Datenobjekte im Databricks Lakehouse
Im Databricks Lakehouse werden Daten organisiert, die mit Delta Lake und klassischen Beziehungen wie Datenbanken, Tabellen und Ansichten im Cloudobjektspeicher gespeichert sind. Dieses Modell kombiniert viele der Vorteile eines Data Warehouses für Unternehmen mit der Skalierbarkeit und Flexibilität eines Data Lakes. Hier erfahren Sie mehr über die Funktionsweise dieses Modells und die Beziehung zwischen Objektdaten und Metadaten, sodass Sie beim Entwerfen und Implementieren des Databricks Lakehouse für Ihre Organisation bewährte Methoden anwenden können.
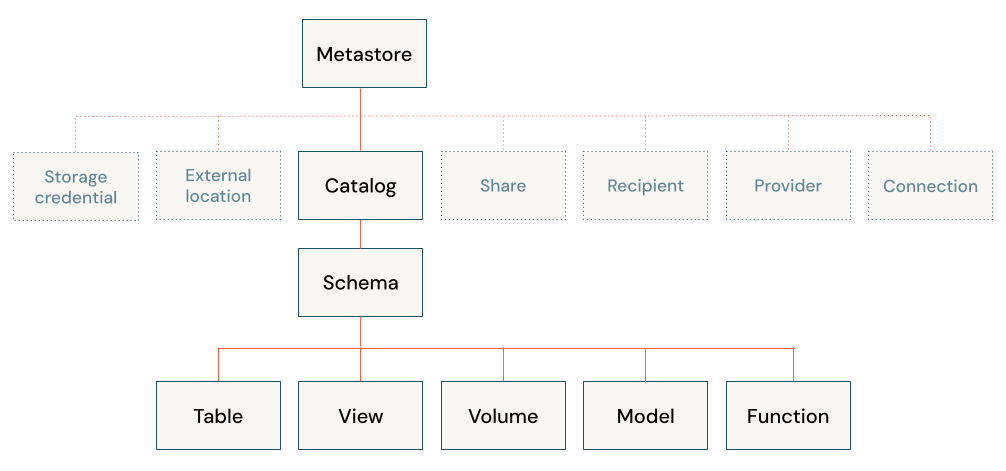
Welche Datenobjekte befinden sich im Databricks Lakehouse?
Die Databricks Lakehouse-Architektur kombiniert Daten, die mit dem Delta Lake-Protokoll im Cloudobjektspeicher gespeichert sind, mit Metadaten, die in einem Metastore registriert sind. Das Databricks Lakehouse verfügt über fünf primäre Objekte:
- Katalog: eine Gruppe von Datenbanken.
- Datenbank oder Schema: eine Gruppe von Objekten in einem Katalog. Datenbanken enthalten Tabellen, Ansichten und Funktionen.
- Tabelle: eine Sammlung von Zeilen und Spalten, die als Datendateien in einem Objektspeicher gespeichert sind.
- Ansicht: eine gespeicherte Abfrage, meist für eine oder mehrere Tabellen oder Datenquellen.
- Funktion: gespeicherte Logik, die einen Skalarwert oder eine Gruppe von Zeilen zurückgibt.
Informationen zum Schützen von Objekten mit Unity Catalog finden Sie unter dem Modell für sicherungsfähige Objekte.
Was ist ein Metastore?
Der Metastore enthält alle Metadaten, die Datenobjekte im Lakehouse definieren. Azure Databricks bietet die folgenden Metastore-Optionen:
Unity Catalog-Metastore: Unity Catalog bietet zentralisierte Zugriffssteuerungs-, Überwachungs-, Herkunfts- und Datenermittlungsfunktionen. Sie erstellen Unity Catalog-Metastores auf Azure Databricks-Kontoebene, und ein einzelner Metastore kann in mehreren Arbeitsbereichen verwendet werden.
Jeder Unity Catalog-Metastore ist mit einem Stammspeicherort in einem Azure Data Lake Storage Gen2-Container in Ihrem Azure-Konto konfiguriert. Dieser Speicherort wird standardmäßig zum Speichern von Daten für verwaltete Tabellen verwendet.
Die Daten in Unity Catalog sind standardmäßig geschützt. Benutzer*innen können anfangs nicht auf die Daten in einem Metastore zugreifen. Zugriff kann von einem Metastore-Administrator oder vom Besitzer eines Objekts gewährt werden. Sicherungsobjekte in Unity Catalog sind hierarchisch, und Berechtigungen werden abwärts vererbt. Unity Catalog bietet einen zentralen Ort zum Verwalten von Datenzugriffsrichtlinien. Benutzer können aus jedem Arbeitsbereich, an den der Metastore angefügt ist, auf Daten in Unity Catalog zugreifen. Weitere Informationen finden Sie unter Verwalten von Berechtigungen in Unity Catalog.
Integrierter Hive-Metastore (Legacy): Jeder Azure Databricks-Arbeitsbereich enthält einen integrierten Hive-Metastore als verwalteten Dienst. Eine Metastore-Instanz ist für Bereitstellungen für jeden Cluster zuständig und greift über ein zentrales Repository für jeden Kundenarbeitsbereich sicher auf Metadaten zu.
Der Hive-Metastore bietet ein weniger zentralisiertes Datengovernancemodell als Unity Catalog. Standardmäßig ermöglicht ein Cluster allen Benutzern den Zugriff auf alle Daten, die vom integrierten Hive-Metastore des Arbeitsbereichs verwaltet werden, es sei denn, die Tabellenzugriffssteuerung ist für diesen Cluster aktiviert. Weitere Informationen finden Sie unter Zugriffssteuerung für Hive-Metastore-Tabellen (Legacy).
Tabellenzugriffssteuerungen werden nicht auf Kontoebene gespeichert und müssen daher für jeden Arbeitsbereich separat konfiguriert werden. Um das von Unity Catalog bereitgestellte zentralisierte und optimierte Datengovernancemodell zu nutzen, empfiehlt Databricks, ein Upgrade für die Tabellen, die vom Hive-Metastore Ihres Arbeitsbereichs verwaltet werden, auf den Unity Catalog-Metastore durchzuführen.
Externer Hive-Metastore (Legacy): Sie können auch Ihren eigenen Metastore in Azure Databricks verwenden. Azure Databricks-Cluster können eine Verbindung mit vorhandenen externen Apache Hive-Metastores herstellen. Sie können die Tabellenzugriffssteuerung verwenden, um Berechtigungen in einem externen Metastore zu verwalten. Tabellenzugriffssteuerungen werden nicht im externen Metastore gespeichert und müssen daher für jeden Arbeitsbereich separat konfiguriert werden. Databricks empfiehlt, aus Gründen der Einfachheit und des kontozentrierten Governancemodells, stattdessen Unity Catalog zu verwenden.
Unabhängig vom verwendeten Metastore speichert Azure Databricks alle Tabellendaten im Objektspeicher in Ihrem Cloudkonto.
Was ist ein Katalog?
Beim Katalog handelt es sich um die höchste Abstraktionsebene im relationalen Modell des Databricks Lakehouse. Jede Datenbank wird einem Katalog zugeordnet. Kataloge sind in einem Metastore als Objekte vorhanden.
Bevor Unity Catalog eingeführt wurde, nutzte Azure Databricks einen zweistufigen Namespace. Kataloge entsprechen der dritten Stufe im Namespace-Modell von Unity Catalog:
catalog_name.database_name.table_name
Der integrierte Hive-Metastore unterstützt nur einen einzelnen Katalog: hive_metastore.
Was ist eine Datenbank?
Eine Datenbank ist eine Sammlung von Datenobjekten wie Tabellen oder Ansichten (auch „Beziehungen“ genannt) und Funktionen. In Azure Databricks werden die Begriffe „Schema“ und „Datenbank“ austauschbar verwendet, obgleich es sich in vielen relationalen Systemen bei einer Datenbank um eine Sammlung von Schemas handelt.
Datenbanken werden immer einem Speicherort im Cloudobjektspeicher zugeordnet. Sie können beim Registrieren einer Datenbank optional einen LOCATION angeben. Beachten Sie dabei Folgendes:
- Der einer Datenbank zugeordnete
LOCATIONwird immer als verwalteter Speicherort betrachtet. - Beim Erstellen einer Datenbank werden keine Dateien am Zielspeicherort erstellt.
- Der
LOCATIONeiner Datenbank bestimmt den Standardspeicherort für die Daten aller Tabellen, die in dieser Datenbank registriert sind. - Durch das erfolgreiche Ablegen einer Datenbank werden rekursiv alle Daten und Dateien abgelegt, die an einem verwalteten Speicherort gespeichert sind.
Diese Interaktion zwischen Speicherorten, die von Datenbank- und Datendateien verwaltet werden, ist sehr wichtig. So vermeiden Sie das unbeabsichtigte Löschen von Daten:
- Geben Sie keine Datenbankspeicherorte für mehrere Datenbankdefinitionen frei.
- Registrieren Sie keine Datenbank an einem Speicherort, der bereits Daten enthält.
- Um den Datenlebenszyklus unabhängig von der Datenbank zu verwalten, speichern Sie Daten an einem Speicherort, der nicht unter einem Datenbankspeicherort geschachtelt ist.
Was ist eine Tabelle?
Eine Azure Databricks-Tabelle ist eine Sammlung strukturierter Daten. Eine Delta-Tabelle speichert Daten als Datenverzeichnis im Cloudobjektspeicher und registriert Tabellenmetadaten im Metaspeicher innerhalb eines Katalogs und Schemas. Da Delta Lake der Standardspeicheranbieter für in Azure Databricks erstellte Tabellen ist, sind alle in Databricks erstellten Tabellen standardmäßig Delta-Tabellen. Da Delta-Tabellen Daten im Cloudobjektspeicher speichern und Verweise auf Daten über einen Metaspeicher bereitstellen, können Benutzer*innen überall in einer Organisation mithilfe ihrer bevorzugten APIs auf die Daten zugreifen. In Databricks umfasst dies SQL, Python, PySpark, Scala und R.
Beachten Sie, dass Sie auch andere Tabellen in Databricks erstellen können, bei denen es sich nicht um Delta-Tabellen handelt. Diese Tabellen werden nicht von Delta Lake unterstützt und bieten weder die ACID-Transaktionen noch die optimierte Leistung von Delta-Tabellen. Tabellen in dieser Kategorie umfassen Tabellen, die für Daten in externen Systemen und für andere Dateiformate im Data Lake registriert sind. Weitere Informationen finden Sie unter Herstellen von Verbindungen mit Datenquellen.
Es gibt zwei Arten von Tabellen in Databricks: verwaltete und nicht verwaltete (oder externe) Tabellen.
Hinweis
Die Unterscheidung von Delta Live Tables zwischen Livetabellen und Streaming-Livetabellen wird von Tabellenseite nicht erzwungen.
Was ist eine verwaltete Tabelle?
Azure Databricks verwaltet sowohl die Metadaten als auch die Daten für eine verwaltete Tabelle. Wenn Sie eine Tabelle ablegen, löschen Sie auch die zugrunde liegenden Daten. Data Analysts und andere Benutzer*innen, die hauptsächlich in SQL arbeiten, könnten dieses Verhalten bevorzugen. Verwaltete Tabellen sind beim Erstellen einer Tabelle der Standard. Die Daten für eine verwaltete Tabelle befinden sich im LOCATION der Datenbank, bei der sie registriert sind. Diese verwaltete Beziehung zwischen dem Datenspeicherort und der Datenbank bedeutet, dass Sie alle Daten an den neuen Speicherort schreiben müssen, wenn Sie eine verwaltete Tabelle in eine neue Datenbank verschieben.
Es gibt eine Reihe von Möglichkeiten zum Erstellen verwalteter Tabellen, zum Beispiel:
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name (field_name1 INT, field_name2 STRING)
df.write.saveAsTable("table_name")
Was ist eine nicht verwaltete Tabelle?
Azure Databricks verwaltet nur die Metadaten für nicht verwaltete (externe) Tabellen. Wenn Sie eine Tabelle ablegen, wirkt sich dies nicht auf die zugrunde liegenden Daten aus. Nicht verwaltete Tabellen geben während der Tabellenerstellung immer einen LOCATION an. Sie können entweder ein vorhandenes Verzeichnis mit Datendateien als Tabelle registrieren oder einen Pfad angeben, wenn zuerst eine Tabelle definiert wird. Da Daten und Metadaten unabhängig voneinander verwaltet werden, können Sie eine Tabelle umbenennen oder in einer neuen Datenbank registrieren, ohne Daten verschieben zu müssen. Data Engineers bevorzugen oft nicht verwaltete Tabellen und die Flexibilität, die diese für Produktionsdaten bieten.
Es gibt eine Reihe von Möglichkeiten zum Erstellen nicht verwalteter Tabellen, zum Beispiel:
CREATE TABLE table_name
USING DELTA
LOCATION '/path/to/existing/data'
CREATE TABLE table_name
(field_name1 INT, field_name2 STRING)
LOCATION '/path/to/empty/directory'
df.write.option("path", "/path/to/empty/directory").saveAsTable("table_name")
Was ist eine Ansicht?
Eine Ansicht speichert den Text für eine Abfrage, in der Regel für eine oder mehrere Datenquellen oder Tabellen im Metastore. In Databricks entspricht eine Ansicht einem Spark DataFrame, der als Objekt in einer Datenbank beibehalten wird. Im Gegensatz zu DataFrames können Sie Ansichten aus jedem beliebigen Teil des Databricks-Produkts abfragen, wenn Sie über die Berechtigung dazu verfügen. Beim Erstellen einer Ansicht werden keine Daten verarbeitet oder geschrieben. Nur der Abfragetext wird im Metastore in der zugeordneten Datenbank registriert.
Was ist eine temporäre Ansicht?
Eine temporäre Ansicht verfügt über eingeschränkten Umfang und eingeschränkte Persistenz und ist nicht in einem Schema oder Katalog registriert. Die Lebensdauer einer temporären Ansicht unterscheidet sich je nach der verwendeten Umgebung:
- In Notebooks und Aufträgen werden temporäre Ansichten auf der Notebook- oder Skriptebene festgelegt. Außerhalb des Notebooks, in dem sie deklariert sind, kann nicht auf sie verwiesen werden, wenn das Notebook vom Cluster getrennt wird, sind sie nicht mehr vorhanden.
- In Databricks SQL werden temporäre Ansichten auf der Abfrageebene festgelegt. Die temporäre Ansicht kann von mehreren Anweisungen innerhalb derselben Abfrage verwendet werden, in anderen Abfragen kann jedoch nicht darauf verwiesen werden, auch nicht auf demselben Dashboard.
- Globale temporäre Ansichten werden auf Clusterebene festgelegt und können zwischen Notebooks oder Aufträgen geteilt werden, die Computerressourcen gemeinsam nutzen. Databricks empfiehlt, Ansichten mit geeigneten Tabellen-ACLs anstelle von globalen temporären Ansichten zu verwenden.
Was ist eine Funktion?
Mit Funktionen können Sie benutzerdefinierte Logik einer Datenbank zuordnen. Funktionen können entweder Skalarwerte oder Gruppen von Zeilen zurückgeben. Funktionen werden zum Aggregieren von Daten verwendet. Azure Databricks ermöglicht es Ihnen, Funktionen je nach Ausführungskontext in verschiedenen Sprachen zu speichern, wobei SQL umfassend unterstützt wird. Mit Funktionen können Sie verwalteten Zugriff auf benutzerdefinierte Logik in verschiedenen Kontexten des Databricks-Produkts bereitstellen.
Wie funktionieren relationale Objekte in Delta Live Tables?
Delta Live Tables verwendet deklarative Syntax zum Definieren und Verwalten von DDL, DML und Infrastrukturbereitstellung. Delta Live Tables verwendet das Konzept eines „virtuellen Schemas“ beim Planen und Ausführen der Logik. Delta Live Tables kann mit anderen Datenbanken in Ihrer Databricksumgebung interagieren und Tabellen zum Abfragen an anderer Stelle veröffentlichen und beibehalten, indem eine Zieldatenbank in den Pipelinekonfigurationseinstellungen angegeben wird.
Alle in Delta Live Tables erstellte Tabellen sind Delta-Tabellen. Bei Verwendung von Unity Catalog mit Delta Live Tables sind alle Tabellen verwaltete Unity Catalog-Tabellen. Wenn Unity Catalog nicht aktiv ist, können Sie Tabellen entweder als verwaltete oder nicht verwaltete Tabellen deklarieren.
Während Ansichten in Delta Live Tables deklariert werden können, sollten diese als temporäre Ansichten betrachtet werden, die auf die Pipeline festgelegt sind. Temporäre Tabellen in Delta Live Tables sind ein einzigartiges Konzept: Diese Tabellen speichern Daten im Speicher, veröffentlichen jedoch keine Daten in der Zieldatenbank.
Einige Vorgänge, z. B. APPLY CHANGES INTO, registrieren sowohl eine Tabelle als auch eine Ansicht in der Datenbank. Der Tabellenname beginnt mit einem Unterstrich (_), und für die Ansicht wird der Tabellenname als Ziel des APPLY CHANGES INTO-Vorgangs deklariert. Die Ansicht fragt die entsprechende ausgeblendete Tabelle ab, um die Ergebnisse abzubilden.