MLOps-Workflows in Azure Databricks
In diesem Artikel wird beschrieben, wie Sie MLOps auf der Databricks-Plattform verwenden können, um die Leistung und langfristige Effizienz Ihrer Systeme für maschinelles Lernen (ML) zu optimieren. Der Artikel enthält allgemeine Empfehlungen für eine MLOps-Architektur und beschreibt einen generalisierten Workflow mithilfe der Databricks-Plattform, den Sie als Modell für Ihren ML-Prozess von der Entwicklung bis zum Produktivbetrieb verwenden können.
Weitere Details finden Sie im The Big Book of MLOps.
Was ist MLOps?
Der Begriff MLOps bezeichnet eine Reihe von Prozessen und automatisierten Schritten zum Verwalten von Code, Daten und Modellen. Die Prozesse vereinen DevOps, DataOps und ModelOps.
ML-Ressourcen wie Code, Daten und Modelle werden in Phasen entwickelt, die von frühen Entwicklungsphasen, für die keine strengen Zugriffsbeschränkungen gelten und die nicht streng getestet werden, über eine Zwischentestphase bis hin zu einer endgültigen Produktionsphase reichen, die streng kontrolliert wird. Mit der Databricks-Plattform können Sie diese Ressourcen auf einer einzigen Plattform mit einheitlicher Zugriffssteuerung verwalten. Sie können Datenanwendungen und ML-Anwendungen auf derselben Plattform entwickeln und so die Risiken und Verzögerungen verringern, die mit dem Verschieben von Daten verbunden sind.
Allgemeine Empfehlungen für MLOps
Dieser Abschnitt enthält einige allgemeine Empfehlungen für MLOps für Databricks mit Links für weitere Informationen.
Erstellen einer separaten Umgebung für jede Phase
Eine Ausführungsumgebung ist der Ort, an dem Modelle und Daten durch Code erstellt oder genutzt werden. Jede Ausführungsumgebung besteht aus Computeinstanzen, ihren Runtimes und Bibliotheken und automatisierten Aufträgen.
Databricks empfiehlt, separate Umgebungen für die verschiedenen Phasen von ML-Code- und Modellentwicklung mit klar definierten Übergängen zwischen den Phasen zu erstellen. Der in diesem Artikel beschriebene Workflow folgt diesem Prozess, wobei die allgemeinen Namen für die einzelnen Phasen verwendet werden:
Sie können auch andere Konfigurationen verwenden, damit die spezifischen Anforderungen Ihrer Organisation erfüllt werden.
Zugriffssteuerung und Versionsverwaltung
Zugriffssteuerung und Versionsverwaltung sind wichtige Komponenten aller Softwarebetriebsvorgänge. Databricks empfiehlt Folgendes:
- Verwenden Sie Git für die Versionskontrolle. Pipelines und Code sollten zum Zweck der Versionskontrolle in Git gespeichert werden. Das Verschieben der ML-Logik zwischen Phasen kann dann als Verschieben von Code aus dem Entwicklungsbranch in den Stagingbranch und dann in den Releasebranch interpretiert werden. Verwenden Sie Databricks-Git-Ordner, um die Integration mit Ihrem Git-Anbieter durchzuführen und Notebooks und Quellcode mit Databricks-Arbeitsbereichen zu synchronisieren. Databricks bietet außerdem zusätzliche Tools für Git-Integration und Versionskontrolle; siehe Tools und Anleitungen für Entwickler.
- Speichern Sie Daten in einer Lakehouse-Architektur mithilfe von Deltatabellen. Die Daten sollten in einer Lakehouse-Architektur in Ihrem Cloudkonto gespeichert werden. Sowohl Rohdaten als auch Featuretabellen sollten als Delta-Tabellen mit Zugriffskontrollen gespeichert werden, damit bestimmt werden kann, wer sie lesen und ändern darf.
- Verwalten Sie die Modellentwicklung mit MLflow. Sie können MLflow verwenden, um den Modellentwicklungsprozess nachzuverfolgen und Codemomentaufnahmen, Modellparameter, Metriken und andere Metadaten zu speichern.
- Verwenden Sie Modelle im Unity Catalog, um den Modelllebenszyklus zu verwalten. Verwenden Sie Modelle im Unity Catalog, um Modellversionen, Governance und Bereitstellungsstatus zu verwalten.
Bereitstellen von Code, nicht von Modellen
In den meisten Situationen empfiehlt Databricks, dass Sie während des ML-Entwicklungsprozesses Code statt Modelle von einer Umgebung in die nächste übertragen. Durch das dergestalt ausgeführte Verschieben von Projektressourcen wird sichergestellt, dass der gesamte Code im ML-Entwicklungsprozess dieselben Prozesse für Codeüberprüfung und Integrationstests durchläuft. Außerdem wird sichergestellt, dass die Produktionsversion des Modells mit Produktionscode trainiert wird. Ausführlichere Erläuterungen zu den Optionen und Einschränkungen finden Sie unter Modellimplementierungsmuster.
Empfohlener MLOps-Workflow
In den folgenden Abschnitten wird ein typischer MLOps-Workflow beschrieben, der jede der drei Phasen umfasst: Entwicklung, Staging und Produktion.
In diesem Abschnitt werden die Begriffe „Wissenschaftliche Fachkraft für Daten“ und „ML-Ingenieur“ als grundlegende Personas verwendet; bestimmte Rollen und Zuständigkeiten im MLOps-Workflow variieren zwischen Teams und Organisationen.
Entwicklungsphase
In der Entwicklungsphase liegt der Schwerpunkt auf Experimenten. Wissenschaftliche Fachkräfte für Daten entwickeln Features und Modelle und führen Experimente durch, um die Modellleistung zu optimieren. Die Ausgabe des Entwicklungsprozesses ist ML-Pipelinecode, der Featureberechnungen, Modellschulungen, Rückschlüsse und Überwachung umfassen kann.
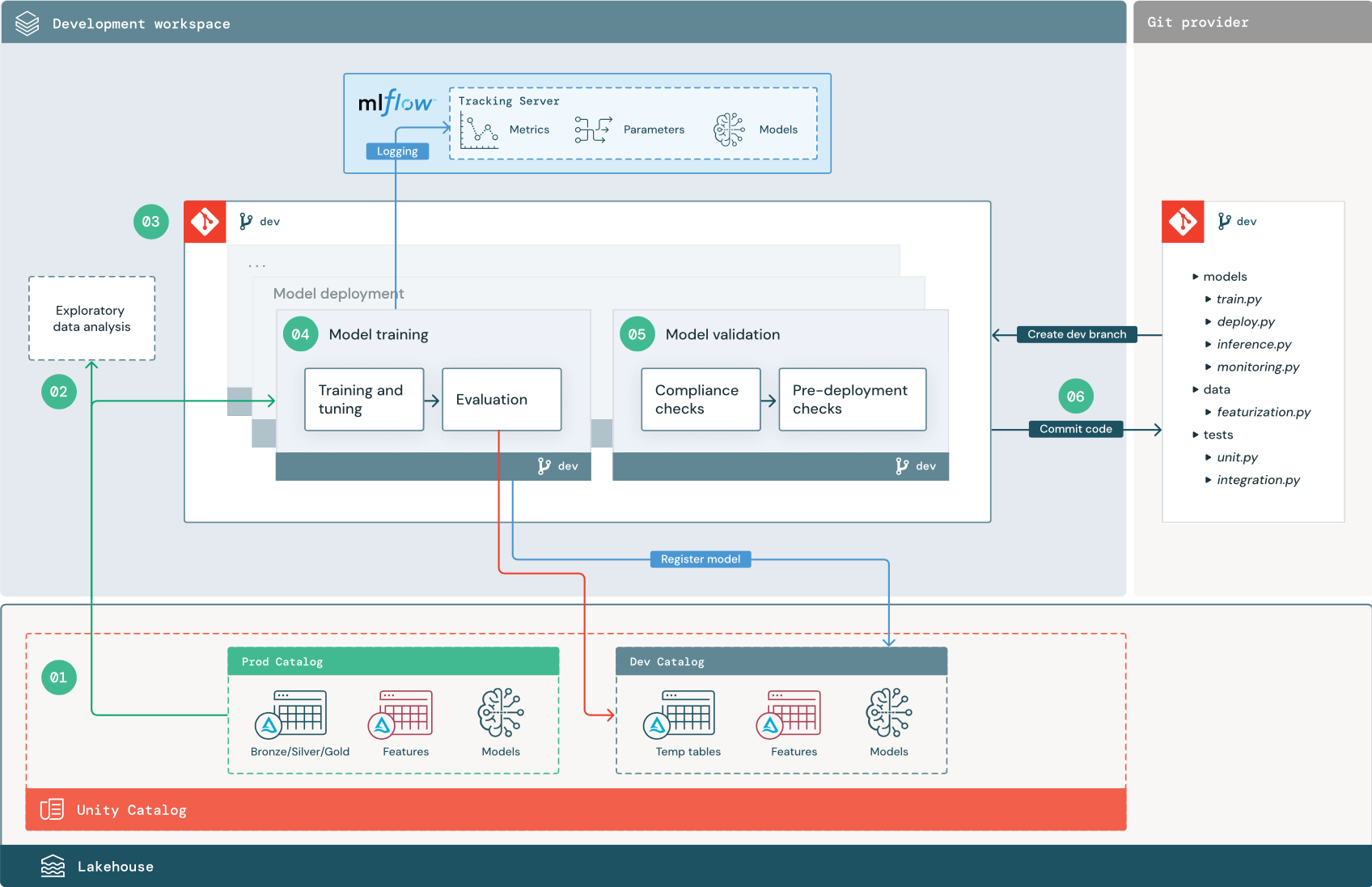
Die nummerierten Schritte entsprechen den Ziffern im Diagramm.
1. Datenquellen
Die Entwicklungsumgebung wird durch den Entwicklungskatalog im Unity Catalog dargestellt. Wissenschaftliche Fachkräfte für Daten haben Lese-/Schreibzugriff auf den Entwicklungskatalog, während sie temporäre Daten und Featuretabellen im Entwicklungsarbeitsbereich erstellen. Modelle, die in der Entwicklungsphase erstellt werden, werden im Entwicklungskatalog registriert.
Im Idealfall haben wissenschaftliche Fachkräfte für Daten, die im Entwicklungsarbeitsbereich arbeiten, auch schreibgeschützten Zugriff auf Produktionsdaten im Produktionskatalog. Wenn wissenschaftliche Fachkräfte für Daten Lesezugriff auf Produktionsdaten, Rückschlusstabellen und Metriktabellen im Produktionskatalog erhalten, können sie aktuelle Vorhersagen der Produktionsmodell und ihre Leistung analysieren. Wissenschaftliche Fachkräfte für Daten sollten auch in der Lage sein, Produktionsmodelle für Experimente und Analysen zu laden.
Wenn es nicht möglich ist, schreibgeschützten Zugriff auf den Produktionskatalog zuzuweisen, kann eine Momentaufnahme der Produktionsdaten in den Entwicklungskatalog geschrieben werden, damit wissenschaftliche Fachkräfte für Daten Projektcode entwickeln und auswerten können.
2. Explorative Datenanalyse (EDA)
Wissenschaftliche Fachkräfte für Daten untersuchen und analysieren Daten in einem interaktiven, iterativen Prozess mithilfe von Notebooks. Ziel ist es, zu beurteilen, ob die verfügbaren Daten das Potenzial haben, ein Geschäftsproblem zu lösen. In diesem Schritt beginnen die wissenschaftlichen Fachkräfte für Daten mit der Identifizierung von Datenaufbereitungs- und Featurierungsschritten für das Modelltraining. Dieser Ad-hoc-Prozess ist in der Regel nicht Teil einer Pipeline, die in anderen Ausführungsumgebungen bereitgestellt wird.
Databricks AutoML beschleunigt diesen Prozess durch Generieren von Baselinemodellen für ein Dataset. AutoML führt eine Reihe von Tests aus, zeichnet diese auf und stellt ein Python-Notebook mit dem Quellcode für jede Testausführung bereit, sodass Sie den Code überprüfen, reproduzieren und ändern können. Darüber hinaus werden von AutoML auch zusammenfassende Statistiken für Ihr Dataset berechnet. Diese Informationen werden in einem Notebook gespeichert, das Sie dann überprüfen können.
3. Code
Das Coderepository enthält alle Pipelines, Module und sonstigen Projektdateien für ein ML-Projekt. Wissenschaftliche Fachkräfte für Daten erstellen neue oder aktualisierte Pipelines in einem Entwicklungsbranch („dev“) des Projektrepositorys. Ab EDA und den ersten Phasen eines Projekts sollten wissenschaftliche Fachkräfte für Daten in einem Repository arbeiten, um Code freigeben und Änderungen nachverfolgen zu können.
4. Trainieren des Modells (Entwicklung)
Wissenschaftliche Fachkräfte für Daten entwickeln eine Pipeline für das Modelltraining in der Entwicklungsumgebung mithilfe von Tabellen aus den Entwicklungs- oder Produktionskatalogen.
Diese Pipeline umfasst zwei Aufgaben:
Training und Optimierung. Beim Trainieren werden Modellparameter, Metriken und Artefakte auf dem MLflow-Nachverfolgungsserver protokolliert. Nach dem Training und der Optimierung von Hyperparametern wird das endgültige Modellartefakt auf dem Nachverfolgungsserver protokolliert, um eine Verknüpfung zwischen dem Modell, den Eingabedaten, mit denen es trainiert wurde, und dem Code, mit dem es generiert wurde, festzuhalten.
Auswertung. Bewerten Sie die Modellqualität, indem Sie die verfügbar gemachten Daten testen. Die Ergebnisse dieser Tests werden auf dem MLflow-Nachverfolgungsserver protokolliert. Der Zweck der Auswertung besteht darin festzustellen, ob das neu entwickelte Modell besser als das aktuelle Produktionsmodell funktioniert. Mit ausreichenden Berechtigungen kann jedes im Produktionskatalog registrierte Produktionsmodell in den Entwicklungsarbeitsbereich geladen und mit einem neu trainierten Modell verglichen werden.
Wenn die Governance-Anforderungen Ihrer Organisation zusätzliche Informationen zum Modell enthalten, können Sie diese mithilfe von MLflow-Tracking speichern. Typische Artefakte sind Nur-Text-Beschreibungen und Modellinterpretationen, z. B. die von SHAP generierten Plots. Bestimmte Governanceanforderungen können von einem Data Governance Officer oder Projektbeteiligten stammen.
Die Ausgabe der Pipeline für das Modelltraining ist ein ML-Modellartefakt, das auf dem MLflow-Nachverfolgungsserver für die Entwicklungsumgebung gespeichert ist. Wenn die Ausführung der Pipeline im Staging- oder Produktionsarbeitsbereich erfolgt, wird das Modellartefakt auf dem MLflow-Nachverfolgungsserver für diesen Arbeitsbereich gespeichert.
Wenn das Modelltraining abgeschlossen ist, registrieren Sie das Modell im Unity Catalog. Richten Sie Ihren Pipelinecode ein, um das Modell im Katalog der Umgebung zu registrieren, in der die Modellpipeline ausgeführt wurde – in diesem Beispiel im Entwicklungskatalog.
Mit der empfohlenen Architektur stellen Sie einen Databricks-Workflow mit mehreren Aufgaben bereit, in dem die erste Aufgabe die Pipeline für das Modelltraining ist, auf die Aufgaben für Modellüberprüfung und Modellimplementierung folgen. Die Modelltrainingsaufgabe liefert einen Modell-URI, der für die Modellüberprüfungsaufgabe verwendet werden kann. Sie können Aufgabenwerte verwenden, um diesen URI an das Modell zu übergeben.
5. Validieren und Bereitstellen des Modells (Entwicklung)
Neben der Pipeline für das Modelltraining werden weitere Pipelines (z. B. für Modellüberprüfung und Modellimplementierung) in der Entwicklungsumgebung entwickelt.
Modellüberprüfung. Die Modellüberprüfungspipeline verwendet den Modell-URI aus der Modelltrainingspipeline, lädt das Modell aus dem Unity Catalog und führt die Validierungen durch.
Die Überprüfungsschritte hängen vom Kontext ab. Sie können grundlegende Prüfungen wie das Bestätigen des Formats und der erforderlichen Metadaten, aber auch komplexere Prüfungen umfassen, die für stark regulierte Branchen erforderlich sein können, z. B. vordefinierte Complianceprüfungen und die Überprüfung der Modellleistung für ausgewählte Datensegmente.
Die Modellüberprüfungspipeline dient hauptsächlich zur Bestimmung, ob ein Modell in den Bereitstellungsschritt übertragen werden kann. Wenn das Modell die Überprüfungen vor der Bereitstellung besteht, kann es dem Alias „Challenger“ im Unity Catalog zugewiesen werden. Wenn die Überprüfungen zu Fehlern führen, wird der Prozess beendet. Sie können Ihren Workflow so konfigurieren, dass Benutzer*innen über Überprüfungsfehler benachrichtigt werden. Weitere Informationen finden Sie unter Hinzufügen von E-Mail- und Systembenachrichtigungen für Auftragsereignisse.
Modellimplementierung. Die Modellimplementierungspipeline stuft in der Regel entweder das neu trainierte „Challenger“-Modell über ein Aliasupdate auf „Champion“-Status hoch, oder es liefert einen Vergleich zwischen dem vorhandenen „Champion“-Modell und dem neuen „Challenger“-Modell. Diese Pipeline kann auch die erforderliche Rückschlussinfrastruktur einrichten, z. B. Model Serving-Endpunkte. Eine ausführliche Erläuterung der Schritte in der Modellimplementierungspipeline finden Sie unter Produktion.
6. Committen von Code
Nach der Entwicklung von Code für Pipelines für Training, Validierung, Bereitstellung sowie für andere Pipelines committet eine wissenschaftliche Fachkraft für Daten oder eine technische Fachkraft für maschinelles Lernen die im Entwicklungsbranch vorgenommenen Änderungen in die Quellcodeverwaltung.
Stagingphase
Der Fokus dieser Phase besteht darin, den ML-Pipelinecode zu testen und dadurch sicherzustellen, dass er für die Produktion bereit ist. Der gesamte ML-Pipelinecode wird in dieser Phase getestet, einschließlich Code für Pipelines u. a. für Modelltraining, Feature Engineering und Rückschluss.
ML-Ingenieure erstellen eine CI-Pipeline, um die in dieser Phase ausgeführten Komponenten- und Integrationstests zu implementieren. Die Ausgabe des Stagingprozesses ist ein Releasebranch, über den das CI/CD-System ausgelöst wird, sodass die Produktionsphase gestartet wird.
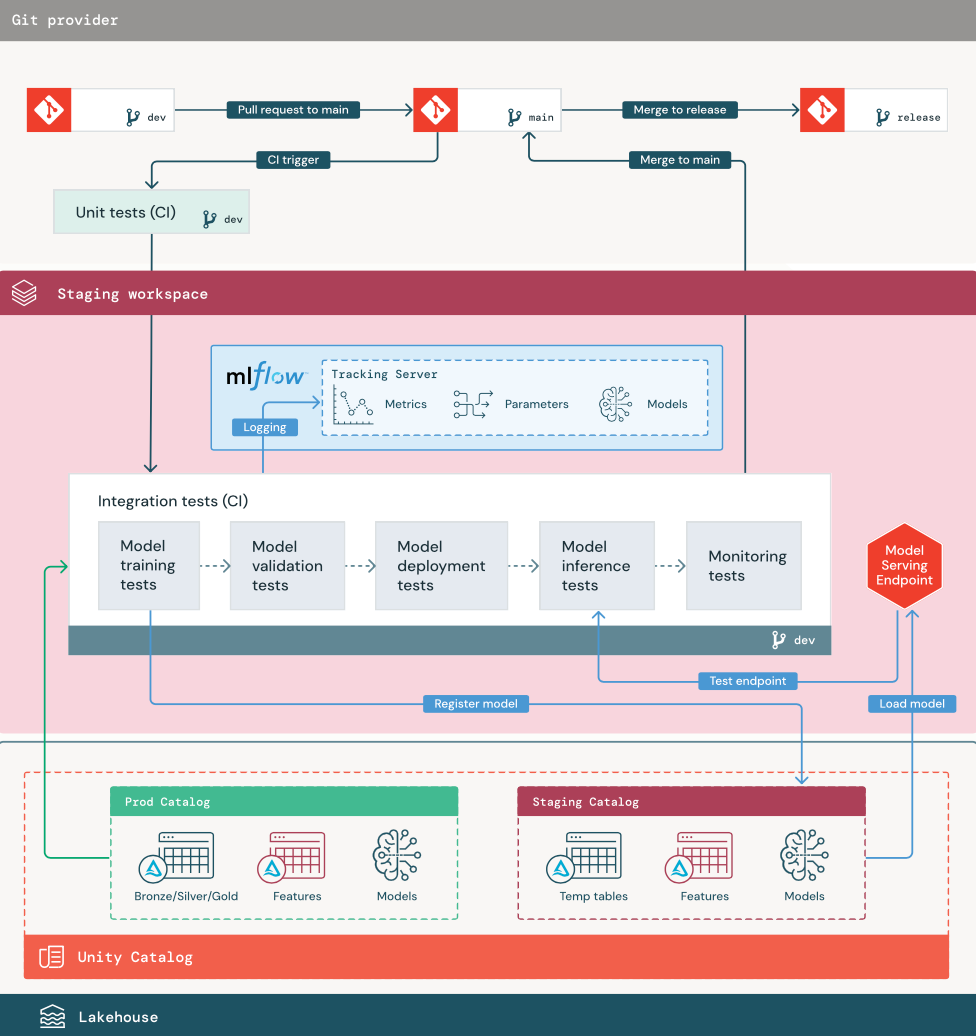
1. Daten
Die Stagingumgebung sollte über einen eigenen Katalog im Unity Catalog verfügen, um ML-Pipelines zu testen und Modelle im Unity Catalog zu registrieren. Dieser Katalog wird im Diagramm als „Staging“-Katalog bezeichnet. Ressourcen, die in diesen Katalog geschrieben werden, sind im Allgemeinen temporär und werden nur bis zum Abschluss aller Tests aufbewahrt. Die Entwicklungsumgebung kann für Debuggingzwecke auch Zugriff auf den Stagingkatalog erfordern.
2. Zusammenführen von Code
Wissenschaftliche Fachkräfte für Daten entwickeln eine Pipeline für das Modelltraining in der Entwicklungsumgebung mithilfe von Tabellen aus den Entwicklungs- oder Produktionskatalogen.
Ein Pull Request Der Bereitstellungsprozess beginnt, wenn in der Quellcodeverwaltung ein Pull Request für den Mainbranch des Projekts erstellt wird.
Komponententests. Der Pull Request erstellt automatisch Quellcode und löst Komponententests aus. Bei Fehlern in den Komponententests wird der Pull Request abgelehnt.
Komponententests sind Teil des Softwareentwicklungsprozesses und werden während der Entwicklung von Code kontinuierlich ausgeführt und der Codebasis hinzugefügt. Durch das Ausführen von Komponententests als Teil einer CI-Pipeline wird sichergestellt, dass Änderungen, die in einem Entwicklungsbranch vorgenommen wurden, nicht zu Fehlern bei vorhandenen Funktionen führen.
3. Integrationstests (CI)
Vom CI-Prozess werden dann die Integrationstests ausgeführt. Bei Integrationstests werden alle Pipelines ausgeführt (einschließlich Feature Engineering, Modelltraining, Rückschluss und Überwachung), damit sichergestellt ist, dass sie zusammen ordnungsgemäß funktionieren. Die Stagingumgebung sollte der Produktionsumgebung so genau entsprechen, wie es sinnvoll ist.
Wenn Sie eine Anwendung für maschinelles Lernen mit Echtzeitrückschlüssen bereitstellen, sollten Sie die dafür erforderliche Infrastruktur in der Stagingumgebung erstellen und testen. Dies umfasst das Auslösen der Modellimplementierungspipeline, die einen Endpunkt in der Stagingumgebung erstellt und ein Modell lädt.
Zur Verringerung der Zeit, die zum Ausführen von Integrationstests erforderlich ist, können bei einigen Schritten Kompromisse zwischen Genauigkeit der Tests und Geschwindigkeit eingegangen werden. Wenn das Trainieren einiger Modelle z. B. arbeits- oder zeitaufwendig ist, können Sie kleine Teilmengen der Daten verwenden oder weniger Trainingsiterationen ausführen. Für die Modellbereitstellung können Sie abhängig von den Produktionsanforderungen in Integrationstests vollständige Auslastungstests durchführen oder nur kleine Batchaufträge oder Anforderungen an einen temporären Endpunkt testen.
4. Zusammenführen im Stagingbranch
Wenn alle Tests bestanden werden, wird der neue Code mit dem Mainbranch des Projekts zusammengeführt. Bei Testfehlern, sollten die Benutzer*innen vom CI/CD-System benachrichtigt werden, und die Ergebnisse sollten im Pull Request veröffentlicht werden.
Sie können regelmäßige Integrationstests für den Mainbranch planen. Dies ist empfehlenswert, wenn ein Branch häufig mit gleichzeitigen Pull Requests von mehreren Benutzer*innen aktualisiert wird.
5. Erstellen eines Releasebranch
Nachdem CI-Tests bestanden und der Entwicklungsbranch in den Mainbranch zusammengeführt wurde, erstellt die technische Fachkraft für maschinelles Lernen einen Releasebranch, der das Aktualisieren von Produktionsaufträgen durch das CI/CD-System auslöst.
Produktionsstufe
Technische Fachkräfte für maschinelles Lernen besitzen die Produktionsumgebung, in der ML-Pipelines bereitgestellt und ausgeführt werden. Diese Pipelines lösen das Modelltraining aus, validieren und implementieren neue Modellversionen, veröffentlichen Vorhersagen in nachgelagerten Tabellen oder Anwendungen und überwachen den gesamten Prozess, um Leistungsbeeinträchtigungen und Instabilität zu vermeiden.
Wissenschaftliche Fachkräfte für Daten haben in der Regel keinen Schreib- oder Berechnungszugriff in der Produktionsumgebung. Es ist jedoch wichtig, dass sie Testergebnisse, Protokolle, Modellartefakte, Produktionspipelinestatus und Überwachungstabellen einsehen können. Diese Sichtbarkeit ermöglicht ihnen, Probleme in der Produktion zu identifizieren und zu diagnostizieren und die Leistung neuer Modelle mit Modellen zu vergleichen, die derzeit in der Produktion verwendet werden. Sie können wissenschaftlichen Fachkräften für Daten für diese Zwecke schreibgeschützten Zugriff auf Ressourcen im Produktionskatalog zuweisen.
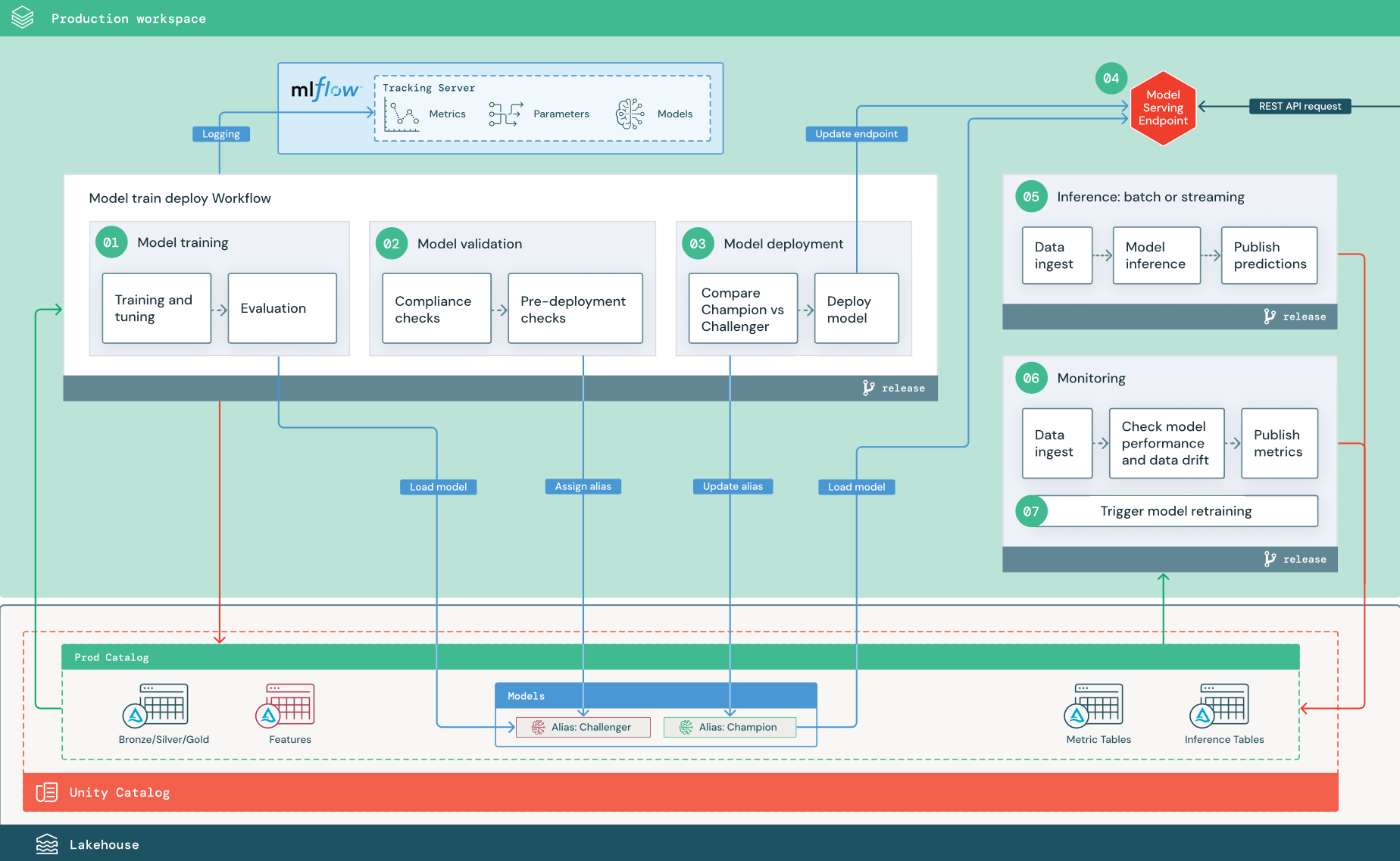
Die nummerierten Schritte entsprechen den Ziffern im Diagramm.
1. Trainieren des Modells
Diese Pipeline kann durch Codeänderungen oder durch automatisierte Aufträge für erneute Trainings ausgelöst werden. In diesem Schritt werden Tabellen aus dem Produktionskatalog für die folgenden Schritte verwendet.
Training und Optimierung. Während des Trainings werden Protokolle auf dem MLflow-Nachverfolgungsserver der Produktionsumgebung aufgezeichnet. Dazu gehören Modellmetriken, -parameter und -tags sowie das Modell selbst. Wenn Sie Featuretabellen verwenden, wird das Modell mit dem Databricks Feature Store-Client in MLflow protokolliert, der das Modell mit Lookupinformationen zum Feature packt, die zur Rückschlusszeit verwendet wurden.
Während der Entwicklung können wissenschaftliche Fachkräfte für Daten viele Algorithmen und Hyperparameter testen. Im Produktionstrainingscode ist es üblich, nur die wichtigsten Optionen zu berücksichtigen. Diese Einschränkung der Optimierung spart Zeit und kann die optimierungsbedingte Varianz in automatisierten erneuten Trainings reduzieren.
Wenn wissenschaftliche Fachkräfte für Daten schreibgeschützten Zugriff auf den Produktionskatalog haben, können sie möglicherweise die optimalen Hyperparameter für ein Modell ermitteln. In diesem Fall kann die in der Produktion bereitgestellte Modelltrainingspipeline mithilfe der ausgewählten Hyperparameter ausgeführt werden, die in der Regel als Konfigurationsdatei in der Pipeline enthalten sind.
Auswertung. Die Modellqualität wird durch Tests verfügbar gemachter Produktionsdaten ausgewertet. Die Ergebnisse dieser Tests werden auf dem MLflow-Überwachungsserver protokolliert. In diesem Schritt werden die Auswertungsmetriken verwendet, die von wissenschaftlichen Fachkräften für Daten in der Entwicklungsphase angegeben werden. Diese Metriken können benutzerdefinierten Code enthalten.
Registrieren des Modells Wenn das Modelltraining abgeschlossen ist, wird das Modellartefakt als registrierte Modellversion im angegebenen Modellpfad im Produktionskatalog von Unity Catalog gespeichert. Die Modelltrainingsaufgabe liefert einen Modell-URI, der für die Modellüberprüfungsaufgabe verwendet werden kann. Sie können Aufgabenwerte verwenden, um diesen URI an das Modell zu übergeben.
2. Überprüfen des Modells
Diese Pipeline verwendet den Modell-URI aus Schritt 1 und lädt das Modell aus dem Unity Catalog. Anschließend werden verschiedene Überprüfungen ausgeführt. Diese Prüfungen hängen von Ihrer Organisation und dem Anwendungsfall ab und können Elemente wie grundlegende Format- und Metadatenüberprüfungen, Leistungsbewertungen für ausgewählte Datensegmente und die Einhaltung von Organisationsanforderungen wie Complianceprüfungen für Tags oder Dokumentation umfassen.
Wenn das Modell alle Überprüfungen erfolgreich bestanden hat, können Sie der Modellversion im Unity Catalog den Alias „Challenger“ zuweisen. Wenn das Modell nicht alle Überprüfungen besteht, wird der Prozess beendet. Sie können in diesem Fall die Benutzer*innen automatisch benachrichtigen lassen. Sie können Tags verwenden, um abhängig vom Ergebnis dieser Überprüfungen Schlüssel-Wert-Attribute hinzuzufügen. Sie können z. B. das Tag „model_validation_status“ erstellen und den Wert während der Tests auf „PENDING“ festlegen. Nach Abschluss der Pipeline kann es dann in „PASSED“ oder „FAILED“ geändert werden.
Da das Modell im Unity Catalog registriert ist, können wissenschaftliche Fachkräfte für Daten, die in der Entwicklungsumgebung arbeiten, diese Modellversion aus dem Produktionskatalog laden, um zu untersuchen, ob die Validierung des Modells Fehler offenbart. Unabhängig vom Ergebnis werden die Ergebnisse im Produktionskatalog mithilfe von Anmerkungen zur Modellversion im registrierten Modell aufgezeichnet.
3. Bereitstellen des Modells
Wie bei der Überprüfungspipeline hängt die Modellimplementierungspipeline von Ihrer Organisation und dem Anwendungsfall ab. In diesem Abschnitt wird davon ausgegangen, dass Sie dem neu überprüften Modell den Alias „Challenger“ zugewiesen haben und dass das vorhandene Produktionsmodell den Alias „Champion“ hat. Der erste Schritt vor der Implementierung des neuen Modells besteht darin zu bestätigen, dass es mindestens genauso gut wie das aktuelle Produktionsmodell ist.
Vergleichen Sie das „Challenger“- mit dem „Champion“-Modell. Sie können diesen Vergleich offline oder online durchführen. Bei einem Offlinevergleich werden beide Modelle mit einem bereitgestellten Dataset ausgeführt und die Ergebnisse mithilfe des MLflow-Nachverfolgungsservers erfasst. Für die Echtzeitmodellimplementierung sollten Sie längere Onlinevergleiche durchführen, z. B. A/B-Tests oder einen schrittweisen Rollout des neuen Modells. Wenn die Modellversion „Challenger“ im Vergleich besser funktioniert, ersetzt sie den aktuellen „Champion“-Alias.
Databricks Model Serving und Databricks Lakehouse Monitoring ermöglichen Ihnen, Rückschlusstabellen, die Anforderungs- und Antwortdaten für einen Endpunkt enthalten, automatisch zu sammeln und zu überwachen.
Wenn kein „Champion“-Modell vorhanden ist, können Sie das „Challenger“-Modell mit einem heuristischen Geschäftswert oder einem anderen Schwellenwert als Baseline vergleichen.
Der hier beschriebene Prozess läuft vollständig automatisiert ab. Wenn manuelle Genehmigungsschritte erforderlich sind, können Sie diese mithilfe von Workflowbenachrichtigungen oder CI/CD-Rückrufen aus der Modellimplementierungspipeline einrichten.
Stellen Sie das Modell bereit. Batch- oder Streaming-Rückschlusspipelines können so eingerichtet werden, dass das Modell mit dem Alias „Champion“ verwendet wird. Für Echtzeit-Anwendungsfälle müssen Sie eine Infrastruktur einrichten, um das Modell als REST-API-Endpunkt bereitzustellen. Sie können diesen Endpunkt mithilfe von Databricks Model Serving erstellen und verwalten. Wenn bereits ein Endpunkt für das aktuelle Modell verwendet wird, können Sie den Endpunkt mit dem neuen Modell aktualisieren. Databricks Model Serving führt ein Update ohne Downtime durch, indem die vorhandene Konfiguration weiter ausgeführt wird, bis die neue bereit ist.
4. Modellbereitstellung
Beim Konfigurieren eines Model Serving-Endpunkts geben Sie den Namen des Modells im Unity Catalog und die zu unterstützende Version an. Wenn die Modellversion mithilfe von Features aus Tabellen im Unity Catalog trainiert wurde, werden im Modell auch die Abhängigkeiten für die Features und Funktionen gespeichert. Model Serving verwendet dieses Abhängigkeitsdiagramm automatisch, um bei Rückschlüssen Features in den entsprechenden Onlinespeichern nachzuschlagen. Dieser Ansatz kann auch zum Anwenden von Funktionen für die Datenvoraufbereitung oder zum Berechnen von On-Demand-Features während der Modellauswertung verwendet werden.
Sie können einen einzelnen Endpunkt mit mehreren Modellen erstellen und den Endpunktdatenverkehr zwischen diesen Modellen aufteilen, sodass Sie Vergleiche zwischen „Champion“- und „Challenger“-Version online durchführen können.
5. Rückschluss: Batch oder Streaming
Die Rückschlusspipeline liest die neuesten Daten aus dem Produktionskatalog, führt Funktionen zum Berechnen von On-Demand-Features aus, lädt das „Champion“-Modell, bewertet die Daten und gibt Vorhersagen zurück. Batch- oder Streamingrückschlüsse sind im Allgemeinen die kostengünstigste Option für Anwendungsfälle mit höherem Durchsatz und höherer Latenz. Bei Szenarien, in denen Vorhersagen mit geringer Latenz erforderlich sind, die aber offline berechnet werden können, ist es möglich, diese Batchvorhersagen in einem Onlinespeicher wie DynamoDB oder Cosmos DB als Schlüssel-Wert-Paare zu veröffentlichen.
Auf das registrierte Modell im Unity Catalog wird anhand seines Alias verwiesen. Die Rückschlusspipeline ist so konfiguriert, dass die „Champion“-Modellversion geladen und angewandt wird. Wenn die „Champion“-Version auf eine neue Modellversion aktualisiert wird, verwendet die Rückschlusspipeline bei der nächsten Ausführung automatisch die neue Version. Auf diese Weise wird der Modellimplementierungsschritt von Rückschlusspipelines entkoppelt.
Batchaufträge veröffentlichen in der Regel Vorhersagen in Tabellen im Produktionskatalog, in Flatfiles oder über eine JDBC-Verbindung. Bei Streamingaufträgen werden Vorhersagen in der Regel in Unity Catalog-Tabellen oder in Nachrichtenwarteschlangen wie Apache Kafka veröffentlicht.
6. Lakehouse Monitoring
Lakehouse Monitoring überwacht statistische Eigenschaften wie Datendrift und Modellleistung von Eingabedaten und Modellvorhersagen. Sie können Benachrichtigungen basierend auf diesen Metriken erstellen oder sie in Dashboards veröffentlichen.
- Datenerfassung. Diese Pipeline liest in Protokollen aus Batch-, Streaming- oder Onlinerückschlüssen.
- Überprüfen Sie Genauigkeit und Datendrift. Die Pipeline berechnet Metriken zu den Eingabedaten, den Vorhersagen des Modells und der Infrastrukturleistung. Wissenschaftliche Fachkräfte für Daten geben Daten- und Modellmetriken während der Entwicklung an, und ML-Ingenieure geben Infrastrukturmetriken an. Sie können mit Lakehouse Monitoring auch benutzerdefinierte Metriken definieren.
- Veröffentlichen Sie Metriken, und richten Sie Warnungen ein. Die Pipeline schreibt zur Analyse und Berichterstellung in Tabellen im Produktionskatalog. Sie sollten diese Tabellen so konfigurieren, dass sie aus der Entwicklungsumgebung lesbar sind, damit wissenschaftliche Fachkräfte für Daten zu Analysezwecken darauf zugreifen können. Sie können Databricks SQL verwenden, um Überwachungsdashboards zum Nachverfolgen der Modellleistung zu erstellen und den Überwachungsauftrag oder das Dashboardtool einzurichten, um eine Benachrichtigung auszugeben, wenn eine Metrik einen angegebenen Schwellenwert überschreitet.
- Lösen Sie das erneute Modelltraining aus. Wenn Überwachungsmetriken auf Leistungsprobleme oder Änderungen in den Eingabedaten hindeuten, müssen die wissenschaftlichen Fachkräfte für Daten möglicherweise eine neue Modellversion entwickeln. Sie können SQL-Benachrichtigungen einrichten, um wissenschaftliche Fachkräfte für Daten in einem solchen Fall zu benachrichtigen.
7. Erneutes Training
Diese Architektur unterstützt das automatische erneute Trainieren mithilfe derselben Modelltrainingspipeline wie oben. Databricks empfiehlt, das erneute Training regelmäßig und nach einem Zeitplan durchzuführen und nur bei Bedarf direkt auszulösen.
- Geplant: Wenn regelmäßig neue Daten verfügbar sind, können Sie einen geplanten Auftrag erstellen, um den Modelltrainingscode mit den neuesten verfügbaren Daten auszuführen.
- Ausgelöst. Wenn die Überwachungspipeline Probleme bei der Modellleistung identifizieren und Warnungen senden kann, kann sie auch das erneute Trainieren auslösen. Wenn sich beispielsweise die Verteilung eingehender Daten signifikant ändert oder die Modellleistung beeinträchtigt wird, können Sie durch das automatische erneute Trainieren und die erneute Bereitstellung die Modellleistung mit minimalem menschlichem Eingriff steigern. Dies kann durch eine SQL-Warnung erreicht werden, für die überprüft wird, ob eine Metrik abweicht (z. B. durch Überprüfung auf Datendrift oder den Vergleich der Modellqualität mit einem Schwellenwert). Die Warnung kann für die Verwendung eines Webhookziels konfiguriert werden, der anschließend den Trainingsworkflow auslösen kann.
Wenn die Pipeline für das erneute Trainieren oder andere Pipelines Leistungsprobleme aufweisen, müssen die wissenschaftlichen Fachkräfte für Daten möglicherweise zur Entwicklungsumgebung zurückkehren, um die Probleme durch weitere Experimente zu beheben.