Archivierte Versionshinweise
Zusammenfassung
Azure HDInsight ist unter Enterprisekunden einer der beliebtesten Dienste für Open-Source-Analysen in Azure. Abonnieren Sie die HDInsight-Versionshinweise, die aktuelle Informationen zu HDInsight und allen HDInsight-Versionen enthalten.
Klicken Sie zum Abonnieren auf die Schaltfläche „Ansehen“ im Banner, und prüfen Sie auf neue HDInsight-Releases.
Informationen zu dieser Version
Veröffentlichungsdatum: 15. Februar 2024
Dieses Release gilt für die HDInsight-Versionen 4.x und 5.x. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Dieses Release gilt für die Imagenummer 2401250802. Wie überprüft man die Image-Nummer?
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
Betriebssystemversionen
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Hinweis
Ubuntu 18.04 wird unter ESM (Extended Security Maintenance) vom Azure Linux-Team ab dem Release Azure HDInsight Juli 2023 unterstützt.
Informationen zu workload-spezifischen Versionen finden Sie
Neue Funktionen
- Apache Ranger-Unterstützung für Spark SQL in Spark 3.3.0 (HDInsight Version 5.1) mit Enterprise-Sicherheitspaket. Weitere Informationen dazu finden Sie hier.
Behobene Probleme
- Sicherheitsupdates von Ambari- und Oozie-Komponenten
 Bald verfügbar
Bald verfügbar
- Einstellung von VMs der Basic- und Standard-A-Serie
- Am 31. August 2024 werden die Basic- und Standard-VMs der A-Serie ausgemustert. Vor diesem Datum müssen Sie Ihre Workloads auf VMs der Av2-Serie migrieren, die mehr Arbeitsspeicher pro vCPU und schnelleren Speicher auf SSD-Laufwerken (Solid State Drive) bieten.
- Um Dienstunterbrechungen zu vermeiden, migrieren Sie Ihre Workloads von VMs der Basic- und Standard-A-Serie vor dem 31. August 2024 zu VMs der Av2-Serie.
Sollten Sie weitere Fragen haben, wenden Sie sich an den Azure-Support.
Sie können uns Fragen zu HDInsight jederzeit im Microsoft Q&A zu Azure HDInsight stellen
Wir hören zu: Unter HDInsight Ideas können Sie gerne weitere Ideen sowie andere Themen hinzufügen und abstimmen. Folgen Sie uns für weitere Neuigkeiten in der Azure HDInsight-Community
Hinweis
Wir empfehlen Kunden, die neuesten Versionen von HDInsight-Images zu verwenden, da sie das Beste aus Open Source-Updates, Azure-Updates und Sicherheits-Patches bieten. Weitere Informationen finden Sie unter Bewährte Methoden.
Nächste Schritte
- Azure HDInsight: Häufig gestellte Fragen
- Konfigurieren des Zeitplans für das Patchen des Betriebssystems für Linux-basierte HDInsight-Cluster
- Vorherige Versionshinweise
Azure HDInsight ist unter Enterprisekunden einer der beliebtesten Dienste für Open-Source-Analysen in Azure. Wenn Sie die Anmerkungen zu dieser Version abonnieren möchten, sehen Sie sich die Releases auf diesem GitHub-Repository an.
Veröffentlichungsdatum: 10. Januar 2024
Dieses Hotfixrelease gilt für die HDInsight-Versionen 4.x und 5.x. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Dieses Release gilt für die Imagenummer 2401030422. Wie überprüft man die Image-Nummer?
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
Betriebssystemversionen
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Hinweis
Ubuntu 18.04 wird unter ESM (Extended Security Maintenance) vom Azure Linux-Team ab dem Release Azure HDInsight Juli 2023 unterstützt.
Informationen zu workload-spezifischen Versionen finden Sie
Behobene Probleme
- Sicherheitsupdates von Ambari- und Oozie-Komponenten
Bald verfügbar
- Einstellung von VMs der Basic- und Standard-A-Serie
- Am 31. August 2024 werden die Basic- und Standard-VMs der A-Serie ausgemustert. Vor diesem Datum müssen Sie Ihre Workloads auf VMs der Av2-Serie migrieren, die mehr Arbeitsspeicher pro vCPU und schnelleren Speicher auf SSD-Laufwerken (Solid State Drive) bieten.
- Um Dienstunterbrechungen zu vermeiden, migrieren Sie Ihre Workloads von VMs der Basic- und Standard-A-Serie vor dem 31. August 2024 zu VMs der Av2-Serie.
Sollten Sie weitere Fragen haben, wenden Sie sich an den Azure-Support.
Sie können uns Fragen zu HDInsight jederzeit im Microsoft Q&A zu Azure HDInsight stellen
Wir hören zu: Unter HDInsight Ideas können Sie gerne weitere Ideen sowie andere Themen hinzufügen und abstimmen. Folgen Sie uns für weitere Neuigkeiten in der Azure HDInsight-Community
Hinweis
Wir empfehlen Kunden, die neuesten Versionen von HDInsight-Images zu verwenden, da sie das Beste aus Open Source-Updates, Azure-Updates und Sicherheits-Patches bieten. Weitere Informationen finden Sie unter Bewährte Methoden.
Veröffentlichungsdatum: 26. Oktober 2023
Dieses Release gilt für HDInsight 4.x und 5.x. Das HDInsight-Release wird für alle Regionen mehrere Tage lang verfügbar sein. Dieses Release gilt für die Image-Nummer 2310140056. Wie überprüft man die Image-Nummer?
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
Betriebssystemversionen
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Informationen zu workload-spezifischen Versionen finden Sie
Neuerungen
HDInsight kündigt die allgemeine Verfügbarkeit von HDInsight 5.1 ab dem 1. November 2023 an. Diese Version bietet eine vollständige Stapelaktualisierung der Open Source-Komponenten und der Integrationen von Microsoft.
- Die neuesten Open Source-Versionen – Für HDInsight 5.1 ist die neueste stabile Open-Source-Version verfügbar. Kunden können von allen neuesten Open-Source-Features, Microsoft-Leistungsverbesserungen und Bugfixes profitieren.
- Sicher – Die aktuellsten Versionen enthalten die neuesten Sicherheitsverbesserungen, sowohl Open-Source als auch von Microsoft.
- Niedrigere Gesamtkosten – Dank der Leistungsverbesserungen und der verbesserte Autoskalierung können Kunden die Betriebskosten senken.
Cluster-Berechtigungen für sicheren Speicher
- Kunden können (während der Cluster-Erstellung) angeben, ob ein sicherer Kanal für HDInsight-Cluster-Knoten für die Verbindung des Speicherkontos verwendet werden soll.
HDInsight-Clustererstellung mit benutzerdefinierten VNETs
- Zur Verbesserung des allgemeinen Sicherheitsstatus der HDInsight-Cluster muss für HDInsight-Cluster mit Verwendung benutzerdefinierter VNETs sichergestellt werden, dass die Benutzer*innen über die Berechtigung für
Microsoft Network/virtualNetworks/subnets/join/actionverfügen, um Erstellungsvorgänge ausführen zu können. Es können Fehler bei der Erstellung auftreten, wenn diese Überprüfung nicht aktiviert ist.
- Zur Verbesserung des allgemeinen Sicherheitsstatus der HDInsight-Cluster muss für HDInsight-Cluster mit Verwendung benutzerdefinierter VNETs sichergestellt werden, dass die Benutzer*innen über die Berechtigung für
ABFS-Cluster ohne ESP [Clusterberechtigungen für World Readable]
- ABFS-Cluster ohne Enterprise-Sicherheitspaket hindern Gruppenbenutzer ohne Hadoop an der Ausführung von Hadoop-Befehlen für Speichervorgänge. Diese Änderung dient dazu, den Sicherheitsstatus des Clusters zu verbessern.
Inline-Kontingentaktualisierung
- Jetzt können Sie die Kontingenterhöhung direkt von der Seite „Mein Kontingent“ anfordern, wobei der direkte API-Aufruf viel schneller ist. Wenn der API-Aufruf fehlschlägt, können Sie eine neue Supportanfrage zur Erhöhung des Kontingents erstellen.
Bald verfügbar
Die maximale Länge des Clusternamens wird von 59 auf 45 Zeichen geändert, um den Sicherheitsstatus von Clustern zu verbessern. Diese Änderung wird mit der bevorstehenden Veröffentlichung für alle Regionen eingeführt.
Einstellung von VMs der Basic- und Standard-A-Serie
- Am 31. August 2024 werden die Basic- und Standard-VMs der A-Serie ausgemustert. Vor diesem Datum müssen Sie Ihre Workloads auf VMs der Av2-Serie migrieren, die mehr Arbeitsspeicher pro vCPU und schnelleren Speicher auf SSD-Laufwerken (Solid State Drive) bieten.
- Um Dienstunterbrechungen zu vermeiden, migrieren Sie Ihre Workloads von VMs der Basic- und Standard-A-Serie vor dem 31. August 2024 zu VMs der Av2-Serie.
Sollten Sie weitere Fragen haben, wenden Sie sich an den Azure-Support.
Sie können uns Fragen zu HDInsight jederzeit im Microsoft Q&A zu Azure HDInsight stellen
Wir hören zu: Unter HDInsight Ideas können Sie gerne weitere Ideen sowie andere Themen hinzufügen und abstimmen. Folgen Sie uns für weitere Neuigkeiten in der Azure HDInsight-Community
Hinweis
Dieses Release behandelt die folgenden CVEs, die am 12. September 2023 von MSRC veröffentlicht wurden. Die Aktion besteht darin, auf das neueste Image 2308221128 oder 2310140056 zu aktualisieren. Kunden wird empfohlen, dies entsprechend zu planen.
| CVE | severity | CVE-Titel | Anmerkung |
|---|---|---|---|
| CVE-2023-38156 | Wichtig | Sicherheitsanfälligkeit in Azure HDInsight: Rechteerweiterung in Apache Ambari | Im Image 2308221128 oder 2310140056 enthalten |
| CVE-2023-36419 | Wichtig | Sicherheitsanfälligkeit in Azure HDInsight: Rechteerweiterung in Apache Oozie Workflow Scheduler | Anwenden einer Skriptaktion auf Ihre Cluster oder Aktualisieren auf Image 2310140056 |
Hinweis
Wir empfehlen Kunden, die neuesten Versionen von HDInsight-Images zu verwenden, da sie das Beste aus Open Source-Updates, Azure-Updates und Sicherheits-Patches bieten. Weitere Informationen finden Sie unter Bewährte Methoden.
Veröffentlichungsdatum: 7. September 2023
Dieses Release gilt für HDInsight 4.x und 5.x. Das HDInsight-Release wird für alle Regionen mehrere Tage lang verfügbar sein. Dieses Release gilt für die Image-Nummer 2308221128. Wie überprüft man die Image-Nummer?
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
Betriebssystemversionen
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Informationen zu workload-spezifischen Versionen finden Sie
Wichtig
Dieses Release behandelt die folgenden CVEs, die am 12. September 2023 von MSRC veröffentlicht wurden. Die Aktion besteht darin, auf das neueste Image 2308221128 zu aktualisieren. Kunden wird empfohlen, dies entsprechend zu planen.
| CVE | severity | CVE-Titel | Anmerkung |
|---|---|---|---|
| CVE-2023-38156 | Wichtig | Sicherheitsanfälligkeit in Azure HDInsight: Rechteerweiterung in Apache Ambari | Im Image 2308221128 enthalten |
| CVE-2023-36419 | Wichtig | Sicherheitsanfälligkeit in Azure HDInsight: Rechteerweiterung in Apache Oozie Workflow Scheduler | Anwenden einer Skriptaktion auf Ihre Cluster |
In Kürze verfügbar
- Die maximale Länge des Clusternamens wird von 59 auf 45 Zeichen geändert, um den Sicherheitsstatus von Clustern zu verbessern. Diese Änderung wird bis zum 30. September 30 2023 implementiert.
- Cluster-Berechtigungen für sicheren Speicher
- Kunden können (während der Cluster-Erstellung) angeben, ob ein sicherer Kanal für HDInsight-Cluster-Knoten zum Kontaktieren des Speicherkontos verwendet werden soll.
- Inline-Kontingentaktualisierung
- Anforderungskontingente werden direkt über die Seite „Mein Kontingent“ erhöht. Dies ist ein direkter API-Aufruf und daher schneller. Wenn der APdl-Aufruf fehlschlägt, müssen Kunden eine neue Supportanfrage zur Erhöhung des Kontingents erstellen.
- HDInsight-Clustererstellung mit benutzerdefinierten VNETs
- Zur Verbesserung des allgemeinen Sicherheitsstatus der HDInsight-Cluster muss für HDInsight-Cluster mit Verwendung benutzerdefinierter VNETs sichergestellt werden, dass die Benutzer*innen über die Berechtigung für
Microsoft Network/virtualNetworks/subnets/join/actionverfügen, um Erstellungsvorgänge ausführen zu können. Kunden sollten entsprechend planen, da es sich bei dieser Änderung um eine obligatorische Überprüfung handelt, um Fehler bei der Erstellung von Clustern nach dem 30. September 2023 zu vermeiden.
- Zur Verbesserung des allgemeinen Sicherheitsstatus der HDInsight-Cluster muss für HDInsight-Cluster mit Verwendung benutzerdefinierter VNETs sichergestellt werden, dass die Benutzer*innen über die Berechtigung für
- Einstellung von VMs der Basic- und Standard-A-Serie
- Am 31. August 2024 werden die Basic- und Standard-VMs der A-Serie ausgemustert. Vor diesem Datum müssen Sie Ihre Workloads auf VMs der Av2-Serie migrieren, die mehr Arbeitsspeicher pro vCPU und schnelleren Speicher auf SSD-Laufwerken (Solid State Drive) bieten. Um Dienstunterbrechungen zu vermeiden, migrieren Sie Ihre Workloads von VMs der Basic- und Standard-A-Serie vor dem 31. August 2024 zu VMs der Av2-Serie.
- ABFS-Cluster ohne ESP [Clusterberechtigungen für World Readable]
- Planen Sie die Einführung einer Änderung in ABFS-Clustern ohne Enterprise-Sicherheitspaket, die Gruppenbenutzer ohne Hadoop an der Ausführung von Hadoop-Befehlen für Speichervorgänge hindert. Diese Änderung dient dazu, den Sicherheitsstatus des Clusters zu verbessern. Kunden müssen die Updates vor dem 30. September 2023 einplanen.
Sollten Sie weitere Fragen haben, wenden Sie sich an den Azure-Support.
Sie können uns Fragen zu HDInsight jederzeit im Microsoft Q&A zu Azure HDInsight stellen
In der HDInsight Community (azure.com) können Sie gerne weitere Vorschläge und Ideen sowie andere Themen hinzufügen und abstimmen.
Hinweis
Wir empfehlen Kunden, die neuesten Versionen von HDInsight-Images zu verwenden, da sie das Beste aus Open Source-Updates, Azure-Updates und Sicherheits-Patches bieten. Weitere Informationen finden Sie unter Bewährte Methoden.
Veröffentlichungsdatum: 25. Juli 2023
Dieses Release gilt für HDInsight 4.x und 5.x. Das HDInsight-Release wird für alle Regionen mehrere Tage lang verfügbar sein. Dieses Release gilt für die Imagenummer 2307201242. Wie überprüft man die Image-Nummer?
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
Betriebssystemversionen
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.1: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Informationen zu workload-spezifischen Versionen finden Sie
 Neuigkeiten
Neuigkeiten
- HDInsight 5.1 wird jetzt mit ESP-Clustern unterstützt.
- Aktualisierte Versionen von Ranger 2.3.0 und Oozie 5.2.1 sind jetzt Bestandteil von HDInsight 5.1
- Der Spark 3.3.1-Cluster (HDInsight 5.1) umfasst den Hive Warehouse-Connector 2.1 (HWC), der mit dem Interactive Query-Cluster (HDInsight 5.1) zusammenarbeitet.
- Ubuntu 18.04 wird unter ESM(Extended Security Maintenance) vom Azure Linux-Team für Azure HDInsight Juli 2023 ab Version unterstützt.
Wichtig
Dieses Release behandelt die folgenden CVEs, die am 8. August 2023 von MSRC veröffentlicht wurden. Die Aktion besteht darin, auf das neueste Image 2307201242 zu aktualisieren. Kunden wird empfohlen, dies entsprechend zu planen.
| CVE | severity | CVE-Titel |
|---|---|---|
| CVE-2023-35393 | Wichtig | Spoofing-Sicherheitsrisiko in Azure Apache Hive |
| CVE-2023-35394 | Wichtig | Spoofing-Sicherheitsrisiko in Azure HDInsight-Jupyter Notebook |
| CVE-2023-36877 | Wichtig | Spoofing-Sicherheitsrisiko in Azure Apache Oozie |
| CVE-2023-36881 | Wichtig | Spoofing-Sicherheitsrisiko in Azure Apache Ambari |
| CVE-2023-38188 | Wichtig | Spoofing-Sicherheitsrisiko in Azure Apache Hadoop |
Bald verfügbar
- Die maximale Länge des Clusternamens wird von 59 auf 45 Zeichen geändert, um den Sicherheitsstatus von Clustern zu verbessern. Kunden müssen die Updates vor dem 30. September 2023 einplanen.
- Cluster-Berechtigungen für sicheren Speicher
- Kunden können (während der Cluster-Erstellung) angeben, ob ein sicherer Kanal für HDInsight-Cluster-Knoten zum Kontaktieren des Speicherkontos verwendet werden soll.
- Inline-Kontingentaktualisierung
- Anforderungskontingente werden direkt über die Seite „Mein Kontingent“ erhöht. Dies ist ein direkter API-Aufruf und daher schneller. Wenn der API-Aufruf fehlschlägt, müssen Kunden eine neue Supportanfrage zur Erhöhung des Kontingents erstellen.
- HDInsight-Clustererstellung mit benutzerdefinierten VNETs
- Zur Verbesserung des allgemeinen Sicherheitsstatus der HDInsight-Cluster muss für HDInsight-Cluster mit Verwendung benutzerdefinierter VNETs sichergestellt werden, dass die Benutzer*innen über die Berechtigung für
Microsoft Network/virtualNetworks/subnets/join/actionverfügen, um Erstellungsvorgänge ausführen zu können. Kunden sollten entsprechend planen, da es sich bei dieser Änderung um eine obligatorische Überprüfung handelt, um Fehler bei der Erstellung von Clustern nach dem 30. September 2023 zu vermeiden.
- Zur Verbesserung des allgemeinen Sicherheitsstatus der HDInsight-Cluster muss für HDInsight-Cluster mit Verwendung benutzerdefinierter VNETs sichergestellt werden, dass die Benutzer*innen über die Berechtigung für
- Einstellung von VMs der Basic- und Standard-A-Serie
- Am 31. August 2024 werden die Basic- und Standard-VMs der A-Serie ausgemustert. Vor diesem Datum müssen Sie Ihre Workloads auf VMs der Av2-Serie migrieren, die mehr Arbeitsspeicher pro vCPU und schnelleren Speicher auf SSD-Laufwerken (Solid State Drive) bieten. Um Dienstunterbrechungen zu vermeiden, migrieren Sie Ihre Workloads von VMs der Basic- und Standard-A-Serie vor dem 31. August 2024 zu VMs der Av2-Serie.
- ABFS-Cluster ohne ESP [Clusterberechtigungen für World Readable]
- Planen Sie die Einführung einer Änderung in ABFS-Clustern ohne Enterprise-Sicherheitspaket, die Gruppenbenutzer ohne Hadoop an der Ausführung von Hadoop-Befehlen für Speichervorgänge hindert. Diese Änderung dient dazu, den Sicherheitsstatus des Clusters zu verbessern. Kund*innen müssen die Updates vor dem 30. September 2023 einplanen.
Sollten Sie weitere Fragen haben, wenden Sie sich an den Azure-Support.
Sie können uns Fragen zu HDInsight jederzeit im Microsoft Q&A zu Azure HDInsight stellen
In der HDInsight Community (azure.com) können Sie gerne weitere Vorschläge und Ideen sowie andere Themen hinzufügen und abstimmen. Hier können Sie uns auf Twitter folgen.
Hinweis
Wir empfehlen Kunden, die neuesten Versionen von HDInsight-Images zu verwenden, da sie das Beste aus Open Source-Updates, Azure-Updates und Sicherheits-Patches bieten. Weitere Informationen finden Sie unter Bewährte Methoden.
Veröffentlichungsdatum: 08. Mai 2023
Dieses Release gilt für HDInsight 4.x und 5.x. Das HDInsight-Release wird für alle Regionen mehrere Tage lang verfügbar sein. Dieses Release gilt für die Image-Nummer 2304280205. Wie überprüft man die Image-Nummer?
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
Betriebssystemversionen
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Informationen zu workload-spezifischen Versionen finden Sie
![]()
Azure HDInsight 5.1 aktualisiert mit
- Apache HBase 2.4.11
- Apache Phoenix 5.1.2
- Apache Hive 3.1.2
- Apache Spark 3.3.1
- Apache Tez 0.9.1
- Apache Zeppelin 0.10.1
- Apache Livy 0.5
- Apache Kafka 3.2.0
Hinweis
- Alle Komponenten sind in Hadoop 3.3.4 und ZK 3.6.3 integriert
- Alle oben aktualisierten Komponenten sind jetzt in Nicht-ESP-Clustern für die öffentliche Vorschau verfügbar.
![]()
Erweiterte Autoskalierung für HDInsight
Azure HDInsight hat die Stabilität und Latenz bei der automatischen Skalierung erheblich verbessert. Die wesentlichen Änderungen umfassen eine verbesserte Feedbackschleife für Skalierungsentscheidungen, eine deutliche Verbesserung der Latenz für die Skalierung und Unterstützung für die Wiedereinsetzung der außer Betrieb gesetzten Knoten. Erfahren Sie mehr über die Erweiterungen und wie Sie Ihren Cluster benutzerdefiniert konfigurieren und zu einer verbesserten Autoskalierung migrieren können. Die erweiterte Autoskalierungsfunktion ist ab dem 17. Mai 2023 in allen unterstützten Regionen verfügbar.
Azure HDInsight ESP für Apache Kafka 2.4.1 ist jetzt allgemein verfügbar.
Azure HDInsight ESP für Apache Kafka 2.4.1 befindet sich seit April 2022 in der öffentlichen Vorschauphase. Nach bedeutenden Verbesserungen bei CVE-Fixes und -Stabilität ist Azure HDInsight ESP Kafka 2.4.1 jetzt allgemein verfügbar und bereit für Produktionsworkloads. Hier finden Sie weitere Informationen zur Konfiguration und zur Migration.
Kontingentverwaltung für HDInsight
HDInsight ordnet Kundenabonnements derzeit Kontingente auf regionaler Ebene zu. Die Kunden zugeordneten Kerne sind generisch und nicht auf VM-Familienebene klassifiziert (z. B.
Dv2,Ev3,Eav4usw.).HDInsight hat eine verbesserte Ansicht eingeführt, die Details und eine Klassifizierung von Kontingenten für VMs auf Familienebene bietet. Mit diesem Feature können Kunden aktuelle und verbleibende Kontingente für eine Region auf VM-Familienebene anzeigen. Die erweiterte Ansicht bieten den Kunden eine umfassendere Transparenz für die Planung von Kontingenten sowie eine bessere Benutzererfahrung. Dieses Feature ist derzeit in HDInsight 4.x und 5.x für die EUAP-Region „USA, Osten“ verfügbar. Weitere Regionen werden später folgen.
Weitere Informationen finden Sie unter Anzeigen der Kontingentverwaltung für HDInsight | Microsoft Learn.
![]()
- Polen, Mitte
- Die maximale Länge des Clusternamens wird von 59 in 45 Zeichen geändert, um den Sicherheitsstatus von Clustern zu verbessern.
- Cluster-Berechtigungen für sicheren Speicher
- Kunden können (während der Cluster-Erstellung) angeben, ob ein sicherer Kanal für HDInsight-Cluster-Knoten zum Kontaktieren des Speicherkontos verwendet werden soll.
- Inline-Kontingentaktualisierung
- Anforderungskontingente werden direkt über die Seite „Mein Kontingent“ erhöht. Dies ist ein direkter API-Aufruf und daher schneller. Wenn der API-Aufruf fehlschlägt, müssen Kunden eine neue Supportanfrage zur Erhöhung des Kontingents erstellen.
- HDInsight-Clustererstellung mit benutzerdefinierten VNETs
- Zur Verbesserung des allgemeinen Sicherheitsstatus der HDInsight-Cluster muss für HDInsight-Cluster mit Verwendung benutzerdefinierter VNETs sichergestellt werden, dass die Benutzer*innen über die Berechtigung für
Microsoft Network/virtualNetworks/subnets/join/actionverfügen, um Erstellungsvorgänge ausführen zu können. Kunden müssten entsprechend planen, da dies eine obligatorische Überprüfung ist, um Fehler bei der Clustererstellung zu vermeiden.
- Zur Verbesserung des allgemeinen Sicherheitsstatus der HDInsight-Cluster muss für HDInsight-Cluster mit Verwendung benutzerdefinierter VNETs sichergestellt werden, dass die Benutzer*innen über die Berechtigung für
- Einstellung von VMs der Basic- und Standard-A-Serie
- Am 31. August 2024 werden die Basic- und Standard-VMs der A-Serie ausgemustert. Vor diesem Datum müssen Sie Ihre Workloads auf VMs der Av2-Serie migrieren, die mehr Arbeitsspeicher pro vCPU und schnelleren Speicher auf SSD-Laufwerken (Solid State Drive) bieten. Um Dienstunterbrechungen zu vermeiden, migrieren Sie Ihre Workloads von VMs der Basic- und Standard-A-Serie vor dem 31. August 2024 zu VMs der Av2-Serie.
- ABFS-Cluster ohne Enterprise-Sicherheitspaket [Cluster-Berechtigungen für World Readable]
- Planen Sie die Einführung einer Änderung in ABFS-Clustern ohne Enterprise-Sicherheitspaket, die Gruppenbenutzer ohne Hadoop an der Ausführung von Hadoop-Befehlen für Speichervorgänge hindert. Diese Änderung dient dazu, den Sicherheitsstatus des Clusters zu verbessern. Kunden müssen die Updates planen.
Veröffentlichungsdatum: 28. Februar 2023
Dieses Release gilt für HDInsight 4.0. und 5.0, 5.1. Das HDInsight-Release ist mehrere Tage lang für alle Regionen verfügbar. Dieses Release gilt für die Image-Nummer 2302250400. Wie überprüft man die Image-Nummer?
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
Betriebssystemversionen
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Informationen zu workload-spezifischen Versionen finden Sie
Wichtig
Microsoft hat CVE-2023-23408 veröffentlicht, die in der aktuellen Version behoben sind, und Kunden wird empfohlen, ein Upgrade ihres Clusters auf das neueste Image zu durchzuführen.
![]()
HDInsight 5.1
Wir haben mit dem Rollout einer neuen Version von HDInsight 5.1 begonnen. Alle neuen Open-Source-Releases werden als inkrementelle Releases auf HDInsight 5.1 hinzugefügt.
Weitere Informationen finden Sie unter HDInsight 5.1.0-Version
![]()
Kafka 3.2.0-Upgrade (Vorschau)
- Kafka 3.2.0 enthält mehrere wichtige neue Features/Verbesserungen.
- Zookeeper auf 3.6.3 geupgradet
- Unterstützung für Kafka Streams
- Höhere Liefergarantien für den standardmäßig aktivierten Kafka Producer.
log4j1.x ersetzt durchreload4j.- Senden Sie einen Hinweis an den Partitionsleiter, um die Partition wiederherzustellen.
JoinGroupRequestundLeaveGroupRequesthaben einen Grund angefügt.- Broker-Anzahlmetriken8 hinzugefügt.
- Mirror
Maker2Verbesserungen.
HBase 2.4.11-Upgrade (Vorschau)
- Diese Version bietet neue Features, z. B. das Hinzufügen neuer Cache-Mechanismustypen für den Block-Cache, die Möglichkeit, die Tabelle über die HBase-WEB-Benutzeroberfläche zu ändern
hbase:meta tableund anzuzeigenhbase:meta.
Phoenix 5.1.2-Upgrade (Vorschau)
- Die Phoenix-Version wurde in diesem Release auf 5.1.2 upgegradet. Dieses Upgrade umfasst den Phoenix Query Server. Der Phoenix Query Server stellt den standardmäßigen Phoenix JDBC-Treiber als Proxy und ein abwärtskompatibles Wire-Protokoll zum Aufrufen dieses JDBC-Treibers bereit.
Ambari-CVEs
- Mehrere Ambari-CVEs sind behoben.
Hinweis
ESP wird in dieser Version nicht für Kafka und HBase unterstützt.
![]()
Ende der Unterstützung für Azure HDInsight-Cluster in Spark 2.4 am 10. Februar 2024. Weitere Informationen finden Sie unter Unterstützte Spark-Versionen in Azure HDInsight
Nächste Schritte
- Autoscale
- Automatische Skalierung mit verbesserter Latenz und mehreren Verbesserungen
- Einschränkung der Änderung des Cluster-Namens
- Die maximale Länge des Clusternamens wird in Public, Azure China und Azure Government in 45 von 59 geändert.
- Cluster-Berechtigungen für sicheren Speicher
- Kunden können (während der Cluster-Erstellung) angeben, ob ein sicherer Kanal für HDInsight-Cluster-Knoten zum Kontaktieren des Speicherkontos verwendet werden soll.
- ABFS-Cluster ohne Enterprise-Sicherheitspaket [Cluster-Berechtigungen für World Readable]
- Planen Sie die Einführung einer Änderung in ABFS-Clustern ohne Enterprise-Sicherheitspaket, die Gruppenbenutzer ohne Hadoop an der Ausführung von Hadoop-Befehlen für Speichervorgänge hindert. Diese Änderung dient dazu, den Sicherheitsstatus des Clusters zu verbessern. Kunden müssen die Updates planen.
- Open-Source-Upgrades
- Apache Spark 3.3.0 und Hadoop 3.3.4 werden in HDInsight 5.1 entwickelt und enthalten einige wichtige neue Features, Leistungsverbesserungen und andere Verbesserungen.
Hinweis
Wir empfehlen Kunden, die neuesten Versionen von HDInsight-Images zu verwenden, da sie das Beste aus Open Source-Updates, Azure-Updates und Sicherheits-Patches bieten. Weitere Informationen finden Sie unter Bewährte Methoden.
Veröffentlichungsdatum: 12. Dezember 2022
Dieses Release gilt für HDInsight 4.0. Das HDInsight 5.0-Release wird über mehrere Tage für alle Regionen verfügbar gemacht.
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
Betriebssystemversionen
- HDInsight 4.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
- HDInsight 5.0: Ubuntu 18.04.5 LTS Linux Kernel 5.4
Informationen zu workloadspezifischen Versionen finden Sie hier.
![]()
- Log Analytics: Kunden können die klassische Überwachung aktivieren, um die neueste OMS-Version 14.19 zu erhalten. Um alte Versionen zu entfernen, deaktivieren und aktivieren Sie die klassische Überwachung.
- Automatische Benutzeroberflächenabmeldung von Ambari-Benutzern aufgrund von Inaktivität. Weitere Informationen finden Sie hier.
- Spark: In diesem Release ist eine neue und optimierte Version von Spark 3.1.3 enthalten. Wir haben Apache Spark 3.1.2 (vorherige Version) und Apache Spark 3.1.3 (aktuelle Version) mithilfe der TPC-DS-Benchmark getestet. Der Test wurde mit der E8 V3-SKU für Apache Spark für eine Workload mit 1 TB durchgeführt. Apache Spark 3.1.3 (aktuelle Version) übertraf Apache Spark 3.1.2 (Vorgängerversion) unter Verwendung derselben Hardwarespezifikationen bei der Gesamtlaufzeit von TPC-DS-Abfragen um mehr als 40 %. Das Microsoft Spark-Team hat Optimierungen hinzugefügt, die in Azure Synapse mit Azure HDInsight verfügbar sind. Weitere Informationen finden Sie unter Beschleunigen Ihrer Datenworkloads mit Leistungsupdates für Apache Spark 3.1.2 in Azure Synapse.
![]()
- Katar, Mitte
- Deutschland, Norden
![]()
HDInsight ist von Azul Zulu Java JDK 8 zu
Adoptium Temurin JDK 8gewechselt, um hochwertige TCK-zertifizierte Runtimes und zugehörige Technologie für die Verwendung im gesamten Java-Ökosystem zu unterstützen.HDInsight wurde zu
reload4jmigriert. Dielog4j-Änderungen gelten für- Apache Hadoop
- Apache Zookeeper
- Apache Oozie
- Apache Ranger
- Apache Sqoop
- Apache Pig
- Apache Ambari
- Apache Kafka
- Apache Spark
- Apache Zeppelin
- Apache Livy
- Apache Rubix
- Apache Hive
- Apache Tez
- Apache HBase
- OMI
- Apache Pheonix
![]()
HDInsight implementiert TLS1.2 in Zukunft, und frühere Versionen werden auf der Plattform aktualisiert. Wenn Sie Anwendungen zusätzlich zu HDInsight ausführen und diese TLS 1.0 und 1.1 verwenden, führen Sie ein Upgrade auf TLS 1.2 durch, um Dienstunterbrechungen zu vermeiden.
Weitere Informationen finden Sie unter Aktivieren von TLS 1.2 auf Clients.
![]()
Am 30. November 2022 läuft der Support für Azure HDInsight-Cluster unter Ubuntu 16.04 LTS ab. HDInsight beginnt am 27. Juni 2021 mit der Veröffentlichung von Clusterimages mittels Ubuntu 18.04. Unseren Kunden, die Cluster mit Ubuntu 16.04 ausführen, wird empfohlen, ihre Cluster bis zum 30. November 2022 mit den neuesten HDInsight-Images neu zu erstellen.
Weitere Informationen zum Überprüfen der Ubuntu-Version des Clusters finden Sie hier.
Führen Sie den Befehl „lsb_release -a“ im Terminal aus.
Wenn der Wert für die Eigenschaft „Description“ in der Ausgabe „Ubuntu 16.04 LTS“ lautet, gilt dieses Update für den Cluster.
![]()
- Unterstützung der Auswahl von Verfügbarkeitszonen für Kafka- und HBase-Cluster (Schreibzugriff)
Open Source-Fehlerkorrekturen
Hive-Fehlerbehebungen
| Fehlerbehebungen | Apache JIRA |
|---|---|
| HIVE-26127 | INSERT OVERWRITE-Fehler – Datei nicht gefunden |
| HIVE-24957 | Falsche Ergebnisse, wenn die Unterabfrage COALESCE im Korrelationsprädikat enthält |
| HIVE-24999 | HiveSubQueryRemoveRule generiert einen ungültigen Plan für die IN-Unterabfrage mit mehreren Korrelationen. |
| HIVE-24322 | Wenn eine direkte Einfügung erfolgt, muss die Versuchs-ID beim Lesen der Manifestdateien überprüft werden |
| HIVE-23363 | Upgrade der DataNucleus-Abhängigkeit auf 5.2 |
| HIVE-26412 | Erstellen einer Schnittstelle zum Abrufen verfügbarer Slots und Hinzufügen der Standardschnittstelle |
| HIVE-26173 | Upgrade von derby auf 10.14.2.0 |
| HIVE-25920 | Bumpen von Xerce2 zu 2.12.2. |
| HIVE-26300 | Upgrade der Jackson-Datenbindungsversion auf Version 2.12.6.1 und höher, um CVE-2020-36518 zu vermeiden |
Veröffentlichungsdatum: 10.08.2022
Dieses Release gilt für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht.
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
![]()
Neue Funktion
1. Anfügen externer Datenträger in HDI Hadoop-/Spark-Clustern
Ein HDInsight-Cluster weist einen vordefinierten SKU-basierenden Speicherplatz auf. Dieser Speicherplatz reicht in umfangreichen Auftragsszenarien möglicherweise nicht aus.
Mit diesem neuen Feature können Sie weitere Datenträger im Cluster hinzufügen, die als lokales Knotenverwaltungsverzeichnis verwendet werden. Sie können bei der HIVE- und Spark-Clustererstellung mehrere Datenträger zu Workerknoten hinzufügen, während die ausgewählten Datenträger Teil der lokalen Knotenverwaltungsverzeichnisse sind.
Hinweis
Die hinzugefügten Datenträger werden nur für lokale NodeManager-Verzeichnisse konfiguriert.
Weitere Informationen finden Sie hier.
2. Selektive Protokollierungsanalyse
Die selektive Protokollierungsanalyse ist jetzt in allen Regionen als öffentliche Vorschau verfügbar. Sie können Ihren Cluster mit einem Log Analytics-Arbeitsbereich verbinden. Nach der Aktivierung können Sie die Protokolle und Metriken wie HDInsight-Sicherheitsprotokolle, Yarn Resource Manager, Systemmetriken usw. anzeigen. Sie können Workloads überwachen und sehen, wie sie sich auf die Clusterstabilität auswirken. Mit der selektiven Protokollierung können Sie alle Tabellen aktivieren/deaktivieren oder ausgewählte Tabellen im Log Analytics-Arbeitsbereich aktivieren. Sie können den Quellentyp für jede Tabelle anpassen, da eine Tabelle in der neuen Version der Geneva-Überwachung über mehrere Quellen verfügt.
- Das Geneva-Überwachungssystem verwendet mdsd (MDS-Daemon), der ein Überwachungs-Agent ist, und fluentd zum Sammeln von Protokollen mit einheitlicher Protokollierungsebene.
- Die selektive Protokollierung verwendet Skriptaktionen, um Tabellen und ihre Protokolltypen zu deaktivieren/aktivieren. Da keine neuen Ports geöffnet oder vorhandene Sicherheitseinstellungen geändert werden, gibt es keine Sicherheitsänderungen.
- Die Skriptaktion wird parallel auf allen angegebenen Knoten ausgeführt und ändert die Konfigurationsdateien zum Deaktivieren/Aktivieren von Tabellen und deren Protokolltypen.
Weitere Informationen finden Sie hier.
![]()
Fest
Log Analytics
Für Log Analytics, das in Azure HDInsight mit OMS-Version 13 integriert ist, muss ein Upgrade auf OMS-Version 14 durchgeführt werden, um die neuesten Sicherheitsupdates anzuwenden. Kunden, die eine ältere Version des Clusters mit OMS-Version 13 verwenden, müssen OMS-Version 14 installieren, um die Sicherheitsanforderungen zu erfüllen. (Informationen zum Überprüfen der aktuellen Version und Installieren von Version 14)
Ermitteln der aktuellen OMS-Version
- Melden Sie sich per SSH bei dem Cluster an.
- Führen Sie in Ihrem SSH-Client den folgenden Befehl aus.
sudo /opt/omi/bin/ominiserver/ --version

Aktualisieren der OMS-Version von 13 auf 14
- Melden Sie sich beim Azure-Portal
- Wählen Sie in der Ressourcengruppe die HDInsight-Clusterressource aus.
- Wählen Sie Skriptaktionen aus.
- Wählen Sie im Bereich der Skriptaktion „Übermitteln“ den Skripttyp „Benutzerdefiniert“ aus.
- Fügen Sie den folgenden Link im URL-Feld des Bash-Skripts ein: https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh.
- Wählen Sie Knotentyp(en) aus.
- Klicken Sie auf Erstellen
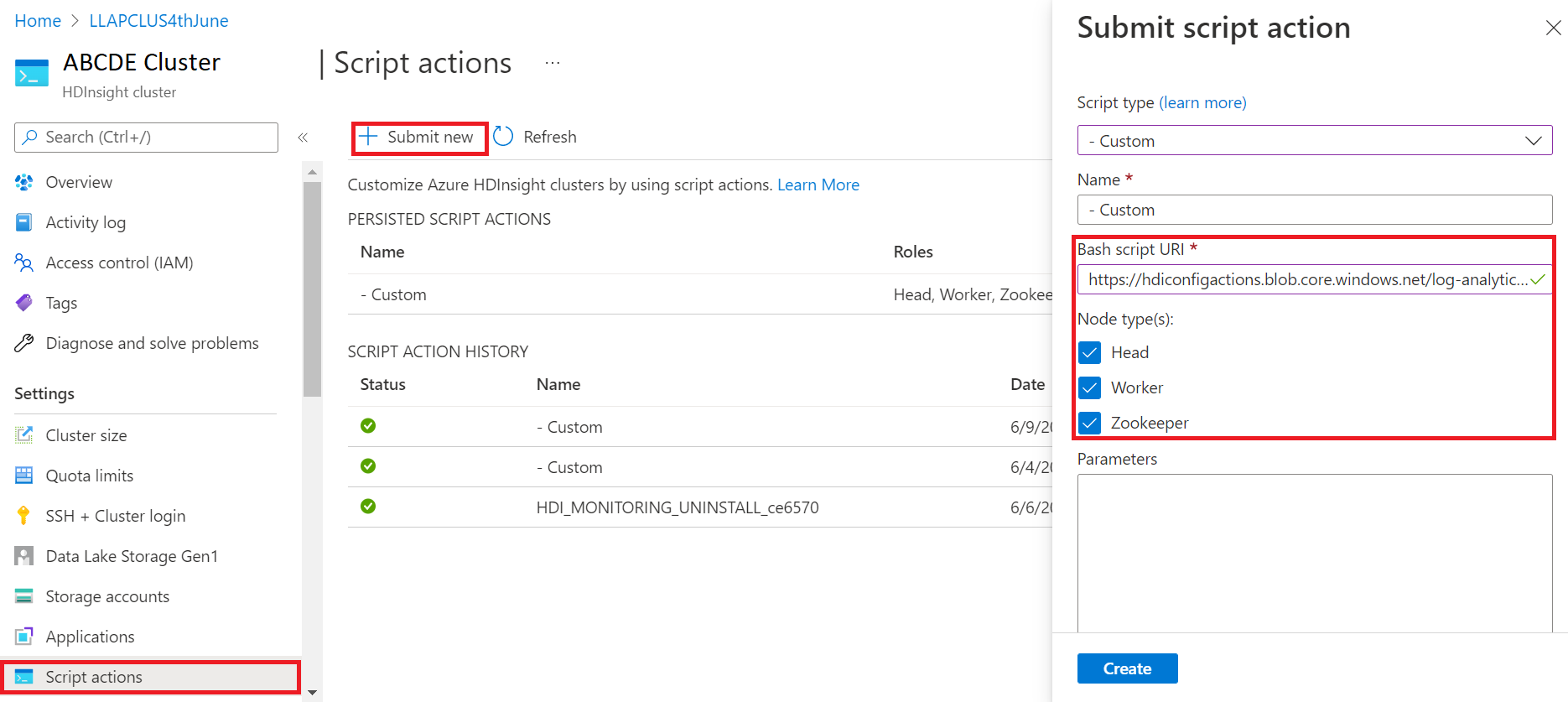
Führen Sie die folgenden Schritte aus, um die erfolgreiche Installation des Patchs zu überprüfen:
Melden Sie sich per SSH bei dem Cluster an.
Führen Sie in Ihrem SSH-Client den folgenden Befehl aus.
sudo /opt/omi/bin/ominiserver/ --version
Weitere Fehlerbehebungen
- Die CLI des Yarn-Protokolls kann die Protokolle nicht abrufen, wenn
TFilebeschädigt oder leer ist. - Der Fehler mit ungültigen Dienstprinzipaldetails beim Abrufen des OAuth-Token von Azure Active Directory wurde behoben.
- Verbesserte Zuverlässigkeit der Clustererstellung, wenn mehr als 100 Workerknoten konfiguriert werden.
Open Source-Fehlerkorrekturen
TEZ-Fehlerbehebungen
| Fehlerbehebungen | Apache JIRA |
|---|---|
| Tez Buildfehler: FileSaver.js nicht gefunden | TEZ-4411 |
Falsche FS-Ausnahme, wenn sich Warehouse und scratchdir auf unterschiedlichen FS befinden |
TEZ-4406 |
| TezUtils.createConfFromByteString bei einer Konfiguration mit mehr als 32 MB löst eine „com.google.protobuf.CodedInputStream“-Ausnahme aus. | TEZ-4142 |
| TezUtils::createByteStringFromConf sollte snappy anstelle von DeflaterOutputStream verwenden. | TEZ-4113 |
| Aktualisierung der protobuf-Abhängigkeit auf 3.x | TEZ-4363 |
Hive-Fehlerbehebungen
| Fehlerbehebungen | Apache JIRA |
|---|---|
| Perf-Optimierungen in ORC-Splitgenerierung | HIVE-21457 |
| Vermeiden, eine Tabelle als ACID zu lesen, wenn der Tabellenname mit „delta“ beginnt, die Tabelle aber nicht transaktional ist und die BI-Splitstrategie verwendet wird | HIVE-22582 |
| Entfernen eines FS#exists-Aufrufs aus AcidUtils#getLogicalLength | HIVE-23533 |
| Vektorisierung von OrcAcidRowBatchReader.computeOffset und Bucketoptimierung | HIVE-17917 |
Bekannte Probleme
HDInsight ist mit Apache HIVE 3.1.2 kompatibel. Aufgrund eines Fehlers in dieser Version wird die Hive-Version in Hive-Oberflächen als 3.1.0 angezeigt. Es gibt jedoch keine Auswirkungen auf die Funktionalität.
Veröffentlichungsdatum: 10.08.2022
Dieses Release gilt für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht.
HDInsight verwendet sichere Bereitstellungsmethoden einschließlich einer graduellen Bereitstellung in Regionen. Es kann bis zu 10 Arbeitstage dauern, bis ein neues Release oder eine neue Version in allen Regionen verfügbar ist.
![]()
Neue Funktion
1. Anfügen externer Datenträger in HDI Hadoop-/Spark-Clustern
Ein HDInsight-Cluster weist einen vordefinierten SKU-basierenden Speicherplatz auf. Dieser Speicherplatz reicht in umfangreichen Auftragsszenarien möglicherweise nicht aus.
Mit diesem neuen Feature können Sie weitere Datenträger im Cluster hinzufügen, die als lokales NodeManager-Verzeichnis verwendet werden. Sie können bei der HIVE- und Spark-Clustererstellung mehrere Datenträger zu Workerknoten hinzufügen, während die ausgewählten Datenträger Teil der lokalen Knotenverwaltungsverzeichnisse sind.
Hinweis
Die hinzugefügten Datenträger werden nur für lokale NodeManager-Verzeichnisse konfiguriert.
Weitere Informationen finden Sie hier.
2. Selektive Protokollierungsanalyse
Die selektive Protokollierungsanalyse ist jetzt in allen Regionen als öffentliche Vorschau verfügbar. Sie können Ihren Cluster mit einem Log Analytics-Arbeitsbereich verbinden. Nach der Aktivierung können Sie die Protokolle und Metriken wie HDInsight-Sicherheitsprotokolle, Yarn Resource Manager, Systemmetriken usw. anzeigen. Sie können Workloads überwachen und sehen, wie sie sich auf die Clusterstabilität auswirken. Mit der selektiven Protokollierung können Sie alle Tabellen aktivieren/deaktivieren oder ausgewählte Tabellen im Log Analytics-Arbeitsbereich aktivieren. Sie können den Quellentyp für jede Tabelle anpassen, da eine Tabelle in der neuen Version der Geneva-Überwachung über mehrere Quellen verfügt.
- Das Geneva-Überwachungssystem verwendet mdsd (MDS-Daemon), der ein Überwachungs-Agent ist, und fluentd zum Sammeln von Protokollen mit einheitlicher Protokollierungsebene.
- Die selektive Protokollierung verwendet Skriptaktionen, um Tabellen und ihre Protokolltypen zu deaktivieren/aktivieren. Da keine neuen Ports geöffnet oder vorhandene Sicherheitseinstellungen geändert werden, gibt es keine Sicherheitsänderungen.
- Die Skriptaktion wird parallel auf allen angegebenen Knoten ausgeführt und ändert die Konfigurationsdateien zum Deaktivieren/Aktivieren von Tabellen und deren Protokolltypen.
Weitere Informationen finden Sie hier.
![]()
Fest
Log Analytics
Für Log Analytics, das in Azure HDInsight mit OMS-Version 13 integriert ist, muss ein Upgrade auf OMS-Version 14 durchgeführt werden, um die neuesten Sicherheitsupdates anzuwenden. Kunden, die eine ältere Version des Clusters mit OMS-Version 13 verwenden, müssen OMS-Version 14 installieren, um die Sicherheitsanforderungen zu erfüllen. (Informationen zum Überprüfen der aktuellen Version und Installieren von Version 14)
Ermitteln der aktuellen OMS-Version
- Stellen Sie mit SSH eine Verbindung mit dem Cluster her.
- Führen Sie in Ihrem SSH-Client den folgenden Befehl aus.
sudo /opt/omi/bin/ominiserver/ --version
Aktualisieren der OMS-Version von 13 auf 14
- Melden Sie sich beim Azure-Portal
- Wählen Sie in der Ressourcengruppe die HDInsight-Clusterressource aus.
- Wählen Sie Skriptaktionen aus.
- Wählen Sie im Bereich der Skriptaktion „Übermitteln“ den Skripttyp „Benutzerdefiniert“ aus.
- Fügen Sie den folgenden Link im URL-Feld des Bash-Skripts ein: https://hdiconfigactions.blob.core.windows.net/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh.
- Wählen Sie Knotentyp(en) aus.
- Klicken Sie auf Erstellen
Führen Sie die folgenden Schritte aus, um die erfolgreiche Installation des Patchs zu überprüfen:
Melden Sie sich per SSH bei dem Cluster an.
Führen Sie in Ihrem SSH-Client den folgenden Befehl aus.
sudo /opt/omi/bin/ominiserver/ --version
Weitere Fehlerbehebungen
- Die CLI des Yarn-Protokolls kann die Protokolle nicht abrufen, wenn
TFilebeschädigt oder leer ist. - Der Fehler mit ungültigen Dienstprinzipaldetails beim Abrufen des OAuth-Token von Azure Active Directory wurde behoben.
- Verbesserte Zuverlässigkeit der Clustererstellung, wenn mehr als 100 Workerknoten konfiguriert werden.
Open Source-Fehlerkorrekturen
TEZ-Fehlerbehebungen
| Fehlerbehebungen | Apache JIRA |
|---|---|
| Tez Buildfehler: FileSaver.js nicht gefunden | TEZ-4411 |
Falsche FS-Ausnahme, wenn sich Warehouse und scratchdir auf unterschiedlichen FS befinden |
TEZ-4406 |
| TezUtils.createConfFromByteString bei einer Konfiguration mit mehr als 32 MB löst eine „com.google.protobuf.CodedInputStream“-Ausnahme aus. | TEZ-4142 |
| TezUtils::createByteStringFromConf sollte snappy anstelle von DeflaterOutputStream verwenden. | TEZ-4113 |
| Aktualisierung der protobuf-Abhängigkeit auf 3.x | TEZ-4363 |
Hive-Fehlerbehebungen
| Fehlerbehebungen | Apache JIRA |
|---|---|
| Perf-Optimierungen in ORC-Splitgenerierung | HIVE-21457 |
| Vermeiden, eine Tabelle als ACID zu lesen, wenn der Tabellenname mit „delta“ beginnt, die Tabelle aber nicht transaktional ist und die BI-Splitstrategie verwendet wird | HIVE-22582 |
| Entfernen eines FS#exists-Aufrufs aus AcidUtils#getLogicalLength | HIVE-23533 |
| Vektorisierung von OrcAcidRowBatchReader.computeOffset und Bucketoptimierung | HIVE-17917 |
Bekannte Probleme
HDInsight ist mit Apache HIVE 3.1.2 kompatibel. Aufgrund eines Fehlers in dieser Version wird die Hive-Version in Hive-Oberflächen als 3.1.0 angezeigt. Es gibt jedoch keine Auswirkungen auf die Funktionalität.
Veröffentlichungsdatum: 03.06.2022
Dieses Release gilt für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Highlights der Version
Der Hive Warehouse Connector (HWC) auf Spark v3.1.2
Mit dem Hive Warehouse Connector (HWC) können Sie die einzigartigen Features von Hive und Spark nutzen, um leistungsfähige Big Data-Anwendungen zu entwickeln. HWC wird derzeit nur für Spark v2.4 unterstützt. Mit diesem Feature wird ein geschäftlicher Mehrwert erzeugt, indem ACID-Transaktionen mit Hive-Tabellen mithilfe von Spark zugelassen werden. Dieses Feature ist für Kunden nützlich, die Hive und Spark in ihrem Datenbestand verwenden. Weitere Informationen finden Sie unter Apache Spark und Hive – Hive Warehouse Connector – Azure HDInsight | Microsoft-Dokumentation
Ambari
- Änderungen zur Verbesserung von Skalierung und Bereitstellung
- HDI Hive ist jetzt mit OSS-Version 3.1.2 kompatibel.
Die HDI Hive 3.1-Version wurde auf OSS Hive 3.1.2 aktualisiert. Diese Version enthält all Fixes und Features, die in der Open Source-Version 3.1.2 von Hive verfügbar sind.
Hinweis
Spark
- Wenn Sie die Azure-Benutzeroberfläche zum Erstellen von Spark-Clustern für HDInsight verwenden, wird in der Dropdownliste eine weitere Version Spark 3.1 (HDI 5.0) zusammen mit den älteren Versionen angezeigt. Diese Version ist eine umbenannte Version von Spark 3.1. (HDI 4.0). Dies ist lediglich eine Änderung auf Benutzeroberflächenebene, die sich sonst gar nicht auf die vorhandenen Benutzer und Benutzer, die bereits die ARM-Vorlage verwenden, auswirkt.
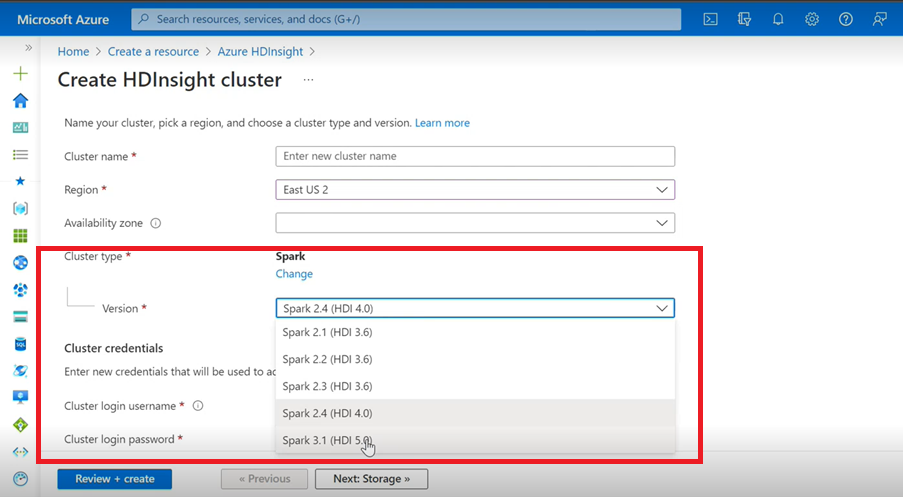
Hinweis
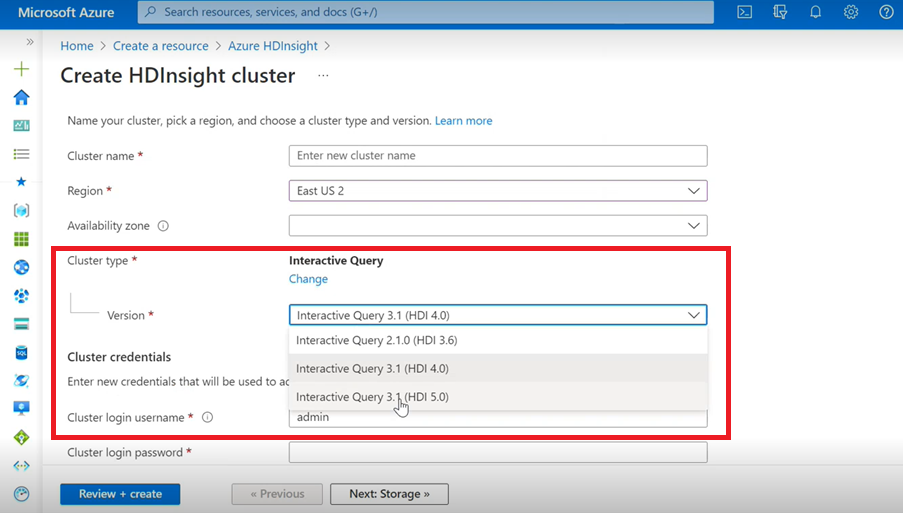
Interactive Query
- Wenn Sie einen Interactive Query-Cluster erstellen, wird in der Dropdownliste eine andere Version als Interactive Query 3.1 (HDI 5.0) angezeigt.
- Wenn Sie die Version „Spark 3.1“ zusammen mit Hive verwenden möchten, wofür ACID-Unterstützung erforderlich ist, müssen Sie diese Version „Interactive Query 3.1 (HDI 5.0)“ auswählen.
TEZ-Fehlerbehebungen
| Fehlerbehebungen | Apache JIRA |
|---|---|
| TezUtils.createConfFromByteString bei einer Konfiguration mit mehr als 32 MB löst eine „com.google.protobuf.CodedInputStream“-Ausnahme aus. | TEZ-4142 |
| TezUtils createByteStringFromConf sollte snappy anstelle von DeflaterOutputStream verwenden. | TEZ-4113 |
HBase-Fehlerbehebungen
| Fehlerbehebungen | Apache JIRA |
|---|---|
TableSnapshotInputFormat sollte ReadType.STREAM zum Überprüfen von HFiles verwenden |
HBASE-26273 |
| Option hinzufügen, um scanMetrics in TableSnapshotInputFormat zu deaktivieren. | HBASE-26330 |
| Fix für ArrayIndexOutOfBoundsException bei Ausführung des Balancers | HBASE-22739 |
Hive-Fehlerbehebungen
| Fehlerbehebungen | Apache JIRA |
|---|---|
| NPE beim Einfügen von Daten mit „distribute by“-Klausel mit dynpart-Sortieroptimierung | HIVE-18284 |
| MSCK REPAIR-Befehl mit Partitionsfilterung schlägt beim Trennen von Partitionen fehl. | HIVE-23851 |
| Falsche Ausnahme ausgelöst, wenn Kapazität <= 0. | HIVE-25446 |
| Unterstützung für parallelen Ladevorgang für HastTables – Schnittstellen | HIVE-25583 |
| MultiDelimitSerDe standardmäßig in HiveServer2 einschließen | HIVE-20619 |
| Die Klassen glassfish.jersey und mssql-jdbc aus jdbc-standalone-JAR entfernen | HIVE-22134 |
| Nullzeigerausnahme beim Ausführen der Komprimierung gegen eine MM-Tabelle. | HIVE-21280 |
Große Hive-Abfrage über knox schlägt fehl mit fehlerhaftem Pipeschreibvorgang |
HIVE-22231 |
| Hinzufügen der Möglichkeit für den Benutzer zum Festlegen des Bindungsbenutzers | HIVE-21009 |
| Implementieren von UDF zum Interpretieren von Datum/Zeitstempel mithilfe der internen Darstellung und des Gregorianischen-Julianischen Hybridkalenders | HIVE-22241 |
| Beeline-Option zum Anzeigen/nicht Anzeigen des Ausführungsberichts. | HIVE-22204 |
| Tez: SplitGenerator versucht, nach Plandateien zu suchen, die es für Tez nicht gibt | HIVE-22169 |
Entfernen der kostspieligen Protokollierung aus dem hotpath des LLAP-Caches |
HIVE-22168 |
| UDF: FunctionRegistry synchronisiert auf org.apache.hadoop.hive.ql.udf.UDFType-Klasse. | HIVE-22161 |
| Erstellung des Abfrageweiterleitungs-Appenders verhindern, wenn die Eigenschaft auf „false“ festgelegt ist. | HIVE-22115 |
| Abfrageübergreifende Synchronisierung für die Partitionsauswertung entfernen. | HIVE-22106 |
| Einrichten des Scratchverzeichnisses für Hive während der Planung überspringen. | HIVE-21182 |
| Erstellen von Scratchverzeichnissen für tez überspringen, wenn RPC aktiviert ist. | HIVE-21171 |
Hive-UDFs auf Verwendung des Re2J-Regex-Moduls umschalten |
HIVE-19661 |
| Gruppierte Tabellen, die mit bucketing_version 1 für Hive 3 migriert wurden, verwenden bucketing_version 2 für Einfügungen. | HIVE-22429 |
| Bucketing: Bucketing, Version 1, partitioniert Daten fehlerhaft. | HIVE-21167 |
| ASF-Lizenzheader wird zu neu hinzugefügter Datei hinzugefügt. | HIVE-22498 |
| Verbesserungen des Schematools zur Unterstützung von mergeCatalog | HIVE-22498 |
| Hive mit TEZ UNION ALL und UDTF führt zu Datenverlust. | HIVE-21915 |
| Textdateien aufteilen, selbst wenn Kopf-/Fußzeile vorhanden ist. | HIVE-21924 |
| MultiDelimitSerDe gibt falsche Ergebnisse in der letzten Spalte zurück, wenn die geladene Datei mehr Spalten aufweist, als im Tabellenschema vorhanden sind. | HIVE-22360 |
| Externer LLAP-Client – Notwendigkeit zur Verringerung des Speicherbedarfs von LlapBaseInputFormat#getSplits(). | HIVE-22221 |
| Ein Spaltenname mit reserviertem Schlüsselwort ist nicht escapet, wenn eine Abfrage, die eine Verknüpfungen (join) mit einer Tabelle mit Maskenspalte enthält, erneut generiert wird (Zoltan Matyus über Zoltan Haindrich). | HIVE-22208 |
Verhindern des Herunterfahrens von LLAP bei AMReporter-bezogener RuntimeException |
HIVE-22113 |
| Der LLAP-Statusdiensttreiber kann sich bei einer falschen Yarn-App-ID aufhängen | HIVE-21866 |
| OperationManager.queryIdOperation bereinigt mehrere QueryIds nicht ordnungsgemäß. | HIVE-22275 |
| Das Herunterfahren eines Knoten-Managers blockiert den Neustart des LLAP-Diensts. | HIVE-22219 |
| StackOverflowError beim Trennen vieler Partitionen. | HIVE-15956 |
| Fehler bei der Zugriffsüberprüfung, wenn ein temporäres Verzeichnis entfernt wird. | HIVE-22273 |
| Beheben falscher Ergebnisse/ArrayOutOfBound-Ausnahme in linken äußeren Zuordnungsverknüpfungen bei bestimmten Grenzbedingungen. | HIVE-22120 |
| Entfernen des Distributionsverwaltungstags aus pom.xml. | HIVE-19667 |
| Die Analysezeit kann hoch sein, wenn tief geschachtelte Unterabfragen vorhanden sind. | HIVE-21980 |
Bei ALTER TABLE t SET TBLPROPERTIES ('EXTERNAL'='TRUE'); werden Änderungen des TBL_TYPE-Attributs nicht wiedergegeben, wenn Groß-/Kleinschreibung nicht beachtet wird. |
HIVE-20057 |
JDBC: HiveConnection verdeckt log4j-Schnittstellen |
HIVE-18874 |
Aktualisieren von Repository-URLs in poms – Branch 3.1-Version |
HIVE-21786 |
DBInstall-Tests in Master und branch-3.1 fehlerhaft |
HIVE-21758 |
| Das Laden von Daten in eine Buckettabelle ignoriert Partitionsspezifikationen und lädt Daten in die Standardpartition. | HIVE-21564 |
| Abfragen mit Verknüpfungsbedingung mit Zeitstempel oder Zeitstempel mit lokalem Zeitzonenliteral lösen eine SemanticException aus. | HIVE-21613 |
| Das Analysieren von Berechnungsstatistiken für eine Spalte hinterlässt ein Stagingverzeichnis auf HDFS. | HIVE-21342 |
| Inkompatible Änderung an Hive-Bucketberechnung. | HIVE-21376 |
| Fallbackautorisierer bereitstellen, wenn kein anderer Autorisierer verwendet wird. | HIVE-20420 |
| Einige alterPartitions-Aufrufe lösen „NumberFormatException: null“ aus. | HIVE-18767 |
| HiveServer2: Vorab authentifizierter Betreff für HTTP-Transport bleibt in einigen Fällen nicht über die gesamte Dauer der HTTP-Kommunikation erhalten. | HIVE-20555 |
Releasedatum: 10.03.2022
Dieses Release gilt für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Die Betriebssystemversionen für dieses Release sind:
- HDInsight 4.0: Ubuntu 18.04.5
Spark 3.1 ist jetzt allgemein verfügbar
Spark 3.1 ist jetzt allgemein in HDInsight 4.0 verfügbar. Diese Version umfasst:
- Ausführung von adaptiven Abfragen,
- Konvertierung von Sort-Merge-Join in Übertragungshashjoin,
- Spark-Catalyst-Optimierer,
- Dynamische Partitionsbereinigung,
- Kunden können neue Spark 3.1-Cluster und keine Spark 3.0-Cluster (Vorschauversion) erstellen.
Weitere Informationen finden Sie unter Apache Spark 3.1 ist jetzt allgemein verfügbar in HDInsight – Microsoft Tech Community.
Eine vollständige Liste der Verbesserungen finden Sie in den Versionshinweisen zu Apache Spark Version 3.1.
Weitere Informationen zur Migration finden Sie im Migrationsleitfaden.
Kafka 2.4 ist jetzt allgemein verfügbar
Kafka 2.4.1 ist jetzt allgemein verfügbar. Weitere Informationen finden Sie in den Versionshinweisen zu Kafka 2.4.1. Weitere Features sind MirrorMaker 2-Verfügbarkeit, neue Metrikkategorie AtMinIsr-Themenpartition, verbesserte Brokerstartzeit durch verzögerte bedarfsgesteuertes mmap für Indexdateien, weitere Consumermetriken zum Beobachten des Benutzerabrufverhaltens.
Zuordnungsdatentyp in HWC wird jetzt in HDInsight 4.0 unterstützt.
Dieses Release umfasst die Unterstützung von Zuordnungsdatentypen für HWC 1.0 (Spark 2.4) über die Spark-Shell-Anwendung und alle anderen Spark-Clients, die von HWC unterstützt werden. Die folgenden Verbesserungen sind wie bei allen anderen Datentypen enthalten:
Ein Benutzer kann:
- Eine Hive-Tabelle mit allen Spalten erstellen, die Zuordnungsdatentypen enthalten, Daten in die Tabelle einfügen und die Ergebnisse daraus lesen.
- Einen Apache Spark-Datenrahmen mit Zuordnungstyp erstellen und Lese-/Schreibvorgänge für Batch/Stream durchführen.
Neue Regionen
HDInsight hat nun seine geografische Präsenz auf zwei neue Regionen erweitert: „China, Osten 3“ und „China, Norden 3“.
Änderungen für OSS-Zurückportierungen
OSS-Zurückportierungen, die in Hive enthalten sind, einschließlich HWC 1.0 (Spark 2.4), das den Zuordnungsdatentyp unterstützt.
Dies sind die OSS-Zurückportierungen der Apache-JIRAs für dieses Release:
| Betroffenes Feature | Apache JIRA |
|---|---|
| Direkte SQL-Metastore-Abfragen mit IN/(NOT IN) sollten basierend auf den von der SQL DB maximal zulässigen Parametern aufgeteilt werden. | HIVE-25659 |
Upgrade log4j 2.16.0 auf 2.17.0 |
HIVE-25825 |
Update Flatbuffer Version |
HIVE-22827 |
| Native Unterstützung des Zuordnungsdatentyps im Pfeilformat | HIVE-25553 |
| Externer LLAP-Client: Behandeln geschachtelter Werte, wenn die übergeordnete Struktur NULL ist | HIVE-25243 |
| Upgrade der Pfeilversion auf 0.11.0 | HIVE-23987 |
Hinweise zur Abwärtskompatibilität
Azure Virtual Machine Scale Sets in HDInsight
HDInsight wird keine Azure Virtual Machine Scale Sets mehr verwenden, um die Cluster bereitzustellen. Es wird kein Breaking Change erwartet. Bestehende HDInsight-Cluster in VM-Skalierungsgruppeninstanzen haben keine Auswirkungen, neue Cluster auf den aktuellen Images werden keine Virtual Machine Scale Sets mehr verwenden.
Die Skalierung von Azure HDInsight HBase-Workloads wird jetzt nur mit manueller Skalierung unterstützt.
Ab dem 01. März 2022 wird HDInsight nur noch die manuelle Skalierung von HBase unterstützen, das Ausführen von Clustern ist davon nicht betroffen. Neue HBase-Cluster können die zeitplanbasierte automatische Skalierung nicht mehr aktivieren. Weitere Informationen zur manuellen Skalierung Ihres HBase-Clusters finden Sie in unserer Dokumentation zur manuellen Skalierung von Azure HDInsight-Clustern.
Releasedatum: 27.12.2021
Dieses Release gilt für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Die Betriebssystemversionen für dieses Release sind:
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Das HDInsight 4.0-Image wurde aktualisiert, um das in der Log4jAntwort von Microsoft im Zusammenhang mit CVE-2021-44228 Apache Log4j 2 beschriebene Sicherheitsrisiko zu entschärfen.
Hinweis
- Nach dem 27. Dezember 2021 00:00 UTC werden alle HDI 4.0-Cluster mit einer aktualisierten Version des Images erstellt. Dadurch werden die
log4j-Sicherheitsrisiken verringert. Daher müssen Kunden diese Cluster nicht patchen/neu starten. - Für neue HDInsight 4.0-Cluster, die zwischen dem 16. Dezember 2021 um 01:15 Uhr (UTC) und dem 27. Dezember 2021 um 00:00 Uhr (UTC), mit HDInsight 3.6 oder in angehefteten Abonnements nach dem 16. Dezember 2021 erstellt wurden, wird der Patch automatisch innerhalb der Stunde angewendet, in der der Cluster erstellt wird. Kund*innen müssen ihre Knoten jedoch neu starten, damit das Patchen abgeschlossen werden kann (mit Ausnahme von Kafka-Verwaltungsknoten, die automatisch neu gestartet werden).
Veröffentlichungsdatum: 27.07.2021
Diese Version gilt sowohl für HDInsight 3.6 als auch für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Die Betriebssystemversionen für dieses Release sind:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Neue Funktionen
Azure HDInsight-Unterstützung für eingeschränkte öffentliche Konnektivität ab 15. Oktober 2021 allgemein verfügbar
Azure HDInsight unterstützt jetzt eine eingeschränkte öffentliche Konnektivität in allen Regionen. Im Folgenden finden Sie einige der wichtigsten Highlights dieser Funktion:
- Die Kommunikation zwischen Ressourcenanbieter und Cluster kann umgekehrt werden, sodass sie aus dem Cluster ausgehend an den Ressourcenanbieter fließt
- Die Verwendung eigener Private Link-fähiger Ressourcen (z. B. Speicher, SQL, Schlüsseltresor) für HDInsight-Cluster zum Zugriff auf die Ressourcen nur über das private Netzwerk wird unterstützt
- Von der Ressource werden keine öffentlichen IP-Adressen bereitgestellt
Mit dieser neuen Funktion können Sie auch die eingehenden Diensttagregeln für Netzwerksicherheitsgruppen (NSG) für HDInsight-Verwaltungs-IPs überspringen. Erfahren Sie mehr über das Einschränken der öffentlichen Konnektivität
Azure HDInsight-Unterstützung für Azure Private Link ab 15. Oktober 2021 allgemein verfügbar
Sie können jetzt private Endpunkte verwenden, um über Private Link eine Verbindung mit Ihren HDInsight-Clustern herzustellen. Private Link kann in VNet-übergreifenden Szenarien genutzt werden, in denen VNet-Peering nicht verfügbar oder aktiviert ist.
Mit Azure Private Link können Sie über einen privaten Endpunkt in Ihrem virtuellen Netzwerk auf Azure-PaaS-Dienste (beispielsweise Azure Storage und SQL Database) sowie auf in Azure gehostete kundeneigene Dienste/Partnerdienste zugreifen.
Der Datenverkehr zwischen Ihrem virtuellen Netzwerk und dem Dienst verläuft über das Microsoft-Backbone-Netzwerk. Es ist nicht mehr erforderlich, dass Sie Ihren Dienst über das öffentliche Internet verfügbar machen.
Weitere Informationen finden Sie unter Aktivieren von Private Link.
Neue Azure Monitor-Integrationserfahrung (Vorschauversion)
Die neue Azure Monitor-Integrationserfahrung ist mit diesem Release in den Regionen „USA, Osten“ und „Europa, Westen“ in der Vorschauphase. Erfahren Sie hier weitere Details über die neue Azure Monitor-Erfahrung.
Eingestellte Unterstützung
HDInsight 3.6-Version gilt ab dem 01. Oktober 2022 veraltet.
Verhaltensänderungen
HDInsight Interactive Query unterstützt nur die zeitplanbasierte Autoskalierung
Aufgrund der zunehmenden Reife und Vielfalt von Kundenszenarien haben wir einige Einschränkungen bei der lastbasierten Autoskalierung von Interactive Query (LLAP) festgestellt. Diese Einschränkungen werden durch die Art der LLAP-Abfragedynamik, Probleme bei der Genauigkeit der Vorhersage der zukünftigen Auslastung und Probleme bei der Neuverteilung von Aufgaben des LLAP-Schedulers verursacht. Aufgrund dieser Einschränkungen stellen Benutzer u. U. fest, dass Abfragen in LLAP-Clustern langsamer ausgeführt werden, wenn die Autoskalierung aktiviert ist. Die Auswirkungen auf die Leistung können die Kostenvorteile der Autoskalierung aufwiegen.
Ab Juli 2021 wird für die Interactive Query-Workload in HDInsight nur die zeitplanbasierte Autoskalierung unterstützt. Sie können die lastenbasierte Autoskalierung für neue Interactive Query-Cluster nicht mehr aktivieren. Vorhandene aktive Cluster können weiterhin mit den oben beschriebenen bekannten Einschränkungen ausgeführt werden.
Microsoft empfiehlt Ihnen, zu einer zeitplanbasierten Autoskalierung für LLAP zu wechseln. Sie können das aktuelle Nutzungsmuster Ihres Clusters über das Grafana Hive-Dashboard analysieren. Weitere Informationen finden Sie unter Automatische Skalierung von Azure HDInsight-Clustern.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen vorgenommen.
Die integrierte LLAP-Komponente im ESP Spark-Cluster wird entfernt.
HDInsight 4.0 ESP Spark-Cluster verfügt über integrierte LLAP-Komponenten, die auf beiden Hauptknoten ausgeführt werden. Die LLAP-Komponenten im ESP Spark-Cluster wurden ursprünglich für HDInsight 3.6 ESP Spark hinzugefügt, umfassen aber keinen echten Benutzerfall für HDInsight 4.0 ESP Spark. Im nächsten Release, das für September 2021 geplant ist, entfernt HDInsight die integrierte LLAP-Komponente aus dem HDInsight 4.0 ESP Spark-Cluster. Diese Änderung hilft, die Workload des Hauptknotens abzuladen und Verwechslungen zwischen den Clustertypen ESP Spark und ESP Interactive Hive zu vermeiden.
Neue Region
- USA, Westen 3
JioIndien, Westen- Australien, Mitte
Änderung der Komponentenversion
Die folgende Komponentenversion wurde mit diesem Release geändert:
- ORC-Version von 1.5.1 auf 1.5.9
Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Zurückportierte JIRAs
Dies sind die zurückportierten Apache-JIRAs für dieses Release:
| Betroffenes Feature | Apache JIRA |
|---|---|
| Datum/Zeitstempel | HIVE-25104 |
| HIVE-24074 | |
| HIVE-22840 | |
| HIVE-22589 | |
| HIVE-22405 | |
| HIVE-21729 | |
| HIVE-21291 | |
| HIVE-21290 | |
| UDF | HIVE-25268 |
| HIVE-25093 | |
| HIVE-22099 | |
| HIVE-24113 | |
| HIVE-22170 | |
| HIVE-22331 | |
| ORC | HIVE-21991 |
| HIVE-21815 | |
| HIVE-21862 | |
| Tabellenschema | HIVE-20437 |
| HIVE-22941 | |
| HIVE-21784 | |
| HIVE-21714 | |
| HIVE-18702 | |
| HIVE-21799 | |
| HIVE-21296 | |
| Arbeitsauslastungsverwaltung | HIVE-24201 |
| Komprimierung | HIVE-24882 |
| HIVE-23058 | |
| HIVE-23046 | |
| Materialisierte Sicht | HIVE-22566 |
Preiskorrektur für virtuelle HDInsight-Computer der Dv2-Serie
Am 25. April 2021 wurde ein Preisfehler für die Dv2-VM-Serie in HDInsight korrigiert. Der Preisfehler hat in den Rechnungen einiger Kunden vor dem 25. April zu einer niedrigeren Gebühr geführt. Nach der Korrektur stimmen die Preise nun mit den Preisen überein, die auf der HDInsight-Preisseite und im HDInsight-Preisrechner angekündigt wurden. Von diesem Preisfehler waren Kunden in den folgenden Regionen betroffen, die VMs der Dv2-Serie genutzt haben:
- Kanada, Mitte
- Kanada, Osten
- Asien, Osten
- Südafrika, Norden
- Asien, Südosten
- VAE, Mitte
Ab dem 25. April 2021 wird der korrigierte Betrag für die VMs der Dv2-Serie in Ihrem Konto angezeigt. Bevor die Änderung vorgenommen wurde, wurden Kundenbenachrichtigungen an die Abonnementbesitzer gesendet. Sie können den Preisrechner, die HDInsight-Preisseite oder das Blatt „HDInsight-Cluster erstellen“ im Azure-Portal verwenden, um die korrigierten Kosten für VMs der Dv2-Serie in Ihrer Region anzuzeigen.
Sie müssen keine weiteren Maßnahmen ergreifen. Die Preiskorrektur gilt nur für die Nutzung am oder nach dem 25. April 2021 in den angegebenen Regionen, und nicht für die Nutzung vor diesem Datum. Um sicherzustellen, dass Sie über die leistungsstärkste und kostengünstigste Lösung verfügen, empfehlen wir Ihnen, die Daten zu den Preisen, vCPUs und RAM-Werten für Ihre Dv2-Cluster zu überprüfen und die Dv2-Spezifikationen mit den Angaben für die Ev3-VMs zu vergleichen. Auf diese Weise können Sie ermitteln, ob es für Ihre Lösung vorteilhaft wäre, eine der neueren VM-Serien zu nutzen.
Veröffentlichungsdatum: 02.06.2021
Diese Version gilt sowohl für HDInsight 3.6 als auch für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Die Betriebssystemversionen für dieses Release sind:
- HDInsight 3.6: Ubuntu 16.04.7 LTS
- HDInsight 4.0: Ubuntu 18.04.5 LTS
Neue Funktionen
Upgrade der Betriebssystemversion
Wie im Releasezyklus von Ubuntu aufgeführt, erreicht der Ubuntu 16.04-Kernel im April 2021 das Ende der Lebensdauer (End of Life, EOL). Wir haben mit diesem Release mit dem Rollout des neuen HDInsight 4.0-Clusterimages unter Ubuntu 18.04 begonnen. Neu erstellte HDInsight 4.0-Cluster laufen standardmäßig unter Ubuntu 18.04, sobald verfügbar. Vorhandene Cluster unter Ubuntu 16.04 laufen ohne Änderung mit voller Unterstützung.
HDInsight 3.6 wird weiterhin unter Ubuntu 16.04 ausgeführt. Ab dem 1. Juli 2021 erfolgt ein Wechsel zum Basic-Support (vom Standard-Support). Weitere Informationen zu Datumsangaben und Supportoptionen finden Sie unter Azure HDInsight-Versionen. Ubuntu 18.04 wird für HDInsight 3.6 nicht unterstützt. Wenn Sie Ubuntu 18.04 verwenden möchten, müssen Sie Ihre Cluster zu HDInsight 4.0 migrieren.
Sie müssen Ihre Cluster löschen und neu erstellen, wenn Sie vorhandene HDInsight 4.0-Cluster nach Ubuntu 18.04 verschieben möchten. Planen Sie ein, die Cluster zu erstellen oder neu zu erstellen, nachdem die Unterstützung für Ubuntu 18.04 verfügbar ist.
Nachdem Sie den neuen Cluster erstellt haben, können Sie eine SSH-Shell für den Cluster öffnen und sudo lsb_release -a ausführen, um zu überprüfen, ob er unter Ubuntu 18.04 ausgeführt wird. Es wird empfohlen, Anwendungen zuerst in Testabonnements zu testen, bevor Sie in die Produktion wechseln.
Skalierungsoptimierungen für HBase-Cluster mit beschleunigten Schreibvorgängen
Von HDInsight wurden einige Verbesserungen und Optimierungen bei der Skalierung für HBase-Cluster mit beschleunigtem Schreibzugriff vorgenommen. Weitere Informationen zu beschleunigten HBase-Schreibvorgängen.
Eingestellte Unterstützung
Keine eingestellte Unterstützung für dieses Release.
Verhaltensänderungen
Deaktivieren der Stardard_A5 VM-Größe als Hauptknoten für HDInsight 4.0
Der Hauptknoten des HDInsight-Clusters ist für die Initialisierung und Verwaltung des Clusters verantwortlich. Die Standard_A5 VM-Größe hat Zuverlässigkeitsprobleme als Hauptknoten für HDInsight 4.0. Ab dem nächsten Release können Kunden keine neuen Cluster mit einer der VM-Größe „Standard_A5“ als Hauptknoten erstellen. Sie können andere VMs mirv 2 Kernen wie E2_v3 oder E2s_v3 verwenden. Vorhandene Cluster werden unverändert ausgeführt. Um die Hochverfügbarkeit und Zuverlässigkeit von HDInsight-Produktionsclustern zu gewährleisten, wird für den Hauptknoten ein virtueller Computer mit vier Kernen dringend empfohlen.
Netzwerkschnittstellen-Ressource nicht sichtbar für Cluster, die in Azure-VM-Skalierungsgruppen ausgeführt werden
HDInsight wird schrittweise zu Azure-VM-Skalierungsgruppen migriert. Netzwerkschnittstellen virtueller Computer sind für Kunden in Clustern, die Azure-VM-Skalierungsgruppen verwenden, nicht mehr sichtbar.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen durchgeführt.
HDInsight Interactive Query unterstützt nur die zeitplanbasierte Autoskalierung
Aufgrund der zunehmenden Reife und Vielfalt von Kundenszenarien haben wir einige Einschränkungen bei der lastbasierten Autoskalierung von Interactive Query (LLAP) festgestellt. Diese Einschränkungen werden durch die Art der LLAP-Abfragedynamik, Probleme bei der Genauigkeit der Vorhersage der zukünftigen Auslastung und Probleme bei der Neuverteilung von Aufgaben des LLAP-Schedulers verursacht. Aufgrund dieser Einschränkungen stellen Benutzer u. U. fest, dass Abfragen in LLAP-Clustern langsamer ausgeführt werden, wenn die Autoskalierung aktiviert ist. Die Auswirkungen auf die Leistung können die Kostenvorteile der Autoskalierung aufwiegen.
Ab Juli 2021 wird für die Interactive Query-Workload in HDInsight nur die zeitplanbasierte Autoskalierung unterstützt. Sie können die Autoskalierung für neue Interactive Query-Cluster nicht mehr aktivieren. Vorhandene aktive Cluster können weiterhin mit den oben beschriebenen bekannten Einschränkungen ausgeführt werden.
Microsoft empfiehlt Ihnen, zu einer zeitplanbasierten Autoskalierung für LLAP zu wechseln. Sie können das aktuelle Nutzungsmuster Ihres Clusters über das Grafana Hive-Dashboard analysieren. Weitere Informationen finden Sie unter Automatische Skalierung von Azure HDInsight-Clustern.
Die Benennung von VM-Hosts wird am 1. Juli 2021 geändert.
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Der Dienst wird schrittweise zu Azure-VM-Skalierungsgruppen migriert. Bei dieser Migration wird das FQDN-Namensformat für Clusterhostnamen geändert, sodass die Zahlen im Hostnamen nicht notwendigerweise fortlaufend sind. Weitere Informationen zum Ermitteln der FQDN-Namen für die einzelnen Knoten finden Sie unter Suchen der Hostnamen von Clusterknoten.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Der Dienst wird schrittweise zu Azure-VM-Skalierungsgruppen migriert. Der gesamte Prozess kann Monate dauern. Nachdem Ihre Regionen und Abonnements migriert wurden, werden neu erstellte HDInsight-Cluster ohne Kundenaktionen in VM-Skalierungsgruppen ausgeführt. Es wird kein Breaking Change erwartet.
Veröffentlichungsdatum: 24.03.2021
Neue Funktionen
Spark 3.0 (Vorschau)
HDInsight hat Spark 3.0.0-Support zu HDInsight 4.0 als Previewfunktion hinzugefügt.
Kafka 2.4 (Vorschau)
HDInsight hat Kafka 2.4.1-Support zu HDInsight 4.0 als Previewfunktion hinzugefügt.
Unterstützung bei Eav4-Serien
In HDInsight wurde in diesem Release Support für die Eav4-Serie hinzugefügt.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Der Dienst wird schrittweise zu Azure-VM-Skalierungsgruppen migriert. Der gesamte Prozess kann Monate dauern. Nachdem Ihre Regionen und Abonnements migriert wurden, werden neu erstellte HDInsight-Cluster ohne Kundenaktionen in VM-Skalierungsgruppen ausgeführt. Es wird kein Breaking Change erwartet.
Eingestellte Unterstützung
Keine eingestellte Unterstützung für dieses Release.
Verhaltensänderungen
Standardclusterversion wird auf 4.0 geändert
Ab Februar wird die Standardversion des HDInsight-Clusters von 3.6 auf 4.0 geändert. Weitere Informationen zu verfügbaren Versionen finden Sie unter Verfügbare Versionen. Erfahren Sie mehr über die Neuerungen in HDInsight 4.0.
Änderung der VM-Standardgröße für Cluster in Ev3-Serie
Die VM-Standardgröße für Cluster wird von der D-Serie in die Ev3-Serie geändert. Diese Änderung gilt für Hauptknoten und Workerknoten. Um zu vermeiden, dass sich diese Änderung auf Ihre getesteten Workflows auswirkt, geben Sie die VM-Größen an, die Sie in der ARM-Vorlage verwenden möchten.
Netzwerkschnittstellen-Ressource nicht sichtbar für Cluster, die in Azure-VM-Skalierungsgruppen ausgeführt werden
HDInsight wird schrittweise zu Azure-VM-Skalierungsgruppen migriert. Netzwerkschnittstellen virtueller Computer sind für Kunden in Clustern, die Azure-VM-Skalierungsgruppen verwenden, nicht mehr sichtbar.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen durchgeführt.
HDInsight Interactive Query unterstützt nur die zeitplanbasierte Autoskalierung
Aufgrund der zunehmenden Reife und Vielfalt von Kundenszenarien haben wir einige Einschränkungen bei der lastbasierten Autoskalierung von Interactive Query (LLAP) festgestellt. Diese Einschränkungen werden durch die Art der LLAP-Abfragedynamik, Probleme bei der Genauigkeit der Vorhersage der zukünftigen Auslastung und Probleme bei der Neuverteilung von Aufgaben des LLAP-Schedulers verursacht. Aufgrund dieser Einschränkungen stellen Benutzer u. U. fest, dass Abfragen in LLAP-Clustern langsamer ausgeführt werden, wenn die Autoskalierung aktiviert ist. Die Auswirkungen auf die Leistung können die Kostenvorteile der Autoskalierung aufwiegen.
Ab Juli 2021 wird für die Interactive Query-Workload in HDInsight nur die zeitplanbasierte Autoskalierung unterstützt. Sie können die Autoskalierung für neue Interactive Query-Cluster nicht mehr aktivieren. Vorhandene aktive Cluster können weiterhin mit den oben beschriebenen bekannten Einschränkungen ausgeführt werden.
Microsoft empfiehlt Ihnen, zu einer zeitplanbasierten Autoskalierung für LLAP zu wechseln. Sie können das aktuelle Nutzungsmuster Ihres Clusters über das Grafana Hive-Dashboard analysieren. Weitere Informationen finden Sie unter Automatische Skalierung von Azure HDInsight-Clustern.
Upgrade der Betriebssystemversion
HDInsight-Cluster werden derzeit unter Ubuntu 16.04 LTS ausgeführt. Wie im Releasezyklus von Ubuntu verwiesen, erreicht der Ubuntu 16.04-Kernel im April 2021 das Ende der Lebensdauer (End of Life, EOL). Wir beginnen im Mai 2021 mit der Einführung des neuen HDInsight 4.0-Clusterimages unter Ubuntu 18.04. Neu erstellte HDInsight 4.0-Cluster werden standardmäßig unter Ubuntu 18.04 ausgeführt, sobald sie verfügbar sind. Vorhandene Cluster unter Ubuntu 16.04 werden ohne vollständige Unterstützung ausgeführt.
HDInsight 3.6 wird weiterhin unter Ubuntu 16.04 ausgeführt. Die Standardunterstützung wird bis zum 30. Juni 2021 beendet und ab dem 1. Juli 2021 in Basic-Support geändert. Weitere Informationen zu Datumsangaben und Supportoptionen finden Sie unter Azure HDInsight-Versionen. Ubuntu 18.04 wird für HDInsight 3.6 nicht unterstützt. Wenn Sie Ubuntu 18.04 verwenden möchten, müssen Sie Ihre Cluster zu HDInsight 4.0 migrieren.
Sie müssen Ihre Cluster löschen und neu erstellen, wenn Sie vorhandene Cluster zu Ubuntu 18.04 verschieben möchten. Planen Sie, Ihren Cluster zu erstellen oder neu zu erstellen, nachdem die Unterstützung für Ubuntu 18.04 verfügbar ist. Wir senden eine weitere Benachrichtigung, nachdem das neue Image in allen Regionen verfügbar ist.
Es wird dringend empfohlen, Ihre Skriptaktionen und benutzerdefinierten Anwendungen, die auf Edgeknoten auf einem virtuellen Ubuntu 18.04-Computer (VM) bereitgestellt werden, vorab zu testen. Sie können einen virtuellen Ubuntu Linux-Computer unter 18.04-LTS erstellen und dann ein SSH-Schlüsselpaar (Secure Shell) auf Ihrem virtuellen Computer erstellen und verwenden, um Ihre Skriptaktionen und benutzerdefinierten Anwendungen auszuführen und zu testen, die auf Edgeknoten bereitgestellt werden.
Deaktivieren der Stardard_A5 VM-Größe als Hauptknoten für HDInsight 4.0
Der Hauptknoten des HDInsight-Clusters ist für die Initialisierung und Verwaltung des Clusters verantwortlich. Die Standard_A5 VM-Größe hat Zuverlässigkeitsprobleme als Hauptknoten für HDInsight 4.0. Ab dem nächsten Release im Mai 2021 können Kunden keine neuen Cluster mit der VM-Größe „Standard_A5“ als Hauptknoten erstellen. Sie können andere 2-Kern-VMs wie E2_v3 oder E2s_v3 verwenden. Vorhandene Cluster werden unverändert ausgeführt. Um die Hochverfügbarkeit und Zuverlässigkeit von ihren HDInsight-Produktionsclustern zu gewährleisten, wird für den Hauptknoten ein virtueller Computer mit vier Kernen dringend empfohlen.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Änderung der Komponentenversion
Zusätzlicher Support für Spark 3.0.0 und Kafka 2.4.1 als Preview hinzugefügt. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Veröffentlichungsdatum: 05.02.2021
Diese Version gilt sowohl für HDInsight 3.6 als auch für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Neue Funktionen
Unterstützung der Dav4-Serie
In HDInsight wurde in dieser Version Unterstützung für die Dav4-Serie hinzugefügt. Weitere Informationen zur Dav4-Serie finden Sie hier.
Kafka-REST-Proxy allgemein verfügbar
Mithilfe des REST-Proxys von Kafka können Sie über eine REST-API per HTTPS mit Ihrem Kafka-Cluster interagieren. Der Kafka-REST-Proxy ist ab dieser Version allgemein verfügbar. Weitere Informationen zum Kafka-REST-Proxy finden Sie hier.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Der Dienst wird schrittweise zu Azure-VM-Skalierungsgruppen migriert. Der gesamte Prozess kann Monate dauern. Nachdem Ihre Regionen und Abonnements migriert wurden, werden neu erstellte HDInsight-Cluster ohne Kundenaktionen in VM-Skalierungsgruppen ausgeführt. Es wird kein Breaking Change erwartet.
Eingestellte Unterstützung
Deaktivierte VM-Größen
Ab dem 9. Januar 2021 hindert HDInsight alle Kunden daran, Cluster mit den VM-Größen standand_A8, standand_A9, standand_A10 und standand_A11 zu erstellen. Vorhandene Cluster werden unverändert ausgeführt. Sie sollten zu HDInsight 4.0 wechseln, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Verhaltensänderungen
Änderung der VM-Standardgröße für Cluster in Ev3-Serie
Di VM-Standardgröße für Cluster wird von der D-Serie in die Ev3-Serie geändert. Diese Änderung gilt für Hauptknoten und Workerknoten. Um zu vermeiden, dass sich diese Änderung auf Ihre getesteten Workflows auswirkt, geben Sie die VM-Größen an, die Sie in der ARM-Vorlage verwenden möchten.
Netzwerkschnittstellen-Ressource nicht sichtbar für Cluster, die in Azure-VM-Skalierungsgruppen ausgeführt werden
HDInsight wird schrittweise zu Azure-VM-Skalierungsgruppen migriert. Netzwerkschnittstellen virtueller Computer sind für Kunden in Clustern, die Azure-VM-Skalierungsgruppen verwenden, nicht mehr sichtbar.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen durchgeführt.
Standardclusterversion wird in 4.0 geändert
Ab Februar 2021 wird die Standardversion des HDInsight-Clusters von 3.6 in 4.0 geändert. Weitere Informationen zu verfügbaren Versionen finden Sie unter Verfügbare Versionen. Erfahren Sie mehr über die Neuerungen in HDInsight 4.0.
Upgrade der Betriebssystemversion
Für HDInsight erfolgt ein Upgrade der Betriebssystemversion von Ubuntu 16.04 auf 18.04. Das Upgrade wird vor April 2021 abgeschlossen sein.
Ende der Unterstützung von HDInsight 3.6 am 30. Juni 2021
Die Unterstützung von HDInsight 3.6 endet bald. Ab dem 30. Juni 2021 können Kunden keine neuen HDInsight 3.6-Cluster mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Sie sollten zu HDInsight 4.0 wechseln, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Änderung der Komponentenversion
Für dieses Release gibt es keine Änderung der Komponentenversion. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Veröffentlichungsdatum: 11/18/2020
Diese Version gilt sowohl für HDInsight 3.6 als auch für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Neue Funktionen
Automatische Schlüsselrotation für kundenseitig verwaltete Schlüsselverschlüsselung ruhender Daten
Ab dieser Version können Kunden die versionslosen Verschlüsselungsschlüssel-URLs von Azure Key Vault für die Verschlüsselung ruhender Daten mit kundenseitig verwalteten Schlüsseln verwenden. HDInsight rotiert die Schlüssel automatisch, wenn sie ablaufen oder durch neue Versionen ersetzt werden. Ausführlichere Informationen finden Sie hier.
Möglichkeit zum Auswählen anderer Größen virtueller Zookeeper-Computer für Spark, Hadoop und ML Services
HDInsight unterstützte bisher nicht die Anpassung der Zookeeper-Knotengröße für die Clustertypen „Spark“, „Hadoop“ und „ML Services“. Standardmäßig wird A2_v2/A2 für die Größen virtueller Computer verwendet, die kostenlos zur Verfügung gestellt werden. Ab dieser Version können Sie die Größe der virtuellen Zookeeper-Computer auswählen, die für Ihr Szenario am besten geeignet ist. Für Zookeeper-Knoten mit einer anderen Größe der virtuellen Computer als A2_v2/A2 fallen Gebühren an. Die virtuellen Computer vom Typ A2_v2 und A2 werden weiterhin kostenlos angeboten.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Ab dieser Version wird der Dienst schrittweise zu Azure-VM-Skalierungsgruppen migriert. Der gesamte Prozess kann Monate dauern. Nachdem Ihre Regionen und Abonnements migriert wurden, werden neu erstellte HDInsight-Cluster ohne Kundenaktionen in VM-Skalierungsgruppen ausgeführt. Es wird kein Breaking Change erwartet.
Eingestellte Unterstützung
Eingestellte Unterstützung des HDInsight 3.6 ML Services-Clusters
Der Support für den Clustertyp „HDInsight 3.6 ML Services“ wird am 31. Dezember 2020 auslaufen. Kunden können ab 31. Dezember 2020 keine neuen 3.6 ML Services-Cluster mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Prüfen Sie hier das Auslaufen des Supports für HDInsight-Versionen und Clustertypen.
Deaktivierte VM-Größen
Ab dem 16. November 2020 hindert HDInsight neue Kunden daran, Cluster mit den VM-Größen standand_A8, standand_A9, standand_A10 und standand_A11 zu erstellen. Bestandskunden, die diese VM-Größen in den letzten drei Monaten verwendet haben, sind nicht betroffen. Ab dem 9. Januar 2021 hindert HDInsight alle Kunden daran, Cluster mit den VM-Größen standand_A8, standand_A9, standand_A10 und standand_A11 zu erstellen. Vorhandene Cluster werden unverändert ausgeführt. Sie sollten zu HDInsight 4.0 wechseln, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Verhaltensänderungen
Hinzufügen der NSG-Regelüberprüfung vor dem Skalierungsvorgang
HDInsight hat die Überprüfung von Netzwerksicherheitsgruppen (NSGs) und benutzerdefinierten Routen (UDRs, User-Defined Routes) mit dem Skalierungsvorgang hinzugefügt. Die gleiche Überprüfung erfolgt neben der Clustererstellung auch für die Clusterskalierung. Diese Überprüfung hilft, unvorhersehbare Fehler zu vermeiden. Wenn die Überprüfung nicht bestanden wird, tritt bei der Skalierung ein Fehler auf. Weitere Informationen zum ordnungsgemäßen Konfigurieren von NSGs und UDRs finden Sie unter HDInsight-Verwaltungs-IP-Adressen.
Änderung der Komponentenversion
Für dieses Release gibt es keine Änderung der Komponentenversion. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Veröffentlichungsdatum: 09.11.2020
Diese Version gilt sowohl für HDInsight 3.6 als auch für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Neue Funktionen
HDInsight Identity Broker (HIB) ist jetzt GA
Der HDInsight Identity Broker (HIB), der die OAuth-Authentifizierung für ESP-Cluster ermöglicht, ist jetzt mit diesem Release allgemein verfügbar. HIB-Cluster, die nach diesem Release erstellt werden, verfügen über die neuesten HIB-Features:
- Hochverfügbarkeit (High Availability, HA)
- Unterstützung für die Multi-Faktor-Authentifizierung (MFA)
- Verbundbenutzer melden sich ohne Kennworthashsynchronisierung bei AAD-DS an. Weitere Informationen finden Sie in der HIB-Dokumentation.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Ab dieser Version wird der Dienst schrittweise zu Azure-VM-Skalierungsgruppen migriert. Der gesamte Prozess kann Monate dauern. Nachdem Ihre Regionen und Abonnements migriert wurden, werden neu erstellte HDInsight-Cluster ohne Kundenaktionen in VM-Skalierungsgruppen ausgeführt. Es wird kein Breaking Change erwartet.
Eingestellte Unterstützung
Eingestellte Unterstützung des HDInsight 3.6 ML Services-Clusters
Der Support für den Clustertyp „HDInsight 3.6 ML Services“ wird am 31. Dezember 2020 auslaufen. Kunden werden nach dem 31. Dezember 2020 keine neuen 3.6 ML Services-Cluster mehr erstellen können. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Prüfen Sie hier das Auslaufen des Supports für HDInsight-Versionen und Clustertypen.
Deaktivierte VM-Größen
Ab dem 16. November 2020 hindert HDInsight neue Kunden daran, Cluster mit den VM-Größen standand_A8, standand_A9, standand_A10 und standand_A11 zu erstellen. Bestandskunden, die diese VM-Größen in den letzten drei Monaten verwendet haben, sind nicht betroffen. Ab dem 9. Januar 2021 hindert HDInsight alle Kunden daran, Cluster mit den VM-Größen standand_A8, standand_A9, standand_A10 und standand_A11 zu erstellen. Vorhandene Cluster werden unverändert ausgeführt. Sie sollten zu HDInsight 4.0 wechseln, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Verhaltensänderungen
Keine Verhaltensänderung für diese Version.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen durchgeführt.
Möglichkeit zum Auswählen anderer Größen virtueller Zookeeper-Computer für Spark, Hadoop und ML Services
HDInsight unterstützt derzeit keine Anpassung der Zookeeper-Knotengröße für die Clustertypen „Spark“, „Hadoop“ und „ML Services“. Standardmäßig wird A2_v2/A2 für die Größen virtueller Computer verwendet, die kostenlos zur Verfügung gestellt werden. In der kommenden Version können Sie die Größe der virtuellen Zookeeper-Computer auswählen, die für Ihr Szenario am besten geeignet ist. Für Zookeeper-Knoten mit einer anderen Größe der virtuellen Computer als A2_v2/A2 fallen Gebühren an. Die virtuellen Computer vom Typ A2_v2 und A2 werden weiterhin kostenlos angeboten.
Standardclusterversion wird in 4.0 geändert
Ab Februar 2021 wird die Standardversion des HDInsight-Clusters von 3.6 in 4.0 geändert. Weitere Informationen zu verfügbaren Versionen finden Sie unter Unterstützte Versionen. Erfahren Sie mehr über die Neuerungen in HDInsight 4.0.
Ende der Unterstützung von HDInsight 3.6 am 30. Juni 2021
Die Unterstützung von HDInsight 3.6 endet bald. Ab dem 30. Juni 2021 können Kunden keine neuen HDInsight 3.6-Cluster mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Sie sollten zu HDInsight 4.0 wechseln, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Problembehebung beim Neustarten von VMs im Cluster
Das Problem beim Neustarten von VMs im Cluster wurde behoben. Sie können PowerShell oder die REST-API verwenden, um die Knoten im Cluster erneut zu starten.
Änderung der Komponentenversion
Für dieses Release gibt es keine Änderung der Komponentenversion. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Veröffentlichungsdatum: 08.10.2020
Diese Version gilt sowohl für HDInsight 3.6 als auch für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Neue Funktionen
Private HDInsight-Cluster ohne öffentliche IP-Adresse und private Verbindung (Vorschau)
HDInsight unterstützt jetzt die Erstellung von Clustern ohne öffentliche IP-Adresse und den Zugriff auf Cluster über private Verbindungen in der Vorschau. Kunden können die neuen erweiterten Netzwerkeinstellungen verwenden, um einen vollständig isolierten Cluster ohne öffentliche IP-Adresse zu erstellen und ihre eigenen privaten Endpunkte für den Zugriff auf den Cluster verwenden.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Ab dieser Version wird der Dienst schrittweise zu Azure-VM-Skalierungsgruppen migriert. Der gesamte Prozess kann Monate dauern. Nachdem Ihre Regionen und Abonnements migriert wurden, werden neu erstellte HDInsight-Cluster ohne Kundenaktionen in VM-Skalierungsgruppen ausgeführt. Es wird kein Breaking Change erwartet.
Eingestellte Unterstützung
Eingestellte Unterstützung des HDInsight 3.6 ML Services-Clusters
Der Support für den Clustertyp „HDInsight 3.6 ML Services“ wird am 31. Dezember 2020 auslaufen. Kunden werden danach keine neuen 3.6 ML Services-Cluster mehr erstellen können. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Prüfen Sie hier das Auslaufen des Supports für HDInsight-Versionen und Clustertypen.
Verhaltensänderungen
Keine Verhaltensänderung für diese Version.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen durchgeführt.
Möglichkeit zum Auswählen anderer Größen virtueller Zookeeper-Computer für Spark, Hadoop und ML Services
HDInsight unterstützt derzeit keine Anpassung der Zookeeper-Knotengröße für die Clustertypen „Spark“, „Hadoop“ und „ML Services“. Standardmäßig wird A2_v2/A2 für die Größen virtueller Computer verwendet, die kostenlos zur Verfügung gestellt werden. In der kommenden Version können Sie die Größe der virtuellen Zookeeper-Computer auswählen, die für Ihr Szenario am besten geeignet ist. Für Zookeeper-Knoten mit einer anderen Größe der virtuellen Computer als A2_v2/A2 fallen Gebühren an. Die virtuellen Computer vom Typ A2_v2 und A2 werden weiterhin kostenlos angeboten.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Änderung der Komponentenversion
Für dieses Release gibt es keine Änderung der Komponentenversion. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Veröffentlichungsdatum: 28.09.2020
Diese Version gilt sowohl für HDInsight 3.6 als auch für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Neue Funktionen
Autoskalierung für Interactive Query mit HDInsight 4.0 ist jetzt allgemein verfügbar
Die Autoskalierung für den Interactive Query-Clustertyp ist jetzt für HDInsight 4.0 allgemein verfügbar (GA). Alle nach dem 27. August 2020 erstellten Interactive Query 4.0-Cluster werden GA-Unterstützung (allgemeine Verfügbarkeit) für die Autoskalierung haben.
HBase-Cluster unterstützt Premium ADLS Gen2
HDInsight unterstützt jetzt Premium ADLS Gen2 als primäres Speicherkonto für Cluster mit HDInsight HBase 3.6 und 4.0. Zusammen mit beschleunigten Schreibvorgängen können Sie eine bessere Leistung für Ihre HBase-Cluster erzielen.
Kafka-Partitionsverteilung auf Azure-Fehlerdomänen
Eine Fehlerdomäne ist eine logische Gruppierung von zugrundeliegender Hardware in einem Azure-Rechenzentrum. Jede Fehlerdomäne verwendet eine Stromquelle und einen Netzwerkswitch gemeinsam. Bevor HDInsight Kafka alle Partitionsreplikate in derselben Fehlerdomäne speichern darf. Ab dieser Version unterstützt HDInsight jetzt die automatische Verteilung von Kafka-Partitionen auf der Basis von Azure-Fehlerdomänen.
Verschlüsselung während der Übertragung
Kunden können die Verschlüsselung während der Übertragung zwischen Clusterknoten mithilfe der IPSec-Verschlüsselung mit plattformseitig verwalteten Schlüsseln aktivieren. Diese Option kann zum Zeitpunkt der Clustererstellung aktiviert werden. Erfahren Sie weitere Einzelheiten zum Aktivieren der Verschlüsselung während der Übertragung.
Verschlüsselung auf dem Host
Wenn Sie die Verschlüsselung auf dem Host aktivieren, werden die auf dem VM-Host gespeicherten Daten ruhend verschlüsselt und verschlüsselt an den Speicherdienst übermittelt. Ab dieser Version können Sie die Verschlüsselung beim Host auf einem temporären Datenträger aktivieren, wenn Sie den Cluster erstellen. Die Verschlüsselung auf dem Host wird nur für bestimmte VM-SKUs in ausgewählten Regionen unterstützt. HDInsight unterstützt folgende Knotenkonfiguration und SKUs. Erfahren Sie weitere Einzelheiten zum Aktivieren der Verschlüsselung auf dem Host.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Ab dieser Version wird der Dienst schrittweise zu Azure-VM-Skalierungsgruppen migriert. Der gesamte Prozess kann Monate dauern. Nachdem Ihre Regionen und Abonnements migriert wurden, werden neu erstellte HDInsight-Cluster ohne Kundenaktionen in VM-Skalierungsgruppen ausgeführt. Es wird kein Breaking Change erwartet.
Eingestellte Unterstützung
Keine eingestellte Unterstützung für diese Version.
Verhaltensänderungen
Keine Verhaltensänderung für diese Version.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen durchgeführt.
Möglichkeit zum Auswählen einer anderen Zookeeper-SKU für Spark, Hadoop und ML-Dienste
HDInsight unterstützt derzeit keine Änderung der Zookeeper-SKU für die Clustertypen „Spark“, „Hadoop“ und „ML-Dienste“. HDInsight verwendet die SKU „A2_v2/A2“ für Zookeeper-Knoten, die Kunden nicht in Rechnung gestellt werden. In der nächsten Version können Kunden nach Bedarf die Zookeeper-SKU für Spark, Hadoop und ML-Dienste ändern. Zookeeper-Knoten mit einer anderen SKU als A2_v2/A2 sind kostenpflichtig. A2_V2/A2 bleibt weiterhin die Standard-SKU und ist kostenfrei.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Änderung der Komponentenversion
Für dieses Release gibt es keine Änderung der Komponentenversion. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Veröffentlichungsdatum: 09.08.2020
Diese Version gilt nur für HDInsight 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Neue Funktionen
Unterstützung für SparkCruise
SparkCruise ist ein System für die automatische Wiederverwendung von Berechnungsergebnissen für Spark. Es wählt gängige zu materialisierende Teilausdrücke anhand der vergangenen Abfrageworkload aus. SparkCruise materialisiert diese Teilausdrücke im Rahmen der Abfrageverarbeitung, und die Wiederverwendung von Berechnungsergebnissen wird automatisch im Hintergrund angewendet. Sie können von SparkCruise profitieren, ohne Änderungen am Spark-Code vornehmen zu müssen.
Unterstützung der Hive-Ansicht für HDInsight 4.0
Die Apache Ambari-Hive-Ansicht ist dazu konzipiert, Sie beim Erstellen, Optimieren und Ausführen von Hive-Abfragen über Ihren Webbrowser zu unterstützen. Die Hive-Ansicht wird ab diesem Release nativ für HDInsight 4.0-Cluster unterstützt. Dies gilt nicht für vorhandene Cluster. Sie müssen den Cluster löschen und neu erstellen, um die integrierte Hive-Ansicht zu nutzen.
Unterstützung der Tez-Ansicht für HDInsight 4.0
Die Apache Tez-Ansicht wird zum Nachverfolgen und Debuggen der Ausführung von Hive Tez-Aufträgen verwendet. Die Tez-Ansicht wird ab diesem Release nativ für HDInsight 4.0 unterstützt. Dies gilt nicht für vorhandene Cluster. Sie müssen den Cluster löschen und neu erstellen, um die integrierte Tez-Ansicht zu nutzen.
Eingestellte Unterstützung
Einstellung der Unterstützung von Spark 2.1 und 2.2 für Spark-Cluster in HDInsight 3.6
Ab dem 1. Juli 2020 können Kunden in HDInsight 3.6 keine neuen Spark-Cluster mit Spark 2.1 und 2.2 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Ziehen Sie in Erwägung, bis 30. Juni 2020 in HDInsight 3.6 zu Spark 2.3 zu wechseln, um eine potenzielle Unterbrechung von System/Support zu vermeiden.
Einstellung der Unterstützung von Spark 2.3 für Spark-Cluster in HDInsight 4.0
Ab dem 1. Juli 2020 können Kunden in HDInsight 4.0 keine neuen Spark-Cluster mit Spark 2.3 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Ziehen Sie in Erwägung, bis 30. Juni 2020 in HDInsight 4.0 zu Spark 2.4 zu wechseln, um eine potenzielle Unterbrechung von System/Support zu vermeiden.
Einstellung von Kafka 1.1 für Kafka-Cluster in HDInsight 4.0
Ab dem 1. Juli 2020 können Kunden in HDInsight 4.0 keine neuen Kafka-Cluster mit Kafka 1.1 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Es empfiehlt sich, in HDInsight 4.0 bis zum 30. Juni 2020 auf Kafka 2.1 umzustellen, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Verhaltensänderungen
Änderung der Ambari-Stapelversion
In diesem Release ändert sich die Ambari-Version von 2.x.x.x in 4.1. Sie können die Stapelversion (HDInsight 4.1) in Ambari unter „Ambari > Benutzer > Versionen“ überprüfen.
Bevorstehende Änderungen
Es stehen keine Breaking Changes an, um die Sie sich kümmern müssen.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Für die folgenden JIRA-Tickets wurden Backports für Hive durchgeführt:
Für die folgenden JIRA-Tickets wurden Backports für HBase durchgeführt:
Änderung der Komponentenversion
Für dieses Release gibt es keine Änderung der Komponentenversion. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Bekannte Probleme
Es wurde ein Problem im Azure-Portal behoben, das zu einem Fehler führte, wenn Benutzer einen Azure HDInsight-Cluster mit einem öffentlichen Schlüssel als SSH-Authentifizierungstyp erstellt haben. Benutzern, die auf Überprüfen + erstellen geklickt haben, erhielten die Fehlermeldung „Es dürfen keine drei aufeinanderfolgenden Zeichen aus dem SSH-Benutzernamen enthalten sein“. Dieses Problem wurde behoben, aber es kann erforderlich sein, den Browsercache zu aktualisieren. Drücken Sie hierzu STRG+F5, um die korrigierte Ansicht zu laden. Dieses Problem konnten Sie umgehen, indem Sie einen Cluster mit einer ARM-Vorlage erstellten.
Veröffentlichungsdatum: 13.07.2020
Diese Version gilt für HDInsight 3.6 und 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Neue Funktionen
Unterstützung der Kunden-Lockbox für Microsoft Azure
Azure HDInsight unterstützt jetzt die Azure Kunden-Lockbox. Sie stellt für Kunden eine Schnittstelle zum Überprüfen und Genehmigen oder zum Ablehnen von Zugriffsanforderungen für Kundendaten bereit. Sie wird verwendet, wenn ein Microsoft-Techniker während einer Supportanfrage auf Kundendaten zugreifen muss. Weitere Informationen finden Sie unter Kunden-Lockbox für Microsoft Azure.
Dienstendpunkt-Richtlinien für Speicher
Kunden können nun im HDInsight-Clustersubnetz Dienstendpunkt-Richtlinien (Service Endpoint Policies, SEP) verwenden. Weitere Informationen finden Sie unter Azure-Dienstendpunkt-Richtlinie.
Eingestellte Unterstützung
Einstellung der Unterstützung von Spark 2.1 und 2.2 für Spark-Cluster in HDInsight 3.6
Ab dem 1. Juli 2020 können Kunden in HDInsight 3.6 keine neuen Spark-Cluster mit Spark 2.1 und 2.2 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Ziehen Sie in Erwägung, bis 30. Juni 2020 in HDInsight 3.6 zu Spark 2.3 zu wechseln, um eine potenzielle Unterbrechung von System/Support zu vermeiden.
Einstellung der Unterstützung von Spark 2.3 für Spark-Cluster in HDInsight 4.0
Ab dem 1. Juli 2020 können Kunden in HDInsight 4.0 keine neuen Spark-Cluster mit Spark 2.3 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Ziehen Sie in Erwägung, bis 30. Juni 2020 in HDInsight 4.0 zu Spark 2.4 zu wechseln, um eine potenzielle Unterbrechung von System/Support zu vermeiden.
Einstellung von Kafka 1.1 für Kafka-Cluster in HDInsight 4.0
Ab dem 1. Juli 2020 können Kunden in HDInsight 4.0 keine neuen Kafka-Cluster mit Kafka 1.1 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Es empfiehlt sich, in HDInsight 4.0 bis zum 30. Juni 2020 auf Kafka 2.1 umzustellen, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Verhaltensänderungen
Keine Verhaltensänderungen, auf die Sie achten müssen.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen durchgeführt.
Möglichkeit zum Auswählen einer anderen Zookeeper-SKU für Spark, Hadoop und ML-Dienste
HDInsight unterstützt derzeit keine Änderung der Zookeeper-SKU für die Clustertypen „Spark“, „Hadoop“ und „ML-Dienste“. HDInsight verwendet die SKU „A2_v2/A2“ für Zookeeper-Knoten, die Kunden nicht in Rechnung gestellt werden. In der nächsten Version können Kunden nach Bedarf die Zookeeper-SKU für Spark, Hadoop und ML-Dienste ändern. Zookeeper-Knoten mit einer anderen SKU als A2_v2/A2 sind kostenpflichtig. A2_V2/A2 bleibt weiterhin die Standard-SKU und ist kostenfrei.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Behobenes Problem mit Hive Warehouse Connector
In der vorherigen Version gab es ein Problem bei der Verwendbarkeit von Hive Warehouse Connector. Dieses Problem wurde behoben.
Behobenes Problem mit Zeppelin-Notebook und dem Abschneiden führender Nullen
Zeppelin hat in der Tabellenausgabe für das Zeichenfolgenformat fälschlicherweise führende Nullen abgeschnitten. Dieses Problem wurde in dieser Version behoben.
Änderung der Komponentenversion
Für dieses Release gibt es keine Änderung der Komponentenversion. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Veröffentlichungsdatum: 11.06.2020
Diese Version gilt für HDInsight 3.6 und 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Neue Funktionen
Wechsel zu Azure-VM-Skalierungsgruppen
Von HDInsight werden jetzt virtuelle Azure-Computer für die Clusterbereitstellung verwendet. Ab diesem Release werden von neu erstellten HDInsight-Clustern Azure-VM-Skalierungsgruppen verwendet. Die Änderung wird schrittweise eingeführt. Dabei ist nicht mit einem Breaking Change zu rechnen. Weitere Informationen zu Azure-VM-Skalierungsgruppen.
Neustarten von virtuellen Computern im HDInsight-Cluster
In dieser Version wird das Neustarten von virtuellen Computern in einem HDInsight-Cluster unterstützt, um nicht reagierende Knoten neu starten zu können. Momentan ist dies nur per API möglich, an der PowerShell- und CLI-Unterstützung wird jedoch bereits gearbeitet. Weitere Informationen zur API finden Sie in dieser Dokumentation.
Eingestellte Unterstützung
Einstellung der Unterstützung von Spark 2.1 und 2.2 für Spark-Cluster in HDInsight 3.6
Ab dem 1. Juli 2020 können Kunden in HDInsight 3.6 keine neuen Spark-Cluster mit Spark 2.1 und 2.2 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Ziehen Sie in Erwägung, bis 30. Juni 2020 in HDInsight 3.6 zu Spark 2.3 zu wechseln, um eine potenzielle Unterbrechung von System/Support zu vermeiden.
Einstellung der Unterstützung von Spark 2.3 für Spark-Cluster in HDInsight 4.0
Ab dem 1. Juli 2020 können Kunden in HDInsight 4.0 keine neuen Spark-Cluster mit Spark 2.3 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Ziehen Sie in Erwägung, bis 30. Juni 2020 in HDInsight 4.0 zu Spark 2.4 zu wechseln, um eine potenzielle Unterbrechung von System/Support zu vermeiden.
Einstellung von Kafka 1.1 für Kafka-Cluster in HDInsight 4.0
Ab dem 1. Juli 2020 können Kunden in HDInsight 4.0 keine neuen Kafka-Cluster mit Kafka 1.1 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Es empfiehlt sich, in HDInsight 4.0 bis zum 30. Juni 2020 auf Kafka 2.1 umzustellen, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Verhaltensänderungen
Änderung der Hauptknotengröße für Spark-Cluster mit Enterprise-Sicherheitspaket (ESP)
Die kleinstmögliche Hauptknotengröße für Spark-Cluster mit Enterprise-Sicherheitspaket wird in „Standard_D13_V2“ geändert. Virtuelle Computer mit einer geringen Anzahl von Kernen und wenig Arbeitsspeicher können aufgrund der relativ geringen CPU- und Speicherkapazität als Hauptknoten zu ESP-Clusterproblemen führen. Verwenden Sie als Hauptknoten für Spark-Cluster mit Enterprise-Sicherheitspaket ab dem Release SKUs, die über „Standard_D13_V2“ und „Standard_E16_V3“ liegen.
Virtueller Computer mit mindestens vier Kernen erforderlich für den Hauptknoten
Um die Hochverfügbarkeit und Zuverlässigkeit von HDInsight-Clustern zu gewährleisten, wird für den Hauptknoten ein virtueller Computer mit mindestens vier Kernen benötigt. Ab dem 6. April 2020 können Kunden nur noch VMs mit mindestens vier Kernen als Hauptknoten für die neuen HDInsight-Cluster auswählen. Vorhandene Cluster funktionieren weiterhin erwartungsgemäß.
Änderung bei der Bereitstellung von Workerknoten für Cluster
Wenn 80 Prozent der Workerknoten bereit sind, ist der Cluster betriebsbereit. Kunden können nun alle Vorgänge auf der Datenebene nutzen und beispielsweise Skripts und Aufträge ausführen. Vorgänge auf der Steuerungsebene (etwa das Hoch-/Herunterskalieren) stehen dagegen nicht zur Verfügung. Nur Löschvorgänge werden unterstützt.
Im Anschluss an die Phase Betriebsbereit wartet der Cluster noch 60 Minuten auf die restlichen 20 Prozent der Workerknoten. Nach dieser 60 Minuten-Periode wechselt das Cluster in die Ausführungsphase, auch wenn noch nicht alle Workerknoten verfügbar sind. Sobald sich ein Cluster in der Ausführungsphase befindet, können er ganz normal verwendet werden. Sowohl Vorgänge auf der Steuerungsebene (etwa das Hoch-/Herunterskalieren) als auch Vorgänge auf der Datenebene (beispielsweise das Ausführen von Skripts und Aufträgen) werden akzeptiert. Sollten einige der angeforderten Workerknoten nicht verfügbar sein, wird der Cluster als teilweise erfolgreich gekennzeichnet. Ihnen werden die Knoten in Rechnung gestellt, die erfolgreich bereitgestellt wurden.
Erstellen eines neuen Dienstprinzipals über HDInsight
Bislang konnten Kunden mit der Clustererstellung einen neuen Dienstprinzipal für den Zugriff auf das verbundene ADLS Gen 1-Konto im Azure-Portal erstellen. Ab dem 15. Juni 2020 kann im Rahmen des HDInsight-Erstellungsworkflows kein neuer Dienstprinzipal mehr erstellet werden, und es wird nur noch ein bereits vorhandener Dienstprinzipal unterstützt. Weitere Informationen finden Sie unter Gewusst wie: Erstellen einer Azure AD-Anwendung und eines Dienstprinzipals mit Ressourcenzugriff über das Portal.
Timeout für Skriptaktionen mit Clustererstellung
HDInsight unterstützt das Ausführen von Skriptaktionen mit Clustererstellung. Ab diesem Release müssen alle Skriptaktionen mit Clustererstellung innerhalb von 60 Minuten abgeschlossen werden. Andernfalls tritt ein Timeout auf. An aktive Cluster übermittelte Skriptaktionen sind davon nicht betroffen. Ausführlichere Informationen finden Sie hier.
Bevorstehende Änderungen
Es stehen keine Breaking Changes an, um die Sie sich kümmern müssen.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Änderung der Komponentenversion
HBase 2.0 auf 2.1.6
Die HBase-Version wird von 2.0 auf 2.1.6 aktualisiert.
Spark 2.4.0 auf 2.4.4
Die Spark-Version wird von 2.4.0 auf 2.4.4 aktualisiert.
Kafka 2.1.0 auf 2.1.1
Die Kafka-Version wird von 2.1.0 auf 2.1.1 aktualisiert.
Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie in dieser Dokumentation.
Bekannte Probleme
Problem mit Hive Warehouse Connector
In diesem Release gibt es ein Problem mit Hive Warehouse Connector. Eine entsprechende Korrektur wird in das nächste Release aufgenommen. Cluster, die vor diesem Release erstellt wurden, sind nicht davon betroffen. Vermeiden Sie nach Möglichkeit das Löschen und Neuerstellen des Clusters. Sollten Sie weitere Unterstützung benötigen, erstellen Sie ein Supportticket.
Veröffentlichungsdatum: 09.01.2020
Diese Version gilt für HDInsight 3.6 und 4.0. Das HDInsight-Release wird über mehrere Tage für alle Regionen verfügbar gemacht. Das hier angegebene Veröffentlichungsdatum entspricht dem Veröffentlichungsdatum in der ersten Region. Es kann sein, dass die unten angegebenen Änderungen in Ihrer Region erst einige Tage später verfügbar werden.
Neue Funktionen
Erzwingen von TLS 1.2
Transport Layer Security (TLS) und Secure Sockets Layer (SSL) sind kryptografische Protokolle, die Kommunikationssicherheit über ein Computernetzwerk bereitstellen. Erfahren Sie mehr über TLS. HDInsight verwendet auf öffentlichen HTTPS-Endpunkten TLS 1.2, TLS 1.1 wird jedoch aus Gründen der Abwärtskompatibilität weiterhin unterstützt.
Mit diesem Release können Kunden nur TLS 1.2 für alle Verbindungen über den öffentlichen Clusterendpunkt auswählen. Zur Unterstützung dieser Möglichkeit wird die neue minSupportedTlsVersion-Eigenschaft eingeführt, die bei der Clustererstellung angegeben werden kann. Wenn die Eigenschaft nicht festgelegt ist, unterstützt der Cluster weiterhin TLS 1.0, 1.1 und 1.2. Dies entspricht dem derzeitigen Verhalten. Kunden können den Wert für diese Eigenschaft auf „1.2“ festlegen, damit der Cluster nur TLS 1.2 und höher unterstützt. Weitere Informationen finden Sie unter Transport Layer Security.
Bring Your Own Key für Datenträgerverschlüsselung
Alle verwalteten Datenträger in HDInsight werden mit der Speicherdienstverschlüsselung (Storage Service Encryption, SSE) von Azure geschützt. Die Daten auf diesen Datenträgern werden standardmäßig mit von Microsoft verwalteten Schlüsseln verschlüsselt. Ab diesem Release können Sie Bring Your Own Key (BYOK) für die Datenträgerverschlüsselung auswählen und mithilfe von Azure Key Vault verwalten. Die BYOK-Verschlüsselung ist eine Konfiguration in einem einzigen Schritt bei der Clustererstellung ohne weitere Kosten. Registrieren Sie beim Erstellen Ihres Clusters lediglich HDInsight als verwaltete Identität bei Azure Key Vault, und fügen Sie den Verschlüsselungsschlüssel hinzu. Weitere Informationen finden Sie unter Datenträgerverschlüsselung mit kundenseitig verwalteten Schlüsseln.
Eingestellte Unterstützung
Keine eingestellte Unterstützung für diese Version. Informationen zur Vorbereitung auf anstehende Einstellungen finden Sie unter Bevorstehende Änderungen.
Verhaltensänderungen
Keine Verhaltensänderungen für diese Version. Informationen zur Vorbereitung auf anstehende Änderungen finden Sie unter Bevorstehende Änderungen.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen durchgeführt.
Einstellung der Unterstützung von Spark 2.1 und 2.2 für Spark-Cluster in HDInsight 3.6
Ab dem 1. Juli 2020 können Kunden in HDInsight 3.6 keine neuen Spark-Cluster mit Spark 2.1 und 2.2 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Es empfiehlt sich, in HDInsight 3.6 bis zum 30. Juni 2020 auf Spark 2.3 umzustellen, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Einstellung der Unterstützung von Spark 2.3 für Spark-Cluster in HDInsight 4.0
Ab dem 1. Juli 2020 können Kunden in HDInsight 4.0 keine neuen Spark-Cluster mit Spark 2.3 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Es empfiehlt sich, in HDInsight 4.0 bis zum 30. Juni 2020 auf Spark 2.4 umzustellen, um potenzielle System-/Supportunterbrechungen zu vermeiden.
Einstellung von Kafka 1.1 für Kafka-Cluster in HDInsight 4.0
Ab dem 1. Juli 2020 können Kunden in HDInsight 4.0 keine neuen Spark-Cluster mit Kafka 1.1 mehr erstellen. Vorhandene Cluster werden unverändert ohne Unterstützung durch Microsoft ausgeführt. Es empfiehlt sich, in HDInsight 4.0 bis zum 30. Juni 2020 auf Kafka 2.1 umzustellen, um potenzielle System-/Supportunterbrechungen zu vermeiden. Weitere Informationen finden Sie unter Migrieren von Apache Kafka-Workloads zu Azure HDInsight 4.0.
HBase 2.0 auf 2.1.6
Im bevorstehenden Release von HDInsight 4.0 erfolgt ein Upgrade der HBase-Version von Version 2.0 auf 2.1.6.
Spark 2.4.0 auf 2.4.4
Im bevorstehenden Release von HDInsight 4.0 erfolgt ein Upgrade der Spark-Version von Version 2.4.0 auf 2.4.4.
Kafka 2.1.0 auf 2.1.1
Im bevorstehenden Release von HDInsight 4.0 erfolgt ein Upgrade der Kafka-Version von Version 2.1.0 auf 2.1.1.
Virtueller Computer mit mindestens vier Kernen erforderlich für den Hauptknoten
Um die Hochverfügbarkeit und Zuverlässigkeit von HDInsight-Clustern zu gewährleisten, wird für den Hauptknoten ein virtueller Computer mit mindestens vier Kernen benötigt. Ab dem 6. April 2020 können Kunden nur noch VMs mit mindestens vier Kernen als Hauptknoten für die neuen HDInsight-Cluster auswählen. Vorhandene Cluster funktionieren weiterhin erwartungsgemäß.
Änderung der Knotengröße für ESP Spark-Cluster
Im anstehenden Release wird die minimal zulässige Knotengröße für ESP Spark-Cluster in Standard_D13_V2 geändert. VMs der A-Serie können aufgrund der relativ geringen CPU- und Speicherkapazität zu ESP-Clusterproblemen führen. Die Unterstützung von VMs der A-Serie zum Erstellen von neuen ESP-Clustern wird eingestellt.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Im anstehenden Release verwendet HDInsight stattdessen Azure-VM-Skalierungsgruppen. Informieren Sie sich ausführlicher über Azure-VM-Skalierungsgruppen.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Änderung der Komponentenversion
Für dieses Release gibt es keine Änderung der Komponentenversion. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie hier.
Veröffentlichungsdatum: 17.12.2019
Diese Version gilt für HDInsight 3.6 und 4.0.
Neue Funktionen
Diensttags
Diensttags bieten vereinfachte Sicherheit für virtuelle Azure-Computer und virtuelle Azure-Netzwerke, indem Sie den Netzwerkzugriff auf die Azure-Dienste problemlos einschränken können. Sie können Diensttags in Ihren Regeln für Netzwerksicherheitsgruppen (NSGs) verwenden, um Datenverkehr für einen bestimmten Azure-Dienst global oder nach Azure-Region zuzulassen oder zu verweigern. Azure bietet die Wartung von IP-Adressen, die den einzelnen Tags zugrunde liegen. HDInsight-Diensttags für Netzwerksicherheitsgruppen (NSGs) sind Gruppen von IP-Adressen für Integritäts- und Verwaltungsdienste. Diese Gruppen reduzieren die Komplexität beim Erstellen von Sicherheitsregeln. HDInsight-Kunden können Diensttags über das Azure-Portal, PowerShell und die REST-API aktivieren. Weitere Informationen finden Sie unter NSG-Diensttags (Netzwerksicherheitsgruppen) für Azure HDInsight.
Benutzerdefinierte Ambari-Datenbank
HDInsight ermöglicht nun die Verwendung Ihrer eigenen SQL-Datenbank für Apache Ambari. Sie können diese benutzerdefinierte Ambari-Datenbank über das Azure-Portal oder über eine Resource Manager-Vorlage konfigurieren. Diese Funktion ermöglicht es Ihnen, die richtige SQL-Datenbank für Ihre Verarbeitungs- und Kapazitätsanforderungen auszuwählen. Sie können auch problemlos ein Upgrade durchführen, um den Anforderungen des Unternehmenswachstums gerecht zu werden. Weitere Informationen finden Sie unter Einrichten von HDInsight-Clustern mit einer benutzerdefinierten Ambari-Datenbank.

Außer Betrieb nehmen
Keine eingestellte Unterstützung für diese Version. Informationen zur Vorbereitung auf anstehende Einstellungen finden Sie unter Bevorstehende Änderungen.
Verhaltensänderungen
Keine Verhaltensänderungen für diese Version. Informationen zur Vorbereitung auf anstehende Verhaltensänderungen finden Sie unter Bevorstehende Änderungen.
Bevorstehende Änderungen
Die folgenden Änderungen werden in kommenden Versionen durchgeführt.
Erzwingung von Transport Layer Security (TLS) 1.2
Transport Layer Security (TLS) und Secure Sockets Layer (SSL) sind kryptografische Protokolle, die Kommunikationssicherheit über ein Computernetzwerk bereitstellen. Weitere Informationen finden Sie unter Transport Layer Security. Zwar werden TLS 1.2-Verbindungen an öffentlichen HTTPS-Endpunkten von Azure HDInsight-Clustern akzeptiert, doch wird TLS 1.1 weiterhin aus Gründen der Abwärtskompatibilität mit älteren Clients unterstützt.
Ab der nächsten Version sind Sie in der Lage, Ihre neuen HDInsight-Cluster so zu konfigurieren, dass nur TLS 1.2-Verbindungen akzeptiert werden.
Später im Jahr, ab dem 30.06.2020, wird in Azure HDInsight die Verwendung von TLS 1.2 oder höheren Versionen für alle HTTPS-Verbindungen erzwungen. Es wird empfohlen sicherzustellen, dass alle Ihre Clients für die Verarbeitung von TLS 1.2 oder höheren Versionen geeignet sind.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Ab Februar 2020 (das genaue Datum wird noch mitgeteilt) verwendet HDInsight stattdessen Azure Virtual Machine Scale Sets. Weitere Informationen zu Azure-VM-Skalierungsgruppen.
Änderung der Knotengröße für ESP Spark-Cluster
In der nächsten Version:
- Die minimal zulässige Knotengröße für ESP Spark-Cluster wird in Standard_D13_V2 geändert.
- Die Unterstützung von VMs der A-Serie für das Erstellen neuer ESP-Cluster wird eingestellt, da VMS der A-Serie aufgrund der relativ geringen CPU- und Speicherkapazität zu ESP-Clusterproblemen führen können.
HBase 2.0 zu 2.1
Im bevorstehenden Release von HDInsight 4.0 erfolgt ein Upgrade der HBase-Version von Version 2.0 auf 2.1.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Änderung der Komponentenversion
Die Unterstützung von HDInsight 3.6 wurde bis zum 31. Dezember 2020 verlängert. Weitere Informationen finden Sie unter Unterstützte HDInsight-Versionen.
Keine Änderung der Komponentenversion für HDInsight 4.0.
Apache Zeppelin in HDInsight 3.6: 0.7.0 > 0.7.3.
Die aktuellsten Komponentenversionen finden Sie diesem Dokument.
Neue Regionen
Vereinigte Arabische Emirate, Norden
Die Verwaltungs-IP-Adressen von „Vereinigte Arabische Emirate, Norden“ sind 65.52.252.96 und 65.52.252.97.
Veröffentlichungsdatum: 07.11.2019
Diese Version gilt für HDInsight 3.6 und 4.0.
Neue Funktionen
HDInsight Identity Broker (HIB) (Vorschauversion)
HDInsight Identity Broker (HIB) ermöglicht es Benutzern, sich über Multi-Factor Authentication (MFA) bei Apache Ambari anzumelden und die erforderlichen Kerberos-Tickets zu erhalten, ohne dass Kennworthashes in Azure Active Directory Domain Services (AAD-DS) erforderlich sind. Derzeit ist HIB nur für Cluster verfügbar, die über eine ARM-Vorlage (Azure Resource Management) bereitgestellt werden.
Kafka-REST-API-Proxy (Vorschauversion)
Der Kafka-REST-API-Proxy bietet die Bereitstellung eines hochverfügbaren REST-Proxys mit Kafka-Cluster über eine gesicherte Azure AD-Autorisierung und ein OAuth-Protokoll mit nur einem Klick.
Automatische Skalierung
Die Autoskalierung für Azure HDInsight ist jetzt in allen Regionen für Apache Spark- und Hadoop-Clustertypen allgemein verfügbar. Dieses Feature ermöglicht es, Big Data-Workloads kostengünstiger und auf produktivere Weise zu verwalten. Jetzt können Sie die Verwendung Ihrer HDInsight-Cluster optimieren und dabei die bedarfsabhängige Bezahlung nutzen.
Abhängig von Ihren Anforderungen können Sie zwischen der lastbasierten und der zeitplanbasierten Autoskalierung wählen. Mit der lastbasierten Autoskalierung kann die Clustergröße basierend auf den aktuellen Ressourcenanforderungen hoch- und herunterskaliert werden, während bei der zeitplanbasierten Autoskalierung die Clustergröße basierend auf einem vordefinierten Zeitplan geändert werden kann.
Die Unterstützung für die Autoskalierung von HBase- und LLAP-Workloads befindet sich ebenfalls in der öffentlichen Vorschauversion. Weitere Informationen finden Sie unter Automatische Skalierung von Azure HDInsight-Clustern.
Beschleunigte HDInsight-Schreibvorgänge für Apache HBase
Bei „Beschleunigte Schreibvorgänge“ werden verwaltete Azure-Premium-SSD-Datenträger zur Verbesserung der Leistung des Apache HBase-Write-Ahead-Protokolls (Write Ahead Log, WAL) verwendet. Weitere Informationen finden Sie unter Beschleunigte Azure HDInsight-Schreibvorgänge für Apache HBase.
Benutzerdefinierte Ambari-Datenbank
HDInsight bietet jetzt eine neue Kapazität, mit der Kunden ihre eigene SQL-Datenbank für Ambari verwenden können. Kunden können nun die richtige SQL-Datenbank für Ambari auswählen und sie auf einfache Weise basierend auf ihren eigenen geschäftlichen Wachstumsanforderungen aktualisieren. Die Bereitstellung erfolgt über eine Azure Resource Manager-Vorlage. Weitere Informationen finden Sie unter Einrichten von HDInsight-Clustern mit einer benutzerdefinierten Ambari-Datenbank.
Virtuelle Computer der F-Serie sind jetzt mit HDInsight verfügbar.
Virtuelle Computer (VMs) der F-Serie sind eine gute Wahl für die ersten Schritte mit HDInsight bei geringen Verarbeitungsanforderungen. Die F-Serie hat einen niedrigeren Listenpreis pro Stunde und bietet auf Basis der Azure-Compute-Einheit (Azure Compute Unit, ACU) das beste Preis-Leistungs-Verhältnis pro vCPU im Azure-Portfolio. Weitere Informationen finden Sie unter Auswählen der richtigen VM-Größe für Ihren Azure HDInsight-Cluster.
Eingestellte Unterstützung
Eingestellte Unterstützung der virtuellen Computer der G-Serie
Ab dieser Version werden VMs der G-Serie in HDInsight nicht mehr angeboten.
Eingestellte Unterstützung der virtuellen Dv1-Computer
Ab dieser Version wird die Verwendung von Dv1-VMs mit HDInsight nicht mehr unterstützt. Jegliche Kundenanforderungen für Dv1 werden automatisch mit Dv2 bedient. Es gibt keinen Preisunterschied zwischen Dv1- und Dv2-VMs.
Verhaltensänderungen
Änderung der Größe des verwalteten Clusterdatenträgers
HDInsight stellt verwalteten Speicherplatz auf dem Datenträger mit dem Cluster bereit. Ab dieser Version wird die Größe des verwalteten Datenträgers der einzelnen Knoten im neu erstellten Cluster in 128 GB geändert.
Bevorstehende Änderungen
Die folgenden Änderungen werden in den kommenden Versionen durchgeführt.
Wechsel zu Azure-VM-Skalierungsgruppen
HDInsight verwendet jetzt virtuelle Azure-Computer für die Bereitstellung des Clusters. Ab Dezember wird HDInsight stattdessen Azure-VM-Skalierungsgruppen verwenden. Weitere Informationen zu Azure-VM-Skalierungsgruppen.
HBase 2.0 zu 2.1
Im bevorstehenden Release von HDInsight 4.0 erfolgt ein Upgrade der HBase-Version von Version 2.0 auf 2.1.
Eingestellte Unterstützung der virtuellen Computer der A-Serie für ESP-Cluster
VMs der A-Serie können aufgrund der relativ geringen CPU- und Speicherkapazität zu ESP-Clusterproblemen führen. In der kommenden Version wird die Unterstützung von VMs der A-Serie zum Erstellen von neuen ESP-Clustern eingestellt.
Behebung von Programmfehlern
HDInsight sorgt weiterhin für Verbesserungen bei der Clusterzuverlässigkeit und -leistung.
Änderung der Komponentenversion
Für diese Version gibt es keine Änderung der Komponentenversion. Die aktuellen Komponentenversionen für HDInsight 4.0 und HDInsight 3.6 finden Sie hier.
Veröffentlichungsdatum: 07.08.2019
Komponentenversionen
Die offiziellen Apache-Versionen aller HDInsight 4.0-Komponenten werden unten aufgeführt. Die aufgelisteten Komponenten stellen Releases der neuesten stabilen Versionen dar, die verfügbar sind.
- Apache Ambari 2.7.1
- Apache Hadoop 3.1.1
- Apache HBase 2.0.0
- Apache Hive 3.1.0
- Apache Kafka 1.1.1, 2.1.0
- Apache Mahout 0.9.0 und höher
- Apache Oozie 4.2.0
- Apache Phoenix 4.7.0
- Apache Pig 0.16.0
- Apache Ranger 0.7.0
- Apache Slider 0.92.0
- Apache Spark 2.3.1, 2.4.0
- Apache Sqoop 1.4.7
- Apache TEZ 0.9.1
- Apache Zeppelin 0.8.0
- Apache ZooKeeper 3.4.6
Höhere Versionen von Apache-Komponenten werden gelegentlich zusätzlich zu den oben aufgeführten Versionen in der HDP-Distribution gebündelt. In diesem Fall werden diese neueren Versionen in der Technical Previews-Tabelle aufgeführt. Diese sollten die oben aufgeführten Versionen der Apache-Komponenten in einer Produktionsumgebung nicht ersetzen.
Apache-Patchinformationen
Weitere Informationen zu den in HDInsight 4.0 verfügbaren Patches finden Sie in der Patchauflistung zu den einzelnen Produkten in der Tabelle unten.
| Produktname | Patchinformationen |
|---|---|
| Ambari | Ambari-Patchinformationen |
| Hadoop | Hadoop-Patchinformationen |
| hbase | HBase-Patchinformationen |
| Hive | Dieses Release stellt Hive 3.1.0 ohne weitere Apache-Patches bereit. |
| Kafka | Dieses Release stellt Kafka 1.1.1 ohne weitere Apache-Patches bereit. |
| Oozie | Oozie-Patchinformationen |
| Phoenix | Phoenix-Patchinformationen |
| Pig | Pig-Patchinformationen |
| Ranger | Ranger-Patchinformationen |
| Spark | Spark-Patchinformationen |
| Sqoop | Dieses Release stellt Sqoop 1.4.7 ohne weitere Apache-Patches bereit. |
| Tez | Dieses Release stellt Tez 0.9.1 ohne weitere Apache-Patches bereit. |
| Zeppelin | Dieses Release stellt Zeppelin 0.8.0 ohne weitere Apache-Patches bereit. |
| Zookeeper | Zookeeper-Patchinformationen |
Behobene Common Vulnerabilities and Exposures
Weitere Informationen zu den in dieser Version behobenen Sicherheitsproblemen finden Sie unter in Hortonworks Behobene Common Vulnerabilities and Exposures für HDP 3.0.1.
Bekannte Probleme
Die Replikation ist für Secure HBase in der Standardinstallation nicht funktional
Führen Sie für HDInsight 4.0 die folgenden Schritte aus:
Aktivieren Sie die Kommunikation zwischen Clustern.
Melden Sie sich beim aktiven Hauptknoten an.
Laden Sie mit dem folgenden Befehl ein Skript zum Aktivieren der Replikation herunter:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shGeben Sie den Befehl
sudo kinit <domainuser>ein.Geben Sie den folgenden Befehl ein, um das Skript auszuführen:
sudo bash hdi_enable_replication.sh -m <hn*> -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Für HDInsight 3.6
Melden Sie sich beim aktiven HMaster ZK an.
Laden Sie mit dem folgenden Befehl ein Skript zum Aktivieren der Replikation herunter:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.shGeben Sie den Befehl
sudo kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<FQDN>@<DOMAIN>ein.Geben Sie folgenden Befehl ein:
sudo bash hdi_enable_replication.sh -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
Phoenix Sqlline funktioniert nach dem Migrieren des HBase-Clusters nach HDInsight 4.0 nicht mehr
Führen Sie die folgenden Schritte aus:
- Löschen Sie die folgenden Phoenix-Tabellen:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.MUTEXSYSTEM.CATALOG
- Wenn Sie keine der Tabellen löschen können, starten Sie HBase neu, um alle Verbindungen mit den Tabellen zu löschen.
- Führen Sie
sqlline.pyerneut aus. Phoenix erstellt alle Tabellen, die in Schritt 1 gelöscht wurden, erneut. - Regenerieren Sie die Phoenix-Tabellen und -Ansichten für Ihre HBase-Daten.
Phoenix Sqlline funktioniert nach der Replikation von HBase Phoenix-Metadaten von HDInsight 3.6 nach 4.0 nicht mehr
Führen Sie die folgenden Schritte aus:
- Wechseln Sie vor dem Ausführen der Replikation zum 4.0-Zielcluster, und führen Sie
sqlline.pyaus. Dieser Befehl generiert Phoenix-Tabellen wieSYSTEM.MUTEXundSYSTEM.LOG, die nur in Version 4.0 bestehen. - Löschen Sie die folgenden Tabellen:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.CATALOG
- Starten Sie die HBase-Replikation
Eingestellte Unterstützung
Die Apache-Dienste Storm und ML stehen in HDInsight 4.0 nicht zur Verfügung.
Veröffentlichungsdatum: 14.04.2019
Neue Funktionen
Die neuen Updates und Funktionen fallen in die folgenden Kategorien:
Update von Hadoop und anderen Open-Source-Projekten – Zusätzlich zu über 1000 Fehlerkorrekturen in mehr als 20 Open-Source-Projekten enthält dieses Update eine neue Version von Spark (2.3) und Kafka (1.0).
Update von R Server 9.1 auf Machine Learning Services 9.3 – Mit diesem Release erhalten Datenwissenschaftler und Entwickler das Beste aus dem Open-Source-Bereich, ergänzt durch algorithmische Innovationen und einfache Operationalisierung, alles in ihrer bevorzugten Sprache und mit der Geschwindigkeit von Apache Spark. Dieses Release erweitert die in R Server angebotenen Funktionen um die Unterstützung für Python, was zur Änderung des Clusternamens von R Server zu ML Services geführt hat.
Unterstützung für Azure Data Lake Storage Gen2 – HDInsight unterstützt die Vorschauversion von Azure Data Lake Storage Gen2. In den verfügbaren Regionen können Kunden ein ADLS Gen2-Konto als primären oder sekundären Speicher für ihre HDInsight-Cluster auswählen.
Updates für HDInsight-Enterprise-Sicherheitspaket (Vorschau):VNET-Dienstendpunkte unterstützen Azure Blob Storage, ADLS Gen1, Azure Cosmos DB und Azure DB.
Komponentenversionen
Die offiziellen Apache-Versionen aller HDInsight 3.6-Komponenten werden unten aufgeführt. Alle hier aufgeführten Komponenten sind offizielle Apache-Releases der neuesten stabilen Versionen, die verfügbar sind.
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0 und höher
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
Höhere Versionen einiger Apache-Komponenten werden gelegentlich zusätzlich zu den oben aufgeführten Versionen in der HDP-Distribution gebündelt. In diesem Fall werden diese neueren Versionen in der Technical Previews-Tabelle aufgeführt. Diese sollten die oben aufgeführten Versionen der Apache-Komponenten in einer Produktionsumgebung nicht ersetzen.
Apache-Patchinformationen
Hadoop
Dieses Release stellt Hadoop Common 2.7.3 und die folgenden Apache-Patches bereit:
HADOOP-13190: Mention LoadBalancingKMSClientProvider in KMS HA documentation. (Erwähnung von LoadBalancingKMSClientProvider in der Dokumentation zu KMS HA.)
HADOOP-13227: AsyncCallHandler should use an event driven architecture to handle async calls. (AsyncCallHandler sollte eine ereignisgesteuerte Architektur zum Verarbeiten von asynchronen Aufrufen verwenden.)
HADOOP-14104: Client should always ask namenode for kms provider path. (Der Client sollte immer NameNode für den Pfad des KMS-Anbieters abfragen.)
HADOOP-14799: Update von Nimbus-JOSE-JWT auf Version 4.41.1
HADOOP-14814: Fix incompatible API change on FsServerDefaults to HADOOP-14104. (Behebung einer inkompatiblen API-Änderung an FsServerDefaults für HADOOP-14104.)
HADOOP-14903: Add json-smart explicitly to pom.xml. (Explizites Hinzufügen von json-smart zur Datei „pom.xml“.)
HADOOP-15042: Azure PageBlobInputStream.skip() can return negative value when numberOfPagesRemaining is 0. (Azure PageBlobInputStream.skip() kann einen negativen Wert zurückgeben, wenn numberOfPagesRemaining 0 (null) ist.)
HADOOP-15255: Upper/Lower case conversion support for group names in LdapGroupsMapping. (Unterstützung der Anpassung der Groß-/Kleinschreibung für Gruppennamen in LdapGroupsMapping.)
HADOOP-15265: exclude json-smart explicitly from hadoop-auth pom.xml. (Explizites Ausschließen von json-smart aus „hadoop-auth pom.xml“)
HDFS-7922: ShortCircuitCache#close isn't releasing ScheduledThreadPoolExecutors. (ShortCircuitCache#close gibt ScheduledThreadPoolExecutors nicht frei.)
HDFS-8496: Calling stopWriter() with FSDatasetImpl lock held may block other threads (cmccabe). (Aufrufen von stopWriter() während FSDatasetImpl lock aktiv ist, kann andere Threads blockieren (cmccabe).)
HDFS-10267: Extra "synchronized" on FsDatasetImpl#recoverAppend and FsDatasetImpl#recoverClose. (Überflüssiges „synchronized“ in FsDatasetImpl#recoverAppend und FsDatasetImpl#recoverClose.)
HDFS-10489: Deprecate dfs.encryption.key.provider.uri for HDFS encryption zones. (dfs.encryption.key.provider.uri ist für HDFS-Verschlüsselungszonen veraltet).
HDFS-11384: Add option for balancer to disperse getBlocks calls to avoid NameNode's rpc.CallQueueLength spike. (Option zum Auflösen von getBlocks-Aufrufen für Balancer hinzugefügt, um Spike von NameNodes rpc.CallQueueLength zu vermeiden.)
HDFS-11689: Neue von
DFSClient%isHDFSEncryptionEnabledausgelöste Ausnahme hathackyHive-Code kaputt gemacht.HDFS-11711: DN should not delete the block On "Too many open files" Exception. (DN sollte den Block der Ausnahme „zu viele geöffnete Dateien“ nicht löschen.)
HDFS-12347: TestBalancerRPCDelay#testBalancerRPCDelay fails frequently. (TestBalancerRPCDelay#testBalancerRPCDelay schlägt häufig fehl.)
HDFS-12781: Nach Ausfall von
DatanodeinNamenodeUIDatanodeRegisterkarte zeigt eine Warnmeldung an.HDFS-13054: Handling PathIsNotEmptyDirectoryException in
DFSClientdelete call. (Verarbeiten von PathIsNotEmptyDirectoryException in (x) löscht den Aufruf.)HDFS-13120: Snapshot diff could be corrupted after concat. (Vergleich einer Momentaufnahme kann nach concat beschädigt sein.)
YARN-3742: YARN RM will shut down if
ZKClientcreation times out. (YARN-RM wird beendet, wenn ein Timeout bei der Erstellung von (x) auftritt.)YARN-6061: Add an UncaughtExceptionHandler for critical threads in RM. (UncaughtExceptionHandler für kritische Threads in Resource Manager hinzugefügt.)
YARN-7558: yarn logs command fails to get logs for running containers if UI authentication is enabled. (Befehl „yarn logs“ kann Protokolle für ausgeführte Container nicht abrufen, wenn Benutzeroberflächenauthentifizierung aktiviert ist.)
YARN-7697: Fetching logs for finished application fails even though log aggregation is complete. (Abrufen von Protokollen für abgeschlossene Anwendungen schlägt fehl, selbst wenn die Protokollaggregation abgeschlossen ist.)
Mit HDP-2.6.4 wurde Hadoop Common 2.7.3 mit den folgenden Apache-Patches bereitgestellt:
HADOOP-13700: Remove unthrown
IOExceptionfrom TrashPolicy#initialize and #getInstance signatures. (Nicht ausgelöste (x) aus den Signaturen TrashPolicy#initialize und #getInstance entfernt.)HADOOP-13709: Ability to clean up subprocesses spawned by Shell when the process exits. (Möglichkeit zum Bereinigen von Unterprozessen von Shell, wenn der Prozess beendet wird.)
HADOOP-14059: typo in
s3arename(self, subdir) error message. (Tippfehler in der Fehlermeldung zu (x) rename(self, subdir) behoben.)HADOOP-14542: Add IOUtils.cleanupWithLogger that accepts slf4j logger API. (IOUtils.cleanupWithLogger hinzugefügt, der die slf4j logger-API akzeptiert.)
HDFS-9887: WebHdfs socket timeouts should be configurable. (Timeouts von WebHdfs socket sollten konfigurierbar sein.)
HDFS-9914: Fix configurable WebhDFS connect/read timeout. (Konfigurierbarer Timeout von WebhDFS connect/read behoben.)
MAPREDUCE-6698: Increase timeout on TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser. (Timeout für TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser erhöht.)
YARN-4550: Some tests in TestContainerLanch fail on non-english locale environment. (Einige Tests in TestContainerLaunch schlagen bei nicht englischen Gebietsschemas fehl.)
YARN-4717: TestResourceLocalizationService.testPublicResourceInitializesLocalDir fails Intermittently due to IllegalArgumentException from cleanup. (TestResourceLocalizationService.testPublicResourceInitializesLocalDir schlägt gelegentlich aufgrund von IllegalArgumentException durch die Bereinigung fehl.)
YARN-5042: Mount /sys/fs/cgroup into Docker containers as readonly mount. (Einlegen von /sys/fs/cgroup in Docker-Container als schreibgeschützte Einlage.)
YARN-5318: Fix intermittent test failure of TestRMAdminService#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider. (Tests von TestRMAdminService#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider schlagen gelegentlich fehl.)
YARN-5641: Localizer leaves behind tarballs after container is complete. (Lokalisierer hinterlässt tarballs nachdem der Container abgeschlossen ist.)
YARN-6004: Refactor TestResourceLocalizationService#testDownloadingResourcesOnContainer so that it is less than 150 lines. (Umgestaltung von TestResourceLocalizationService#testDownloadingResourcesOnContainer, damit es weniger als 150 Zeilen sind.)
YARN-6078: Containers stuck in Localizing state. (Container bleiben im Lokalisierungszustand stehen.)
YARN-6805: NPE in LinuxContainerExecutor due to null PrivilegedOperationException exit code. (NPE in LinuxContainerExecutor aufgrund von NULL bei PrivilegedOperationException#getExitCode.)
hbase
Dieses Release stellt HBase 1.1.2 und die folgenden Apache-Patches bereit:
HBASE-13376: Improvements to Stochastic load balancer. (Verbesserungen des stochastischen Lastenausgleichsmoduls.)
HBASE-13716: Stop using Hadoop's FSConstants. (Beenden der Verwendung der FSConstants von Hadoop.)
HBASE-13848: Access InfoServer SSL passwords through Credential Provider API. (Zugriff auf InfoServer SSL-Kennwörter über die Anmeldeinformationsanbieter-API.)
HBASE-13947: Use MasterServices instead of Server in AssignmentManager. (Verwendung von MasterServices anstelle von Server in AssignmentManager.)
HBASE-14135: Phase 3 für HBase-Sicherung/-Wiederherstellung: Zusammenführen der Sicherungsimages.
HBASE-14473: Compute region locality in parallel. (Paralleles Berechnen der Bereichslokalität.)
HBASE-14517: Show
regionserver'sversion in master status page. (Anzeigen der Version von (x) auf der Master-Statusseite.)HBASE-14606: TestSecureLoadIncrementalHFiles tests timed out in trunk build on apache. (Timeouts von TestSecureLoadIncrementalHFiles-Tests im Trunk-Build in Apache.)
HBASE-15210: Undo aggressive load balancer logging at tens of lines per millisecond. (Zurücksetzen aggressiver Lastenausgleichsprotokollierung mit zehn Zeilen pro Millisekunde.)
HBASE-15515: Improve LocalityBasedCandidateGenerator in Balancer. (Verbesserung von LocalityBasedCandidateGenerator im Lastenausgleich.)
HBASE-15615: Wrong sleep time when
RegionServerCallableneed retry. (Falsche Sleep Time, wenn (x) einen neuen Versuch braucht.)HBASE-16135: PeerClusterZnode under rs of removed peer may never be deleted. (PeerClusterZnode unter rs von entferntem Peer kann nicht gelöscht werden.)
HBASE-16570: Compute region locality in parallel. (Paralleles Berechnen der Bereichslokalität zum Start.)
HBASE-16810: HBase Balancer throws ArrayIndexOutOfBoundsException when
regionserversare in /hbase/draining znode and unloaded. (Lastenausgleich von HBase löst ArrayIndexOutOfBoundsException aus, wenn (x) sich in /hbase/draining znode befinden, und (x) wird entladen.)HBASE-16852: TestDefaultCompactSelection failed on branch-1.3. (TestDefaultCompactSelection schlägt unter branch-1.3 fehl.)
HBASE-17387: Reduce the overhead of exception report in RegionActionResult for multi(). (Mehraufwand des Ausnahmeberichts in RegionActionResult für multi() reduziert.)
HBASE-17850: Backup system repair utility. (Sicherung des Hilfsprogramms zum Wiederherstellen des Systems.)
HBASE-17931: Assign system tables to servers with highest version. (Zuweisen von Systemtabellen zu Servern mit der höchsten Version.)
HBASE-18083: Make large/small file clean thread number configurable in HFileCleaner. (Threadanzahl in HFileCleaner für große/kleine Dateien konfigurierbar.)
HBASE-18084: Improve CleanerChore to clean from directory which consumes more disk space. (Verbesserung von CleanerChore zum Bereinigen von Verzeichnissen, die mehr Speicherplatz auf dem Datenträger beanspruchen.)
HBASE-18164: Much faster locality cost function and candidate generator. (Deutlich schnellere Kostenfunktion und Kandidatengenerator für die Lokalität.)
HBASE-18212: In Standalone mode with local filesystem HBase logs Warning message: Failed to invoke 'unbuffer' method in class org.apache.hadoop.fs.FSDataInputStream. (Im eigenständigen Modus mit lokalen Dateisystem protokolliert HBase die Warnmeldung: „Aufruf der Methode „unbuffer“ in class org.apache.hadoop.fs.FSDataInputStream fehlgeschlagen“.)
HBASE-18808: Ineffective config check-in BackupLogCleaner#getDeletableFiles(). (Ineffektive Überprüfung der Konfiguration in BackupLogCleaner#getDeletableFiles())
HBASE-19052: FixedFileTrailer should recognize CellComparatorImpl class in branch-1.x. (FixedFileTrailer sollte die Klasse CellComparatorImpl unter branch-1.x erkennen.)
HBASE-19065: HRegion#bulkLoadHFiles() should wait for concurrent Region#flush() to finish. (HRegion#bulkLoadHFiles() sollte Beendigung von Region#flush() abwarten.)
HBASE-19285: Add per-table latency histograms. (Hinzufügen von Latenzhistogrammen pro Tabelle.)
HBASE-19393: HTTP-Fehler 413 während Zugriff auf HBase-Benutzeroberfläche mit SSL
HBASE-19395: branch-1 TestEndToEndSplitTransaction.testMasterOpsWhileSplitting fails with NPE. (TestEndToEndSplitTransaction.testMasterOpsWhileSplitting schlägt unter branch-1 mit NPE fehl.)
HBASE-19421: branch-1 does not compile against Hadoop 3.0.0. (Branch-1 kompiliert nicht mit Hadoop 3.0.0.)
HBASE-19934: HBaseSnapshotException when read replicas is enabled and online snapshot is taken after region splitting. (HBaseSnapshotException wird ausgelöst, wenn Lesereplikate aktiviert sind, und eine Online-Momentaufnahme nach dem Aufteilen der Region aufgenommen wird.)
HBASE-20008: [backport] NullPointerException when restoring a snapshot after splitting a region. (NullPointerException wird ausgelöst, wenn eine Momentaufnahme nach dem Aufteilen einer Region wiederhergestellt wird.)
Hive
Dieses Release stellt Hive 1.2.1 und Hive 2.1.0 mit den folgenden Patches bereit:
Apache-Patches zu Hive 1.2.1:
HIVE-10697: ObjectInspectorConvertors#UnionConvertor does a faulty conversion. (ObjectInspectorConvertors#UnionConvertor führt eine fehlerhafte Konvertierung durch.)
HIVE-11266: count(*) wrong result based on table statistics for external tables. (count(*) führt basierend auf den Tabellenstatistiken für externe Tabellen zu einem falschen Ergebnis.)
HIVE-12245: Support column comments for an HBase backed table. (Unterstützung für Spaltenkommentare für eine HBase-Tabelle.)
HIVE-12315: Fix Vectorized double divide by zero. (Vektorisiertes doppeltes Teilen durch 0 (null) behoben.)
HIVE-12360: Bad seek in uncompressed ORC with predicate pushdown. (Fehlerhafte Positionierung in nicht komprimierten ORC mit Prädikat-Pushdown.)
HIVE-12378: Exception on HBaseSerDe.serialize binary field. (Ausnahme im HBaseSerDe.serialize-Binärfeld.)
HIVE-12785: View with union type and UDF to the struct is broken. (Ansicht mit Union-Typ und UDF auf die Struktur ist fehlerhaft.)
HIVE-14013: Describe table doesn't show unicode properly. (Beschreibungstabelle zeigt Unicode nicht ordnungsgemäß an.)
HIVE-14205: Hive doesn't support union type with AVRO file format. (Hive unterstützt den Union-Typ nicht mit dem Dateiformat AVRO.)
HIVE-14421: FS.deleteOnExit holds references to tmpspace.db files. (FS.deleteOnExit enthält Verweise auf „_tmp_space.db“-Dateien)
HIVE-15563: Ausnahme für unzulässigen Übergang des Vorgangsstatus in SQLOperation.runQuery ignorieren, um tatsächliche Ausnahme zur Verfügung zu stellen.
HIVE-15680: Incorrect results when hive.optimize.index.filter=true and same ORC table is referenced twice in query, in MR mode. (Fehlerhafte Ergebnisse bei hive.optimize.index.filter=true, außerdem wird im MR-Modus in der Abfrage doppelt auf die ORC-Tabelle verwiesen.)
HIVE-15883: HBase mapped table in Hive insert fail for decimal. (Eingabe von Dezimalspalten in der Tabelle, die HBase in Hive zugeordnet ist, schlägt fehl.)
HIVE-16232: Support stats computation for columns in QuotedIdentifier. (Unterstützung für die Berechnung von Statistiken für Spalten in QuotedIdentifier.)
HIVE-16828: With CBO enabled, Query on partitioned views throws IndexOutOfBoundException. (Wenn CBO aktiviert ist, lösen Abfragen von partitionierten Ansichten IndexOutOfBoundException aus.)
HIVE-17013: Delete request with a subquery based on select over a view. (Delete-Anforderung mit Unterabfrage basierend auf der Auswahl einer Ansicht.)
HIVE-17063: Insert overwrite partition onto a external table fail when drop partition first. (Einfügen von „overwrite partition“ in eine externe Tabelle schlägt fehl, wenn „drop partition“ zuerst eingefügt wird.)
HIVE-17259: Hive JDBC does not recognize UNIONTYPE columns. (Hive-JDBC erkennt UNIONTYPE-Spalten nicht.)
HIVE-17419: ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS command shows computed stats for masked tables. (Der Befehl „ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS“ zeigt berechnete Statistik für maskierte Tabellen.)
HIVE-17530: ClassCastException when converting
uniontype. (ClassCastException wird beim Konvertieren von (x) ausgelöst.)HIVE-17621: Hive-site settings are ignored during HCatInputFormat split-calculation. (Einstellungen für Hive-site werden während HCatInputFormat::getSplits() ignoriert.)
HIVE-17636: Add multipleagg.q test for
blobstores. (Hinzufügen von „multiple_agg.q“ für (x).)HIVE-17729: Add Database and Explain related blobstore tests. (Hinzufügen von Blobspeicher-Tests für die Datenbank und für einen EXPLAIN-Befehl.)
HIVE-17731: add a backward
compatoption for external users to HIVE-11985. (Hinzufügen einer Option für die (x) in HIVE-11985 für externe Benutzer.)HIVE-17803: With Pig multi-query, 2 HCatStorers writing to the same table will trample each other's outputs. (Wenn Pig-Skripts mehrere Abfragen verwenden, schreiben 2 HCatStorers in die gleiche Tabelle, wodurch die Ausgaben sich überschreiben.)
HIVE-17829: ArrayIndexOutOfBoundsException - HBASE-backed tables with Avro schema in
Hive2. (ArrayIndexOutOfBoundsException wird bei durch HBASE unterstützten Tabellen mit dem Avro-Schema in (x) ausgelöst.)HIVE-17845: insert fails if target table columns are not lowercase. (Eingabe schlägt fehl, wenn die Spalten der Zieltabelle nicht klein geschrieben sind.)
HIVE-17900: analyze stats on columns triggered by Compactor generates malformed SQL with > 1 partition column. (Fehlerhaft formatierter SQL-Code wird mit mehr als einer Partitionsspalte generiert, wenn Statistiken zu Spalten vom Komprimierungsprogramm analysiert werden.)
HIVE-18026: Hive webhcat principal configuration optimization. (Optimierung der Konfiguration des WebHCat-Prinzipals.)
HIVE-18031: Unterstützung der Replikation des Alter Database-Vorgangs
HIVE-18090: acid heartbeat fails when metastore is connected via hadoop credential. (Heartbeat von ACID schlägt fehl, wenn Metastore über Hadoop-Anmeldeinformationen verbunden ist.)
HIVE-18189: Hive query returning wrong results when set hive.groupby.orderby.position.alias to true. (Hive-Abfrage gibt die falschen Ergebnisse zurück, wenn hive.groupby.orderby.position.alias auf TRUE festgelegt ist.)
HIVE-18258: Vectorization: Reduce-Side GROUP BY MERGEPARTIAL with duplicate columns is broken. (Vektorisierung: GROUP BY MERGEPARTIAL ist mit doppelten Spalten fehlerhaft.)
HIVE-18293: Hive is failing to compact tables contained within a folder that is not owned by identity running HiveMetaStore. (Hive kann Tabellen nicht in einem Ordner komprimieren, der nicht der Identität gehört, die HiveMetaStore ausführt.)
HIVE-18327: Remove the unnecessary HiveConf dependency for MiniHiveKdc. (Unnötige Abhängigkeit von HiveConf für MiniHiveKdc entfernt.)
HIVE-18341: Add repl load support for adding "raw" namespace for TDE with same encryption keys. (Dem Befehl „repl load“ wurde Unterstützung für den Namespace „raw“ für TDE mit denselben Verschlüsselungsschlüsseln hinzugefügt.)
HIVE-18352: introduce a METADATAONLY option while doing REPL DUMP to allow integrations of other tools. (Einführung einer METADATAONLY-Option während REPL DUMP, um die Integration anderer Tools zuzulassen.)
HIVE-18353: CompactorMR should call jobclient.close() to trigger cleanup. (CompactorMR sollte jobclient.close() aufrufen, um die Bereinigung auszulösen.)
HIVE-18390: IndexOutOfBoundsException when querying a partitioned view in ColumnPruner. (IndexOutOfBoundsException wird ausgelöst, wenn eine partitionierte Ansicht in ColumnPruner abgefragt wird.)
HIVE-18429: Compaction should handle a case when it produces no output. (Die Komprimierung sollte einen Fall behandeln, wenn keine Ausgabe erzeugt wird.)
HIVE-18447: JDBC: Provide a way for JDBC users to pass cookie info via connection string. (JDBC: Eine Möglichkeit zum Übergeben von Cookie-Informationen über eine Verbindungszeichenfolge für JDBC-Benutzer.)
HIVE-18460: Compactor doesn't pass Table properties to the Orc writer. (Komprimierungsprogramm übergibt Tabelleneigenschaften nicht an den ORC-Writer.)
HIVE-18467: support whole warehouse dump / load + create/drop database events (Anishek Agarwal, reviewed by Sankar Hariappan). (Unterstützung gesamter Warehouse-Sicherung / Laden und Erstellen/Löschen von Datenbankereignissen.)
HIVE-18551: Vectorization: VectorMapOperator tries to write too many vector columns for Hybrid Grace. (Vektorisierung: VectorMapOperator versucht, zu viele Vektorspalten zu schreiben.)
HIVE-18587: insert DML event may attempt to calculate a checksum on directories. (DML-Insert-Ereignis kann versuchen, eine Prüfsumme für Verzeichnisse zu berechnen.)
HIVE-18613: Extend JsonSerDe to support BINARY type. (JsonSerDe erweitert, um BINARY-Typen zu unterstützen.)
HIVE-18626: Repl load "with" clause does not pass config to tasks. (WITH-Klausel von Repl Load übergibt die Konfiguration nicht an Tasks.)
HIVE-18660: PCR doesn't distinguish between partition and virtual columns. (PCR unterscheidet nicht zwischen Partitionen und virtuellen Spalten.)
HIVE-18754: REPL STATUS should support 'with' clause. (REPL STATUS sollte WITH-Klauseln unterstützen.)
HIVE-18754: REPL STATUS should support 'with' clause. (REPL STATUS sollte WITH-Klauseln unterstützen.)
HIVE-18788: Clean up inputs in JDBC PreparedStatement. (Bereinigen von Eingaben in PreparedStatement von JDBC.)
HIVE-18794: Repl load "with" clause does not pass config to tasks for non-partition tables. (WITH-Klausel von REPL LOAD übergibt die Konfiguration nicht an Tasks für Tabellen, die nicht Partitionstabellen sind.)
HIVE-18808: Make compaction more robust when stats update fails. (Stabilere Komprimierung, wenn Aktualisierung der Statistik fehlschlägt.)
HIVE-18817: ArrayIndexOutOfBounds-Ausnahme wird beim Lesen der ACID-Tabelle ausgelöst.
HIVE-18833: Auto Merge fails when "insert into directory as orcfile". (Automatische Zusammenführung schlägt fehl, wenn die Funktion als ORC-Datei eingefügt wird.)
HIVE-18879: Disallow embedded element in UDFXPathUtil needs to work if xercesImpl.jar in classpath. (Unterbindung des eingebetteten Elements in UDFXPathUtil muss funktionieren, wenn „xercesImpl.jar“ sich auf dem Klassenpfad befindet.)
HIVE-18907: Create utility to fix acid key index issue from HIVE-18817. (Erstellung eines Hilfsprogramms zur Behebung eines Problems mit acid key index von HIVE-18817.)
Apache-Patches zu Hive 2.1.0:
HIVE-14013: Describe table doesn't show unicode properly. (Beschreibungstabelle zeigt Unicode nicht ordnungsgemäß an.)
HIVE-14205: Hive doesn't support union type with AVRO file format. (Hive unterstützt den Union-Typ nicht mit dem Dateiformat AVRO.)
HIVE-15563: Ausnahme für unzulässigen Übergang des Vorgangsstatus in SQLOperation.runQuery ignorieren, um tatsächliche Ausnahme zur Verfügung zu stellen.
HIVE-15680: Incorrect results when hive.optimize.index.filter=true and same ORC table is referenced twice in query, in MR mode. (Fehlerhafte Ergebnisse bei hive.optimize.index.filter=true, außerdem wird im MR-Modus in der Abfrage doppelt auf die ORC-Tabelle verwiesen.)
HIVE-15883: HBase mapped table in Hive insert fail for decimal. (Eingabe von Dezimalspalten in der Tabelle, die HBase in Hive zugeordnet ist, schlägt fehl.)
HIVE-16757: Remove calls to deprecated AbstractRelNode.getRows. (Entfernen der veralteten Aufrufe von AbstractRelNode.getRows.)
HIVE-16828: With CBO enabled, Query on partitioned views throws IndexOutOfBoundException. (Wenn CBO aktiviert ist, lösen Abfragen von partitionierten Ansichten IndexOutOfBoundException aus.)
HIVE-17063: Insert overwrite partition onto a external table fail when drop partition first. (Einfügen von „overwrite partition“ in eine externe Tabelle schlägt fehl, wenn „drop partition“ zuerst eingefügt wird.)
HIVE-17259: Hive JDBC does not recognize UNIONTYPE columns. (Hive-JDBC erkennt UNIONTYPE-Spalten nicht.)
HIVE-17530: ClassCastException when converting
uniontype. (ClassCastException wird beim Konvertieren von (x) ausgelöst.)HIVE-17600: Make OrcFile's enforceBufferSize user-settable. (Benutzerdefinierbarkeit von enforceBufferSize der ORC-Datei.)
HIVE-17601: improve error handling in LlapServiceDriver. (Verbesserung der Fehlerbehandlung in LlapServiceDriver.)
HIVE-17613: remove object pools for short, same-thread allocations. (Entfernen von Objektpools für kurze Zuordnungen im selben Thread.)
HIVE-17617: Rollup of an empty resultset should contain the grouping of the empty grouping set. (Rollup eines leeren Resultsets sollte die Gruppierung der leeren Gruppierungsgruppe enthalten.)
HIVE-17621: Hive-site settings are ignored during HCatInputFormat split-calculation. (Einstellungen für Hive-site werden während HCatInputFormat::getSplits() ignoriert.)
HIVE-17629: CachedStore: Have a whitelist/blacklist config to allow selective caching of tables/partitions and allow read while prewarming. (Vorhalten einer genehmigten/nicht genehmigten Konfiguration, um die selektive Zwischenspeicherung von Tabellen/Partitionen und das Lesen beim Vorwärmen zuzulassen.)
HIVE-17636: Add multipleagg.q test for
blobstores. (Hinzufügen von „multiple_agg.q“ für (x).)HIVE-17702: incorrect isRepeating handling in decimal reader in ORC. (Fehlerhafte Verarbeitung von isRepeating im Dezimalreader in ORC.)
HIVE-17729: Add Database and Explain related blobstore tests. (Hinzufügen von Blobspeicher-Tests für die Datenbank und für einen EXPLAIN-Befehl.)
HIVE-17731: add a backward
compatoption for external users to HIVE-11985. (Hinzufügen einer Option für die (x) in HIVE-11985 für externe Benutzer.)HIVE-17803: With Pig multi-query, 2 HCatStorers writing to the same table will trample each other's outputs. (Wenn Pig-Skripts mehrere Abfragen verwenden, schreiben 2 HCatStorers in die gleiche Tabelle, wodurch die Ausgaben sich überschreiben.)
HIVE-17845: insert fails if target table columns are not lowercase. (Eingabe schlägt fehl, wenn die Spalten der Zieltabelle nicht klein geschrieben sind.)
HIVE-17900: analyze stats on columns triggered by Compactor generates malformed SQL with > 1 partition column. (Fehlerhaft formatierter SQL-Code wird mit mehr als einer Partitionsspalte generiert, wenn Statistiken zu Spalten vom Komprimierungsprogramm analysiert werden.)
HIVE-18006: Optimize memory footprint of HLLDenseRegister. (Optimierung des Speicherbedarfs von HLLDenseRegister.)
HIVE-18026: Hive webhcat principal configuration optimization. (Optimierung der Konfiguration des WebHCat-Prinzipals.)
HIVE-18031: Unterstützung der Replikation des Alter Database-Vorgangs
HIVE-18090: acid heartbeat fails when metastore is connected via hadoop credential. (Heartbeat von ACID schlägt fehl, wenn Metastore über Hadoop-Anmeldeinformationen verbunden ist.)
HIVE-18189: Order by position does not work when
cbois disabled. (Die Abfrage „Order by position“ funktioniert nicht, wenn (x) deaktiviert ist.)HIVE-18258: Vectorization: Reduce-Side GROUP BY MERGEPARTIAL with duplicate columns is broken. (Vektorisierung: GROUP BY MERGEPARTIAL ist mit doppelten Spalten fehlerhaft.)
HIVE-18269: LLAP: Fast
llapio with slow processing pipeline can lead to OOM. (LLAP: Schnelleres (x) IO mit langsamer Verarbeitungspipeline kann zu OOM führen.)HIVE-18293: Hive is failing to compact tables contained within a folder that is not owned by identity running HiveMetaStore. (Hive kann Tabellen nicht in einem Ordner komprimieren, der nicht der Identität gehört, die HiveMetaStore ausführt.)
HIVE-18318: LLAP record reader should check interrupt even when not blocking. (LLAP-Datensatzreader sollte Unterbrechungen überprüfen, selbst wenn nicht blockiert wird.)
HIVE-18326: LLAP Tez scheduler – only preempt tasks if there's a dependency between them. (LLAP Tez-Scheduler: Tasks sollten nur ausgeschlossen werden, wenn eine Abhängigkeit zwischen ihnen besteht.)
HIVE-18327: Remove the unnecessary HiveConf dependency for MiniHiveKdc. (Unnötige Abhängigkeit von HiveConf für MiniHiveKdc entfernt.)
HIVE-18331: Add relogin when TGT expire and some logging/lambda. (Hinzufügen einer erneuten Anmeldung nach Ablauf von TGT und Protokollierung/Lambda.)
HIVE-18341: Add repl load support for adding "raw" namespace for TDE with same encryption keys. (Dem Befehl „repl load“ wurde Unterstützung für den Namespace „raw“ für TDE mit denselben Verschlüsselungsschlüsseln hinzugefügt.)
HIVE-18352: introduce a METADATAONLY option while doing REPL DUMP to allow integrations of other tools. (Einführung einer METADATAONLY-Option während REPL DUMP, um die Integration anderer Tools zuzulassen.)
HIVE-18353: CompactorMR should call jobclient.close() to trigger cleanup. (CompactorMR sollte jobclient.close() aufrufen, um die Bereinigung auszulösen.)
HIVE-18384: ConcurrentModificationException in
log4j2.xlibrary. (ConcurrentModificationException in (x)-Bibliothek.)HIVE-18390: IndexOutOfBoundsException when querying a partitioned view in ColumnPruner. (IndexOutOfBoundsException wird ausgelöst, wenn eine partitionierte Ansicht in ColumnPruner abgefragt wird.)
HIVE-18447: JDBC: Provide a way for JDBC users to pass cookie info via connection string. (JDBC: Eine Möglichkeit zum Übergeben von Cookie-Informationen über eine Verbindungszeichenfolge für JDBC-Benutzer.)
HIVE-18460: Compactor doesn't pass Table properties to the Orc writer. (Komprimierungsprogramm übergibt Tabelleneigenschaften nicht an den ORC-Writer.)
HIVE-18462: (Explain formatted for queries with map join has columnExprMap with unformatted column name). (Formatierung von EXPLAIN mit map join enthält columnExprMap mit unformatierten Spaltennamen.)
HIVE-18467: support whole warehouse dump / load + create/drop database events. (Unterstützung gesamter Warehouse-Sicherung / Laden und Erstellen/Löschen von Datenbankereignissen.)
HIVE-18488: LLAP ORC readers are missing some null checks. (LLAP ORC-Reader fehlen in einigen NULL-Überprüfungen.)
HIVE-18490: Query with EXISTS and NOT EXISTS with non-equi predicate can produce wrong result. (Abfragen mit EXISTS und NOT EXISTS mit ungleichem Prädikat können ein falsches Ergebnis erzeugen.)
HIVE-18506: LlapBaseInputFormat – negative array index. (LlapBaseInputFormat: negativer Arrayindex.)
HIVE-18517: Vectorization: Fix VectorMapOperator to accept VRBs and check vectorized flag correctly to support LLAP Caching. (Vektorisierung: Behebung von VectorMapOperator, damit VRBs akzeptiert und vektorisierte Flags ordnungsgemäß überprüft werden, um LLAP-Zwischenspeicherung zu unterstützen.)
HIVE-18523: Fix summary row in case there are no inputs. (Fehlerbehebung für die Zusammenfassungszeile in Fällen, in denen keine Eingaben vorhanden sind.)
HIVE-18528: Aggregate stats in ObjectStore get wrong result. (Aggregation von Statistiken in ObjectStore führt zu einem fehlerhaften Ergebnis.)
HIVE-18530: Replication should skip MM table (for now). (Replikation sollte (momentan) die MM-Tabelle überspringen.)
HIVE-18548: Fix
log4jimport. ((x)-Import korrigieren.)HIVE-18551: Vectorization: VectorMapOperator tries to write too many vector columns for Hybrid Grace. (Vektorisierung: VectorMapOperator versucht, zu viele Vektorspalten zu schreiben.)
HIVE-18577: SemanticAnalyzer.validate has some pointless metastore calls. (SemanticAnalyzer.validate enthält einige sinnlose Aufrufe von Metastore.)
HIVE-18587: insert DML event may attempt to calculate a checksum on directories. (DML-Insert-Ereignis kann versuchen, eine Prüfsumme für Verzeichnisse zu berechnen.)
HIVE-18597: LLAP: Always package the
log4j2API jar fororg.apache.log4j. (Packen Sie immer das (x) API jar für (x).)HIVE-18613: Extend JsonSerDe to support BINARY type. (JsonSerDe erweitert, um BINARY-Typen zu unterstützen.)
HIVE-18626: Repl load "with" clause does not pass config to tasks. (WITH-Klausel von Repl Load übergibt die Konfiguration nicht an Tasks.)
HIVE-18643: don't check for archived partitions for ACID ops. (Entfernung von Überprüfungen von archivierten Partitionen für ACID-Vorgänge.)
HIVE-18660: PCR doesn't distinguish between partition and virtual columns. (PCR unterscheidet nicht zwischen Partitionen und virtuellen Spalten.)
HIVE-18754: REPL STATUS should support 'with' clause. (REPL STATUS sollte WITH-Klauseln unterstützen.)
HIVE-18788: Clean up inputs in JDBC PreparedStatement. (Bereinigen von Eingaben in PreparedStatement von JDBC.)
HIVE-18794: Repl load "with" clause does not pass config to tasks for non-partition tables. (WITH-Klausel von REPL LOAD übergibt die Konfiguration nicht an Tasks für Tabellen, die nicht Partitionstabellen sind.)
HIVE-18808: Make compaction more robust when stats update fails. (Stabilere Komprimierung, wenn Aktualisierung der Statistik fehlschlägt.)
HIVE-18815: Remove unused feature in HPL/SQL. (Entfernung eines ungenutzten Features in HPL/SQL.)
HIVE-18817: ArrayIndexOutOfBounds-Ausnahme wird beim Lesen der ACID-Tabelle ausgelöst.
HIVE-18833: Auto Merge fails when "insert into directory as orcfile". (Automatische Zusammenführung schlägt fehl, wenn die Funktion als ORC-Datei eingefügt wird.)
HIVE-18879: Disallow embedded element in UDFXPathUtil needs to work if xercesImpl.jar in classpath. (Unterbindung des eingebetteten Elements in UDFXPathUtil muss funktionieren, wenn „xercesImpl.jar“ sich auf dem Klassenpfad befindet.)
HIVE-18944: Grouping sets position is set incorrectly during DPP. (GroupingSetsPosition wird während DPP falsch festgelegt.)
Kafka
Dieses Release stellt Kafka 1.0.0 und die folgenden Apache-Patches bereit:
KAFKA-4827: Kafka connect: error with special characters in connector name. (KafkaConnect: Fehler bei Sonderzeichen in Connectornamen.)
KAFKA-6118: Transient failure in kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials. (Vorübergehender Fehler in kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials.)
KAFKA-6156: JmxReporter can't handle windows style directory paths. (JmxReporter kann Verzeichnispfade im Windows-Format nicht verarbeiten.)
KAFKA-6164: ClientQuotaManager threads prevent shutdown when encountering an error loading logs. (ClientQuotaManager-Threads verhindern Shutdown, wenn ein Fehler beim Laden von Protokollen auftritt.)
KAFKA-6167: Timestamp on streams directory contains a colon, which is an illegal character. (Zeitstempel für Streams-Verzeichnis enthält einen Doppelpunkt, was ein ungültiges Zeichen ist.)
KAFKA-6179: RecordQueue.clear() does not clear MinTimestampTracker's maintained list. (RecordQueue.clear() bereinigt nicht die von MinTimestampTracker beibehaltene Liste.)
KAFKA-6185: Selector memory leak with high likelihood of OOM if there is a down conversion. (Arbeitsspeicherverlust des Selektors mit hoher OOM-Wahrscheinlichkeit bei Konvertierung nach unten.)
KAFKA-6190: GlobalKTable never finishes restoring when consuming transactional messages. (GlobalKTable schließt die Wiederherstellung nie ab, wenn transaktionale Nachrichten verarbeitet werden.)
KAFKA-6210: IllegalArgumentException if 1.0.0 is used for inter.broker.protocol.version or log.message.format.version. (IllegalArgumentException wird ausgelöst, wenn 1.0.0 für inter.broker.protocol.version oder log.message.format.version verwendet wird.)
KAFKA-6214: Using standby replicas with an in memory state store causes Streams to crash. (Die Verwendung von standby-Replikaten mit einem Zustandsspeicher im Arbeitsspeicher führt zu Abstürzen von Streams.)
KAFKA-6215: KafkaStreamsTest fails in trunk. (KafkaStreamsTest schlägt im Trunk fehl.)
KAFKA-6238: Issues with protocol version when applying a rolling upgrade to 1.0.0. (Probleme mit der Protokollversion bei Anwendung eines parallelen Upgrades.)
KAFKA-6260: AbstractCoordinator not clearly handles NULL Exception. (AbstractCoordinator verarbeitet die NULL-Ausnahme nicht eindeutig.)
KAFKA-6261: Request logging throws exception if acks=0. (Protokollierung von Anforderungen löst eine Ausnahme aus, wenn acks=0.)
KAFKA-6274: Improve
KTableSource state store auto-generated names. (Verbesserung der automatisch generierten Namen für den Zustandsspeicher für (x)-Source.)
Mahout
Anstelle der Veröffentlichung eines spezifischen Apache-Releases von Mahout wurde in HDP-2.3.x und 2.4.x auf einen bestimmten Revisionspunkt des Apache Mahout-Trunks synchronisiert. Dieser Revisionspunkt befindet sich zwischen Release 0.9.0 und Release 0.10.0. Damit wird gegenüber dem Release 0.9.0 eine große Anzahl von Fehlerbehebungen und Funktionsverbesserungen implementiert, dennoch wird ein stabiles Release der Funktionalität von Mahout geboten, das nicht die vollständige Konvertierung zum neuen auf Spark basierenden Mahout von Release 0.10.0 umfasst.
Der für Mahout ausgewählte Revisionspunkt in HDP-2.3.x und -2.4.x stammt von dem Branch „mahout-0.10.x“ von Apache Mahout vom 19. Dezember 2014 (Revision 0f037cb03e77c096 in GitHub).
Die Bibliothek „commons-httpclient“ wurde in HDP-2.5.x und -2.6.x aus Mahout entfernt, da sie als veraltet angesehen wird und möglicherweise Sicherheitsprobleme enthält. Außerdem wurde der Hadoop-Client in Mahout auf Version 2.7.3 aktualisiert, die gleiche Version wird in HDP 2.5 verwendet. Infolgedessen:
Müssen zuvor kompilierte Mahout-Aufträge in der Umgebung von HDP-2.5 oder -2.6 neu kompiliert werden.
Besteht eine geringe Wahrscheinlichkeit, dass einige Mahout-Aufträge die Fehlermeldungen „ClassNotFoundException“ oder „could not load class“ (Klasse konnte nicht geladen werden) auslösen, die im Zusammenhang mit „org.apache.commons.httpclient“, „net.java.dev.jets3t“ oder entsprechenden Präfixen von Klassennamen stehen. Wenn diese Fehler auftreten, sollten Sie sich überlegen, ob Sie die erforderlichen JAR-Dateien manuell im Klassenpfad für den Auftrag installieren, wenn das Sicherheitsrisiko in der veralteten Bibliothek für Ihre Umgebung akzeptabel ist.
Es besteht eine noch geringere Möglichkeit, dass einige Mahout-Aufträge aufgrund von Problemen mit der binären Kompatibilität im hbase-client-Code von Mahout hadoop-common-Bibliotheken aufruft. Bedauerlicherweise besteht keine Möglichkeit, dieses Problem zu beheben, außer zur HDP-2.4.2 Version von Mahout zurückzukehren, was zu Sicherheitsproblemen führen kann. Das Problem ist, wie erwähnt, ungewöhnlich und tritt in einer Mahout-Auftragssammlung wahrscheinlich nicht auf.
Oozie
Dieses Release stellt Oozie 4.2.0 und die folgenden Apache-Patches bereit:
OOZIE-2571: Add spark.scala.binary.version Maven property so that Scala 2.11 can be used. (Die Maven-Eigenschaft spark.scala.binary.version wurde hinzugefügt, damit Scala 2.11 verwendet werden kann.)
OOZIE-2606: Set spark.yarn.jars to fix Spark 2.0 with Oozie. (spark.yarn.jars wurde festgelegt, um Fehler bei Spark 2.0 mit Oozie zu beheben.)
OOZIE-2658: --driver-class-path can overwrite the classpath in SparkMain. (--driver-class-path kann den Klassenpfad in SparkMain überschreiben.)
OOZIE-2787: Oozie distributes application jar twice making the spark job fail. (Oozie verteilt die JAR-Datei der Anwendung doppelt, weshalb der Spark-Auftrag fehlschlägt.)
OOZIE-2792:
Hive2action isn't parsing Spark application ID from log file properly when Hive is on Spark. ((x)-Aktion analysiert die Spark-Anwendungs-ID der Protokolldatei nicht ordnungsgemäß, wenn Hive in Spark verwendet wird.)OOZIE-2799: Setting log location for spark sql on hive. (Einstellung des Speicherorts für das Protokoll von Spark-SQL in Hive.)
OOZIE-2802: Spark action failure on Spark 2.1.0 due to duplicate
sharelibs. (Spark-Aktion schlägt unter Spark 2.1.0 aufgrund von doppelten (x) fehl.)OOZIE-2923: Improve Spark options parsing. (Verbesserung der Analyse von Spark-Optionen.)
OOZIE-3109: SCA: Cross-Site Scripting: Reflected. (Websiteübergreifende Skripts: Reflektiert.)
OOZIE-3139: Oozie validates workflow incorrectly. (Oozie überprüft den Workflow nicht ordnungsgemäß.)
OOZIE-3167: Upgrade tomcat version on Oozie 4.3 branch. (Upgrade der Tomcat-Version auf Oozie 4.3.)
Phoenix
Dieses Release stellt Phoenix 4.7.0 und die folgenden Apache-Patches bereit:
PHOENIX-1751: Perform aggregations, sorting, etc., in the preScannerNext instead of postScannerOpen. (Durchführung von Aggregationen, Sortierungen usw. in preScannerNext anstelle von postScannerOpen.)
PHOENIX-2714: Correct byte estimate in BaseResultIterators and expose as interface. (Richtige Schätzung der Bytes in BaseResultIterators und Verfügbarkeit als Schnittstelle.)
PHOENIX-2724: Query with large number of guideposts is slower compared to no stats. (Abfragen mit hoher Anzahl von guideposts ist langsamer im Vergleich zu Abfragen ohne Statistiken.)
PHOENIX-2855: Workaround Increment TimeRange not being serialized for HBase 1.2. (Problemumgehung für die fehlende Serialisierung von Increment.TimeRange für HBase 1.2.)
PHOENIX-3023: Slow performance when limit queries are executed in parallel by default. (Niedrige Leistung wenn limit-Abfragen standardmäßig parallel ausgeführt werden.)
PHOENIX-3040: Don't use guideposts for executing queries serially. (Guideposts nicht zum seriellen Ausführen von Abfragen verwenden.)
PHOENIX-3112: Partial row scan not handled correctly. (Teilausführung der Zeilenüberprüfung wird nicht ordnungsgemäß verarbeitet.)
PHOENIX-3240: ClassCastException from Pig loader. (ClassCastException vom Pig-Ladeprogramm.)
PHOENIX-3452: NULLS FIRST/NULL LAST should not impact whether GROUP BY is order preserving. (NULLS FIRST/NULL LAST sollte keine Auswirkungen darauf haben, ob GROUP BY die Reihenfolge beibehält.)
PHOENIX-3469: Incorrect sort order for DESC primary key for NULLS LAST/NULLS FIRST. (Fehlerhafte Sortierreihenfolge für den DESC-Primärschlüssel für NULLS LAST/NULLS FIRST.)
PHOENIX-3789: Execute cross region index maintenance calls in postBatchMutateIndispensably. (Ausführung regionsübergreifender Wartungsaufrufe in postBatchMutateIndispensably.)
PHOENIX-3865: IS NULL does not return correct results when first column family not filtered against. (IS NULL gibt falsche Ergebnisse zurück, wenn die erste Spaltenfamilie nicht gefiltert wird.)
PHOENIX-4290: Full table scan performed for DELETE with table having immutable indexes. (Vollständige Überprüfung der Tabelle für DELETE mit Tabellen, die unveränderliche Indizes enthalten.)
PHOENIX-4373: Local index variable length key can have trailing nulls while upserting. (Schlüssel für die lokale Indexvariablenlänge kann nachstehende NULL-Werte enthalten, während ein Update eingefügt wird.)
PHOENIX-4466: java.lang.RuntimeException: response code 500 - Executing a spark job to connect to phoenix query server and load data. (Antwortcode 500 für java.lang.RuntimeException: Ausführen eines Spark-Auftrags, um eine Verbindung mit dem Phoenix-Abfrageserver und Auslastungsdaten herzustellen.)
PHOENIX-4489: HBase Connection leak in Phoenix MR Jobs. (HBase-Verbindungslücke in Phoenix-MR-Aufträgen.)
PHOENIX-4525: Integer overflow in GroupBy execution. (Ganzzahlüberlauf in Ausführung von GroupBy.)
PHOENIX-4560: ORDER BY with GROUP BY doesn't work if there is WHERE on
pkcolumn. (ORDER BY funktioniert nicht mit GROUP BY, wenn WHERE in der (x)-Spalte enthalten ist.)PHOENIX-4586: UPSERT SELECT beachtet nicht die Vergleichsoperatoren für Unterabfragen.
PHOENIX-4588: Clone expression also if its children have Determinism.PER_INVOCATION. (Ausdruck auch klonen, wenn die untergeordneten Elemente Determinism.PER_INVOCATION enthalten.)
Pig
Dieses Release stellt Pig 0.16.0 und die folgenden Apache-Patches bereit:
PIG-5159: Fix Pig not saving grunt history. (Fehler, bei dem Pig den Grunt-Verlauf nicht gespeichert hat, wurde behoben.)
PIG-5175: Upgrade
jrubyauf 1.7.26.
Ranger
Dieses Release stellt Ranger 0.7.0 und die folgenden Apache-Patches bereit:
RANGER-1805: Code improvement to follow best practices in js. (Codeverbesserungen zur Implementierung von bewährten Methoden in js.)
RANGER-1960: Take snapshot's table name into consideration for deletion. (Tabellenname von Momentaufnahme für die Löschung in Betracht ziehen.)
RANGER-1982: Error Improvement for Analytics Metric of Ranger Admin and Ranger KMS. (Verbesserung der Verarbeitung von Fehlern für Analysemetriken von Ranger Admin und Ranger KMS.)
RANGER-1984: HBase audit log records may not show all tags associated with accessed column. (Überwachungsprotokoll von HBase zeigt möglicherweise nicht alle Tags an, die der Spalte zugeordnet sind, auf die zugegriffen wird.)
RANGER-1988: Fix insecure randomness. (Fehlerbehebung unsicherer Zufallselemente.)
RANGER-1990: Add One-way SSL MySQL support in Ranger Admin. (Unidirektionale Unterstützung von SSL und MySQL in Ranger Admin.)
RANGER-2006: Fix problems detected by static code analysis in ranger
usersyncforldapsync source. (Behebung von Fehlern, die mit der statischen Codeanalyse in Ranger (x) für (y) sync source erkannt wurden.)RANGER-2008: Die Auswertung von Richtlinien schlägt für mehrzeilige Richtlinienbedingungen fehl.
Schieberegler
Dieses Release stellt Slider 0.92.0 ohne weitere Apache-Patches bereit.
Spark
Dieses Release stellt Spark 2.3.0 und die folgenden Apache-Patches bereit:
SPARK-13587: Support virtualenv in pyspark. (Unterstützung von virtualenv in pyspark.)
SPARK-19964: Avoid reading from remote repos in SparkSubmitSuite. (Vermeiden des Lesevorgangs von Remote-Repositorys in SparkSubmitSuite.)
SPARK-22882: ML test for structured streaming: ml.classification. (ML-Test für strukturiertes Streaming: ml.classification.)
SPARK-22915: Streaming tests for spark.ml.feature, from N to Z. (Streamingtests für spark.ml.feature von N bis Z.)
SPARK-23020: Fix another race in the in-process launcher test. (Behebung eines weiteren Race im in-Process-Starttest.)
SPARK-23040: Returns interruptible iterator for shuffle reader. (Gibt nicht unterbrechbare Iteratoren für den Shuffle-Reader zurück.)
SPARK-23173: Avoid creating corrupt parquet files when loading data from JSON. (Vermeiden der Erstellung fehlerhafter Parquet-Dateien beim Laden von Daten aus JSON.)
SPARK-23264: Fix scala.MatchError in literals.sql.out. (Fehlerbehebung von scala.MatchError in literals.sql.out.)
SPARK-23288: Fix output metrics with parquet sink. (Fehlerbehebung für Ausgabemetriken mit Parquet-Senke.)
SPARK-23329: Fix documentation of trigonometric functions. (Fehlerbehebung bei der Dokumentation von trigonometrischen Funktionen.)
SPARK-23406: Enable stream-stream self-joins for branch-2.3. (Aktivieren von stream-stream Selbstjoins für branch-2.3.)
SPARK-23434: Spark should not warn `metadata directory` for a HDFS file path. (Spark sollte das ‚Metadatenverzeichnis‘ nicht für einen HDFS-Dateipfad warnen.)
SPARK-23436: Infer partition as Date only if it can be cast to Date. (Partition nur als Datum ableiten, wenn sie in Datum umgewandelt werden kann.)
SPARK-23457: Register task completion listeners first in ParquetFileFormat. (Listener für Abschluss von Tasks zuerst in ParquetFileFormat registrieren.)
SPARK-23462: improve missing field error message in ‚StructType‘. (Verbesserung der Fehlermeldung für fehlende Felder in ‚StructType‘.)
SPARK-23490: Check storage.locationUri with existing table in CreateTable. (Überprüfung von storage.locationUri mit vorhandener Tabelle in CreateTable.)
SPARK-23524: Big local shuffle blocks should not be checked for corruption. (Große lokale Shuffle-Blöcke sollten nicht auf Fehler überprüft werden.)
SPARK-23525: Support ALTER TABLE CHANGE COLUMN COMMENT for external hive table. (Unterstützung von ALTER TABLE CHANGE COLUMN COMMENT für externe Hive-Tabelle.)
SPARK-23553: Tests should not assume the default value of `spark.sql.sources.default`. (Tests sollten nicht von einem Standardwert für ‚spark.sql.sources.default‘ ausgehen.)
SPARK-23569: Allow pandas_udf to work with python3 style type-annotated functions. (Zulassen der Zusammenarbeit von pandas_udf mit python3-artigen Funktionen mit kommentierten Typen.)
SPARK-23570: Add Spark 2.3.0 in HiveExternalCatalogVersionsSuite. (Hinzufügen von Spark 2.3.0 in HiveExternalCatalogVersionsSuite.)
SPARK-23598: Make methods in BufferedRowIterator public to avoid runtime error for a large query. (Veröffentlichen von Methoden in BufferedRowIterator, um Runtime-Fehler für eine große Abfrage zu vermeiden.)
SPARK-23599: Add a UUID generator from Pseudo-Random Numbers. (Hinzufügen eines UUID-Generators aus Pseudo-Zufallszahlen.)
SPARK-23599: Use RandomUUIDGenerator in Uuid expression. (Verwendung von RandomUUIDGenerator in Uuid-Ausdrücken.)
SPARK-23601: Remove
.md5files from release. (Entfernung von (x)-Dateien aus dem Release.)SPARK-23608: Add synchronization in SHS between attachSparkUI and detachSparkUI functions to avoid concurrent modification issue to Jetty Handlers. (Synchronisierung der Funktionen attachSparkUI imd detachSparkUI in SHS, um gleichzeitige Änderungen an Jetty-Handlern zu vermeiden.)
SPARK-23614: Fix incorrect reuse exchange when caching is used. (Fehlerbehebung bei der Verwendung der Zwischenspeicherung.)
SPARK-23623: Avoid concurrent use of cached consumers in CachedKafkaConsumer (branch-2.3). (Vermeiden der gleichzeitigen Verwendung zwischengespeicherter Consumer in CachedKafkaConsumer (branch-2.3).)
SPARK-23624: Revise doc of method pushFilters in Datasource V2. (Überarbeitung der Methode „pushFilters“ in Datasource V2.)
SPARK-23628: calculateParamLength should not return 1 + num of expressions. (calculateParamLength sollte nicht 1 + die Anzahl von Ausdrücken zurückgeben.)
SPARK-23630: Allow user's hadoop conf customizations to take effect. (Zulassen von Anpassungen an hadoop conf durch den Benutzer.)
SPARK-23635: Spark executor env variable is overwritten by same name AM env variable. (Umgebungsvariable des Spark-Executor wird vom selben Namen der AM-Umgebungsvariable überschrieben.)
SPARK-23637: Yarn might allocate more resource if a same executor is killed multiple times. (Yarn ordnet möglicherweise mehr Ressourcen zu, wenn ein gleicher Executor mehrmals beendet wird.)
SPARK-23639: Obtain token before init metastore client in SparkSQL CLI. (Abrufen des Tokens bevor Metastore-Client in der SparkSQL-CLI initialisiert wird.)
SPARK-23642: AccumulatorV2 subclass isZero
scaladocfix. (Fehlerbehebung der Unterklasse isZero (x) von AccumulatorV2.)SPARK-23644: Use absolute path for REST call in SHS. (Verwendung eines absoluten Pfads für REST-Aufruf in SHS.)
SPARK-23645: Add docs RE ‚pandas_udf‘ with keyword args. (Hinzufügung von RE ‚pandas_udf‘ mit Schlüsselwortargumenten.)
SPARK-23649: Skipping chars disallowed in UTF-8. (Überspringen von Zeichen, die in UTF-8 nicht zulässig sind.)
SPARK-23658: InProcessAppHandle uses the wrong class in getLogger. (InProcessAppHandle verwendet die falsche Klasse in getLogger.)
SPARK-23660: Fix exception in yarn cluster mode when application ended fast. (Fehlerbehebung der Ausnahme im Clustermodus von Yarn, wenn eine Anwendung schnell beendet.)
SPARK-23670: Fix memory leak on SparkPlanGraphWrapper. (Fehlerbehebung bei Arbeitsspeicherverlust auf SParkPlanGraphWrapper.)
SPARK-23671: Fix condition to enable the SHS thread pool. (Behebung der Bedingung zum Aktivieren des SHS-Threadpools.)
SPARK-23691: Use sql_conf util in PySpark tests where possible. (Verwendung von sql_conf-Hilfsprogramm in PySpark-Tests, wenn möglich.)
SPARK-23695: Fix the error message for Kinesis streaming tests. (Behebung der Fehlermeldung für Kinesis-Streamingtests.)
SPARK-23706: spark.conf.get(value, default=None) should produce None in PySpark. (spark.conf.get(value, default=None) sollte die Ausgabe „None“ in PySpark erzeugen.)
SPARK-23728: Fix ML tests with expected exceptions running streaming tests. (Fehlerbehebung bei ML-Tests mit erwarteten Ausnahmen bei der Ausführung von Streamingtests.)
SPARK-23729: Respect URI fragment when resolving globs. (Beachtung von URI-Fragmenten beim Auflösen von globs.)
SPARK-23759: Unable to bind Spark UI to specific host name / IP. (Spark-Benutzeroberfläche kann nicht an einen bestimmten Hostnamen oder eine IP gebunden werden.)
SPARK-23760: CodegenContext.withSubExprEliminationExprs should save/restore CSE state correctly. (CodegenContext.withSubExprEliminationExprs sollte den CSE-Zustand ordnungsgemäß speichern/wiederherstellen.)
SPARK-23769: Remove comments that unnecessarily disable
Scalastylecheck. (Entfernung von Kommentaren, die (x) unnötigerweise deaktivieren.)SPARK-23788: Fix race in StreamingQuerySuite. (Behebung von Race in StreamingQuerySuite.)
SPARK-23802: PropagateEmptyRelation can leave query plan in unresolved state. (PropagateEmptyRelation kann Abfrageplan in unvollendetem Zustand hinterlassen.)
SPARK-23806: Broadcast.unpersist can cause fatal exception when used with dynamic allocation. (Broadcast.unpersist kann schwerwiegende Ausnahmefehler verursachen, wenn im Zusammenhang die dynamische Zuteilung verwendet wird.)
SPARK-23808: Set default Spark session in test-only spark sessions. (Festlegung der Spark-Standardsitzung in Spark-Sitzungen, die ausschließlich für Tests vorgesehen sind.)
SPARK-23809: Active SparkSession should be set by getOrCreate. (Aktive Spark-Sitzung sollte über getOrCreate festgelegt werden.)
SPARK-23816: Killed tasks should ignore FetchFailures. (Beendete Tasks sollten FetchFailures ignorieren.)
SPARK-23822: Improve error message for Parquet schema mismatches. (Verbesserung der Fehlermeldung für Konflikte mit dem Parquet-Schema.)
SPARK-23823: Keep origin in transformExpression. (Beibehalten des Ursprungs in transformExpression.)
SPARK-23827: StreamingJoinExec should ensure that input data is partitioned into specific number of partitions. (StreamingJoinExec sollte sicherstellen, dass Eingabedaten in eine spezifische Anzahl von Partitionen partitioniert werden.)
SPARK-23838: Running SQL query is displayed as "completed" in SQL tab. (Ausführung von SQL-Abfragen wird auf der SQL-Registerkarte als „Abgeschlossen“ angezeigt.)
SPARK-23881: Fix flaky test JobCancellationSuite."interruptible iterator of shuffle reader". (Fehlerbehebung für den unzuverlässigen Test JobCancellationSuite."interruptible iterator of shuffle reader".)
Sqoop
Dieses Release stellt Sqoop 1.4.6 ohne weitere Apache-Patches bereit.
Storm
Dieses Release stellt Storm 1.1.1 und die folgenden Apache-Patches bereit:
STORM-2652: Exception thrown in JmsSpout open method. (Ausnahme wird in der Methode „JmsSpout.open“ ausgelöst.)
STORM-2841: testNoAcksIfFlushFails UT fails with NullPointerException. (testNoAcksIfFlushFails UT schlägt mit NullPointerException fehl.)
STORM-2854: Expose IEventLogger to make event log pluggable. (IEventLogger wird zur Verfügung gestellt, damit die Ereignisprotokollierung austauschbar ist.)
STORM-2870: FileBasedEventLogger leaks non-daemon ExecutorService, which prevents process to be finished. (FileBasedEventLogger stellt nicht Daemon ExecutorService ungewollt frei, wodurch der Vorgang nicht abgeschlossen werden kann.)
STORM-2960: Better to stress importance of setting up proper OS account for Storm processes. (In der Dokumentation wurde mehr Betonung auf die Wichtigkeit des Einrichtens eines richtigen Betriebssystemkontos für Storm-Prozesse verwendet.)
Tez
Dieses Release stellt Tez 0.7.0 und die folgenden Apache-Patches bereit:
- TEZ-1526: LoadingCache for TezTaskID slow for large jobs. (LoadingCache ist bei großen Aufträgen für TezTaskID langsam.)
Zeppelin
Dieses Release stellt Zeppelin 0.7.3 ohne weitere Apache-Patches bereit.
ZEPPELIN-3072: Zeppelin UI becomes slow/unresponsive if there are too many notebooks. (Die Benutzeroberfläche von Zeppelin wird langsam oder reagiert nicht, wenn zu viele Notebooks vorhanden sind.)
ZEPPELIN-3129: Zeppelin UI doesn't sign out in IE. (Die Zeppelin-Benutzeroberfläche wird in Internet Explorer nicht abgemeldet.)
ZEPPELIN-903: Replace CXF with
Jersey2. (CXF durch (x) ersetzt.)
ZooKeeper
Dieses Release stellt ZooKeeper 3.4.6 und die folgenden Apache-Patches bereit:
ZOOKEEPER-1256: ClientPortBindTest is failing on Mac OS X. (Bei ClientPortBindTest unter Mac OS X tritt ein Fehler auf.)
ZOOKEEPER-1901: [JDK8] Sort children for comparison in AsyncOps tests. ([JDK8] Sortieren von untergeordneten Elementen für den Vergleich in AsyncOps-Tests.)
ZOOKEEPER-2423: Upgrade Netty version due to security vulnerability (CVE-2014-3488). (Upgrade der Netty-Version aufgrund von Sicherheitsrisiko (CVE-2014-3488).)
ZOOKEEPER-2693: DOS attack on wchp/wchc four letter words (4lw). (DOS-Angriffe auf Wörter mit vier Buchstaben wchp/wchc.)
ZOOKEEPER-2726: Patch introduces potential race condition. (Patch hat eine potenzielle Racebedingung implementiert.)
Behobene Common Vulnerabilities and Exposures
Dieser Abschnitt umfasst alle Common Vulnerabilities and Exposures (Allgemeine Sicherheitslücken und Schwachstellen, CVE), die in diesem Release behoben wurden.
CVE-2017-7676
| Zusammenfassung: Apache Ranger-Richtlinienauswertung ignoriert Zeichen nach dem ‘*’-Platzhalterzeichen |
|---|
| Schweregrad: Kritisch |
| Anbieter: Hortonworks |
| Betroffene Versionen: HDInsight 3.6-Versionen, einschließlich der Apache Ranger-Versionen 0.5.x/0.6.x/0.7.0 |
| Betroffene Benutzer: Umgebungen, die Ranger-Richtlinien mit Zeichen nach dem Platzhalterzeichen ‘*’ verwenden, etwa „my*test“, „test*.txt“ |
| Auswirkung: Der Matcher für Richtlinienressourcen ignoriert Zeichen nach dem Platzhalterzeichen ‘*’, was zu unerwartetem Verhalten führen kann. |
| Details zur Fehlerbehebung: Der Richtlinienressourcen-Matcher von Ranger wurde aktualisiert, um Platzhalterübereinstimmungen ordnungsgemäß zu verarbeiten. |
| Empfohlene Maßnahme: Upgrade auf HDI 3.6 (mit Apache Ranger 0.7.1 oder höher). |
CVE-2017-7677
| Zusammenfassung: Der Apache Ranger Hive-Autorisierer sollte auf RWX-Berechtigung prüfen, wenn ein externer Speicherort angegeben ist. |
|---|
| Schweregrad: Kritisch |
| Anbieter: Hortonworks |
| Betroffene Versionen: HDInsight 3.6-Versionen, einschließlich der Apache Ranger-Versionen 0.5.x/0.6.x/0.7.0 |
| Betroffene Benutzer: Umgebungen, die einen externen Speicherort für Hive-Tabellen verwenden |
| Auswirkung: In Umgebungen, die einen externen Speicherort für Hive-Tabellen verwenden, sollte der Apache Ranger Hive-Autorisierer auf RWX-Berechtigungen für den externen Speicherort prüfen, der zum Erstellen der Tabelle angegeben wurde. |
| Details zur Fehlerbehebung: Der Ranger Hive-Autorisierer wurde aktualisiert, um die Überprüfung von Berechtigungen für den externen Speicherort ordnungsgemäß zu verarbeiten. |
| Empfohlene Maßnahme: Upgrade auf HDI 3.6 (mit Apache Ranger 0.7.1 oder höher). |
CVE-2017-9799
| Zusammenfassung: Mögliche Ausführung von Code als falscher Benutzer in Apache Storm |
|---|
| Schweregrad: Wichtig |
| Anbieter: Hortonworks |
| Betroffene Versionen: HDP 2.4.0, HDP-2.5.0, HDP-2.6.0 |
| Betroffene Benutzer: Benutzer, die Storm im sicheren Modus und Blobspeicher zum Verteilen von topologiebasierten Artefakten oder zum Verteilen von Topologieressourcen verwenden. |
| Auswirkung: In einigen Situationen und Konfigurationen von Storm ist es für den Besitzer einer Topologie theoretisch möglich, den Supervisor dazu zu bringen, einen Worker als einen anderen Benutzer zu starten, der nicht zum Stamm gehört. Im schlimmsten Fall führt dies zur Gefährdung der Anmeldeinformationen des anderen Benutzers. Dieses Sicherheitsrisiko gilt nur für Apache Storm-Installationen mit aktivierter Sicherheit. |
| Lösung: Upgrade auf HDP 2.6.2.1, da derzeit keine Problemumgehungen vorhanden sind. |
CVE-2016-4970
| Zusammenfassung: handler/ssl/OpenSslEngine.java in Netty 4.0.x vor 4.0.37. Final und 4.1.x vor 4.1.1. Final erlaubt entfernten Angreifern, einen Denial-of-Service (Endlosschleife) zu verursachen |
|---|
| Schweregrad: Moderat |
| Anbieter: Hortonworks |
| Betroffene Versionen: HDP 2. x. x seit 2.3. x |
| Betroffene Benutzer: Alle Benutzer, die HDFS verwenden. |
| Auswirkung: Die Auswirkungen sind gering, da Hortonworks OpenSslEngine.java nicht direkt in der Hadoop-Codebasis verwendet. |
| Empfohlene Maßnahme: Upgrade auf HDP 2.6.3. |
CVE-2016-8746
| Zusammenfassung: Fehler beim Pfadabgleich von Apache Ranger in der Richtlinienauswertung |
|---|
| Schweregrad: Normal |
| Anbieter: Hortonworks |
| Betroffene Versionen: Alle Versionen von HDP 2.5, einschließlich der Apache Ranger-Versionen 0.6.0/0.6.1/0.6.2 |
| Betroffene Benutzer: Alle Benutzer des Administratortools für Ranger-Richtlinien. |
| Auswirkung: Ranger-Richtlinien-Engine führt fehlerhaften Abgleich von Pfaden mit bestimmten Bedingungen durch, wenn eine Richtlinie Platzhalter und rekursive Flags enthält. |
| Details zur Fehlerbehebung: Richtlinienauswertungslogik wurde behoben |
| Empfohlene Maßnahme: Upgrade auf HDP 2.5.4 oder höher (mit Apache Ranger 0.6.3 oder höher) oder HDP 2.6 oder höher (mit Apache Ranger 0.7.0 oder höher) |
CVE-2016-8751
| Zusammenfassung: Apache Ranger hat ein Problem in Bezug auf webseitenübergreifendes Skripting gespeichert. |
|---|
| Schweregrad: Normal |
| Anbieter: Hortonworks |
| Betroffene Versionen: Alle Versionen von HDP 2.3/2.4/2.5, einschließlich der Apache Ranger-Versionen 0.5.x/0.6.0/0.6.1/0.6.2 |
| Betroffene Benutzer: Alle Benutzer des Administratortools für Ranger-Richtlinien. |
| Auswirkung: Apache Ranger ist anfällig für webseitenübergreifendes Skripting, wenn benutzerdefinierte Richtlinienbedingungen eingegeben werden. Administratorbenutzer können beliebigen JavaScript-Code speichern, der ausgeführt wird, wenn normale Benutzer sich anmelden und auf Richtlinien zugreifen. |
| Details zur Fehlerbehebung: Logik zum Säubern der Benutzereingabe wurde hinzugefügt. |
| Empfohlene Maßnahme: Upgrade auf HDP 2.5.4 oder höher (mit Apache Ranger 0.6.3 oder höher) oder HDP 2.6 oder höher (mit Apache Ranger 0.7.0 oder höher) |
Für den Support behobene Probleme
Behobene Probleme stellen ausgewählte Probleme dar, die zuvor über den Support von Hortonworks protokolliert wurden, aber im aktuellen Release behoben werden. Diese Probleme wurden möglicherweise in vorherigen Versionen im Abschnitt „Bekannte Probleme“ gemeldet. Das bedeutet, dass sie zuvor von Kunden gemeldet oder durch das Quality Engineering-Team von Hortonworks identifiziert wurden.
Falsche Ergebnisse
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-100019 | YARN-8145 | yarn rmadmin -getGroups gibt aktualisierte Gruppen für den Benutzer zurück |
| BUG-100058 | PHOENIX-2645 | Platzhalterzeichen stimmen nicht mit Zeilenumbruchzeichen überein |
| BUG-100266 | PHOENIX-3521, PHOENIX-4190 | Falsche Ergebnisse mit lokalen Indizes |
| BUG-88774 | HIVE-17617, HIVE-18413, HIVE-18523 | Abfrage 36 schlägt fehl, Konflikt bei Zeilenanzahl |
| BUG-89765 | HIVE-17702 | Fehlerhafte Verarbeitung von isRepeating im Dezimalreader in ORC |
| BUG-92293 | HADOOP-15042 | Azure PageBlobInputStream.skip() kann einen negativen Wert zurückgeben, wenn numberOfPagesRemaining 0 (null) ist. |
| BUG-92345 | ATLAS-2285 | Benutzeroberfläche: Gespeicherte Suche mit Date-Attribut wurde umbenannt. |
| BUG-92563 | HIVE-17495, HIVE-18528 | Aggregation von Statistiken in ObjectStore führt zu einem fehlerhaften Ergebnis |
| BUG-92957 | HIVE-11266 | count(*) führt basierend auf den Tabellenstatistiken für externe Tabellen zu einem falschen Ergebnis |
| BUG-93097 | RANGER-1944 | Aktionsfilter für Administratorüberwachung funktioniert nicht |
| BUG-93335 | HIVE-12315 | vectorization_short_regress.q weist ein Problem mit einem falschen Ergebnis für eine doppelte Berechnung auf |
| BUG-93415 | HIVE-18258, HIVE-18310 | Vectorization: Reduce-Side GROUP BY MERGEPARTIAL with duplicate columns is broken. (Vektorisierung: GROUP BY MERGEPARTIAL ist mit doppelten Spalten fehlerhaft.) |
| BUG-93939 | ATLAS-2294 | Zusätzlicher „Description“-Parameter wurde für die Erstellung eines Typs hinzugefügt |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Phoenix-Abfragen geben aufgrund von Teilen von HBase-Zeilen NULL-Werte zurück. |
| BUG-94266 | HIVE-12505 | Einfügen von Überschreibung in gleichen verschlüsselten Zonen schlägt ohne Meldung beim Entfernen vorhandener Dateien fehl. |
| BUG-94414 | HIVE-15680 | Fehlerhafte Ergebnisse bei hive.optimize.index.filter=true, außerdem wird in der Abfrage doppelt auf die ORC-Tabelle verwiesen. |
| BUG-95048 | HIVE-18490 | Abfragen mit EXISTS und NOT EXISTS mit ungleichem Prädikat können ein falsches Ergebnis erzeugen. |
| BUG-95053 | PHOENIX-3865 | IS NULL gibt falsche Ergebnisse zurück, wenn die erste Spaltenfamilie nicht gefiltert wird. |
| BUG-95476 | RANGER-1966 | Bei der Initialisierung der Richtlinien-Engine werden in manchen Fällen keine Kontextanreicherungen erstellt. |
| BUG-95566 | SPARK-23281 | Abfrage erzeugt Ergebnisse in falscher Reihenfolge, wenn eine zusammengesetzte ORDERBY-Klausel auf beide ursprünglichen Spalten und Aliase verweist. |
| BUG-95907 | PHOENIX-3451, PHOENIX-3452, PHOENIX-3469, PHOENIX-4560 | Behebung von Fehlern bei ORDER BY ASC, wenn eine Abfrage Aggregation enthält. |
| BUG-96389 | PHOENIX-4586 | UPSERT SELECT beachtet nicht die Vergleichsoperatoren für Unterabfragen. |
| BUG-96602 | HIVE-18660 | PCR unterscheidet nicht zwischen Partitionen und virtuellen Spalten. |
| BUG-97686 | ATLAS-2468 | [Standardsuche] Problem mit OR-Fällen, wenn NEQ mit numerischen Typen verwendet wird. |
| BUG-97708 | HIVE-18817 | ArrayIndexOutOfBounds-Ausnahme wird beim Lesen der ACID-Tabelle ausgelöst. |
| BUG-97864 | HIVE-18833 | Automatische Zusammenführung schlägt fehl, wenn die Funktion als ORC-Datei eingefügt wird. |
| BUG-97889 | RANGER-2008 | Die Auswertung von Richtlinien schlägt für mehrzeilige Richtlinienbedingungen fehl. |
| BUG-98655 | RANGER-2066 | Zugriff auf HBase-Spaltenfamilie wird von einer markierten Spalte in der Spaltenfamilie autorisiert |
| BUG-99883 | HIVE-19073, HIVE-19145 | StatsOptimizer kann konstante Spalten beschädigen |
Andere
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-100267 | HBASE-17170 | HBase wiederholt auch DoNotRetryIOException aufgrund von Unterschieden beim Klassenladeprogramm. |
| BUG-92367 | YARN-7558 | Befehl „yarn logs“ kann Protokolle für ausgeführte Container nicht abrufen, wenn Benutzeroberflächenauthentifizierung aktiviert ist. |
| BUG-93159 | OOZIE-3139 | Oozie überprüft den Workflow nicht ordnungsgemäß. |
| BUG-93936 | ATLAS-2289 | Eingebetteter Start-/Stop-Code auf Kafka-/ZooKeeper-Servern der aus der Implementierung von KafkaNotification verschoben werden soll. |
| BUG-93942 | ATLAS-2312 | Verwendung von ThreadLocal-Instanzen für DateFormat-Objekte, um gleichzeitige Verwendung durch mehrere Threads zu vermeiden. |
| BUG-93946 | ATLAS-2319 | Benutzeroberfläche: Das Löschen eines Tags mit einer Position von 25 oder höher in der Liste von Tags in der flachen Struktur und der Baumstruktur erfordert eine Aktualisierung, um das Tag aus der Liste zu entfernen. |
| BUG-94618 | YARN-5037, YARN-7274 | Möglichkeit zum Deaktivieren der Elastizität auf der Ebene der Blattwarteschlange |
| BUG-94901 | HBASE-19285 | Hinzufügen von Latenzhistogrammen pro Tabelle. |
| BUG-95259 | HADOOP-15185, HADOOP-15186 | Update für adls-Connector, damit die aktuelle Version des ADLS SDK verwendet wird. |
| BUG-95619 | HIVE-18551 | Vectorization: VectorMapOperator tries to write too many vector columns for Hybrid Grace. (Vektorisierung: VectorMapOperator versucht, zu viele Vektorspalten zu schreiben.) |
| BUG-97223 | SPARK-23434 | Spark should not warn `metadata directory` for a HDFS file path. (Spark sollte das ‚Metadatenverzeichnis‘ nicht für einen HDFS-Dateipfad warnen.) |
Leistung
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-83282 | HBASE-13376, HBASE-14473, HBASE-15210, HBASE-15515, HBASE-16570, HBASE-16810, HBASE-18164 | Schnelle Berechnung der Lokalität im Lastenausgleichsmodul |
| BUG-91300 | HBASE-17387 | Mehraufwand des Ausnahmeberichts in RegionActionResult für multi() reduziert. |
| BUG-91804 | TEZ-1526 | LoadingCache ist bei großen Aufträgen für TezTaskID langsam. |
| BUG-92760 | ACCUMULO-4578 | Abbrechen der Komprimierung des FATE-Vorgangs gibt Namespace-Sperre nicht frei. |
| BUG-93577 | RANGER-1938 | Solr verwendet für die Einrichtung der Überprüfung DocValues nicht effektiv. |
| BUG-93910 | HIVE-18293 | Hive kann Tabellen nicht in einem Ordner komprimieren, der nicht der Identität gehört, die HiveMetaStore ausführt. |
| BUG-94345 | HIVE-18429 | Die Komprimierung sollte einen Fall behandeln, wenn keine Ausgabe erzeugt wird. |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Reihenfolge für RetryAction bei der Verarbeitung von RequestHedgingProxyProvider: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR sollte jobclient.close() aufrufen, um die Bereinigung auszulösen. |
| BUG-94869 | PHOENIX-4290, PHOENIX-4373 | Angeforderte Zeile befindet sich außerhalb der Reichweite für Aufrufe von Get auf HRegion für lokal indizierte mit Salt verschlüsselte Phoenix-Tabellen. |
| BUG-94928 | HDFS-11078 | Behebung von NPE in LazyPersistFileScrubber |
| BUG-94964 | HIVE-18269, HIVE-18318, HIVE-18326 | Mehrere Fehlerbehebungen für LLAP |
| BUG-95669 | HIVE-18577, HIVE-18643 | Beim Ausführen von Update/Delete-Abfragen auf mit ACID partitionierten Tabellen kann HS2 für jede Partition lesen. |
| BUG-96390 | HDFS-10453 | ReplicationMonitor-Thread kann aufgrund einer Racebedingung zwischen Wiederherstellung und Löschung derselben Datei in einem großen Cluster für einen langen Zeitraum unterbrochen werden. |
| BUG-96625 | HIVE-16110 | Wiederherstellung von „Vektorisierung: Unterstützungswert 2 CASE WHEN anstelle von Fallback auf VectorUDFAdaptor“ |
| BUG-97109 | HIVE-16757 | Die Verwendung der veralteten Funktion getRows() anstelle der neue Funktion estimateRowCount(RelMetadataQuery...) hat erhebliche Auswirkungen auf die Leistung. |
| BUG-97110 | PHOENIX-3789 | Ausführung regionsübergreifender Wartungsaufrufe in postBatchMutateIndispensably. |
| BUG-98833 | YARN-6797 | TimelineWriter verarbeitet die POST-Antwort nicht vollständig. |
| BUG-98931 | ATLAS-2491 | Update von Hive-Hook, um Atlas V2-Benachrichtigungen zu verwenden. |
Potenzieller Datenverlust
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-95613 | HBASE-18808 | Ineffektiver Check-In der Konfiguration in BackupLogCleaner#getDeletableFiles() |
| BUG-97051 | HIVE-17403 | Fehler bei der Verkettung für nicht verwaltete und transaktionale Tabellen. |
| BUG-97787 | HIVE-18460 | Komprimierungsprogramm übergibt Tabelleneigenschaften nicht an den ORC-Writer. |
| BUG-97788 | HIVE-18613 | JsonSerDe erweitert, um BINARY-Typen zu unterstützen. |
Abfragefehler
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-100180 | CALCITE-2232 | Assertionsfehler für AggregatePullUpConstantsRule bei aggregierten Indizes |
| BUG-100422 | HIVE-19085 | FastHiveDecimal abs(0) legt Signierung von +ve fest |
| BUG-100834 | PHOENIX-4658 | IllegalStateException: requestSeek kann nicht für ReversedKeyValueHeap aufgerufen werden. |
| BUG-102078 | HIVE-17978 | TPCDS-Abfragen 58 und 83 erzeugen Ausnahme in der Vektorisierung. |
| BUG-92483 | HIVE-17900 | Fehlerhaft formatierter SQL-Code wird mit mehr als einer Partitionsspalte generiert, wenn Statistiken zu Spalten vom Komprimierungsprogramm analysiert werden. |
| BUG-93135 | HIVE-15874, HIVE-18189 | Hive-Abfrage gibt die falschen Ergebnisse zurück, wenn hive.groupby.orderby.position.alias auf TRUE festgelegt ist. |
| BUG-93136 | HIVE-18189 | Order by position does not work when cbo is disabled. (Die Abfrage „Order by position“ funktioniert nicht, wenn (x) deaktiviert ist.) |
| BUG-93595 | HIVE-12378, HIVE-15883 | Eingabe von Dezimal- und Binärspalten in der Tabelle, die HBase in Hive zugeordnet ist, schlägt fehl. |
| BUG-94007 | PHOENIX-1751, PHOENIX-3112 | Phoenix-Abfragen geben aufgrund von Teilen von HBase-Zeilen NULL-Werte zurück. |
| BUG-94144 | HIVE-17063 | Einfügen von „overwrite partition“ in eine externe Tabelle schlägt fehl, wenn „drop partition“ zuerst eingefügt wird |
| BUG-94280 | HIVE-12785 | Ansicht mit Union-Typ und UDF zum ‚Umwandeln‘ der Struktur ist fehlerhaft. |
| BUG-94505 | PHOENIX-4525 | Ganzzahlüberlauf in Ausführung von GroupBy. |
| BUG-95618 | HIVE-18506 | LlapBaseInputFormat: negativer Arrayindex. |
| BUG-95644 | HIVE-9152 | CombineHiveInputFormat: Hive-Abfrage schlägt mit der Ausnahme java.lang.IllegalArgumentException in Tez fehl. |
| BUG-96762 | PHOENIX-4588 | Clone expression also if its children have Determinism.PER_INVOCATION. (Ausdruck auch klonen, wenn die untergeordneten Elemente Determinism.PER_INVOCATION enthalten.) |
| BUG-97145 | HIVE-12245, HIVE-17829 | Unterstützung für Spaltenkommentare für eine HBase-Tabelle. |
| BUG-97741 | HIVE-18944 | Grouping sets position is set incorrectly during DPP. (GroupingSetsPosition wird während DPP falsch festgelegt) |
| BUG-98082 | HIVE-18597 | LLAP: Always package the log4j2 API jar for org.apache.log4j. (Packen Sie immer das (x) API jar für (x).) |
| BUG-99849 | – | Beim Erstellen einer neuen Tabelle aus einer Datei versucht der Assistent, die Standarddatenbank zu verwenden. |
Security
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-100436 | RANGER-2060 | Knox-Proxy mit knox-sso funktioniert für Ranger nicht |
| BUG-101038 | SPARK-24062 | Fehlermeldung „Connection refused“ (Verbindung abgelehnt) bei %Spark-Interpreter von Zeppelin. Fehlermeldung „A secret key must be specified...“ („Ein geheimer Schlüssel muss angegeben werden...“) in HiveThriftServer. |
| BUG-101359 | ACCUMULO-4056 | Update von commons-collection auf Version 3.2.2 bei Veröffentlichung |
| BUG-54240 | HIVE-18879 | Unterbindung des eingebetteten Elements in UDFXPathUtil muss funktionieren, wenn „xercesImpl.jar“ sich auf dem Klassenpfad befindet. |
| BUG-79059 | OOZIE-3109 | HTML-spezifische Zeichen des Protokollstreamings mit Escapezeichen versehen. |
| BUG-90041 | OOZIE-2723 | Lizenz von JSON.org ist nun CatX |
| BUG-93754 | RANGER-1943 | Die Ranger Solr-Autorisierung wird übersprungen, wenn die Auflistung leer oder NULL ist. |
| BUG-93804 | HIVE-17419 | Der Befehl „ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS“ zeigt berechnete Statistiken für maskierte Tabellen. |
| BUG-94276 | ZEPPELIN-3129 | Die Benutzeroberfläche von Zeppelin wird nicht mehr von Internet Explorer abgemeldet. |
| BUG-95349 | ZOOKEEPER-1256, ZOOKEEPER-1901 | Upgrade für Netty |
| BUG-95483 | – | Fehlerbehebung für CVE-2017-15713 |
| BUG-95646 | OOZIE-3167 | Upgrade der Tomcat-Version auf Oozie 4.3. |
| BUG-95823 | Nicht zutreffend | Knox: Upgrade Beanutils |
| BUG-95908 | RANGER-1960 | HBase auth berücksichtigt Tabellen-Namespace nicht für die Löschung von Momentaufnahmen. |
| BUG-96191 | FALCON-2322, FALCON-2323 | Upgrade für die Jackson- und Spring-Versionen, um Sicherheitsrisiken zu vermeiden. |
| BUG-96502 | RANGER-1990 | Unidirektionale Unterstützung von SSL und MySQL in Ranger Admin. |
| BUG-96712 | FLUME-3194 | Upgrade von Derby auf die neueste Version (1.14.1.0) |
| BUG-96713 | FLUME-2678 | Upgrade von Xalan auf Version 2.7.2, um das Sicherheitsrisiko von CVE-2014-0107 zu beheben. |
| BUG-96714 | FLUME-2050 | Upgrade zu log4j2 (wenn GA) |
| BUG-96737 | – | Verwendung von Methoden für Java-E/A-Dateisysteme, um auf lokale Dateien zugreifen zu können |
| BUG-96925 | – | Upgrade von Tomcat von Version 6.0.48 auf 6.0.53 in Hadoop |
| BUG-96977 | FLUME-3132 | Upgrade der Abhängigkeiten der Tomcat jasper-Bibliothek |
| BUG-97022 | HADOOP-14799, HADOOP-14903, HADOOP-15265 | Upgrade der Nimbus-JOSE-JWT-Bibliothek auf eine Version über 4.39 |
| BUG-97101 | RANGER-1988 | Fehlerbehebung unsicherer Zufallselemente. |
| BUG-97178 | ATLAS-2467 | Upgrade der Abhängigkeiten für Spring und Nimbus-JOSE-JWT |
| BUG-97180 | – | Upgrade für Nimbus-JOSE-JWT |
| BUG-98038 | HIVE-18788 | Bereinigen von Eingaben in PreparedStatement von JDBC. |
| BUG-98353 | HADOOP-13707 | Wiederherstellung von „If kerberos is enabled while HTTP SPNEGO is not configured, some links cannot be accessed“ (Wenn Kerberos aktiviert ist, während HTTP SPNEGO nicht konfiguriert ist, kann auf einige Links nicht zugegriffen werden.) |
| BUG-98372 | HBASE-13848 | Zugriff auf InfoServer SSL-Kennwörter über die Anmeldeinformationsanbieter-API |
| BUG-98385 | ATLAS-2500 | Hinzufügen zusätzlicher Header für die Atlas-Antwort |
| BUG-98564 | HADOOP-14651 | Update der okhttp-Version auf 2.7.5 |
| BUG-99440 | RANGER-2045 | Wenn die Richtlinie nicht explizit auf „allow“ festgelegt ist, werden Hive-Tabellenspalten mit dem Befehl „desc table“ aufgeführt. |
| BUG-99803 | – | Oozie sollte das Laden dynamischer Klassen von HBase deaktivieren. |
Stabilität
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-100040 | ATLAS-2536 | NPE in Atlas Hive-Hook |
| BUG-100057 | HIVE-19251 | ObjectStore.getNextNotification mit LIMIT sollte weniger Arbeitsspeicher beanspruchen |
| BUG-100072 | HIVE-19130 | NPE wird ausgelöst, wenn REPL LOAD auf DROP_PARTITION-Ereignis angewendet wird. |
| BUG-100073 | Nicht zutreffend | Zu viele close_wait-Verbindungen zwischen hiveserver und Datenknoten |
| BUG-100319 | HIVE-19248 | REPL LOAD löst keinen Fehler aus, wenn das Kopieren der Datei fehlschlägt. |
| BUG-100352 | – | CLONE-Ressource-Manager löscht „/registry znode“-Logiküberprüfungen zu oft. |
| BUG-100427 | HIVE-19249 | Replikation: WITH-Klausel gibt nicht in allen Fällen die Konfiguration ordnungsgemäß an den Task weiter. |
| BUG-100430 | HIVE-14483 | java.lang.ArrayIndexOutOfBoundsException org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays |
| BUG-100432 | HIVE-19219 | Die inkrementelle REPL DUMP-Funktion sollte einen Fehler auslösen, wenn angeforderte Ereignisse bereinigt werden. |
| BUG-100448 | SPARK-23637, SPARK-23802, SPARK-23809, SPARK-23816, SPARK-23822, SPARK-23823, SPARK-23838, SPARK-23881 | Aktualisieren Sie Spark2 auf 2.3.0+ (4/11) |
| BUG-100740 | HIVE-16107 | JDBC: HttpClient sollte einen weiteren Versuch für NoHttpResponseException ausführen. |
| BUG-100810 | HIVE-19054 | Replikation von Hive-Funktionen schlägt fehl |
| BUG-100937 | MAPREDUCE-6889 | Job#close-API zum Beenden der MR-Clientdienste hinzugefügt. |
| BUG-101065 | ATLAS-2587 | Festlegen des ACL-Lesevorgangs für /apache_atlas/active_server_info znode in HA für den Lesevorgang durch Knox-Proxy. |
| BUG-101093 | STORM-2993 | Storm-HDFS-Bolt löst die Ausnahme ClosedChannelException aus, wenn eine Zeitrotationsrichtlinie verwendet wird. |
| BUG-101181 | – | PhoenixStorageHandler verarbeitet AND in Prädikat nicht ordnungsgemäß. |
| BUG-101266 | PHOENIX-4635 | Arbeitsspeicherverlust bei der HBase-Verbindung in org.apache.phoenix.hive.mapreduce.PhoenixInputFormat |
| BUG-101458 | HIVE-11464 | Herkunftsinformationen fehlen, wenn mehrere Ausgaben vorhanden sind. |
| BUG-101485 | – | Hive-Metastore-Thrift-API ist langsam und verursacht Zeitüberschreitung beim Client. |
| BUG-101628 | HIVE-19331 | Inkrementelle Hive-Replikation in der Cloud schlägt fehl. |
| BUG-102048 | HIVE-19381 | Replikation der Hive-Funktion in der Cloud schlägt mit FunctionTask fehl. |
| BUG-102064 | Nicht zutreffend | \[ onprem to onprem \]-Tests schlagen bei der Hive-Replikation in ReplCopyTask fehl |
| BUG-102137 | HIVE-19423 | \[ Onprem to Cloud \]-Tests schlagen bei der Hive-Replikation in ReplCopyTask fehl |
| BUG-102305 | HIVE-19430 | OOM-Abbilder von HS2 und Hive-Metastore |
| BUG-102361 | Nicht zutreffend | Mehrere INSERT-Ergebnisse in einem einzelnen INSERT werden im Hive-Zielcluster repliziert ( onprem - s3 ) |
| BUG-87624 | – | Aktivieren der Ereignisprotokollierung von Storm beendet Worker kontinuierlich |
| BUG-88929 | HBASE-15615 | Falsche Ruhezeit, wenn RegionServerCallable einen erneuten Versuch benötigt. |
| BUG-89628 | HIVE-17613 | Entfernen von Objektpools für kurze Zuordnungen im selben Thread. |
| BUG-89813 | – | SCA: Coderichtigkeit: Nicht synchronisierte Methode überschreibt synchronisierte Methode |
| BUG-90437 | ZEPPELIN-3072 | Die Benutzeroberfläche von Zeppelin wird langsam oder reagiert nicht, wenn zu viele Notebooks vorhanden sind. |
| BUG-90640 | HBASE-19065 | HRegion#bulkLoadHFiles() should wait for concurrent Region#flush() to finish. (HRegion#bulkLoadHFiles() sollte die Beendigung von Region#flush() abwarten.) |
| BUG-91202 | HIVE-17013 | Delete-Anforderung mit Unterabfrage basierend auf der Auswahl einer Ansicht. |
| BUG-91350 | KNOX-1108 | Für NiFiHaDispatch wird kein Failover ausgeführt |
| BUG-92054 | HIVE-13120 | Verteilung von doAs beim Generieren von ORC-Aufteilungen |
| BUG-92373 | FALCON-2314 | Ändern der TestNG-Version auf 6.13.1, um Abhängigkeit von BeanShell zu vermeiden. |
| BUG-92381 | – | testContainerLogsWithNewAPI und TestContainerLogsWithOldAPI UT schlägt fehl |
| BUG-92389 | STORM-2841 | testNoAcksIfFlushFails UT schlägt mit NullPointerException fehl. |
| BUG-92586 | SPARK-17920, SPARK-20694, SPARK-21642, SPARK-22162, SPARK-22289, SPARK-22373, SPARK-22495, SPARK-22574, SPARK-22591, SPARK-22595, SPARK-22601, SPARK-22603, SPARK-22607, SPARK-22635, SPARK-22637, SPARK-22653, SPARK-22654, SPARK-22686, SPARK-22688, SPARK-22817, SPARK-22862, SPARK-22889, SPARK-22972, SPARK-22975, SPARK-22982, SPARK-22983, SPARK-22984, SPARK-23001, SPARK-23038, SPARK-23095 | Update auf den neuesten Stand von Spark2 auf 2.2.1 (16. Jan.) |
| BUG-92680 | ATLAS-2288 | Die Ausnahme NoClassDefFoundError wird ausgelöst, während Skript zum Importieren von Hive ausgeführt wird, wenn eine HBase-Tabelle über Hive erstellt wird. |
| BUG-92760 | ACCUMULO-4578 | Abbrechen der Komprimierung des FATE-Vorgangs gibt Namespace-Sperre nicht frei. |
| BUG-92797 | HDFS-10267, HDFS-8496 | Reduzierung der DataNode-Sperrkonflikte in bestimmten Anwendungsfällen. |
| BUG-92813 | FLUME-2973 | Deadlock in HDFS-Senke |
| BUG-92957 | HIVE-11266 | count(*) führt basierend auf den Tabellenstatistiken für externe Tabellen zu einem falschen Ergebnis |
| BUG-93018 | ATLAS-2310 | In HA leitet der passive Knoten die Anforderung mit der falschen URL-Verschlüsselung um. |
| BUG-93116 | RANGER-1957 | Ranger Usersync synchronisiert Benutzer oder Gruppen nicht regelmäßig, wenn die inkrementelle Synchronisierung aktiviert ist. |
| BUG-93361 | HIVE-12360 | Fehlerhafte Positionierung in nicht komprimierten ORC mit Prädikat-Pushdown. |
| BUG-93426 | CALCITE-2086 | HTTP/413 tritt aufgrund von großen Autorisierungsheader in bestimmten Umständen auf. |
| BUG-93429 | PHOENIX-3240 | ClassCastException vom Pig-Ladeprogramm |
| BUG-93485 | Nicht zutreffend | mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException-Tabelle kann nicht abgerufen werden: Tabelle kann nicht gefunden werden, wenn die Tabellenanalyse auf Spalten in LLAP ausgeführt wird |
| BUG-93512 | PHOENIX-4466 | Antwortcode 500 für java.lang.RuntimeException: Ausführen eines Spark-Auftrags, um eine Verbindung mit dem Phoenix-Abfrageserver und Auslastungsdaten herzustellen. |
| BUG-93550 | – | Zeppelin %spark.r funktioniert nicht mit spark1 aufgrund eines Konflikts bei der Scala-Version. |
| BUG-93910 | HIVE-18293 | Hive kann Tabellen nicht in einem Ordner komprimieren, der nicht der Identität gehört, die HiveMetaStore ausführt. |
| BUG-93926 | ZEPPELIN-3114 | Notebooks und Interpreter werden nach >1d-Stresstests nicht in Zeppelin gespeichert. |
| BUG-93932 | ATLAS-2320 | Klassifizierung von „*“ mit Abfrage löst „500 Interne Serverausnahme“ aus. |
| BUG-93948 | YARN-7697 | NM fällt mit OOM aus, da ein Arbeitsspeicherverlust in LogAggregation besteht (Teil#1) |
| BUG-93965 | ATLAS-2229 | DSL-Suche: ORDERBY-Attribut, das keine Zeichenfolge ist, löst Ausnahme aus. |
| BUG-93986 | YARN-7697 | NM fällt mit OOM aus, da ein Arbeitsspeicherverlust in LogAggregation besteht (Teil#2) |
| BUG-94030 | ATLAS-2332 | Erstellung eines Typs mit Attributen, die geschachtelte Auflistungsdatentypen aufweisen, schlagen fehl. |
| BUG-94080 | YARN-3742, YARN-6061 | Beide Ressourcen-Manager befinden sich im sicheren Cluster im Standbymodus. |
| BUG-94081 | HIVE-18384 | ConcurrentModificationException in log4j2.x library. (ConcurrentModificationException in (x)-Bibliothek.) |
| BUG-94168 | – | Yarn-Ressource-Manager fällt mit der Dienstregistrierung aus, der falsche Fehlerzustand besteht. |
| BUG-94330 | HADOOP-13190, HADOOP-14104, HADOOP-14814, HDFS-10489, HDFS-11689 | HDFS sollte mehrere KMS Uris unterstützen |
| BUG-94345 | HIVE-18429 | Die Komprimierung sollte einen Fall behandeln, wenn keine Ausgabe erzeugt wird. |
| BUG-94372 | ATLAS-2229 | DSL-Abfrage: hive_table name = ["t1","t2"] löst ungültige Ausnahme für die DSL-Abfrage aus. |
| BUG-94381 | HADOOP-13227, HDFS-13054 | Reihenfolge für RetryAction bei der Verarbeitung von RequestHedgingProxyProvider: FAIL < RETRY < FAILOVER_AND_RETRY. |
| BUG-94432 | HIVE-18353 | CompactorMR sollte jobclient.close() aufrufen, um die Bereinigung auszulösen. |
| BUG-94575 | SPARK-22587 | Spark-Auftrag schlägt fehl, wenn fs.defaultFS und die JAR-Anwendung zu einer anderen URL gehören. |
| BUG-94791 | SPARK-22793 | Arbeitsspeicherverlust in Spark Thrift-Server |
| BUG-94928 | HDFS-11078 | Behebung von NPE in LazyPersistFileScrubber |
| BUG-95013 | HIVE-18488 | LLAP ORC-Reader fehlen in einigen NULL-Überprüfungen. |
| BUG-95077 | HIVE-14205 | Hive unterstützt den Union-Typ nicht mit dem Dateiformat AVRO. |
| BUG-95200 | HDFS-13061 | SaslDataTransferClient#checkTrustAndSend sollte einem nur teilweise vertrauenswürdigen Kanal nicht vertrauen |
| BUG-95201 | HDFS-13060 | Hinzufügen von BlacklistBasedTrustedChannelResolver für TrustedChannelResolver |
| BUG-95284 | HBASE-19395 | TestEndToEndSplitTransaction.testMasterOpsWhileSplitting schlägt unter [branch-1] mit NPE fehl. |
| BUG-95301 | HIVE-18517 | Vectorization: Fix VectorMapOperator to accept VRBs and check vectorized flag correctly to support LLAP Caching. (Vektorisierung: Behebung von VectorMapOperator, damit VRBs akzeptiert und vektorisierte Flags ordnungsgemäß überprüft werden, um LLAP-Zwischenspeicherung zu unterstützen.) |
| BUG-95542 | HBASE-16135 | PeerClusterZnode unter rs von entferntem Peer kann nicht gelöscht werden |
| BUG-95595 | HIVE-15563 | Ausnahme für unzulässigen Übergang des Vorgangsstatus in SQLOperation.runQuery ignorieren, um tatsächliche Ausnahme zur Verfügung zu stellen. |
| BUG-95596 | YARN-4126, YARN-5750 | TestClientRMService schlägt fehl |
| BUG-96019 | HIVE-18548 | Korrektur des log4j Imports |
| BUG-96196 | HDFS-13120 | Vergleich einer Momentaufnahme kann nach concat beschädigt sein. |
| BUG-96289 | HDFS-11701 | NPE von nicht aufgelöstem Host verursacht permanente DFSInputStream-Fehler. |
| BUG-96291 | STORM-2652 | Ausnahme wird in der Methode „JmsSpout.open“ ausgelöst |
| BUG-96363 | HIVE-18959 | Vermeiden der Erstellung zusätzlicher Threadpools in LLAP |
| BUG-96390 | HDFS-10453 | ReplicationMonitor-Thread kann aufgrund einer Racebedingung zwischen Wiederherstellung und Löschung der gleichen Datei in einem großen Cluster für einen langen Zeitraum unterbrochen werden. |
| BUG-96454 | YARN-4593 | Deadlock in AbstractService.getConfig() |
| BUG-96704 | FALCON-2322 | ClassCastException wird während submitAndSchedule-Feed ausgelöst |
| BUG-96720 | SLIDER-1262 | Funktionstests von Slider schlagen in Kerberized Umgebung fehl |
| BUG-96931 | SPARK-23053, SPARK-23186, SPARK-23230, SPARK-23358, SPARK-23376, SPARK-23391 | Spark2-Update ist auf dem neuesten Stand (Feb. 19) |
| BUG-97067 | HIVE-10697 | ObjectInspectorConvertors#UnionConvertor does a faulty conversion. (ObjectInspectorConvertors#UnionConvertor führt eine fehlerhafte Konvertierung durch.) |
| BUG-97244 | KNOX-1083 | Standardzeitlimit für HttpClient sollte einen sinnvollen Wert aufweisen |
| BUG-97459 | ZEPPELIN-3271 | Option zum Deaktivieren des Planers |
| BUG-97511 | KNOX-1197 | AnonymousAuthFilter wird nicht hinzugefügt, wenn authentication=Anonymous im Dienst vorhanden ist |
| BUG-97601 | HIVE-17479 | Stagingverzeichnisse werden nicht für Update-/Delete-Abfragen bereinigt |
| BUG-97605 | HIVE-18858 | Systemeigenschaften in der Auftragskonfiguration werden nicht aufgelöst, wenn MR-Auftrag übermittelt wird |
| BUG-97674 | OOZIE-3186 | Oozie kann die mit „jceks://file/...“ verknüpfte Konfiguration nicht verwenden. |
| BUG-97743 | – | Die Ausnahme java.lang.NoClassDefFoundError wird während der Bereitstellung der Storm-Topologie ausgelöst. |
| BUG-97756 | PHOENIX-4576 | Behebung von Fehlern bei LocalIndexSplitMergeIT-Tests |
| BUG-97771 | HDFS-11711 | DN sollte den Block der Ausnahme „zu viele geöffnete Dateien“ nicht löschen. |
| BUG-97869 | KNOX-1190 | Unterstützung von Knox-SSO für Google-OIDC ist fehlerhaft. |
| BUG-97879 | PHOENIX-4489 | HBase-Verbindungslücke in Phoenix-MR-Aufträgen. |
| BUG-98392 | RANGER-2007 | Kerberos-Ticket von ranger-tagsync kann nicht wiederhergestellt werden |
| BUG-98484 | – | Inkrementelle Hive-Replikation in der Cloud funktioniert nicht |
| BUG-98533 | HBASE-19934, HBASE-20008 | Wiederherstellung der HBase-Momentaufnahme schlägt aufgrund einer NULL-Zeigerausnahme fehl |
| BUG-98555 | PHOENIX-4662 | NullPointerException wird in der erneuten Übermittlung von TableResultIterator.java ausgelöst |
| BUG-98579 | HBASE-13716 | Entfernen der veralteten FSConstants-Klasse von Hadoop |
| BUG-98705 | KNOX-1230 | Viele gleichzeitige Anforderungen an Knox verursachen Beschädigungen der URL |
| BUG-98983 | KNOX-1108 | Für NiFiHaDispatch wird kein Failover ausgeführt |
| BUG-99107 | HIVE-19054 | Funktionsreplikation sollte „hive.repl.replica.functions.root.dir“ als Stamm verwenden |
| BUG-99145 | RANGER-2035 | Fehler beim Zugriff auf servicedefs mit leerer implClass mit Oracle-Back-End |
| BUG-99160 | SLIDER-1259 | Slider funktioniert nicht in mehrfach vernetzten Umgebungen. |
| BUG-99239 | ATLAS-2462 | Sqoop-Import für alle Tabellen löst NPE für keine im Befehl angegebene Tabelle aus |
| BUG-99301 | ATLAS-2530 | Zeilenumbruch am Anfang des Namensattributs von hive_process und hive_column_lineage |
| BUG-99453 | HIVE-19065 | Konformitätsprüfung des Metastore-Clients sollte syncMetaStoreClient enthalten |
| BUG-99521 | – | ServerCache für HashJoin wird nicht wiederhergestellt, wenn Iteratoren erneut instanziiert werden |
| BUG-99590 | PHOENIX-3518 | Arbeitsspeicherverlust in RenewLeaseTask |
| BUG-99618 | SPARK-23599, SPARK-23806 | Aktualisieren Sie Spark2 auf 2.3.0+ (3/28) |
| BUG-99672 | ATLAS-2524 | Hive-Hook mit V2-Benachrichtigungen: Fehlerhafte Verarbeitung des Vorgangs „alter view as“ |
| BUG-99809 | HBASE-20375 | Entfernen der Verwendung von getCurrentUserCredentials im hbase-spark-Modul |
Unterstützungsmöglichkeiten
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-87343 | HIVE-18031 | Unterstützung der Replikation des Alter Database-Vorgangs |
| BUG-91293 | RANGER-2060 | Knox-Proxy mit knox-sso funktioniert für Ranger nicht |
| BUG-93116 | RANGER-1957 | Ranger Usersync synchronisiert Benutzer oder Gruppen nicht regelmäßig, wenn die inkrementelle Synchronisierung aktiviert ist. |
| BUG-93577 | RANGER-1938 | Solr verwendet für die Einrichtung der Überprüfung DocValues nicht effektiv. |
| BUG-96082 | RANGER-1982 | Error Improvement for Analytics Metric of Ranger Admin and Ranger Kms (Verbesserung der Verarbeitung von Fehlern für Analysemetriken von Ranger Admin und Ranger (x)) |
| BUG-96479 | HDFS-12781 | Nach Ausfall von Datanode in Namenode UI Datanode Registerkarte zeigt eine Warnmeldung an. |
| BUG-97864 | HIVE-18833 | Automatische Zusammenführung schlägt fehl, wenn die Funktion als ORC-Datei eingefügt wird. |
| BUG-98814 | HDFS-13314 | NameNode sollte optional beendet werden, wenn eine Beschädigung in FsImage erkannt wird |
Upgrade
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-100134 | SPARK-22919 | Wiederherstellen von „Ändern der Apache-HttpClient-Version“ |
| BUG-95823 | Nicht zutreffend | Knox: Upgrade Beanutils |
| BUG-96751 | KNOX-1076 | Update von Nimbus-JOSE-JWT auf Version 4.41.2 |
| BUG-97864 | HIVE-18833 | Automatische Zusammenführung schlägt fehl, wenn die Funktion als ORC-Datei eingefügt wird. |
| BUG-99056 | HADOOP-13556 | Änderung für Configuration.getPropsWithPrefix, damit getProps anstelle des Iterators verwendet wird. |
| BUG-99378 | ATLAS-2461, ATLAS-2554 | Hilfsprogramm für die Migration, um Atlas-Daten in eine Titan Graph-Datenbank |
Benutzerfreundlichkeit
| Fehler-ID | Apache JIRA | Zusammenfassung |
|---|---|---|
| BUG-100045 | HIVE-19056 | IllegalArgumentException wird in FixAcidKeyIndex ausgelöst, wenn ORC-Datei 0 (null) Zeilen enthält |
| BUG-100139 | KNOX-1243 | Normalisieren der erforderlichen DNs (Distinguished Names), die im KnoxToken-Dienst konfiguriert werden |
| BUG-100570 | ATLAS-2557 | Fehlerbehebung, um die lookup nach Hadoop ldap-Gruppen zu ermöglichen, wenn Gruppen von UGI falsch festgelegt oder nicht leer sind |
| BUG-100646 | ATLAS-2102 | Verbesserungen der Atlas-Benutzeroberfläche: Seite „Suchergebnisse“ |
| BUG-100737 | HIVE-19049 | Hinzufügen von Unterstützung für ALTER TABLE zum Hinzufügen von Spalten für Druid |
| BUG-100750 | KNOX-1246 | Update für die Dienstkonfiguration in Knox, um die neuesten Ranger-Konfigurationen zu unterstützen. |
| BUG-100965 | ATLAS-2581 | Regression mit V2-Hive-Hookbenachrichtigungen: Tabelle wird in eine andere Datenbank verschoben |
| BUG-84413 | ATLAS-1964 | Benutzeroberfläche: Unterstützung der Sortierung von Spalten in der Suchtabelle |
| BUG-90570 | HDFS-11384, HDFS-12347 | Option zum Auflösen von getBlocks-Aufrufen für Balancer hinzugefügt, um Spike von NameNodes rpc.CallQueueLength zu vermeiden |
| BUG-90584 | HBASE-19052 | FixedFileTrailer sollte die Klasse CellComparatorImpl unter branch-1.x erkennen |
| BUG-90979 | KNOX-1224 | Knox Proxy HADispatcher zur Unterstützung von Atlas in HA. |
| BUG-91293 | RANGER-2060 | Knox-Proxy mit Knox-SSO funktioniert für Ranger nicht |
| BUG-92236 | ATLAS-2281 | Speichern von Filterabfragen für Tag-/Typ-Attribute mit NULL-/nicht NULL-Filtern |
| BUG-92238 | ATLAS-2282 | Suche nach gespeicherten Favoriten wird nur nach Aktualisierung nach Erstellung angezeigt, wenn mehr als 25 Suchen nach Favoriten vorhanden sind. |
| BUG-92333 | ATLAS-2286 | Der vorkonfigurierte Typ ‚kafka_topic‘ sollte das ‚topic‘-Attribut nicht als eindeutig deklarieren. |
| BUG-92678 | ATLAS-2276 | Der Pfadwert für die Typentität „hdfs_path“ wird über hive-bridge in Kleinschreibung festgelegt. |
| BUG-93097 | RANGER-1944 | Aktionsfilter für Administratorüberwachung funktioniert nicht |
| BUG-93135 | HIVE-15874, HIVE-18189 | Hive-Abfrage gibt die falschen Ergebnisse zurück, wenn hive.groupby.orderby.position.alias auf TRUE festgelegt ist. |
| BUG-93136 | HIVE-18189 | Die Abfrage „Order by position“ funktioniert nicht, wenn cbo deaktiviert ist |
| BUG-93387 | HIVE-17600 | Benutzerdefinierbarkeit von enforceBufferSize der ORC-Datei |
| BUG-93495 | RANGER-1937 | Ranger tagsync sollte die Benachrichtigung ENTITY_CREATE verarbeiten, um das Import-Feature von Atlas zu unterstützen |
| BUG-93512 | PHOENIX-4466 | Antwortcode 500 für java.lang.RuntimeException: Ausführen eines Spark-Auftrags, um eine Verbindung mit dem Phoenix-Abfrageserver und Auslastungsdaten herzustellen. |
| BUG-93801 | HBASE-19393 | HTTP-Fehler 413 während Zugriff auf HBase-Benutzeroberfläche mit SSL |
| BUG-93804 | HIVE-17419 | Der Befehl „ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS“ zeigt berechnete Statistiken für maskierte Tabellen. |
| BUG-93932 | ATLAS-2320 | Klassifizierung von „*“ mit Abfrage löst „500 Interne Serverausnahme“ aus. |
| BUG-93933 | ATLAS-2286 | Der vorkonfigurierte Typ ‚kafka_topic‘ sollte das ‚topic‘-Attribut nicht als eindeutig deklarieren. |
| BUG-93938 | ATLAS-2283, ATLAS-2295 | Updates der Benutzeroberfläche für Klassifizierungen |
| BUG-93941 | ATLAS-2296, ATLAS-2307 | Verbesserung der Standardsuche, um Entitäten von Untertypen und Klassifizierungen von Untertypen optional auszuschließen |
| BUG-93944 | ATLAS-2318 | Benutzeroberfläche: Wenn ein Doppelklick auf ein untergeordnetes Tag ausgeführt wird, wird ein übergeordnetes Tag ausgewählt |
| BUG-93946 | ATLAS-2319 | Benutzeroberfläche: Das Löschen eines Tags mit einer Position von 25 oder höher in der Liste von Tags in der flachen Struktur und der Baumstruktur erfordert eine Aktualisierung, um das Tag aus der Liste zu entfernen. |
| BUG-93977 | HIVE-16232 | Unterstützung für die Berechnung von Statistiken für Spalten in QuotedIdentifier. |
| BUG-94030 | ATLAS-2332 | Erstellung eines Typs mit Attributen, die geschachtelte Auflistungsdatentypen aufweisen, schlagen fehl. |
| BUG-94099 | ATLAS-2352 | Atlas-Server sollte Konfiguration bereitstellen, um die Gültigkeit für DelegationToken von Kerberos anzugeben |
| BUG-94280 | HIVE-12785 | Ansicht mit Union-Typ und UDF zum ‚Umwandeln‘ der Struktur ist fehlerhaft. |
| BUG-94332 | SQOOP-2930 | Sqoop-Auftragsausführung überschreibt nicht die generischen Eigenschaften des gespeicherten Auftrags |
| BUG-94428 | Nicht zutreffend | Dataplane Profiler Agent REST API Knox Support |
| BUG-94514 | ATLAS-2339 | Benutzeroberfläche: Änderungen in den Spalten der Ansicht der Standardsuchergebnisse wirkt sich auch auf DSL aus. |
| BUG-94515 | ATLAS-2169 | Delete-Anforderung schlägt fehl, wenn endgültiges Löschen konfiguriert ist |
| BUG-94518 | ATLAS-2329 | Mehrere Quickinfos werden auf der Atlas-Benutzeroberfläche angezeigt, wenn Benutzer auf ein anderes Tag klicken, das fehlerhaft ist |
| BUG-94519 | ATLAS-2272 | Speichern des Status gezogener Spalten mithilfe der API zum Speichern der Suche |
| BUG-94627 | HIVE-17731 | hinzufügen einer Option für die compat in HIVE-11985 für externe Benutzer |
| BUG-94786 | HIVE-6091 | Leere pipeout-Dateien werden erstellt, wenn Verbindungen erstellt oder gelöscht werden |
| BUG-94793 | HIVE-14013 | Beschreibungstabelle zeigt Unicode nicht ordnungsgemäß an |
| BUG-94900 | OOZIE-2606, OOZIE-2658, OOZIE-2787, OOZIE-2802 | spark.yarn.jars wurde festgelegt, um Fehler bei Spark 2.0 mit Oozie zu beheben |
| BUG-94901 | HBASE-19285 | Hinzufügen von Latenzhistogrammen pro Tabelle. |
| BUG-94908 | ATLAS-1921 | Benutzeroberfläche: Suche mithilfe der Attribute „Entity“ und „Trait“: Benutzeroberfläche führt keine Bereichsüberprüfung durch und lässt die Angabe von Werten außerhalb der zulässigen Bereichs für die integrale und float-Datentypen zu. |
| BUG-95086 | RANGER-1953 | Verbesserung der Auflistung von Benutzergruppenseiten |
| BUG-95193 | SLIDER-1252 | Agent von Slider schlägt mit SSL-Validierungsfehlern bei Python 2.7.5-58 fehl |
| BUG-95314 | YARN-7699 | queueUsagePercentage tritt als INF für Aufrufe der getApp-REST-API auf |
| BUG-95315 | HBASE-13947, HBASE-14517, HBASE-17931 | Zuweisen von Systemtabellen zu Servern mit der höchsten Version |
| BUG-95392 | ATLAS-2421 | Updates für die Benachrichtigungen, um V2-Datenstrukturen zu unterstützen |
| BUG-95476 | RANGER-1966 | Bei der Initialisierung der Richtlinien-Engine werden in manchen Fällen keine Kontextanreicherungen erstellt. |
| BUG-95512 | HIVE-18467 | Unterstützung gesamter Warehouse-Sicherung / Laden und Erstellen/Löschen von Datenbankereignissen |
| BUG-95593 | Nicht zutreffend | Erweiterungen der Hilfsprogramme für Oozie-Datenbanken zur Unterstützung der Erstellung von Spark2sharelib-Sharelibs |
| BUG-95595 | HIVE-15563 | Ausnahme für unzulässigen Übergang des Vorgangsstatus in SQLOperation.runQuery ignorieren, um tatsächliche Ausnahme zur Verfügung zu stellen. |
| BUG-95685 | ATLAS-2422 | Export: Export, der auf Unterstützungstypen basiert |
| BUG-95798 | PHOENIX-2714, PHOENIX-2724, PHOENIX-3023, PHOENIX-3040 | Guideposts nicht zum seriellen Ausführen von Abfragen verwenden |
| BUG-95969 | HIVE-16828, HIVE-17063, HIVE-18390 | Partitionierte Sicht schlägt mit FEHLER fehl: IndexOutOfBoundsException-Index: 1, Größe: 1 |
| BUG-96019 | HIVE-18548 | Korrektur des log4j Imports |
| BUG-96288 | HBASE-14123, HBASE-14135, HBASE-17850 | Zurückportierung von HBase Backup/Restore 2.0 |
| BUG-96313 | KNOX-1119 | Pac4J OAuth/OpenID muss konfigurierbar sein |
| BUG-96365 | ATLAS-2442 | Benutzer mit schreibgeschützter Berechtigung für die Entitätsressource können keine Standardsuche durchführen |
| BUG-96479 | HDFS-12781 | Nach Ausfall von Datanode in Namenode UI Datanode Registerkarte zeigt eine Warnmeldung an. |
| BUG-96502 | RANGER-1990 | Unidirektionale Unterstützung von SSL und MySQL in Ranger Admin. |
| BUG-96718 | ATLAS-2439 | Update für den Sqoop-Hook zur Verwendung von V2-Benachrichtigungen |
| BUG-96748 | HIVE-18587 | DML-Insert-Ereignis kann versuchen, eine Prüfsumme für Verzeichnisse zu berechnen |
| BUG-96821 | HBASE-18212 | Im eigenständigen Modus mit lokalen Dateisystem protokolliert HBase die Warnmeldung: „Aufruf der Methode „unbuffer“ in class org.apache.hadoop.fs.FSDataInputStream fehlgeschlagen“. |
| BUG-96847 | HIVE-18754 | REPL STATUS sollte WITH-Klauseln unterstützen |
| BUG-96873 | ATLAS-2443 | Erfassung erforderlicher Entitätsattribute in ausgehenden DELETE-Nachrichten |
| BUG-96880 | SPARK-23230 | Wenn hive.default.fileformat andere Dateitypen aufweist, löst das Erstellen einer textfile-Tabelle einen serde-Fehler aus |
| BUG-96911 | OOZIE-2571, OOZIE-2792, OOZIE-2799, OOZIE-2923 | Verbesserung der Analyse von Spark-Optionen |
| BUG-97100 | RANGER-1984 | Überwachungsprotokoll von HBase zeigt möglicherweise nicht alle Tags an, die der Spalte zugeordnet sind, auf die zugegriffen wird |
| BUG-97110 | PHOENIX-3789 | Ausführung regionsübergreifender Wartungsaufrufe in postBatchMutateIndispensably. |
| BUG-97145 | HIVE-12245, HIVE-17829 | Unterstützung für Spaltenkommentare für eine HBase-Tabelle. |
| BUG-97409 | HADOOP-15255 | Unterstützung der Anpassung der Groß-/Kleinschreibung für Gruppennamen in LdapGroupsMapping |
| BUG-97535 | HIVE-18710 | Erweiterung von inheritPerms auf ACID in Hive 2.x |
| BUG-97742 | OOZIE-1624 | Ausschlussmuster für sharelib-JAR-Dateien |
| BUG-97744 | PHOENIX-3994 | Index RPC-Priorität hängt weiterhin von der Controller Factory-Eigenschaft in „hbase-site.xml“ ab |
| BUG-97787 | HIVE-18460 | Komprimierungsprogramm übergibt Tabelleneigenschaften nicht an den ORC-Writer. |
| BUG-97788 | HIVE-18613 | JsonSerDe erweitert, um BINARY-Typen zu unterstützen. |
| BUG-97899 | HIVE-18808 | Stabilere Komprimierung, wenn Aktualisierung der Statistiken fehlschlägt |
| BUG-98038 | HIVE-18788 | Bereinigen von Eingaben in PreparedStatement von JDBC. |
| BUG-98383 | HIVE-18907 | Erstellung eines Hilfsprogramms zur Behebung eines Problems mit acid key index von HIVE-18817 |
| BUG-98388 | RANGER-1828 | Bewährte Codierungsmethoden: Hinzufügen weiterer Header in Ranger |
| BUG-98392 | RANGER-2007 | Kerberos-Ticket von ranger-tagsync kann nicht wiederhergestellt werden |
| BUG-98533 | HBASE-19934, HBASE-20008 | Wiederherstellung der HBase-Momentaufnahme schlägt aufgrund einer NULL-Zeigerausnahme fehl |
| BUG-98552 | HBASE-18083, HBASE-18084 | Threadanzahl in HFileCleaner für große/kleine Dateien konfigurierbar |
| BUG-98705 | KNOX-1230 | Viele gleichzeitige Anforderungen an Knox verursachen Beschädigungen der URL |
| BUG-98711 | – | NiFi-Dispatch kann bidirektionale SSL nicht ohne Änderungen an „service.xml“ verwenden |
| BUG-98880 | OOZIE-3199 | Konfigurierbarkeit der Einschränkung von Systemeigenschaften |
| BUG-98931 | ATLAS-2491 | Update von Hive-Hook, um Atlas V2-Benachrichtigungen zu verwenden. |
| BUG-98983 | KNOX-1108 | Für NiFiHaDispatch wird kein Failover ausgeführt |
| BUG-99088 | ATLAS-2511 | Angeben von Optionen zum selektiven Importieren von Datenbanken/Tabellen aus Hive in Atlas |
| BUG-99154 | OOZIE-2844, OOZIE-2845, OOZIE-2858, OOZIE-2885 | Spark-Abfrage schlägt mit der Ausnahme „java.io.FileNotFoundException: hive-site.xml (Permission denied)“ fehl |
| BUG-99239 | ATLAS-2462 | Sqoop-Import für alle Tabellen löst NPE für keine im Befehl angegebene Tabelle aus |
| BUG-99636 | KNOX-1238 | Fehlerbehebung für benutzerdefinierte Truststore-Einstellungen für Gateway |
| BUG-99650 | KNOX-1223 | Knox-Proxy von Zeppelin leitet /api/ticket nicht erwartungsgemäß um |
| BUG-99804 | OOZIE-2858 | HiveMain, ShellMain und SparkMain sollten Eigenschaften und Konfigurationsdateien nicht lokal überschreiben |
| BUG-99805 | OOZIE-2885 | Ausführung von Spark-Aktionen sollte Hive nicht auf dem Klassenpfad erfordern |
| BUG-99806 | OOZIE-2845 | Ersetzen von reflexionsbasiertem Code, der eine Variable in HiveConf festlegt |
| BUG-99807 | OOZIE-2844 | Erhöhung der Stabilität von Oozie-Aktionen, wenn „log4j.properties“ fehlt oder nicht lesbar ist |
| RMP-9995 | AMBARI-22222 | Auswechseln von Druid, um das Verzeichnis /var/druid anstelle von /apps/druid auf dem lokalen Datenträger zu verwenden |
Verhaltensänderungen
| Apache-Komponente | Apache JIRA | Zusammenfassung | Details |
|---|---|---|---|
| Spark 2.3 | N/V | Änderungen, die in den Versionsanmerkungen zu Apache Spark dokumentiert sind | – Es gibt ein Dokument für veraltete Komponenten und einen Leitfaden für Verhaltensänderungen, https://spark.apache.org/releases/spark-release-2-3-0.html#deprecations – Für den SQL-Abschnitt gibt es einen weiteren ausführlichen Leitfaden zur Migration (von 2.2 zu 2.3), https://spark.apache.org/docs/latest/sql-programming-guide.html#upgrading-from-spark-sql-22-to-23| |
| Spark | HIVE-12505 | Spark-Auftrag wird erfolgreich abgeschlossen, aber es besteht ein HDFS-Fehler aufgrund eines vollen Datenträgerkontingents | Szenario: Ausführen von insert overwrite, wenn ein Kontingent auf den Papierkorb des Benutzers festgelegt ist, der den Befehl ausführt. Vorheriges Verhalten: Der Auftrag wird erfolgreich abgeschlossen, obwohl die Daten nicht in den Papierkorb verschoben werden. Das Ergebnis kann fälschlicherweise einige Daten enthalten, die zuvor in der Tabelle vorhanden waren. Neues Verhalten: Wenn das Verschieben der Daten in den Papierkorb fehlschlägt, werden die Dateien dauerhaft gelöscht. |
| Kafka 1.0 | N/V | Änderungen, die in den Versionsanmerkungen zu Apache Spark dokumentiert sind | https://kafka.apache.org/10/documentation.html#upgrade_100_notable |
| Hive/Ranger | Zusätzliche Ranger Hive-Richtlinien sind für INSERT OVERWRITE erforderlich | Szenario: Zusätzliche Ranger Hive-Richtlinien sind für INSERT OVERWRITE erforderlich Vorheriges Verhalten: Hive-Abfragen von INSERT OVERWRITE werden wie gewohnt erfolgreich ausgeführt. Neues Verhalten: Hive-Abfragen von INSERT OVERWRITE schlagen unerwartet nach dem Upgrade auf HDP-2.6.x mit der folgenden Fehlermeldung fehl: Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user jdoe does not have WRITE privilege on /tmp/*(state=42000,code=40000) (Fehler beim Kompilieren der Anweisung: FEHLER: Berechtigung für HiveAccessControlException wurde verweigert: Benutzer „Jdoe“ verfügt über keine Schreibberechtigung für /tmp/*(state=42000,code=40000)) Ab HDP-2.6.0 erfordern Hive-Abfragen von INSERT OVERWRITE eine Ranger-URI-Richtline, um Schreibvorgänge zuzulassen, selbst wenn der Benutzer über eine HDFS-Richtlinie über Schreibberichtigungen verfügt. Problemumgehung/Erwartete Kundenaktion: 1. Erstellen Sie eine neue Richtlinie im Hive-Repository. 2. Wählen Sie „URI“ in der Dropdownliste aus, bei der „Database“ angezeigt wird. 3. Aktualisieren Sie den Pfad (z.B. /tmp/*) 4. Fügen Sie die Benutzer und Gruppen hinzu, und speichern Sie die Änderungen. 5. Wiederholen Sie die INSERT-Abfrage. |
|
| HDFS | N/V | HDFS sollte mehrere KMS Uris unterstützen |
Vorheriges Verhalten: Die dfs.encryption.key.provider.uri-Eigenschaft wurde verwendet, um den Pfad des KMS-Anbieters zu konfigurieren. Neues Verhalten: dfs.encryption.key.provider.uri ist nun veraltet und wurde zum Konfigurieren des Pfads des KMS-Anbieters durch hadoop.security.key.provider.path ersetzt. |
| Zeppelin | ZEPPELIN-3271 | Option zum Deaktivieren des Planers | Betroffene Komponente: Zeppelin-Server Vorheriges Verhalten: In vorherigen Releases von Zeppelin gab es keine Option zum Deaktivieren des Planers. Neues Verhalten: Standardmäßig wird der Planer nicht mehr für Benutzer angezeigt, da er standardmäßig deaktiviert ist. Problemumgehung/Erwartete Kundenaktion: Wenn Sie den Planer aktivieren möchten, müssen Sie azeppelin.notebook.cron.enable mit dem Wert TRUE in einer benutzerdefinierten „zeppelin-site.xml“ in den Zeppelin-Einstellungen von Ambari hinzufügen. |
Bekannte Probleme
HDInsight-Integration in ADLS Gen 2: In HDInsight-ESP-Clustern mit Azure Data Lake Storage Gen 2 können bei Benutzerverzeichnissen und -berechtigungen zwei Probleme auftreten:
Die Stammverzeichnisse für Benutzer werden in „Head Node 1“ nicht erstellt. Um dieses Problem zu umgehen, erstellen Sie die Verzeichnisse manuell, und ändern Sie den Besitz in den Benutzerprinzipalnamen des jeweiligen Benutzers.
Berechtigungen im Verzeichnis „/hdp“ werden zurzeit nicht auf 751 festgelegt. Diese müssen folgendermaßen festgelegt werden:
chmod 751 /hdp chmod –R 755 /hdp/apps
Spark 2.3
[SPARK-23523][SQL] Fehlerhaftes Ergebnis aufgrund der Regel OptimizeMetadataOnlyQuery
[SPARK-23406] Fehler in Selbstjoins von stream-stream
Beispiel-Notebooks von Spark sind nicht verfügbar, wenn Azure Data Lake Storage (Gen2) sich im Standardspeicher des Clusters befindet.
Enterprise-Sicherheitspaket
- Spark Thrift-Server lässt keine Verbindungen von ODBC-Clients zu.
Schritte zur Problemumgehung:
- Warten Sie nach der Erstellung des Clusters etwa 15 Minuten.
- Überprüfen Sie die Ranger-Benutzeroberfläche auf Vorhandensein von hivesampletable_policy.
- Starten Sie den Spark-Dienst erneut. Die STS-Verbindung sollte nun funktionieren.
- Spark Thrift-Server lässt keine Verbindungen von ODBC-Clients zu.
Schritte zur Problemumgehung:
Problemumgehung für Fehler bei der Ranger-Dienstüberprüfung
RANGER-1607: Problemumgehung für Fehler bei der Ranger-Dienstüberprüfung während des Upgrades auf HDP 2.6.2 aus früheren Versionen von HDP.
Hinweis
Nur wenn Ranger SSL-fähig ist.
Dieses Problem tritt nur auf, wenn versucht wird, ein Upgrade auf HDP-2.6.1 aus früheren HDP-Versionen über Ambari durchzuführen. Ambari verwendet einen Curl-Aufruf, um eine Dienstüberprüfung für den Ranger-Dienst in Ambari durchzuführen. Wenn die von Ambari verwendete JDK-Version JDK-1.7 ist, schlägt der Curl-Aufruf mit der folgenden Fehlermeldung fehl:
curl: (35) error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failureDer Grund für diesen Fehler ist, dass Tomcat-7.0.7* in Ranger verwendet wird. Die Verwendung von JDK-1.7 steht im Konflikt mit Standardverschlüsselungen, die in Tomcat-7.0.7* bereitgestellt werden.
Sie können dieses Problem auf zwei Arten beheben:
Aktualisieren Sie die in Ambari verwendete Version von JDK von JDK-1.7 auf JDK-1.8 (weitere Informationen dazu finden Sie im Abschnitt Change the JDK Version (Ändern der JDK-Version) des Ambari-Handbuchs).
Wenn Sie weiterhin eine JDK-1.7-Umgebung unterstützen möchten:
Fügen Sie die Eigenschaft „ranger.tomcat.ciphers“ in den Abschnitt „ranger-admin-site“ Ihrer Ambari-Ranger-Konfiguration mit dem folgenden Wert ein:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Wenn Ihre Umgebung für Ranger-KMS konfiguriert ist, fügen Sie die Eigenschaft „ranger.tomcat.ciphers“ in den Abschnitt „theranger-kms-site“ Ihrer Ambari-Ranger-Konfiguration mit dem folgenden Wert ein:
SSL_RSA_WITH_RC4_128_MD5, SSL_RSA_WITH_RC4_128_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, SSL_RSA_WITH_3DES_EDE_CBC_SHA
Hinweis
Die aufgeführten Werte sind funktionierende Beispiele und möglicherweise nicht für Ihre Umgebung maßgeblich. Stellen Sie sicher, dass die Art und Weise, in der Sie diese Eigenschaften festlegen, mit der Konfiguration der Umgebung übereinstimmt.
Ranger-Benutzeroberfläche: Auszug aus dem Text der Richtlinienbedingung, der in das Richtlinienformular eingegeben wurde
Betroffene Komponente: Ranger
Beschreibung des Problems
Wenn ein Benutzer eine Richtlinie mit benutzerdefinierten Richtlinienbedingungen erstellen möchte, und der Ausdruck oder Text enthält Sonderzeichen, dann funktioniert die Richtlinienerzwingung nicht. Sonderzeichen werden in ASCII konvertiert, bevor die Richtlinie in der Datenbank gespeichert wird.
Sonderzeichen: & <> " ` '
Beispielsweise würde die Bedingung „tags.attributes['type']='abc'“ in Folgendes konvertiert werden, wenn die Richtlinie gespeichert wird:
tags.attds['dsds']='cssdfs'
Sie können die Richtlinienbedingung mit diesen Zeichen anzeigen, indem Sie die Richtlinie im Bearbeitungsmodus öffnen.
Problemumgehung
Option #1: Erstellen oder Aktualisieren der Richtlinie über die Ranger-REST-API
REST-URL: http://<host>:6080/service/plugins/policies
Erstellen einer Richtlinie mit Richtlinienbedingung:
Mit dem folgenden Beispiel wird eine Richtlinie mit Tags als ‚tags-test‘ erstellt und der Gruppe ‚public‘ mit der Richtlinienbedingung „astags.attr['type']=='abc'“ zugewiesen, indem alle Berechtigungen für Hive-Komponenten wie „select“, „update“, „create“, „drop“, „alter“, „index“, „lock“ und „all“ ausgewählt werden.
Beispiel:
curl -H "Content-Type: application/json" -X POST http://localhost:6080/service/plugins/policies -u admin:admin -d '{"policyType":"0","name":"P100","isEnabled":true,"isAuditEnabled":true,"description":"","resources":{"tag":{"values":["tags-test"],"isRecursive":"","isExcludes":false}},"policyItems":[{"groups":["public"],"conditions":[{"type":"accessed-after-expiry","values":[]},{"type":"tag-expression","values":["tags.attr['type']=='abc'"]}],"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}]}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"service":"tagdev"}'Aktualisieren einer vorhandenen Richtlinie mit Richtlinienbedingung:
Mit dem folgenden Beispiel wird eine Richtlinie mit Tags als ‚tags-test‘ aktualisiert und der Gruppe ‚public‘ mit der Richtlinienbedingung „astags.attr['type']=='abc'“ zugewiesen, indem alle Berechtigungen für Hive-Komponenten wie „select“, „update“, „create“, „drop“, „alter“, „index“, „lock“ und „all“ ausgewählt werden.
REST-URL: http://<host-name>:6080/service/plugins/policies/<policy-id>
Beispiel:
curl -H "Content-Type: application/json" -X PUT http://localhost:6080/service/plugins/policies/18 -u admin:admin -d '{"id":18,"guid":"ea78a5ed-07a5-447a-978d-e636b0490a54","isEnabled":true,"createdBy":"Admin","updatedBy":"Admin","createTime":1490802077000,"updateTime":1490802077000,"version":1,"service":"tagdev","name":"P0101","policyType":0,"description":"","resourceSignature":"e5fdb911a25aa7f77af5a9546938d9ed","isAuditEnabled":true,"resources":{"tag":{"values":["tags"],"isExcludes":false,"isRecursive":false}},"policyItems":[{"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}],"users":[],"groups":["public"],"conditions":[{"type":"ip-range","values":["tags.attributes['type']=abc"]}],"delegateAdmin":false}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"dataMaskPolicyItems":[],"rowFilterPolicyItems":[]}'Option #2: Anwenden von JavaScript-Änderungen
Schritte zum Aktualisieren der JS-Datei:
Suchen Sie unter /usr/hdp/current/ranger-admin nach der Datei „PermissionList.js“.
Suchen Sie die Definition der Funktion „renderPolicyCondtion“ (Zeilennummer: 404)
Entfernen Sie die folgende Zeile aus dieser Funktion, d. h. unter der Anzeigefunktion (Zeile n:434).
val = _.escape(val);//Line No:460
Nach dem Entfernen der obigen Zeile können Sie mit der Ranger-Benutzeroberfläche Richtlinien mit Richtlinienbedingungen erstellen, die Sonderzeichen enthalten, und die Richtlinienauswertung wird für die gleiche Richtlinie erfolgreich ausgeführt.
HDInsight-Integration mit ADLS Gen 2: Benutzerverzeichnisse und Berechtigungsproblem mit ESP-Clustern 1. Basisverzeichnisse für Benutzer werden auf Hauptknoten 1 nicht erstellt. Um dieses Problem zu umgehen, erstellen Sie die Verzeichnisse manuell, und ändern Sie den Besitz in den Benutzerprinzipalnamen des jeweiligen Benutzers. 2. Berechtigungen im Verzeichnis „/hdp“ werden zurzeit nicht auf 751 festgelegt. Dies muss auf a. chmod 751 /hdp b. chmod –R 755 /hdp/apps festgelegt werden
Eingestellte Unterstützung
OMS-Portal: Der Link zur HDInsight-Ressourcenseite, der zum OMS-Portal geführt hat, wurde entfernt. Für Azure Monitor-Protokolle wurde zunächst ein eigenes Portal verwendet – das OMS-Portal –, um die Konfiguration zu verwalten und gesammelte Daten zu analysieren. Alle Funktionen dieses Portals wurden in das Azure-Portal übernommen, wo sie weiter entwickelt werden. HDInsight unterstützt das OMS-Portal nicht mehr. Kunden verwenden die Integration von HDInsight in Azure Monitor-Protokolle im Azure-Portal.
Aktualisieren
Alle dieser Features sind in HDInsight 3.6 verfügbar. Wählen Sie beim Erstellen eines HDInsight 3.6-Clusters die Versionen Spark, Kafka und ML Services aus, um die neuesten Versionen von Spark, Kafka und R Server (Machine Learning Services) zu erhalten. Unterstützung für ADLS erhalten Sie, indem Sie den ADLS-Speichertyp als Option auswählen. Vorhandene Cluster werden nicht automatisch auf diese Versionen aktualisiert.
Alle neuen Cluster, die nach Juni 2018 erstellt werden, erhalten automatisch diese mehr als 1000 Fehlerbehebungen für alle Open-Source-Projekte. Befolgen Sie diesen Leitfaden, um die bewährten Methoden zum Upgrade auf eine neuere HDInsight-Version zu verwenden.