Was ist eine Bildanalyse?
Der Image Analysis-Dienst von Azure KI Vision kann eine Vielzahl von visuellen Features aus Ihren Bildern extrahieren. Beispielsweise kann es ermitteln, ob ein Bild nicht jugendfreie Inhalte aufweist, oder es können bestimmte Marken oder Objekte oder menschliche Gesichter gesucht werden.
Die neueste Version der Bildanalyse, 4.0, die jetzt allgemein verfügbar ist, bietet neue Features wie synchrone OCR und Personenerkennung. Sie sollten zukünftig diese Version verwenden.
Sie können die Bild-Analyse in Ihrer Anwendung über ein Clientbibliothek-SDK oder durch direktes Aufrufen der REST API nutzen. Im Schnellstart erfahren Sie mehr zu den ersten Schritten.
Alternativ können Sie die Funktionen der Bildanalyse mit Vision Studio ganz schnell und einfach in Ihrem Browser ausprobieren.
Diese Dokumentation enthält die folgenden Arten von Artikeln:
- In den Schnellstarts finden Sie Schritt-für-Schritt-Anleitungen, mit denen Sie Aufrufe an den Dienst senden können und in kurzer Zeit Ergebnisse erhalten.
- Die Anleitungen enthalten Anweisungen zur spezifischeren oder individuelleren Verwendung des Diensts.
- Die konzeptionellen Artikel enthalten ausführliche Erläuterungen der Funktionen und Features eines Diensts.
- Die Tutorials sind ausführlichere Leitfäden, in denen die Verwendung dieses Diensts als Komponente in umfassenderen Unternehmenslösungen veranschaulicht wird.
Für einen strukturierteren Ansatz folgen Sie einem Trainingsmodul für die Bildanalyse.
Versionen der Bildanalyse
Wichtig
Wählen Sie die Version der Bildanalyse-API aus, die Ihren Anforderungen am besten entspricht.
| Version | Verfügbare Funktionen | Empfehlung |
|---|---|---|
| Version 4.0 | Text lesen, Beschriftungen, Dense Captioning, Tags, Objekterkennung, Benutzerdefinierte Bildklassifizierung/Objekterkennung, Personen, Intelligentes Zuschneiden | Bessere Modelle, verwenden Sie Version 4.0, wenn sie Ihren Anwendungsfall unterstützt. |
| Version 3.2 | Tags, Objekte, Beschreibungen, Marken, Gesichter, Bildtyp, Farbschema, Wahrzeichen, Prominente, Erwachsene Inhalte, Intelligentes Zuschneiden | Größere Auswahl an Features, verwenden Sie Version 3.2, wenn Ihr Anwendungsfall in Version 4.0 noch nicht unterstützt wird |
Es wird empfohlen, die Bildanalyse-API 4.0 zu verwenden, wenn sie Ihren Anwendungsfall unterstützt. Verwenden Sie Version 3.2, wenn Ihr Anwendungsfall von 4.0 noch nicht unterstützt wird.
Sie müssen auch Version 3.2 verwenden, wenn Sie Bildbeschriftungen ausführen möchten und sich Ihre Vision-Ressource für maschinelles Sehen außerhalb dieser Azure-Regionen befindet: „Asien, Osten“, „Asien, Südosten“, „Europa, Norden“, „Europa, Westen“, „Frankreich, Mitte“, „Südkorea, Mitte“, „USA, Osten“ oder „USA, Westen“. Das Feature für die Bildbeschriftung in der Bildanalyse 4.0 wird nur in diesen Azure-Regionen unterstützt. Die Bildbeschriftung in Version 3.2 ist in allen Azure KI Vision-Regionen verfügbar.
Bild analysieren
Sie können Bilder analysieren, um Erkenntnisse zu visuellen Merkmalen und Eigenschaften zu gewinnen. Alle Features in dieser Liste werden von der API für die Bildanalyse bereitgestellt. Nutzen Sie einen Schnellstart, um erste Schritte auszuführen.
| Name | BESCHREIBUNG | Konzeptseite |
|---|---|---|
| Modellanpassung (nur Vorschauversion v4.0) | Sie können benutzerdefinierte Modelle für die Bildklassifizierung oder Objekterkennung erstellen und trainieren. Bringen Sie Ihre eigenen Bilder mit, beschriften Sie diese mit benutzerdefinierten Tags, und die Bildanalyse wird ein benutzerdefiniertes Modell für Ihren Anwendungsfall trainieren. | Modellanpassung |
| Lesen von Text aus Bildern (nur Version 4.0) | Version 4.0 (Vorschauversion) der Bildanalyse bietet die Möglichkeit, lesbaren Text aus Bildern zu extrahieren. Im Vergleich zur asynchronen allgemein verfügbaren Lese-API für maschinelles Sehen 3.2 bietet die neue Version das vertraute Lese-OCR-Modul in einer einheitlichen, leistungsoptimierten synchronen API. Diese macht es einfach, OCR zusammen mit anderen Erkenntnissen mit einem einzigen API-Aufruf zu erhalten. | OCR für Bilder |
| Erkennen von Personen in Bildern (nur Version 4.0) | Version 4.0 der Bildanalyse bietet die Möglichkeit, Personen auf Bildern zu erkennen. Die Koordinaten des Begrenzungsrahmens für jede erkannte Person werden zusammen mit einer Konfidenzbewertung zurückgegeben. | Personenerkennung |
| Generieren von Bildbeschriftungen | Generieren Sie eine Beschriftung für ein Bild mit vollständigen Sätzen in einer für Menschen lesbaren Sprache. Algorithmen für maschinelles Sehen generieren Beschriftungen auf der Grundlage der im Bild erkannten Objekte. Die Version 40 des Bildbeschriftungsmodells ist eine erweiterte Implementierung und funktioniert mit einer größeren Palette von Eingabebildern. Es ist nur in den folgenden geografischen Regionen verfügbar: „USA, Osten“, „Frankreich, Mitte“, „Südkorea, Mitte“, „Europa, Norden“, „Asien, Südosten“, „Europa, Westen“, „USA, Westen“. Mit Version 4.0 können Sie auch eine dichte Beschriftung verwenden, die detaillierte Beschriftungen für einzelne Objekte generiert, die im Bild gefunden werden. Die API gibt die Begrenzungsrahmenkoordinaten (in Pixeln) für jedes im Bild gefundene Objekt sowie eine Beschriftung zurück. Sie können diese Funktionalität verwenden, um Beschreibungen einzelner Teile eines Bilds zu generieren. 
|
Generieren von Bildbeschriftungen (v3.2) (Version 4.0) |
| Erkennen von Objekten | Die Objekterkennung ähnelt dem Tagging, die API gibt jedoch die Koordinaten des Begrenzungsrahmens für jedes angewendete Tag zurück. Wenn ein Bild z. B. einen Hund, eine Katze und eine Person enthält, werden diese Objekte bei der Erkennung zusammen mit ihren Koordinaten im Bild aufgelistet. Sie können diese Funktion verwenden, um weitere Beziehungen zwischen den Objekten in einem Bild zu verarbeiten. Außerdem können Sie feststellen, ob mehrere Instanzen des gleichen Tags in einem Bild enthalten sind. 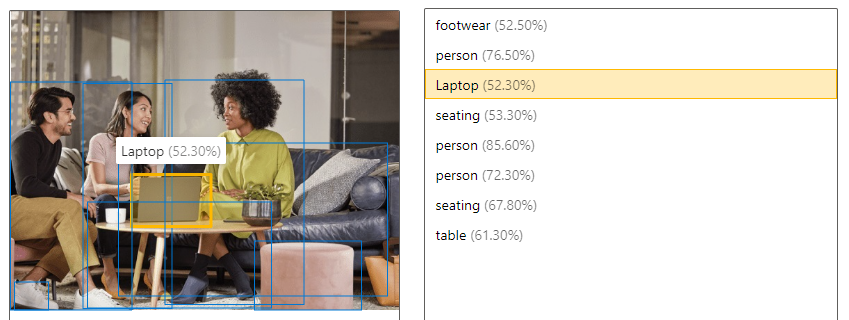
|
Erkennen von Objekten (v3.2) (Version 4.0) |
| Markieren visueller Merkmale | Erkennen und markieren Sie visuelle Merkmale in einem Bild auf der Grundlage von Tausenden von erkennbaren Objekten, Lebewesen, Landschaften und Aktionen. Wenn die Tags nicht eindeutig sind oder nicht zum Allgemeinwissen gehören, enthält die API-Antwort Hinweise, um den Kontext des Tags zu verdeutlichen. Die Markierung ist nicht auf den Hauptinhalt (etwa eine Person im Vordergrund) beschränkt, sondern bezieht auch die Umgebung (Innen- oder Außenbereich), Möbel, Werkzeuge, Pflanzen, Tiere, Zubehör, Geräte und Ähnliches mit ein.
|
Markieren visueller Merkmale (v3.2) (Version 4.0) |
| Abrufen des relevanten Bereichs/intelligentes Zuschneiden | Analysieren Sie den Inhalt eines Bilds, um die Koordinaten des relevanten Bereichs zurückzugeben, der einem angegebenen Seitenverhältnis entspricht. Maschinelles Sehen gibt die Koordinaten des Begrenzungsrahmens des Bereichs zurück, sodass die aufrufende Anwendung das ursprüngliche Bild nach Bedarf ändern kann. Das Version 4.0 des Modells für intelligentes Zuschneiden ist eine erweiterte Implementierung und funktioniert mit einer größeren Palette von Eingabebildern. Es ist nur in den folgenden geografischen Regionen verfügbar: „USA, Osten“, „Frankreich, Mitte“, „Südkorea, Mitte“, „Europa, Norden“, „Asien, Südosten“, „Europa, Westen“, „USA, Westen“. |
Generieren einer Miniaturansicht (v3.2) (Vorschauversion v4.0) |
| Erkennen von Marken (nur v3.2) | Erkennen Sie auf Bildern oder in Videos kommerzielle Marken auf der Grundlage einer Datenbank mit Tausenden Logos aus der ganzen Welt. Mit diesem Feature können Sie beispielsweise ermitteln, welche Marken in sozialen Medien besonders beliebt sind oder besonders gerne in Medien platziert werden. | Erkennen von Marken |
| Kategorisieren eines Bilds (nur v3.2) | Erkennen und kategorisieren Sie ein gesamtes Bild unter Verwendung einer Kategorietaxonomie mit über-/untergeordneten vererbbaren Hierarchien. Kategorien können einzeln oder in Kombination mit unseren neuen Markierungsmodellen verwendet werden. Als Sprache für die Markierung und Kategorisierung von Bildern wird derzeit nur Englisch unterstützt. |
Kategorisieren eines Bilds |
| Erkennen von Gesichtern (nur v3.2) | Erkennen Sie Gesichter in einem Bild, und stellen Sie Informationen zu den einzelnen Gesichtern bereit. Azure KI Vision gibt für jedes erkannte Gesicht die Koordinaten, ein Rechteck, das Geschlecht und das Alter zurück. Sie können auch die dedizierte Gesichtserkennungs-API für diese Zwecke verwenden. Diese ermöglicht eine eingehendere Analyse, z. B. für den Gesichtsausdruck, die Kopfhaltung und Ähnliches. |
Erkennen von Gesichtern |
| Erkennen von Bildtypen (nur v3.2) | Erkennen Sie Merkmale eines Bilds – also beispielsweise, ob es sich bei dem Bild um eine Strichzeichnung handelt oder wie wahrscheinlich es ist, dass es sich bei dem Bild um ein ClipArt handelt. | Erkennen von Bildtypen |
| Erkennen domänenspezifischer Inhalte (nur v3.2) | Verwenden Sie Domänenmodelle, um domänenspezifische Inhalte (etwa berühmte Personen und Orientierungspunkte) in einem Bild zu erkennen. Wenn ein Bild also beispielsweise Personen enthält, kann Azure KI Vision auf ein Domänenmodell für berühmte Personen zurückgreifen und so ermitteln, ob es sich bei den Personen auf dem Bild um berühmte Personen handelt. | Erkennen domänenspezifischer Inhalte |
| Erkennen des Farbschemas (nur v3.2) | Analysieren Sie die Farben eines Bilds. Azure KI Vision kann ermitteln, ob es sich um ein Schwarzweißbild oder um ein Farbbild handelt. Bei Farbbildern kann maschinelles Sehen außerdem die dominante Farbe sowie Akzentfarben erkennen. | Erkennen des Farbschemas |
| Moderieren von Inhalten in Bildern (nur v3.2) | Azure KI Vision ermöglicht die Erkennung nicht jugendfreier Inhalte in einem Bild sowie die Rückgabe einer Zuverlässigkeitsbewertung für verschiedene Klassifizierungen. Der Schwellenwert für die Kennzeichnung von Inhalten kann mithilfe eines Schiebereglers nach Bedarf angepasst werden. | Erkennen nicht jugendfreier Inhalte |
Tipp
Sie können die Features „Text lesen“ und „Objekterkennung“ der Bildanalyse über den Azure OpenAI-Dienst verwenden. Mit dem Modell GPT-4 Turbo mit Vision können Sie mit einem KI-Assistenten chatten, der die von Ihnen freigegebenen Bilder analysieren kann. Die Option „Vision-Erweiterung“ verwendet die Bildanalyse, um dem KI-Assistenten zusätzliche Details (lesbarer Text und Objektpositionen) zum Bild zu liefern. Weitere Informationen finden Sie im Schnellstart zu GPT-4 Turbo mit Vision.
Produkterkennung (nur Vorschauversion v4.0)
Mit den Produkterkennungs-APIs können Sie Fotos von Regalen in einem Einzelhandelsgeschäft analysieren. Sie können das Vorhandensein oder Nichtvorhandensein von Produkten erkennen und deren Begrenzungsrahmenkoordinaten abrufen. Verwenden Sie sie in Kombination mit der Modellanpassung, um ein Modell zur Identifizierung Ihrer Produkte zu trainieren. Sie können die Ergebnisse der Produkterkennung auch mit dem Planogrammdokument Ihres Ladens vergleichen.
Multimodale Einbettungen (nur v4.0)
Die APIs für multimodale Einbettungen ermöglichen die Vektorisierung von Bild- und Textabfragen. Sie konvertieren Bilder in Koordinaten in einem mehrdimensionalen Vektorraum. Dann können eingehende Textabfragen auch in Vektoren konvertiert werden, und Bilder können basierend auf semantischer Nähe mit dem Text abgeglichen werden. Dadurch kann der Benutzer eine Reihe von Bildern mithilfe von Text durchsuchen, ohne dass Bildtags oder andere Metadaten verwendet werden müssen. Die semantische Nähe führt häufig zu besseren Ergebnissen in der Suche.
Die 2024-02-01-API enthält ein mehrsprachiges Modell, das die Textsuche in 102 Sprachen unterstützt. Das ursprüngliche englischsprachige Modell ist weiterhin verfügbar, kann aber nicht mit dem neuen Modell im selben Suchindex kombiniert werden. Wenn Sie Text und Bilder mit dem rein englischsprachigen Modell vektorisiert haben, sind diese Vektoren nicht mit mehrsprachigen Text- und Bildvektoren kompatibel.
Diese APIs sind nur in den folgenden geografischen Regionen verfügbar: „USA, Osten“, „Frankreich, Mitte“, „Südkorea, Mitte“, „Europa, Norden“, „Asien, Südosten“, „Europa, Westen“, „USA, Westen“.
Hintergrundentfernung (nur Vorschauversion v4.0)
Die Bildanalyse 4.0 (Vorschauversion) bietet die Möglichkeit, den Hintergrund eines Bilds zu entfernen. Dieses Feature kann entweder ein Bild des erkannten Vordergrundobjekts mit transparentem Hintergrund oder ein Graustufen-Alpha-Mattbild ausgeben, das die Deckkraft des erkannten Vordergrundobjekts anzeigt.
| Originalbild | Mit entferntem Hintergrund | Alpha-Matte |
|---|---|---|

|

|

|
Bildanforderungen
Die Bild-Analyse kann Bilder analysieren, die folgende Anforderungen erfüllen:
- Das Bild muss im JPEG-, PNG-, GIF-, BMP-, WEBP-, ICO-, TIFF- oder MPO-Format übergeben werden.
- Die Dateigröße muss weniger als 20 MB betragen.
- Die Abmessungen des Bilds müssen größer als 50 x 50 Pixel und kleiner als 16.000 x 16.000 Pixel sein.
Tipp
Die Anforderungen an die Eingaben für multimodale Einbettungen unterscheiden sich. Sie finden sie unter Multimodale Einbettungen.
Datenschutz und Sicherheit
Wie bei allen Azure KI Services müssen Entwickler, die den Azure KI Vision-Dienst nutzen, die Microsoft-Richtlinien zu Kundendaten beachten. Weitere Informationen finden Sie im Microsoft Trust Center auf der Seite zu Azure KI Services.
Nächste Schritte
Führen Sie anhand der Schnellstartanleitung in der bevorzugten Entwicklungssprache erste Schritte für die Bild-Analyse aus: