Zugriffssteuerung und Data Lake-Konfigurationen in Azure Data Lake Storage Gen2
Mit diesem Artikel bewerten und verstehen Sie die Mechanismen zur Zugriffssteuerung in Azure Data Lake Storage Gen2 noch besser. Die Mechanismen enthalten sowohl rollenbasierte Zugriffssteuerung (RBAC) in Azure als auch Zugriffssteuerungslisten (ACLs). Folgendes wird beschrieben:
- Bewerten des Zugriffs zwischen Azure RBAC und ACLs
- Konfiguration der Zugriffssteuerung mit einem oder beiden dieser Mechanismen
- Anwendung dieser Mechanismen zur Zugriffssteuerung auf Data Lake-Implementierungsmuster
Sie benötigen grundlegende Kenntnisse zu Speichercontainern, Sicherheitsgruppen, Azure RBAC und ACLs. Um die Diskussion zu gestalten, verweisen wir auf eine allgemein gehaltene Data Lake-Struktur von rohen, angereicherten und gepflegten Zonen.
Sie können dieses Dokument mit Datenzugriffsverwaltung verwenden.
Verwenden der integrierten Azure RBAC-Rollen
Azure Storage verfügt über zwei Zugriffsebenen: Dienstverwaltung und Daten. Sie können auf Abonnements und Speicherkonten über die Dienstverwaltungsebene zugreifen. Auf Container, Blobs und andere Datenressourcen wird über die Datenebene zugegriffen. Wenn Sie beispielsweise eine Liste mit Ihren Speicherkonten aus Azure abrufen möchten, senden Sie eine Anforderung an den Verwaltungsendpunkt. Wenn Sie eine Liste der Dateisysteme, Ordner oder Dateien in einem Speicherkonto wünschen, senden Sie eine Anforderung an einen Dienstendpunkt.
Rollen können Berechtigungen für den Zugriff auf die Verwaltungs- oder Datenebene enthalten. Die Rolle „Leser“ gewährt schreibgeschützten Zugriff auf Ressourcen der Verwaltungsebene, aber keinen Lesezugriff auf Daten.
Rollen wie Besitzer, Mitwirkender, Leser und Mitwirkender am Speicherkonto ermöglichen einem Sicherheitsprinzipal die Verwaltung eines Speicherkontos. Sie bieten jedoch keinen Zugriff auf die Daten in diesem Konto. Nur Rollen, die explizit für den Datenzugriff definiert sind, ermöglichen einem Sicherheitsprinzipal den Zugriff auf Daten. Diese Rollen, außer „Leser“, erhalten Zugriff auf die Speicherschlüssel, um auf Daten zuzugreifen.
Integrierte Verwaltungsrollen
Integrierte Verwaltungsrollen sind die folgenden.
- Besitzer: Sie können alles verwalten, einschließlich des Zugriffs auf Ressourcen. Diese Rolle bietet Schlüsselzugriff.
- Mitwirkender: Kann alles verwalten, mit Ausnahme von Zugriff auf Ressourcen. Diese Rolle bietet Schlüsselzugriff.
- Speicherkontomitwirkender: Vollständige Verwaltung von Speicherkonten. Diese Rolle bietet Schlüsselzugriff.
- Leser: Lesen und Auflisten von Ressourcen. Diese Rolle bietet keinen Schlüsselzugriff.
Integrierte Datenrollen
Integrierte Datenrollen sind die folgenden.
- Besitzer von Speicherblobdaten: Vollzugriff auf Azure Storage-Blobcontainer und -daten, einschließlich Festlegen von Eigentum und Verwaltung der POSIX-Zugriffssteuerung.
- Mitwirkender an Speicherblobdaten: Lesen, Schreiben und Löschen von Azure Storage-Containern und -Blobs.
- Leser von Speicherblobdaten: Lesen und Auflisten von Azure Storage-Containern und -Blobs.
Der Besitzer von Speicherblobdaten ist eine Superbenutzerrolle, die Vollzugriff auf alle mutierenden Vorgänge erhält. Zu diesen Vorgängen gehören das Festlegen des Besitzers eines Verzeichnisses oder einer Datei sowie ACLs für Verzeichnisse und Dateien, von denen sie nicht der Besitzer sind. Dieser Administratorzugriff ist die einzige autorisierte Möglichkeit, den Besitzer einer Ressource zu ändern.
Hinweis
Es kann bis zu fünf Minuten dauern, bis Azure RBAC-Zuweisungen sich verbreiten und wirksam werden.
Wie Zugang bewertet wird
Während der auf Sicherheitsprinzipalen beruhenden Autorisierung wertet das System Berechtigungen in der folgenden Reihenfolge aus. Weitere Informationen finden Sie unter dem folgenden Diagramm.
- Azure RBAC werden zuerst ausgewertet und haben Vorrang vor allen ACL-Zuweisungen.
- Wenn der Vorgang auf Grundlage des Azure RBAC bereits vollständig autorisiert ist, werden ACLs überhaupt nicht ausgewertet.
- Wenn der Vorgang nicht vollständig autorisiert ist, werden ACLs ausgewertet.
Für weitere Informationen siehe Wie Berechtigungen ausgewertet werden.
Hinweis
Dieses Berechtigungsmodell gilt nur für Azure Data Lake Storage. Sie gilt nicht für den universellen Speicher oder Blobspeicher ohne aktivierten hierarchischen Namespace.
Diese Beschreibung schließt die Authentifizierungsmethoden für gemeinsam genutzte Schlüssel und SAS aus. Außerdem schließt sie Szenarien aus, in denen dem Sicherheitsprinzipal die integrierte Rolle Speicher-Blobdatenbesitzer zugewiesen wurde, die den Zugriff als Superbenutzer ermöglicht.
Legen Sie allowSharedKeyAccess auf FALSE fest, damit der Zugriff anhand der Identität überwacht wird.

Weitere Informationen dazu, welche ACL-basierten Berechtigungen für einen bestimmten Vorgang erforderlich sind, finden Sie unter Zugriffssteuerungslisten in Azure Data Lake Storage Gen2.
Hinweis
- Zugriffssteuerungslisten gelten nur für Sicherheitsprinzipale im gleichen Mandanten, einschließlich Gastbenutzern.
- Jeder Benutzer mit Berechtigungen zum Anfügen an einen Cluster kann Azure Databricks Bereitstellungspunkte erstellen. Konfigurieren Sie den Bereitstellungspunkt mithilfe von Anmeldeinformationen des Dienstprinzipals oder der Passthrough-Option von Microsoft Entra. Zum Zeitpunkt der Erstellung werden Berechtigungen nicht ausgewertet. Berechtigungen werden ausgewertet, wenn ein Vorgang den Bereitstellungspunkt verwendet. Jeder Benutzer, der an einen Cluster anfügen kann, kann versuchen, den Bereitstellungspunkt zu verwenden.
- Beim Erstellen einer Tabellendefinition in Azure Databricks oder Azure Synapse Analytics benötigt der Benutzer Lesezugriff auf die zugrunde liegenden Daten.
Konfigurieren des Zugriffs auf Azure Data Lake Storage Gen2
Richten Sie die Zugriffssteuerung in Azure Data Lake Storage mithilfe von Azure RBAC, ACLs oder einer Kombination aus beiden ein.
Konfigurieren des Zugriffs nur mithilfe von Azure RBAC
Wenn die Zugriffssteuerung auf Containerebene ausreichend ist, bieten Azure RBAC-Zuweisungen einen einfachen Verwaltungsansatz zum Schützen von Daten. Es wird empfohlen, Zugriffssteuerungslisten für eine große Anzahl von Datenressourcen mit Zugangsbeschränkung zu verwenden, oder wenn Sie eine besonders genaue Zugriffssteuerung erfordern.
Konfigurieren des Zugriffs nur mithilfe von ACLs
Im Folgenden finden Sie Konfigurationsempfehlungen für Zugriffssteuerungslisten für Analysen auf Cloudebene.
Weisen Sie Zugriffssteuerungseinträge nicht einem einzelnen Benutzer oder Dienstprinzipal, sondern einer Sicherheitsgruppe zu. Für weitere Informationen siehe Verwenden von Sicherheitsgruppen im Vergleich zu einzelnen Nutzern.
Wenn Sie der Gruppe Benutzer hinzufügen oder daraus entfernen, müssen Sie keine Aktualisierungen an Data Lake Storage vornehmen. Die Verwendung von Gruppen verringert auch die Wahrscheinlichkeit, dass die 32 Zugriffssteuerungseinträge pro Datei oder Ordner-ACL überschritten werden. Nach den vier Standardeinträgen sind nur noch 28 Einträge für Berechtigungszuweisungen verfügbar.
Auch wenn Sie Gruppen verwenden, haben Sie möglicherweise viele Zugriffssteuerungseinträge auf den obersten Ebenen der Verzeichnisstruktur. Diese Situation tritt auf, wenn sehr genau ausdifferenzierte Berechtigungen für verschiedene Gruppen erforderlich sind.

Konfigurieren des Zugriffs mithilfe von Azure RBAC und Zugriffssteuerungslisten
Die Berechtigungen Speicher-Blobdatenmitwirkender und Speicher-Blobdatenleser ermöglichen den Zugriff auf die Daten und nicht auf das Speicherkonto. Sie können Zugriff auf Speicherkonto- oder Containerebene gewähren. Wenn Speicher-Blobdatenmitwirkender zugewiesen ist, können ACLs nicht zum Verwalten des Zugriffs verwendet werden. Wenn Speicher-Blobdatenleser zugewiesen ist, Sie können mithilfe von ACLs erhöhte Schreibberechtigungen erteilen. Für weitere Informationen siehe Wie Zugriff ausgewertet wird.
Dieser Ansatz ist günstig für Szenarien, in denen die meisten Benutzer Lesezugriff benötigen, aber nur wenige Benutzer Schreibzugriff brauchen. Die Data Lake-Zonen können unterschiedliche Speicherkonten sein, und Datenressourcen können unterschiedliche Container sein. Die Data Lake-Zonen können durch Container und Datenressourcen dargestellt werden, die wiederum durch Ordner dargestellt werden.
Ansätze für geschachtelte Zugriffssteuerung für Gruppen
Es gibt zwei Ansätze für geschachtelte ACL-Gruppen.
Option 1: Die übergeordnete Ausführungsgruppe
Bevor Sie Dateien und Ordner erstellen, beginnen Sie mit einer übergeordneten Gruppe. Weisen Sie diese Gruppenlaufberechtigungen sowohl Standard- als auch Zugriffs-ACLs auf Containerebene zu. Fügen Sie dann die Gruppen hinzu, die Datenzugriff auf die übergeordnete Gruppe erfordern.
Warnung
Wir empfehlen, dieses Muster bei rekursiven Löschungen nicht zu verwenden und stattdessen Option 2: Der andere Eintrag der Zugriffskontrollliste zu verwenden.
Dieses Verfahren wird als Gruppenschachtelung bezeichnet. Die Mitgliedergruppe erbt die Berechtigungen der übergeordneten Gruppe, die globale Ausführungsberechtigungen für alle Mitgliedergruppen bereitstellt. Die Mitgliedergruppe benötigt keine Ausführungsberechtigungen, da diese Berechtigungen geerbt werden. Eine höhere Schachtelung kann mehr Flexibilität und Agilität bieten. Fügen Sie den Lese- und Schreibgruppen für Datenzugriff Sicherheitsgruppen hinzu, die Teams oder automatisierte Aufträge darstellen.
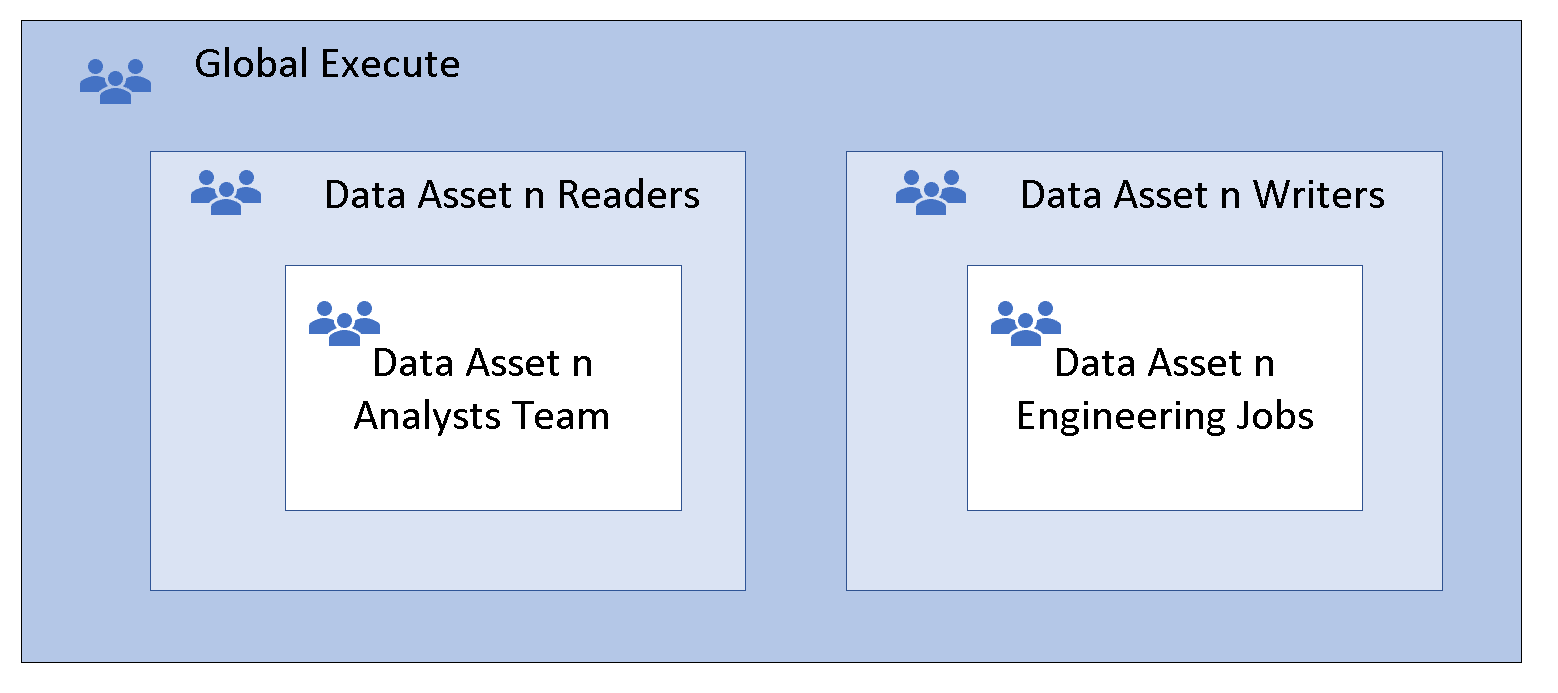
Option 2: Der andere Eintrag der Zugriffssteuerungsliste
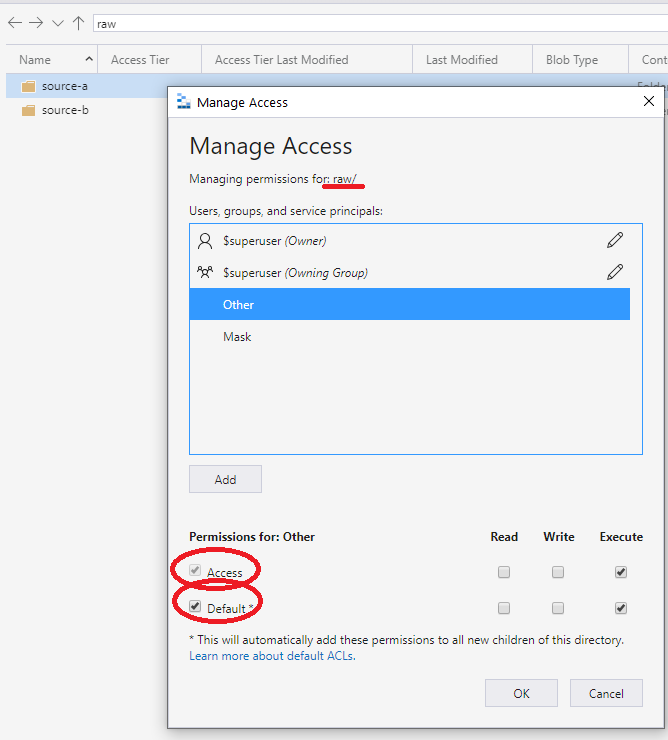
Der empfohlene Ansatz besteht darin, den anderen Eintragssatz für die ACL im Container oder Stammverzeichnis zu verwenden. Standardwerte und Zugriffs-ACLs sind wie im folgenden Bildschirm gezeigt. Dieser Ansatz stellt sicher, dass jeder Teil des Pfads vom Stamm zur niedrigsten Ebene über Ausführungsberechtigungen verfügt.
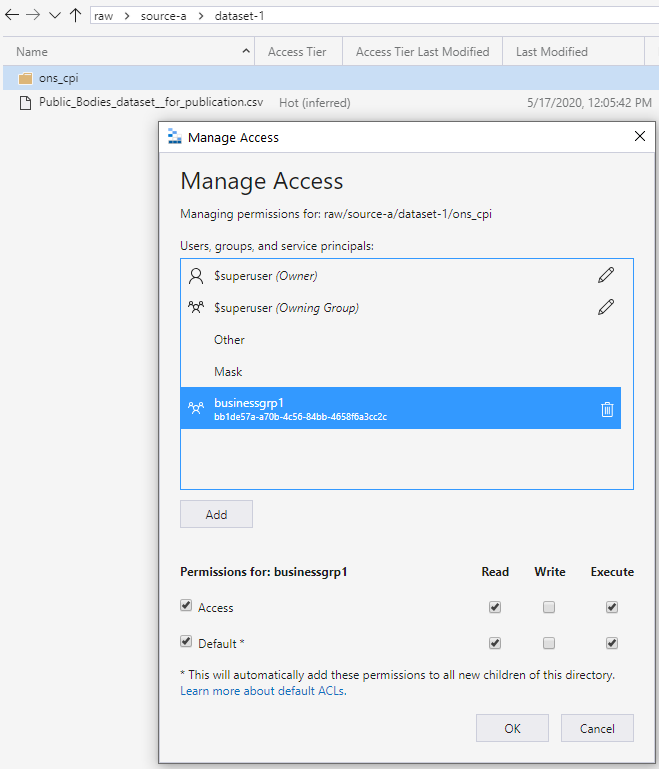
Diese Ausführungsberechtigung verbreitet alle hinzugefügten nachgeordneten Ordner nach unten. Die Berechtigung wird an die Tiefe weitergegeben, in der die beabsichtigte Zugriffsgruppe Berechtigungen zum Lesen und Ausführen benötigt. Diese Ebene befindet sich im untersten Teil der Kette, wie im folgenden Bildschirm dargestellt. Dieser Ansatz gewährt Gruppenzugriff zum Lesen der Daten. Der Ansatz funktioniert beim Schreibzugriff ähnlich.
Empfohlene Sicherheit für Data Lake-Zonen.
Die folgenden Verwendungen sind die empfohlenen Sicherheitsmuster für jede der Data Lake-Zonen:
- Im Rohzustand sollte der Zugriff auf Daten nur mithilfe von Sicherheitsprinzipalnamen (SPNs) zugelassen sein.
- Im angereicherten Zustand sollte der Zugriff auf Daten nur mithilfe von Sicherheitsprinzipalnamen (SPNs) zugelassen sein.
- Im gepflegten Zustand sollte der Zugriff sowohl mit Sicherheitsprinzipalnamen (SPNs) als auch mit Benutzerprinzipalnamen (UPNs) zugelassen sein.
Beispielszenario für die Verwendung von Microsoft Entra-Sicherheitsgruppen
Es gibt viele verschiedene Möglichkeiten zum Einrichten von Gruppen. Angenommen, Sie haben ein Verzeichnis namens /LogData, das Protokolldaten enthält, die von Ihrem Server generiert werden. Azure Data Factory erfasst Daten in diesen Ordner hinein. Bestimmte Benutzer aus dem Service-Engineeringteam laden Protokolle hoch und verwalten andere Benutzer dieses Ordners. Die Azure Databricks-Analysen und Data Science-Arbeitsbereichscluster können Protokolle aus diesem Ordner analysieren.
Um diese Aktivitäten zu ermöglichen, können Sie eine LogsWriter-Gruppe und eine LogsReader-Gruppe erstellen. Weisen Sie die folgenden Berechtigungen zu:
- Fügen Sie die Gruppe
LogsWriterzur ACL des Verzeichnisses/LogDatamitrwx-Berechtigungen hinzu. - Fügen Sie die Gruppe
LogsReaderzur ACL des Verzeichnisses/LogDatamitr-x-Berechtigungen hinzu. - Fügen Sie das Dienstprinzipalobjekt oder die verwaltete Dienstidentität (Managed Service Identity, MSI) für Data Factory zur
LogsWriters-Gruppe hinzu. - Fügen Sie Benutzer aus dem IT-Support-Team zur
LogsWriter-Gruppe hinzu. - Azure Databricks wird für Microsoft Entra-Passthrough zu Azure Data Lake Store konfiguriert.
Wenn ein Benutzer im Service Engineering-Team zu einem anderen Team wechselt, entfernen Sie einfach diese Benutzer aus der LogsWriter- Gruppe.
Wenn Sie diesen Benutzer nicht zu einer Gruppe hinzugefügt, sondern stattdessen einen dedizierten ACL-Eintrag für den Benutzer hinzugefügt hätten, müssen Sie diesen ACL-Eintrag aus dem /LogData-Verzeichnis entfernen. Außerdem müssen Sie den Eintrag aus allen Unterverzeichnissen und Dateien in der gesamten Verzeichnishierarchie des /LogData-Verzeichnisses entfernen.
Datenzugriffssteuerung für Azure Synapse Analytics
Zum Bereitstellen eines Azure Synapse-Arbeitsbereichs ist ein Azure Data Lake Storage Gen2-Konto erforderlich. Azure Synapse Analytics verwendet das primäre Speicherkonto für verschiedene Integrationsszenarien und speichert Daten in einem Container. Der Container enthält Apache Spark-Tabellen und Anwendungsprotokolle in einem Ordner namens /synapse/{workspaceName} Der Arbeitsbereich verwendet auch Container für die Verwaltung von Bibliotheken, die Sie installieren.
Geben Sie während der Bereitstellung des Arbeitsbereichs durch das Azure-Portalein vorhandenes Speicherkonto an, oder erstellen Sie ein neues. Das bereitgestellte Speicherkonto ist das primäre Speicherkonto für den Arbeitsbereich. Der Bereitstellungsprozess gewährt der Arbeitsbereichsidentität Zugriff auf das angegebene Data Lake Storage Gen2-Konto mithilfe der Rolle Speicher-Blobdaten-Mitwirkender.
Wenn Sie den Arbeitsbereich außerhalb des Azure-Portal bereitstellen, fügen Sie Azure Synapse Analytics Arbeitsbereichsidentität manuell der Rolle Speicher-Blobdaten-Mitwirkender hinzu. Es wird empfohlen, die Rolle Speicher-Blobdaten-Mitwirkender auf Containerebene zuzuweisen, um das Prinzip der geringsten Rechte zu beachten.
Beim Ausführen von Pipelines, Workflows und Notebooks über Aufträge, verwenden diese den Berechtigungskontext für die Arbeitsbereichsidentität. Wenn einer der Aufträge den primären Speicher des Arbeitsbereichs liest oder in diesen schreibt, verwendet die Arbeitsbereichsidentität die Lese-/Schreibberechtigungen, die über den Speicher-Blobdaten-Mitwirkenden erteilt wurden.
Wenn sich Benutzer beim Arbeitsbereich anmelden, um Skripts auszuführen oder für die Entwicklung, ermöglichen die Kontextberechtigungen des Benutzers Lese-/Schreibzugriff auf den primären Speicher.
Azure Synapse Analytics besitzt eine fein abgrenzende Datenzugriffssteuerung mithilfe von Zugriffssteuerungslisten
Beim Einrichten der Data Lake-Zugriffssteuerung benötigen einige Organisationen präzisen Zugriff auf bestimmte Ebenen. Sie verfügen möglicherweise über vertrauliche Daten, die einigen Gruppen in der Organisation nicht gezeigt werden dürfen. Azure RBAC lässt Lese- oder Schreibzugriff nur auf Speicherkonto- und Containerebene zu. Mit ACLs können Sie eine fein abgrenzende Zugriffssteuerung auf Ordner- und Dateiebene einrichten, um Lese-/Schreibzugriff auf Teilmengen von Daten für bestimmte Gruppen zu ermöglichen.
Überlegungen bei der Verwendung von Spark-Tabellen
Wenn Sie die Tabellen von Apache Spark im Spark-Pool verwenden, wird ein Warehouseordner erstellt. Der Ordner befindet sich im Stammverzeichnis des Containers im primären Speicher des Arbeitsbereichs:
synapse/workspaces/{workspaceName}/warehouse
Wenn Sie planen, Apache Spark-Tabellen im Azure Synapse Spark-Pool zu erstellen, erteilen Sie der Gruppe, die den Befehl zum Erstellen der Spark-Tabelle erteilt, Schreibberechtigung für denWarehouse-Ordner. Wenn der Befehl durch einen ausgelösten Auftrag in einer Pipeline ausgeführt wird, erteilen Sie der Arbeitsbereich-MSI Schreibberechtigung.
In diesem Beispiel wird eine Spark-Tabelle erstellt:
df.write.saveAsTable("table01")
Für weitere Informationen siehe Einrichten der Zugriffssteuerung für Ihren Synapse-Arbeitsbereich.
Zusammenfassung des Azure Data Lake-Zugriffs
Es gibt keinen Ansatz für die Verwaltung des Data Lake-Zugriffs, der für jedermann geeignet wäre. Ein großer Vorteil eines Data Lake ist der reibungslose Zugriff auf Daten. In der Praxis wünschen sich verschiedene Organisationen unterschiedliche Governance- und Steuerungsebenen für ihre Daten. Einige Organisationen haben ein zentralisiertes Team zum Verwalten des Zugriffs und zum Versorgen von Gruppen unter strengen internen Kontrollen. Andere Organisationen sind flexibler und haben eine dezentralisierte Kontrolle. Wählen Sie den Ansatz aus, der Ihrem Niveau von Governance entspricht. Ihre Wahl sollte nicht zu übermäßigen Verzögerungen oder Spannungen beim Zugriff auf Daten führen.