Von Azure HDInsight unterstützte Hochverfügbarkeitsdienste
HDInsight wurde mit einer einzigartigen Architektur entwickelt, um Hochverfügbarkeit (HA) wichtiger Dienste sicherzustellen und Ihnen ein optimales Maß an Verfügbarkeit für Ihre Analysekomponenten bereitzustellen. Einige Komponenten dieser Architektur wurden von Microsoft zur Bereitstellung eines automatischen Failovers entwickelt. Andere Komponenten sind standardmäßige Apache-Komponenten, die zur Unterstützung bestimmter Dienste bereitgestellt werden. In diesem Artikel wird die Architektur des Hochverfügbarkeitsdienst-Modells in HDInsight erläutert und erklärt, wie HDInsight Failover für Hochverfügbarkeitsdienste unterstützt. Außerdem werden bewährte Methoden für die Wiederherstellung nach anderen Dienstunterbrechungen vorgestellt.
Hinweis
Dieser Artikel enthält Verweise auf den Begriff Slave, einen Begriff, den Microsoft nicht mehr verwendet. Sobald der Begriff aus der Software entfernt wurde, wird er auch aus diesem Artikel entfernt.
Hochverfügbarkeitsinfrastruktur
HDInsight stellt eine angepasste Infrastruktur bereit, um sicherzustellen, dass vier primäre Dienste hoch verfügbar sind und automatische Failoverfunktionen bieten:
- Apache Ambari-Server
- Anwendungszeitachsenserver für Apache YARN
- Auftragsverlaufsserver für Hadoop MapReduce
- Apache Livy
Diese Infrastruktur besteht aus einer Reihe von Diensten und Softwarekomponenten, von denen einige von Microsoft entwickelt wurden. Die folgenden Komponenten sind einzigartig für die HDInsight-Plattform:
- Untergeordneter Failovercontroller (sekundär)
- Übergeordneter Failovercontroller (Master)
- Untergeordneter Hochverfügbarkeitsdienst (sekundär)
- Übergeordneter Hochverfügbarkeitsdienst (Master)
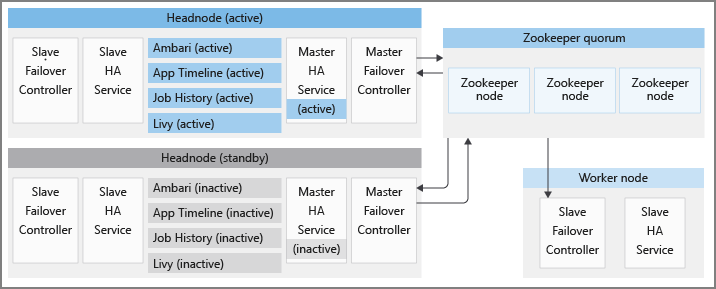
Es gibt noch weitere Hochverfügbarkeitsdienste, die von Zuverlässigkeitskomponenten für Open-Source-Apache unterstützt werden. Diese Komponenten sind auch in HDInsight-Clustern enthalten:
- Hadoop Distributed File System (HDFS) NameNode
- YARN ResourceManager
- HBase Master
In den folgenden Abschnitten finden Sie weitere Informationen zur Interaktion dieser Dienste.
HDInsight-Hochverfügbarkeitsdienste
Microsoft bietet Unterstützung für die vier Apache-Dienste in der folgenden Tabelle in HDInsight-Clustern. Um sie von den von Apache-Komponenten unterstützten Hochverfügbarkeitsdiensten zu unterscheiden, werden Sie als HDInsight-Hochverfügbarkeitsdienste bezeichnet.
| Dienst | Clusterknoten | Clustertypen | Zweck |
|---|---|---|---|
| Apache Ambari-Server | Aktiver Hauptknoten | All | Überwacht und verwaltet den Cluster. |
| Anwendungszeitachsenserver für Apache YARN | Aktiver Hauptknoten | Alle außer Kafka | Verwaltet Debuginformationen über YARN-Aufträge, die auf dem Cluster ausgeführt werden. |
| Auftragsverlaufsserver für Hadoop MapReduce | Aktiver Hauptknoten | Alle außer Kafka | Verwaltet Debugdaten für MapReduce-Aufträge. |
| Apache Livy | Aktiver Hauptknoten | Spark | Ermöglicht die einfache Interaktion mit einem Spark-Cluster über eine REST-Schnittstelle. |
Hinweis
HDInsight-ESP-Cluster (Enterprise-Sicherheitspaket, Enterprise Security Package) bieten zurzeit nur Hochverfügbarkeit für den Ambari-Server. Anwendungszeitachsenserver, Auftragsverlaufsserver und Livy werden alle nur auf Headnode0 ausgeführt, und bei einem Failover von Ambari erfolgt kein Failover auf Headnode1. Die Anwendungszeitachsen-Datenbank befindet sich ebenfalls auf Headnode0, nicht auf dem Ambari SQL-Server.
Aufbau
Jeder HDInsight-Cluster verfügt über zwei Hauptknoten im aktiven bzw. Standbymodus. Die HDInsight-Hochverfügbarkeitsdienste werden nur auf Hauptknoten ausgeführt. Diese Dienste sollten immer auf dem aktiven Hauptknoten ausgeführt werden und auf dem Standbyhauptknoten angehalten und in den Wartungsmodus versetzt werden.
Um die korrekten Zustände der Hochverfügbarkeitsdienste aufrechtzuerhalten und ein schnelles Failover bereitzustellen, nutzt HDInsight Apache ZooKeeper, einen Koordinationsdienst für verteilte Anwendungen, zur Auswahl des aktiven Hauptknotens. HDInsight stellt außerdem einige Java-Hintergrundprozesse bereit, die das Failover für HDInsight-Hochverfügbarkeitsdienste koordinieren. Dabei handelt es sich um die folgenden Dienste: den übergeordneten (primären) Failovercontroller, den untergeordneten (sekundären) Failovercontroller, den master-ha-service und den slave-ha-service.
Apache ZooKeeper
Apache ZooKeeper ist ein leistungsstarker Koordinationsdienst für verteilte Anwendungen. In der Produktionsumgebung wird ZooKeeper normalerweise im replizierten Modus ausgeführt, in dem eine replizierte Gruppe von ZooKeeper-Servern ein Quorum bildet. Jeder HDInsight-Cluster verfügt über drei ZooKeeper-Knoten, die es drei ZooKeeper-Servern ermöglichen, ein Quorum zu bilden. HDInsight verfügt über zwei parallele ZooKeeper-Quoren. Ein Quorum entscheidet über den aktiven Hauptknoten in einem Cluster, auf dem HDInsight-Hochverfügbarkeitsdienste ausgeführt werden sollen. Ein anderes Quorum wird zum Koordinieren der von Apache bereitgestellten Hochverfügbarkeitsdienste verwendet, wie in späteren Abschnitten erläutert.
Untergeordneter Failovercontroller (sekundär)
Der untergeordnete Failovercontroller wird auf jedem Knoten in einem HDInsight-Cluster ausgeführt. Dieser Controller ist dafür verantwortlich, den Ambari-Agent und slave-ha-service auf jedem Knoten zu starten. Er fragt in regelmäßigen Abständen den aktiven Hauptknoten beim ersten ZooKeeper-Quorum ab. Wenn sich die aktiven und Standbyhauptknoten ändern, führt der untergeordnete Failovercontroller folgende Schritte aus:
- Die Hostkonfigurationsdatei wird aktualisiert.
- Der Ambari-Agent wird neu gestartet.
Der slave-ha-service ist für das Beenden der HDInsight-Hochverfügbarkeitsdienste (mit Ausnahme des Ambari-Servers) auf dem Standbyhauptknoten verantwortlich.
Übergeordneter Failovercontroller (Master)
Auf beiden Hauptknoten wird ein übergeordneter Failovercontroller ausgeführt. Beide übergeordneten Failovercontroller kommunizieren mit dem ersten ZooKeeper-Quorum, um den Hauptknoten, auf dem Sie ausgeführt werden, als aktiven Hauptknoten zu nominieren.
Wenn der übergeordnete Failovercontroller z.B. auf Hauptknoten 0 den Auswahlprozess für sich entscheidet, werden die folgenden Änderungen durchgeführt:
- Hauptknoten 0 wird aktiv.
- Der übergeordnete Failovercontroller startet den Ambari-Server und den master-ha-service auf Hauptknoten 0.
- Der andere übergeordnete Failovercontroller beendet den Ambari-Server und den master-ha-service auf Hauptknoten 1.
Der master-ha-service wird nur auf dem aktiven Hauptknoten ausgeführt. Die HDInsight-Hochverfügbarkeitsdienste (mit Ausnahme des Ambari-Servers) auf dem Standbyhauptknoten werden angehalten und auf dem aktiven Hauptknoten gestartet.
Der Failoverprozess
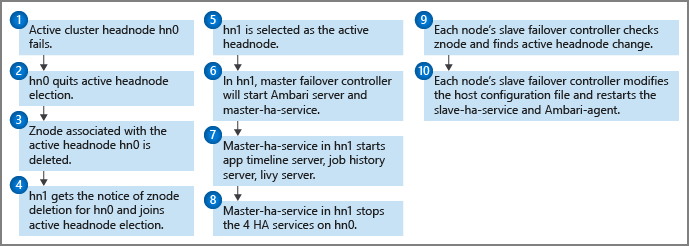
Auf jedem Hauptknoten wird zusammen mit dem übergeordneten Failovercontroller ein Integritätsmonitor ausgeführt, der Heartbeatbenachrichtigungen an das Zookeeper-Quorum sendet. Der Hauptknoten wird in diesem Szenario als Hochverfügbarkeitsdienst betrachtet. Der Integritätsmonitor überprüft, ob jeder Hochverfügbarkeitsdienst fehlerfrei und bereit ist, an der Auswahl der übergeordneten Instanz teilzunehmen. Wenn ja, wird dieser Hauptknoten bei der Auswahl berücksichtigt. Wenn nicht, wird die Auswahl beendet, bis der Knoten wieder bereit ist.
Wenn der Standbyhauptknoten jemals zum Hauptknoten gewählt und aktiv wird (z.B. bei einem Fehler auf dem bisherigen aktiven Knoten), startet sein übergeordneter Failovercontroller darauf alle HDInsight-Hochverfügbarkeitsdienste. Der übergeordnete Failovercontroller beendet diese Dienste auf dem anderen Hauptknoten.
Bei Ausfällen des HDInsight-Hochverfügbarkeitsdiensts, z.B. einem ausgefallenen oder fehlerhaften Dienst, sollte der übergeordnete Failovercontroller die Dienste entsprechend dem Hauptknotenstatus automatisch neu starten oder beenden. Benutzer sollten HDInsight-Hochverfügbarkeitsdienste nicht manuell auf beiden Hauptknoten starten. Lassen Sie stattdessen automatisches oder manuelles Failover zu, damit der Dienst wiederhergestellt werden kann.
Unbeabsichtigter manueller Eingriff
HDInsight-Hochverfügbarkeitsdienste sollten nur auf dem aktiven Hauptknoten ausgeführt werden und werden bei Bedarf automatisch neu gestartet. Da einzelne Hochverfügbarkeitsdienste über keinen eigenen Integritätsmonitor verfügen, kann das Failover nicht auf der Ebene einzelner Dienste ausgelöst werden. Das Failover wird auf Knotenebene und nicht auf Dienstebene sichergestellt.
Einige bekannte Probleme
Wird ein Hochverfügbarkeitsdienst manuell auf dem Standbyhauptknoten gestartet, wird er erst beendet, wenn das nächste Failover stattfindet. Wenn Hochverfügbarkeitsdienste auf beiden Hauptknoten ausgeführt werden, können unter anderem die folgenden Probleme auftreten: Der Zugriff auf die Ambari-Benutzeroberfläche ist nicht möglich, Ambari löst Fehler aus, YARN-, Spark- und Oozie-Aufträge können hängen bleiben.
Wenn ein Hochverfügbarkeitsdienst auf dem aktiven Hauptknoten beendet wird, wird er erst wieder gestartet, wenn das nächste Failover erfolgt oder der übergeordnete Failovercontroller/master-ha-service neu gestartet wird. Wenn ein oder mehrere Hochverfügbarkeitsdienste auf dem aktiven Hauptknoten beendet werden, insbesondere wenn der Ambari-Server beendet wird, kann auf die Ambari-Benutzeroberfläche nicht zugegriffen werden. Weitere mögliche Probleme sind YARN-, Spark- und Oozie-Fehler.
Apache-Hochverfügbarkeitsdienste
Apache bietet hohe Verfügbarkeit für HDFS NameNode, YARN ResourceManager und HBase Master, die auch in HDInsight-Clustern verfügbar sind. Im Gegensatz zu HDInsight-Hochverfügbarkeitsdiensten werden diese in ESP-Clustern unterstützt. Apache-Hochverfügbarkeitsdienste kommunizieren mit dem zweiten Zookeeper-Quorum (im obigen Abschnitt beschrieben), um den Aktiv/Standby-Status auszuwählen und ein automatisches Failover durchzuführen. In den folgenden Abschnitten wird erläutert, wie diese Dienste funktionieren.
Hadoop Distributed File System (HDFS) NameNode
HDInsight-Cluster, die auf Apache Hadoop 2.0 oder höher basieren, bieten NameNode-Hochverfügbarkeit. Auf den Hauptknoten, die für automatisches Failover konfiguriert sind, werden zwei NameNodes ausgeführt. Die NameNodes verwenden den ZKFailoverController für die Kommunikation mit Zookeeper, um den Aktiv/Standby-Status auszuwählen. Der ZKFailoverController wird auf beiden Hauptknoten ausgeführt und funktioniert auf die gleiche Weise wie der übergeordnete Failovercontroller.
Das zweite Zookeeper-Quorum ist unabhängig vom ersten Quorum, sodass der aktive NameNode möglicherweise nicht auf dem aktiven Hauptknoten ausgeführt wird. Wenn der aktive NameNode nicht verfügbar oder fehlerhaft ist, entscheidet der Standby-NameNode den Auswahlprozess für sich und wird aktiv.
YARN ResourceManager
HDInsight-Cluster, die auf Apache Hadoop 2.4 oder höher basieren, unterstützen YARN ResourceManager-Hochverfügbarkeit. Es gibt zwei ResourceManager, RM1 und RM2, die auf Hauptknoten 0 bzw. Hauptknoten 1 ausgeführt werden. Wie bei NameNode ist auch YARN ResourceManager für automatisches Failover konfiguriert. Ein weiterer ResourceManager wird automatisch als aktiv ausgewählt, wenn der aktuelle aktive ResourceManager ausfällt oder nicht mehr reagiert.
YARN ResourceManager verwendet den eingebetteten ActiveStandbyElector als Fehlererkennung und zur Auswahl der übergeordneten Instanz. Im Gegensatz zu HDFS NameNode benötigt YARN ResourceManager keinen separaten ZKFC-Daemon. Der aktive ResourceManager schreibt seine Zustände in Apache Zookeeper.
Die hohe Verfügbarkeit von YARN ResourceManager ist von NameNode und anderen HDInsight-Hochverfügbarkeitsdiensten unabhängig. Der aktive ResourceManager kann möglicherweise nicht auf dem aktiven Hauptknoten oder auf dem Hauptknoten ausgeführt werden, auf dem der aktive NameNode ausgeführt wird. Weitere Informationen zur Hochverfügbarkeit von YARN ResourceManager finden Sie unter ResourceManager High Availability (Hochverfügbarkeit von ResourceManager).
HBase Master
HDInsight HBase-Cluster unterstützen HBase Master-Hochverfügbarkeit. Im Gegensatz zu anderen auf Hauptknoten ausgeführten Hochverfügbarkeitsdiensten werden HBase Master-Instanzen auf den drei Zookeeper-Knoten ausgeführt, wobei eine davon die aktive Masterinstanz ist und die beiden anderen Standbyinstanzen sind. Genau wie NameNode koordiniert HBase Master mit Apache Zookeeper die Auswahl der übergeordneten Instanz und führt ein automatisches Failover aus, wenn auf der aktuellen aktiven Masterinstanz Probleme auftreten. Es ist immer nur ein aktiver HBase Master vorhanden.