Prozess für Machine Learning-Vorgänge
Der Modellentwicklungsprozess
Der Entwicklungsprozess sollte zu den folgenden Ergebnissen führen:
Das Training erfolgt automatisiert, und Modelle werden überprüft. Dies beinhaltet Tests auf Funktionalität und Leistung (z. B. mithilfe von Metriken für die Genauigkeit).
Die Bereitstellung in der Infrastruktur, die für Rückschlüsse verwendet wird, wird (einschließlich der Überwachung) automatisiert.
Es bestehen Methoden, die ein End-to-End-Überwachungsprotokoll für Daten erstellen. Ein automatisches erneutes Training des Modells erfolgt, wenn es im Lauf der Zeit zu Datendrift kommt. Dies spielt für große auf Machine Learning basierende Systeme eine Rolle.
Auf der folgenden Abbildung ist der Bereitstellungslebenszyklus eines Machine-Learning-Systems dargestellt:
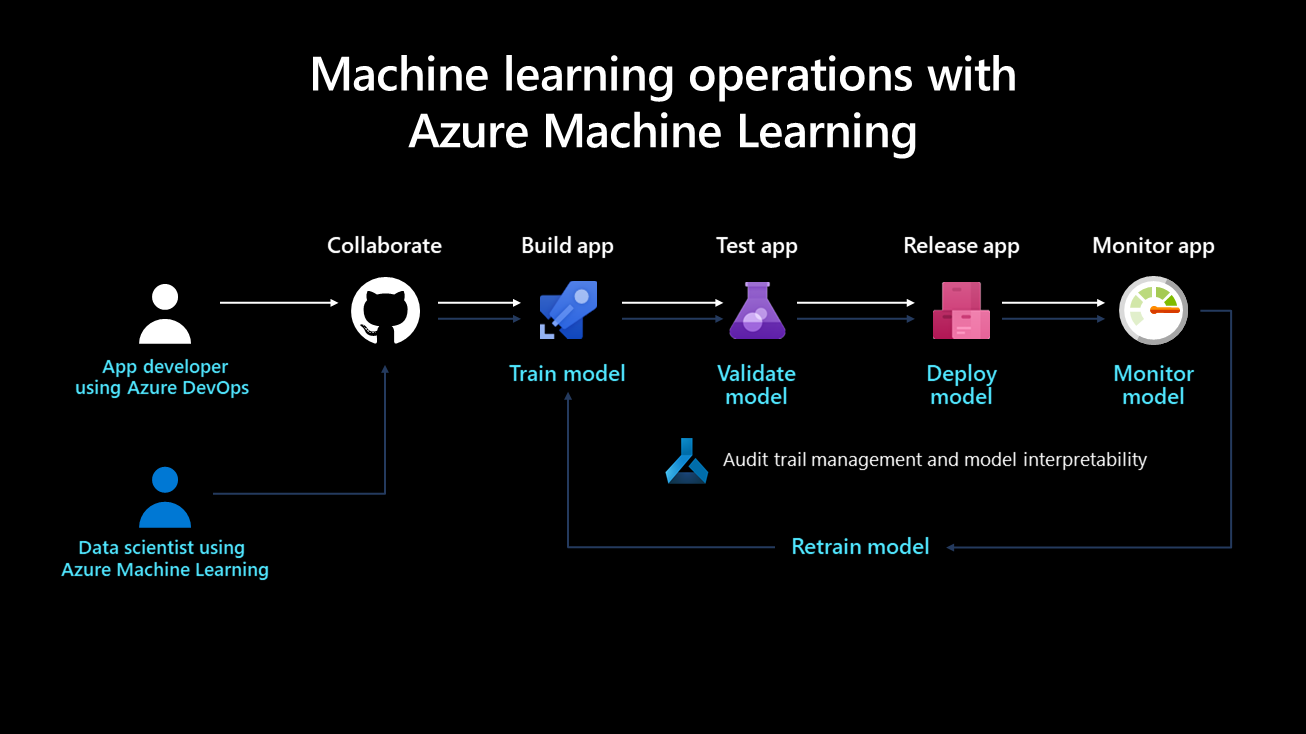
Nach seiner Entwicklung wird ein Machine Learning-Modell trainiert, überprüft, bereitgestellt und überwacht. Aus Organisationsperspektive und aus technischer und verwaltungstechnischer Sicht ist es wichtig, zu definieren, wer für diesen Prozess und seine Implementierung zuständig ist. In größeren Unternehmen könnte ein Data Scientist mit den Schritten für Modelltraining- und -überprüfung befasst sein. Eine technische Fachkraft für Machine Learning könnte für die übrigen Schritte verantwortlich sein. In kleineren Unternehmen ist ein Data Scientist möglicherweise für alle Schritte zuständig.
Trainieren des Modells
Bei diesem Schritt wird das Machine Learning-Modell mithilfe eines Trainingsdatasets trainiert. Der Trainingscode weist eine Versionskontrolle auf und ist wiederverwendbar. Dieses Feature optimiert Schaltflächenklicks und Ereignisauslöser (z. B. wenn eine neue Version der Daten verfügbar gemacht wird), um zu automatisieren, wie das Modell trainiert wird.
Überprüfen des Modells
Für diesen Schritt werden gängige Metriken wie eine Genauigkeitsmetrik verwendet, um das neu trainierte Modell automatisch zu überprüfen und mit älteren zu vergleichen. Hierbei stellt sich die Frage, ob die Genauigkeit verbessert werden konnte. Ist dies der Fall, kann das Modell in der Modellregistrierung registriert werden, um sicherzustellen, dass es von den folgenden Schritten verwendet werden kann. Wenn sich die Leistung des neuen Modells verschlechtert hat, kann ein Data Scientist benachrichtigt werden, damit dieser untersucht, warum sich die Leistung verschlechtert hat. Er kann sich auch dazu entschließen, das Modell zu verwerfen.
Bereitstellen des Modells
Im Bereitstellungsschritt stellen Sie das Modell als API-Dienst für Webanwendungen bereit. Dieser Ansatz ermöglicht es, dass das Modell unabhängig von Anwendungen skaliert und aktualisiert werden kann. Alternativ kann das Modell genutzt werden, um Batchbewertungen durchzuführen, wenn es einmalig oder regelmäßig verwendet wird, um Vorhersagen für neue Datenpunkte zu berechnen. Dies ist hilfreich, wenn große Datenmengen asynchron verarbeitet werden müssen. Weitere Informationen zu Bereitstellungsmodellen finden Sie im Artikel Machine-Learning-Rückschlüsse während der Bereitstellung.
Überwachen des Modells
Aus zwei Gründen ist es unerlässlich, das Modell zu überwachen. Erstens sorgt die Überwachung des Modells für seine technische Funktionalität, z. B. wird seine Fähigkeit sichergestellt, Vorhersagen zu generieren. Dies ist wichtig, wenn die Anwendungen einer Organisation von dem Modell abhängen und es in Echtzeit verwenden. Die Überwachung des Modells unterstützt Organisationen außerdem bei Messungen, wenn regelmäßig hilfreiche Vorhersagen generiert werden. Dies ist weniger hilfreich, wenn Datendrift auftritt, z. B. wenn sich die für das Modelltraining verwendeten Daten erheblich von den Daten unterscheiden, die während der Vorhersagephase an das Modell gesendet werden. Ein Modell, das beispielsweise für Empfehlungen von Produkten für junge Menschen trainiert wurde, führt möglicherweise zu unerwünschten Ergebnissen, wenn Produkte an Personen einer anderen Altersgruppe empfohlen werden. Bei der Modellüberwachung auf Datendrift kann dieses Problem erkannt werden. Auf dieser Grundlage werden technische Fachkräfte für Machine Learning benachrichtigt, und das Modell wird automatisch mit relevanteren oder neueren Daten neu trainiert.
Anleitung für die Überwachung von Modellen
Da Datendrift, Saisonalität oder neuere Architekturen, die mit Fokus auf einer besseren Leistung entworfen wurden, dazu führen können, dass die Modellleistung im Lauf der Zeit abnimmt, ist es wichtig, einen Prozess zu etablieren, Modelle regelmäßig bereitzustellen. Dabei gilt Folgendes als Best Practice:
Verantwortlichkeiten: Dem Prozess für die Leistungsüberwachung des Modells sollte eine verantwortliche Person zugewiesen werden, damit die Leistung aktiv verwaltet wird.
Releasepipelines: Richten Sie in Azure DevOps zuerst eine Releasepipeline ein, und legen Sie den Trigger auf die Modellregistrierung fest. Wenn ein neues Modell in der Registrierung registriert wird, wird die Releasepipeline ausgelöst, und ein Bereitstellungsprozess wird eingeleitet.
Voraussetzungen für ein erneutes Training von Modellen
Die Datenerfassung für Modelle in der Produktion ist eine Voraussetzung dafür, dass Modelle in einem Continuous-Integration-/Continuous-Development-Framework erneut trainiert werden können. Für diesen Prozess werden Eingabedaten von Bewertungsanforderungen verwendet. Diese Funktionalität ist aktuell auf Tabellendaten beschränkt, die im JSON-Format mit minimaler Formatierung und Änderung analysiert werden können. Video-, Audio- und Bilddaten sind ausgenommen. Diese Funktionalität ist für Modelle in Azure Kubernetes Service (AKS) verfügbar. Die erfassten Daten werden in Blobspeicher in Azure gespeichert.
So bereiten Sie das erneute Trainieren eines Modells vor:
Überwachen Sie die Datendrift für erfasste Eingabedaten. Für die Einrichtung eines Überwachungsprozesses muss der Zeitstempel aus den Produktionsdaten extrahiert werden. Dies ist erforderlich, um die Produktionsdaten und die Baselinedaten (die zum Erstellen des Modells verwendeten Trainingsdaten) zu vergleichen. Die bevorzugte Methode, Datendrift zu überwachen, erfolgt über das Azure Monitor-Feature Application Insights. Dieses Feature gibt eine Warnung aus, die Aktionen wie eine E-Mail, eine Textnachricht per SMS, einen Pushvorgang oder Azure Functions auslösen kann. Sie müssen Application Insights aktivieren, um Daten zu protokollieren.
Analysieren Sie die erfassten Daten. Achten Sie darauf, Daten aus Produktionsmodellen zu erfassen, und schließen Sie die Ergebnisse im Skript für die Modellbewertung ein. Erfassen Sie alle für die Modellbewertung verwendeten Features. Dies sorgt dafür, dass alle erforderlichen Features vorhanden sind und als Trainingsdaten verwendet werden können.
Entscheiden Sie sich, ob ein erneutes Training mit den erfassten Daten erforderlich ist. Viele Faktoren können zu Datendrift führen, z. B. Sensorprobleme oder Saisonalität, Änderungen des Benutzerverhaltens und Probleme mit der Datenqualität im Hinblick auf die Datenquelle. Ein erneutes Modelltraining ist nicht in allen Fällen erforderlich. Sie sollten also die Ursache für die Datendrift ermitteln und analysieren, bevor Sie weiter ins Detail gehen.
Trainieren Sie das Modell neu. Das Modelltraining sollte bereits automatisiert sein. Dieser Schritt beinhaltet das Auslösen des aktuellen Trainingsschritts. Dies könnte der Fall sein, wenn eine Datendrift erkannt wurde, die nicht im Zusammenhang mit einem Datenproblem steht, oder wenn ein Datentechniker eine neue Version eines Dataset veröffentlicht hat. Je nach Anwendungsfall können diese Schritte vollständig automatisiert oder von einer Person überwacht werden. Während beispielsweise einige Anwendungsfälle wie Produktempfehlungen in der Zukunft autonom ausgeführt werden können, würden im Finanzbereich Standards wie Modellfairness und Transparenz berücksichtigt werden. Außerdem wäre ein Mensch erforderlich, der neu trainierte Modelle genehmigt.
Zunächst ist es üblich, dass eine Organisation nur das Training und die Bereitstellung eines Modells automatisiert, nicht jedoch die Schritte für Überprüfung, Überwachung und erneutes Training. Diese werden manuell durchgeführt. Schließlich können die Automatisierungsschritte für diese Aufgaben so lange fortgesetzt werden, bis ein erwünschter Zustand erreicht ist. DevOps und Machine-Learning-Vorgänge sind Konzepte, die sich im Lauf der Zeit entwickeln, und Organisationen sollten ihre Entwicklung berücksichtigen.
Lebenszyklus des Team Data Science-Prozesses
Der Team Data Science-Prozess (TDSP) umfasst einen Lebenszyklus zum Strukturieren der Entwicklung Ihrer Data Science-Projekte. Der Lebenszyklus beschreibt die wichtigsten Phasen, die Projekte typischerweise, oft iterativ, durchlaufen:
- Geschäftliche Aspekte
- Datenerfassung und -auswertung
- Modellierung
- Bereitstellung
Die Ziele, Aufgaben und Dokumentationsartefakte für die einzelnen Phasen des Lebenszyklus im TDSP werden im Artikel Lebenszyklus des Team Data Science-Prozesses beschrieben.
Rollen und Aktivitäten bei Machine-Learning-Vorgängen
Im TDSP-Lebenszyklus sind die Hauptrollen für KI-Projekte Data Engineer, Data Scientist und Operations Engineer für Machine Learning. Diese Rollen sind entscheidend für den Erfolg Ihres Projekts, und sie müssen gemeinsam an genauen, wiederholbaren, skalierbaren und für die Produktion einsatzbereiten Lösungen arbeiten.

Data Engineer: Diese Rolle ist für Erfassung, Überprüfung und Bereinigung der Daten verantwortlich. Sobald die Daten aufbereitet wurden, werden sie katalogisiert und zur Verwendung für Data Scientists zur Verfügung gestellt. In dieser Phase ist es wichtig, Datenduplikate zu ermitteln und zu analysieren, Ausreißer zu entfernen und fehlende Daten zu identifizieren. Diese Aktivitäten sollten in den Pipelineschritten definiert und ausgeführt werden, wenn die Trainingspipeline vorverarbeitet wird. Den Hauptfeatures und generierten Features sollten eindeutige und bestimmte Namen zugewiesen werden.
Data Scientist (oder AI Engineer): Diese Rolle übernimmt die Navigation im Trainingspipelineprozess und bewertet die Modelle. Ein Data Scientist empfängt die Daten vom Data Engineer und ermittelt darin enthaltene Muster und Beziehungen. Dabei kann er Features für das Experiment auswählen oder generieren. Da Feature Engineering eine wichtige Rolle dabei spielt, ein stabiles generalisiertes Modell zu entwickeln, ist es wichtig, dass diese Phase so gründlich wie möglich abgeschlossen wird. Verschiedene Experimente können mit verschiedenen Algorithmen und Hyperparametern ausgeführt werden. Azure-Tools wie automatisiertes maschinelles Lernen können diese Aufgabe automatisieren und auch bei Problemen einer Unter- oder Überanpassung eines Modells hilfreich sein. Ein erfolgreich trainiertes Modell wird dann in der Modellregistrierung registriert. Das Modell sollte einen eindeutigen und bestimmten Namen haben. Außerdem sollte ein Versionsverlauf aus Nachverfolgbarkeitsgründen gespeichert werden.
Operations Engineer für Machine Learning: Diese Rolle erstellt End-to-End-Pipelines für Continuous Integration und Continuous Delivery. Dies beinhaltet die Erstellung eines Modellpakets in einem Docker-Image, die Überprüfung und Profilerstellung für das Modell, das Warten auf Genehmigung eines Projektbeteiligten und das Bereitstellen des Modells in einem Containerorchestrierungsdienst wie AKS. Während der Continuous Integration können verschiedene Trigger eingerichtet werden, und der Code des Modells kann die Trainingspipeline und anschließend die Releasepipeline auslösen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für