Verwalten von Verlaufsdaten in temporalen Tabellen mit einer Aufbewahrungsrichtlinie
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Temporale Tabellen können die Größe einer Datenbank ggf. mehr erhöhen als reguläre Tabellen. Dies gilt besonders, wenn Sie Verlaufsdaten über längere Zeiträume aufbewahren. Daher stellt eine Aufbewahrungsrichtlinie für Verlaufsdaten einen wichtigen Aspekt der Planung und Verwaltung des Lebenszyklus jeder temporalen Tabelle dar. Temporale Tabellen in Azure SQL-Datenbank und auf verwalteten Azure SQL-Instanzen verfügen über einen benutzerfreundlichen Aufbewahrungsmechanismus, der Sie bei dieser Aufgabe unterstützt.
Die Beibehaltung temporaler Verlaufsdaten kann auf den einzelnen Tabellenebenen konfiguriert werden, sodass Benutzer flexible Ablaufrichtlinien erstellen können. Das Anwenden der temporalen Beibehaltung ist einfach: Sie erfordert nur einen Parameter, der bei der Tabellenerstellung oder einer Schemaänderung festgelegt werden muss.
Nachdem Sie Beibehaltungsrichtlinien festgelegt haben, wird von Azure SQL-Datenbank und der verwalteten Azure SQL-Instanz in regelmäßigen Abständen überprüft, ob Zeilen mit Verlaufsdaten vorhanden sind, die für die automatische Datenbereinigung infrage kommen. Die Ermittlung übereinstimmender Zeilen und ihre Entfernung aus der Verlaufstabelle erfolgen transparent mithilfe eines vom System geplanten und ausgeführten Hintergrundtasks. Die Ablaufbedingungen für die Zeilen der Verlaufstabelle werden basierend auf der Spalte überprüft, die das Ende des SYSTEM_TIME-Zeitraums repräsentiert. Wenn die Beibehaltungsdauer beispielsweise auf sechs Monate festgelegt ist, erfüllen die für die Bereinigung infrage kommenden Zeilen folgende Bedingung:
ValidTo < DATEADD (MONTH, -6, SYSUTCDATETIME())
Im vorherigen Beispiel wird angenommen, dass die Spalte ValidTo dem Ende des SYSTEM_TIME-Zeitraums entspricht.
Konfigurieren der Aufbewahrungsrichtlinie
Bevor Sie die Aufbewahrungsrichtlinie für eine temporale Tabelle konfigurieren, überprüfen Sie zunächst, ob die temporale Verlaufsdatenaufbewahrung auf Datenbankebene aktiviert ist.
SELECT is_temporal_history_retention_enabled, name
FROM sys.databases
Das Datenbankflag Is_temporal_history_retention_enabled ist standardmäßig auf „ON“ festgelegt, aber Benutzer können dies mit der Anweisung ALTER DATABASE ändern. Nach dem Vorgang Point-in-Time-Wiederherstellung wird es außerdem automatisch auf OFF gesetzt. Um die Bereinigung der Beibehaltung temporaler Verlaufsdaten in Ihrer Datenbank zu aktivieren, führen Sie folgende Anweisung aus:
ALTER DATABASE [<myDB>]
SET TEMPORAL_HISTORY_RETENTION ON
Wichtig
Sie können die Aufbewahrungsdauer für temporale Tabellen selbst dann konfigurieren, wenn is_temporal_history_retention_enabled auf „OFF“ festgelegt ist. In diesem Fall wird jedoch keine automatische Bereinigung veralteter Zeilen ausgelöst.
Die Beibehaltungsrichtlinien werden während der Tabellenerstellung konfiguriert, indem ein Wert für den Parameter HISTORY_RETENTION_PERIOD angegeben wird:
CREATE TABLE dbo.WebsiteUserInfo
(
[UserID] int NOT NULL PRIMARY KEY CLUSTERED
, [UserName] nvarchar(100) NOT NULL
, [PagesVisited] int NOT NULL
, [ValidFrom] datetime2 (0) GENERATED ALWAYS AS ROW START
, [ValidTo] datetime2 (0) GENERATED ALWAYS AS ROW END
, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo)
)
WITH
(
SYSTEM_VERSIONING = ON
(
HISTORY_TABLE = dbo.WebsiteUserInfoHistory,
HISTORY_RETENTION_PERIOD = 6 MONTHS
)
);
Bei Azure SQL-Datenbank und verwalteten Azure SQL-Instanzen können Sie den Aufbewahrungszeitraum mit unterschiedlichen Zeiteinheiten angeben: TAGE, WOCHEN, MONATE und JAHRE. Wenn HISTORY_RETENTION_PERIOD weggelassen wird, wird von einer unbegrenzten (INFINITE) Beibehaltung ausgegangen. Sie können das Schlüsselwort INFINITE auch explizit verwenden.
In manchen Szenarios sollten Sie die Beibehaltung erst nach der Tabellenerstellung konfigurieren oder den zuvor konfigurierten Wert ändern. Verwenden Sie für diesen Fall die Anweisung ALTER TABLE:
ALTER TABLE dbo.WebsiteUserInfo
SET (SYSTEM_VERSIONING = ON (HISTORY_RETENTION_PERIOD = 9 MONTHS));
Wichtig
Wenn Sie SYSTEM_VERSIONING auf OFF setzen, bleibt der Wert für die Beibehaltungsdauer nicht erhalten. Wenn Sie SYSTEM_VERSIONING auf ON setzen, ohne explizit HISTORY_RETENTION_PERIOD anzugeben, führt dies zu einer unbegrenzten Beibehaltungsdauer (INFINITE).
Zum Prüfen des aktuellen Status der Beibehaltungsrichtlinie verwenden Sie die folgende Abfrage, die das Flag für die Aktivierung der temporalen Beibehaltung auf Datenbankebene mit den Beibehaltungszeiträumen für die einzelnen Tabellen verknüpft:
SELECT DB.is_temporal_history_retention_enabled,
SCHEMA_NAME(T1.schema_id) AS TemporalTableSchema,
T1.name as TemporalTableName, SCHEMA_NAME(T2.schema_id) AS HistoryTableSchema,
T2.name as HistoryTableName,T1.history_retention_period,
T1.history_retention_period_unit_desc
FROM sys.tables T1
OUTER APPLY (select is_temporal_history_retention_enabled from sys.databases
where name = DB_NAME()) AS DB
LEFT JOIN sys.tables T2
ON T1.history_table_id = T2.object_id WHERE T1.temporal_type = 2
Löschen von veralteten Zeilen
Der Bereinigungsprozess hängt vom Indexlayout der Verlaufstabelle ab. Zu beachten ist, dass eine Richtlinie für die begrenzte Beibehaltung nur für Verlaufstabellen mit einem gruppierten Index (B-Struktur oder Columnstore) konfiguriert werden können. Es wird ein Hintergrundtask erstellt, um die Bereinigung veralteter Daten für alle temporalen Tabellen mit begrenztem Beibehaltungszeitraum auszuführen. Die Bereinigungslogik für den gruppierten Index für Rowstore (B-Struktur) löscht veraltete Zeilen in kleineren Blöcken (max. 10.000), was die Belastung des Datenbankprotokolls und des E/A-Subsystems minimiert. Die Bereinigungslogik verwendet zwar den benötigten B-Strukturindex, jedoch kann die Löschreihenfolge der Zeilen, die den Beibehaltungszeitraum übersteigen, nicht sicher garantiert werden. Verwenden Sie in Ihren Anwendungen daher keine Abhängigkeit von der Bereinigungsreihenfolge.
Der Bereinigungstask für den gruppierten Columnstore entfernt ganze Zeilengruppen gleichzeitig (die üblicherweise jeweils 1 Mio. Zeilen enthalten). Dies ist sehr effizient, vor allem dann, wenn mit einer hohen Geschwindigkeit Verlaufsdaten generiert werden.
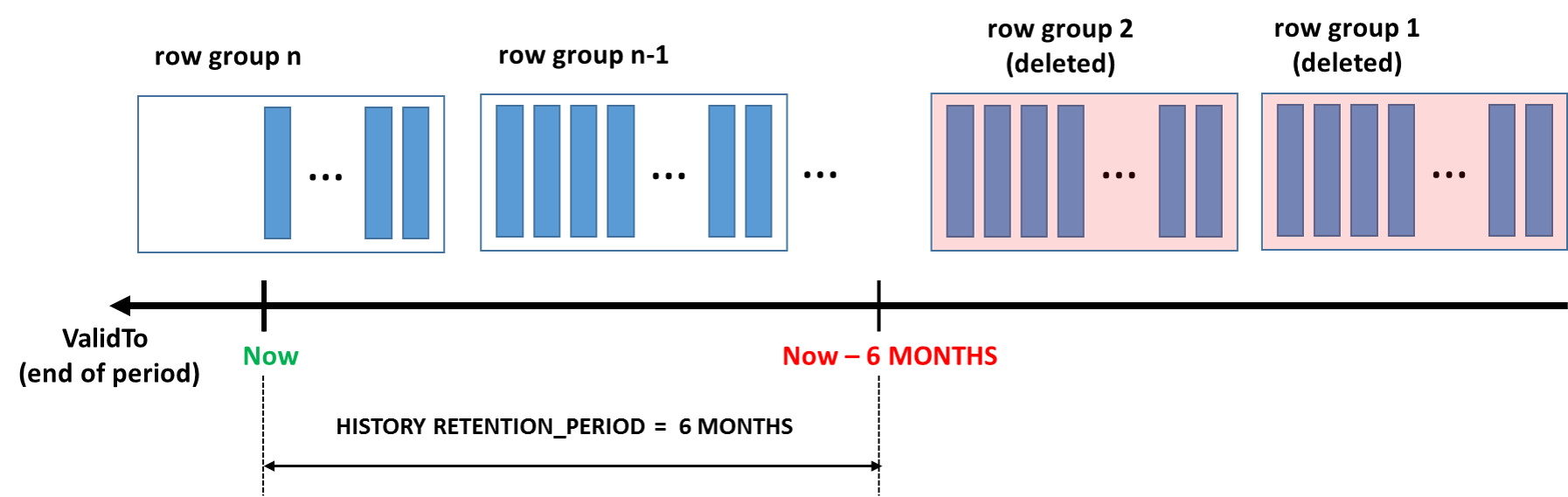
Die hervorragende Datenkompression und die effiziente Beibehaltungsbereinigung machen den gruppierten Columnstore-Index zur perfekten Lösung für Szenarios, bei denen Ihre Workload in kürzester Zeit eine große Menge an Verlaufsdaten generiert. Dieses Muster ist typisch für intensive Transaktionsverarbeitungs-Workloads, die temporale Tabellen verwenden, um die Änderungsnachverfolgung und -überwachung, Trendanalysen oder die Erfassung von IoT-Daten durchzuführen.
Überlegungen bezüglich des Index
Beim Bereinigungstask für Tabellen mit gruppiertem Rowstore-Index muss der Index mit der Spalte beginnen, die dem Ende des SYSTEM_TIME-Zeitraums entspricht. Wenn kein solcher Index vorhanden ist, können Sie keine begrenzte Beibehaltungsdauer konfigurieren:
Meldung 13765, Ebene 16, Status 1
Festlegen einer unbegrenzten Beibehaltungsdauer bei der temporalen Tabelle mit Systemversionsverwaltung 'temporalstagetestdb.dbo.WebsiteUserInfo' fehlgeschlagen, da die Verlaufstabelle 'temporalstagetestdb.dbo.WebsiteUserInfoHistory' nicht den erforderlichen gruppierten Index enthält. Sie könnten nun für die Verlaufstabelle einen gruppierten Columnstore- oder B-Strukturindex erstellen, der mit der Spalte beginnt, die mit dem Ende des SYSTEM_TIME-Zeitraums entspricht.
Hierbei ist zu beachten, dass die von Azure SQL-Datenbank und der verwalteten Azure SQL-Instanz erstellte Standardverlaufstabelle bereits einen gruppierten Index enthält, der mit der Aufbewahrungsrichtlinie konform ist. Wenn Sie versuchen, diesen Index für eine Tabelle mit begrenzte Beibehaltungsdauer zu entfernen, schlägt der Vorgang mit folgender Fehlermeldung fehl:
Meldung 13766, Ebene 16, Status 1
Der gruppierte Index „WebsiteUserInfoHistory.IX_WebsiteUserInfoHistory“ kann nicht gelöscht werden, da er für die automatische Bereinigung von veralteten Daten verwendet wird. Consider setting HISTORY_RETENTION_PERIOD to INFINITE on the corresponding system-versioned temporal table if you need to drop this index. (Der gruppierte Index "WebsiteUserInfoHistory.IX_WebsiteUserInfoHistory" kann nicht entfernt werden, da er für die automatische Bereinigung veralteter Daten verwendet wird. Legen Sie ggf. "HISTORY_RETENTION_PERIOD" für die zugehörige temporale Tabelle mit Systemversionsverwaltung auf "INFINITE" fest, wenn Sie diesen Index entfernen müssen.)
Die Bereinigung des gruppierten Columnstore-Index funktioniert optimal, wenn Zeilen mit Verlaufsdaten in aufsteigender Reihenfolge (geordnet nach der Periodenende-Spalte) eingefügt werden, was immer dann der Fall ist, wenn die Verlaufstabelle ausschließlich mithilfe des Mechanismus SYSTEM_VERSIONING gefüllt wird. Wenn Zeilen in der Verlaufstabelle nicht nach der Periodenende-Spalte sortiert sind (was beim Migrieren vorhandener Verlaufsdaten der Fall sein kann), sollten Sie den gruppierten Columnstore-Index auf Basis des ordnungsgemäß sortierten B-Struktur-Rowstore-Index neu erstellen, um eine optimale Leistung zu erzielen.
Vermeiden Sie eine Neuerstellung des gruppierten Columnstore-Index für die Verlaufstabelle mit begrenzter Beibehaltungsdauer, da hierdurch die Reihenfolge der Zeilengruppen verändert werden kann, die durch die Systemversionsverwaltung automatisch auferlegt wurde. Wenn Sie den gruppierten Columnstore-Index für die Verlaufstabelle neu erstellen müssen, erstellen Sie ihn hierzu auf Basis des kompatiblen B-Strukturindex neu. So behalten Sie die Reihenfolge der Zeilengruppen bei, die für eine regelmäßige Datenbereinigung erforderlich ist. Derselbe Ansatz sollte gewählt werden, wenn Sie eine temporale Tabelle mit einer vorhandenen Verlaufstabelle erstellen, die über einen gruppierten Spaltenindex ohne garantierte Datenreihenfolge verfügt:
/*Create B-tree ordered by the end of period column*/
CREATE CLUSTERED INDEX IX_WebsiteUserInfoHistory ON WebsiteUserInfoHistory (ValidTo)
WITH (DROP_EXISTING = ON);
GO
/*Re-create clustered columnstore index*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_WebsiteUserInfoHistory ON WebsiteUserInfoHistory
WITH (DROP_EXISTING = ON);
Wenn eine begrenzte Beibehaltungsdauer für die Verlaufstabelle mit dem gruppierten Columnstore-Index konfiguriert ist, können Sie keine zusätzlichen ungruppierten B-Strukturindizes für diese Tabelle erstellen:
CREATE NONCLUSTERED INDEX IX_WebHistNCI ON WebsiteUserInfoHistory ([UserName])
Der Versuch, die obige Anweisung auszuführen, ist nicht erfolgreich, und es wird folgende Fehlermeldung ausgegeben:
Meldung 13772, Ebene 16, Status 1
Nicht-gruppierter Index kann für temporale Verlaufstabelle 'WebsiteUserInfoHistory' nicht erstellt werden, da sie eine begrenzte Beibehaltungsdauer hat und ein gruppierter Columnstore-Index definiert wurde.
Abfragen von Tabellen mit Aufbewahrungsrichtlinie
Alle Abfragen für die temporale Tabelle filtern automatisch Zeilen mit Verlaufsdaten aus, die der begrenzten Aufbewahrungsrichtlinie entsprechen, um unvorhersehbare und inkonsistente Ergebnisse zu vermeiden, da veraltete Zeilen jederzeit und in beliebiger Reihenfolge durch den Bereinigungstask gelöscht werden können.
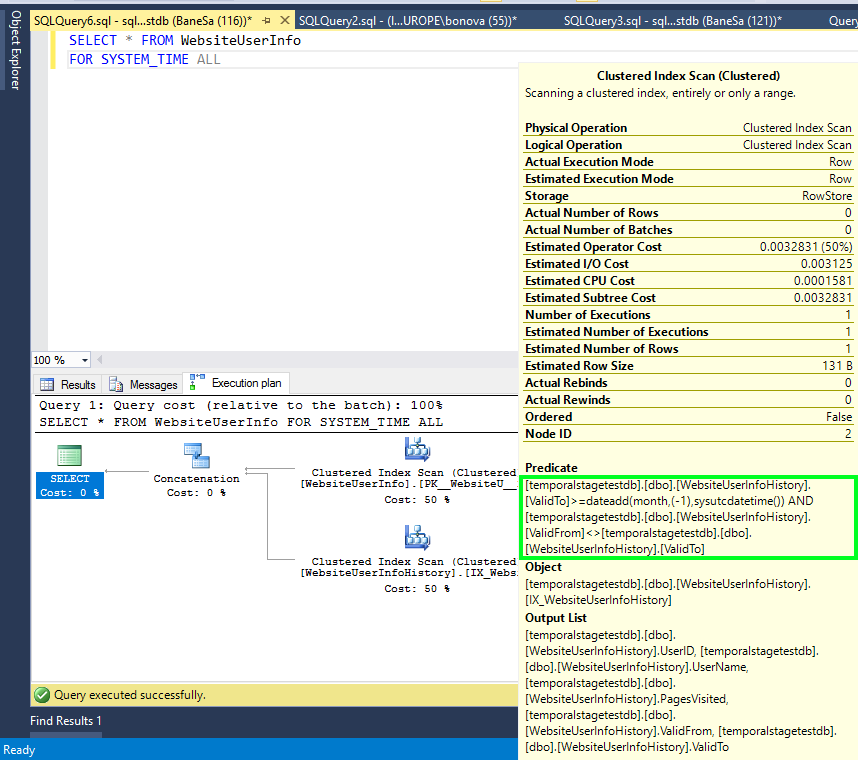
Das folgende Bild zeigt den Abfrageplan für eine einfache Abfrage:
SELECT * FROM dbo.WebsiteUserInfo FOR SYSTEM_TIME ALL;
Der Abfrageplan enthält einen zusätzlichen Filter, der auf die Spalte mit dem Zeitraumende (ValidTo) im Operator „Clustered Index Scan“ für die Verlaufstabelle angewendet wird (siehe Hervorhebung). In diesem Beispiel wird davon ausgegangen, dass in der Tabelle „WebsiteUserInfo“ eine Beibehaltungsdauer von einem MONAT festgelegt wurde.
Wenn Sie allerdings die Verlaufstabelle direkt abfragen, sehen Sie möglicherweise Zeilen, die älter sind als die angegebene Beibehaltungsdauer – allerdings ohne Garantie für wiederholbare Abfrageergebnisse. Das folgende Bild zeigt den Abfrageausführungsplan für die Abfrage der Verlaufstabelle, ohne dass zusätzliche Filter angewandt werden:
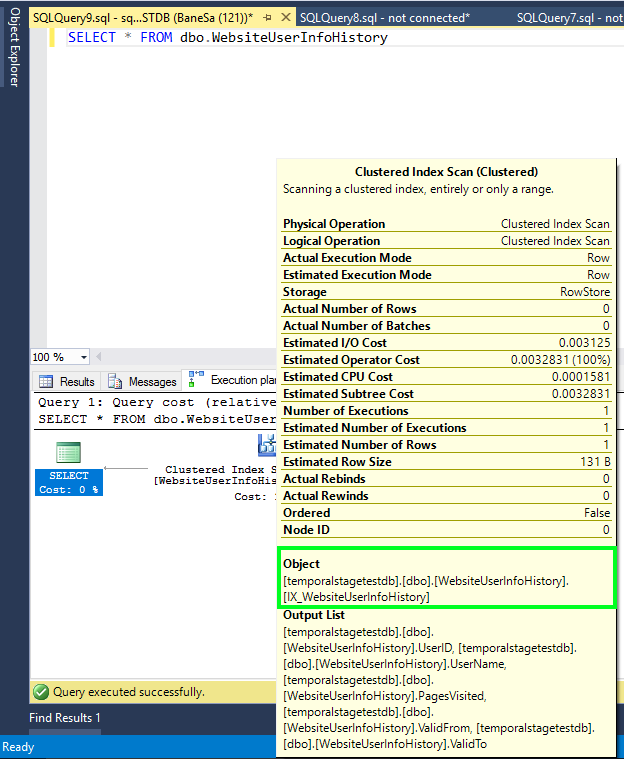
Basieren Sie Ihre Geschäftslogik nicht auf das Lesen der Verlaufstabelle nach der Beibehaltungsdauer, da Sie inkonsistente oder unerwartete Ergebnisse erhalten könnten. Es empfiehlt sich, temporale Abfragen mit der Klausel „FOR SYSTEM_TIME“ zu verwenden, um Daten in temporalen Tabellen zu analysieren.
Überlegungen zur Point-in-Time-Wiederherstellung
Wenn Sie eine neue Datenbank erstellen, indem Sie eine vorhandene Datenbank zu einem bestimmten Zeitpunkt wiederherstellen, ist die temporale Beibehaltungsdauer auf Datenbankebene deaktiviert. (Das Flag is_temporal_history_retention_enabled ist auf OFF gesetzt.) Mit dieser Funktion können Sie bei der Wiederherstellung alle Zeilen mit Verlaufsdaten untersuchen, ohne dass veraltete Zeilen entfernt werden, bevor Sie diese abfragen können. Sie können diese Funktion verwenden, um Verlaufsdaten außerhalb der konfigurierten Beibehaltungsdauer zu überprüfen.
Ein Beispiel: Für eine temporale Tabelle wurde eine Beibehaltungsdauer von einem MONAT angegeben. Wenn Ihre Datenbank im Premium-Tarif erstellt wurde, könnten Sie eine Datenbankkopie mit dem Status der Datenbank vor 35 Tagen erstellen. So könnten Sie effektiv Zeilen mit Verlaufsdaten analysieren, die bis zu 65 Tage alt sind, indem Sie die Verlaufstabelle direkt abfragen.
Wenn Sie die temporale Aufbewahrungsbereinigung aktivieren möchten, führen Sie die folgende Transact-SQL-Anweisung nach der Point-in-Time-Wiederherstellung aus:
ALTER DATABASE [<myDB>]
SET TEMPORAL_HISTORY_RETENTION ON
Nächste Schritte
Informationen zur Verwendung temporaler Tabellen in Ihren Anwendungen finden Sie unter Erste Schritte mit temporalen Tabellen.
Ausführliche Informationen zu temporalen Tabellen finden Sie unter Temporale Tabellen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für