Bewährte Methoden für das Skalieren des bereitgestellten Durchsatzes (RU/Sekunde)
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabelle
Tabelle
In diesem Artikel werden bewährte Methoden und Strategien für das Skalieren des Durchsatzes (RU/Sekunde) Ihrer Datenbank oder Ihres Containers (Sammlung, Tabelle oder Diagramm) beschrieben. Die Konzepte gelten, wenn Sie entweder die bereitgestellten manuellen Anforderungseinheiten (Request Units, RU) pro Sekunde oder die maximale Anzahl automatisch skalierter RU/Sekunde einer Ressource für eine der Azure Cosmos DB-APIs erhöhen.
Voraussetzungen
- Wenn Sie noch nicht mit dem Partitionieren und Skalieren in Azure Cosmos DB vertraut sind, empfiehlt es sich, zunächst den Artikel Partitionierung und horizontale Skalierung in Azure Cosmos DB zu lesen.
- Wenn Sie planen, Ihre RU/Sekunde aufgrund von Ausnahmen mit dem Fehlercode 429 zu skalieren, lesen Sie die Anleitung unter Diagnostizieren und Behandeln von Problemen im Zusammenhang mit der Azure Cosmos DB-Ausnahme „Zu hohe Anforderungsrate“ (429). Ermitteln Sie vor dem Erhöhen der RU/Sekunde die Grundursache des Problems und ob die Erhöhung der RU/Sekunde die richtige Lösung ist.
Hintergrundinformationen zum Skalieren von RU/Sekunde
Wenn Sie eine Anforderung zum Erhöhen der RU/Sekunde Ihrer Datenbank oder Ihres Containers senden, wird der Vorgang zum Hochskalieren abhängig von den angeforderten RU/Sekunde und dem aktuellen Layout der physischen Partitionen entweder sofort oder asynchron (in der Regel innerhalb von 4 bis 6 Stunden) abgeschlossen.
- Sofortige Hochskalierung
- Wenn die angeforderten RU/Sekunde vom aktuellen Layout der physischen Partitionen unterstützt werden können, muss Azure Cosmos DB weder Partitionen teilen noch neue Partitionen hinzufügen.
- Daher wird der Vorgang sofort abgeschlossen, und die RU/Sekunde stehen zur Verwendung zur Verfügung.
- Asynchrone Hochskalierung
- Wenn der Wert der angeforderten RU/Sekunde höher ist als der vom Layout der physischen Partitionen unterstützte Wert, teilt Azure Cosmos DB vorhandene physische Partitionen. Dies geschieht, bis die Ressource über die Mindestanzahl von Partitionen verfügt, die für die Unterstützung der angeforderten RU/Sekunde erforderlich sind.
- Daher kann die Ausführung des Vorgangs einige Zeit dauern, in der Regel 4 bis 6 Stunden. Jede physische Partition kann einen Durchsatz von maximal 10.000 RU/Sekunde (dies gilt für alle APIs) und eine Speichergröße von 50 GB unterstützen (dies gilt für alle APIs, mit Ausnahme von Cassandra mit 30 GB Speicher).
Hinweis
Wenn Sie einen manuellen Failovervorgang ausführen oder eine neue Region hinzufügen/entfernen, während eine asynchroner Hochskalierung ausgeführt wird, wird der Vorgang zum Hochskalieren des Durchsatzes angehalten. Er wird automatisch fortgesetzt, sobald der Failovervorgang oder das Hinzufügen/Entfernen der Region abgeschlossen ist.
- Sofortige Herunterskalierung
- Um einen Herunterskalierungsvorgang durchzuführen, muss Azure Cosmos DB keine Partitionen teilen oder neue hinzufügen.
- Daher wird der Vorgang sofort abgeschlossen, und die RU/Sekunde stehen zur Verwendung zur Verfügung.
- Das wichtigste Ergebnis dieses Vorgangs ist, dass RUs pro physischer Partition reduziert werden.
Hochskalieren von RU/Sekunde ohne Änderung des Partitionslayouts
Schritt 1: Ermitteln der aktuellen Anzahl physischer Partitionen
Navigieren Sie zu Erkenntnisse>Durchsatz>Normalisierter RU-Verbrauch (%) nach PartitionKeyRangeID. Zählen Sie die eindeutige Anzahl von PartitionKeyRangeIDs.
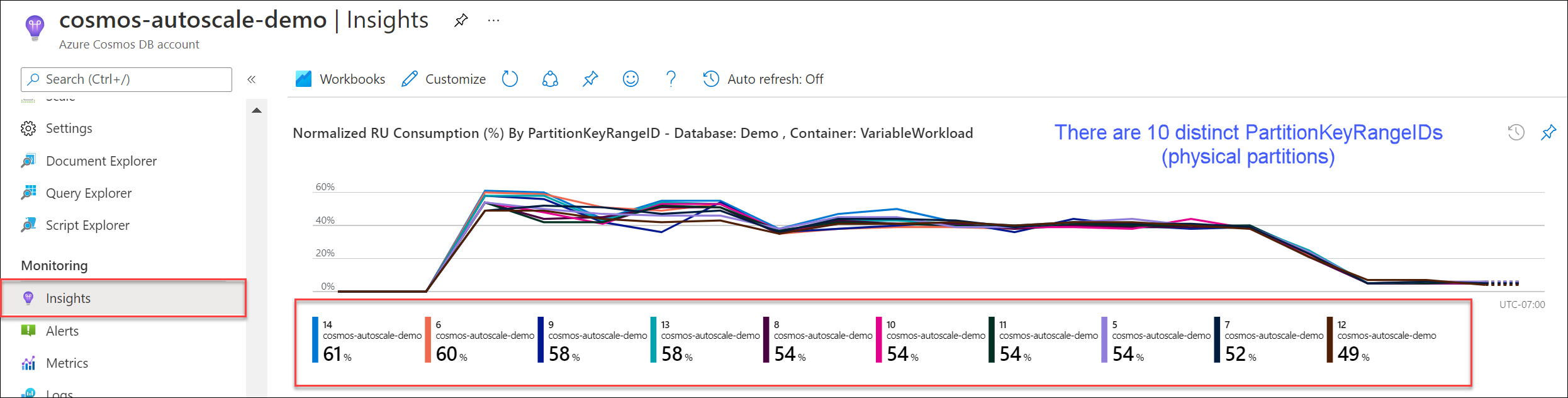
Hinweis
Im Diagramm werden nur maximal 50 PartitionKeyRangeIDs angezeigt. Wenn Ihre Ressource mehr als 50 umfasst, können Sie die Azure Cosmos DB-REST-API verwenden, um die Gesamtzahl der Partitionen zu zählen.
Jede PartitionKeyRangeID ist einer physischen Partition zugeordnet und wird zugewiesen, um Daten für einen Bereich möglicher Hashwerte zu speichern.
Azure Cosmos DB verteilt Ihre Daten basierend auf Ihrem Partitionsschlüssel auf logische und physische Partitionen, um die horizontale Skalierung zu ermöglichen. Wenn Daten geschrieben werden, verwendet Azure Cosmos DB den Hash des Partitionsschlüsselwerts, um zu ermitteln, auf welcher logischen und physischen Partition sich die Daten befinden.
Schritt 2: Berechnen des maximalen Standarddurchsatzes
Die höchste Anzahl von RU/Sekunde, auf die Sie skalieren können, ohne dass Azure Cosmos DB Partitionen teilen muss, ist gleich Current number of physical partitions * 10,000 RU/s. Sie können diesen Wert vom Azure Cosmos DB Ressourcenanbieter erhalten. Führen Sie eine GET-Anforderung für Ihre Datenbank- oder Container-Durchsatzeinstellungsobjekte durch und rufen Sie die Eigenschaft instantMaximumThroughput ab. Diesen Wert finden Sie auch auf der Seite „Skalierung und Einstellungen“ Ihrer Datenbank oder Ihres Containers im Portal.
Beispiel
Angenommen, wir verfügen über einen Container mit fünf physischen Partitionen und 30.000 RU/Sekunde von manuell bereitgestelltem Durchsatz. Wir können die RU/Sekunde sofort auf 5 * 10.000 RU/Sek. = 50.000 RU/Sek. erhöhen. Analog dazu könnten wir bei einem Container mit maximal 30.000 automatisch skalierten RU/Sekunde (Skalierung zwischen 3.000 und 30.000 RU/Sek.) sofort auf 50.000 RU/Sekunde (Skalierung zwischen 5.000 und 50.000 RU/Sek.) erhöhen.
Tipp
Wenn Sie RU/Sekunde hochskalieren, um auf Ausnahmen des Typs „Zu hohe Anforderungsrate“ (429) zu reagieren, wird empfohlen, zuerst die RU/Sekunde auf den höchsten vom aktuellen Layout der physischen Partitionen unterstützten Wert zu erhöhen und dann zu bewerten, ob die neue Anzahl von RU/Sekunde ausreicht, bevor Sie den Wert weiter erhöhen.
Sicherstellen einer gleichmäßigen Datenverteilung während der asynchronen Skalierung
Hintergrund
Wenn Sie für die RU/s einen höheren Wert als die aktuelle Anzahl physischer Partitionen * 10.000 RU/s angeben, teilt Azure Cosmos DB vorhandene Partitionen, bis die neue Anzahl von Partitionen ROUNDUP(requested RU/s / 10,000 RU/s) lautet. Bei einer Teilung werden übergeordnete Partitionen in zwei untergeordnete Partitionen aufgeteilt.
Angenommen, wir verfügen über einen Container mit drei physischen Partitionen und 30.000 RU/Sekunde von manuell bereitgestelltem Durchsatz. Wenn wir den Durchsatz auf 45.000 RU/Sekunde erhöhen, teilt Azure Cosmos DB zwei der vorhandenen physischen Partitionen so auf, dass sich insgesamt ROUNDUP(45,000 RU/s / 10,000 RU/s) = 5 physische Partitionen ergeben.
Hinweis
Von Anwendungen können während einer Teilung jederzeit Daten erfasst oder abgefragt werden. Die Azure Cosmos DB-Client-SDKs und der Dienst bedienen dieses Szenario automatisch und stellen sicher, dass Anforderungen an die richtige physische Partition weitergeleitet werden, sodass keine zusätzliche Benutzeraktion erforderlich ist.
Wenn Sie über eine Workload verfügen, die in Bezug auf Speicher- und Anforderungsvolumen sehr gleichmäßig verteilt ist (in der Regel durch Partitionierung durch Felder mit hoher Kardinalität wie /id), wird beim Hochskalieren empfohlen, die RU/Sekunde so festzulegen, dass alle Partitionen gleichmäßig aufgeteilt werden.
Zum besseren Verständnis verwenden wir ein Beispiel mit einem Container mit 2 physischen Partitionen, 20.000 RU/Sekunde und 80 GB Daten.
Dank der Auswahl eines guten Partitionsschlüssels mit hoher Kardinalität werden die Daten ungefähr gleichmäßig auf beide physischen Partitionen verteilt. Jeder physischen Partition werden ungefähr 50 % des Keyspace zugewiesen, der als Gesamtbereich der möglichen Hashwerte definiert ist.
Darüber hinaus verteilt Azure Cosmos DB die RU/Sekunde gleichmäßig auf alle physischen Partitionen. Daher umfasst jede physische Partition 10.000 RU/Sekunde und 50 % (40 GB) der gesamten Daten. Im folgenden Diagramm ist der aktuelle Zustand dargestellt.

Angenommen, wir möchten die Anzahl der RU/Sekunde von 20.000 RU/Sek. auf 30.000 RU/Sek. erhöhen.
Wenn wir die RU/Sekunde einfach nur auf 30.000 RU/Sekunde erhöhen, wird nur eine der Partitionen aufgeteilt. Nach der Aufteilung ergibt sich Folgendes:
- Eine Partition, die 50 % der Daten enthält (diese Partition wurde nicht aufgeteilt)
- Zwei Partitionen, die jeweils 25 % der Daten enthalten (dies sind die resultierenden untergeordneten Partitionen der übergeordneten Partition, die aufgeteilt wurde)
Da Azure Cosmos DB die RU/Sekunde gleichmäßig auf alle physischen Partitionen verteilt, werden jeder physischen Partition weiterhin 10.000 RU/Sekunde zugewiesen. Jetzt besteht jedoch eine Schieflage bei der Speicher- und Anforderungsverteilung.
Im folgenden Diagramm sehen wir, dass die Partitionen 3 und 4 (die untergeordneten Partitionen von Partition 2) jeweils über 10.000 RU/Sekunde verfügen, um Anforderungen für 20 GB Daten zu verarbeiten, während Partition 1 mit 10.000 RU/Sekunde Anforderungen für die doppelte Datenmenge (40 GB) verarbeiten muss.

Um eine gleichmäßige Speicherverteilung zu erhalten, können wir zuerst die RU/Sekunde hochskalieren, um sicherzustellen, dass jede Partition aufgeteilt wird. Anschließend können wir die RU/Sekunde wieder auf den gewünschten Zustand reduzieren.
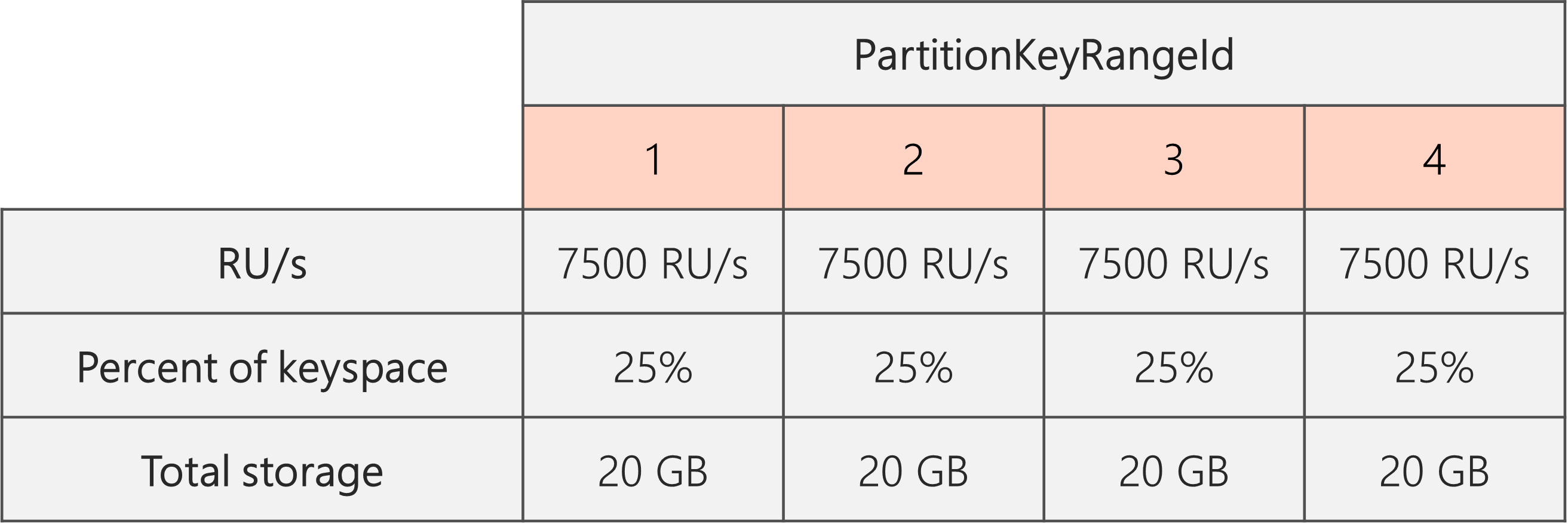
Wenn wir also mit zwei physischen Partitionen beginnen und eine gleichmäßige Partitionsaufteilung sicherstellen möchten, müssen wir die RU/Sekunde so festlegen, dass wir am Ende vier physische Partitionen erhalten. Um dies zu erreichen, legen wir zuerst RU/Sek. = 4 * 10.000 RU/Sek. pro Partition = 40.000 RU/Sek. fest. Nach Abschluss der Aufteilung können wir dann die RU/Sekunde auf 30.000 RU/Sek. reduzieren.
Wie im folgenden Diagramm zu sehen ist, erhält also jede physische Partition 30.000 RU/Sek. / 4 = 7.500 RU/Sekunde, um Anforderungen für 20 GB Daten zu verarbeiten. Insgesamt ergibt sich eine gleichmäßige Verteilung von Speicher und Anforderungen auf alle Partitionen.
Allgemeine Formel
Schritt 1: Erhöhen der RU/Sekunde, um sicherzustellen, dass alle Partitionen gleichmäßig aufgeteilt werden
Wenn Sie bei einer Anfangsanzahl der physischen Partitionen von P eine gewünschte Anzahl von RU/Sekunde S festlegen möchten, gilt im Allgemeinen Folgendes:
Erhöhen Sie die RU/Sekunde wie folgt: 10,000 * P * (2 ^ (ROUNDUP(LOG_2 (S/(10,000 * P)))). Dies ergibt den Wert von RU/Sekunde, der dem gewünschten Wert am nächsten kommt und sicherstellt, dass alle Partitionen gleichmäßig aufgeteilt werden.
Hinweis
Wenn Sie die RU/Sekunde einer Datenbank oder eines Containers erhöhen, kann sich dies auf die Mindestanzahl von RU/Sekunde auswirken, auf die Sie in Zukunft reduzieren können. Der Mindestwert von RU/Sekunde entspricht in der Regel MAX(400 RU/Sekunde, aktueller Speicher in GB * 1 RU/Sekunde, höchste Anzahl jemals bereitgestellter RU/Sek. / 100). Wenn beispielsweise die höchste Anzahl von RU/Sekunde, auf die Sie jemals skaliert haben, 100.000 RU/Sek. beträgt, beläuft sich die Mindestanzahl von RU/Sekunde, die Sie in Zukunft festlegen können, auf 1.000 RU/Sekunde. Weitere Informationen hierzu finden Sie unter Mindestdurchsatzwerte.
Schritt 2: Reduzieren der RU/Sekunde auf die gewünschte Anzahl
Angenommen, wir verfügen über fünf physische Partitionen mit 50.000 RU/Sek. und möchten auf 150.000 RU/Sek. skalieren. Wir sollten zuerst 10,000 * 5 * (2 ^ (ROUND(LOG_2(150,000/(10,000 * 5)))) = 200.000 RU/Sek. festlegen und dann die Anzahl auf 150.000 RU/Sek. reduzieren.
Wenn wir auf bis zu 200.000 RU/Sek. hochskaliert haben, beträgt die Mindestanzahl manueller RU/Sekunde, die wir in Zukunft festlegen können, 2.000 RU/Sekunde. Der kleinste mögliche Wert für die Autoskalierung für die maximale Anzahl von RU/Sekunde, den wir festlegen können, lautet 20.000 RU/Sek. (Skalierung zwischen 2.000 und 20.000 RU/Sekunde). Da unser Zielwert 150.000 RU/Sek. lautet, spielt der Mindestwert der RU/Sek. in unserem Szenario keine Rolle.
Optimieren der Anzahl von RU/Sekunde für die Erfassung großer Datenmengen
Wenn Sie planen, eine große Datenmenge in Azure Cosmos DB zu migrieren oder zu erfassen, empfiehlt es sich, die RU/Sek. des Containers so festzulegen, dass Azure Cosmos DB die physischen Partitionen vorab bereitstellt, die zum Speichern der Gesamtmenge der Daten erforderlich sind, die Sie im Voraus erfassen möchten. Andernfalls muss Azure Cosmos DB möglicherweise während der Erfassung Partitionen aufteilen, wodurch die Datenerfassung mehr Zeit in Anspruch nimmt.
Wir können die Tatsache nutzen, dass Azure Cosmos DB während der Containererstellung die heuristische Formel für die Anfangsanzahl von RU/Sek. verwendet, um die Anfangsanzahl der physischen Partitionen zu berechnen.
Schritt 1: Überprüfen der Auswahl des Partitionsschlüssels
Befolgen Sie die bewährten Methoden zum Auswählen eines Partitionsschlüssels, um nach der Migration eine gleichmäßige Verteilung von Anforderungsvolumen und Speicher sicherzustellen.
Schritt 2: Berechnen der Anzahl der benötigten physischen Partitionen
Number of physical partitions = Total data size in GB / Target data per physical partition in GB
Jede physische Partition kann maximal 50 GB Speicher (30 GB für die API für Cassandra) umfassen. Der Wert, den Sie für die Target data per physical partition in GB auswählen sollten, hängt davon ab, wie vollgepackt die physischen Partitionen sein sollen und welches Speicherwachstum Sie nach der Migration erwarten.
Wenn Sie beispielsweise davon ausgehen, dass der Speicher weiter wächst, können Sie den Wert auf 30 GB festlegen. Davon ausgehend, dass Sie einen guten Partitionsschlüssel ausgewählt haben, der den Speicher gleichmäßig verteilt, ist jede Partition zu ca. 60 % belegt (30 GB von 50 GB). Wenn zukünftige Daten geschrieben werden, können sie auf den vorhandenen physischen Partitionen gespeichert werden, ohne dass der Dienst sofort weitere physische Partitionen hinzufügen muss.
Wenn Sie hingegen davon ausgehen, dass der Speicher nach der Migration nicht wesentlich anwächst, können Sie einen höheren Wert (z. B. 45 GB) festlegen. Das bedeutet, dass jede Partition zu ca. 90 % belegt ist (45 GB von 50 GB). Dadurch wird die Anzahl der physischen Partitionen minimiert, auf die Ihre Daten verteilt sind, was bedeutet, dass jede physische Partition einen größeren Anteil der insgesamt bereitgestellten RU/Sekunde erhalten kann.
Schritt 3: Berechnen der Anfangsanzahl von RU/Sekunde für alle Partitionen
Starting RU/s for all partitions = Number of physical partitions * Initial throughput per physical partition.
Beginnen wir mit einem Beispiel mit einer beliebigen Anzahl von Ziel-RU/Sek. pro physischer Partition.
Initial throughput per physical partition= 10.000 RU/Sek. pro physischer Partition bei Verwendung von Datenbanken mit automatisch skaliertem oder gemeinsam genutztem DurchsatzInitial throughput per physical partition= 6000 RU/Sek. pro physischer Partition bei Verwendung von manuellem Durchsatz
Beispiel
Angenommen, wir möchten 1 TB (1.000 GB) Daten erfassen und den manuellen Durchsatz verwenden. Jede physische Partition in Azure Cosmos DB verfügt über eine Kapazität von 50 GB. Angenommen, die Partitionen dürfen zu 80 % belegt werden (40 GB umfassen), sodass wir Platz für zukünftiges Wachstum haben.
Das bedeutet, dass wir für 1 TB Daten 1.000 GB / 40 GB = 25 physische Partitionen benötigen. Um sicherzustellen, dass wir 25 physische Partitionen erhalten, müssen wir bei Verwendung des manuellen Durchsatzes zuerst 25 * 6.000 RU/Sek. = 150.000 RU/Sek. bereitstellen. Nachdem der Container erstellt wurde, erhöhen wir zur Beschleunigung der Erfassung die Anzahl der RU/Sek. auf 250.000 RU/Sekunde, bevor die Erfassung beginnt (erfolgt sofort, weil wir bereits über 25 physische Partitionen verfügen). Dadurch kann jede Partition die maximale Anzahl von 10.000 RU/Sek. erhalten.
Bei Verwendung einer Datenbank mit automatisch skaliertem oder gemeinsam genutztem Durchsatz müssten wir zuerst 25 * 10.000 RU/Sek. = 250.000 RU/Sek. bereitstellen, um 25 physische Partitionen zu erhalten. Da wir bereits die höchste Anzahl von RU/Sek. erreicht haben, die mit 25 physischen Partitionen unterstützt werden kann, würden wir die Anzahl der bereitgestellten RU/Sek. vor der Erfassung nicht weiter erhöhen.
Theoretisch kann bei 250.000 RU/Sek. und 1 TB Daten, wenn wir von 1-KB-Dokumenten und 10 RU für den Schreibvorgang ausgehen, die Erfassung in der folgenden Zeit abgeschlossen werden: 1.000 GB * (1.000.000 KB / 1 GB) * (1 Dokument / 1 KB) * (10 RU / Dokument) * (1 Sekunde / 250.000 RU) * (1 Stunde / 3.600 Sekunden) = 11,1 Stunden.
Bei dieser Berechnung handelt es sich um eine Schätzung, bei der davon ausgegangen wird, dass der Client, der die Erfassung durchführt, den Durchsatz vollständig auslasten und Schreibvorgänge auf alle physischen Partitionen verteilen kann. Als bewährte Methode wird empfohlen, Ihre Daten clientseitig zu „mischen“. Dadurch wird sichergestellt, dass der Client jede Sekunde in viele verschiedene logische (und somit physische) Partitionen schreibt.
Sobald die Migration abgeschlossen ist, können wir bei Bedarf die RU/Sek. reduzieren oder die Autoskalierung aktivieren.
Nächste Schritte
- Überwachen Sie den normalisierten RU/s-Verbrauch Ihrer Datenbank oder Ihres Containers.
- Diagnostizieren und behandeln Sie Probleme im Zusammenhang mit Ausnahmen des Typs „Zu hohe Anforderungsrate“ (429).
- Aktivieren Sie die Autoskalierung für eine Datenbank oder einen Container.