Strategien für die Notfallwiederherstellung für Anwendungen mit Pools für elastische Datenbanken in Azure SQL-Datenbank
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Azure SQL-Datenbank verfügt über verschiedene Funktionen, mit denen Sie für die geschäftliche Kontinuität Ihrer Anwendung in Katastrophenfällen sorgen können. Pools für elastische Datenbanken und einzelne Datenbanken unterstützen die gleichen Funktionen für die Notfallwiederherstellung. In diesem Artikel werden mehrere Notfallwiederherstellungsstrategien für Pools für elastische Datenbanken beschrieben, bei denen diese Features von Azure SQL-Datenbank zur Sicherstellung der geschäftlichen Kontinuität verwendet werden.
In diesem Artikel wird das folgende kanonische SaaS-ISV-Anwendungsmuster verwendet:
Bei einer modernen cloudbasierten Webanwendung wird eine Datenbank für jeden Endbenutzer bereitgestellt. Der ISV verfügt über zahlreiche Kunden und setzt aus diesem Grund viele Datenbanken ein, die als Mandantendatenbanken bezeichnet werden. Da die Mandantendatenbanken in der Regel unvorhersagbare Aktivitätsmuster aufweisen, nutzt der ISV einen Pool für elastische Datenbanken, um die Datenbankkosten für längere Zeiträume eindeutig vorhersagbar zu machen. Mit dem Pool für elastische Datenbanken wird außerdem die Leistungsverwaltung bei Spitzen der Benutzeraktivität vereinfacht. Zusätzlich zu den Mandantendatenbanken verwendet die Anwendung auch mehrere Datenbanken zum Verwalten von Benutzerprofilen, Sicherheit, Sammeln von Verwendungsmustern usw. Die Verfügbarkeit der einzelnen Mandanten wirkt sich nicht auf die Verfügbarkeit der Anwendung als Ganzes aus. Die Verfügbarkeit und Leistung von Verwaltungsdatenbanken ist für die Funktion der Anwendung von entscheidender Bedeutung, und wenn die Verwaltungsdatenbanken offline sind, ist auch die gesamte Anwendung offline.
In diesem Artikel werden Strategien für die Notfallwiederherstellung anhand mehrerer Szenarios besprochen, angefangen bei kostenbewussten Anwendungen bis hin zu Anwendungen mit strengen Verfügbarkeitsanforderungen.
Notiz
Wenn Sie Premium-Datenbanken, unternehmenskritische Datenbanken oder Pools für elastische Datenbanken verwenden, können Sie sie resistent gegenüber regionalen Ausfällen machen, indem Sie sie auf die Konfiguration der zonenredundanten Bereitstellung umstellen. Informationen finden Sie unter Hochverfügbarkeit und Azure SQL-Datenbank.
Szenario 1. Kostenbewusste Anwendung für Startup-Unternehmen
Wir sind ein Startup-Unternehmen, bei dem stark auf die Kosten geachtet wird. Wir möchten die Bereitstellung und Verwaltung der Anwendung vereinfachen und einen eingeschränkten Servicelevel (SLA) für einzelne Kunden verwenden. Es soll aber sichergestellt sein, dass die Anwendung als Ganzes niemals offline ist.
Um die Anforderung zur Vereinfachung zu erfüllen, stellen Sie alle Mandantendatenbanken in einem Pool für elastische Datenbanken in der Azure-Region Ihrer Wahl und die Verwaltungsdatenbanken als georeplizierte einzelne Datenbanken bereit. Verwenden Sie für die Notfallwiederherstellung von Mandanten die Geowiederherstellung, für die keine zusätzlichen Kosten anfallen. Um die Verfügbarkeit der Verwaltungsdatenbanken sicherzustellen, sollten sie mithilfe einer Gruppe für automatisches Failover in eine andere Region georepliziert werden (Schritt 1). Die laufenden Kosten der Notfallwiederherstellungskonfiguration in diesem Szenario entsprechen den Gesamtkosten der sekundären Datenbanken. Diese Konfiguration ist im nächsten Diagramm dargestellt.
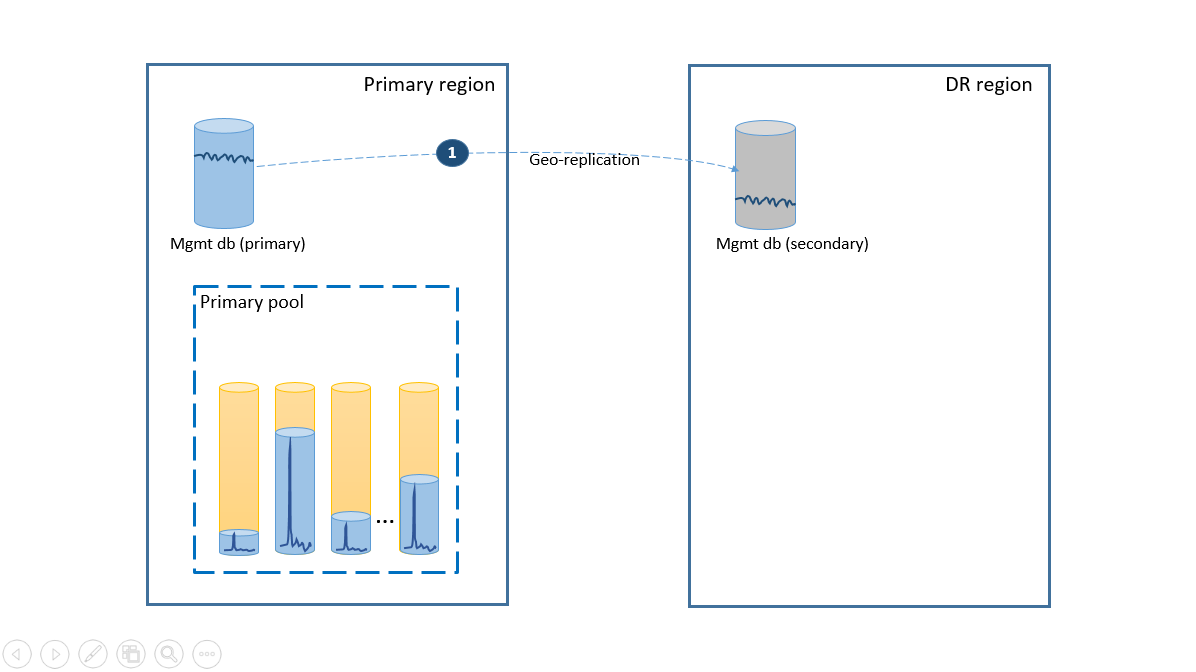
Bei einem Ausfall in der primären Region können Sie die Wiederherstellungsschritte ausführen, die im nächsten Diagramm angegeben sind, um die Anwendung wieder in den Onlinezustand zu versetzen.
- Die Failovergruppe initiiert das automatische Failover der Verwaltungsdatenbank in die DR-Region. Die Anwendung stellt die Verbindung mit der neuen primären Datenbank und allen neuen Konten automatisch wieder her, und in der DR-Region werden Mandantendatenbanken erstellt. Für die vorhandenen Kunden sind die Daten vorübergehend nicht verfügbar.
- Erstellen Sie den Pool für elastische Datenbanken mit der gleichen Konfiguration wie für den ursprünglichen Pool (2).
- Verwenden Sie die Geowiederherstellung, um Kopien der Mandantendatenbanken zu erstellen (3). Sie können erwägen, die einzelnen Wiederherstellungen über die Endbenutzerverbindungen auszulösen, oder Sie können ein anderes anwendungsspezifisches Prioritätsschema verwenden.
An diesem Punkt befindet sich die Anwendung in der Region für die Notfallwiederherstellung wieder im Onlinezustand, aber bei einigen Kunden kommt es beim Zugreifen auf ihre Daten zu Verzögerungen.
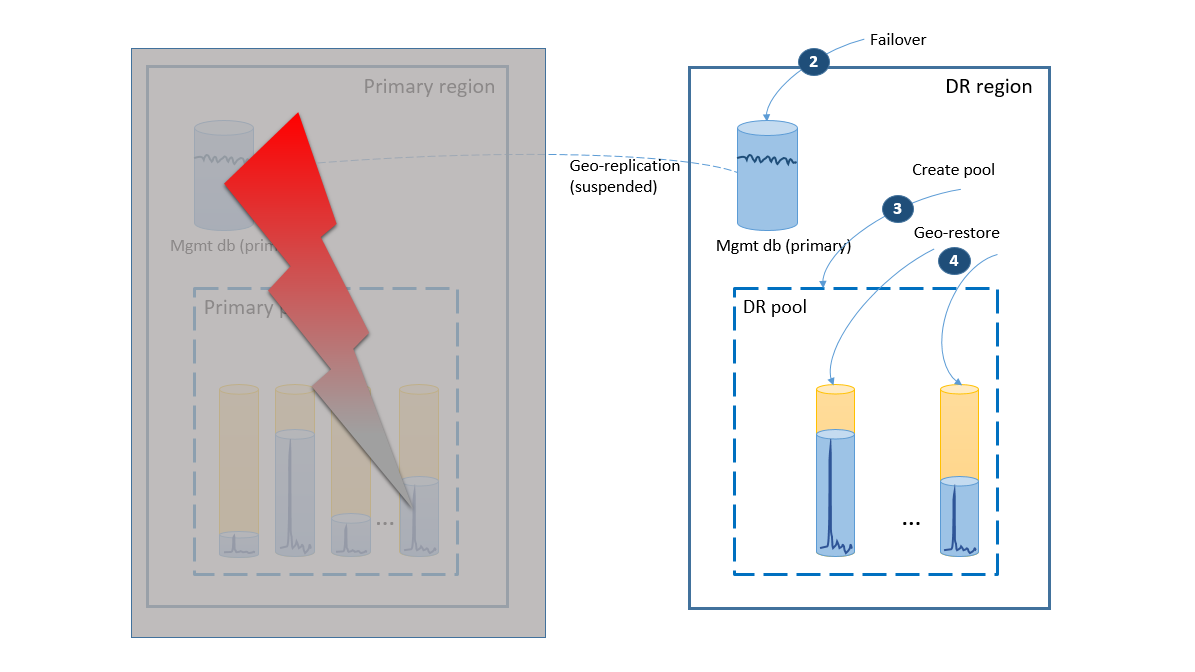
Wenn der Ausfall temporärer Art war, ist es möglich, dass die primäre Region von Azure wiederhergestellt wird, bevor in der Region für die Notfallwiederherstellung alle Datenbankwiederherstellungen abgeschlossen sind. Orchestrieren Sie in diesem Fall, dass die Anwendung zurück in die primäre Region verschoben wird. Während des Vorgangs werden die Schritte ausgeführt, die im nächsten Diagramm dargestellt sind.
- Brechen Sie alle ausstehenden Anforderungen zur Geowiederherstellung ab.
- Führen Sie für die Verwaltungsdatenbanken ein Failover in die primäre Region durch (5). Nach der Wiederherstellung der Region sind aus den alten primären Replikaten automatisch sekundäre Replikate geworden. Nun werden die Rollen wieder gewechselt.
- Ändern Sie die Verbindungszeichenfolge der Anwendung so, dass sie wieder auf die primäre Region verweist. Alle neuen Konten und Mandantendatenbanken werden jetzt in der primären Region erstellt. Für einige der vorhandenen Kunden sind die Daten vorübergehend nicht verfügbar.
- Legen Sie alle Datenbanken im Pool für die Notfallwiederherstellung auf „Schreibgeschützt“ fest, um sicherzustellen, dass sie in der Region für die Notfallwiederherstellung nicht geändert werden können (6).
- Benennen Sie für jede Datenbank im Pool für die Notfallwiederherstellung, die sich seit der Wiederherstellung geändert hat, die entsprechenden Datenbanken im primären Pool um, oder löschen Sie sie (7).
- Kopieren Sie die aktualisierten Datenbanken aus dem Pool für die Notfallwiederherstellung in den primären Pool (8).
- Löschen Sie den Pool für die Notfallwiederherstellung (9)
An diesem Punkt ist die Anwendung in der primären Region online, und alle Mandantendatenbanken sind im primären Pool verfügbar.

Vorteil
Der Hauptvorteil dieser Strategie sind die geringen laufenden Kosten für die Redundanz der Datenschicht. Azure SQL-Datenbank sichert Datenbanken automatisch ohne Umschreiben von Anwendungen und ohne zusätzliche Kosten. Kosten fallen nur an, wenn die elastischen Datenbanken wiederhergestellt werden.
Kompromiss
Der Kompromiss besteht darin, dass die vollständige Wiederherstellung aller Mandantendatenbanken sehr lange dauert. Die Dauer hängt von der Gesamtanzahl von Wiederherstellungen ab, die Sie in der Region für die Notfallwiederherstellung initiieren, sowie von der Gesamtgröße der Mandantendatenbanken. Auch wenn Sie den Wiederherstellungen einiger Mandanten Vorrang einräumen, entsteht ein Wettbewerb mit allen anderen Wiederherstellungen, die in derselben Region initiiert werden. Der Dienst führt Vermittlungen und Drosselungen durch, um die allgemeinen Auswirkungen auf die Datenbanken der vorhandenen Kunden gering zu halten. Außerdem kann die Wiederherstellung der Mandantendatenbanken erst beginnen, nachdem der neue Pool für elastische Datenbanken in der Region für die Notfallwiederherstellung erstellt wurde.
Szenario 2. Ausgereifte Anwendung mit Diensten auf mehreren Ebenen
Wir verwenden eine ausgereifte SaaS-Anwendung mit Dienstangeboten auf mehreren Ebenen und unterschiedlichen SLAs für Testkunden und zahlende Kunden. Für die Testkunden sollen die Kosten so weit wie möglich reduziert werden. Für Testkunden kann es zu Ausfallzeiten kommen, aber die Wahrscheinlichkeit dafür soll verringert werden. In Bezug auf die zahlenden Kunden ist jede Ausfallzeit mit einem Abwanderungsrisiko verbunden. Daher soll sichergestellt sein, dass zahlende Kunden immer auf ihre Daten zugreifen können.
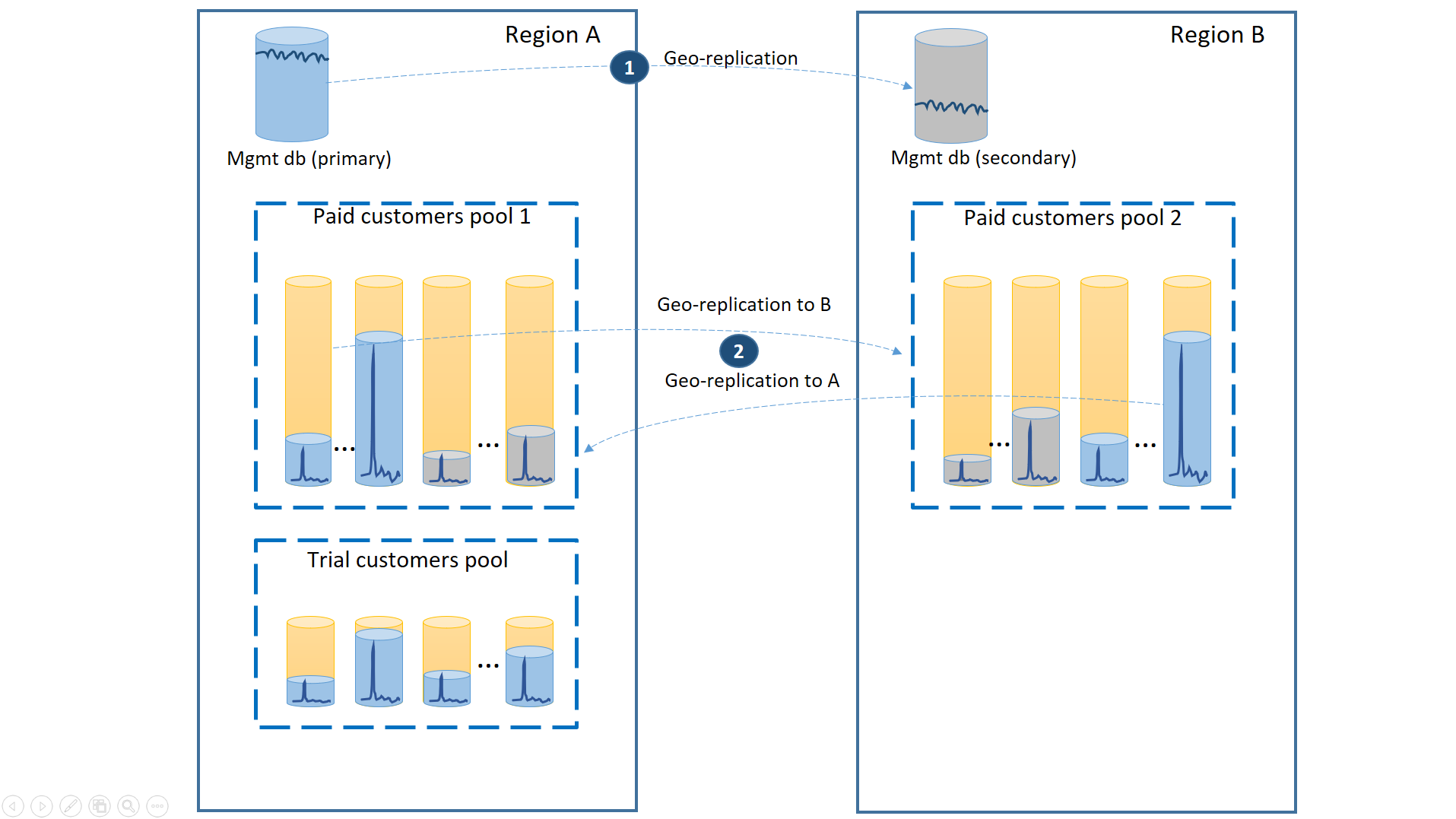
Trennen Sie zur Unterstützung dieses Szenarios die Testmandanten von den zahlenden Mandanten, indem Sie sie in separaten Pools für elastische Datenbanken anordnen. Für die Testkunden gilt dann eine niedrigere Anzahl von eDTUs oder virtuellen Kernen pro Mandant und ein SLA mit einer längeren Wiederherstellungszeit. Die zahlenden Kunden sind in einem Pool mit einer höheren Anzahl von eDTUs oder virtuellen Kernen pro Mandant und einem höheren SLA angeordnet. Um die kürzeste Wiederherstellungsdauer zu gewährleisten, werden die Mandantendatenbanken der zahlenden Kunden georepliziert. Diese Konfiguration ist im nächsten Diagramm dargestellt.
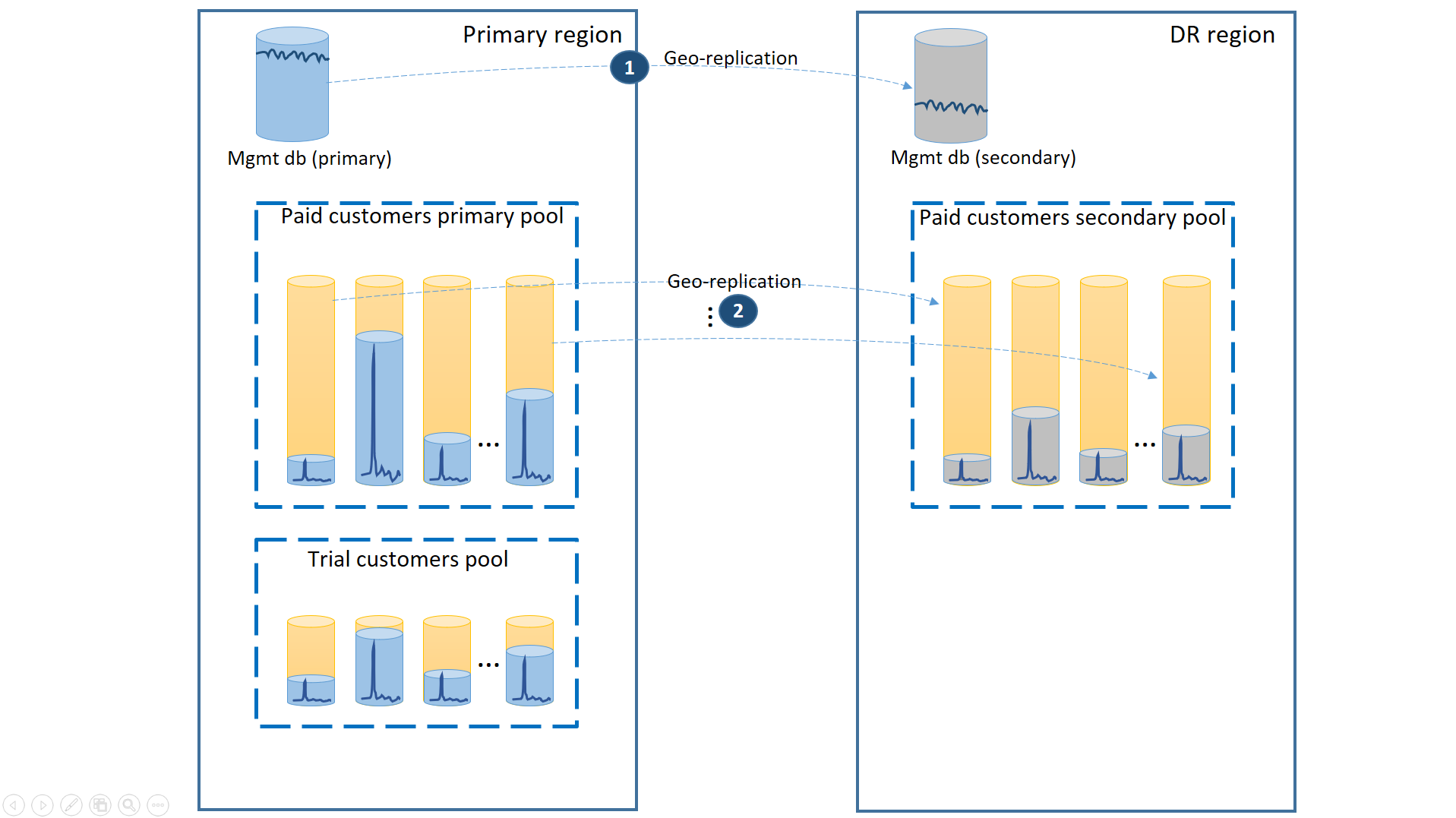
Wie beim ersten Szenario auch sind die Verwaltungsdatenbanken ziemlich aktiv, sodass Sie dafür eine einzelne georeplizierte Datenbank verwenden (1). So wird die vorhersagbare Leistung für neue Kundensubscriptons, Profilupdates und andere Verwaltungsvorgänge sichergestellt. Die Region, in der sich die primären Replikate der Verwaltungsdatenbanken befinden, ist die primäre Region, und die Region, in der sich die sekundären Replikate der Verwaltungsdatenbanken befinden, ist die Region für die Notfallwiederherstellung.
Die Mandantendatenbanken der zahlenden Kunden verfügen über aktive Datenbanken im bezahlten Pool, der in der primären Region bereitgestellt wird. Stellen Sie in der Region für die Notfallwiederherstellung einen sekundären Pool gleichen Namens bereit. Jeder Mandant wird dann in den sekundären Pool georepliziert (2). Dies ermöglicht eine schnelle Wiederherstellung aller Mandantendatenbanken per Failover.
Bei einem Ausfall in der primären Region können Sie die Wiederherstellungsschritte ausführen, die im nächsten Diagramm angegeben sind, um die Anwendung wieder in den Onlinezustand zu versetzen:
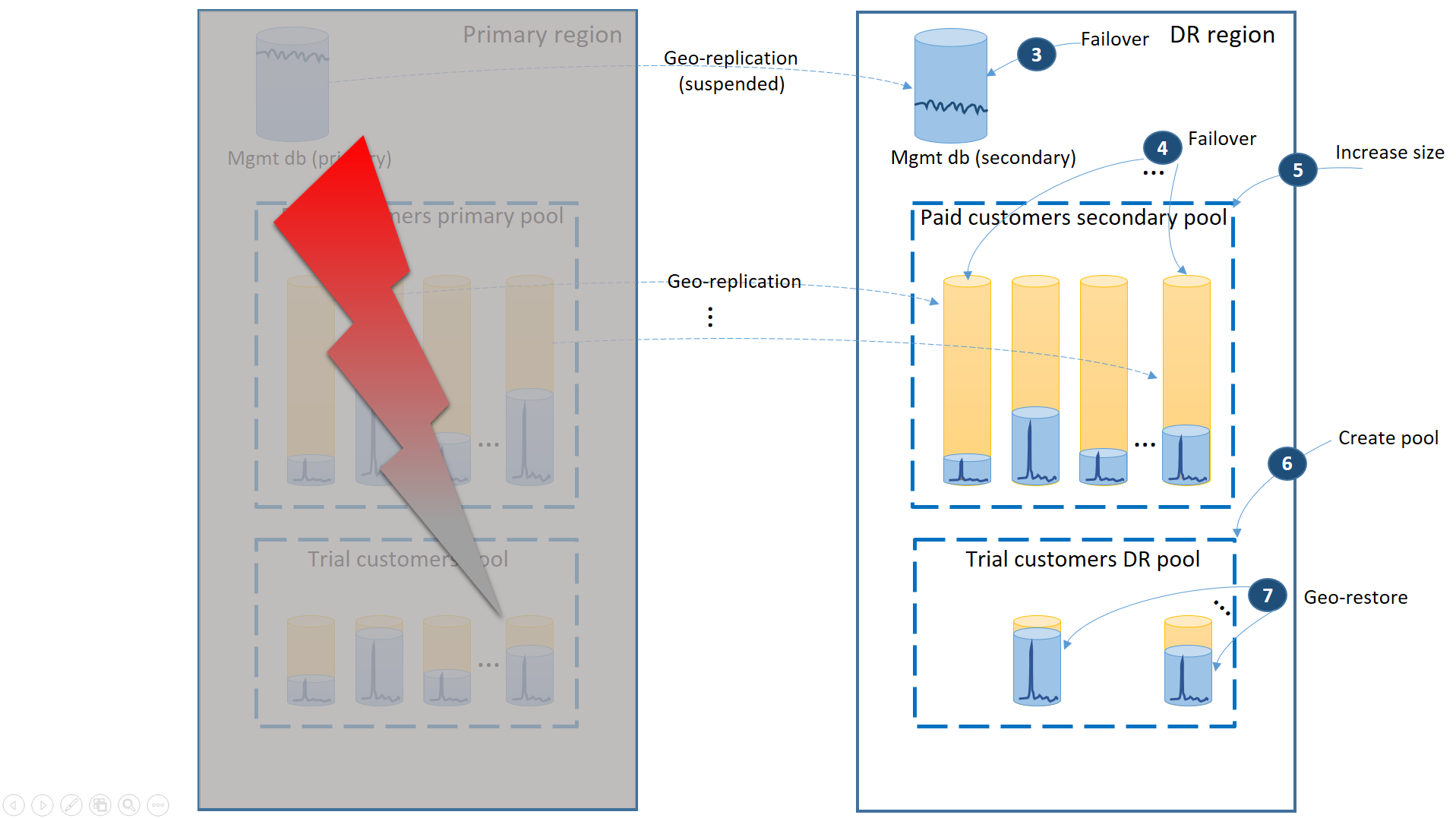
- Führen Sie ein sofortiges Failover der Verwaltungsdatenbanken in die Region für die Notfallwiederherstellung durch (3).
- Ändern Sie die Verbindungszeichenfolge der Anwendung so, dass sie auf die Region für die Notfallwiederherstellung verweist. Alle neuen Konten und Mandantendatenbanken werden jetzt in der Region für die Notfallwiederherstellung erstellt. Für die vorhandenen Testkunden sind die Daten vorübergehend nicht verfügbar.
- Führen Sie für die Datenbanken der bezahlten Mandanten ein Failover in den Pool in der Region für die Notfallwiederherstellung durch, um die Verfügbarkeit sofort wiederherzustellen (4). Da es sich beim Failover um eine schnelle Änderung der Metadatenebene handelt, erwägen Sie eine Optimierung, bei der die einzelnen Failover bei Bedarf von den Endbenutzerverbindungen ausgelöst werden.
- Falls die eDTU-Größe oder der Wert der virtuellen Kerne des sekundären Pools niedriger als die Größe des primären Pools war, weil für die sekundären Datenbanken die Kapazität zum Verarbeiten der Änderungsprotokolle nur erforderlich war, als es sich um sekundäre Replikate gehandelt hat, erhöhen Sie die Poolkapazität jetzt sofort. Dies ist nötig, um die gesamte Workload aller Mandanten abdecken zu können (5).
- Erstellen Sie den neuen Pool für elastische Datenbanken mit dem gleichen Namen und der gleichen Konfiguration in der Notfallwiederherstellungsregion für die Datenbanken der Testkunden (6).
- Nachdem der Pool für die Testkunden erstellt wurde, verwenden Sie die Geowiederherstellung, um die einzelnen Testmandanten-Datenbanken im neuen Pool wiederherzustellen (7). Erwägen Sie die Auslösung der einzelnen Wiederherstellungen über die Endbenutzerverbindungen, oder verwenden Sie ein anderes anwendungsspezifisches Prioritätsschema.
An diesem Punkt ist Ihre Anwendung in der Region für die Notfallwiederherstellung wieder online. Alle zahlenden Kunden haben Zugriff auf ihre Daten, während es für Testkunden beim Zugreifen auf die Daten zu Verzögerungen kommt.
Wenn die primäre Region von Azure wiederhergestellt wurde, nachdem Sie die Anwendung in der Region für die Notfallwiederherstellung wiederhergestellt haben, können Sie die Ausführung der Anwendung in dieser Region fortsetzen, oder Sie können ein Failback zurück zur primären Region durchführen. Falls die primäre Region wiederhergestellt wird, bevor der Failoverprozess abgeschlossen ist, sollten Sie erwägen, sofort ein Failback durchzuführen. Beim Failback werden die Schritte ausgeführt, die im nächsten Diagramm dargestellt sind:
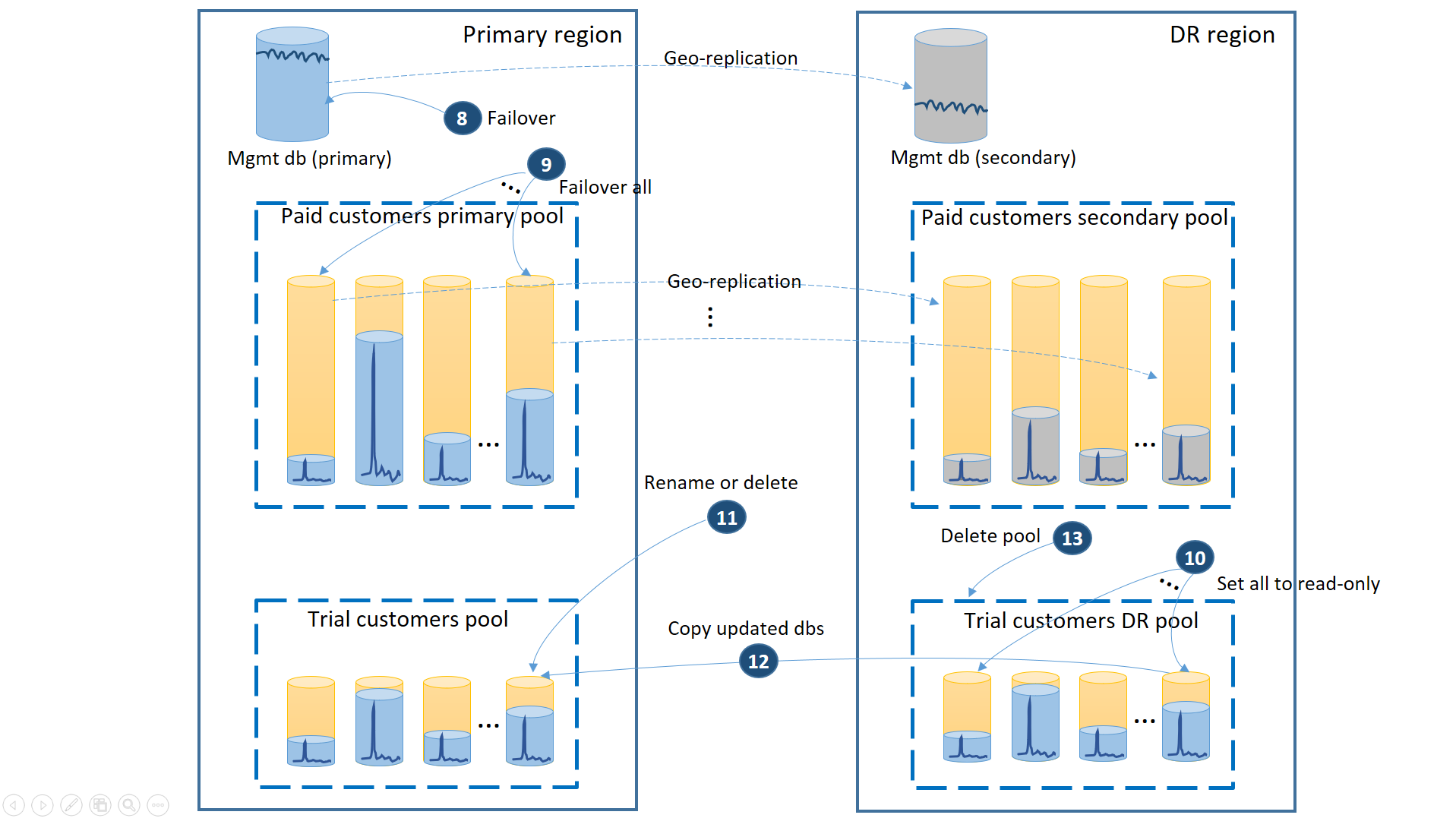
- Brechen Sie alle ausstehenden Anforderungen zur Geowiederherstellung ab.
- Führen Sie das Failover für die Verwaltungsdatenbank durch (8). Nach der Wiederherstellung der Region werden die alten primären Replikate automatisch zu den sekundären Replikaten. Nun werden sie wieder zu primären Replikaten.
- Führen Sie das Failover der bezahlten Mandantendatenbanken durch (9). Entsprechend werden die alten primären Replikate nach der Wiederherstellung der Region automatisch zu den sekundären Replikaten. Nun werden sie wieder zu primären Replikaten.
- Legen Sie die wiederhergestellten Testdatenbanken, die sich in der Region für die Notfallwiederherstellung geändert haben, auf „Schreibgeschützt“ fest (10).
- Benennen Sie für jede Datenbank im Notfallwiederherstellungspool für die Testkunden, die sich seit der Wiederherstellung geändert hat, die entsprechende Datenbank im primären Pool für Testkunden um, oder löschen Sie sie (11).
- Kopieren Sie die aktualisierten Datenbanken aus dem Pool für die Notfallwiederherstellung in den primären Pool (12).
- Löschen Sie den Pool für die Notfallwiederherstellung (13).
Notiz
Der Failovervorgang ist asynchron. Um die Wiederherstellungszeit zu minimieren, ist es wichtig, dass Sie den Failoverbefehl der Mandantendatenbanken für Batches von mindestens 20 Datenbanken ausführen.
Vorteil
Der Hauptvorteil dieser Strategie besteht darin, dass für die zahlenden Kunden die höchste Vereinbarung zum Servicelevel (SLA) erzielt wird. Außerdem ist sichergestellt, dass die Blockierung der neuen Testzugriffe sofort aufgehoben wird, sobald der Notfallwiederherstellungspool für Testkunden erstellt wurde.
Kompromiss
Der Kompromiss besteht darin, dass sich bei dieser Einrichtung die Gesamtkosten der Mandantendatenbanken für zahlende Kunden um die Kosten für den sekundären Notfallwiederherstellungspool erhöhen. Wenn der sekundäre Pool eine andere Größe hat, verringert sich für zahlende Kunden außerdem die Leistung nach einem Failover, bis das Poolupgrade in der Region für die Notfallwiederherstellung abgeschlossen ist.
Szenario 3. Geografisch verteilte Anwendung mit Diensten auf mehreren Ebenen
Wir verwenden eine ausgereifte SaaS-Anwendung mit Dienstangeboten auf mehreren Ebenen. Wir möchten zahlenden Kunden einen sehr aggressiven Servicelevel (SLA) anbieten und die Auswirkungen bei Ausfällen gering halten, da auch kurze Unterbrechungen bei Kunden zu Unzufriedenheit führen können. Es ist sehr wichtig, dass die zahlenden Kunden immer Zugriff auf ihre Daten haben. Die Testversionen sind kostenlos, und während des Testzeitraums wird keine SLA angeboten.
Verwenden Sie für dieses Szenario drei separate Pools für elastische Datenbanken. Stellen Sie zwei Pools gleicher Größe mit einer hohen Anzahl von eDTUs oder virtuellen Kernen pro Datenbank in zwei unterschiedlichen Regionen bereit, um die Mandantendatenbanken der zahlenden Kunden aufnehmen zu können. Der dritte Pool mit den Testmandanten kann hierbei über weniger eDTUs oder virtuelle Kerne pro Datenbank verfügen und in einer der beiden Regionen bereitgestellt werden.
Um bei Ausfällen die kürzeste Wiederherstellungsdauer garantieren zu können, werden die Mandantendatenbanken der zahlenden Kunden mit 50 Prozent der primären Datenbanken in beiden Regionen georepliziert. Außerdem verfügt jede Region über 50 Prozent der sekundären Datenbanken. Wenn eine Region offline ist, sind hierbei also nur 50 Prozent der Datenbanken zahlender Kunden betroffen und müssen einem Failover unterzogen werden. Die restlichen Datenbanken bleiben intakt. Diese Konfiguration ist im folgenden Diagramm dargestellt:
Wie in den vorherigen Szenarien auch sind die Verwaltungsdatenbanken sehr aktiv, sodass Sie sie als einzelne georeplizierte Datenbanken konfigurieren sollten (1). So wird die vorhersagbare Leistung der neuen Kundensubscriptons, Profilupdates und anderen Verwaltungsvorgänge sichergestellt. Region A ist die primäre Region für die Verwaltungsdatenbanken, und Region B wird für die Wiederherstellung der Verwaltungsdatenbanken verwendet.
Die Mandantendatenbanken der zahlenden Kunden werden auch georepliziert, aber die primären und sekundären Replikate werden auf Region A und Region B aufgeteilt (2). So kann für die primären Mandantendatenbanken, die vom Ausfall betroffen sind, ein Failover in die andere Region durchgeführt werden, damit sie verfügbar sind. Die andere Hälfte der Mandantendatenbanken ist davon nicht betroffen.
Im nächsten Diagramm sind die Wiederherstellungsschritte dargestellt, die ausgeführt werden müssen, wenn es in Region A zu einem Ausfall kommt.
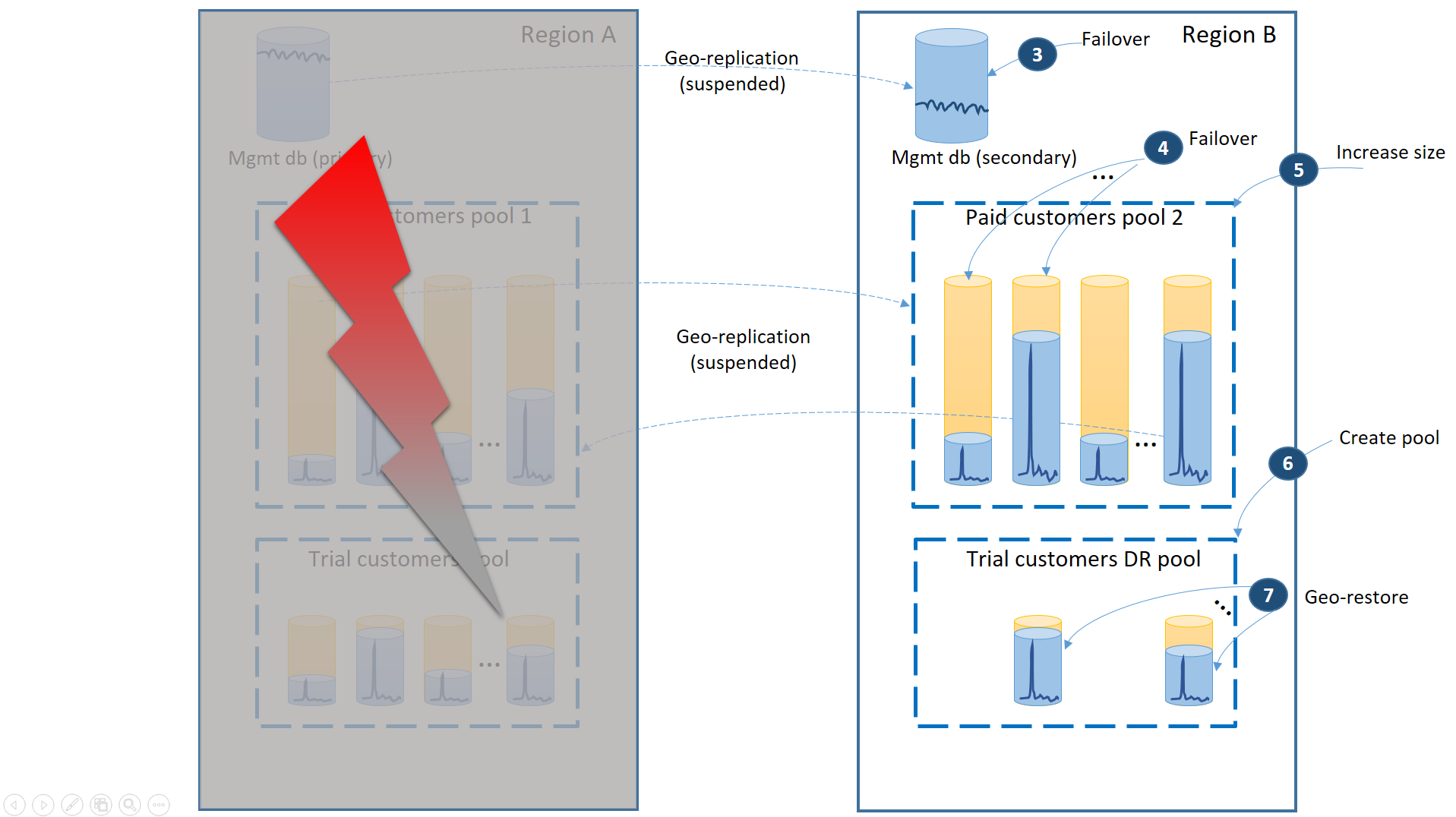
- Führen Sie für die Verwaltungsdatenbanken sofort ein Failover in Region B durch (3).
- Ändern Sie die Verbindungszeichenfolge der Anwendung so, dass sie auf die Verwaltungsdatenbanken in Region B verweist. Ändern Sie die Verwaltungsdatenbanken, um sicherzustellen, dass die neuen Konten und Mandantendatenbanken in Region B erstellt werden und die vorhandenen Mandantendatenbanken ebenfalls dort angeordnet sind. Für die vorhandenen Testkunden sind die Daten vorübergehend nicht verfügbar.
- Führen Sie für die Datenbanken der bezahlten Mandanten ein Failover in Pool 2 von Region B durch, um die Verfügbarkeit sofort wiederherzustellen (4). Da es sich beim Failover um eine schnelle Änderung der Metadatenebene handelt, können Sie eine Optimierung erwägen, bei der die einzelnen Failover bei Bedarf von den Endbenutzerverbindungen ausgelöst werden.
- Da Pool 2 jetzt nur primäre Datenbanken enthält, erhöht sich die gesamte Workload im Pool und kann die eDTU-Größe (5) oder die Anzahl von virtuellen Kernen sofort erhöhen.
- Erstellen Sie den neuen Pool für elastische Datenbanken mit dem gleichen Namen und der gleichen Konfiguration in Region B für die Datenbanken der Testkunden (6).
- Verwenden Sie nach der Erstellung des Pools die Geowiederherstellung, um die individuelle Testmandanten-Datenbank im Pool wiederherzustellen (7). Sie können erwägen, die einzelnen Wiederherstellungen über die Endbenutzerverbindungen auszulösen, oder Sie können ein anderes anwendungsspezifisches Prioritätsschema verwenden.
Notiz
Der Failovervorgang ist asynchron. Um die Wiederherstellungszeit zu minimieren, ist es wichtig, dass Sie den Failoverbefehl der Mandantendatenbanken für Batches von mindestens 20 Datenbanken ausführen.
An diesem Punkt ist die Anwendung in Region B wieder online. Alle zahlenden Kunden haben Zugriff auf ihre Daten, während es für Testkunden beim Zugreifen auf die Daten zu Verzögerungen kommt.
Nach dem Wiederherstellen von Region A müssen Sie entscheiden, ob Sie Region B für Testkunden verwenden oder ein Failback zur Verwendung des Testkundenpools in Region A durchführen möchten. Ein Kriterium kann der Prozentsatz der Testmandanten-Datenbanken sein, die seit der Wiederherstellung geändert wurden. Unabhängig von dieser Entscheidung müssen Sie die kostenpflichtigen Mandanten zwischen zwei Pools neu verteilen. Das nächste Diagramm veranschaulicht den Prozess, bei dem für die Mandantendatenbanken für Testkunden ein Failback auf Region A ausgeführt wird.
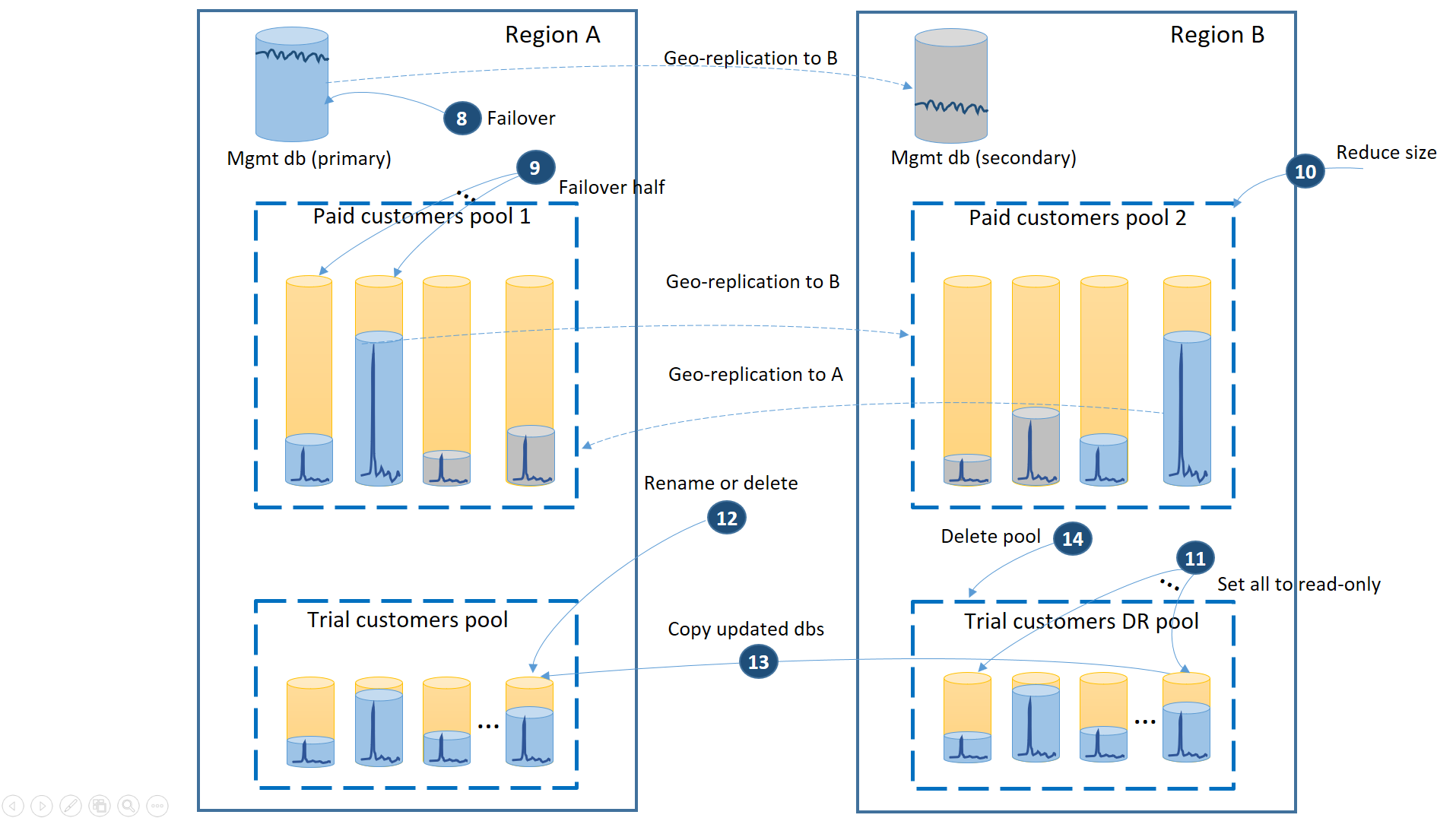
- Brechen Sie alle ausstehenden Anforderungen der Geowiederherstellung an den Notfallwiederherstellungspool für Testkunden ab.
- Führen Sie das Failover für die Verwaltungsdatenbank durch (8). Nach der Wiederherstellung der Region werden die alten primären Replikate automatisch zu den sekundären Replikaten. Nun werden sie wieder zu primären Replikaten.
- Wählen Sie aus, für welche Datenbanken für bezahlte Mandaten ein Failback zu Pool 1 durchgeführt werden soll, und initiieren Sie das Failover zu den sekundären Replikaten (9). Nach der Wiederherstellung der Region werden alle Datenbanken in Pool 1 automatisch zu sekundären Replikaten. Nun werden 50 Prozent davon wieder zu primären Replikaten.
- Reduzieren Sie die Größe von Pool 2 auf die ursprüngliche Anzahl von eDTUs (10) oder virtuellen Kernen.
- Legen Sie alle wiederhergestellten Testdatenbanken in Region B auf „Schreibgeschützt“ fest (11).
- Benennen Sie für jede Datenbank im Notfallwiederherstellungspool für Testkunden, die sich seit der Wiederherstellung geändert hat, die entsprechende Datenbank im primären Testpool um, oder löschen Sie sie (12).
- Kopieren Sie die aktualisierten Datenbanken aus dem Pool für die Notfallwiederherstellung in den primären Pool (13).
- Löschen Sie den Pool für die Notfallwiederherstellung (14).
Vorteil
Die Hauptvorteile dieser Strategie lauten:
- Es wird ein aggressiver Servicelevel (SLA) für die zahlenden Kunden unterstützt, da sichergestellt ist, dass bei einem Ausfall nicht mehr als 50% der Mandantendatenbanken betroffen sind.
- Es ist sichergestellt, dass die Blockierung der neuen Testzugriffe sofort aufgehoben wird, sobald der Notfallwiederherstellungspool für Testkunden bei der Wiederherstellung erstellt wurde.
- Ermöglicht eine effizientere Nutzung der Poolkapazität, da 50 Prozent der sekundären Datenbanken in Pool 1 und Pool 2 garantiert weniger aktiv als die primären Datenbanken sind.
Nachteile
Die Hauptnachteile lauten:
- Die CRUD-Vorgänge für die Verwaltungsdatenbanken weisen für die Endbenutzer, die mit Region A verbunden sind, eine geringere Latenz als für die Endbenutzer auf, die mit Region B verbunden sind. Der Grund ist, dass sie für das primäre Replikat der Verwaltungsdatenbanken ausgeführt werden.
- Hierfür ist ein komplexeres Design der Verwaltungsdatenbank erforderlich. Beispielsweise verfügt jeder Mandantendatensatz über eine Standortkennzeichnung, die beim Failover und Failback geändert werden muss.
- Für die zahlenden Kunden kann sich die Leistung ggf. verschlechtern, bis das Poolupgrade in Region B abgeschlossen ist.
Zusammenfassung
In diesem Artikel geht es um die Notfallwiederherstellungsstrategien für die Datenbankebene, die für eine mehrinstanzenfähige SaaS-ISV-Anwendung verwendet werden. Die gewählte Strategie basiert auf den Anforderungen der Anwendung, z.B. dem Geschäftsmodell, dem SLA, das Sie Ihren Kunden anbieten möchten, Budgetbeschränkungen usw. Für jede Strategie werden die Vor- und Nachteile beschrieben, damit Sie eine fundierte Entscheidung treffen können. Ihre Anwendung umfasst wahrscheinlich noch weitere Azure-Komponenten. Sie beachten also die damit verbundenen Hinweise zur Geschäftskontinuität und orchestrieren die Wiederherstellung der Datenbankebene mit ihnen. Weitere Informationen zum Verwalten der Wiederherstellung von Datenbankanwendungen in Azure finden Sie unter Entwerfen von Cloudlösungen für die Notfallwiederherstellung.
Nächste Schritte
- Informationen zu automatisierten Sicherungen von Azure SQL-Datenbank finden Sie unter Automatisierte Sicherungen von Azure SQL-Datenbank.
- Eine Übersicht und verschiedene Szenarien zum Thema Geschäftskontinuität finden Sie unter Übersicht über die Geschäftskontinuität.
- Informationen zum Verwenden automatisierter Sicherungen für die Wiederherstellung finden Sie unter Wiederherstellen einer Datenbank aus vom Dienst initiierten Sicherungen.
- Informationen zu schnelleren Wiederherstellungsoptionen finden Sie unter Aktive Georeplikation und Failovergruppen.
- Informationen zum Verwenden automatisierter Sicherungen für die Archivierung finden Sie unter Datenbankkopie.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für