Worum handelt es sich bei Apache Hadoop in Azure HDInsight?
Apache Hadoop war ursprünglich ein Open Source-Framework für die verteilte Verarbeitung und Analyse umfangreicher Datasets in Clustern. Das Hadoop-Ökosystem umfasst verwandte Software und Hilfsprogramme, einschließlich Apache Hive, Apache HBase, Spark, Kafka und viele andere.
Azure HDInsight ist ein umfassender, vollständig verwalteter Open-Source-Analysedienst in der Cloud für Unternehmen. Der Apache Hadoop-Clustertyp in Azure HDInsight ermöglicht Ihnen die Verwendung von Apache Hadoop Distributed File System (HDFS), der Apache Hadoop YARN-Ressourcenverwaltung und eines einfachen MapReduce-Programmiermodells zum parallelen Verarbeiten und Analysieren von Batchdaten. Hadoop-Cluster in HDInsight sind mit Azure Blob Storage, Azure Data Lake Storage Gen1 oder Azure Data Lake Storage Gen2 kompatibel.
Informationen zu verfügbare Komponenten des Hadoop-Technologiestapels für HDInsight finden Sie unter Welche Hadoop-Komponenten und -Versionen sind in HDInsight verfügbar?. Weitere Informationen zu Hadoop in HDInsight finden Sie auf der Seite mit Azure-Features für HDInsight.
Was ist MapReduce?
Apache Hadoop MapReduce ist ein Softwareframework zum Schreiben von Aufträgen, die sehr große Datenmengen verarbeiten. Eingabedaten werden in unabhängigen Blöcke aufgeteilt. Jeder Block wird in den Knoten im Cluster parallel verarbeitet. Ein MapReduce-Auftrag besteht aus zwei Funktionen:
Mapper: Verarbeitet Eingabedaten, analysiert sie (in der Regel mit Filter- und Sortiervorgängen) und gibt Tupel (Schlüssel-Wert-Paare) aus.
Reducer: Verarbeitet Tupel, die vom Mapper ausgegeben wurden, und führt einen Zusammenfassungsvorgang aus, der kleinere, kombinierte Ergebnisse aus den Mapper-Daten erstellt.
Ein Beispiel für einen grundlegenden MapReduce-Auftrag zum Zählen von Wörtern wird im folgenden Diagramm veranschaulicht:
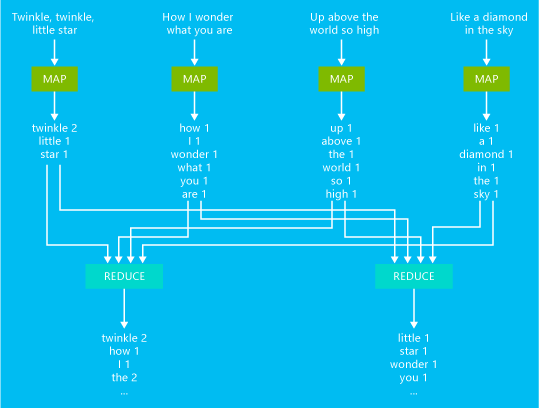
Dieses Auftrag gibt die Anzahl der Vorkommen jedes Worts im Text aus.
- Der Mapper verwendet die einzelnen Zeilen des Eingabetexts als Eingabe und unterteilt diese in Wörter. Er gibt bei jedem Vorkommen eines Worts ein Schlüssel-Wert-Paar des Worts gefolgt von 1 aus. Die Ausgabe wird sortiert, bevor sie an den Reducer gesendet wird.
- Der Reducer addiert die einzelnen Zählwerte jedes Worts und gibt ein einziges Schlüssel-Wert-Paar aus, das aus dem Wort gefolgt von der Summe seiner Vorkommen besteht.
MapReduce kann in verschiedenen Sprachen implementiert werden. Java ist die am häufigsten verwendete Implementierung und wird in diesem Dokument zu Demonstrationszwecken verwendet.
Entwicklungssprachen
Sprachen oder Frameworks auf der Grundlage von Java und Java Virtual Machine können direkt als MapReduce-Auftrag ausgeführt werden. Das in diesem Artikel verwendete Beispiel ist eine Java-MapReduce-Anwendung. Nicht Java-basierte Sprachen (etwa C# oder Python) bzw. eigenständige ausführbare Dateien müssen Hadoop-Datenströme verwenden.
Hadoop-Datenströme kommunizieren über STDIN und STDOUT mit Mapper und Reducer. Mapper und Reducer lesen zeilenweise Daten aus STDIN, und schreiben die Ausgabe in STDOUT. Jede vom Mapper und vom Reducer gelesene oder ausgegebene Zeile muss als Schlüssel-Wert-Paar mit Tabstopptrennzeichen formatiert sein:
[key]\t[value]
Weitere Informationen finden Sie unter Hadoop Streaming(in englischer Sprache).
Beispiele für die Verwendung von Hadoop-Datenströmen mit HDInsight finden Sie in dem folgenden Artikel:
Erste Schritte
- Schnellstart: Erstellen eines Apache Hadoop-Clusters in Azure HDInsight im Azure-Portal
- Tutorial: Übermitteln von Apache Hadoop-Aufträgen in HDInsight
- Entwickeln von Java MapReduce-Programmen für Apache Hadoop in HDInsight
- Verwenden von Apache Hive als Tool zum Extrahieren, Transformieren und Laden (ETL)
- Bedarfsorientiertes Extrahieren, Transformieren und Laden (ETL)
- Operationalisieren einer Datenanalysepipeline