Verwenden Sie Apache Spark MLlib zum Erstellen einer Machine Learning-Anwendung und zur Analyse eines Datasets.
Erfahren Sie, wie Sie Apache Spark MLlib verwenden, um eine Machine Learning-Anwendung zu erstellen. Die Anwendung führt eine Vorhersageanalyse für ein geöffnetes Dataset durch. Aus den in Spark-integrierten Machine Learning-Bibliotheken verwendet dieses Beispiel die Klassifizierung durch logistische Regression.
MLlib ist eine Spark-Kernbibliothek, die viele nützliche Hilfsprogramme für Aufgaben aus dem Bereich des maschinellen Lernens enthält, beispielsweise:
- Klassifizierung
- Regression
- Clustering
- Modellierung
- Singulärwertzerlegung (Singular Value Decomposition, SVD) und Hauptkomponentenanalyse (Principal Component Analysis, PCA)
- Testen von Hypothesen und Berechnen von Beispielstatistiken
Grundlegendes zu Klassifizierung und logistischer Regression
Klassifizierung, eine Aufgabe im Bereich des Machine Learning, ist der Prozess, bei dem Eingabedaten in Kategorien sortiert werden. Der Klassifizierungsalgorithmus hat die Aufgabe herauszufinden, wie „Bezeichnungen“ den bereitgestellten Eingabedaten zugewiesen werden. Gehen Sie als Beispiel von einem Algorithmus mit maschinellem Lernen aus, der Aktieninformationen als Eingabe akzeptiert. Anschließend dividiert er den Kurs in zwei Kategorien: Aktien, die Sie verkaufen sollten, und Aktien, die Sie behalten sollten.
Logistische Regression ist der Algorithmus, den Sie für die Klassifizierung verwenden. Die API für die logistische Regression von Spark ist nützlich für eine binäre Klassifizierungoder für die Klassifizierung der Eingabedaten in einer von zwei Gruppen. Weitere Informationen zur logistischen Regression finden Sie in Wikipedia.
Zusammenfassend führt der Prozess der logistischen Regression zu einer logistischen Funktion. Verwenden Sie diese Funktion, um die Wahrscheinlichkeit vorherzusagen, dass ein Eingabevektor zu der einen oder der anderen Gruppe gehört.
Beispiel für Vorhersageanalysen für Lebensmittelkontrolldaten
In diesem Beispiel führen Sie mit Spark einige Vorhersageanalysen für Lebensmittelinspektionsdaten (Food_Inspections1.csv) durch. Die Daten wurden über das Datenportals der Stadt Chicago abgerufen. Dieses Dataset enthält Informationen zu Inspektionen bei Lebensmitteleinrichtungen, die in Chicago durchgeführt wurden. Dazu gehören Informationen zu den einzelnen Einrichtungen, die gefundenen Verstöße (sofern vorhanden) und die Ergebnisse der Überprüfung. Die CSV-Datendatei ist bereits im Speicherkonto verfügbar, das dem Cluster in /HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv zugeordnet ist.
In den folgenden Schritten entwickeln Sie ein Modell, um zu ermitteln, wie Sie eine Lebensmittelkontrolle erfolgreich bestehen können bzw. wann Sie nicht bestehen.
Erstellen einer Apache Spark-MLlib-Machine Learning-App
Erstellen Sie eine Jupyter Notebook-Instanz mit dem PySpark-Kernel. Anweisungen hierzu finden Sie unter Erstellen einer Jupyter Notebook-Datei.
Importieren Sie die Typen, die für diese Anwendung benötigt werden. Kopieren Sie den folgenden Code, fügen Sie ihn in eine leere Zelle ein, und drücken Sie UMSCHALT+EINGABE.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row from pyspark.sql.functions import UserDefinedFunction from pyspark.sql.types import *Durch den PySpark-Kernel müssen Sie keine Kontexte explizit erstellen. Die Spark- und Hive-Kontexte werden automatisch erstellt, wenn Sie die erste Codezelle ausführen.
Erstellen des Eingabedatenrahmens
Verwenden Sie den Spark-Kontext, um die unstrukturierten CSV-Daten als unstrukturierten Text in den Arbeitsspeicher abzurufen. Verwenden Sie dann die Python-CSV-Bibliothek, um jede Zeile der Daten zu analysieren.
Führen Sie die folgenden Zeilen aus, um ein Resilient Distributed Dataset (RDD) zu erstellen, indem Sie die Eingabedaten importieren und analysieren.
def csvParse(s): import csv from io import StringIO sio = StringIO(s) value = next(csv.reader(sio)) sio.close() return value inspections = sc.textFile('/HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections1.csv')\ .map(csvParse)Führen Sie den folgenden Code aus, um eine Zeile aus dem RDD abzurufen, damit Sie sich das Datenschema ansehen können:
inspections.take(1)Die Ausgabe ist:
[['413707', 'LUNA PARK INC', 'LUNA PARK DAY CARE', '2049789', "Children's Services Facility", 'Risk 1 (High)', '3250 W FOSTER AVE ', 'CHICAGO', 'IL', '60625', '09/21/2010', 'License-Task Force', 'Fail', '24. DISH WASHING FACILITIES: PROPERLY DESIGNED, CONSTRUCTED, MAINTAINED, INSTALLED, LOCATED AND OPERATED - Comments: All dishwashing machines must be of a type that complies with all requirements of the plumbing section of the Municipal Code of Chicago and Rules and Regulation of the Board of Health. OBSEVERD THE 3 COMPARTMENT SINK BACKING UP INTO THE 1ST AND 2ND COMPARTMENT WITH CLEAR WATER AND SLOWLY DRAINING OUT. INST NEED HAVE IT REPAIR. CITATION ISSUED, SERIOUS VIOLATION 7-38-030 H000062369-10 COURT DATE 10-28-10 TIME 1 P.M. ROOM 107 400 W. SURPERIOR. | 36. LIGHTING: REQUIRED MINIMUM FOOT-CANDLES OF LIGHT PROVIDED, FIXTURES SHIELDED - Comments: Shielding to protect against broken glass falling into food shall be provided for all artificial lighting sources in preparation, service, and display facilities. LIGHT SHIELD ARE MISSING UNDER HOOD OF COOKING EQUIPMENT AND NEED TO REPLACE LIGHT UNDER UNIT. 4 LIGHTS ARE OUT IN THE REAR CHILDREN AREA,IN THE KINDERGARDEN CLASS ROOM. 2 LIGHT ARE OUT EAST REAR, LIGHT FRONT WEST ROOM. NEED TO REPLACE ALL LIGHT THAT ARE NOT WORKING. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. MISSING CEILING TILES WITH STAINS IN WEST,EAST, IN FRONT AREA WEST, AND BY THE 15MOS AREA. NEED TO BE REPLACED. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. SPLASH GUARDED ARE NEEDED BY THE EXPOSED HAND SINK IN THE KITCHEN AREA | 34. FLOORS: CONSTRUCTED PER CODE, CLEANED, GOOD REPAIR, COVING INSTALLED, DUST-LESS CLEANING METHODS USED - Comments: The floors shall be constructed per code, be smooth and easily cleaned, and be kept clean and in good repair. INST NEED TO ELEVATE ALL FOOD ITEMS 6INCH OFF THE FLOOR 6 INCH AWAY FORM WALL. ', '41.97583445690982', '-87.7107455232781', '(41.97583445690982, -87.7107455232781)']]Die Ausgabe gewährt Ihnen einen Einblick in das Schema der Eingabedatei. Sie enthält den Namen und den Typ jeder Einrichtung sowie u. a. die Adresse, die Daten zu den Inspektionen und den Standort.
Führen Sie den folgenden Code aus, um einen Datenrahmen (df) und eine temporäre Tabelle (CountResults) mit einigen Spalten zu erstellen, die für Vorhersageanalysen geeignet sind.
sqlContextwird verwendet, um strukturierte Daten zu transformieren.schema = StructType([ StructField("id", IntegerType(), False), StructField("name", StringType(), False), StructField("results", StringType(), False), StructField("violations", StringType(), True)]) df = spark.createDataFrame(inspections.map(lambda l: (int(l[0]), l[1], l[12], l[13])) , schema) df.registerTempTable('CountResults')Die vier relevanten Spalten im Datenrahmen sind ID, name, results und violations.
Führen Sie den folgenden Code aus, um eine kleine Stichprobe der Daten abzurufen:
df.show(5)Die Ausgabe ist:
+------+--------------------+-------+--------------------+ | id| name|results| violations| +------+--------------------+-------+--------------------+ |413707| LUNA PARK INC| Fail|24. DISH WASHING ...| |391234| CAFE SELMARIE| Fail|2. FACILITIES TO ...| |413751| MANCHU WOK| Pass|33. FOOD AND NON-...| |413708|BENCHMARK HOSPITA...| Pass| | |413722| JJ BURGER| Pass| | +------+--------------------+-------+--------------------+
Grundlegendes zu den Daten
Verschaffen Sie sich zunächst einen Überblick darüber, was in dem Dataset enthalten ist.
Führen Sie den folgenden Code aus, um die unterschiedlichen Werte in der Spalte results anzuzeigen:
df.select('results').distinct().show()Die Ausgabe ist:
+--------------------+ | results| +--------------------+ | Fail| |Business Not Located| | Pass| | Pass w/ Conditions| | Out of Business| +--------------------+Führen Sie den folgenden Code aus, um die Verteilung der Ergebnisse zu visualisieren:
%%sql -o countResultsdf SELECT COUNT(results) AS cnt, results FROM CountResults GROUP BY resultsDurch den Befehl
%%sqlgefolgt von-o countResultsdfwird sichergestellt, dass die Ausgabe der Abfrage lokal auf dem Jupyter-Server (in der Regel der Hauptknoten des Clusters) beibehalten wird. Die Ausgabe wird als Pandas -Dataframe mit dem angegebenen Namen countResultsdfbeibehalten. Weitere Informationen zum%%sql-Magic-Befehl sowie anderen für den PySpark-Kernel verfügbaren Magic-Befehlen finden Sie unter Kernel für Jupyter Notebook in Apache Spark-Clustern in Azure HDInsight.Die Ausgabe lautet:
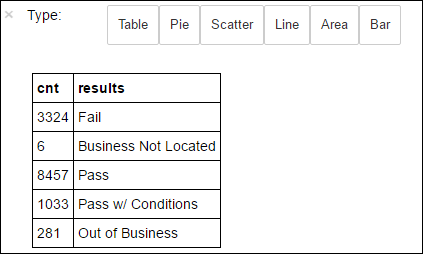
Sie können auch Matplotlib verwenden, eine Bibliothek zur Visualisierung von Daten, um eine Grafik zu erstellen. Da die Grafik aus dem lokal gespeicherten countResultsdf-Dataframe erstellt werden muss, muss der Codeausschnitt mit der
%%local-Magic beginnen. Durch diese Aktion wird sichergestellt, dass der Code lokal auf dem Jupyter-Server ausgeführt wird.%%local %matplotlib inline import matplotlib.pyplot as plt labels = countResultsdf['results'] sizes = countResultsdf['cnt'] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Um das Ergebnis einer Lebensmittelkontrolle vorherzusagen, müssen Sie ein Modell basierend auf den Verstößen entwickeln. Da die logistische Regression eine binäre Klassifizierungsmethode ist, können Sie die Ergebnisdaten in zwei Kategorien gruppieren: Fail und Pass:
Pass
- Pass
- Pass w/ Conditions
Fehler
- Fehler
Verwerfen
- Business not located
- Out of Business
Daten mit den anderen Ergebnissen („Business Not Located“ oder „Out of Business“) sind nicht nützlich und machen auch nur einen geringen Anteil der Ergebnisse aus.
Führen Sie den folgenden Code aus, um den bestehenden Datenrahmen (
df) in einen neuen Datenrahmen zu konvertieren, wobei jede Kontrolle als Label-Violations-Paar dargestellt wird. In diesem Fall stellt die Bezeichnung0.0ein Nichtbestehen dar, die Bezeichnung1.0steht für das Bestehen der Kontrolle, und die Bezeichnung-1.0steht für andere Ergebnisse.def labelForResults(s): if s == 'Fail': return 0.0 elif s == 'Pass w/ Conditions' or s == 'Pass': return 1.0 else: return -1.0 label = UserDefinedFunction(labelForResults, DoubleType()) labeledData = df.select(label(df.results).alias('label'), df.violations).where('label >= 0')Führen Sie den folgenden Code aus, um eine Zeile von Daten mit Label anzuzeigen:
labeledData.take(1)Die Ausgabe ist:
[Row(label=0.0, violations=u"41. PREMISES MAINTAINED FREE OF LITTER, UNNECESSARY ARTICLES, CLEANING EQUIPMENT PROPERLY STORED - Comments: All parts of the food establishment and all parts of the property used in connection with the operation of the establishment shall be kept neat and clean and should not produce any offensive odors. REMOVE MATTRESS FROM SMALL DUMPSTER. | 35. WALLS, CEILINGS, ATTACHED EQUIPMENT CONSTRUCTED PER CODE: GOOD REPAIR, SURFACES CLEAN AND DUST-LESS CLEANING METHODS - Comments: The walls and ceilings shall be in good repair and easily cleaned. REPAIR MISALIGNED DOORS AND DOOR NEAR ELEVATOR. DETAIL CLEAN BLACK MOLD LIKE SUBSTANCE FROM WALLS BY BOTH DISH MACHINES. REPAIR OR REMOVE BASEBOARD UNDER DISH MACHINE (LEFT REAR KITCHEN). SEAL ALL GAPS. REPLACE MILK CRATES USED IN WALK IN COOLERS AND STORAGE AREAS WITH PROPER SHELVING AT LEAST 6' OFF THE FLOOR. | 38. VENTILATION: ROOMS AND EQUIPMENT VENTED AS REQUIRED: PLUMBING: INSTALLED AND MAINTAINED - Comments: The flow of air discharged from kitchen fans shall always be through a duct to a point above the roofline. REPAIR BROKEN VENTILATION IN MEN'S AND WOMEN'S WASHROOMS NEXT TO DINING AREA. | 32. FOOD AND NON-FOOD CONTACT SURFACES PROPERLY DESIGNED, CONSTRUCTED AND MAINTAINED - Comments: All food and non-food contact equipment and utensils shall be smooth, easily cleanable, and durable, and shall be in good repair. REPAIR DAMAGED PLUG ON LEFT SIDE OF 2 COMPARTMENT SINK. REPAIR SELF CLOSER ON BOTTOM LEFT DOOR OF 4 DOOR PREP UNIT NEXT TO OFFICE.")]
Erstellen eines logistischen Regressionsmodells anhand des Eingabedataframes
Die letzte Aufgabe besteht darin, die bezeichneten Daten zu konvertieren. Konvertieren Sie die Daten in ein Format, das mit der logistischen Regression analysiert wird. Die Eingabe für einen Algorithmus für logistische Regression muss aus einem Satz von Label-Feature-Vektorpaaren bestehen. Dabei ist der „Funktionsvektor“ ein Vektor von Zahlen, die den Eingabepunkt darstellen. Daher benötigen Sie eine Möglichkeit, die Spalte „violations“ zu konvertieren, die nur teilweise strukturiert ist und viele Freitextkommentare enthält. Konvertieren Sie die Spalte in ein Array reeller Zahlen, die ein Computer einfach verstehen kann.
Ein Standardansatz des maschinellen Lernens für die Verarbeitung natürlicher Sprache besteht darin, jedem eindeutigen Wort einen Index zuzuweisen. Dieser Vektor wird dann an den Algorithmus für das maschinelle Lernen übergeben. Jeder Indexwert weist dabei die relative Häufigkeit dieses Worts in der Textzeichenfolge auf.
MLlib bietet eine einfache Möglichkeit zum Durchführen dieses Vorgangs. Zunächst wird jeder Verstoßzeichenfolge ein Token zugewiesen, um die einzelnen Wörter in jeder Zeichenfolge abzurufen. Verwenden Sie dann eine HashingTF, um jeden Satz von Token in einen Funktionsvektor zu konvertieren, der dann an den logistischen Regressionsalgorithmus übergeben werden kann, um ein Modell zu erstellen. Sie müssen alle diese Schritte der Reihe nach über eine Pipeline durchführen.
tokenizer = Tokenizer(inputCol="violations", outputCol="words")
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
model = pipeline.fit(labeledData)
Auswerten des Modells mit einem anderen Dataset
Mithilfe des zuvor erstellten Modells können Sie die Ergebnisse der neuen Inspektionen vorhersagen. Die Vorhersagen basieren auf den beobachteten Verstößen. Sie haben dieses Modell mit dem Dataset Food_Inspections1.csv trainiert. Sie können nun ein zweites Dataset, Food_Inspections2.csv, verwenden, um die Stärke dieses Modells für die neuen Daten auszuwerten. Dieses zweite Dataset (Food_Inspections2.csv) befindet sich bereits im Standardspeichercontainer, der dem Cluster zugeordnet ist.
Führen Sie den folgenden Code aus, um einen neuen Datenrahmen, predictionsDf, zu erstellen, der die vom Modell generierte Vorhersage enthält. Der Codeausschnitt erstellt basierend auf dem Dataframe ebenfalls eine temporäre Tabelle namens Predictions.
testData = sc.textFile('wasbs:///HdiSamples/HdiSamples/FoodInspectionData/Food_Inspections2.csv')\ .map(csvParse) \ .map(lambda l: (int(l[0]), l[1], l[12], l[13])) testDf = spark.createDataFrame(testData, schema).where("results = 'Fail' OR results = 'Pass' OR results = 'Pass w/ Conditions'") predictionsDf = model.transform(testDf) predictionsDf.registerTempTable('Predictions') predictionsDf.columnsDie Ausgabe sollte wie der folgende Text aussehen:
['id', 'name', 'results', 'violations', 'words', 'features', 'rawPrediction', 'probability', 'prediction']Betrachten Sie eine der Vorhersagen. Führen Sie diesen Codeausschnitt aus:
predictionsDf.take(1)Sie sehen die Vorhersage für den ersten Eintrag im Testdataset.
Die
model.transform()-Methode wendet dieselbe Transformation auf alle neuen Daten mit dem gleichen Schema an und erhält eine Vorhersage, wie die Daten klassifiziert werden können. Mit einigen Statistikvorgängen gewinnen Sie einen Eindruck von den Vorhersagen:numSuccesses = predictionsDf.where("""(prediction = 0 AND results = 'Fail') OR (prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions'))""").count() numInspections = predictionsDf.count() print ("There were", numInspections, "inspections and there were", numSuccesses, "successful predictions") print ("This is a", str((float(numSuccesses) / float(numInspections)) * 100) + "%", "success rate")Die Ausgabe sieht in etwa wie folgt aus:
There were 9315 inspections and there were 8087 successful predictions This is a 86.8169618894% success rateDurch die Verwendung der logistischen Regression mit Spark erhalten Sie ein Modell der Beziehung zwischen den Verletzungen mit Beschreibungen in englischer Sprache. Außerdem können Sie erkennen, ob ein bestimmtes Unternehmen eine Lebensmittelinspektion bestehen würde.
Erstellen einer visuellen Darstellung der Vorhersage
Nun können Sie eine endgültige Visualisierung erstellen, um sich mit den Ergebnissen dieses Tests auseinanderzusetzen.
Beginnen Sie mit dem Extrahieren der unterschiedlichen Vorhersagen und Ergebnisse aus der zuvor erstellten temporären Tabelle Predictions. Die folgenden Abfragen teilt die Ausgabe in true_positive, false_positive, true_negative, und false_negative auf. In den folgenden Abfragen deaktivieren Sie die Visualisierung mithilfe von
-qund speichern auch die Ausgabe (mithilfe von-o) als Datenrahmen, die dann mit der%%local-Magic verwendet werden können.%%sql -q -o true_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND results = 'Fail'%%sql -q -o false_positive SELECT count(*) AS cnt FROM Predictions WHERE prediction = 0 AND (results = 'Pass' OR results = 'Pass w/ Conditions')%%sql -q -o true_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND results = 'Fail'%%sql -q -o false_negative SELECT count(*) AS cnt FROM Predictions WHERE prediction = 1 AND (results = 'Pass' OR results = 'Pass w/ Conditions')Abschließend verwenden Sie den folgenden Ausschnitt, um die Grafik mithilfe von Matplotlibzu generieren.
%%local %matplotlib inline import matplotlib.pyplot as plt labels = ['True positive', 'False positive', 'True negative', 'False negative'] sizes = [true_positive['cnt'], false_positive['cnt'], false_negative['cnt'], true_negative['cnt']] colors = ['turquoise', 'seagreen', 'mediumslateblue', 'palegreen', 'coral'] plt.pie(sizes, labels=labels, autopct='%1.1f%%', colors=colors) plt.axis('equal')Die folgende Ausgabe wird angezeigt.

In diesem Diagramm bezieht sich ein „positives“ Ergebnis auf eine nicht bestandene Lebensmittelkontrolle, wohingegen sich ein negatives Ergebnis auf eine bestandene Kontrolle bezieht.
Herunterfahren des Notebooks
Nach dem Ausführen der Anwendung empfiehlt es sich, das Notebook herunterzufahren, um die Ressourcen freizugeben. Wählen Sie hierzu im Menü Datei des Notebooks die Option Schließen und Anhalten aus. Mit dieser Aktion wird das Notebook heruntergefahren und geschlossen.