Februar 2019
Diese Features und Azure Databricks-Plattformverbesserungen wurden im Februar 2019 veröffentlicht.
Hinweis
Releases werden gestaffelt. Ihr Azure Databricks-Konto wird möglicherweise erst eine Woche nach dem Datum der ersten Veröffentlichung aktualisiert.
Databricks Light allgemein verfügbar
26. Februar bis 5. März 2019: Version 2.92
Databricks Light (auch als „Data Engineering Light“ bekannt) ist nun verfügbar. Databricks Light ist das Azure Databricks-Paket der Open-Source-Runtime von Apache Spark. Es bietet eine Runtimeoption für Aufträge, die ohne die Vorteile der erweiterten Leistung, Zuverlässigkeit oder automatischen Skalierung auskommen, die Databricks Runtime bietet. Databricks Light kann nur verwendet werden, wenn Sie einen Cluster zum Ausführen eines JAR-, Python- oder spark-submit-Auftrags erstellen. Für Cluster, in denen Sie Workloads für interaktive oder Notebookaufträge ausführen, steht diese Runtime nicht zur Verfügung. Weitere Informationen finden Sie unter Databricks Light.
Verwalteter MLflow für Azure Databricks (Public Preview)
26. Februar bis 5. März 2019: Version 2.92
MLflow ist eine Open-Source-Plattform für die Verwaltung des gesamten Machine Learning-Lebenszyklus. Sie hat drei Hauptfunktionen:
- Das Nachverfolgen von Experimenten zum Aufzeichnen und Vergleichen von Parametern und Ergebnissen
- Das Verwalten und Bereitstellen von Modellen aus einer Vielzahl von ML-Bibliotheken auf einer Vielzahl von Modellplattformen zum Bereitstellen und Rückschließen
- Das Packen von ML-Code in ein wiederverwendbares, reproduzierbares Format, das mit anderen Data Scientists ausgetauscht oder in die Produktion weitergeleitet werden kann
Azure Databricks bietet nun eine vollständig verwaltete und gehostete Version von MLflow, die mit Features für Unternehmenssicherheit, Hochverfügbarkeit und weitere Azure Databricks-Arbeitsbereichsfeatures wie der Verwaltung von Experimenten und Ausführungen sowie der Erfassung von Notebookrevisionen integriert ist. MLflow in Azure Databricks bietet eine integrierte Oberfläche, über die die Trainingsläufe von Machine Learning-Modellen in einer sicheren Umgebung nachverfolgt und Machine Learning-Projekte ausgeführt werden können. Durch die Verwendung der verwalteten MLflow-Plattform auf Azure Databricks profitieren Sie von den Vorteilen beider Plattformen. Dazu gehören folgende Features:
- Arbeitsbereiche: Sie können Experimente und Ergebnisse in Azure Databricks-Arbeitsbereichen, die über einen gehosteten MLflow-Nachverfolgungsserver und eine integrierte Benutzeroberfläche für Experimente verfügen, gemeinsam nachverfolgen und organisieren. Wenn Sie MLflow in Notebooks verwenden, erfasst Azure Databricks automatisch Notebookrevisionen, sodass Sie den gleichen Code und die gleichen Ausführungen später reproduzieren können.
- Sicherheit: Nutzen Sie über ACLs ein einheitliches Sicherheitsmodell für den gesamten ML-Lebenszyklus.
- Aufträge: Führen Sie MLflow-Projekte als Azure Databricks-Aufträge remote und direkt aus Azure Databricks-Notebooks aus.
Hier finden Sie eine Demonstration der Nachverfolgung eines Workflows in einem Azure Databricks-Arbeitsbereich.
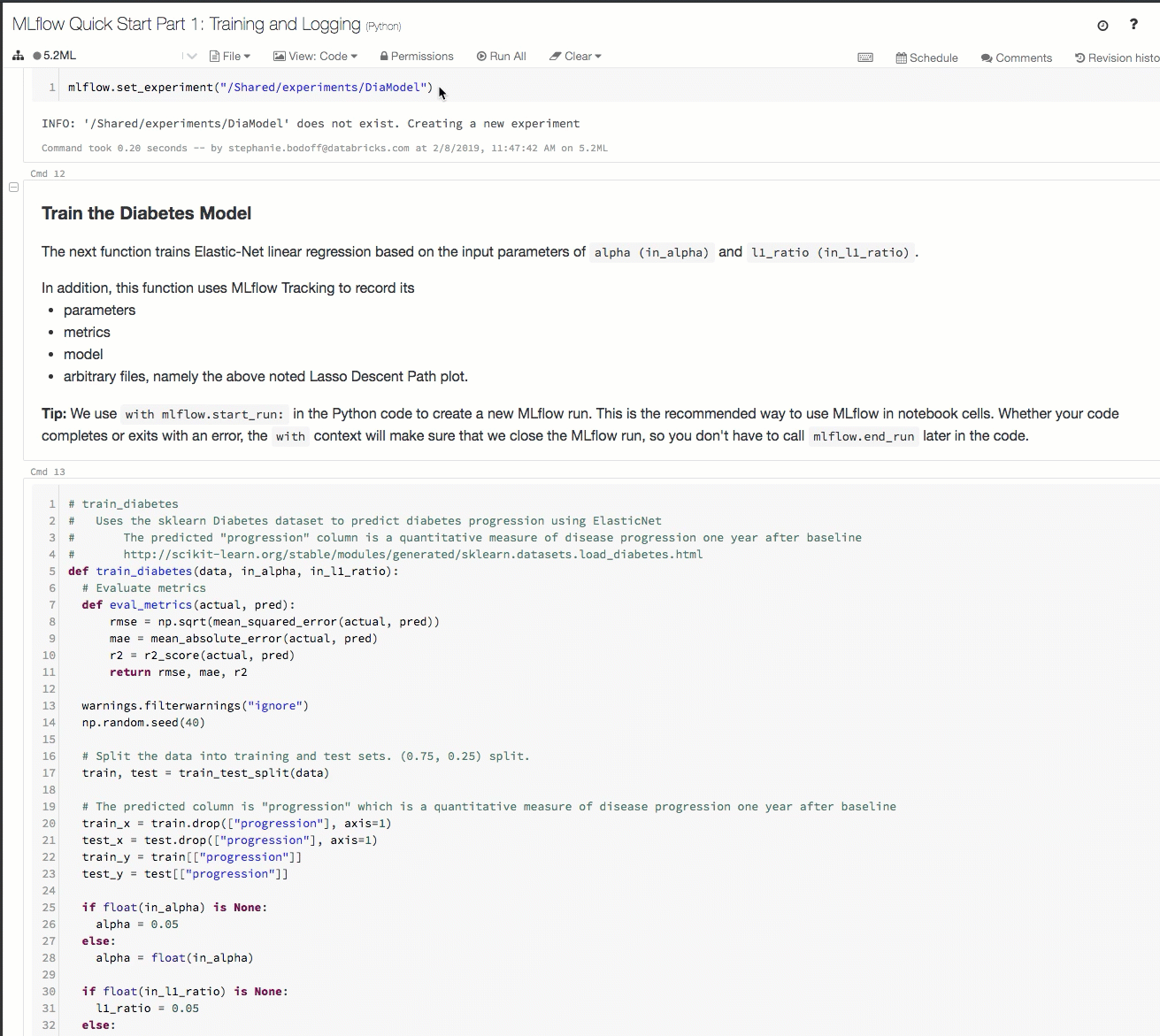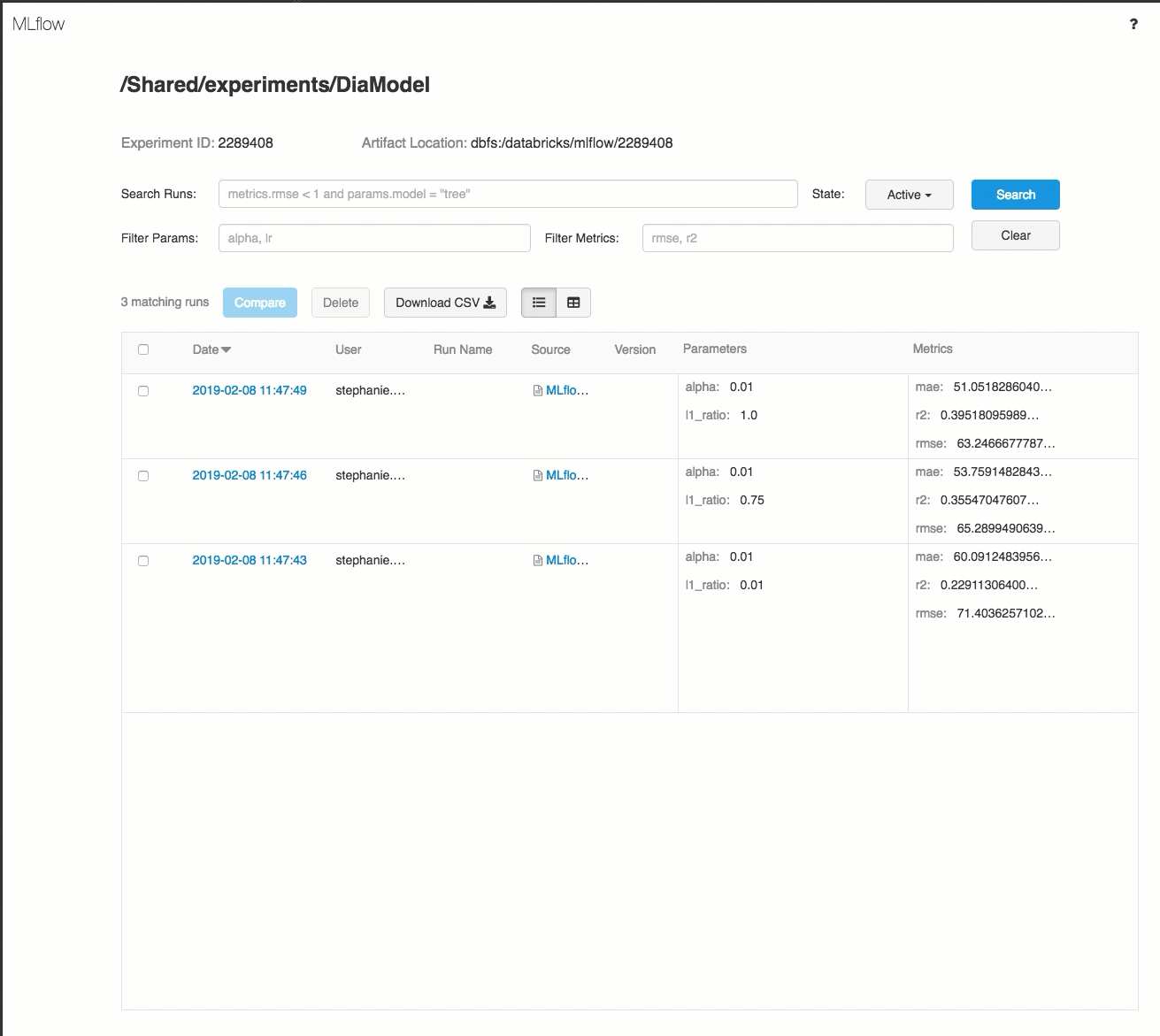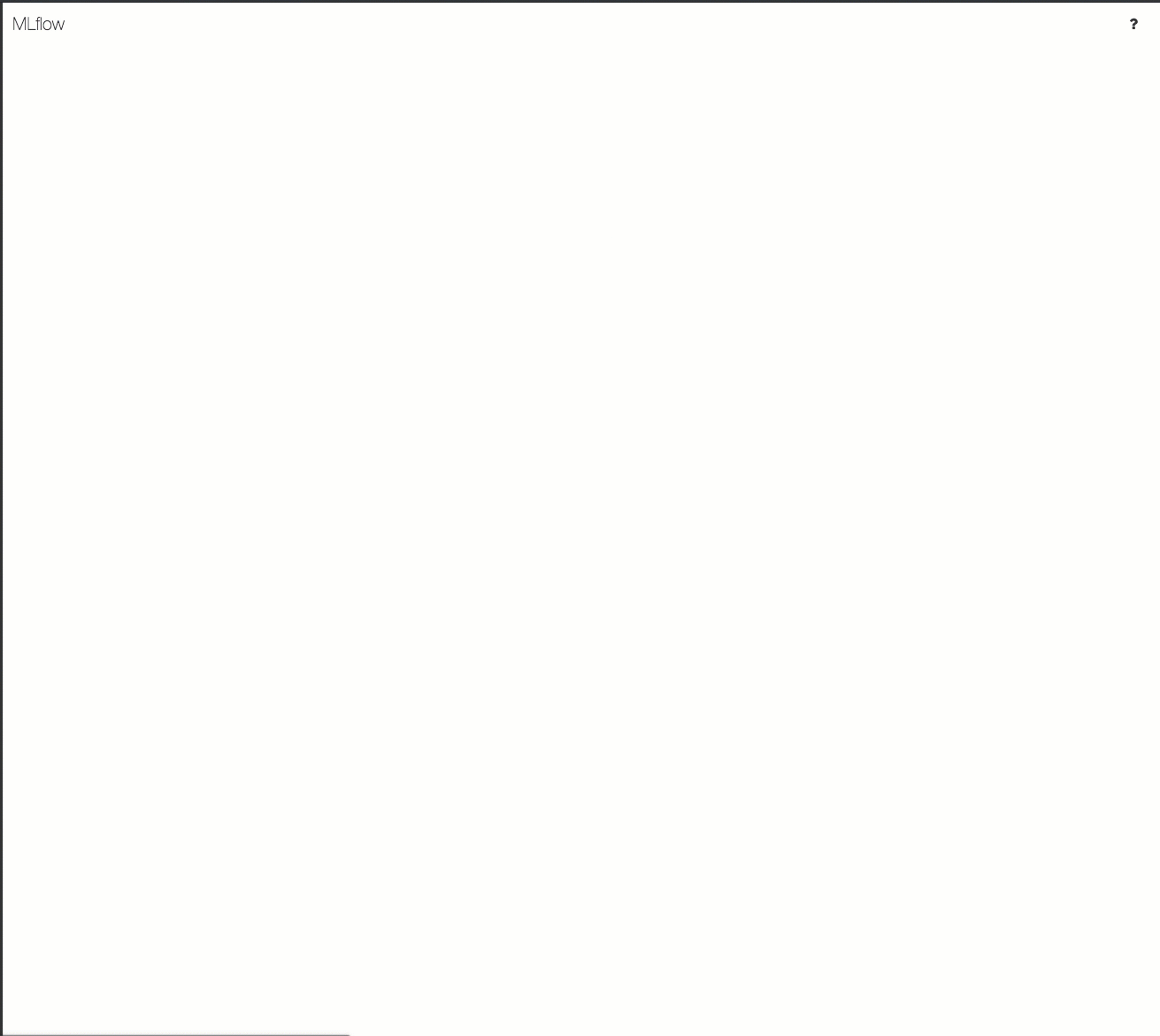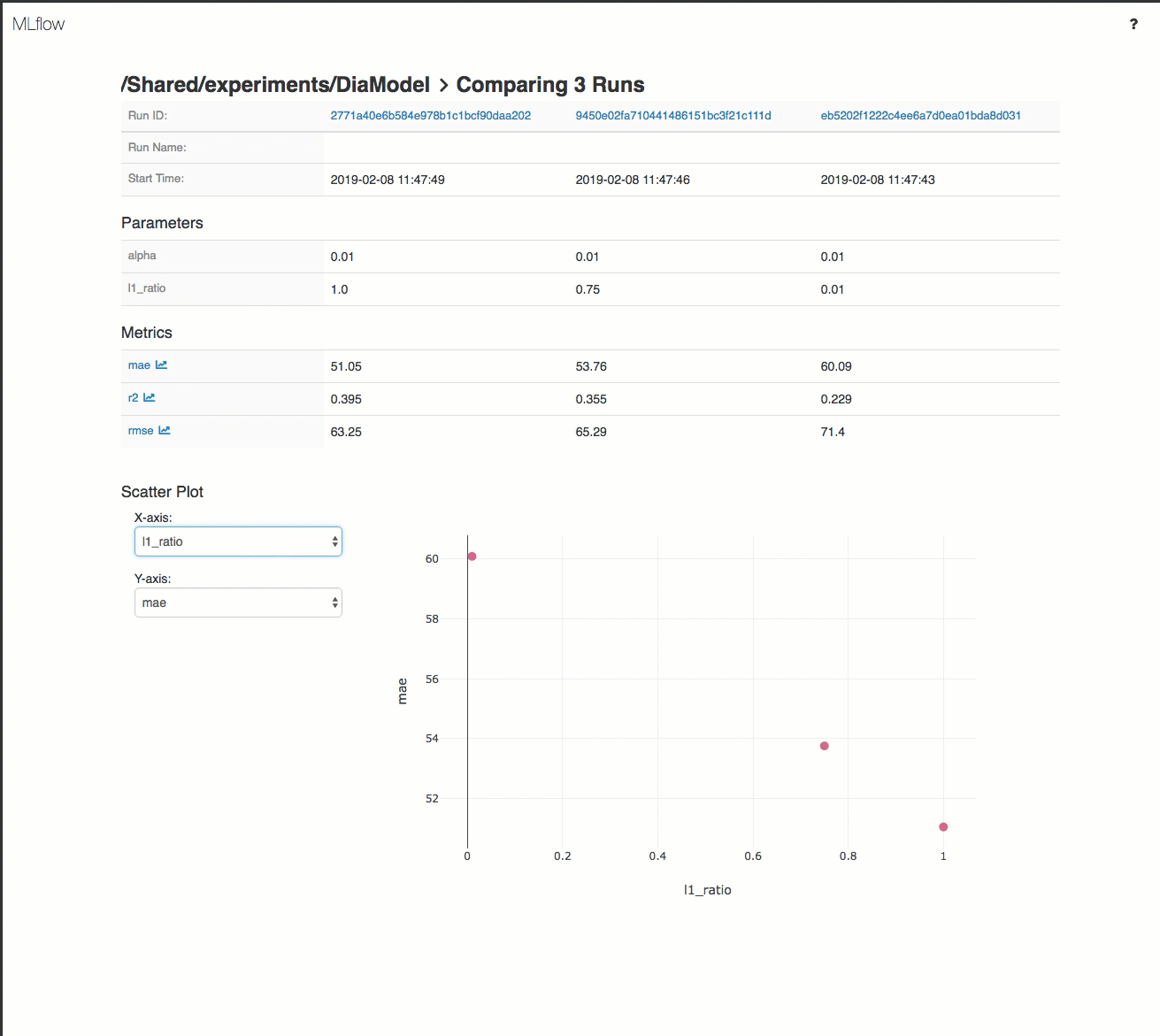
Ausführliche Informationen finden Sie unter Nachverfolgen von Machine Learning-Trainingsausführungen und Ausführen von MLflow-Projekten in Azure Databricks.
Azure Data Lake Storage Gen2-Connector allgemein verfügbar
15. Februar 2019
Azure Data Lake Storage Gen2 (ADLS Gen2), die Data Lake-Lösung der nächsten Generation für Big Data-Analysen, ist jetzt ebenso wie der ADLS Gen2-Connector für Azure Databricks allgemein verfügbar. Wir freuen außerdem, Ihnen mitteilen zu können, dass ADLS Gen2 Databricks Delta unterstützt, wenn Sie Cluster unter Databricks Runtime 5.2 und höher ausführen.
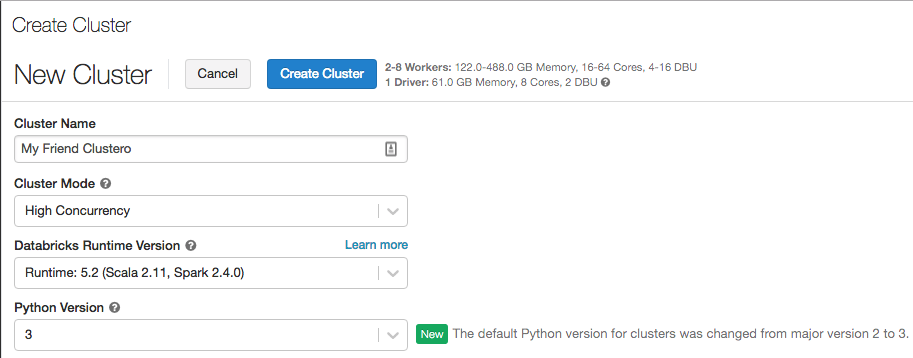
Python 3 jetzt Standard bei der Clustererstellung
12. bis 19 Februar 2019: Version 2.91
Die Python-Standardversion für Cluster, die über die Benutzeroberfläche erstellt wurden, wurde von Python 2 auf Python 3 geändert. Die Standardeinstellung für Cluster, die mit der REST-API erstellt wurden, ist weiterhin Python 2.
Die Python-Versionen vorhandener Cluster werden nicht geändert. Wenn Sie bisher immer Python 2 als Standardeinstellung beim Erstellen neuer Cluster verwendet haben, müssen Sie nun darauf achten, welche Python-Version ausgewählt wurde.
Delta Lake allgemein verfügbar
1. Februar 2019
Nun kann jede*r die Vorteile der leistungsstarken transaktionalen Speicherebene und der superschnellen Lesevorgänge in Databricks Delta genießen: Seit dem 1. Februar ist Delta Lake allgemein verfügbar und kann auf allen unterstützen Versionen von Databricks Runtime verwendet werden. Informationen zu Delta finden Sie unter Was ist Delta?.