Optimieren von Senken
Wenn Datenflüsse in Senken schreiben, werden alle benutzerdefinierten Partitionierungen direkt vor dem Schreibvorgang durchgeführt. Wie auch bei der Quelle, ist es in den meisten Fällen zu empfehlen, die Auswahl der Partitionierungsoption Aktuelle Partitionierung verwenden beizubehalten. Partitionierte Daten werden deutlich schneller als nicht partitionierte Daten geschrieben. Dies gilt auch, wenn Ihr Ziel nicht partitioniert ist. Nachfolgend sind die einzelnen Aspekte für die verschiedenen Senkentypen angegeben.
Azure SQL-Datenbank-Senken
Bei Azure SQL-Datenbank sollte die Standardpartitionierung in den meisten Fällen funktionieren. Es besteht die Möglichkeit, dass Ihre Senke über zu viele Partitionen verfügt, sodass sie von Ihrer SQL-Datenbank-Instanz nicht mehr verarbeitet werden können. Reduzieren Sie in diesem Fall die Anzahl von Partitionen, die von Ihrer SQL-Datenbank-Senke ausgegeben werden.
Bewährtes Verfahren zum Löschen von Zeilen in der Senke aufgrund fehlender Zeilen in der Quelle
In diesem Video wird gezeigt, wie Datenflüsse mit Exists-, Zeilenänderungs- und Senkentransformationen verwendet werden können, um dieses allgemeine Muster zu erreichen:
Auswirkung der Fehlerzeilenbehandlung auf die Leistung
Wenn Sie die Fehlerzeilenbehandlung („Bei Fehler fortsetzen“) in der Senkentransformation aktivieren, führt der Dienst einen zusätzlichen Schritt aus, bevor die kompatiblen Zeilen in die Zieltabelle geschrieben werden. Dieser zusätzliche Schritt führt zu einer geringen Leistungseinbuße, die für diesen Schritt mit etwa 5 % veranschlagt werden kann. Eine zusätzliche kleine Leistungseinbuße tritt auf, wenn Sie auch die Option zum Schreiben inkompatibler Zeilen für eine Protokolldatei festlegen.
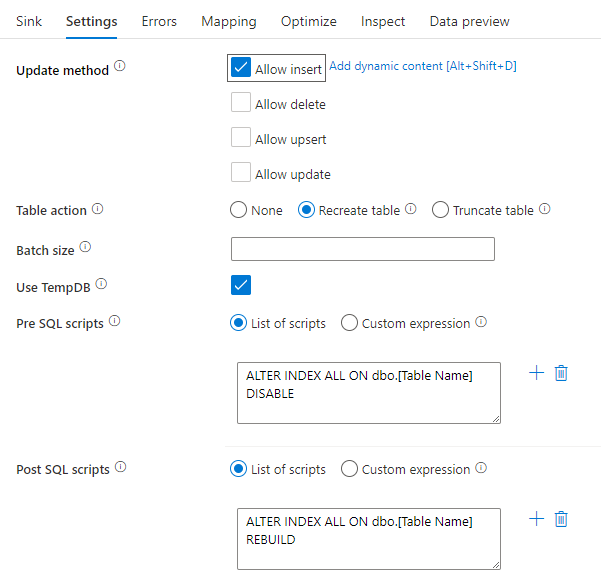
Deaktivieren von Indizes per SQL-Skript
Durch das Deaktivieren von Indizes vor dem Laden in eine SQL-Datenbank kann die Leistung beim Schreiben in die Tabelle erheblich verbessert werden. Führen Sie den unten angegebenen Befehl aus, bevor Sie in Ihre SQL-Senke schreiben.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Nachdem der Schreibvorgang abgeschlossen ist, sollten Sie die Indizes mit dem folgenden Befehl neu erstellen:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Dies kann sowohl nativ mit Pre- und Post-SQL-Skripts auf einer Azure SQL-Datenbank-Instanz als auch über eine Synapse-Senke in Zuordnungsdatenflüssen durchgeführt werden.
Warnung
Beim Deaktivieren von Indizes übernimmt der Datenfluss quasi die Kontrolle über eine Datenbank, und die Durchführung von Abfragen ist dann wahrscheinlich nicht erfolgreich. Aus diesem Grund werden viele ETL-Aufträge nachts ausgelöst, um Konflikte dieser Art zu vermeiden. Weitere Informationen finden Sie im Artikel Deaktivieren von SQL-Indizes und Einschränkungen.
Hochskalieren Ihrer Datenbank
Planen Sie die Anpassung der Größe Ihrer Quelle und Senke in Azure SQL-Datenbank und Azure SQL Data Warehouse vor der Pipelineausführung, um den Durchsatz zu erhöhen und die Drosselung durch Azure beim Erreichen der DTU-Grenzwerte zu minimieren. Stellen Sie nach Abschluss der Pipelineausführung die Größe Ihrer Datenbanken für die normale Ausführung wieder her.
Azure Synapse Analytics-Senken
Stellen Sie beim Schreiben in Azure Synapse Analytics sicher, dass die Option Staging aktivieren aktiviert ist. Hierdurch wird für den Dienst das Schreiben mit dem SQL-Befehl COPY ermöglicht, sodass für die Daten praktisch ein Massenladevorgang erfolgt. Bei Verwendung von Staging müssen Sie auf ein Azure Data Lake Storage Gen2- oder Azure Blob Storage-Konto für das Staging der Daten verweisen.
Mit Ausnahme von Staging gelten für Azure Synapse Analytics die gleichen bewährten Methoden wie für Azure SQL-Datenbank.
Dateibasierte Senken
Für Datenflüsse werden zwar verschiedene Dateitypen unterstützt, zum Erzielen von optimalen Lese- und Schreibzeiten wird aber das native Spark-Format „Parquet“ empfohlen.
Wenn die Daten gleichmäßig verteilt sind, ist Aktuelle Partitionierung verwenden die schnellste Partitionierungsoption für das Schreiben von Dateien.
Dateinamenoptionen
Beim Schreiben von Dateien können Sie zwischen verschiedenen Benennungsoptionen wählen, die sich jeweils auf die Leistung auswirken.

Wenn Sie die Option Standard auswählen, ist der Schreibvorgang am schnellsten. Jede Partition entspricht einer Datei mit dem Standardnamen von Spark. Dies ist hilfreich, wenn Sie nur aus dem Ordner mit den Daten lesen.
Wenn Sie ein Muster für die Benennung auswählen, wird jede Partitionsdatei mit einem benutzerfreundlicheren Namen benannt. Dieser Vorgang erfolgt nach dem Schreibvorgang und ist etwas langsamer als bei der Option „Standard“.
Pro Partition ermöglicht es Ihnen, jede einzelne Partition manuell zu benennen.
Falls eine Spalte bereits die gewünschte Form für die Ausgabe der Daten aufweist, können Sie Dateiname aus Spaltendaten auswählen. Die Daten werden dann neu angeordnet und können die Leistung beeinträchtigen, falls die Spalten nicht gleichmäßig verteilt sind.
Falls eine Spalte bereits die gewünschte Form für das Generieren von Ordnernamen aufweist, können Sie Ordnername aus Spaltendaten auswählen.
Bei Ausgabe in eine einzelne Datei werden alle Daten in einer Partition kombiniert. Dies führt besonders für große Datasets zu langen Schreibzeiten. Von dieser Option wird abgeraten, es sei denn, es gibt einen expliziten geschäftlichen Grund, sie zu verwenden.
Azure Cosmos DB-Senken
Beim Schreiben in Azure Cosmos DB kann die Leistung verbessert werden, indem der Durchsatz und die Batchgröße während der Ausführung des Datenflusses geändert werden. Diese Änderungen sind nur während der Datenfluss-Aktivitätsausführung wirksam und werden nach Abschluss des Vorgangs auf die ursprünglichen Sammlungseinstellungen zurückgesetzt.
Batchgröße: Normalerweise reicht als Startwert die Batchgröße aus. Um diesen Wert weiter anzupassen, berechnen Sie die ungefähre Objektgröße Ihrer Daten, und stellen Sie sicher, dass das Produkt aus Objektgröße und Batchgöße kleiner als 2 MB ist. Erhöhen Sie andernfalls die Batchgröße, um einen besseren Durchsatz zu erzielen.
Durchsatz: Legen Sie hier einen höheren Durchsatz fest, damit Dokumente schneller in Azure Cosmos DB geschrieben werden können. Beachten Sie die höheren RU-Kosten bei einer höheren Durchsatzeinstellung.
Write throughput budget (Schreibdurchsatz): Verwenden Sie einen Wert, der kleiner als die Gesamtanzahl der RUs pro Minute ist. Wenn Ihr Datenfluss eine hohe Anzahl von Spark-Partitionen enthält, können Sie durch das Festlegen eines Durchsatzbudgets eine bessere Balance zwischen diesen Partitionen erzielen.
Zugehöriger Inhalt
- Übersicht über die Datenflussleistung
- Optimieren von Quellen
- Optimieren von Transformationen
- Verwenden von Datenflüssen in Pipelines
Lesen Sie die folgenden Artikel zu Datenflüssen in Bezug auf die Leistung: