung
Informationen zur Behandlung gängiger Problemsymptome, wie z. B. hängende Orchestrierungen, Fehler beim Start, langsame Ausführung, finden Sie in diesem Leitfaden zur Problembehandlung.
Drittanbietertools
Die Durable Functions-Community veröffentlicht eine Vielzahl von Debug-, Diagnose- oder Überwachungstools. Eines dieser Tools ist das Open-Source-Tool Durable Functions Monitor, ein grafisches Tool zum Überwachen, Verwalten und Debuggen Ihrer Orchestrierungsinstanzen.