Konfigurieren einer Failovergruppe für eine verwaltete SQL-Instanz
Gilt für:![]() Azure SQL Managed Instance
Azure SQL Managed Instance
In diesem Artikel wird erläutert, wie Sie eine Failovergruppe für Azure SQL Managed Instance über das Azure-Portal und Azure PowerShell konfigurieren.
Wenn Sie ein End-to-End-PowerShell-Skript zum Erstellen beider Instanzen innerhalb einer Failovergruppe benötigen, lesen Sie Instanz zu einer Failovergruppe hinzufügen.
Voraussetzungen
Beachten Sie die folgenden erforderlichen Voraussetzungen:
- Die sekundäre verwaltete Instanz muss leer sein, d. h. sie darf keine Benutzerdatenbanken enthalten.
- Die beiden Instanzen von SQL Managed Instance müssen dieselbe Dienstebene und Speichergröße aufweisen. Auch wenn dies nicht erforderlich ist, wird dringend empfohlen, dass zwei Instanzen die gleiche Computegröße aufweisen, um sicherzustellen, dass die sekundäre Instanz die Änderungen, die von der primären Instanz repliziert werden, dauerhaft verarbeiten kann, auch in Zeiten hoher Aktivität.
- Der Adressbereich für das virtuelle Netzwerk der primären Instanz darf sich nicht mit dem Adressbereich des virtuellen Netzwerks für die sekundäre verwaltete Instanz, die Sie erstellen möchten, und mit keinem anderen virtuellen Netzwerk, das mit dem primären oder sekundären virtuellen Netzwerk verbunden ist, überschneiden.
- Wenn Sie Ihre sekundäre verwaltete Instanz erstellen, müssen Sie die DNS-Zonen-ID der primären Instanz als Wert des
DnsZonePartnerParameters angeben. Wenn Sie keinen Wert fürDnsZonePartnerangeben, wird die Zonen-ID als zufällige Zeichenfolge generiert, wenn die erste Instanz in jedem virtuellen Netzwerk erstellt wird, und dieselbe ID wird allen anderen Instanzen im selben Subnetz zugewiesen. Nach der Zuweisung kann die DNS-Zone nicht geändert werden. - Die Regeln der Netzwerksicherheitsgruppen (NSG) auf dem Subnetz, das die Instanz hostet, müssen Port 5022 (TCP) und den Portbereich 11000-11999 (TCP) für ein- und ausgehende Verbindungen von und zu dem Subnetz, das die andere verwaltete Instanz hostet, offen halten. Dies gilt für beide Subnetze, die primäre und die sekundäre Instanz.
- Sortierung und Zeitzone der sekundären verwalteten Instanz müssen mit denen der primären verwalteten Instanz übereinstimmen.
- Verwaltete Instanzen sollten aus Leistungsgründen in Regionspaaren bereitgestellt werden. Verwaltete Instanzen, die sich in geografischen Regionspaaren befinden, profitieren im Vergleich zu nicht gekoppelten Regionen von einer deutlich höheren Geschwindigkeit der Georeplikation.
Größe des Adressraums
Um den Adressraum der primären Instanz zu überprüfen, gehen Sie zu der virtuellen Netzwerkressource für die primäre Instanz und wählen Sie Adressraum unter Einstellungen. Überprüfen Sie den Bereich unter Adressbereich:
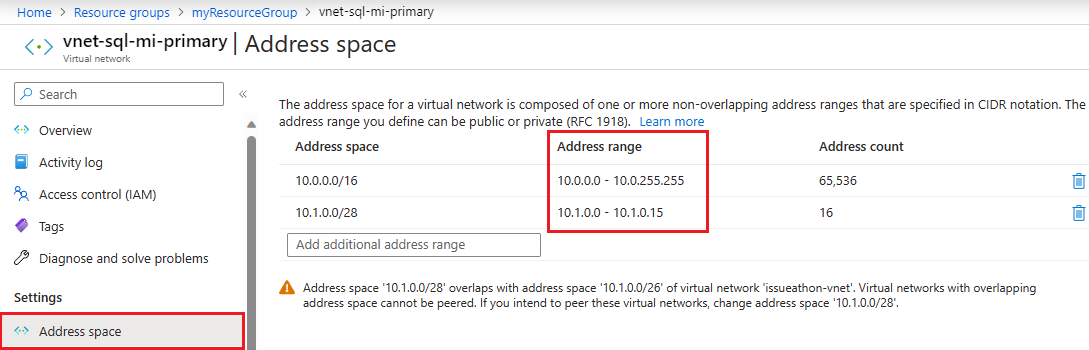
Angeben der Zonen-ID der primären Instanz
Wenn Sie Ihre sekundäre Instanz erstellen, müssen Sie die Zonen-ID der primären Instanz als die DnsZonePartner.
Wenn Sie Ihre sekundäre Instanz im Azure-Portal erstellen, wählen Sie auf der Registerkarte Zusätzliche Einstellungen unter Georeplikation den Eintrag Ja zur Verwendung als sekundärer Failover und wählen Sie dann die primäre Instanz aus der Dropdown-Liste aus:
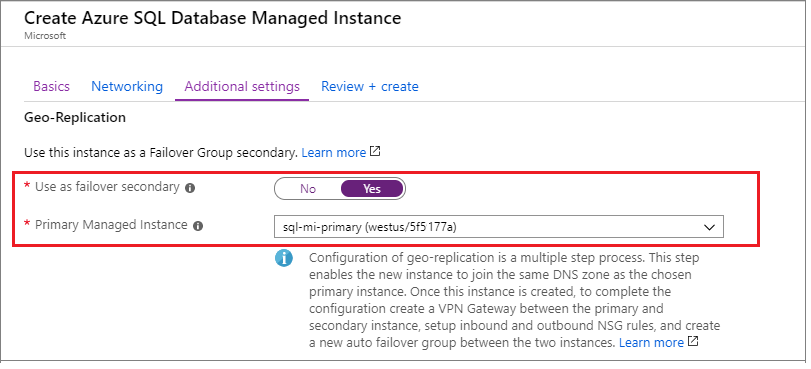
Aktivieren der Konnektivität zwischen den Instanzen
Die Konnektivität zwischen den Subnetzen des virtuellen Netzwerks, die die primäre und sekundäre Instanz hosten, muss für den unterbrechungsfreien Datenverkehrsflow für die Georeplikation eingerichtet werden. Es gibt mehrere Möglichkeiten, Konnektivität zwischen verwalteten Instanzen in verschiedenen Azure-Regionen herzustellen, darunter:
- Globales Peering virtueller Netzwerke
- Azure ExpressRoute
- VPN-Gateways
Globales Peering virtueller Netzwerke wird als die leistungsfähigste und robusteste Methode zum Einrichten der Konnektivität empfohlen. Es bietet eine private Verbindung mit geringer Latenz und hoher Bandbreite zwischen den virtuellen Netzwerken mit Peering mithilfe der Microsoft-Backbone-Infrastruktur. Für die Kommunikation zwischen virtuellen Netzwerken mit Peering wird kein öffentliches Internet, keine Gateways und keine zusätzliche Verschlüsselung benötigt.
Wichtig
Alternative Methoden zum Verbinden von Instanzen, die zusätzliche Netzwerkgeräte umfassen, können die Problembehandlung bei Der Konnektivität oder Replikationsgeschwindigkeit erschweren, möglicherweise die aktive Einbindung von Netzwerkadministratoren und potenziell eine erhebliche Verlängerung der Auflösungszeit.
Unabhängig vom Konnektivitätsmechanismus müssen Anforderungen erfüllt sein, damit der Datenverkehr für die Georeplikation fließt:
- Routingtabellen und Netzwerksicherheitsgruppen, die den Subnetzen der verwalteten Instanzen zugewiesen sind, werden nicht von den beiden virtuellen Netzwerken mit Peer-Rechten gemeinsam genutzt.
- Die Regeln für die Netzwerksicherheitsgruppe (NSG) im Subnetz, das die primäre Instanz hostet, lassen Folgendes zu:
- Eingehenden Datenverkehr aus dem Subnetz, das die sekundäre Instanz hostet, auf Port 5022 und im Portbereich 11000-11999.
- Ausgehenden Datenverkehr zum Subnetz, das die sekundäre Instanz hostet, auf Port 5022 und im Portbereich 11000-11999.
- Die Regeln für die Netzwerksicherheitsgruppe (NSG) im Subnetz, das die sekundäre Instanz hostet, lassen Folgendes zu:
- Eingehenden Datenverkehr aus dem Subnetz, das die primäre Instanz hostet, auf Port 5022 und im Portbereich 11000-11999.
- Ausgehenden Datenverkehr zum Subnetz, das die primäre Instanz hostet, auf Port 5022 und im Portbereich 11000-11999.
- IP-Adressbereiche von VNets, die die primäre und sekundäre Instanz hosten, dürfen sich nicht überlappen.
- Es gibt keine indirekte Überlappung des IP-Adressbereichs zwischen den VNets, die die primäre und sekundäre Instanz hosten, oder anderen VNets, mit denen sie über das lokale Peering virtueller Netzwerk oder andere Wege verbunden sind.
Wenn Sie außerdem weitere Mechanismen zum Bereitstellen der Konnektivität zwischen den Instanzen als dem empfohlenen globalen Peering virtueller Netzwerke verwenden, müssen Sie Folgendes sicherstellen:
- Keine der verwendeten Netzwerkgeräte wie Firewalls oder virtuelle Netzwerkgeräte (NVAs) blockieren den oben beschriebenen Datenverkehr.
- Das Routing ist ordnungsgemäß konfiguriert, und asymmetrisches Routing wird vermieden.
- Wenn Sie Failovergruppen in einer regionsübergreifenden Hub-and-Spoke-Netzwerktopologie bereitstellen, sollte der Replikationsverkehr direkt zwischen den beiden Subnetzen verwalteter Instanzen und nicht über die Hubnetzwerke geleitet werden. Dies hilft Ihnen, Geschwindigkeitsprobleme in Bezug auf Konnektivität und Replikation zu vermeiden.
- Navigieren Sie im Azure-Portal zur Ressource Virtuelles Netzwerk für Ihre primäre verwaltete Instanz.
- Wählen Sie Peerings unter Einstellungen aus, und wählen Sie dann „+ Hinzufügen“ aus.
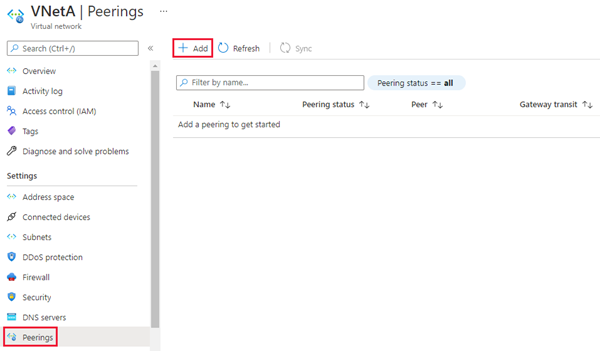
Geben Sie Werte für folgende Einstellungen ein, oder wählen Sie sie aus:
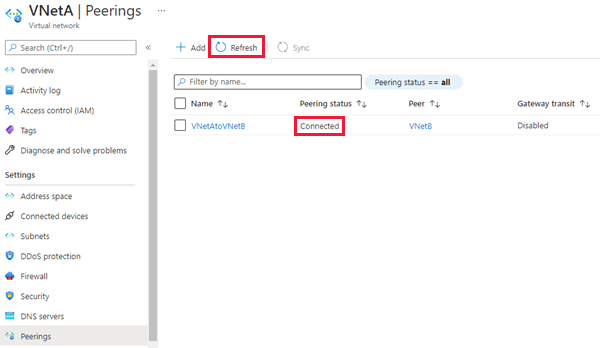
Einstellungen Beschreibung Dieses virtuelle Netzwerk Name des Peeringlinks Der Name für das Peering muss innerhalb des virtuellen Netzwerks eindeutig sein. Datenverkehr zum virtuellen Remotenetzwerk Wählen Sie Zulassen (Standard) aus, um die Kommunikation zwischen beiden virtuellen Netzwerken über den Standardflow VirtualNetworkzu aktivieren. Durch die Aktivierung der Kommunikation zwischen virtuellen Netzwerken können Ressourcen, die mit einem der beiden virtuellen Netzwerke verbunden sind, mit derselben Bandbreite und Latenz kommunizieren, als ob sie mit demselben virtuellen Netzwerk verbunden wären. Die gesamte Kommunikation zwischen Ressourcen in den beiden virtuellen Netzwerken erfolgt über das private Azure-Netzwerk.Traffic forwarded from remote virtual network (Vom virtuellen Remotenetzwerk weitergeleiteter Datenverkehr) Für dieses Tutorial funktionieren sowohl die Option Zulässig (Standard) als auch die Option Blockieren. Weitere Informationen finden Sie unter Erstellen eines Peerings Gateway oder Routenserver des virtuellen Netzwerks Wählen Sie Keine. Weitere Informationen zu den anderen verfügbaren Optionen finden Sie unter Erstellen eines Peerings. Virtuelles Remotenetzwerk Name des Peeringlinks Der Name desselben Peerings, das in dem virtuellen Netzwerk verwendet werden soll, das die sekundäre Instanz hostet. Bereitstellungsmodell für das virtuelle Netzwerk Wählen Sie Ressourcen-Manager aus. Ich kenne meine Ressourcen-ID Lassen Sie dieses Kontrollkästchen deaktiviert. Subscription Wählen Sie die Azure-Subscription des virtuellen Netzwerks aus, das die sekundäre Instanz hostet, mit der Sie ein Peering durchführen möchten. Virtuelles Netzwerk Wählen Sie das virtuelle Netzwerk aus, das die sekundäre Instanz hostet, mit der Sie ein Peering durchführen möchten. Wenn das virtuelle Netzwerk aufgeführt wird, jedoch ausgegraut ist, überschneidet sich der Adressraum des virtuellen Netzwerks möglicherweise mit dem Adressraum dieses virtuellen Netzwerks. Wenn sich die Adressräume des virtuellen Netzwerks überschneiden, können diese nicht mittels Peering verknüpft werden. Datenverkehr zum virtuellen Remotenetzwerk Wählen Sie Zulassen (Standard) aus Traffic forwarded from remote virtual network (Vom virtuellen Remotenetzwerk weitergeleiteter Datenverkehr) Für dieses Tutorial funktionieren sowohl die Option Zulässig (Standard) als auch die Option Blockieren. Weitere Informationen finden Sie unter Erstellen eines Peerings. Gateway oder Routenserver des virtuellen Netzwerks Wählen Sie Keine. Weitere Informationen zu den anderen verfügbaren Optionen finden Sie unter Erstellen eines Peerings. Wählen Sie Hinzufügen aus, um das Peering mit dem ausgewählten virtuellen Netzwerk zu konfigurieren. Wählen Sie nach einigen Sekunden die Schaltfläche Aktualisieren aus, und der Peeringstatus ändert sich von Wird aktualisiert in Verbunden.
Erstellen der Failovergruppe
Erstellen Sie die Failovergruppe für Ihre verwalteten Instanzen mithilfe des Azure-Portals oder PowerShell.
Erstellen Sie die Failovergruppe für Ihre verwalteten Azure SQL-Instanzen mithilfe des Azure-Portals.
Wählen Sie im linken Menü im Azure-Portal die Option Azure SQL aus. Wenn Azure SQL nicht in der Liste aufgeführt wird, wählen Sie Alle Dienste aus, und geben Sie dann im Suchfeld „Azure SQL“ ein. (Optional) Wählen Sie den Stern neben Azure SQL aus, um es als bevorzugtes Element im linken Navigationsbereich hinzuzufügen.
Wählen Sie die primäre verwaltete Instanz aus, die Sie der Failovergruppe hinzufügen möchten.
Navigieren Sie unter Einstellungen zu Instanzfailovergruppen, und wählen Sie dann Gruppe hinzufügen aus, um die Seite für die Erstellung der Instanzfailovergruppe zu öffnen.
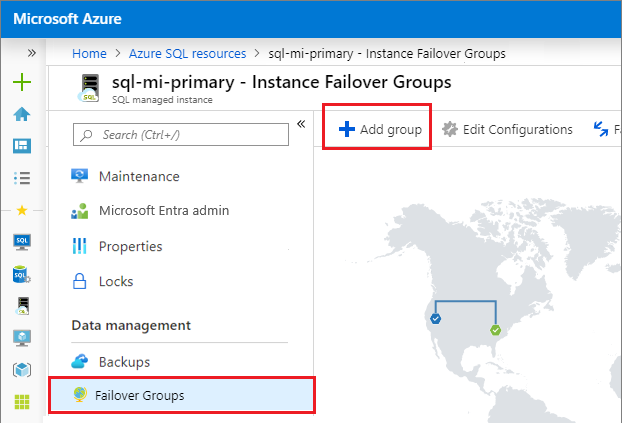
Geben Sie auf der Seite Instanzfailovergruppe den Namen Ihrer Failovergruppe ein, und wählen Sie dann im Dropdownmenü die sekundäre verwaltete Instanz aus. Wählen Sie Erstellen aus, um die Failovergruppe zu erstellen.
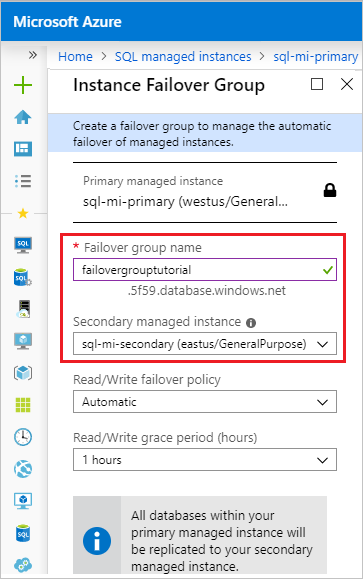
Nachdem die Bereitstellung der Failovergruppe abgeschlossen wurde, gelangen Sie erneut auf die Seite Failovergruppe.
Testfailover
Testen Sie das Failover Ihrer Failovergruppe mithilfe des Azure-Portals oder PowerShell.
Testen Sie das Failover Ihrer Failovergruppe mithilfe des Azure-Portals.
Navigieren Sie im Azure-Portal zu Ihrer sekundären verwalteten Instanz, und wählen Sie unter „Einstellungen“ die Option Instanzfailovergruppen aus.
Beachten Sie die verwalteten Instanzen in der primären und in der sekundären Rolle.
Wählen Sie Failover aus, und klicken Sie dann in der Warnung zu TDS-Sitzungen, die getrennt werden, auf Ja.
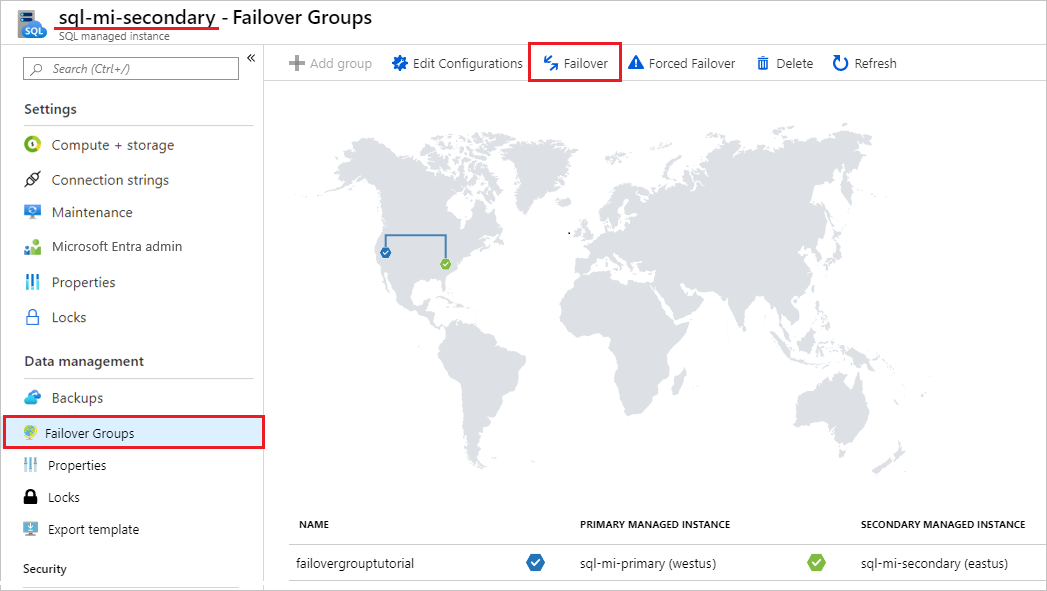
Beachten Sie die verwalteten Instanzen in der primären und in der sekundären Rolle. Wenn das Failover erfolgreich ausgeführt wurde, sollten die beiden Instanzen die Rollen getauscht haben.

Wichtig
Wenn die Rollen nicht gewechselt wurden, überprüfen Sie die Konnektivität zwischen den Instanzen und den zugehörigen NSG- und Firewallregeln. Fahren Sie erst nach dem Rollenwechsel mit dem nächsten Schritt fort.
- Navigieren Sie zur neuen sekundären verwalteten Instanz, und wählen Sie erneut Failover aus, um ein Failback der primären Instanz auf die primäre Rolle durchzuführen.
Listenerendpunkt suchen
Nachdem die Failovergruppe konfiguriert wurde, aktualisieren Sie die Verbindungszeichenfolge für die Anwendung auf den Listenerendpunkt. Dadurch bleibt Ihre Anwendung mit dem Listener der Failovergruppe verbunden und nicht mit der primären Datenbank, dem Elastic Pool oder der Instanzdatenbank. Auf diesen Weise brauchen Sie die Verbindungszeichenfolge nicht bei jedem Failover Ihrer Datenbankentität manuell zu aktualisieren, und der Datenverkehr wird immer zu der Entität geroutet, die aktuell die primäre ist.
Der Listenerendpunkt hat die Form fog-name.database.windows.net und ist beim Anzeigen der Failovergruppe im Azure-Portal sichtbar:

Erstellen einer Gruppe zwischen Instanzen in verschiedenen Subscriptions
Sie können eine Failovergruppe zwischen SQL Managed Instances in zwei verschiedenen Subscriptions erstellen, solange Subscriptions dem gleichen Microsoft Entra-Mandanten zugeordnet sind.
- Wenn Sie die PowerShell-API verwenden, können Sie dazu den Parameter
PartnerSubscriptionIdfür die sekundäre SQL Managed Instance angeben. - Wenn Sie die REST-API verwenden, kann jede im Parameter
properties.managedInstancePairsenthaltene Instanz-ID eine eigene Subscription-ID haben. - Das Erstellen von Failovergruppen über verschiedene Subscriptions hinweg wird im Azure-Portal nicht unterstützt.
Wichtig
Das Erstellen von Failovergruppen über verschiedene Subscriptions hinweg wird im Azure-Portal nicht unterstützt. Für die Failovergruppen in verschiedenen Subscriptions oder Ressourcengruppen kann das Failover von der primären Instanz von SQL Managed Instance aus nicht manuell im Azure-Portal initiiert werden. Initiieren Sie das Failover stattdessen über die sekundäre Geoinstanz.
Verhinderung des Verlusts kritischer Daten
Aufgrund der hohen Latenzzeit von WANs verwendet die Georeplikation einen asynchronen Replikationsmechanismus. Bei der asynchronen Replikation ist die Möglichkeit eines Datenverlusts unvermeidbar, wenn die primäre Datenbank ausfällt. Zum Schutz kritischer Transaktionen vor Datenverlust, kann ein Anwendungsentwickler die gespeicherte Prozedur sp_wait_for_database_copy_sync unmittelbar nach dem Commit der Transaktion aufrufen. Der Aufruf von sp_wait_for_database_copy_sync blockiert den aufrufenden Thread, bis die letzte committete Transaktion übertragen und im Transaktionsprotokoll der sekundären Datenbank gehärtet wurde. Er wartet jedoch nicht darauf, dass die übertragenen Transaktionen in der sekundären Datenbank wiedergegeben (wiederholt) werden. sp_wait_for_database_copy_sync ist auf eine bestimmte Georeplikationslink beschränkt. Jeder Benutzer mit den Rechten zum Herstellen der Verbindung mit der primären Datenbank kann diese Prozedur aufrufen.
Notiz
sp_wait_for_database_copy_sync verhindert Datenverluste nach einem Geofailover für bestimmte Transaktionen, garantiert aber keine vollständige Synchronisierung für Lesezugriffe. Die durch einen sp_wait_for_database_copy_sync-Prozeduraufruf verursachte Verzögerung kann beträchtlich sein und hängt von der Größe des noch nicht übertragenen Transaktionsprotokolls auf der Primärseite zum Zeitpunkt des Aufrufs ab.
Ändern der sekundären Region
Angenommen, Instanz A ist die primäre Instanz, Instanz B die vorhandene sekundäre Instanz und Instanz C die neue sekundäre Instanz in der dritten Region. Führen Sie diese Schritte aus, um die Umstellung durchzuführen:
- Erstellen Sie Instanz C mit der gleichen Größe wie A und in derselben DNS-Zone.
- Löschen Sie die Failovergruppe zwischen den Instanzen A und B. An diesem Punkt treten bei Anmeldungen Fehler auf, weil die SQL-Aliase für die Failovergruppenlistener gelöscht wurden und das Gateway den Namen der Failovergruppe nicht erkennt. Die sekundären Datenbanken werden von den primären Replikaten getrennt und werden zu Datenbanken mit Lese-/Schreibzugriff.
- Erstellen Sie eine Failovergruppe mit dem gleichen Namen zwischen Instanz A und C. Befolgen Sie die Anleitung im Tutorial zu Failovergruppen mit verwalteten Instanzen. Dies ist ein Vorgang, bei dem der Umfang der Daten eine Rolle spielt. Er ist abgeschlossen, wenn für alle Datenbanken von Instanz A das Seeding und die Synchronisierung durchgeführt wurde.
- Löschen Sie Instanz B, wenn sie nicht benötigt wird, um unnötige Kosten zu vermeiden.
Notiz
Nach Schritt 2 und bis zum Abschluss von Schritt 3 sind die Datenbanken auf Instanz A vor dem Ausfall von Instanz A aufgrund eines Katastrophenfalls ungeschützt.
Ändern der primären Region
Angenommen, Instanz A ist die primäre Instanz, Instanz B die vorhandene sekundäre Instanz und Instanz C die neue primäre Instanz in der dritten Region. Führen Sie diese Schritte aus, um die Umstellung durchzuführen:
- Erstellen Sie Instanz C mit der gleichen Größe wie B und in derselben DNS-Zone.
- Stellen Sie eine Verbindung mit Instanz B her, und führen Sie ein manuelles Failover durch, um die primäre Instanz auf B umzustellen. Instanz A wird automatisch zur neuen sekundären Instanz.
- Löschen Sie die Failovergruppe zwischen den Instanzen A und B. An diesem Punkt treten bei Anmeldeversuchen, die Failovergruppenendpunkte verwenden, Fehler auf. Die sekundären Datenbanken auf A werden von den primären Datenbanken getrennt und werden zu Datenbanken mit Lese-/Schreibzugriff.
- Erstellen Sie eine Failovergruppe mit dem gleichen Namen zwischen Instanz B und C. Befolgen Sie die Anleitung im Tutorial zu Failovergruppen mit verwalteten Instanzen. Dies ist ein Vorgang, bei dem der Umfang der Daten eine Rolle spielt. Er ist abgeschlossen, wenn für alle Datenbanken von Instanz A das Seeding und die Synchronisierung durchgeführt wurde. An diesem Punkt schlagen die Anmeldeversuche nicht mehr fehl.
- Führen Sie ein manuelles Failover durch, um für die C-Instanz zur primären Rolle zu wechseln. Instanz B wird automatisch zur neuen sekundären Instanz.
- Löschen Sie Instanz A, wenn sie nicht benötigt wird, um unnötige Kosten zu vermeiden.
Achtung
Nach Schritt 3 und bis zum Abschluss von Schritt 4 sind die Datenbanken auf Instanz A vor dem Ausfall von Instanz A aufgrund eines Katastrophenfalls ungeschützt.
Wichtig
Wenn die Failovergruppe gelöscht wird, werden auch die DNS-Einträge für die Listenerendpunkte gelöscht. An diesem Punkt ist nicht völlig ausgeschlossen, dass eine andere Person eine Failovergruppe mit dem gleichen Namen erstellt. Da Failovergruppennamen global eindeutig sein müssen, wird verhindert, dass Sie denselben Namen noch mal verwenden. Verwenden Sie keine generischen Namen für Failovergruppen um dieses Risiko zu minimieren.
Aktivieren von Szenarien in Abhängigkeit von Objekten in den Systemdatenbanken
Systemdatenbanken werden nicht in die sekundäre Instanz in einer Failovergruppe repliziert. Um Szenarien zu ermöglichen, in denen Objekte aus den Systemdatenbanken erforderlich sind, stellen Sie sicher, dass diese Objekte in der sekundären Instanz erstellt werden, und synchronisieren Sie sie mit der primären Instanz.
Wenn Sie beispielsweise in der sekundären Instanz die gleichen Anmeldungen nutzen möchten, stellen Sie sicher, dass sie mit identischer SID erstellt werden.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Weitere Informationen finden Sie unter Azure SQL Managed Instance – Sync Agent Jobs and Logins in Failover Groups (Azure SQL Managed Instance: Synchronisieren von Agent-Aufträgen und Anmeldungen bei Failovergruppen).
Synchronisieren von Instanzeigenschaften und Aufbewahrungsrichtlinien
Instanzen in einer Failovergruppe bleiben separate Azure-Ressourcen, und Änderungen an der Konfiguration der primären Instanz werden nicht automatisch in die sekundäre Instanz repliziert. Stellen Sie sicher, dass Sie alle relevanten Änderungen in der primären und der sekundären Instanz vornehmen. Wenn Sie beispielsweise die Sicherungsspeicherredundanz oder die Richtlinie für die langfristige Sicherungsaufbewahrung für die primäre Instanz ändern, stellen Sie sicher, dass Sie sie auch in der sekundären Instanz ändern.
Skalieren von Instanzen
Sie können die primäre und sekundäre Instanz auf eine andere Computegröße innerhalb derselben Dienstebene oder auf eine andere Dienstebene hoch- oder herunterskalieren. Bei der Skalierung innerhalb derselben Dienstebene wird empfohlen, zuerst die geo-sekundäre und dann die primäre Ebene zu vergrößern. Beim Herunterskalieren innerhalb derselben Dienstebene gehen Sie in umgekehrter Reihenfolge vor: Skalieren Sie zuerst die primäre Datenbank herunter, dann die sekundäre Datenbank. Wenn Sie eine Instanz auf eine andere Dienstebene skalieren, wird diese Empfehlung erzwungen.
Die Reihenfolge wird besonders zur Vermeidung des Überladens der geosekundären Datenbank auf einer niedrigeren SKU empfohlen, damit während des Upgrade- oder Downgradevorgangs kein neuerliches Seeding durchgeführt werden muss.
Berechtigungen
Berechtigungen für eine Failovergruppe werden über die rollenbasierte Zugriffssteuerung in Azure (Azure Role-Based Access Control, Azure RBAC) verwaltet.
Zum Erstellen und Verwalten von Failovergruppen wird Azure RBAC-Schreibzugriff benötigt. Die Rolle Mitwirkender von SQL Managed Instance verfügt über die erforderlichen Berechtigungen zum Verwalten von Failovergruppen.
In der folgenden Tabelle werden spezifische Berechtigungsbereiche für Azure SQL Managed Instance aufgeführt:
| Aktion | Berechtigung | Umfang |
|---|---|---|
| Erstellen einer Failovergruppe | Azure RBAC-Schreibzugriff | Primäre verwaltete Instanz Sekundäre verwaltete Instanz |
| Aktualisieren einer Failovergruppe | Azure RBAC-Schreibzugriff | Failovergruppe Alle Datenbanken innerhalb der verwalteten Instanz |
| Failover einer Failovergruppe | Azure RBAC-Schreibzugriff | Failovergruppe auf der neuen primären verwalteten Instanz |
Einschränkungen
Bedenken Sie dabei folgende Einschränkungen:
- Failovergruppen können nicht zwischen zwei Instanzen in derselben Azure-Region erstellt werden.
- Failovergruppen können nicht umbenannt werden. Sie müssen die Gruppe löschen und unter einem anderen Namen neu erstellen.
- Eine Failovergruppe enthält genau zwei verwaltete Instanzen. Das Hinzufügen zusätzlicher Instanzen zur Failovergruppe wird nicht unterstützt.
- Eine Instanz kann gleichzeitig nur an einer Failovergruppe teilnehmen.
- Eine Failovergruppe kann nicht zwischen zwei Instanzen erstellt werden, die zu unterschiedlichen Azure-Mandanten gehören.
- Eine Failovergruppe zwischen zwei Instanzen, die zu verschiedenen Azure-Subscriptions gehören, kann nicht über das Azure-Portal oder mithilfe der Azure CLI erstellt werden. Verwenden Sie stattdessen Azure PowerShell oder REST-API, um eine solche Failovergruppe zu erstellen. Nach der Erstellung ist die subscriptionübergreifende Failovergruppe ständig im Azure-Portal sichtbar, und alle nachfolgenden Vorgänge, einschließlich Failovers, können über das Azure-Portal oder die Azure CLI initiiert werden.
- Die Datenbankumbenennung wird für Datenbanken in der Failovergruppe nicht unterstützt. Sie müssen eine Failovergruppe vorübergehend löschen, um eine Datenbank umzubenennen.
- Systemdatenbanken werden nicht in die sekundäre Instanz in einer Failovergruppe repliziert. Daher erfordern Szenarien, die von Objekten in den Systemdatenbanken abhängen (z. B. Serveranmeldungen und Agent-Aufträge), dass die Objekte manuell für die sekundären Instanzen erstellt und auch manuell synchron gehalten werden, nachdem Änderungen an der primären Instanz vorgenommen wurden. Die einzige Ausnahme ist der Diensthauptschlüssel (Service Master Key, SMK) für SQL Managed Instance, der während dem Erstellen der Failovergruppe automatisch in die sekundäre Instanz repliziert wird. Alle nachfolgenden Änderungen des SMK auf der primären Instanz werden jedoch nicht auf die sekundäre Instanz repliziert. Weitere Informationen finden Sie unter Aktivieren von Szenarien in Abhängigkeit von Objekten in den Systemdatenbanken.
- Failovergruppen können nicht zwischen Instanzen erstellt werden, wenn sich eine von ihnen in einem Instanzpool befindet.
Programmgesteuertes Verwalten von Failovergruppen
Gruppen für automatisches Failover können auch programmgesteuert mit Azure PowerShell, Azure CLI und der REST-API verwaltet werden. Die folgenden Tabellen beschreiben den verfügbaren Satz von Befehlen. Die aktive Georeplikation umfasst eine Reihe von Azure Resource Manager-APIs für die Verwaltung. Hierzu zählen unter anderem die Azure SQL-Datenbank-REST-API und Azure PowerShell-Cmdlets. Diese APIs erfordern die Verwendung von Ressourcengruppen und unterstützen die rollenbasierte Zugriffssteuerung (Azure RBAC) in Azure. Weitere Informationen zur Implementierung von Zugriffsrollen finden Sie unter Rollenbasierte Zugriffssteuerung in Azure (Azure RBAC).
| Cmdlet | Beschreibung |
|---|---|
| New-AzSqlDatabaseInstanceFailoverGroup | Dieser Befehl erstellt eine Failovergruppe und registriert sie auf primären und sekundären Instanzen |
| Set-AzSqlDatabaseInstanceFailoverGroup | Ändert die Konfiguration einer Failovergruppe |
| Get-AzSqlDatabaseInstanceFailoverGroup | Ruft die Konfiguration einer Failovergruppe ab |
| Switch-AzSqlDatabaseInstanceFailoverGroup | Löst das Failover einer Failovergruppe auf der sekundären Instanz aus |
| Remove-AzSqlDatabaseInstanceFailoverGroup | Entfernt eine Failovergruppe |
Nächste Schritte
Detaillierte Schritte zur Konfiguration einer Failovergruppe finden Sie im Tutorial Hinzufügen einer verwalteten Instanz zu einer Failovergruppe.
Eine Übersicht über das Feature finden Sie unter Failovergruppen. Informationen zum Sparen von Lizenzkosten finden Sie unter Konfigurieren eines Standbyreplikats.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für