Konfigurieren der Lernschleife der Personalisierung
Wichtig
Ab dem 20. September 2023 können Sie keine neuen Personalisierungsressourcen mehr erstellen. Der Personalisierungsdienst wird am 1. Oktober 2026 eingestellt.
Die Dienstkonfiguration umfasst die Art, wie der Dienst Belohnungen behandelt, wie oft der Dienst Untersuchungen durchführt, wie oft das Modell neu trainiert wird und wie viele Daten gespeichert werden.
Konfigurieren Sie die Lernschleife auf der Seite Konfiguration im Azure-Portal für diese Personalisierungsressource.
Planen von Konfigurationsänderungen
Da einige Konfigurationsänderungen Ihr Modell zurücksetzen, sollten Sie Ihre Konfigurationsänderungen planen.
Wenn Sie planen, den Ausbildungsmodus zu verwenden, stellen Sie sicher, dass Sie Ihre Personalisierungskonfiguration überprüfen, bevor Sie in den Ausbildungsmodus wechseln.
Einstellungen, die das Zurücksetzen des Modells einbeziehen
Die folgenden Aktionen lösen ein erneutes Training des Modells unter Verwendung der bis zu den letzten zwei Tagen verfügbaren Daten aus.
- Relevanz
- Durchsuchen
Verwenden Sie zum Löschen aller Ihrer Daten die Seite Modell- und Lerneinstellungen.
Konfigurieren von Relevanzen für die Feedbackschleife
Konfigurieren Sie den Dienst für die Verwendung von Relevanzen durch die Lernschleife. Änderungen an den folgenden Werten setzen das aktuelle Personalisierungsmodell zurück und trainieren es mit den Daten der letzten 2 Tage neu.

| Wert | Zweck |
|---|---|
| Belohnungswartezeit | Legt die Zeitspanne, während der die Personalisierung Werte für einen Rangfolgeaufruf sammelt werden, ab dem Zeitpunkt fest, zu dem der Rangfolgeaufruf erfolgt. Dieser Wert wird durch die Frage „Wie lange sollte die Personalisierung auf Belohnungsaufrufe warten?“ festgelegt. Jede Belohnung, die nach diesem Fenster eingeht, wird protokolliert, aber nicht zum Lernen verwendet. |
| Standardbelohnung | Wenn während des Zeitfensters für das Warten auf die Belohnung kein Belohnungsaufruf bei der Personalisierung eingeht, weist die Personalisierung die Standardbelohnung zu. Standardmäßig und in den meisten Szenarien ist die Standardrelevanz 0 (null). |
| Belohnungsaggregation | Wenn mehrere Belohnungen für den gleichen Rangfolge-API-Aufruf empfangen werden, wird diese Aggregationsmethode verwendet: sum oder earliest. „Earliest“ wählt das am frühesten empfangene Ergebnis aus, und der Rest wird verworfen. Dies ist nützlich, wenn Sie eine eindeutige Relevanz zwischen möglicherweise doppelten Aufrufen wünschen. |
Wählen Sie nach dem Ändern dieser Werte unbedingt Speichern aus.
Konfigurieren der Erkundung zum Anpassen der Lernschleife
Die Personalisierung kann neue Muster ermitteln und im Laufe der Zeit den Verhaltensänderungen der Benutzer durch Durchsuchen von Alternativen anpassen, anstatt die Vorhersage des trainierten Modells zu verwenden. Der Wert Erkundung bestimmt, wie viel Prozent der Rangfolgeaufrufe mit einem Durchsuchen beantwortet werden.
Änderungen an diesem Wert setzen das aktuelle Personalisierungsmodell zurück und trainieren es mit den Daten der letzten 2 Tage neu.
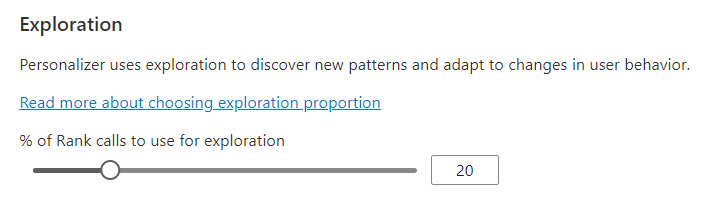
Wählen Sie nach dem Ändern dieses Werts unbedingt Speichern aus.
Konfigurieren der Häufigkeit der Modellaktualisierung für das Modelltraining
Die Häufigkeit der Modellaktualisierung legt fest, wie oft das vom Rangfolgeaufruf verwendete Modell aktualisiert wird.
| Einstellung „Häufigkeit“ | Zweck |
|---|---|
| 1 Minute | Eine Modellaktualisierungshäufigkeit von einer Minute empfiehlt sich beim Debuggen von Anwendungscode mit Personalisierung, bei Demos sowie beim interaktiven Testen von Machine Learning-Aspekten. |
| 15 Minuten | Eine hohe Modellaktualisierungshäufigkeit ist hilfreich, wenn Veränderungen beim Benutzerverhalten genau nachverfolgt werden sollen. Beispiele wären etwa Websites mit Livenachrichten, viralen Inhalten oder Livegeboten für Produkte. In solchen Szenarien kann beispielsweise eine Frequenz von 15 Minuten verwendet werden. |
| 1 Stunde | In den meisten Anwendungsfällen ist eine niedrigere Aktualisierungshäufigkeit sinnvoll. |
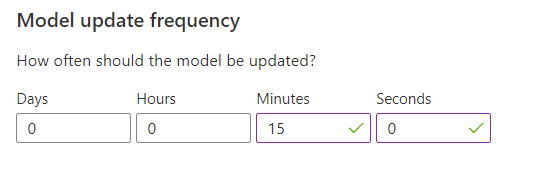
Wählen Sie nach dem Ändern dieses Werts unbedingt Speichern aus.
Beibehaltung von Daten
Data retention period (Zeitraum für die Datenaufbewahrung) legt fest, wie viele Tage die Personalisierung Datenprotokolle aufbewahrt. Frühere Datenprotokolle sind zur Durchführung von Offlineauswertungen erforderlich, die verwendet werden, um die Effektivität der Personalisierung zu messen und die Lernrichtlinie zu optimieren.
Wählen Sie nach dem Ändern dieses Werts unbedingt Speichern aus.