Tutorial: End-to-End-Lösung mit Azure Machine Learning und IoT Edge
Gilt für:![]() IoT Edge 1.1
IoT Edge 1.1
Wichtig
IoT Edge 1.1: Datum für das Supportende war der 13. Dezember 2022. Informationen zur Unterstützung für dieses Produkt, diesen Dienst, diese Technologie oder diese API finden Sie in der Microsoft Lifecycle-Richtlinie. Weitere Informationen zum Aktualisieren auf die neueste Version von IoT Edge finden Sie unter Update IoT Edge.
Bei IoT-Anwendungen ist häufig die Nutzung der intelligenten Cloud sowie von Intelligent Edge wünschenswert. In diesem Tutorial erfahren Sie Schritt für Schritt, wie Sie ein Machine Learning-Modell mit Daten trainieren, die von IoT-Geräten in der Cloud gesammelt wurden, wie Sie dieses Modell in IoT Edge bereitstellen und wie Sie das Modell pflegen und regelmäßig optimieren.
Hinweis
Die Konzepte in diesen Tutorials gelten für alle Versionen von IoT Edge. Auf dem Beispielgerät, das Sie zum Ausprobieren des Szenarios erstellen, wird jedoch Version 1.1. von IoT Edge ausgeführt.
Dieses Tutorial ist in erster Linie als Einführung in die Verarbeitung von IoT-Daten mit maschinellem Lernen (insbesondere im Edgebereich) gedacht. Es werden zwar auch zahlreiche andere Aspekte eines allgemeinen Machine Learning-Workflows angesprochen, bei diesem Tutorial handelt es sich jedoch nicht um eine detaillierte Einführung in maschinelles Lernen. In diesem Fall versuchen wir nicht, ein hochoptimiertes Modell für den Anwendungsfall zu erstellen– wir tun einfach genug, um den Prozess der Erstellung und Verwendung eines praktikablen Modells für die IoT-Datenverarbeitung zu veranschaulichen.
In diesem Abschnitt des Tutorials wird Folgendes behandelt:
- Die Voraussetzungen für die Ausführung der nachfolgenden Teile des Tutorials
- Die Zielgruppe des Tutorials
- Der Anwendungsfall, der im Tutorial simuliert wird
- Der gesamte Prozess, der im Tutorial ausgeführt wird, um den Anwendungsfall zu erfüllen
Wenn Sie kein Azure-Abonnement besitzen, erstellen Sie ein kostenloses Konto, bevor Sie beginnen.
Voraussetzungen
Für dieses Tutorial benötigen Sie Zugriff auf ein Azure-Abonnement, in dem Sie zum Erstellen von Ressourcen berechtigt sind. Für einige der in diesem Tutorial verwendeten Dienste fallen Azure-Gebühren an. Falls Sie noch kein Azure-Abonnement besitzen, können Sie für den Einstieg ggf. ein kostenloses Azure-Konto erstellen.
Darüber hinaus benötigen Sie einen Computer mit einer PowerShell-Installation, auf dem Sie Skripts ausführen können, um einen virtuellen Computer als Entwicklungscomputer einzurichten.
In diesem Dokument werden folgende Tools verwendet:
Eine Azure IoT Hub-Instanz für die Datenerfassung
Azure Notebooks als primäres Front-End für die Datenvorbereitung und die Machine Learning-Experimente. Die Ausführung von Python-Code in einem Notebook für eine Teilmenge der Beispieldaten ermöglicht eine schnelle iterative und interaktive Verarbeitung bei der Datenvorbereitung. Jupyter-Notebooks können auch zur Vorbereitung von Skripts für die skalierbare Ausführung in einem Compute-Back-End verwendet werden.
Azure Machine Learning als Back-End für skalierbares maschinelles Lernen sowie für die Generierung von Machine Learning-Images. Das Azure Machine Learning-Back-End wird mithilfe von Skripts gesteuert, die in Jupyter-Notebooks vorbereitet und getestet wurden.
Azure IoT Edge zum Anwenden eines Machine Learning-Images abseits der Cloud
Selbstverständlich stehen auch noch andere Optionen zur Verfügung. In bestimmten Szenarien kann beispielsweise IoT Central als codelose Alternative verwendet werden, um erste Trainingsdaten von IoT-Geräten zu erfassen.
Zielgruppe und Rollen
Diese Artikelreihe ist für Entwickler ohne Vorkenntnisse in den Bereichen IoT-Entwicklung oder maschinelles Lernen konzipiert. Entwickler, die maschinelles Lernen im Edgebereich bereitstellen möchten, müssen in der Lage sein, ein breites Spektrum an Technologien miteinander zu verknüpfen. In diesem Tutorial wird daher anhand eines vollständigen End-to-End-Szenarios eine der möglichen Vorgehensweisen behandelt, mit denen diese Technologien für eine IoT-Lösung genutzt werden können. In der Praxis werden diese Aufgaben ggf. von unterschiedlichen Spezialisten ausgeführt. So kümmern sich Entwickler beispielsweise in der Regel um Geräte- oder Cloudcode, während sich Data Scientists auf die Erstellung der Analysemodelle konzentrieren. Damit dieses Tutorial von einem einzelnen Entwickler absolviert werden kann, haben wir zusätzliche Anleitungen mit Einblicken und Links zu weiteren Informationen bereitgestellt, um die Vorgehensweise an sich sowie deren Hintergründe zu erläutern.
Alternativ können Sie sich auch mit Kollegen aus verschiedenen Bereichen zusammentun und das Tutorial gemeinsam bearbeiten. Dabei können Sie Ihr geballtes Fachwissen einbringen und sich im Team mit den Zusammenhängen vertraut machen.
Als Orientierungshilfe für den oder die Leser ist bei allen Artikeln jeweils die Rolle des Benutzers angegeben. Folgende Rollen werden verwendet:
- Cloudentwicklung (einschließlich eines Cloudentwicklers in einer DevOps-Kapazität)
- Datenanalyse
Anwendungsfall: Predictive Maintenance
Dieses Szenario basiert auf einem Anwendungsfall, die auf der PHM08-Konferenz (Prognostics and Health Management 2008) vorgestellt wurde. Das Ziel besteht darin, die Restnutzungsdauer (Remaining Useful Life, RUL) einer Gruppe von Turbofan-Flugzeugtriebwerken zu prognostizieren. Die Daten wurden mithilfe von C-MAPSS – der kommerziellen Version der MAPSS-Software (Modular Aero-Propulsion System Simulation) – generiert. Diese Software bietet eine flexible Simulationsumgebung für Turbofan-Triebwerke, in der sich Integritäts-, Kontroll- und Triebwerksparameter komfortabel simulieren lassen.
Die in diesem Tutorial verwendeten Daten stammen aus dem Turbofan Engine Degradation Simulation Data Set.
Aus der Infodatei:
Experimentelles Szenario
Die Datasets bestehen aus mehreren multivariaten Zeitreihen. Jedes Dataset ist außerdem in Trainings- und Testbereiche unterteilt. Jede Zeitreihe stammt aus einer anderen Engine , d. h. die Daten stammen aus einer Flotte von Motoren desselben Typs. Bei den einzelnen Triebwerken wird jeweils von einem unterschiedlich hohen Anfangsverschleiß sowie von unterschiedlichen Fertigungsschwankungen ausgegangen, die dem Benutzer nicht bekannt sind. Verschleiß und Schwankungen dieser Art sind normal und gelten nicht als Fehlerbedingung. Es gibt drei Betriebseinstellungen, die sich erheblich auf die Triebwerksleistung auswirken. Diese Einstellungen sind ebenfalls in den Daten enthalten. Darüber hinaus enthalten die Daten Sensorstörungen.
Zu Beginn der jeweiligen Zeitreihe funktioniert das Triebwerk noch ordnungsgemäß. Im Laufe der Zeit tritt jedoch ein Problem auf. Im Trainingssatz nimmt das Problem immer größere Ausmaße an, bis es schließlich zu einem Systemausfall kommt. Im Testsatz endet die Zeitreihe einige Zeit vor dem Systemausfall. Das Ziel des Wettbewerbs besteht darin, die Anzahl der verbleibenden Betriebszyklen bis zum Ausfall im Testsatz zu prognostizieren (also die Anzahl von Betriebszyklen ab dem letzten Zyklus, in denen das Triebwerk noch funktioniert). Für die Testdaten wurde außerdem ein Vektor mit echten RUL-Werten (Remaining Useful Life, Restnutzungsdauer) bereitgestellt.
Da die Daten für einen Wettbewerb veröffentlicht wurden, wurden bereits verschiedene unabhängige Ansätze für die Ableitung von Machine Learning-Modellen veröffentlicht. Anhand von Beispielen können Sie sich mit dem Prozess und den Überlegungen im Zusammenhang mit der Erstellung eines spezifischen Machine Learning-Modells vertraut machen. Sehen Sie sich beispielsweise Folgendes an:
Aircraft engine failure prediction model von GitHub-Benutzer jancervenka.
Turbofan engine degradation von GitHub-Benutzer hankroark.
Prozess
Die folgende Abbildung zeigt die allgemeinen Schritte, die in diesem Tutorial ausgeführt werden:
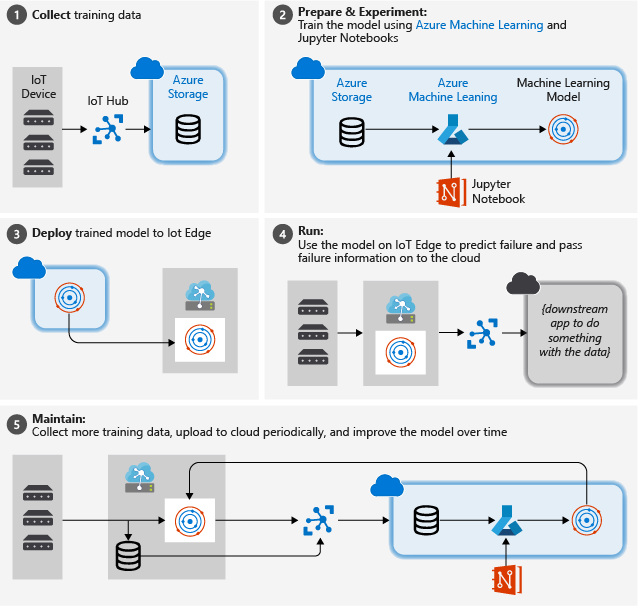
Sammeln von Trainingsdaten: Der Prozess beginnt mit dem Sammeln von Trainingsdaten. Manchmal wurden möglicherweise bereits Daten erfasst und stehen in einer Datenbank oder in Form von Datendateien zur Verfügung. In anderen Fällen (insbesondere in IoT-Szenarien) müssen die Daten von IoT-Geräten und Sensoren gesammelt und in der Cloud gespeichert werden.
Da wir davon ausgehen, dass Sie nicht über eine Sammlung von Turbofan-Triebwerken verfügen, enthalten die Projektdateien einen einfachen Gerätesimulator, der die NASA-Gerätedaten an die Cloud sendet.
Vorbereiten der Daten: In den meisten Fällen müssen die von Geräten und Sensoren gesammelten Rohdaten für das maschinelle Lernen aufbereitet werden. Dieser Schritt kann die Bereinigung, Neuformatierung oder Vorabverarbeitung der Daten umfassen, um zusätzliche Informationen hinzuzufügen, die für das maschinelle Lernen herangezogen werden können.
Bei unseren Flugzeugtriebwerkdaten umfasst die Datenvorbereitung die Berechnung der expliziten Dauer bis zum Ausfall für jeden Datenpunkt des Beispiels (auf der Grundlage der tatsächlichen Beobachtungen für die Daten). Anhand dieser Informationen kann der Machine Learning-Algorithmus Korrelationen zwischen tatsächlichen Sensordatenmustern und der voraussichtlichen Restlebensdauer des Triebwerks ermitteln. Dieser Schritt ist stark domänenspezifisch.
Erstellen eines Machine Learning-Modells: Auf der Grundlage der vorbereiteten Daten können wir nun mit anderen Machine Learning-Algorithmen und Parametrisierungen experimentieren, um Modelle zu trainieren und die Ergebnisse miteinander zu vergleichen.
In diesem Fall vergleichen wir zu Testzwecken das berechnete prognostizierte Ergebnis des Modells mit dem echten Ergebnis für eine Gruppe von Triebwerken. In Azure Machine Learning können wir die verschiedenen Iterationen der von uns erstellten Modelle in einer Modellregistrierung verwalten.
Bereitstellen des Modells: Wenn wir über ein Modell verfügen, das unsere Erfolgskriterien erfüllt, können wir zur Bereitstellung übergehen. Dazu muss das Modell in eine Webdienst-App verpackt werden, die über REST-Aufrufe mit Daten versorgt werden und Analyseergebnisse zurückgeben kann. Die Webdienst-App wird dann in einen Docker-Container verpackt, der wiederum in der Cloud oder als IoT Edge-Modul bereitgestellt werden kann. In diesem Beispiel konzentrieren wir uns auf die IoT Edge-Bereitstellung.
Pflegen und Optimieren des Modells: Die Bereitstellung ist nicht der letzte Schritt für unser Modell. In vielen Fällen empfiehlt es sich, weiter Daten zu sammeln und in regelmäßigen Abständen in die Cloud hochzuladen. Mithilfe dieser Daten können wir unser Modell dann neu trainieren, optimieren und erneut in IoT Edge bereitstellen.
Bereinigen von Ressourcen
Dieses Tutorial ist Teil einer Reihe, in der jeder Artikel auf den Schritten aufbaut, die jeweils im vorherigen Artikel ausgeführt wurden. Warten Sie mit dem Bereinigen von Ressourcen, bis Sie das letzte Tutorial abgeschlossen haben.
Nächste Schritte
Dieses Tutorial ist in folgende Abschnitte unterteilt:
- Einrichten Ihres Entwicklungscomputers und der Azure-Dienste
- Generieren der Trainingsdaten für das Machine Learning-Modul
- Trainieren und Bereitstellen des Machine Learning-Moduls
- Konfigurieren eines IoT Edge-Geräts als transparentes Gateway
- Erstellen und Bereitstellen von IoT Edge-Modulen
- Senden von Daten an Ihr IoT Edge-Gerät
Im nächsten Artikel erfahren Sie, wie Sie einen Entwicklungscomputer einrichten und Azure-Ressourcen bereitstellen.