Transformieren von Daten durch Ausführen eines Databricks-Notebooks
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Die Azure Databricks-Notebook-Aktivität in einer Pipeline führt ein Databricks-Notebook in Ihrem Azure Databricks-Arbeitsbereich aus. Dieser Artikel baut auf dem Artikel zu Datentransformationsaktivitäten auf, der eine allgemeine Übersicht über die Datentransformation und die unterstützten Transformationsaktivitäten bietet. Azure Databricks ist eine verwaltete Plattform für die Ausführung von Apache Spark.
Sie können ein Databricks-Notebook mit einer ARM-Vorlage mit JSON oder direkt über die Azure Data Factory Studio-Benutzeroberfläche erstellen. Eine schrittweise exemplarische Vorgehensweise zum Erstellen einer Databricks Notebook-Aktivität über die Benutzeroberfläche erfahren Sie im Tutorial Ausführen eines Databricks-Notebooks mit der Databricks Notebook-Aktivität in Azure Data Factory.
Hinzufügen einer Notebook-Aktivität für Azure Databricks zu einer Pipeline mit Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um eine Notebook-Aktivität für Azure Databricks in einer Pipeline zu verwenden:
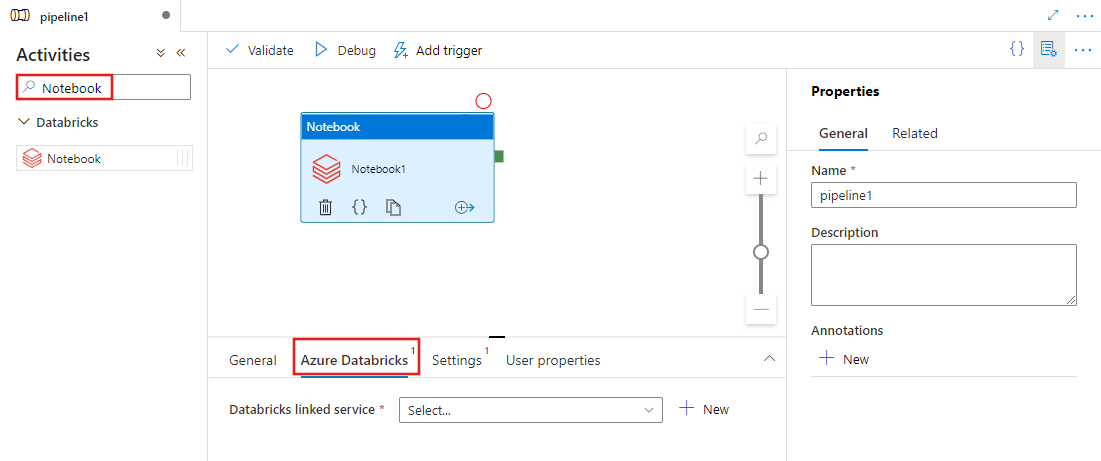
Suchen Sie im Bereich mit den Pipelineaktivitäten nach Notebook, und ziehen Sie eine Webhookaktivität in den Pipelinebereich.
Wählen Sie die neue Notebook-Aktivität im Canvas aus, wenn sie noch nicht ausgewählt ist.
Wählen Sie die Registerkarte Azure Databricks aus, um einen neuen Azure Databricks verknüpften Dienst auszuwählen oder zu erstellen, der die Notebook-Aktivität ausführt.
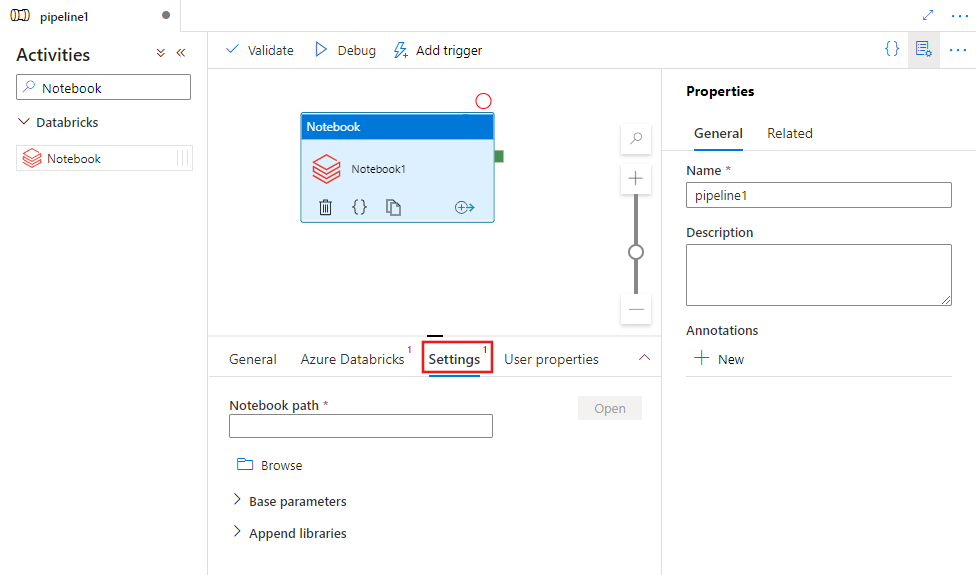
Wählen Sie die Registerkarte Einstellungen aus, und geben Sie den Notebookpfad an, der auf Azure Databricks ausgeführt werden soll, optionale Basisparameter, die an das Notebook übergeben werden sollen, und alle zusätzlichen Bibliotheken, die im Cluster installiert werden sollen, um den Auftrag auszuführen.
Definition der Databricks-Notebook-Aktivität
Dies ist die JSON-Beispieldefinition der Databricks-Notebook-Aktivität:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Eigenschaften der Databricks-Notebook-Aktivität
Die folgende Tabelle beschreibt die JSON-Eigenschaften, die in der JSON-Definition verwendet werden:
| Eigenschaft | BESCHREIBUNG | Erforderlich |
|---|---|---|
| name | Der Name der Aktivität in der Pipeline. | Ja |
| description | Ein Text, der beschreibt, was mit der Aktivität ausgeführt wird. | Nein |
| type | Bei Databricks-Notebook-Aktivitäten lautet der Aktivitätstyp DatabricksNotebook. | Ja |
| linkedServiceName | Der Name des verknüpften Databricks-Diensts, in dem das Databricks-Notebook ausgeführt wird. Weitere Informationen zu diesem verknüpften Dienst finden Sie im Artikel Von Azure Data Factory unterstützten Compute-Umgebungen. | Ja |
| notebookPath | Der absolute Pfad des Notebooks, das im Databricks-Arbeitsbereich ausgeführt werden soll. Dieser Pfad muss mit einem Schrägstrich beginnen. | Ja |
| baseParameters | Ein Array aus Schlüssel-Wert-Paaren. Für jede Aktivitätsausführung können Basisparameter verwendet werden. Wenn das Notebook einen nicht spezifizierten Parameter akzeptiert, wird der Standardwert des Notebooks verwendet. Erfahren Sie mehr über Parameter in Databricks-Notebooks. | Nein |
| libraries | Eine Liste der Bibliotheken, die in dem Cluster installiert werden, der den Auftrag ausführen wird. Es kann ein Array vom Typ <Zeichenfolge, Objekt> sein. | Nein |
Unterstützte Bibliotheken für Databricks-Aktivitäten
In der oben genannten Definition der Databricks-Aktivität geben Sie die folgenden Bibliothekstypen an: JAR, EGG, WHL, Maven, PyPI, CRAN.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Weitere Informationen zu Bibliothekstypen finden Sie in der Databricks-Dokumentation.
Übergeben von Parametern zwischen Notebooks und Pipelines
Mithilfe der baseParameters-Eigenschaft in der Databricks-Aktivität können Sie Parameter an Notebooks übergeben.
In bestimmten Fällen müssen Sie möglicherweise bestimmte Werte aus dem Notebook an den Dienst zurückgeben, die für die Ablaufsteuerung (Bedingungsüberprüfungen) im Dienst oder von Downstreamaktivitäten (Größenbeschränkung ist 2 MB) genutzt werden können.
Sie können in Ihrem Notebook dbutils.notebook.exit("returnValue") aufrufen, um den entsprechenden Rückgabewert (returnValue) an den Dienst zurückzugeben.
Mit einem Ausdruck wie
@{activity('databricks notebook activity name').output.runOutput}können Sie die Ausgabe im Dienst verwenden.Wichtig
Wenn Sie ein JSON-Objekt übergeben, können Sie Werte abrufen, indem Sie Eigenschaftsnamen anhängen. Beispiel:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Hochladen einer Bibliothek in Databricks
Sie können die Benutzeroberfläche des Arbeitsbereichs verwenden:
Verwenden der Benutzeroberfläche des Databricks-Arbeitsbereichs
Sie können den DBFS-Pfad der hinzugefügten Bibliothek über die Benutzeroberfläche mithilfe der Databricks-Befehlszeilenschnittstelle abrufen.
JAR-Bibliotheken werden beim Verwenden der Benutzeroberfläche in der Regel unter dbfs:/FileStore/jars gespeichert. Sie können alle über die Befehlszeilenschnittstelle auflisten: databricks fs ls dbfs:/FileStore/job-jars
Alternativ können Sie die Databricks-Befehlszeilenschnittstelle verwenden:
Informationen finden Sie unter Kopieren der Bibliotheken mit der Databricks-Befehlszeilenschnittstelle.
Verwenden Sie die Databricks-Befehlszeilenschnittstelle (Installationsschritte).
Kopieren Sie damit beispielsweise eine JAR-Ausgabe in DBFS:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar.