Konfigurieren von Speicher und Skalierbarkeit für Apache Kafka in HDInsight
Erfahren Sie, wie Sie die Anzahl der von Apache Kafka in HDInsight verwendeten verwalteten Datenträgern konfigurieren.
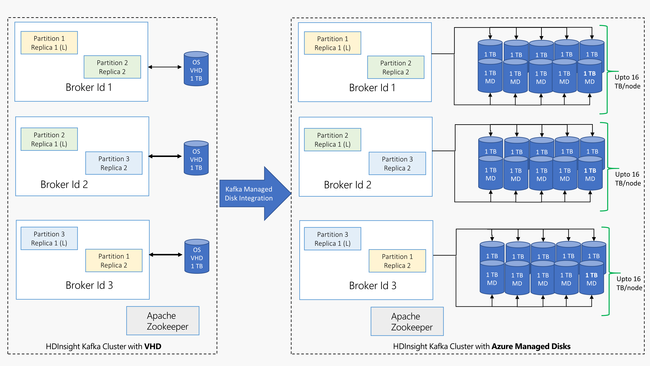
Kafka in HDInsight verwendet den lokalen Datenträger der virtuellen Computer im HDInsight-Cluster. Da Kafka sehr E/A-intensiv ist, wird Azure Managed Disks verwendet, um einen hohen Durchsatz zu ermöglichen und mehr Speicher pro Knoten bereitzustellen. Wenn herkömmliche virtuelle Festplatten (VHD) für Kafka verwendet werden, ist jeder Knoten auf 1 TB beschränkt. Mit verwalteten Datenträgern können Sie mehrere Datenträger verwenden, um für jeden Knoten im Cluster 16 TB zu erzielen.
Das folgende Diagramm zeigt einen Vergleich zwischen Kafka in HDInsight vor verwalteten Datenträgern und Kafka in HDInsight mit verwalteten Datenträgern:
Konfigurieren von verwalteten Datenträgern: Azure-Portal
Führen Sie die Schritte unter Erstellen eines HDInsight-Clusters aus, um die übliche Vorgehensweise zum Erstellen eines Clusters mit dem Portal zu verstehen. Führen Sie den Vorgang zum Erstellen eines Portals nicht aus.
Verwenden Sie im Abschnitt Konfiguration und Preise das Feld Knotenanzahl, um die Anzahl der Datenträger zu konfigurieren.
Hinweis
Der Typ des verwalteten Datenträgers kann entweder Standard (HDD) oder Premium (SSD) sein. Premium-Datenträger werden mit virtuellen Computern der DS- und GS-Serie verwendet. Alle anderen virtuellen Computertypen verwenden den Standardtyp.

Konfigurieren von verwalteten Datenträgern: Resource Manager-Vorlage
Um die Anzahl der von den Workerknoten in einem Kafka-Cluster verwendeten Datenträger zu steuern, verwenden Sie den folgenden Abschnitt der Vorlage:
"dataDisksGroups": [
{
"disksPerNode": "[variables('disksPerWorkerNode')]"
}
],
Nächste Schritte
Weitere Informationen zur Verwendung von Apache Kafka in HDInsight finden Sie in den folgenden Dokumenten: