Verwenden eines partitionierten Graphen in Azure Cosmos DB
GILT FÜR: ![]() Gremlin
Gremlin
Eines der Hauptmerkmale der API für Gremlin in Azure Cosmos DB ist die Funktion, große Graphen mittels horizontaler Skalierung zu verarbeiten. Die Container können in Bezug auf Speicher und Durchsatz unabhängig skaliert werden. Sie können Container in Azure Cosmos DB erstellen, die automatisch so skaliert werden können, dass die Daten eines Graphen gespeichert werden. Die Daten werden basierend auf dem angegebenen Partitionsschlüssel automatisch abgeglichen.
Die Partitionierung erfolgt intern, wenn im Container voraussichtlich Daten mit einer Größe von über 20 GB gespeichert oder mehr als 10.000 Anforderungseinheiten (Request Units, RUs) pro Sekunde zugeteilt werden sollen. Daten werden automatisch auf Grundlage des von Ihnen angegebenen Partitionsschlüssels partitioniert. Der Partitionsschlüssel ist erforderlich, wenn Sie Graphcontainer mithilfe des Azure-Portals oder von Gremlin-Treibern ab Version 3.x erstellen. Der Partitionsschlüssel ist nicht erforderlich, wenn Sie Gremlin-Treiber bis Version 2.x verwenden.
Es gelten die gleichen allgemeinen Prinzipien wie für den Azure Cosmos DB-Partitionierungsmechanismus – abgesehen von einigen graphspezifischen Optimierungen, die weiter unten beschrieben sind.
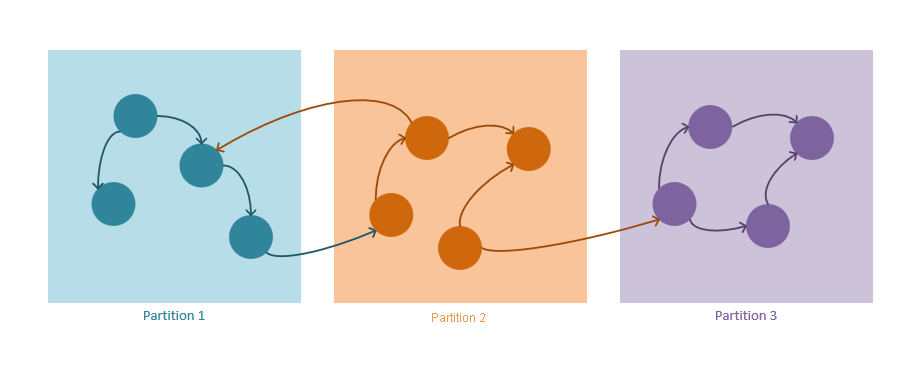
Graphpartitionierungsmechanismus
In den folgenden Richtlinien wird beschrieben, wie die Partitionierungsstrategie in Azure Cosmos DB funktioniert:
Knoten und Kanten werden als JSON-Dokumente gespeichert.
Knoten erfordern einen Partitionsschlüssel. Dieser Schlüssel bestimmt, in welcher Partition der Knoten mithilfe eines Hashalgorithmus gespeichert wird. Der Name der Eigenschaft „Partitionsschlüssel“ wird beim Erstellen eines neuen Containers definiert und hat folgendes Format:
/partitioning-key-name.Kanten werden mit ihren Quellknoten gespeichert. Das heißt, dass über den jeweiligen Partitionsschlüssel für jeden Knoten definiert wird, wo dieser zusammen mit den zugehörigen ausgehenden Kanten gespeichert wird. Diese Optimierung erfolgt, um bei der Verwendung der Kardinalität
out()in Graphenabfragen partitionsübergreifende Abfragen zu vermeiden.Kanten enthalten Verweise auf die Knoten, auf die sie zeigen. Alle Kanten werden mit den Partitionsschlüsseln und IDs der Knoten gespeichert, auf die sie zeigen. Diese Berechnung sorgt dafür, dass alle
out()-Verzeichnisabfragen immer zugeordnete partitionierte Abfragen und keine blinden partitionsübergreifenden Abfragen sind.Abfragen von Graphen müssen einen Partitionsschlüssel angeben. Um die Vorteile der horizontalen Partitionierung in Azure Cosmos DB voll auszunutzen, muss bei Auswahl eines einzelnen Knotens nach Möglichkeit der Partitionsschlüssel angegeben werden. Es folgen Abfragen zur Auswahl eines oder mehrerer Knoten in einem partitionierten Graphen:
/idund/labelwerden als Partitionsschlüssel für einen Container in der API für Gremlin nicht unterstützt.Auswählen eines Knotens anhand der ID und befolgen des Schritts
.has()zum Angeben der Partitionsschlüsseleigenschaft:g.V('vertex_id').has('partitionKey', 'partitionKey_value')Auswählen eines Knotens durch Angeben eines Tupels einschließlich Partitionsschlüssel und ID:
g.V(['partitionKey_value', 'vertex_id'])Auswählen einer Gruppe von Knoten mit deren IDs und Angeben einer Liste von Partitionsschlüsselwerten:
g.V('vertex_id0', 'vertex_id1', 'vertex_id2', …).has('partitionKey', within('partitionKey_value0', 'partitionKey_value01', 'partitionKey_value02', …)Verwenden der Partitionierungsstrategie zu Beginn einer Abfrage und Angeben einer Partition für den restlichem Umfang der Gremlin-Abfrage:
g.withStrategies(PartitionStrategy.build().partitionKey('partitionKey').readPartitions('partitionKey_value').create()).V()
Bewährte Methoden bei der Verwendung eines partitionierten Graphen
Befolgen Sie folgende Richtlinien, um die Leistung und Skalierbarkeit bei der Verwendung partitionierter Graphen in unbegrenzten Containern sicherzustellen:
Geben Sie bei der Abfrage eines Knotens immer den Partitionsschlüsselwert an. Das Abrufen eines Knotens aus einer bekannten Partition ist eine Möglichkeit zur Leistungssteigerung. Alle nachfolgenden Adjazenzvorgänge werden immer einer Partition zugeordnet, da Kanten Referenz-ID und Partitionsschlüssel für ihre Zielknoten enthalten.
Verwenden Sie beim Abfragen von Kanten nach Möglichkeit die Ausgangsrichtung. Wie bereits erwähnt, werden Kanten mit ihren Quellknoten in Ausgangsrichtung gespeichert. So wird die Wahrscheinlichkeit eines Rückgriffs auf partitionsübergreifende Abfragen minimiert, wenn die Daten und Abfragen unter Berücksichtigung dieses Musters entworfen werden. Im Gegensatz dazu ist die
in()-Abfrage immer eine teure Auffächerungsabfrage.Wählen Sie einen Partitionsschlüssel, der die Daten gleichmäßig auf die Partitionen verteilt. Diese Entscheidung hängt stark vom Datenmodell der Lösung ab. Weitere Informationen zum Erstellen eines geeigneten Partitionsschlüssels finden Sie unter Partitionierung und Skalierung in Azure Cosmos DB.
Optimieren Sie Abfragen, um Daten innerhalb der Grenzen einer Partition abzurufen. Eine optimale Partitionierungsstrategie ist auf die Abfragemuster abgestimmt. Abfragen, die Daten aus einer einzelnen Partition abrufen, bieten die bestmögliche Leistung.
Nächste Schritte
Sie können nun mit den folgenden Artikeln fortfahren:
- Erfahren Sie mehr über das Partitionieren und Skalieren in Azure Cosmos DB.
- Erfahren Sie mehr über die Gremlin-Unterstützung in der API für Gremlin.
- Weitere Informationen zur Einführung in die API für Gremlin.