Azure DevOps-Aufgabe für Azure Data Explorer
Azure DevOps Services bietet Tools für die Entwicklungszusammenarbeit wie leistungsstarke Pipelines, kostenlose private Git-Repositorys, konfigurierbare Kanban-Boards und umfangreiche automatisierte und kontinuierliche Testfunktionen. Azure Pipelines ist eine Azure DevOps-Funktion, die es Ihnen ermöglicht, CI/CD zu verwalten, um Ihren Code mit leistungsstarken Pipelines bereitzustellen, die mit jeder Sprache, Plattform und Cloud funktionieren. Azure Data Explorer – Pipeline Tools ist die Azure Pipelines-Aufgabe, mit der Sie Releasepipelines erstellen und Ihre Datenbankänderungen in Ihren Azure Data Explorer-Datenbanken bereitstellen können. Diese finden Sie kostenlos im Visual Studio Marketplace. Diese Erweiterung umfasst drei grundlegende Aufgaben:
Azure Data Explorer-Befehl: Ausführen von Administratorbefehlen für einen Azure Data Explorer-Cluster
Azure Data Explorer-Abfrage: Ausführen von Abfragen für einen Azure Data Explorer-Cluster und Analysieren der Ergebnisse
Azure Data Explorer-Abfrageservergate: Aufgabe ohne Agent zur Einrichtung eines Gates für Releases je nach Abfrageergebnis
In diesem Dokument wird ein einfaches Beispiel für die Verwendung der Aufgabe Azure Data Explorer – Pipeline Tools zum Bereitstellen Ihrer Schemaänderungen in Ihrer Datenbank beschrieben. Vollständige CI/CD-Pipelines finden Sie unter Azure DevOps-Dokumentation.
Voraussetzungen
- Ein Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto.
- Ein Azure Data Explorer-Cluster und eine Datenbank Erstellen eines Clusters und einer Datenbank
- Azure Data Explorer Clustereinrichtung:
- Erstellen Sie Microsoft Entra App, indem Sie eine Microsoft Entra-Anwendung bereitstellen.
- Gewähren Sie Ihrer Microsoft Entra-App zugriff auf Ihre Azure Data Explorer-Datenbank, indem Sie Azure Data Explorer-Datenbankberechtigungen verwalten.
- Azure DevOps-Setup:
- Erweiterungsinstallation:
- Wenn Sie der Besitzer der Azure DevOps-Instanz sind, sollten Sie die Erweiterung über den Marketplace installieren.

- Wenn Sie NICHT der Besitzer der Azure DevOps-Instanz sind, sollten Sie den Besitzer bitten, diese zu installieren.
- Wenn Sie der Besitzer der Azure DevOps-Instanz sind, sollten Sie die Erweiterung über den Marketplace installieren.
Vorbereiten Ihrer Inhalte für das Release
Es gibt drei Möglichkeiten zum Ausführen von Administratorbefehlen für den Cluster in einer Aufgabe.

Verwenden eines Suchmusters zum Abrufen von mehreren Befehlsdateien aus einem lokalen Agent-Ordner (Buildquellen oder Releaseartefakte)

Inline-Schreiben von Befehlen
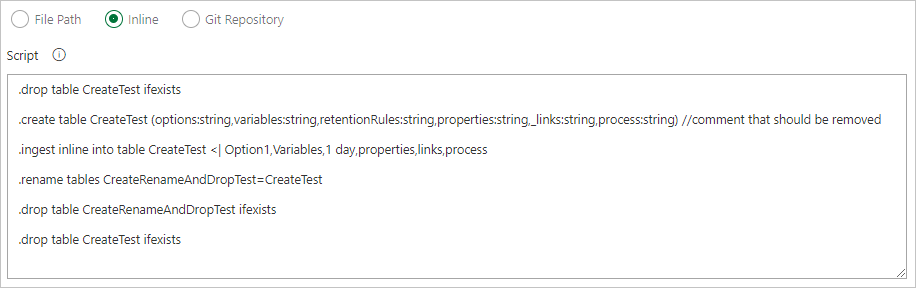
Angeben eines Dateipfads, um Befehlsdateien direkt aus der Git-Quellcodeverwaltung abzurufen (empfohlen)
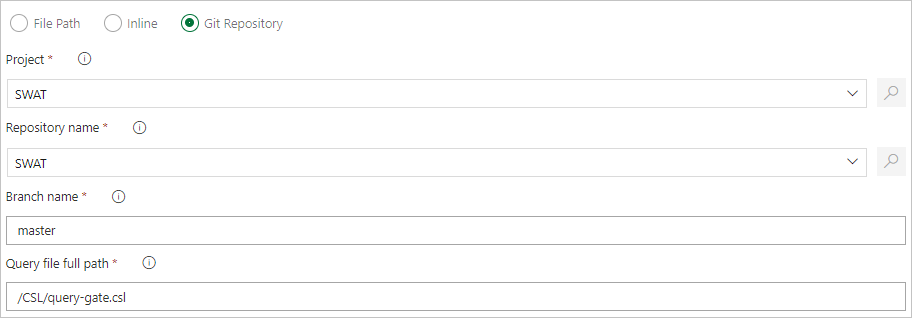
Erstellen Sie die folgenden Beispielordner (Funktionen, Richtlinien, Tabellen) in Ihrem Git-Repository. Kopieren Sie die Dateien von hier in die entsprechenden Ordner wie unten gezeigt, und übertragen Sie die Änderungen. Die Beispieldateien werden zur Verfügung gestellt, um den folgenden Workflow auszuführen.
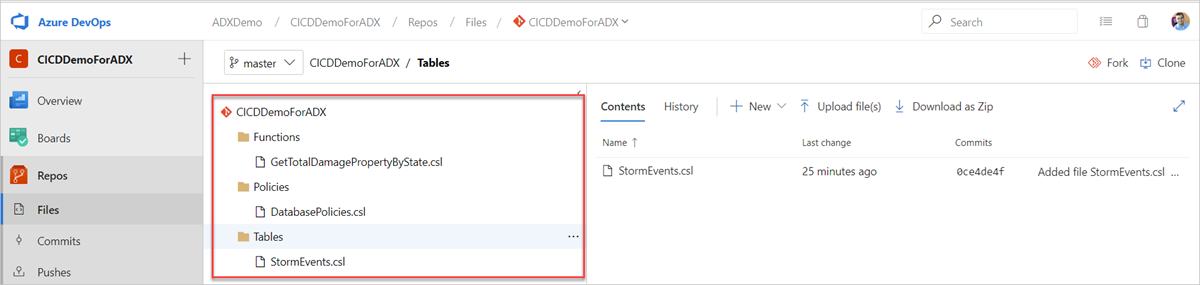
Tipp
Bei der Erstellung eines eigenen Workflows empfehlen wir, den Code idempotent zu gestalten. Verwenden Sie beispielsweise
.create-merge tableanstelle von.create tableund die Funktion.create-or-alteranstelle der Funktion.create.
Erstellen einer Releasepipeline
Melden Sie sich bei Ihrer Azure DevOps-Organisation an.
Wählen Sie Pipelines>Releases aus, und wählen im linken Menü Neue Pipeline.
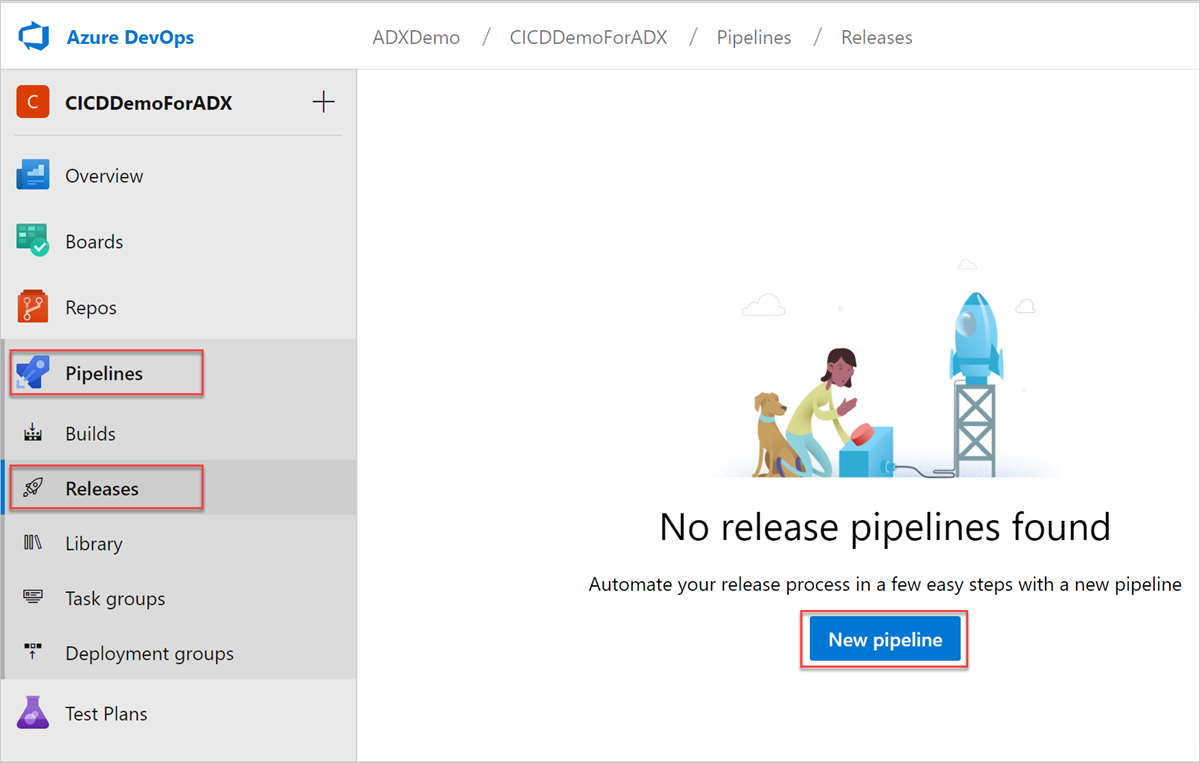
Das Fenster Neue Releasepipeline wird geöffnet. Wählen Sie auf der Registerkarte Pipelines im Bereich Eine Vorlage auswählen die Option Leerer Auftrag aus.
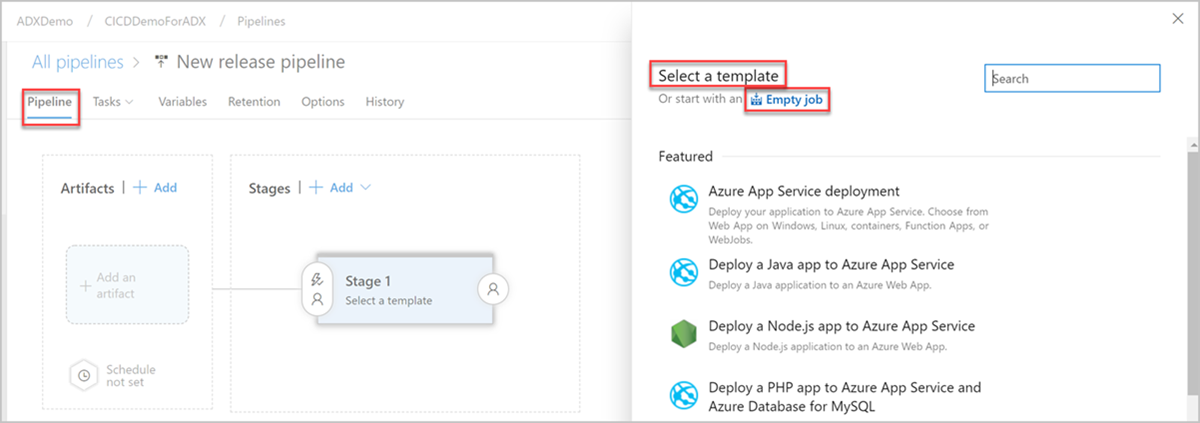
Klicken Sie auf die Schaltfläche Stufe. Fügen Sie im Bereich Stufe den Namen der Stufe hinzu. Klicken Sie auf Speichern, um Ihre Pipeline zu speichern.
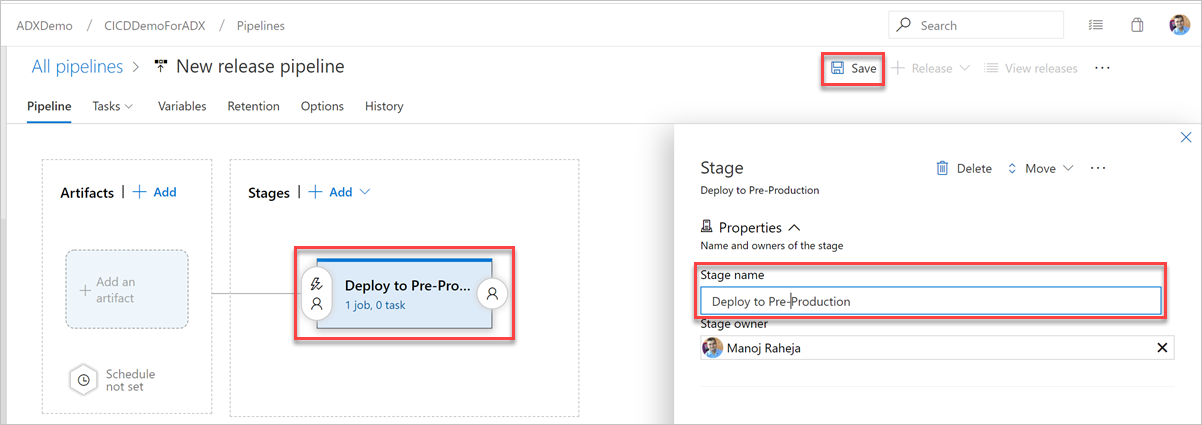
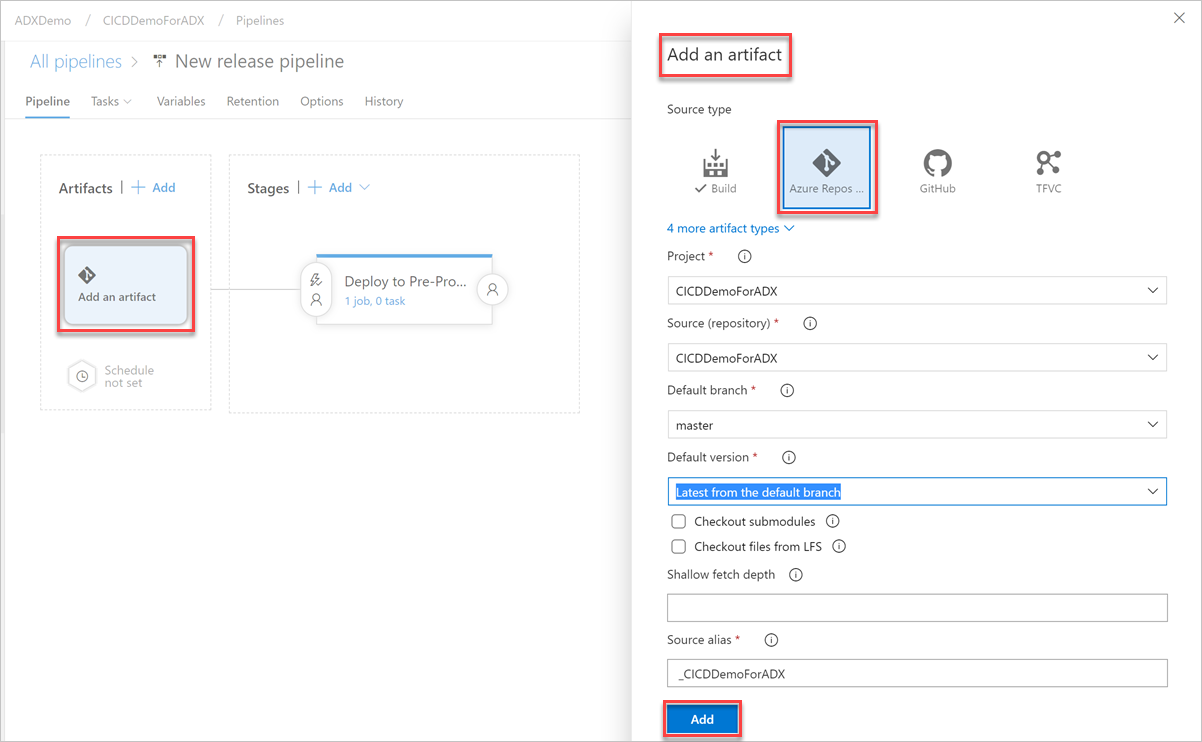
Klicken Sie auf die Schaltfläche Artefakt hinzufügen. Wählen Sie im Bereich Artefakt hinzufügen das Repository aus, in dem sich Ihr Code befindet, geben Sie die relevanten Informationen ein, und klicken Sie auf Hinzufügen. Klicken Sie auf Speichern, um Ihre Pipeline zu speichern.
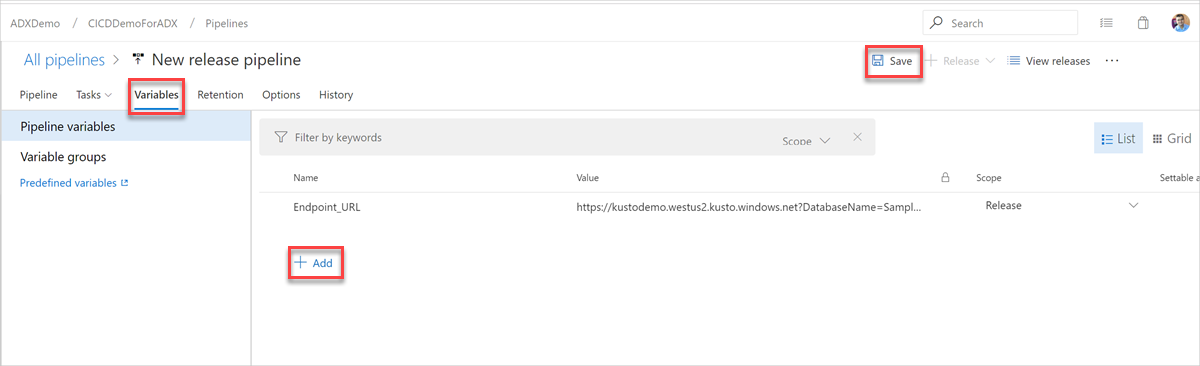
Wählen Sie auf der Registerkarte Variablen+ Hinzufügen, um eine Variable für Endpunkt-URL zu erstellen, die in der Aufgabe verwendet wird. Geben Sie den Namen und den Wert des Endpunkts ein. Klicken Sie auf Speichern, um Ihre Pipeline zu speichern.
Um Ihre Endpoint_URL zu finden, enthält die Übersichtsseite Ihres Azure Data Explorer-Cluster im Azure-Portal die URI des Azure Data Explorer-Cluster. Erstellen Sie den URI im folgenden Format
https://<Azure Data Explorer cluster URI>?DatabaseName=<DBName>. Zum Beispiel, https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB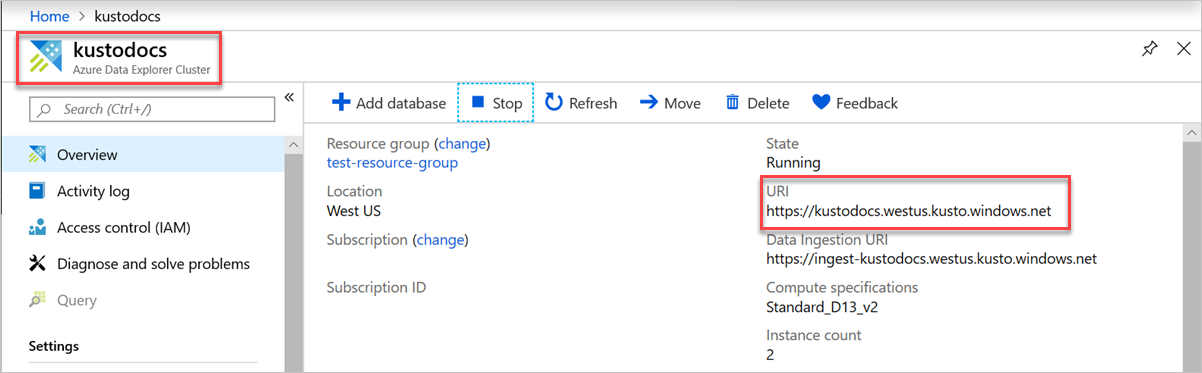
Erstellen von Aufgaben zum Bereitstellen der Ordner
Klicken Sie auf der Registerkarte Pipeline auf 1 Auftrag, 0 Aufgabe, um Aufgaben hinzuzufügen.
Wiederholen Sie die folgenden Schritte, um Befehlsaufgaben zum Bereitstellen von Dateien aus den Ordnern für Tabellen, Funktionen und Richtlinien zu erstellen:
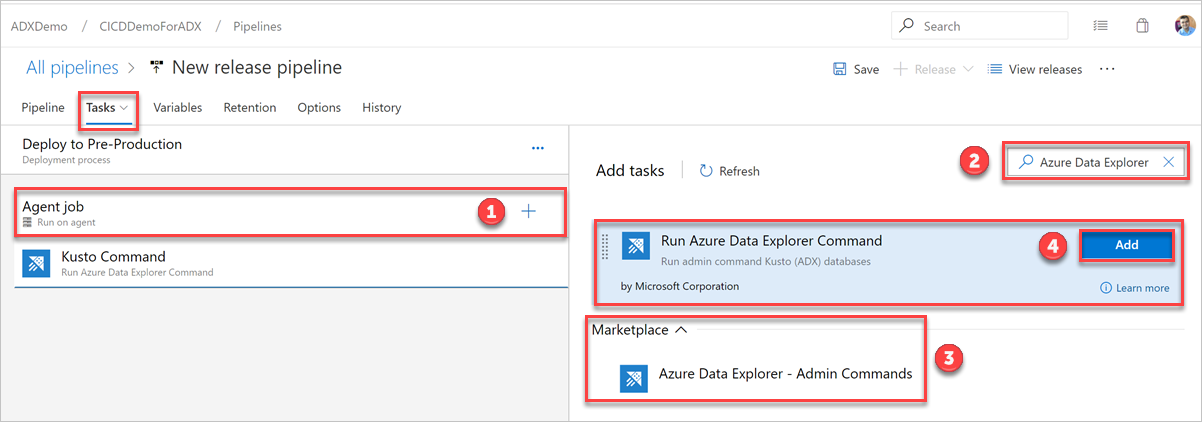
Wählen Sie auf der Registerkarte Aufgaben das Pluszeichen ( + ) für Agentauftrag aus, und suchen Sie nach Azure Data Explorer.
Wählen Sie unter Azure Data Explorer-Befehl ausführen die Option Hinzufügen aus.
Wählen Sie Kusto-Befehl aus, und aktualisieren Sie die Aufgabe mit den folgenden Informationen:
Anzeigename: Der Name der Aufgabe. Ein Beispiel hierfür ist
Deploy <FOLDER>, wobei<FOLDER>der Name des Ordners für die von Ihnen erstellte Bereitstellungsaufgabe ist.Dateipfad: Geben Sie für jeden Ordner den Pfad in der Form
*/<FOLDER>/*.cslan, wobei<FOLDER>der relevante Ordner für die Aufgabe ist.Endpunkt-URL: Geben Sie die im vorherigen Schritt erstellte Variable
EndPoint URLan.Dienstendpunkt verwenden: Wählen Sie diese Option aus.
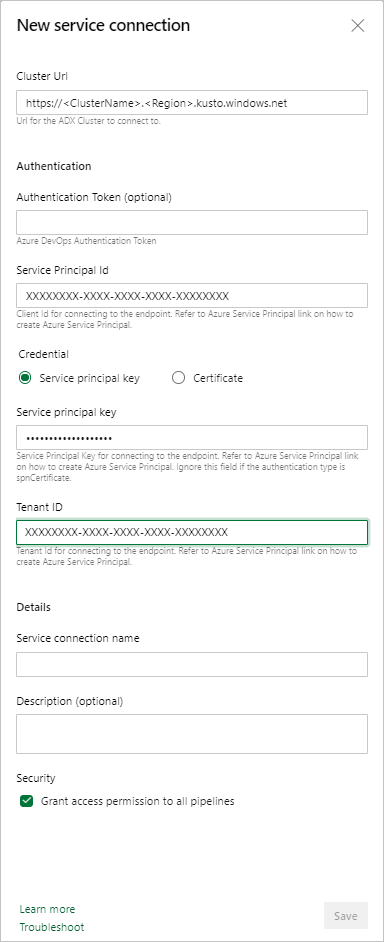
Dienstendpunkt: Wählen Sie einen vorhandenen Dienstendpunkt aus, oder erstellen Sie einen neuen ( + Neu), indem Sie im Fenster Azure Data Explorer-Dienstverbindung hinzufügen die folgenden Informationen angeben:
Einstellung Vorgeschlagener Wert Verbindungsname Geben Sie den Namen zum Identifizieren dieses Dienstendpunkts ein. Cluster-URL Den Wert finden Sie im Übersichtsbereich Ihres Azure Data Explorer-Clusters im Azure-Portal. Dienstprinzipal-ID Geben Sie die Microsoft Entra-App-ID ein (als Voraussetzung erstellt) Dienstprinzipal-App-Schlüssel Geben Sie den Microsoft Entra App Key (als Voraussetzung erstellt) ein. Microsoft Entra Mandanten-ID Geben Sie Ihren Microsoft Entra Mandanten ein (z. B. microsoft.com oder contoso.com).
Aktivieren Sie das Kontrollkästchen Nutzung dieser Verbindung für alle Pipelines erlauben, und wählen Sie anschließend OK aus.
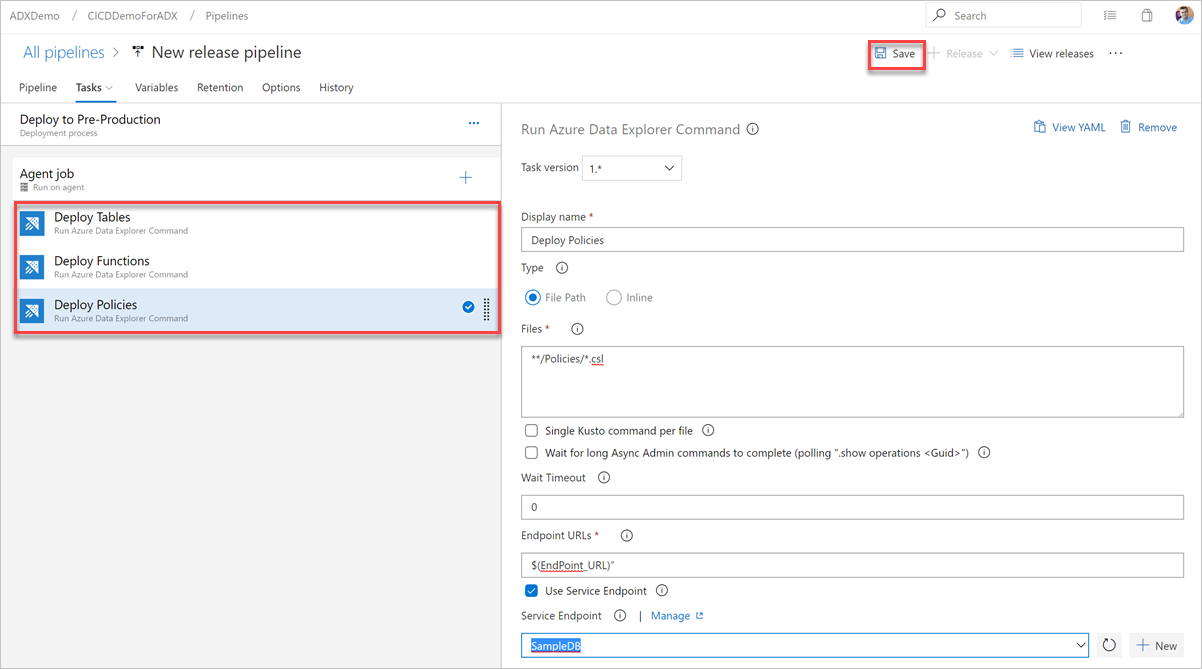
Wählen Sie Speichern aus, und überprüfen Sie auf der Registerkarte Aufgaben, ob drei Aufgaben vorhanden sind: Deploy Tables (Tabellen bereitstellen), Deploy Functions (Funktionen bereitstellen) und Deploy Policies (Richtlinien bereitstellen).
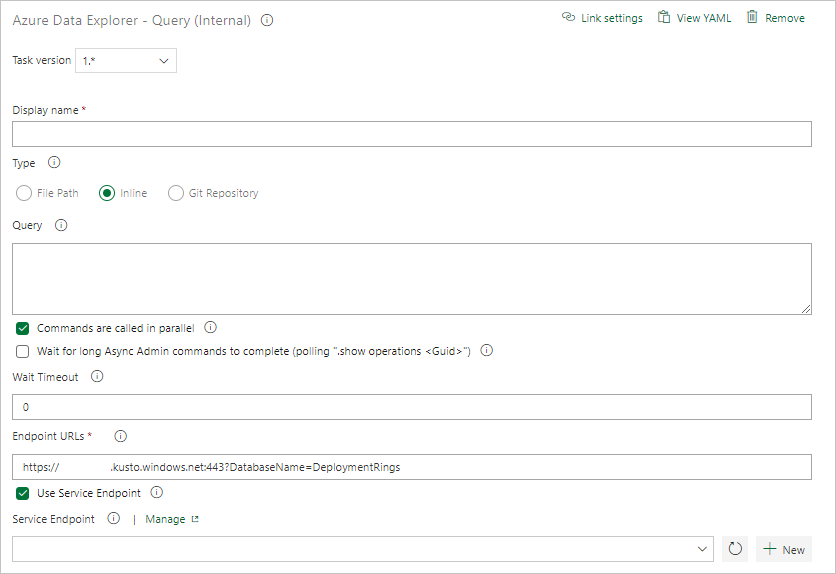
Erstellen einer Abfrageaufgabe
Erstellen Sie bei Bedarf eine Aufgabe, um für den Cluster eine Abfrage auszuführen. Das Ausführen von Abfragen in einer Build- oder Releasepipeline kann verwendet werden, um ein Dataset zu überprüfen und basierend auf den Abfrageergebnissen einen Schritt erfolgreich auszuführen oder einen Fehler zu erzielen. Die Erfolgskriterien für Aufgaben können auf einem Schwellenwert für die Zeilenanzahl oder einem einzelnen Wert basieren. Dies hängt davon ab, was von der Abfrage zurückgegeben wird.
Wählen Sie auf der Registerkarte Aufgaben das Pluszeichen ( + ) für Agentauftrag aus, und suchen Sie nach Azure Data Explorer.
Wählen Sie unter Azure Data Explorer-Abfrage ausführen die Option Hinzufügen aus.
Wählen Sie Kusto-Abfrage aus, und aktualisieren Sie die Aufgabe mit den folgenden Informationen:
- Anzeigename: Der Name der Aufgabe. Beispiel: Abfragecluster.
- Typ: Wählen Sie Inline aus.
- Abfrage: Geben Sie die Abfrage ein, die Sie ausführen möchten.
- Endpunkt-URL: Geben Sie die zuvor erstellte Variable
EndPoint URLan. - Dienstendpunkt verwenden: Wählen Sie diese Option aus.
- Dienstendpunkt: Wählen Sie einen Dienstendpunkt aus.
Wählen Sie unter „Aufgabenergebnisse“ die Erfolgskriterien der Aufgabe je nach den Ergebnissen Ihrer Abfrage wie folgt aus:
Wenn von Ihrer Abfrage Zeilen zurückgegeben werden, wählen Sie die Option Zeilenanzahl aus und geben die erforderlichen Kriterien an.
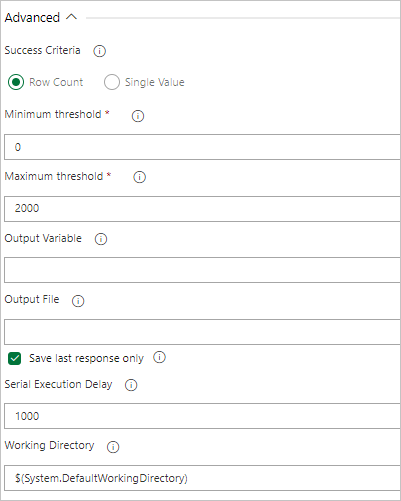
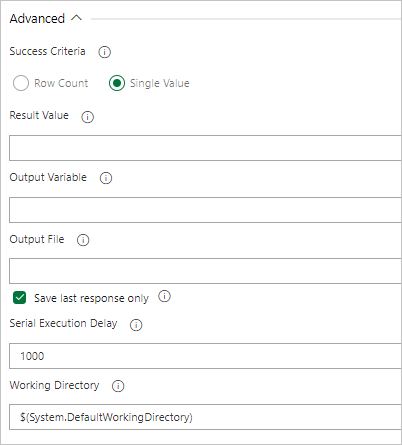
Wenn von Ihrer Abfrage ein Wert zurückgegeben wird, wählen Sie Einzelwert aus und geben das erwartete Ergebnis an.
Erstellen einer Aufgabe für ein Abfrageservergate
Erstellen Sie bei Bedarf eine Aufgabe zum Ausführen einer Abfrage für einen Cluster, und richten Sie ein Gate für den Releaseprozess in Abhängigkeit der Zeilenanzahl in den Abfrageergebnissen ein. Die Aufgabe für ein Abfrageservergate ist ein Auftrag ohne Agent. Dies bedeutet, dass die Abfrage direkt in Azure DevOps Server ausgeführt wird.
Wählen Sie auf der Registerkarte Aufgaben das Pluszeichen ( + ) für Auftrag ohne Agent aus, und suchen Sie nach Azure Data Explorer.
Wählen Sie unter Run Azure Data Explorer Query Server Gate (Azure Data Explorer-Abfrageservergate ausführen) die Option Hinzufügen aus.
Wählen Sie die Option Kusto Query Server Gate (Kusto-Abfrageservergate) und dann Server Gate Test (Servergatetest) aus.
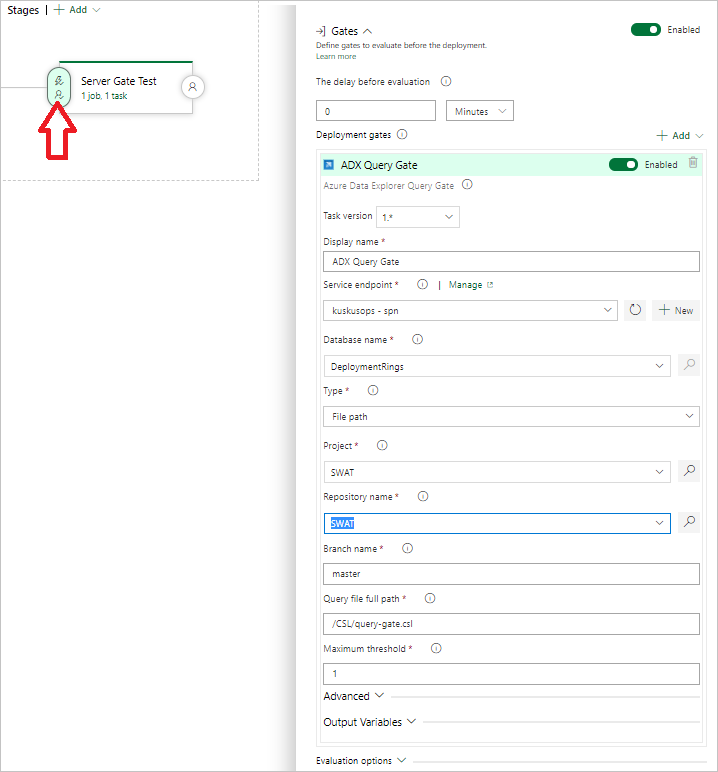
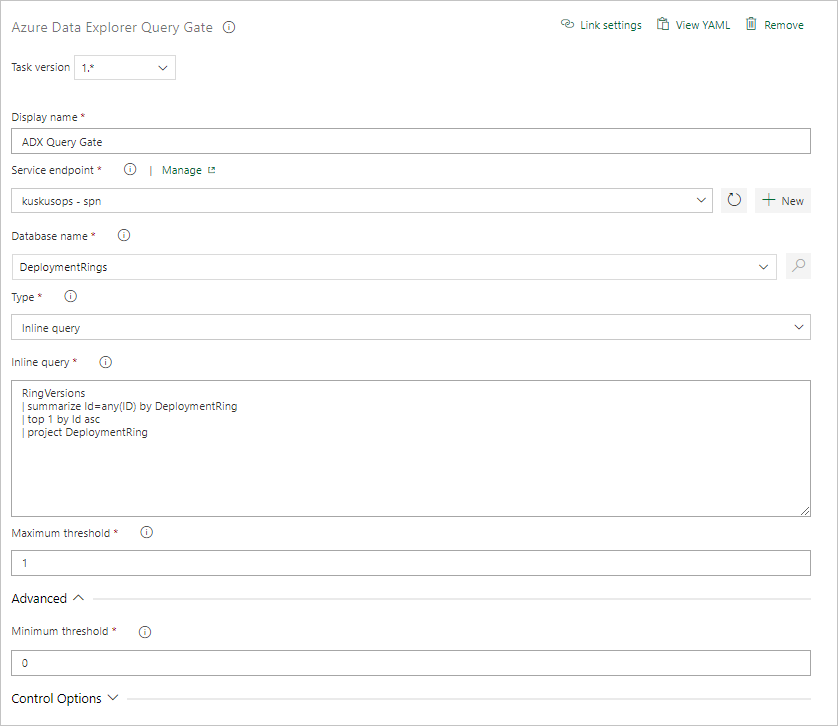
Konfigurieren Sie die Aufgabe, indem Sie die folgenden Informationen angeben:
- Anzeigename: Der Name des Gates.
- Dienstendpunkt: Wählen Sie einen Dienstendpunkt aus.
- Datenbankname: Geben Sie den Namen der Datenbank an.
- Typ: Wählen Sie Inline query (Inline-Abfrage) aus.
- Abfrage: Geben Sie die Abfrage ein, die Sie ausführen möchten.
- Maximum threshold (Maximaler Schwellenwert): Geben Sie die maximale Zeilenanzahl für die Erfolgskriterien der Abfrage an.
Hinweis
Beim Ausführen des Release sollten Ergebnisse der folgenden Art angezeigt werden.
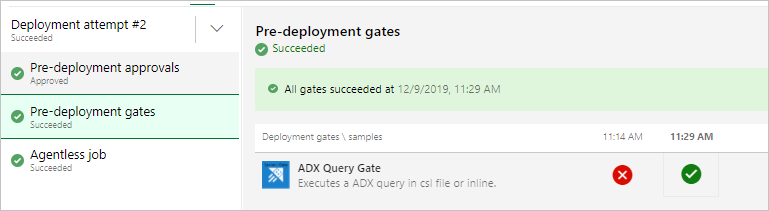
Ausführen des Release
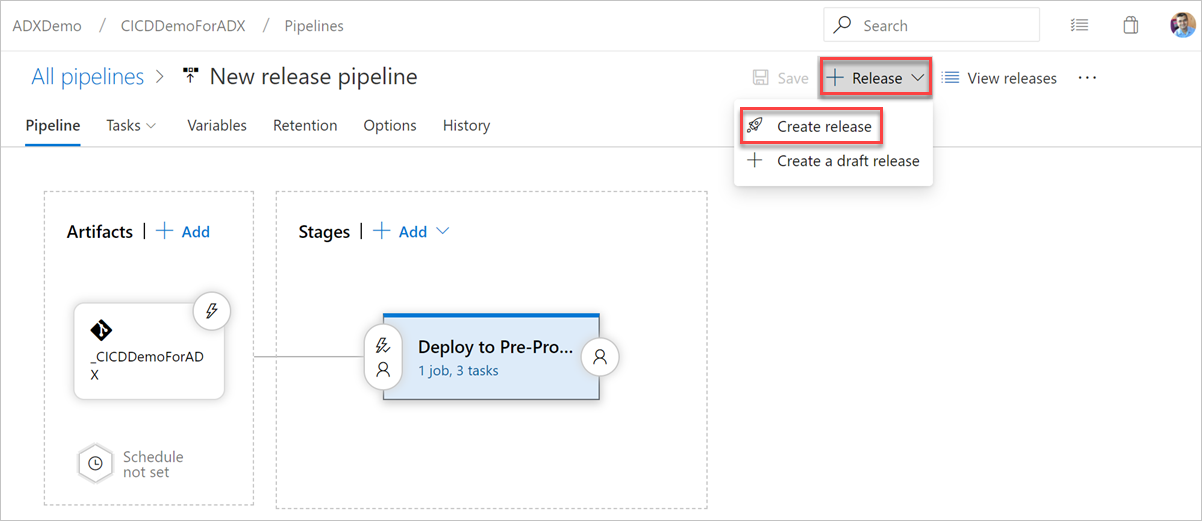
Wählen Sie + Release>Release erstellen, um ein Release zu erstellen.
Überprüfen Sie auf der Registerkarte Protokolle, ob die Bereitstellung erfolgreich war.

Sie haben nun die Erstellung einer Releasepipeline für die Bereitstellung in der Präproduktion abgeschlossen.
Konfiguration der YAML-Pipeline
Die Aufgaben können sowohl über die Azure DevOps-Weboberfläche (wie oben gezeigt) als auch über YAML-Code innerhalb des Pipelineschemas konfiguriert werden.
Beispiel für die Verwendung eines Administratorbefehls
steps:
- task: Azure-Kusto.PublishToADX.PublishToADX.PublishToADX@1
displayName: '<Task Name>'
inputs:
script: '<inline Script>'
waitForOperation: true
kustoUrls: '$(CONNECTIONSTRING):443?DatabaseName=""'
customAuth: true
connectedServiceName: '<Service Endpoint Name>'
serialDelay: 1000
continueOnError: true
condition: ne(variables['ProductVersion'], '') ## Custom condition Sample
Beispiel für die Verwendung einer Abfrage
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@1
displayName: '<Task Display Name>'
inputs:
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DataBaneName>'
customAuth: true
connectedServiceName: '<Service Endpoint Name>'
continueOnError: true
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für