Orchestrieren von Azure Databricks-Aufträgen mit Apache Airflow
In diesem Artikel wird die Apache Airflow-Unterstützung für die Orchestrierung von Datenpipelines mit Azure Databricks beschrieben. Außerdem enthält er Anweisungen zum lokalen Installieren und Konfigurieren von Airflow und bietet ein Beispiel für die Bereitstellung und Ausführung eines Azure Databricks-Workflows mit Airflow.
Auftragsorchestrierung in einer Datenpipeline
Das Entwickeln und Bereitstellen einer Datenverarbeitungspipeline erfordert häufig die Verwaltung komplexer Abhängigkeiten zwischen Aufgaben. So liest eine Pipeline beispielsweise möglicherweise Daten aus einer Quelle, bereinigt sie, transformiert die bereinigten Daten und schreibt sie in ein Ziel. Außerdem benötigen Sie möglicherweise Unterstützung für Tests und Planung und müssen beim Operationalisieren einer Pipeline Fehler beheben.
Workflowsysteme helfen Ihnen dabei, diese Herausforderungen zu bewältigen, indem sie es Ihnen ermöglichen, Abhängigkeiten zwischen Aufgaben zu definieren, die Pipelineausführung zu planen und Workflows zu überwachen. Apache Airflow ist eine Open-Source-Lösung zum Verwalten und Planen von Datenpipelines. Airflow stellt Datenpipelines als gerichtete azyklische Graphen (DAGs) von Vorgängen dar. Sie definieren einen Workflow in einer Python-Datei, und Airflow verwaltet die Planung und Ausführung. Die Verbindung aus Airflow und Azure Databricks gibt Ihnen die Möglichkeit, die optimierte Spark-Engine zu nutzen, die Azure Databricks zusammen mit den Planungsfeatures von Airflow bietet.
Anforderungen
- Die Integration von Airflow in Azure Databricks erfordert Airflow-Version 2.5.0 oder höher. Die Beispiele in diesem Artikel wurden mit der Airflow-Version 2.6.1 getestet.
- Airflow erfordert Python 3.8, 3.9, 3.10 oder 3.11. Die Beispiele in diesem Artikel werden mit Python 3.8 getestet.
- Die Anweisungen zum Installieren und Ausführen von Airflow in diesem Artikel erfordernpipenv zum Erstellen einer virtuellen Python-Umgebung.
Airflow-Operatoren für Databricks
Ein gerichteter azyklischer Airflow-Graph besteht aus Aufgaben, bei denen jeder Vorgang einen Airflow-Operatorausführt. Airflow-Operator, die die Integration in Databricks unterstützen, werden im Databricks-Anbieter implementiert.
Der Databricks-Anbieter stellt Operatoren zum Ausführen einer Reihe von Aufgaben in einem Azure Databricks-Arbeitsbereich bereit, einschließlich des Importierens von Daten in eine Tabelle, des Ausführens von SQL-Abfragenund des Arbeitens mit Databricks-Git-Ordnern.
Der Databricks-Anbieter implementiert zwei Operatoren zum Auslösen von Aufträgen:
- Der DatabricksRunNowOperator erfordert einen vorhandenen Azure Databricks-Auftrag und verwendet die POST /api/2.1/jobs/run-now-API-Anforderung zum Auslösen einer Ausführung. Databricks empfiehlt die Verwendung von
DatabricksRunNowOperator, da dadurch die Duplizierung von Auftragsdefinitionen reduziert wird und mit diesem Operator ausgelöste Auftragsausführungen in der Benutzeroberfläche für Aufträge gefunden werden können. - Der DatabricksSubmitRunOperator erfordert keinen vorhandenen Auftrag in Azure Databricks und verwendet zum Übermitteln der Auftragsspezifikation und zum Auslösen einer Ausführung die POST /api/2.1/jobs/runs/submit-API-Anforderung.
Um einen neuen Azure Databricks-Auftrag zu erstellen oder einen vorhandenen Auftrag zurückzusetzen, implementiert der Databricks-Anbieter den DatabricksCreateJobsOperator. Der DatabricksCreateJobsOperator verwendet die POST /api/2.1/jobs/create- und die POST /api/2.1/jobs/reset-API-Anforderung. Sie können den DatabricksCreateJobsOperator mit dem DatabricksRunNowOperator verwenden, um einen Auftrag zu erstellen und auszuführen.
Hinweis
Für die Verwendung der Databricks-Operatoren zum Auslösen eines Auftrags müssen Sie Anmeldeinformationen in der Databricks-Verbindungskonfiguration bereitstellen. Weitere Informationen finden Sie unter Erstellen eines persönlichen Azure Databricks-Zugriffstokens für Airflow.
Der Databricks-Airflow-Operator schreibt die URL der Auftragsausführungsseiten mit der Einstellung polling_period_seconds (Standardwert entspricht 30 Sekunden) in die Airflow-Protokolle. Weitere Informationen finden Sie auf der Seite zum Paket apache-airflow-providers-databricks auf der Airflow-Website.
Lokales Installieren der Airflow-Azure Databricks-Integration
Führen Sie die folgenden Schritte aus, um Airflow und den Databricks-Anbieter lokal für Tests und Entwicklung zu installieren. Weitere Installationsmöglichkeiten für Airflow, einschließlich der Erstellung einer Produktionsinstallation, finden Sie in der Airflow-Dokumentation unter Installation.
Öffnen Sie ein Terminal, und führen Sie die folgenden Befehle aus:
mkdir airflow
cd airflow
pipenv --python 3.8
pipenv shell
export AIRFLOW_HOME=$(pwd)
pipenv install apache-airflow
pipenv install apache-airflow-providers-databricks
mkdir dags
airflow db init
airflow users create --username admin --firstname <firstname> --lastname <lastname> --role Admin --email <email>
Ersetzen Sie <firstname>, <lastname>und <email> durch Ihren Benutzernamen und Ihre E-Mail-Adresse. Sie werden aufgefordert, ein Kennwort für den Administratorbenutzer einzugeben. Achten Sie darauf, dieses Kennwort zu speichern, da es für die Anmeldung bei der Airflow-Benutzeroberfläche erforderlich ist.
Dieses Skript führt die folgenden Schritte aus:
- Es erstellt ein Verzeichnis namens
airflow, und wechselt in dieses Verzeichnis. - Es verwendet
pipenv, um eine virtuelle Python-Umgebung zu erzeugen. Databricks empfiehlt die Verwendung einer virtuellen Python-Umgebung, um Paketversionen und Codeabhängigkeiten für diese Umgebung zu isolieren. Die Isolation trägt dazu bei, unerwartete Konflikte in Bezug auf Paketversionen und Codeabhängigkeiten zu reduzieren. - Es initialisiert die Umgebungsvariable namens
AIRFLOW_HOME, die auf den Pfad desairflow-Verzeichnisses festgelegt ist. - Es installiert Airflow und die Airflow-Databricks-Anbieterpakete.
- Es erstellt ein
airflow/dags-Verzeichnis. Airflow verwendet das Verzeichnisdagszum Speichern von DAG-Definitionen. - Es Initialisiert eine SQLite-Datenbank, die Airflow zum Nachverfolgen von Metadaten verwendet. In einer Airflow-Produktionsbereitstellung würden Sie Airflow mit einer Standarddatenbank konfigurieren. Die SQLite-Datenbank und die Standardkonfiguration für Ihre Airflow-Bereitstellung werden im Verzeichnis
airflowinitialisiert. - Es erstellt eine*n Administratorbenutzer*in für Airflow.
Tipp
Um die Installation des Databricks-Anbieters zu bestätigen, führen Sie im Airflow-Installationsverzeichnis den folgenden Befehl aus:
airflow providers list
Starten des Airflow-Webservers und -Planers
Der Airflow-Webserver ist erforderlich, um die Airflow-Benutzeroberfläche anzuzeigen. Um den Webserver zu starten, öffnen Sie ein Terminal im Airflow-Installationsverzeichnis, und führen Sie die folgenden Befehle aus:
Hinweis
Wenn der Airflow-Webserver aufgrund eines Portkonflikts nicht startet, können Sie den Standardport in der Airflow-Konfiguration ändern.
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow webserver
Der Planer ist die Airflow-Komponente, die DAGs geplant. Um den Scheduler zu starten, öffnen Sie ein neues Terminal im Airflow-Installationsverzeichnis, und führen Sie die folgenden Befehle aus:
pipenv shell
export AIRFLOW_HOME=$(pwd)
airflow scheduler
Testen der Airflow-Installation
Um die Airflow-Installation zu überprüfen, können Sie eine der in Airflow enthaltenen Beispiel-DAGs ausführen:
- Öffnen Sie
http://localhost:8080/homein einem Browserfenster. Melden Sie sich bei der Airflow-Benutzeroberfläche mit dem Benutzernamen und Kennwort an, die Sie beim Installieren von Airflow erstellt haben. Die Airflow-Seite für gerichtete azyklische Graphen wird angezeigt. - Klicken Sie auf die Umschaltfläche Pause/Unpause DAG (DAG anhalten/fortsetzen), um einen der Beispiel-DAGs fortzusetzen (z. B.
example_python_operator). - Lösen Sie den gerichteten azyklischen Beispiel-Graph aus, indem Sie auf die Schaltfläche Gerichteten azyklischen Graph auslösen klicken.
- Klicken Sie auf den DAG-Namen, um Details anzuzeigen (einschließlich des DAG-Ausführungsstatus).
Erstellen eines persönlichen Azure Databricks-Zugriffstokens für Airflow
Airflow stellt mithilfe eines persönlichen Azure Databricks-Zugriffstokens (PAT) eine Verbindung mit Databricks her. Um einen PAT zu erstellen:
- Klicken Sie in Ihrem Azure Databricks-Arbeitsbereich in der oberen Leiste auf Ihren Azure Databricks-Benutzernamen, und wählen Sie dann im Dropdownmenü die Option Einstellungen aus.
- Klicken Sie auf Entwickler.
- Klicken Sie neben Zugriffstoken auf Verwalten.
- Klicken Sie auf Neues Token generieren.
- (Optional) Geben Sie einen Kommentar ein, durch den Sie dieses Token in Zukunft identifizieren können, und ändern Sie die standardmäßige Lebensdauer des Tokens von 90 Tagen. Wenn Sie ein Token ohne Gültigkeitsdauer erstellen möchten (nicht empfohlen), lassen Sie das Feld Lebensdauer (Tage) leer.
- Klicken Sie auf Generate (Generieren) .
- Kopieren Sie das angezeigte Token an einen sicheren Speicherort, und klicken Sie auf Fertig.
Hinweis
Achten Sie darauf, den kopierten Token an einem sicheren Ort zu speichern. Geben Sie das kopierte Token nicht an andere Personen weiter. Wenn Sie das kopierte Token verlieren, können Sie das gleiche Token nicht erneut generieren. Stattdessen müssen Sie erneut das Verfahren zum Erstellen eines neuen Tokens durchlaufen. Wenn Sie das kopierte Token verlieren oder glauben, dass das Token kompromittiert wurde, empfiehlt Databricks dringend, dass Sie das Token sofort aus Ihrem Arbeitsbereich löschen. Klicken Sie hierzu auf der Seite Zugriffstoken auf das Papierkorbsymbol (Widerrufen) neben dem Token.
Wenn Sie in Ihrem Arbeitsbereich keine Token erstellen oder verwenden können, liegt dies möglicherweise daran, dass Ihr Arbeitsbereichsadministrator Token deaktiviert hat oder Ihnen keine Berechtigung zum Erstellen oder Verwenden von Token erteilt hat. Wenden Sie sich an Ihren Arbeitsbereichsadministrator oder lesen Sie:
Hinweis
Als bewährte Methode für die Sicherheit empfiehlt Databricks, dass Sie bei der Authentifizierung mit automatisierten Tools, Systemen, Skripten und Anwendungen persönliche Zugriffstoken verwenden, die zu Dienstprinzipalen und nicht zu Benutzern des Arbeitsbereichs gehören. Informationen zum Erstellen von Token für Dienstprinzipale finden Sie unter Verwalten von Token für einen Dienstprinzipal.
Sie können sich auch mit einem Microsoft Entra ID-Token (früher Azure Active Directory) bei Azure Databricks authentifizieren. Weitere Informationen finden Sie in der Airflow-Dokumentation unter Databricks-Verbindung.
Konfigurieren einer Azure Databricks-Verbindung
Ihre Airflow-Installation enthält eine Standardverbindung für Azure Databricks. Führen Sie die folgenden Schritte aus, um die Verbindung zu aktualisieren und Ihren Arbeitsbereich mithilfe des zuvor erstellten persönlichen Zugriffstokens zu verbinden:
- Öffnen Sie
http://localhost:8080/connection/list/in einem Browserfenster. Wenn Sie aufgefordert werden, sich anzumelden, geben Sie Ihren Administratorbenutzernamen und Ihr Kennwort ein. - Suchen Sie unter Verbindungs-ID nach databricks_default, und klicken Sie auf die Schaltfläche Datensatz bearbeiten.
- Ersetzen Sie den Wert im Feld Host durch den Namen der Arbeitsbereichsinstanz Ihrer Azure Databricks-Bereitstellung, zum Beispiel
https://adb-123456789.cloud.databricks.com. - Geben Sie im Feld Kennwort Ihr persönliches Azure Databricks-Zugriffstoken ein.
- Klicken Sie auf Speichern.
Wenn Sie ein Microsoft Entra ID-Token verwenden, lesen Sie für Informationen zum Konfigurieren der Authentifizierung den AbschnittDatabricks-Verbindung in der Airflow-Dokumentation.
Beispiel: Erstellen eines gerichteten azyklischen Airflow-Graphs zum Ausführen eines Azure Databricks-Auftrags
Im folgenden Beispiel wird veranschaulicht, wie Sie eine einfache Airflow-Bereitstellung erstellen, die auf Ihrem lokalen Computer ausgeführt wird und einen Beispiel-DAG zum Auslösen von Ausführungen in Azure Databricks bereitstellt. In diesem Beispiel führen Sie folgende Schritte aus:
- Erstellen Sie ein neues Notebook, und fügen Sie Code zum Ausgeben einer Grußformel basierend auf einem konfigurierten Parameter hinzu.
- Erstellen Sie einen Azure Databricks-Auftrag mit einer einzelnen Aufgabe, die das Notebook ausführt.
- Konfigurieren Sie eine Airflow-Verbindung mit Ihrem Azure Databricks-Arbeitsbereich.
- Erstellen Sie einen Airflow-DAG, um den Notebookauftrag auszulösen. Sie definieren den DAG mithilfe von
DatabricksRunNowOperatorin einem Python-Skript. - Verwenden Sie die Airflow-Benutzeroberfläche, um den DAG auszulösen und den Ausführungsstatus anzuzeigen.
Erstellen eines Notebooks
In diesem Beispiel wird ein Notebook verwendet, das zwei Zellen enthält:
- Die erste Zelle enthält ein Textwidget der Databricks-Hilfsprogramme, das eine Variable namens
greetingdefiniert, die auf den Standardwertworldfestgelegt ist. - Die zweite Zelle gibt den Wert der Variable
greetingmit dem Präfixhelloaus.
Führen Sie die folgenden Schritte aus, um das Notebook zu erstellen:
Wechseln Sie zu Ihrem Azure Databricks-Arbeitsbereich, klicken Sie in der Seitenleiste auf
 Neu, und wählen Sie Notebook aus.
Neu, und wählen Sie Notebook aus.Geben Sie Ihrem Notizbuch einen Namen, z. B. Hallo Airflow, und stellen Sie sicher, dass die Standardsprache auf Python festgelegt ist.
Kopieren Sie den folgenden Python-Code, und fügen Sie ihn in die erste Zelle des Notebooks ein.
dbutils.widgets.text("greeting", "world", "Greeting") greeting = dbutils.widgets.get("greeting")Fügen Sie unter der ersten Zelle eine neue Zelle hinzu, kopieren Sie den folgenden Python-Code, und fügen Sie ihn in die neue Zelle ein:
print("hello {}".format(greeting))
Erstellen eines Auftrags
Klicken Sie auf der Randleiste auf
 Workflows.
Workflows.Klicken Sie auf die
 .
.Die Registerkarte Aufgaben wird mit dem Dialogfeld „Aufgabe erstellen“ angezeigt.
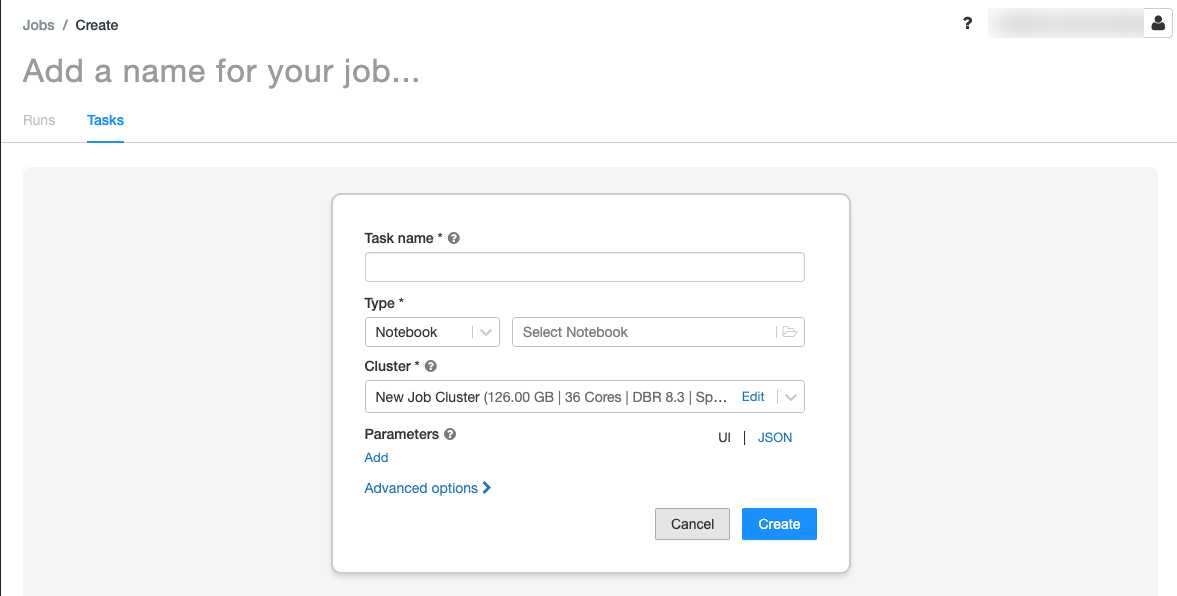
Ersetzen Sie Add a name for your job… (Namen für Ihren Auftrag hinzufügen...) mit dem Namen für den Auftrag.
Geben Sie im Feld Aufgabenname einen Namen für die Aufgabe ein (z. B. greeting-task).
Wählen Sie im Dropdownmenü TypNotebook aus.
Wählen Sie im Dropdownmenü Quelle die Option Arbeitsbereich aus.
Klicken Sie auf das Pfad-Textfeld und verwenden Sie den Dateibrowser, um das erstellte Notebook zu suchen. Klicken Sie auf den Namen des Notebooks und dann auf Bestätigen.
Klicken Sie unter Parameter auf Hinzufügen. Geben Sie im Feld Schlüssel
greetingein. Geben Sie im Feld WertAirflow userein.Klicken Sie auf Aufgabe erstellen.
Kopieren Sie im Bereich Auftragsdetails den Wert Auftrags-ID. Dieser Wert ist erforderlich, um den Auftrag über Airflow auszulösen.
Ausführung des Auftrags.
Um Ihren neuen Auftrag in der Workflows-Benutzeroberfläche von Azure Databricks zu testen, klicken Sie in der oberen rechten Ecke auf  . Nach Abschluss der Ausführung können Sie die Ausgabe überprüfen, indem Sie die Details zur Auftragsausführung anzeigen.
. Nach Abschluss der Ausführung können Sie die Ausgabe überprüfen, indem Sie die Details zur Auftragsausführung anzeigen.
Erstellen eines neuen Airflow-DAG
Sie definieren einen Airflow-DAG in einer Python-Datei. Führen Sie die folgenden Schritte aus, um einen DAG zum Auslösen des Beispielnotebookauftrags zu erstellen:
Erstellen Sie in einem Text-Editor oder einer IDE eine neue Datei namens
databricks_dag.pymit dem folgenden Inhalt:from airflow import DAG from airflow.providers.databricks.operators.databricks import DatabricksRunNowOperator from airflow.utils.dates import days_ago default_args = { 'owner': 'airflow' } with DAG('databricks_dag', start_date = days_ago(2), schedule_interval = None, default_args = default_args ) as dag: opr_run_now = DatabricksRunNowOperator( task_id = 'run_now', databricks_conn_id = 'databricks_default', job_id = JOB_ID )Ersetzen Sie
JOB_IDdurch den Wert der zuvor gespeicherten Auftrags-ID.Speichern Sie die Datei im Verzeichnis
airflow/dags. Airflow liest und installiert inairflow/dags/gespeicherte DAG-Dateien automatisch.
Installieren und Überprüfen des DAG in Airflow
Führen Sie die folgenden Schritte aus, um den DAG mithilfe der Airflow-Benutzeroberfläche auszulösen und zu überprüfen:
- Öffnen Sie
http://localhost:8080/homein einem Browserfenster. Der Airflow-Bildschirm für DAGs wird angezeigt. - Suchen Sie nach
databricks_dag, und klicken Sie auf die Umschaltfläche Pause/Unpause DAG (DAG anhalten/fortsetzen), um den DAG fortzusetzen. - Lösen Sie den gerichteten azyklischen Graph aus, indem Sie auf die Schaltfläche Gerichteten azyklischen Graph auslösen klicken.
- Klicken Sie in der Spalte Ausführungen auf eine Ausführung, um den zugehörigen Status und Details anzuzeigen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für