Januar 2019
Diese Features und Azure Databricks-Plattformverbesserungen wurden im Januar 2019 veröffentlicht.
Hinweis
Releases werden gestaffelt. Ihr Azure Databricks-Konto wird möglicherweise erst eine Woche nach dem Datum der ersten Veröffentlichung aktualisiert.
Bevorstehende Änderung: Python 3 wird bei der Clustererstellung zum Standard
29. Januar 2019
Wenn die Databricks-Plattformversion 2.91 Mitte Februar veröffentlicht wird, wechselt die Python-Standardversion für neue Cluster von Python 2 zu Python 3. Die Python-Versionen vorhandener Cluster werden natürlich nicht geändert. Wenn Sie bisher immer Python 2 als Standardeinstellung beim Erstellen neuer Cluster verwendet haben, müssen Sie nun darauf achten, welche Python-Version ausgewählt wurde.
Freigabe von Databricks Runtime 5.2 für Machine Learning (Beta)
24. Januar 2019
Databricks Runtime 5.2 ML basiert auf Databricks Runtime 5.2 (nicht unterstützt). Es enthält viele beliebte Machine Learning-Bibliotheken, darunter TensorFlow, PyTorch, Keras und XGBoost, und bietet verteiltes TensorFlow-Training mit Horovod. Zusätzlich zu Bibliotheksupdates seit Databricks Runtime ML 5.1 enthält Databricks Runtime 5.2 ML die folgenden neuen Features:
- GraphFrames unterstützt jetzt die Pregel-API (Python) mit den Leistungsoptimierungen von Databricks.
- HorovodRunner fügt Folgendes hinzu:
- In einem GPU-Cluster werden Trainingsprozesse GPUs anstelle von Workerknoten zugeordnet, um die Unterstützung von Multi-GPU-Instanztypen zu vereinfachen. Mit dieser integrierten Unterstützung können Sie ohne benutzerdefinierten Code auf alle GPUs auf einem Multi-GPU-Computer verteilen.
HorovodRunner.run()gibt nun den Rückgabewert aus dem ersten Trainingsprozess zurück.
Die vollständigen Versionshinweise finden Sie unter Databricks Runtime 5.2 ML.
Databricks Runtime 5.2-Release
24. Januar 2019
Databricks Runtime 5.2 ist jetzt verfügbar. Databricks Runtime 5.2 enthält Apache Spark 2.4.0, neue Features und Upgrades für Delta Lake und Structured Streaming sowie aktualisierte Python-, R-, Java- und Scala-Bibliotheken. Weitere Informationen finden Sie unter Databricks Runtime 5.2 (nicht unterstützt).
JSON-Ansicht der Clusterkonfiguration
15.–22. Januar 2019
Die Clusterkonfigurationsseite unterstützt jetzt eine JSON-Ansicht:
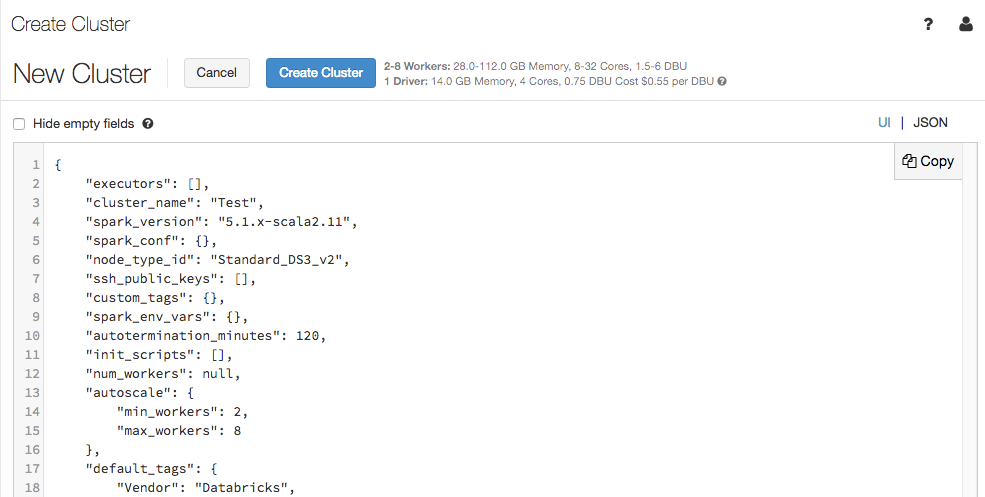
Die JSON-Ansicht ist schreibgeschützt. Sie können den JSON-Code jedoch kopieren und zum Erstellen und Aktualisieren von Clustern mit der Cluster-API verwenden.
Clusterbenutzeroberfläche
15.–22. Januar 2019: Version 2.89
Die Seite für die Clustererstellung wurde bereinigt und neu organisiert, um die Benutzerfreundlichkeit zu erleichtern, einschließlich eines neuen Umschalters „Erweiterte Optionen“.

Bereitstellen von Azure Databricks im eigenen virtuellen Azure-Netzwerk (VNet-Einschleusung)
10. Januar 2019
Wichtig
Dieses Feature befindet sich in der Public Preview.
Standardmäßig wird Azure Databricks als vollständig verwalteter Dienst in Azure bereitgestellt: Alle Ressourcen auf Computeebene (einschließlich eines virtuellen Netzwerks (VNet), dem alle Cluster zugeordnet werden) werden in einer gesperrten Ressourcengruppe bereitgestellt. Wenn jedoch eine Netzwerkanpassung erforderlich ist, können Sie Azure Databricks jetzt in Ihrem eigenen virtuellen Netzwerk bereitstellen (manchmal auch als VNet-Injektion bezeichnet), was Ihnen dies ermöglicht:
- Sicheres Verbinden von Azure Databricks mit anderen Azure-Diensten (z.B. Azure Storage) über Dienstendpunkte.
- Verbinden mit lokalen Datenquellen zur Verwendung mit Azure Databricks unter Verwendung von benutzerdefinierten Routen
- Verbinden von Azure Databricks mit einem virtuellen Netzwerkgerät, um den ausgehenden Datenverkehr zu untersuchen und anhand von Zulassungs- und Ablehnungsregeln Maßnahmen zu ergreifen.
- Konfigurieren von Azure Databricks zur Verwendung eines benutzerdefinierten DNS.
- Konfigurieren von Netzwerksicherheitsgruppen-Regeln (NSG-Regeln), um Einschränkungen für ausgehenden Datenverkehr zu definieren
- Bereitstellen von Azure Databricks-Clustern in Ihrem vorhandenen virtuellen Netzwerk.
Durch die Bereitstellung von Azure Databricks in Ihrem eigenen virtuellen Netzwerk können Sie auch die Vorteile flexibler CIDR-Bereiche nutzen (an einer beliebigen Stelle zwischen /16-/24 für das virtuelle Netzwerk und zwischen /18-/26 für die Subnetze).
Die Konfiguration mithilfe der Azure-Portal-Benutzeroberfläche ist schnell und einfach: Wenn Sie einen Arbeitsbereich erstellen, wählen Sie einfach Deploy Azure Databricks workspace in your Virtual Network (Azure Databricks-Arbeitsbereich in Ihrem virtuellen Netzwerk bereitstellen) aus, wählen Ihr virtuelles Netzwerk und geben CIDR-Bereiche für zwei Subnetze an. Azure Databricks aktualisiert das virtuelle Netzwerk mit zwei neuen Subnetzen und Netzwerksicherheitsgruppen unter Verwendung der von Ihnen bereitgestellten CIDR-Bereiche, erlaubt Zugriff auf den eingehenden und ausgehenden Subnetzverkehr, und stellt den Arbeitsbereich für das aktualisierte virtuelle Netzwerk bereit.
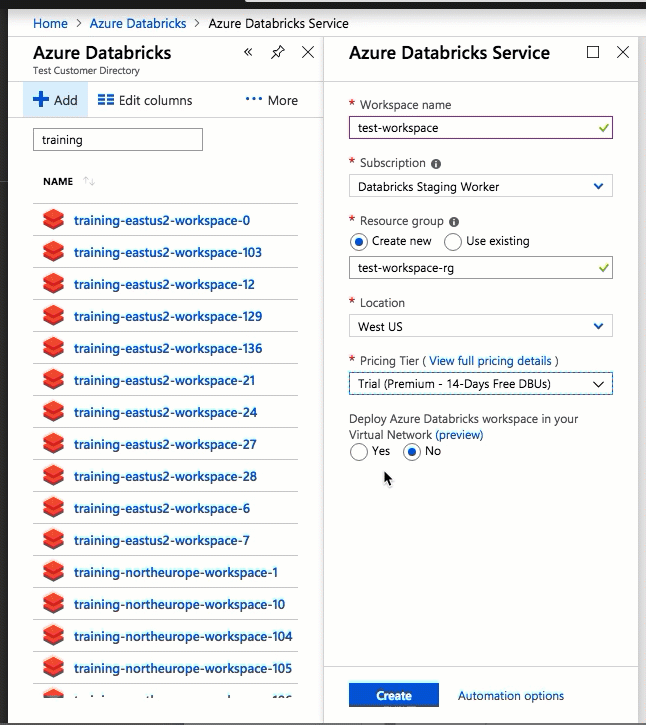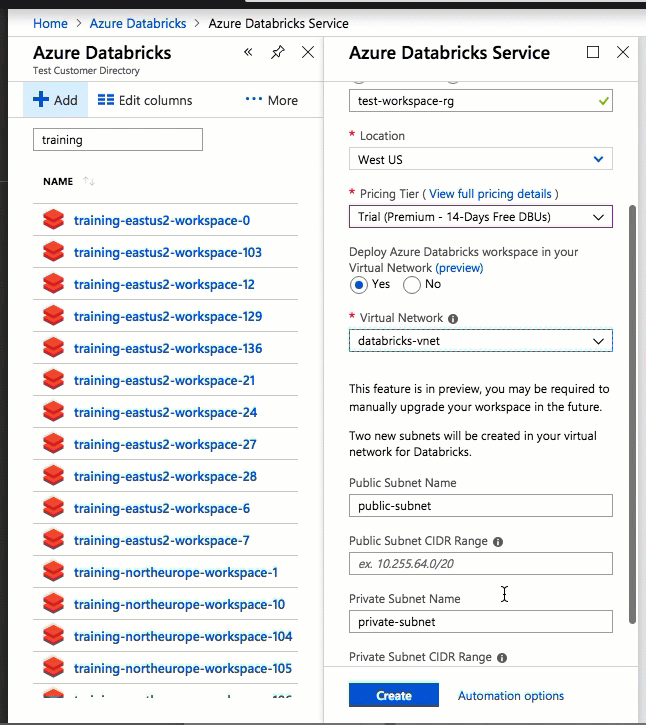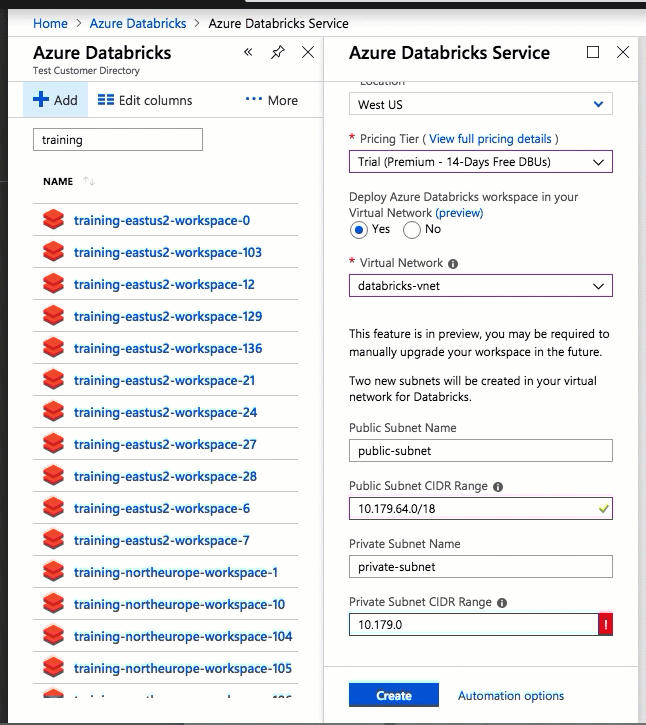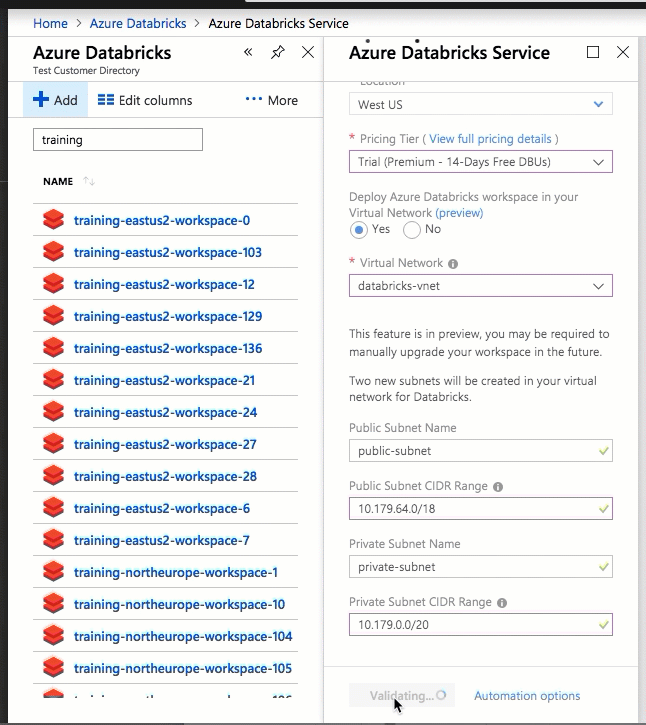
Wenn Sie das virtuelle Netzwerk für die VNet-Einschleusung lieber selbst konfigurieren möchten, z. B. wenn Sie vorhandene Subnetze verwenden, vorhandene Netzwerksicherheitsgruppen nutzen oder eigene Sicherheitsregeln erstellen möchten, können Sie die von Azure Databricks bereitgestellten ARM-Vorlagen anstelle der Portal-Benutzeroberfläche verwenden.
Hinweis
Dieses Feature war zuvor nur für die Registrierung verfügbar. Es verbleibt in der Vorschau , ist aber jetzt vollständig selbst bedienbar.
Weitere Informationen finden Sie unter Bereitstellen von Azure Databricks in Ihrem virtuellen Azure-Netzwerk (VNET-Einschleusung) und Verbinden Ihres Azure Databricks-Arbeitsbereichs in Ihrem lokalen Netzwerk.
Bibliotheksbenutzeroberfläche
2.–9. Januar 2019: Version 2.88
Die Verbesserungen der Bibliotheksbenutzeroberfläche, die ursprünglich im November 2018 veröffentlicht und kurz danach zurückgesetzt wurden, wurden erneut veröffentlicht. Diese Updates erleichtern das Hochladen, Installieren und Verwalten von Bibliotheken für Ihre Azure Databricks-Cluster.
Die Azure Databricks-Benutzeroberfläche unterstützt jetzt Arbeitsbereichsbibliotheken und an Cluster angefügte Bibliotheken. Eine Arbeitsbereichsbibliothek existiert im Arbeitsbereich und kann auf einem oder mehreren Clustern installiert werden. Eine im Cluster installierte Bibliothek ist eine Bibliothek, die nur im Kontext des Clusters existiert, in dem sie installiert ist. Außerdem haben Sie folgende Möglichkeiten:
- Sie können jetzt eine Bibliothek aus einer Datei erstellen, die in den Objektspeicher hochgeladen wurde.
- Sie können jetzt Bibliotheken auf der Seite mit den Bibliotheksdetails und auf der Registerkarte „Bibliotheken“ eines Clusters installieren und deinstallieren.
- Bibliotheken, die mithilfe der API installiert wurden, werden jetzt auf der Registerkarte „Bibliotheken“ eines Clusters angezeigt.
Weitere Informationen finden Sie unter Bibliotheken.
Clusterereignisse
2.–9. Januar 2019: Version 2.88
Es wurden neue Cluster-Ereignisse hinzugefügt, die den Status des Spark-Treibers widerspiegeln. Weitere Informationen finden Sie unter Cluster-API.
Notebook-Versionskontrolle über Azure DevOps Services
2.–9. Januar 2019: Version 2.88
Azure Databricks ermöglicht jetzt die Verwendung von Azure DevOps Services (früher VSTS) zur Versionssteuerung Ihrer Notebooks. Die Authentifizierung erfolgt automatisch, das Setup ist unkompliziert, und Sie verwalten Ihre Notebookrevisionen genau wie bei unserer GitHub Integration.
Weitere Informationen finden Sie unter Git-Versionskontrolle für Notebooks (Legacy).
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für