Tutorial: Ausführen eines Batchauftrags über Data Factory mit Batch Explorer, Storage-Explorer und Python
In diesem Tutorial erfahren Sie, wie Sie eine Azure Data Factory-Pipeline zum Ausführen einer Azure Batch-Workload erstellen und ausführen. Ein Python-Skript wird auf den Batch-Knoten ausgeführt, um CSV-Eingaben (kommagetrennte Werte) aus einem Azure Blob Storage-Container abzurufen, die Daten zu bearbeiten und die Ausgabe in einen anderen Speichercontainer zu schreiben. Sie verwenden Batch Explorer, um einen Batch-Pool und Batch-Knoten zu erstellen, und Azure Storage-Explorer, um mit Speichercontainern und -dateien zu arbeiten.
In diesem Tutorial lernen Sie Folgendes:
- Verwenden Sie Batch Explorer, um einen Batch-Pool und Batch-Knoten zu erstellen.
- Verwenden Sie Storage-Explorer, um Speichercontainer zu erstellen und Eingabedateien hochzuladen.
- Entwickeln Sie ein Python-Skript, um Eingabedaten zu bearbeiten und Ausgaben zu erzeugen.
- Erstellen Sie eine Data Factory-Pipeline, die die Batch-Workload ausführt.
- Verwenden Sie Batch Explorer, um die Ausgabeprotokolldateien anzuzeigen.
Voraussetzungen
- Ein Azure-Konto mit einem aktiven Abonnement. Falls Sie nicht über ein Abonnement verfügen, können Sie ein kostenloses Konto erstellen.
- Ein Batch-Konto mit einem verknüpften Azure Storage-Konto. Sie können die Konten mit einer der folgenden Methoden erstellen: Azure-Portal | Azure CLI | Bicep | ARM-Vorlage | Terraform.
- Eine Data Factory-Instanz. Befolgen Sie zum Erstellen der Data Factory die Anweisungen unter Erstellen einer Data Factory.
- Batch Explorer heruntergeladen und installiert.
- Storage-Explorer heruntergeladen und installiert.
- Python 3.8 oder höher, mit installiertem azure-storage-blob-Paket unter Verwendung von
pip. - Das von GitHub heruntergeladene Eingabedataset „iris.csv “.
Verwenden von Batch Explorer zum Erstellen von Batch-Pool und Batch-Knoten
Verwenden Sie Batch Explorer, um einen Pool mit Computeknoten zum Ausführen Ihrer Workload zu erstellen.
Melden Sie sich mit Ihren Azure-Anmeldeinformationen bei Batch Explorer an.
Wählen Sie Ihr Batch-Konto aus.
Wählen Sie in der linken Randleiste Pools und dann das +-Symbol aus, um einen Pool hinzuzufügen.
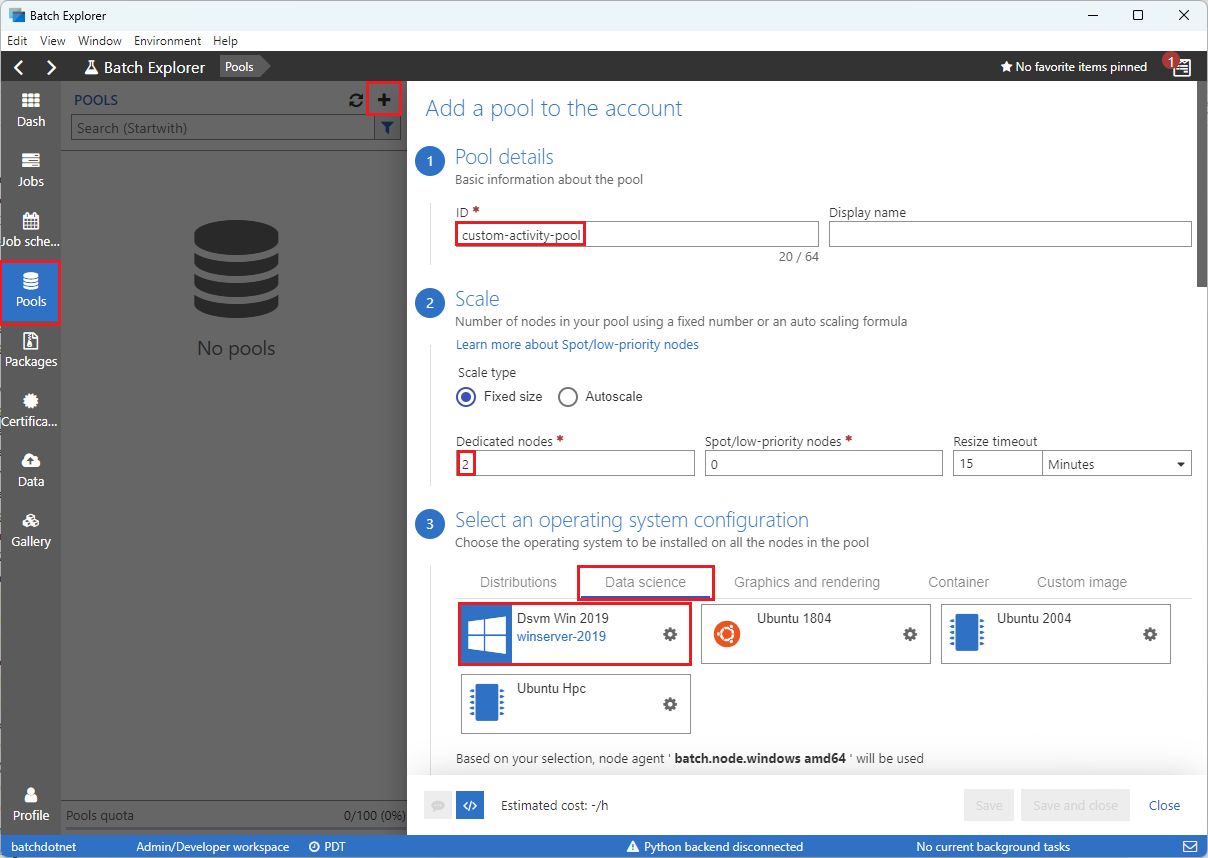
Füllen Sie das Formular zum Hinzufügen eines Pools zum Konto wie folgt aus:
- Geben Sie unter ID die Zeichenfolge custom-activity-pool ein.
- Geben Sie unter Dedizierte Knoten den Wert 2 ein.
- Wählen Sie unter Betriebssystemkonfiguration auswählen die Registerkarte Data Science und dann Dsvm Win 2019 aus.
- Wählen Sie unter VM-Größe auswählen die Option Standard_F2s_v2 aus.
- Wählen Sie unter Startaufgabe die Option Startaufgabe hinzufügen aus.
Geben Sie auf dem Bildschirm der Startaufgabe unter Befehlszeile den Befehl
cmd /c "pip install azure-storage-blob pandas"ein, und wählen Sie dann Auswählen aus. Mit diesem Befehl wird das Paketazure-storage-blobauf jedem Knoten beim Starten installiert.
Klicken Sie auf Speichern und schließen.

Verwenden von Storage-Explorer zum Erstellen eines Blobcontainers
Verwenden Sie Storage-Explorer, um Blobcontainer zum Speichern von Eingabe- und Ausgabedateien zu erstellen und dann Ihre Eingabedateien hochzuladen.
- Melden Sie sich mit Ihren Azure-Anmeldeinformationen bei Storage-Explorer an.
- Suchen und erweitern Sie in der linken Randleiste das Speicherkonto, das mit Ihrem Batch-Konto verknüpft ist.
- Klicken Sie mit der rechten Maustaste auf Blobcontainer, und wählen Sie Blobcontainer erstellen aus, oder wählen Sie unter Aktionen unten in der Randleiste die Option Blobcontainer erstellen aus.
- Geben Sie input in das Eingabefeld ein.
- Erstellen Sie einen weiteren Blobcontainer mit dem Namen output.
- Wählen Sie den Container input und dann im rechten Bereich Upload>Dateien hochladen aus.
- Wählen Sie auf dem Bildschirm Dateien hochladen unter Ausgewählte Dateien die Auslassungspunkte ... neben dem Eingabefeld aus.
- Navigieren Sie zum Speicherort der heruntergeladenen iris.csv-Datei, wählen Sie Öffnen und dann Hochladen aus.

Entwickeln eines Python-Skripts
Das folgende Python-Skript lädt die Datasetdatei iris.csv aus Ihrem Storage-Explorer-Eingabecontainer (input), bearbeitet die Daten und speichert die Ergebnisse im Ausgabecontainer (output).
Das Skript muss die Verbindungszeichenfolge für das mit Ihrem Batch-Konto verknüpfte Azure Storage-Konto verwenden. So rufen Sie die Verbindungszeichenfolge ab:
- Suchen Sie im Azure-Portal nach dem Namen des Speicherkontos, das mit Ihrem Batch-Konto verknüpft ist, und wählen Sie diesen aus.
- Wählen Sie auf der Seite für das Speicherkonto im linken Navigationsbereich unter Sicherheit + Netzwerkdie Option Zugriffsschlüssel aus.
- Wählen Sie unter key1 die Option Anzeigen neben Verbindungszeichenfolge und dann das Symbol Kopieren aus, um die Verbindungszeichenfolge zu kopieren.
Fügen Sie die Verbindungszeichenfolge in das folgende Skript ein, und ersetzen Sie den Platzhalter <storage-account-connection-string>. Speichern Sie das Skript als Datei mit dem Namen main.py.
Wichtig
Das Verfügbarmachen von Kontoschlüsseln in der App-Quelle wird für die Produktionsnutzung nicht empfohlen. Sie sollten den Zugriff auf Anmeldeinformationen einschränken und in Ihrem Code über Variablen oder eine Konfigurationsdatei darauf verweisen. Es empfiehlt sich, Batch- und Storage-Kontoschlüssel in Azure Key Vault zu speichern.
# Load libraries
from azure.storage.blob import BlobClient
import pandas as pd
# Define parameters
connectionString = "<storage-account-connection-string>"
containerName = "output"
outputBlobName = "iris_setosa.csv"
# Establish connection with the blob storage account
blob = BlobClient.from_connection_string(conn_str=connectionString, container_name=containerName, blob_name=outputBlobName)
# Load iris dataset from the task node
df = pd.read_csv("iris.csv")
# Take a subset of the records
df = df[df['Species'] == "setosa"]
# Save the subset of the iris dataframe locally in the task node
df.to_csv(outputBlobName, index = False)
with open(outputBlobName, "rb") as data:
blob.upload_blob(data, overwrite=True)
Führen Sie das Skript lokal aus, um die Funktionalität zu testen und zu überprüfen.
python main.py
Das Skript sollte eine Ausgabedatei namens iris_setosa.csv erstellen, die nur die Datensätze mit „Species = setosa“ enthält. Nachdem Sie sich von der ordnungsgemäßen Funktion vergewissert haben, laden Sie die Skriptdatei main.py in Ihren Storage-Explorer-Eingabecontainer (input) hoch.
Einrichten einer Data Factory-Pipeline
Erstellen und überprüfen Sie eine Data Factory-Pipeline, die Ihr Python-Skript verwendet.
Abrufen von Kontoinformationen
Die Data Factory-Pipeline verwendet Ihre Batch- und Storage-Kontonamen, Ihre Kontoschlüsselwerte und Ihren Batch-Kontoendpunkt. Diese Informationen finden Sie im Azure-Portal:
Suchen Sie in der Azure Search-Leiste nach dem Namen Ihres Batch-Kontos, und wählen Sie ihn aus.
Wählen Sie auf der Seite Ihres Batch-Kontos im linken Navigationsbereich die Option Schlüssel aus.
Kopieren Sie auf der Seite Schlüssel die folgenden Werte:
- Batch-Konto
- Kontoendpunkt
- Primärer Zugriffsschlüssel
- Speicherkontoname
- Key1
Erstellen und Ausführen der Pipeline
Wenn Azure Data Factory Studio noch nicht ausgeführt wird, wählen Sie Studio starten auf der Data Factory-Seite im Azure-Portal aus.
Wählen Sie in Data Factory Studio im linken Navigationsbereich das Stiftsymbol Autor aus.
Wählen Sie unter Factoryressourcen das +-Symbol und dann Pipeline aus.
Ändern Sie im Bereich Eigenschaften auf der rechten Seite den Namen der Pipeline in Python ausführen.
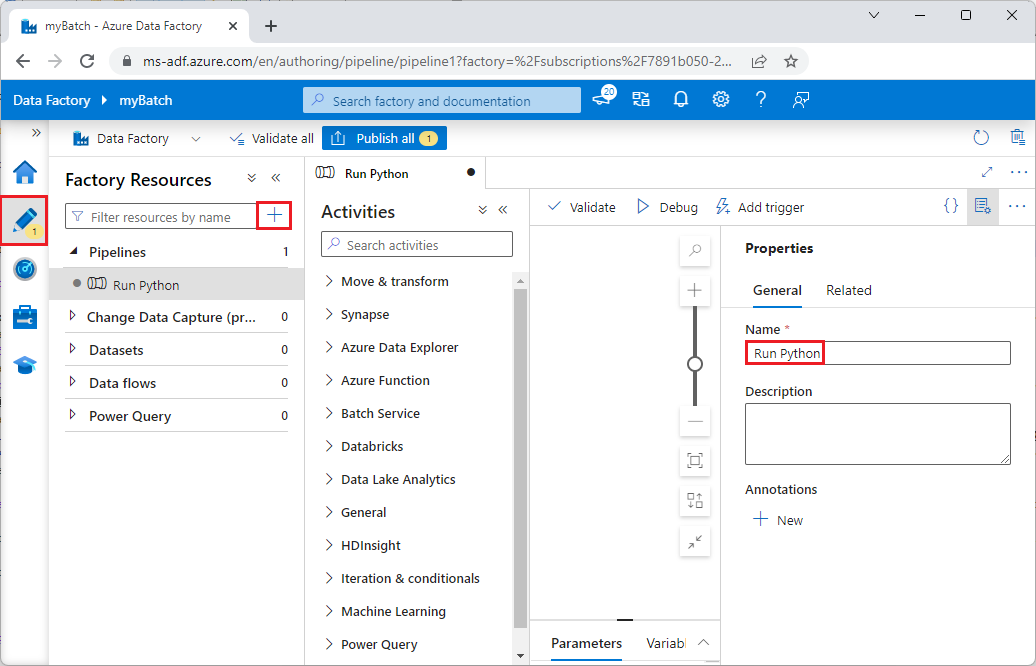
Erweitern Sie im Bereich Aktivitäten die Option Batch-Dienst, und ziehen Sie die Aktivität Benutzerdefiniert auf die Oberfläche des Pipeline-Designers.
Geben Sie unter dem Designer-Canvas auf der Registerkarte Allgemein unter Name die Zeichenfolge testPipeline ein.
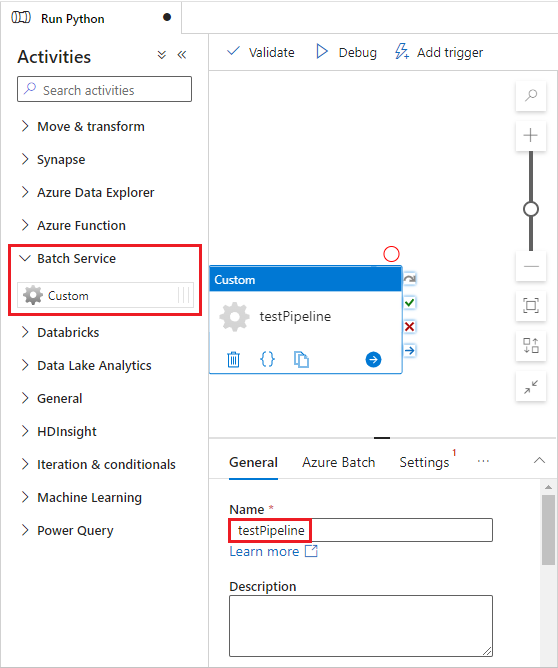
Wählen Sie die Registerkarte Azure Batch und dann Neu aus.
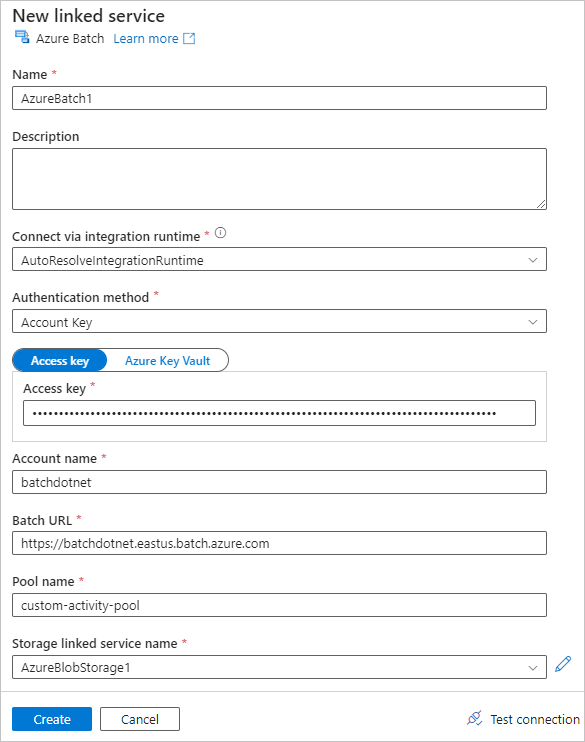
Füllen Sie das Formular Neuer verknüpfter Dienst wie folgt aus:
- Name: Geben Sie einen Namen für den verknüpften Dienst ein, z. B. AzureBatch1.
- Zugriffsschlüssel: Geben Sie den primären Zugriffsschlüssel ein, den Sie aus Ihrem Batch-Konto kopiert haben.
- Kontoname: Geben Sie den Namen Ihres Batch-Kontos ein.
- Batch-URL: Geben Sie den Kontoendpunkt ein, den Sie aus Ihrem Batch-Konto kopiert haben, z. B
https://batchdotnet.eastus.batch.azure.com. - Poolname: Geben Sie den in Batch Explorer erstellten Pool custom-activity-pool ein.
- Name des verknüpften Speicherkontodiensts: Wählen Sie Neu aus. Geben Sie auf dem nächsten Bildschirm einen Namen für den verknüpften Speicherdienst ein, z. B. AzureBlobStorage1, wählen Sie Ihr Azure-Abonnement und ihr verknüpftes Speicherkonto aus, und wählen Sie dann Erstellen aus.
Wählen Sie unten im Batch-Bildschirm Neuer verknüpfter Dienst die Option Verbindung testen aus. Wenn die Verbindung erfolgreich ist, wählen Sie Erstellen aus.
Wählen Sie die Registerkarte Einstellungen aus, und geben Sie die folgenden Einstellungen ein, bzw. wählen Sie sie aus:
- Befehl: Geben Sie
cmd /C python main.pyein. - Verknüpfter Ressourcendienst: Wählen Sie den von Ihnen erstellten verknüpften Speicherdienst aus, z. B. AzureBlobStorage1, und testen Sie die Verbindung, um sicherzustellen, dass sie erfolgreich ist.
- Ordnerpfad: Wählen Sie das Ordnersymbol, dann den Eingabecontainer (input) und anschließend OK aus. Die Dateien aus diesem Ordner werden aus dem Container auf die Poolknoten heruntergeladen, bevor das Python-Skript ausgeführt wird.
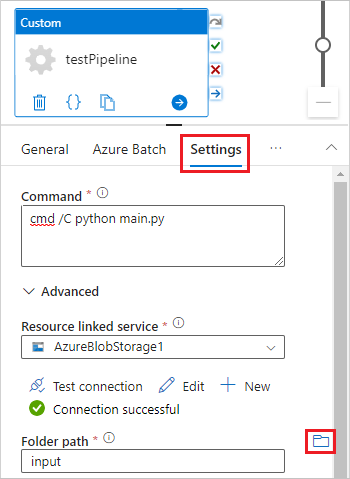
- Befehl: Geben Sie
Wählen Sie auf der Symbolleiste der Pipeline die Option Überprüfen zum Überprüfen der Pipeline aus.
Wählen Sie Debuggen aus, um die Pipeline zu testen und sicherzustellen, dass sie richtig funktioniert.
Klicken Sie auf Alle veröffentlichen, um die Pipeline zu veröffentlichen.
Wählen Sie Trigger hinzufügen und dann Jetzt auslösen aus, um die Pipeline auszuführen, oder Neu/Bearbeiten, um sie zu planen.
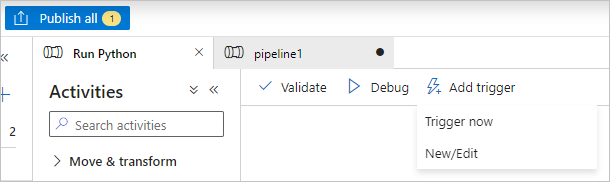

Verwenden von Batch Explorer zum Anzeigen von Protokolldateien
Wenn die Ausführung Ihrer Pipeline Warnungen oder Fehler erzeugt, können Sie Batch Explorer verwenden, um sich die Ausgabedateien stdout.txt und stderr.txt anzusehen und weitere Informationen zu erhalten.
- Wählen Sie in Batch Explorer in der linken Randleiste die Option Aufträge aus.
- Wählen Sie den Auftrag adfv2-custom-activity-pool aus.
- Wählen Sie die Aufgabe aus, die über einen Fehlerexitcode verfügt.
- Zeigen Sie die Dateien stdout.txt und stderr.txt an, um Ihr Problem zu untersuchen und zu diagnostizieren.
Bereinigen von Ressourcen
Batch-Konten, -Aufträge und -Aufgaben sind kostenlos, aber für Computeknoten fallen Gebühren an, auch wenn sie keine Aufträge ausführen. Es ist am besten, Knotenpools nur bei Bedarf zuzuweisen und die Pools zu löschen, wenn Sie sie nicht mehr benötigen. Beim Löschen von Pools werden alle Aufgabenausgaben auf den Knoten und die Knoten selbst gelöscht.
Die Eingabe- und Ausgabedateien verbleiben im Speicherkonto, und es können Gebühren anfallen. Wenn Sie die Dateien nicht mehr benötigen, können Sie die Dateien oder Container löschen. Wenn Sie Ihr Batch-Konto oder das verknüpfte Speicherkonto nicht mehr benötigen, können Sie es löschen.
Nächste Schritte
In diesem Tutorial haben Sie erfahren, wie Sie ein Python-Skript mit Batch Explorer, Storage-Explorer und Data Factory verwenden, um eine Batch-Workload auszuführen. Weitere Informationen zu Data Factory finden Sie unter Was ist Azure Data Factory?