Zugriff auf Azure Data Lake Storage mithilfe von Passthrough (Legacy) für Microsoft Entra ID (früher Azure Active Directory)-Anmeldeinformationen
Wichtig
Diese Dokumentation wurde eingestellt und wird unter Umständen nicht aktualisiert.
Passthrough für Anmeldeinformationen ist ein Legacy-Datengovernancemodell. Databricks empfiehlt, ein Upgrade auf Unity Catalog durchzuführen. Unity Catalog vereinfacht die Sicherheit und Governance Ihrer Daten durch die Bereitstellung eines zentralen Ortes zum Verwalten und Überwachen des Datenzugriffs über mehrere Arbeitsbereiche in Ihrem Konto. Siehe Was ist Unity Catalog?.
Wenden Sie sich für mehr Sicherheit und Governance an Ihr Azure Databricks-Kontoteam, um Passthrough für Anmeldeinformationen in Ihrem Azure Databricks-Konto zu deaktivieren.
Hinweis
Dieser Artikel enthält Verweise auf den Begriff Whitelist, einen Begriff, den Azure Databricks nicht verwendet. Sobald der Begriff aus der Software entfernt wird, wird er auch aus diesem Artikel entfernt.
Sie können sich von einem Azure Databricks-Cluster aus automatisch bei Zugriff auf Azure Data Lake Storage Gen1 von Azure Data Bricks (ADLS Gen1) und ADLS Gen2 authentifizieren, indem Sie dieselbe Microsoft Entra ID (früher Azure Active Directory)-Identität wie zur Anmeldung bei Azure Databricks verwenden. Wenn Sie das Passthrough für Anmeldeinformationen in Azure Data Lake Storage für Ihren Cluster aktivieren, können Befehle, die Sie in diesem Cluster ausführen, Daten in Azure Data Lake Storage lesen und schreiben, ohne dass Sie Dienstprinzipal-Anmeldeinformationen für den Zugriff auf den Speicher konfigurieren müssen.
Das Passthrough für Anmeldeinformationen in Azure Data Lake Storage wird nur mit Azure Data Lake Storage Gen1 und Gen2 unterstützt. Azure Blob Storage unterstützt kein Passthrough für Anmeldeinformationen.
In diesem Artikel wird Folgendes behandelt:
- Aktivieren des Passthroughs für Anmeldeinformationen für Standardcluster und Cluster mit hoher Parallelität.
- Konfigurieren des Passthroughs für Anmeldeinformationen und Initialisieren von Speicherressourcen in ADLS-Konten.
- Direkter Zugriff auf ADLS-Ressourcen bei aktiviertem Passthrough für Anmeldeinformationen.
- Zugriff auf ADLS-Ressourcen über einen Bereitstellungspunkt bei aktiviertem Passthrough für Anmeldeinformationen.
- Unterstützte Features und Einschränkungen bei der Verwendung des Passthroughs für Anmeldeinformationen.
Enthaltene Notebooks stellen Beispiele für die Verwendung des Passthroughs von Anmeldeinformationen mit ADLS Gen1 und ADLS Gen2 bereit.
Anforderungen
- Premium-Tarif: Weitere Informationen zum Upgrade eines Standard- auf einen Premium-Tarif finden Sie unter Upgrade oder Downgrade eines Azure Databricks-Arbeitsbereichs.
- Ein Azure Data Lake Storage Gen1- oder Gen2-Speicherkonto. Azure Data Lake Storage Gen2-Speicherkonten müssen den hierarchischen Namespace verwenden, um Passthrough für Anmeldeinformationen in Azure Data Lake Storage zu nutzen. Unter Erstellen eines Speicherkontos finden Sie Anweisungen zum Erstellen eines neuen ADLS Gen2-Kontos und zur Aktivierung des hierarchischen Namespace.
- Ordnungsgemäß konfigurierte Benutzerberechtigungen für Azure Data Lake Storage. Ein Azure Databricks-Administrator muss sicherstellen, dass Benutzer über die richtigen Rollen verfügen, z. B. „Mitwirkender an Storage-Blobdaten“, um in Azure Data Lake Storage gespeicherte Daten zu lesen und zu schreiben. Weitere Informationen finden Sie unter Zuweisen einer Azure-Rolle für den Zugriff auf Blob- und Warteschlangendaten über das Azure-Portal.
- Machen Sie sich mit den Berechtigungen der Administrator von Arbeitsbereichen vertraut, die für Passthrough aktiviert sind. Überprüfen Sie Ihre vorhandenen Administratorzuweisungen für Arbeitsbereiche. Arbeitsbereichsadministrator*innen können Vorgänge für ihren Arbeitsbereich verwalten und beispielsweise Benutzer*innen und Dienstprinzipale hinzufügen, Cluster erstellen und andere Benutzer*innen als Arbeitsbereichsadministrator*innen delegieren. Arbeitsbereichsverwaltungsaufgaben, z. B. das Verwalten des Auftragsbesitzes und das Anzeigen von Notebooks, können indirekten Zugriff auf Daten gewähren, die in Azure Data Lake Storage registriert sind. „Arbeitsbereichsadministrator“ ist eine privilegierte Rolle, die Sie sorgfältig vergeben sollten.
- Sie können keinen Cluster verwenden, der mit ADLS-Anmeldeinformationen konfiguriert ist, z. B. Dienstprinzipal-Anmeldeinformationen, mit Passthrough für Anmeldeinformationen.
Wichtig
Sie können sich nicht bei Azure Data Lake Storage mit Ihren Microsoft Entra ID-Anmeldeinformationen authentifizieren, wenn Sie sich hinter einer Firewall befinden, deren Konfiguration keinen Datenverkehr zu Microsoft Entra ID zulässt. Durch Azure Firewall wird der Active Directory-Zugriff standardmäßig blockiert. Um den Zugriff zuzulassen, konfigurieren Sie das AzureActiveDirectory-diensttag. Entsprechende Informationen für virtuelle Netzwerkgeräte finden Sie unter dem Tag „AzureActiveDirectory“ in der JSON-Datei mit den Azure-IP-Bereichen und Diensttags. Weitere Informationen finden Sie unter Azure Firewall-Diensttags und Azure-IP-Adressen für die öffentliche Cloud.
Protokollierungsempfehlungen
Sie können Identitäten protokollieren, die in den Azure Storage-Diagnoseprotokollen an den ADLS-Speicher übergeben werden. Durch die Protokollierung von Identitäten können ADLS-Anforderungen an einzelne Benutzer aus Azure Databricks-Clustern gebunden werden. Aktivieren Sie die Diagnoseprotokollierung für Ihr Speicherkonto, um mit dem Empfang dieser Protokolle zu beginnen:
- Azure Data Lake Storage Gen1: Befolgen Sie die Anweisungen unter Aktivieren der Diagnoseprotokollierung für Ihr Data Lake Storage Gen1-Konto.
- Azure Data Lake Storage Gen2: Führen Sie die Konfiguration unter Verwendung von PowerShell mit dem Befehl
Set-AzStorageServiceLoggingPropertyaus. Geben Sie 2.0 als Version an, da der Protokolleintrag im Format 2.0 den Benutzerprinzipalnamen in der Anforderung enthält.
Aktivieren des Passthrough für Anmeldeinformationen in Azure Data Lake Storage für einen Cluster mit hoher Parallelität
Cluster mit hoher Parallelität können von mehreren Benutzern gemeinsam genutzt werden. Sie unterstützen nur Python und SQL mit Passthrough für Anmeldeinformationen Azure Data Lake Storage.
Wichtig
Durch Aktivieren des Passthroughs für Anmeldeinformationen in Azure Data Lake Storage für einen Cluster mit hoher Parallelität werden alle Ports im Cluster blockiert, mit Ausnahme der Ports 44, 53 und 80.
- Legen Sie beim Erstellen eines Clustersden Clustermodus auf Hohe Parallelität fest.
- Wählen Sie unter Erweiterte Optionen die Option Passthrough für Anmeldeinformationen für den Datenzugriff auf Benutzerebene aktivieren aus, und lassen Sie nur Python- und SQL-Befehle zu.

Aktivieren des Passthroughs für Anmeldeinformationen in Azure Data Lake Storage für einen Standardcluster
Standardcluster mit Passthrough für Anmeldeinformationen sind auf einen einzelnen Benutzer beschränkt. Standardcluster unterstützen Python, SQL, Scala und R. Ab Databricks Runtime 10.4 LTS wird Sparklyr unterstützt.
Sie müssen bei der Clustererstellung einen Benutzer zuweisen. Ein Benutzer mit KANN VERWALTEN-Berechtigungen kann das Cluster jederzeit bearbeiten und den ursprünglichen Benutzer ersetzen.
Wichtig
Der dem Cluster zugewiesene Benutzer muss mindestens über die Berechtigung KANN ANFÜGEN AN für das Cluster verfügen, um Befehle im Cluster auszuführen. Arbeitsbereichsadministratoren und der Clusterersteller verfügen über KANN VERWALTEN-Berechtigungen, können jedoch keine Befehle im Cluster ausführen, es sei denn, sie sind der designierte Clusterbenutzer.
- Legen Sie beim Erstellen eines Clusters den Clustermodus auf Standard fest.
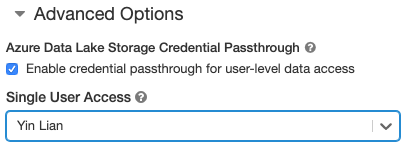
- Wählen Sie unter Erweiterte Optionen die Option Passthrough für Anmeldeinformationen für den Datenzugriff auf Benutzerebene aktivieren und dann den Benutzernamen aus der Dropdownliste Einzelbenutzerzugriff aus.
Erstellen eines Containers
Container bieten eine Möglichkeit, Objekte in einem Azure-Speicherkonto zu organisieren.
Direkter Zugriff auf Azure Data Lake Storage mithilfe von Passthrough für Anmeldeinformationen
Nach dem Konfigurieren des Passthroughs für Anmeldeinformationen in Azure Data Lake Storage und dem Erstellen von Speichercontainern können Sie direkt in Azure Data Lake Storage Gen1 unter Verwendung eines adl://-Pfads und in Azure Data Lake Storage Gen2 unter Verwendung eines abfss://-Pfads auf Daten zugreifen.
Azure Data Lake Storage Gen1
Python
spark.read.format("csv").load("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("adl://<storage-account-name>.azuredatalakestore.net/MyData.csv") %>% sdf_collect()
- Ersetzen Sie
<storage-account-name>durch den Namen des ADLS Gen1-Speicherkontos.
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Ersetzen Sie
<container-name>durch den Namen eines Containers im ADLS Gen2-Speicherkonto. - Ersetzen Sie
<storage-account-name>durch den Namen des ADLS Gen2-Speicherkontos.
Einbinden von Azure Data Lake Storage in DBFS mithilfe von Passthrough für Anmeldeinformationen
Sie können ein Azure Data Lake Storage-Konto oder einen darin enthaltenen Ordner in das Databricks-Dateisystem (Databricks File System, DBFS) einbinden. Die Einbindung ist ein Zeiger auf einen Data Lake-Speicher, sodass die Daten nie lokal synchronisiert werden.
Wenn Sie Daten mithilfe eines Clusters bereitstellen, für den Passthrough für Anmeldeinformationen in Azure Data Lake Storage aktiviert ist, werden bei jedem Lese- oder Schreibzugriff auf den Bereitstellungspunkt Ihre Microsoft Entra ID-Anmeldeinformationen verwendet. Dieser Bereitstellungspunkt ist für andere Benutzer sichtbar, aber nur die folgenden Benutzer verfügen über Lese- und Schreibzugriff:
- Benutzer mit Zugriff auf das zugrunde liegende Azure Data Lake Storage-Speicherkonto
- Benutzer, die einen Cluster verwenden, für den Passthrough für Anmeldeinformationen in Azure Data Lake Storage aktiviert ist
Azure Data Lake Storage Gen1
Verwenden Sie zum Bereitstellen einer Azure Data Lake Storage Gen1-Ressource oder eines darin enthaltenen Ordners die folgenden Befehle:
Python
configs = {
"fs.adl.oauth2.access.token.provider.type": "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider": spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.adl.oauth2.access.token.provider.type" -> "CustomAccessTokenProvider",
"fs.adl.oauth2.access.token.custom.provider" -> spark.conf.get("spark.databricks.passthrough.adls.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://<storage-account-name>.azuredatalakestore.net/<directory-name>",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Ersetzen Sie
<storage-account-name>durch den Namen des ADLS Gen2-Speicherkontos. - Ersetzen Sie
<mount-name>durch den Namen des beabsichtigten Bereitstellungspunkts in DBFS.
Azure Data Lake Storage Gen2
Verwenden Sie zum Bereitstellen eines Azure Data Lake Storage Gen2-Dateisystems oder eines darin enthaltenen Ordners die folgenden Befehle:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Ersetzen Sie
<container-name>durch den Namen eines Containers im ADLS Gen2-Speicherkonto. - Ersetzen Sie
<storage-account-name>durch den Namen des ADLS Gen2-Speicherkontos. - Ersetzen Sie
<mount-name>durch den Namen des beabsichtigten Bereitstellungspunkts in DBFS.
Warnung
Geben Sie zur Authentifizierung beim Bereitstellungspunkt nicht den Zugriffsschlüssel für Ihr Speicherkonto und keine Dienstprinzipal-Anmeldeinformationen an. Dadurch könnten andere Benutzern diese Anmeldeinformationen verwenden und Zugriff auf das Dateisystem erhalten. Der Zweck des Passthroughs für Anmeldeinformationen in Azure Data Lake Storage besteht darin, die Verwendung dieser Anmeldeinformationen zu verhindern und sicherzustellen, dass der Zugriff auf das Dateisystem auf Benutzer beschränkt ist, die Zugriff auf das zugrunde liegende Azure Data Lake Storage-Konto haben.
Sicherheit
Es ist sicher, Azure Data Lake Storage-Cluster mit Passthrough für Anmeldeinformationen für andere Benutzer freizugeben. Sie sind voneinander isoliert und können die Anmeldeinformationen des jeweils anderen Benutzers weder lesen noch verwenden.
Unterstützte Funktionen
| Funktion | Mindestversion von Databricks Runtime | Notizen |
|---|---|---|
| Python und SQL | 5.5 | |
| Azure Data Lake Storage Gen1 | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | Anmeldeinformationen werden nur übergeben, wenn der DBFS-Pfad zu einem Speicherort in Azure Data Lake Storage Gen1 oder Gen2 aufgelöst wird. Verwenden Sie für DBFS-Pfade, die zu anderen Speichersystemen aufgelöst werden, eine andere Methode zur Angabe Ihrer Anmeldeinformationen. |
| Azure Data Lake Storage Gen2 | 5.5 | |
| Datenträgerzwischenspeicherung | 5.5 | |
| PySpark ML-API | 5.5 | Die folgenden ML-Klassen werden nicht unterstützt: * org/apache/spark/ml/classification/RandomForestClassifier* org/apache/spark/ml/clustering/BisectingKMeans* org/apache/spark/ml/clustering/GaussianMixture* org/spark/ml/clustering/KMeans* org/spark/ml/clustering/LDA* org/spark/ml/evaluation/ClusteringEvaluator* org/spark/ml/feature/HashingTF* org/spark/ml/feature/OneHotEncoder* org/spark/ml/feature/StopWordsRemover* org/spark/ml/feature/VectorIndexer* org/spark/ml/feature/VectorSizeHint* org/spark/ml/regression/IsotonicRegression* org/spark/ml/regression/RandomForestRegressor* org/spark/ml/util/DatasetUtils |
| Broadcastvariablen | 5.5 | In PySpark gibt es eine Beschränkung der Größe der Python-UDFs, die Sie erstellen können, da große UDFs als Broadcastvariablen gesendet werden. |
| Bibliotheken im Notebookbereich | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6,0 | |
| sparklyr | 10.1 | |
| Ausführen eines Databricks-Notebooks über ein anderes Notebook | 6.1 | |
| PySpark ML-API | 6.1 | Alle PySpark-ML-Klassen werden unterstützt. |
| Clustermetriken | 6.1 | |
| Databricks Connect | 7.3 | Passthrough wird in Standardclustern unterstützt. |
Einschränkungen
Die folgenden Features werden beim Passthrough für Anmeldeinformationen in Azure Data Lake Storage nicht unterstützt:
%fs(verwenden Sie stattdessen den entsprechenden dbutils.fs-Befehl).- Databricks-Workflows.
- Die Referenz zur Databricks-REST-API
- Unity Catalog.
- Tabellenzugriffssteuerung. Die von Passthrough für Anmeldeinformationen in Azure Data Lake Storage gewährten Berechtigungen können verwendet werden, um die differenzierten Berechtigungen von Tabellen-ACLs zu umgehen, während die zusätzlichen Einschränkungen von Tabellen-ACLs einige der Vorteile des Passthroughs für Anmeldeinformationen einschränken. Dies gilt insbesondere für:
- Wenn Sie über die Microsoft Entra ID-Berechtigung für den Zugriff auf die Datendateien verfügen, die einer bestimmten Tabelle zugrunde liegen, verfügen Sie über die RDD-API über vollständige Berechtigungen für diese Tabelle, unabhängig von den über Tabellen-ACLs festgelegten Einschränkungen.
- Sie werden nur bei Verwendung der DataFrame-API durch Tabellen-ACL-Berechtigungen eingeschränkt. Wenn Sie versuchen, Dateien direkt mit der DataFrame-API zu lesen, werden Warnungen angezeigt, dass Sie keine
SELECT-Berechtigung für eine Datei haben, obwohl Sie diese Dateien direkt über die RDD-API lesen könnten. - Sie können nicht aus Tabellen lesen, die von anderen Dateisystemen als Azure Data Lake Storage unterstützt werden, auch wenn Sie über die Tabellen-ACL-Berechtigung zum Lesen der Tabellen verfügen.
- Die folgenden Methoden für SparkContext- (
sc) und SparkSession (spark)-Objekte:- Veraltete Methoden.
- Methoden wie
addFile()undaddJar(), mit denen Benutzer ohne Administratorrechte Scala-Code aufrufen können. - Jede Methode, die auf ein anderes Dateisystem als Azure Data Lake Storage Gen1 oder Gen2 zugreift. (Für den Zugriff auf andere Dateisysteme in einem Cluster mit aktiviertem Passthrough für Anmeldeinformationen in Azure Data Lake Storage verwenden Sie eine andere Methode, um Ihre Anmeldeinformationen anzugeben, und schauen Sie sich den Abschnitt zu vertrauenswürdigen Dateisystemen unter Problembehandlung an.)
- Die alten Hadoop-APIs (
hadoopFile()undhadoopRDD()). - Streaming-APIs, da die übergebenen Anmeldeinformationen ablaufen würden, während der Stream noch ausgeführt wird.
- DBFS-Einbindungen (
/dbfs) sind nur in Databricks Runtime 7.3 LTS und höher verfügbar. Bereitstellungspunkte mit konfiguriertem Passthrough für Anmeldeinformationen werden über diesen Pfad nicht unterstützt. - Azure Data Factory
- MLflow in Clustern mit hoher Parallelität.
- azureml-sdk-Python-Paket in Clustern mit hoher Parallelität.
- Die Lebensdauer von Microsoft Entra ID-Passthroughtoken kann nicht mithilfe von Richtlinien für die Gültigkeitsdauer von Microsoft Entra ID-Token verlängert werden. Wenn Sie also einen Befehl an den Cluster senden, der länger als eine Stunde dauert, tritt nach Ablauf der 1-Stunden-Marke beim Zugriff auf eine Azure Data Lake Storage-Ressource ein Fehler auf.
- Bei Verwendung von Hive 2.3 und höher können Sie keine Partition in einem Cluster hinzufügen, für den das Passthrough für Anmeldeinformationen aktiviert ist. Weitere Informationen finden Sie im relevanten Abschnitt zur Problembehandlung.
Beispielnotebooks
Die folgenden Notebooks veranschaulichen das Passthrough für Anmeldeinformationen in Azure Data Lake Storage für Azure Data Lake Storage Gen1 und Gen2.
Azure Data Lake Storage Gen1-Passthrough-Notebook
Azure Data Lake Storage Gen2-Passthrough-Notebook
Problembehandlung
py4j.security.Py4JSecurityException: … ist nicht in der Whitelist enthalten
Diese Ausnahme wird ausgelöst, wenn Sie auf eine Methode zugegriffen haben, die von Azure Databricks nicht explizit als sichere Methode für Azure Data Lake Storage-Cluster mit Passthrough für Anmeldeinformationen gekennzeichnet wurde. In den meisten Fällen bedeutet dies, dass bei dieser Methode ein Benutzer in einem Azure Data Lake Storage-Cluster mit Passthrough für Anmeldeinformationen unter Umständen auf die Anmeldeinformationen eines anderen Benutzers zugreifen kann.
org.apache.spark.api.python.PythonSecurityException: Path … verwendet ein nicht vertrauenswürdiges Dateisystem
Diese Ausnahme wird ausgelöst, wenn Sie versucht haben, auf ein Dateisystem zuzugreifen, das vom Azure Data Lake Storage-Cluster mit Passthrough für Anmeldeinformationen nicht als sicher bekannt ist. Die Verwendung eines nicht vertrauenswürdigen Dateisystems könnte es einem Benutzer in einem Azure Data Lake Storage-Cluster mit Passthrough für Anmeldeinformationen ermöglichen, auf die Anmeldeinformationen eines anderen Benutzers zuzugreifen. Daher werden keine Dateisysteme zugelassen, von denen wir nicht überzeugt sind, dass sie sicher verwendet werden können.
Um den Satz vertrauenswürdiger Dateisysteme in einem Azure Data Lake Storage-Cluster mit Passthrough für Anmeldeinformationen zu konfigurieren, legen Sie den Spark-Conf-Schlüssel spark.databricks.pyspark.trustedFilesystems für diesen Cluster auf eine durch Kommas getrennte Liste der Klassennamen fest, bei denen es sich um vertrauenswürdige Implementierungen von org.apache.hadoop.fs.FileSystem handelt.
Beim Hinzufügen einer Partition tritt ein AzureCredentialNotFoundException-Fehler auf, wenn das Passthrough für Anmeldeinformationen aktiviert ist.
Bei Verwendung von Hive 2.3-3.1 tritt die folgende Ausnahme auf, wenn Sie versuchen, eine Partition in einem Cluster hinzuzufügen, für den das Passthrough für Anmeldeinformationen aktiviert sind:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
Um dieses Problem zu umgehen, fügen Sie Partitionen in einem Cluster hinzu, ohne dass das Passthrough für Anmeldeinformationen aktiviert ist.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für