Was ist die Sprechererkennung?
Mithilfe der Sprechererkennung kann festgestellt werden, wer in einem Audioclip spricht. Der Dienst kann Sprecher anhand ihrer einzigartigen Stimmmerkmale mithilfe der Stimmbiometrie verifizieren und identifizieren.
Wenn Sie Audiotrainingsdaten für einen einzelnen Sprechers bereitstellen, wird basierend auf den eindeutigen Stimmmerkmalen des Sprechers ein Registrierungsprofil erstellt. Anschließend können Sie Audiostimmproben anhand dieses Profils überprüfen, um sicherzustellen, dass es sich bei dem Sprecher um dieselbe Person handelt (Sprecherüberprüfung). Sie können Audiostimmproben auch mit einer Gruppe registrierter Sprecherprofile vergleichen, um zu überprüfen, ob sie einem Profil in der Gruppe entsprechen (Sprecheridentifikation).
Wichtig
Microsoft schränkt den Zugang zur Sprechererkennung ein. Sie können den Zugriff über die Überprüfung des eingeschränkten Zugriffs der Azure KI Services-Sprecher*innenerkennung beantragen. Weitere Informationen finden Sie unter Beschränkter Zugriff auf die Sprechererkennung.
Sprecherüberprüfung
Die Sprecherüberprüfung optimiert den Prozess zum Verifizieren einer registrierten Sprecheridentität mithilfe von Passphrasen oder einer Spracheingabe in Freiform. Sie können sie beispielsweise zur Überprüfung der Kundenidentität in Callcentern oder für den kontaktlosen Zugang zu Gebäuden verwenden.
Wie funktioniert die Sprecherüberprüfung?
Im folgenden Flussdiagramm ist die Funktionsweise dargestellt:
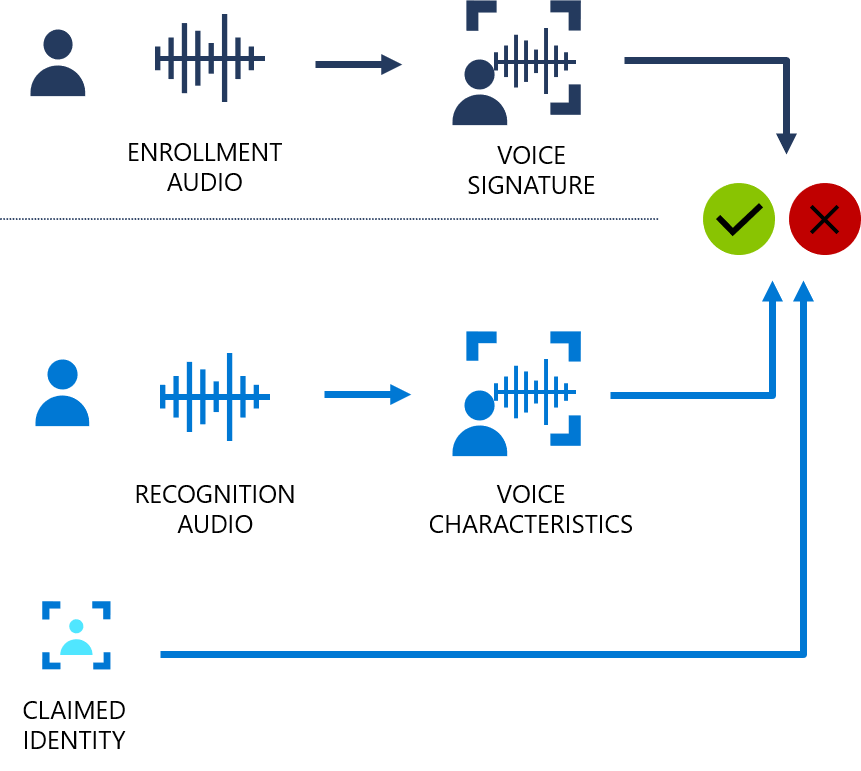
Die Sprecherüberprüfung kann entweder textabhängig oder textunabhängig sein. Bei der textabhängigen Überprüfung müssen die Sprecher sowohl bei der Registrierung als auch bei der Überprüfung dieselbe Passphrase verwenden. Bei der textunabhängigen Überprüfung können Sprecher sowohl bei der Registrierung als auch bei der Überprüfung eine beliebige Äußerung angeben.
Bei der textabhängigen Überprüfung wird die Stimme des Sprechers registriert, wenn er eine Passphrase aus vorgegebenen Phrasen spricht. Stimmmerkmale werden aus der Audioaufzeichnung extrahiert, um eine eindeutige Stimmsignatur zu bilden, und auch die Passphrase wird erkannt. Die Stimmsignatur und die Passphrase werden verwendet, um den Sprecher zu überprüfen.
Bei der textunabhängigen Verifizierung gibt es keine Einschränkungen für das, was der Sprecher während der Anmeldung sagt, abgesehen von der anfänglichen Aktivierungsphrase bei der Aktivierung der Anmeldung. Es gibt keine Beschränkungen für die zu überprüfenden Audioproben, weil nur Stimmmerkmale extrahiert werden, um die Ähnlichkeit zu bewerten.
Die APIs dienen nicht zum Bestimmen, ob die Audioprobe von einer echten Person oder einer Imitation oder Aufzeichnung eines registrierten Sprechers stammt.
Sprecheridentifikation
Die Sprecheridentifikation unterstützt Sie dabei, die Identität eines unbekannten Sprechers innerhalb einer Gruppe registrierter Sprecher zu ermitteln. Sie ermöglicht es Ihnen, Spracheingaben einzelnen Sprechern zuzuordnen und einen Mehrwert aus Szenarios mit mehreren Sprechern zu ziehen:
- Unterstützen von Lösungen für die Produktivität bei Remotemeetings
- Erstellen einer Personalisierung von Geräten mit mehreren Benutzern
Wie funktioniert die Sprecheridentifikation?
Die Registrierung für die Sprecheridentifikation ist textunabhängig. Abgesehen von dem ersten Aktivierungsbegriff beim Aktivieren der Registrierung gibt es keine Einschränkungen hinsichtlich der Aussage des Sprechers in der Audiodatei. Ähnlich wie bei der Sprecherüberprüfung wird die Stimme des Sprechers in der Registrierungsphase aufgezeichnet, und die Stimmmerkmale werden extrahiert, um eine eindeutige Stimmsignatur zu erstellen. In der Identifikationsphase wird das Spracheingabebeispiel mit einer bestimmten Liste registrierter Stimmen verglichen (bis zu 50 in jeder Anforderung).
Datensicherheit und -schutz
Sprecheranmeldungsdaten werden in einem gesicherten System gespeichert, einschließlich der Sprachaudioinformationen für die Registrierung und der Sprachsignaturmerkmale. Die Sprachaudiodaten für die Registrierung wird nur beim Upgrade des Algorithmus verwendet, und die Merkmale müssen noch einmal extrahiert werden. Der Dienst speichert weder die Sprachaufzeichnung noch die extrahierten Stimmmerkmale, die während der Erkennungsphase an den Dienst gesendet werden.
Sie steuern, wie lange Daten aufbewahrt werden sollen. Sie können über API-Aufrufe Registrierungsdaten für einzelne Sprecher erstellen, aktualisieren und entfernen. Beim Löschen des Abonnements werden auch alle mit dem Abonnement verbundenen Sprecherregistrierungsdaten gelöscht.
Wie bei allen Azure KI Services-Ressourcen müssen Entwickler, die das Feature zur Sprecher*innenerkennung nutzen, die Microsoft-Richtlinien zu Kundendaten beachten. Sie müssen sicherstellen, dass Sie von den Benutzer*innen die entsprechende Erlaubnis erhalten haben. Weitere Einzelheiten finden Sie unter Daten und Datenschutz für die Sprechererkennung. Weitere Informationen finden Sie im Microsoft Trust Center auf der Azure KI Services-Seite.
Häufige Fragen und Lösungen
| Frage | Lösung |
|---|---|
| In welchen Situationen wird die Sprechererkennung am häufigsten verwendet? | Zu den gängigen Beispielen gehören die Kundenüberprüfung in Callcentern, der sprachbasierte Check-In von Patienten, Besprechungstranskriptionen und die Personalisierung von Geräten mit mehreren Benutzern. |
| Was ist der Unterschied zwischen Identifikation und Überprüfung? | Identifikation ist der Prozess der Erkennung, welches Mitglied aus einer Gruppe von Sprechern spricht. Durch die Überprüfung wird bestätigt, dass ein Sprecher mit einer bekannten registrierten Stimme übereinstimmt. |
| Welche Sprachen werden unterstützt? | Informationen hierzu finden Sie unter Sprechererkennung. |
| Welche Azure-Regionen werden unterstützt? | Informationen hierzu finden Sie unter Sprechererkennung. |
| Welche Audioformate werden unterstützt? | Mono 16 Bit, 16 kHz PCM-codiertes WAV |
| Können Sie einen Sprecher mehrmals registrieren? | Ja, bei der textabhängigen Überprüfung können Sie einen Sprecher bis zu 50-mal registrieren. Bei der textunabhängigen Überprüfung oder der Sprecheridentifikation können Sie die Registrierung mit bis zu 300 Sekunden Audioeingabe durchführen. |
| Welche Daten werden in Azure gespeichert? | Registrierungsaudiodaten werden im Dienst gespeichert, bis das Stimmprofil gelöscht wird. Audioproben zur Erkennung werden nicht aufbewahrt oder gespeichert. |
Verantwortungsbewusste künstliche Intelligenz
Zu einem KI-System gehört nicht nur die Technologie, sondern auch die Personen, die das System verwenden, sowie die davon betroffenen Personen und die Umgebung, in der es bereitgestellt wird. Lesen Sie die Transparenzhinweise, um mehr über die verantwortungsvolle Nutzung und den Einsatz von KI in Ihren Systemen zu erfahren.
- Transparenzhinweis und Anwendungsfälle
- Merkmale und Einschränkungen
- Eingeschränkter Zugriff
- Allgemeine Richtlinien
- Daten, Datenschutz und Sicherheit