Verantwortungsbewusste und vertrauenswürdige KI
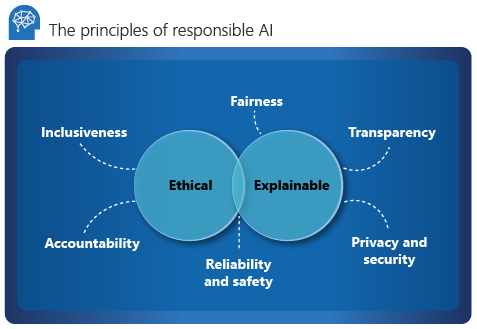
Microsoft legt sechs Leitprinzipien für verantwortungsbewusste KI, Inklusion, Zuverlässigkeit und Sicherheit, Fairness, Transparenz sowie Datenschutz zugrunde. Diese Grundsätze sind von entscheidender Bedeutung für die Entwicklung verantwortungsvoller und vertrauenswürdiger KI-Funktionen, während diese zunehmend Einzug in Mainstreamprodukte und -dienstleistungen hält. Sie orientieren sich an zwei Gesichtspunkten: ethisch und erklärbar.
Ethik
Aus ethischer Sicht sollte für die KI Folgendes gelten:
- Fair und inklusiv hinsichtlich der getroffenen Behauptungen
- Verantwortungsbewusst hinsichtlich der getroffenen Entscheidungen
- Keine Diskriminierung oder Benachteiligung von Menschen aufgrund von Ethnie, Behinderungen oder sozialem Hintergrund
Im Jahr 2017 hat Microsoft ein beratendes Komitee für KI, Ethik und Auswirkungen in Technik und Forschung eingerichtet (AETHER). Die Hauptaufgabe des Komitees besteht in der Beratung zu Fragen, Technologien, Prozessen und bewährten Verfahren für verantwortungsvolle KI. Weitere Informationen finden Sie in den Informationen zum Governancemodell von Microsoft – AETHER und Office of Responsible AI.
Verantwortlichkeit
Die Verantwortlichkeit ist eine wesentliche Säule der verantwortungsbewussten KI. Die Personen, die ein KI-System entwerfen und bereitstellen, müssen für dessen Aktionen und Entscheidungen Verantwortung übernehmen. Dies gilt insbesondere im Hinblick auf zunehmend autonome Systeme.
Organisationen sollten es in Erwägung ziehen, einen internen Überprüfungsausschuss zu gründen, der die Entwicklung und Bereitstellung von KI-Systemen beaufsichtigt sowie Erkenntnisse und Anleitungen bietet. Diese Beratung kann sich je nach Unternehmen und Region unterscheiden, sollte jedoch die KI-Journey der Organisation widerspiegeln.
Nichtausgrenzung
Inklusion bedeutet, dass die KI Menschen jeder Herkunft und Erfahrung berücksichtigen muss. Inklusive Entwurfsmethoden können Entwickler*innen dabei unterstützen, potenzielle Barrieren zu verstehen und zu beseitigen, die Menschen unbeabsichtigt ausschließen könnten. Wo immer möglich, sollten Organisationen Technologien für Spracherkennung, Sprachsynthese und visuelle Erkennung verwenden, um Personen mit Hör- und Sehbehinderungen sowie anderen Beeinträchtigungen zu unterstützen.
Zuverlässigkeit und Sicherheit
KI-Systeme müssen zuverlässig und sicher sein, damit sie als vertrauenswürdig eingestuft werden können. Es ist wichtig, dass ein System dem ursprünglichen Entwurf entsprechend funktioniert und sicher auf neue Situationen reagiert. Die inhärente Resilienz des Systems sollte vor beabsichtigten oder unbeabsichtigten Änderungen schützen.
Organisationen sollten anhand von strengen Test- und Validierungsverfahren für den Betrieb sicherstellen, dass das System sicher auf Grenzfälle reagiert. A/B-Tests und Champion-/Challenger-Methoden sollten in den Bewertungsprozess integriert werden.
Die Leistung eines KI-Systems kann mit der Zeit nachlassen. Organisationen müssen einen robusten Überwachungs- und Modellnachverfolgungsprozess einrichten, um die Leistung des Modells reaktiv und proaktiv zu messen (und es bei Bedarf für eine Modernisierung erneut trainieren).
Erklärbar
Durch die Erklärbarkeit können Data Scientists, Prüfer*innen und Entscheidungsträger*innen in Unternehmen sicherstellen, dass KI-Systeme die getroffenen Entscheidungen und die Art der Schlussfolgerung angemessen rechtfertigen können. Die Erklärbarkeit trägt außerdem dazu bei, die Einhaltung von Unternehmensrichtlinien, Branchenstandards und gesetzlichen Vorschriften zu gewährleisten.
Data Scientists sollten Projektbeteiligten erläutern können, wie bestimmte Genauigkeitsstufen erreicht wurden und wodurch das Ergebnis beeinflusst wurde. Ebenso benötigen Prüfer*innen zur Einhaltung der Unternehmensrichtlinien ein Instrument zur Validierung des Modells. Entscheidungsträger*innen in Unternehmen müssen Vertrauen gewinnen, indem sie ein transparentes Modell bereitstellen.
Tools für die Erklärbarkeit
Microsoft hat InterpretML entwickelt, ein Open-Source-Toolkit, das Organisationen dabei unterstützt, Modelle erklärbar zu machen. Es bietet Unterstützung für Glass-Box- und Black-Box-Modelle:
Transparente Modelle können aufgrund ihrer Struktur interpretiert werden. Für diese Modelle stellt Explainable Boosting Machine (EBM) den Status des Algorithmus basierend auf einer Entscheidungsstruktur oder anhand von linearen Modellen bereit. EBM bietet verlustfreie Erklärungen und kann von Fachbereichsexpert*innen bearbeitet werden.
Intransparente Modelle sind aufgrund einer komplexen internen Struktur, dem neuronalen Netz, schwieriger zu interpretieren. Erklärmodule wie LIME (Local Interpretable Model-Agnostic Explanations) oder SHAP (SHapley Additive exPlanations) interpretieren diese Modelle, indem sie die Beziehung zwischen Eingabe und Ausgabe analysieren.
Fairlearn ist eine Azure Machine Learning-Integration und ein Open-Source-Toolkit für das SDK und die grafische Benutzeroberfläche für automatisiertes maschinelles Lernen. Anhand der Module kann nachvollzogen werden, welche Faktoren das Modell hauptsächlich beeinflussen, und mit der Hilfe von Fachbereichsexpert*innen können diese Einflüsse validiert werden.
Weitere Informationen zur Erklärbarkeit finden Sie unter Modellinterpretierbarkeit in Azure Machine Learning.
Fairness
Fairness ist ein grundlegendes ethisches Prinzip, das alle Menschen verstehen und anwenden müssen. Dieses Prinzip ist bei der Entwicklung von KI-Systemen noch wichtiger. Durch gegenseitige Kontrolle muss sichergestellt werden, dass bei den Entscheidungen des Systems weder eine Gruppe noch Einzelpersonen aufgrund ihres Geschlechts, ihrer Herkunft, ihrer sexuellen Orientierung oder ihrer Religion diskriminiert oder voreingenommen behandelt werden.
Microsoft stellt eine Prüfliste für KI-Fairness zur Verfügung, die Anweisungen und Lösungen für KI-Systeme bietet. Diese Lösungen werden grob in fünf Phasen kategorisiert: Planung, Prototyp, Erstellung, Start und Weiterentwicklung. In jeder Phase werden Sorgfaltspflichten aufgeführt, deren Einhaltung dabei hilft, die Auswirkungen von Ungerechtigkeit im System zu minimieren.
Fairlearn ist mit Azure Machine Learning integriert und unterstützt Data Scientists und Entwickler bei der Bewertung und Verbesserung der Fairness ihrer KI-Systeme. Es werden Algorithmen zur Minimierung von Ungerechtigkeiten und ein interaktives Dashboard zur Visualisierung der Fairness des Modells bereitgestellt. Organisationen sollten das Toolkit nutzen und die Fairness des Modells während der Entwicklung eingehend prüfen. Dieses Vorgehen sollte ein integraler Bestandteil des Data-Science-Prozesses sein.
Erfahren Sie, wie Sie die Fairness in Machine Learning-Modellen fördern.
Transparenz
Durch die Schaffung von Transparenz kann das Team die folgenden Elemente besser verstehen:
- Die Daten und Algorithmen, die zum Trainieren des Modells verwendet wurden
- Die Transformationslogik, die auf die Daten angewendet wurde
- Das endgültige Modell, das generiert wurde
- Die dem Modell zugeordneten Ressourcen
Diese Informationen geben Aufschluss darüber, wie das Modell erstellt wurde, sodass das Team es auf transparente Weise reproduzieren kann. Momentaufnahmen in Azure Machine Learning-Arbeitsbereichen unterstützen die Transparenz, indem alle auf Training bezogene Ressourcen und Metriken des Experiments aufgezeichnet oder neu trainiert werden.
Datenschutz und -sicherheit
Datenbesitzer*innen sind verpflichtet, die Daten in einem KI-System zu schützen. Datenschutz und Sicherheit sind ein integraler Bestandteil dieses Systems.
Personenbezogene Daten müssen geschützt werden, und der Zugriff darauf darf die Privatsphäre von Personen nicht gefährden. Der differenzierte Datenschutz von Azure trägt zum Schutz und zur Wahrung der Privatsphäre bei, indem Daten randomisiert und Fülldaten hinzugefügt werden, um personenbezogene Informationen für Data Scientists unkenntlich zu machen.
Richtlinien für die Interaktion zwischen Mensch und KI
Die Entwurfsrichtlinien für die Interaktion zwischen Mensch und KI bestehen aus 18 Prinzipien, die über vier Zeiträume hinweg auftreten: zu Beginn, bei der Interaktion, bei einem Fehler und im Laufe der Zeit. Diese Grundsätze unterstützen eine Organisation bei der Entwicklung eines integrativen KI-Systems, bei dem der Mensch im Mittelpunkt steht.
Einleitung
Erläuterung, welche Aktivitäten das System durchführen kann: Wenn das KI-System Metriken verwendet oder generiert, ist es wichtig, dass diese und ihre Nachverfolgung angezeigt werden.
Erläuterung, wie gut das System seine Aufgaben erfüllen kann: Machen Sie den Benutzer*innen klar, dass KI nicht vollständig präzise ist. Verdeutlichen Sie, wann das KI-System Fehler machen könnte.
Bei der Interaktion
Bereitstellung von kontextbezogenen Informationen: Stellen Sie visuelle Informationen zur Verfügung, die sich auf den aktuellen Kontext und die Umgebung der Benutzer*innen beziehen, z. B. Hotels in der Nähe. Geben Sie Details in der Nähe des Zielorts und rund um das angestrebte Datum zurück.
Minderung sozialer Voreingenommenheiten: Stellen Sie sicher, dass die Sprache und das Verhalten keine unbeabsichtigten Stereotypen oder Voreingenommenheiten verursachen. Ein Feature zur automatischen Vervollständigung muss zum Beispiel auch die Geschlechtsidentität berücksichtigen.
Bei einem Fehler
- Unterstützung einer effizienten Ablehnung: Stellen Sie einen einfachen Mechanismus bereit, um unerwünschte Features oder Dienste zu ignorieren oder zu verwerfen.
- Unterstützung effizienter Korrekturen: Stellen Sie eine intuitive Methode zum Vereinfachen der Bearbeitung, Optimierung oder Wiederherstellung bereit.
- Begründung der Funktionsweise des Systems: Optimieren Sie die erklärbare KI, um Erkenntnisse zu den Assertionen des KI-Systems bereitzustellen.
Im Laufe der Zeit
- Protokollieren der aktuellen Interaktionen: Legen Sie einen Verlauf der Interaktionen zur späteren Referenz an.
- Lernen aus dem Benutzerverhalten: Personalisieren Sie die Interaktion anhand des Verhaltens des Benutzers.
- Umsichtige Aktualisierung und Anpassung: Beschränken Sie unterbrechende Änderungen, und führen Sie Updates basierend auf dem Benutzerprofil aus.
- Förderung von detailliertem Feedback: Erfassen Sie Feedback von Benutzern anhand ihrer Interaktionen mit dem KI-System.
Framework für vertrauenswürdige KI
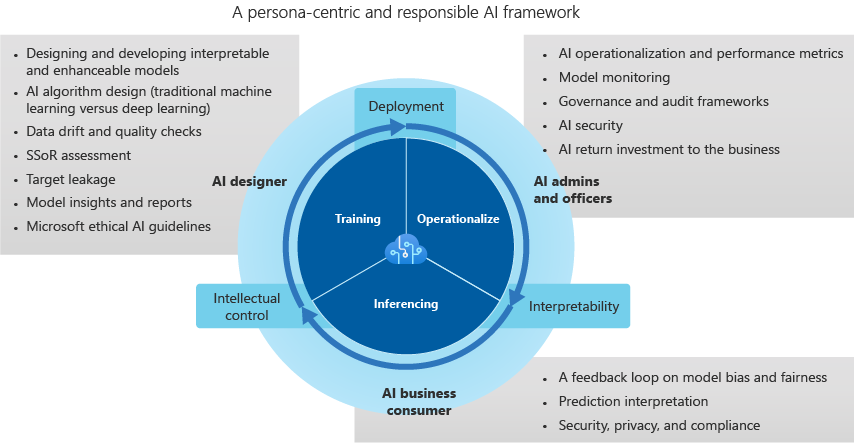
KI-Designer
KI-Designer erstellen das Modell und sind für Folgendes verantwortlich:
Datendrift und Qualitätsprüfungen: Die Designer*innen erkennen Ausreißer und führen Datenqualitätsprüfungen durch, um fehlende Werte zu identifizieren. Sie standardisieren darüber hinaus die Verteilung, prüfen die Daten und erstellen Anwendungsfall- und Projektberichte.
Sie bewerten Daten in der Quelle des Systems, um mögliche Voreingenommenheiten zu identifizieren.
Sie entwerfen KI-Algorithmen, um Einseitigkeit bei Daten zu minimieren. Im Rahmen dieser Bemühungen wird u. a. untersucht, wie durch Kategorisierung, Gruppierung und Normalisierung (insbesondere bei traditionellen Modellen für maschinelles Lernen, wie etwa strukturbasierten Modellen) Minderheitengruppen aus Daten entfernt werden können. Ein kategorischer KI-Entwurf verstärkt die Einseitigkeit von Daten, indem soziale, ethnische und geschlechtsspezifische Klassen in Branchen gruppiert werden, die mit geschützten Gesundheitsdaten und personenbezogenen Informationen arbeiten.
Sie optimieren die Überwachung und Warnungen, um Zielungenauigkeit zu identifizieren und die Entwicklung des Modells zu verbessern.
Sie führen bewährte Methoden für die Berichterstellung und das Gewinnen von Erkenntnissen ein, die ein detailliertes Verständnis des Modells ermöglichen. Die Designer*innen vermeiden Black-Box-Ansätze, die Feature- oder Vektorrelevanz, UMAP-Clustering (Uniform Manifold Approximation and Projection), Friedman-Test (H-Statistik), Featureauswirkungen und ähnliche Techniken verwenden. Identifikationsmetriken tragen zur Definition der prädiktiven Auswirkung, Beziehungen und Abhängigkeiten zwischen Korrelationen in komplexen und modernen Datasets bei.
KI-Administrator*innen und -Beauftragte
Die Administrator*innen und Beauftragten für KI beaufsichtigen die KI-, Governance- und Prüfverfahren sowie die Leistungsmetriken. Sie überwachen außerdem die Umsetzung der KI-Sicherheit und haben die Rendite für das Unternehmen im Blick. Zu ihren Aufgaben gehören:
Überwachung eines Dashboards, das die Modellüberwachung unterstützt und Modellmetriken für Produktionsmodelle kombiniert. Das Dashboard konzentriert sich auf Genauigkeit, Modellverschlechterung, Datendrift, Abweichung und Veränderungen hinsichtlich der Geschwindigkeit/Fehlerrate für Rückschlüsse.
Implementierung einer flexiblen Bereitstellung und Neubereitstellung (vorzugsweise über eine REST-API), mit der Modelle in einer offenen, systemunabhängigen Architektur implementiert werden können. Die Architektur integriert das Modell in die Geschäftsprozesse und schafft einen Mehrwert für Feedbackschleifen.
Festlegung von Grenzen und Entschärfung negativer geschäftlicher und betrieblicher Auswirkungen durch Modellgovernance und -zugriff. Standards der rollenbasierten Zugriffssteuerung (RBAC) legen Sicherheitskontrollmechanismen fest, die begrenzte Produktionsumgebungen und das geistige Eigentum schützen.
Sie verwenden KI-Überwachungs- und Complianceframeworks, um zu überwachen, wie sich Modelle entwickeln. Außerdem nehmen sie Änderungen vor, damit branchenspezifische Standards eingehalten werden. Interpretierbare und verantwortungsbewusste KI basiert auf messbarer Erklärbarkeit, präzisen Features, Modellvirtualisierungen und branchenspezifischer Sprache.
KI-Unternehmensbenutzer*innen
KI-Unternehmensbenutzer (Unternehmensexperten) schließen die Feedbackschleife und bieten Anregungen für den KI-Designer. Die prädiktive Entscheidungsfindung und Implizierung möglicher Voreingenommenheiten durch Messungen von Fairness und Ethik, Datenschutz und Konformität sowie Geschäftseffizienz unterstützen die Auswertung von KI-Systemen. Nachfolgend werden einige Überlegungen für Unternehmensbenutzer*innen aufgeführt:
Feedbackschleifen sind Teil des Ökosystems eines Unternehmens. Daten, die Informationen zu Einseitigkeit, Fehlern, Vorhersagegeschwindigkeit und Fairness eines Modells aufzeigen, schaffen Vertrauen und sorgen für ein ausgewogenes Verhältnis zwischen KI-Designer*innen, -Administrator*innen und -Beauftragten. Eine auf den Menschen ausgerichtete Bewertung sollte die KI im Laufe der Zeit schrittweise verbessern.
Die Minimierung des KI-Lernens anhand multidimensionaler, komplexer Daten kann dazu beitragen, ein voreingenommenes Lernen zu verhindern. Diese Technik wird als „LO-Shot-Learning“ (Less-than-One-Shot) bezeichnet.
Mit einem auf Interpretierbarkeit ausgerichteten System und den entsprechenden Tools kann eine mögliche Voreingenommenheit der KI-Systeme festgestellt werden. Modellvoreingenommenheit und Fairnessprobleme müssen gekennzeichnet und in ein Warnungs- und Anomalieerkennungssystem eingespeist werden, das von diesem Verhalten lernt und Voreingenommenheit automatisch behebt.
Jeder Vorhersagewert sollte nach Relevanz oder Auswirkung in einzelne Features oder Vektoren aufgeschlüsselt werden. Er sollte ausführliche Erklärungen zu den Vorhersagen liefern, die in einen Geschäftsbericht für Audits und Konformitätsprüfungen, Kundentransparenz und Bereitschaft des Unternehmens exportiert werden können.
Aufgrund zunehmender globaler Sicherheits- und Datenschutzrisiken erfordern bewährte Methoden zur Behebung von Datenverletzungen in der Rückschlussphase die Einhaltung von Vorschriften in einzelnen Branchen. Beispiele hierfür sind Warnungen aufgrund der Nichteinhaltung von gesetzlichen Vorschriften in Bezug auf geschützte Gesundheitsdaten und personenbezogene Daten oder Warnungen aufgrund von Verstößen gegen nationale/regionale Sicherheitsgesetze.
Nächste Schritte
Weitere Informationen über verantwortungsbewusste KI finden Sie in den Richtlinien für die Interaktion zwischen Mensch und KI.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für