Importieren von Trainingsdaten aus verschiedenen Datenquellen in Machine Learning Studio (klassisch)
GILT FÜR: Machine Learning Studio (Classic)
Machine Learning Studio (Classic)  Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
Um Ihre eigenen Daten in Machine Learning Studio (klassisch) zum Entwickeln und Trainieren einer Predictive Analytics-Lösung zu verwenden, können Sie Daten aus folgenden Quellen verwenden:
- Lokale Datei: Laden Sie lokale Daten von der Festplatte im Voraus, um damit ein Datasetmodul in Ihrem Arbeitsbereich zu erstellen.
- Onlinedatenquellen: Greifen Sie mithilfe des Moduls Daten importieren auf Daten aus einer von mehreren Onlinequellen zu, während Ihr Experiment ausgeführt wird.
- Machine Learning Studio-Experiment (klassisch): Verwenden Sie Daten, die als Dataset in Machine Learning Studio (klassisch) gespeichert wurden.
- SQL Server-Datenbank: Verwenden Sie Daten aus einer SQL Server-Datenbank, ohne Daten manuell kopieren zu müssen.
Hinweis
Es gibt eine Reihe von Beispiel-Datasets in Machine Learning Studio (klassisch), die Sie als Trainingsdaten verwenden können. Weitere Informationen finden Sie unter Verwenden von Beispieldatasets in Machine Learning Studio (klassisch).
Vorbereiten von Daten
Machine Learning Studio (klassisch) ist für die Nutzung von rechteckigen oder tabellarischen Daten vorgesehen, z. B. Textdaten, bei denen es sich um mit Trennzeichen versehene oder strukturierte Daten aus einer Datenbank handelt. Unter Umständen können nicht rechteckige Daten verwendet werden.
Ihre Daten sollten relativ problemfrei sein, bevor Sie sie in Studio (klassisch) importieren. Beispielsweise sollten Sie vermeiden, dass Zeichenfolgen nicht in Anführungszeichen eingeschlossen sind.
In Studio (klassisch) sind jedoch Module verfügbar, mit denen Sie nach dem Importieren Ihrer Daten bestimmte Änderungen an den Daten im Experiment vornehmen können. Abhängig vom verwendeten Machine Learning-Algorithmen müssen Sie möglicherweise entscheiden, wie Sie mit Datenstrukturproblemen wie fehlenden Werten und geringen Datenmengen umgehen möchten. Es gibt Module, die dabei helfen können. Suchen Sie im Abschnitt Data Transformation der Modulpalette nach Modulen, die diese Funktionen ausführen.
Zu jedem Zeitpunkt des Experiments können Sie die von einem Modul erstellten Daten anzeigen oder herunterladen, indem Sie auf den Ausgabeport klicken. Je nach Modul können verschiedene Downloadoptionen verfügbar sein, oder Sie können die Daten in Ihrem Webbrowser in Studio (klassisch) anzeigen.
Unterstützte Datenformate und Datentypen
Sie können eine Reihe von Datentypen in das Experiment importieren, je nachdem, welchen Mechanismus Sie zum Importieren von Daten verwenden und woher die Daten stammen:
- Nur-Text (.txt)
- Durch Trennzeichen getrennte Werte (CSV) mit einer Kopfzeile (.csv) oder ohne (.nh.csv)
- Durch Tabulator getrennte Werte (TSV) mit einer Kopfzeile (.tsv) oder ohne (.nh.tsv)
- Excel-Datei
- Azure-Tabelle
- Hive-Tabelle
- SQL-Datenbanktabelle
- OData-Werte
- SVMLight-Daten (.svmlight) (Formatinformationen finden Sie in der SVMLight-Definition (in englischer Sprache))
- ARFF-Daten (Attribute Relation File Format) (.arff) (Formatinformationen finden Sie in der ARFF-Definition (in englischer Sprache))
- ZIP-Datei (.zip)
- R-Objektdatei oder -Arbeitsbereichsdatei (.RData)
Wenn Sie Daten in einem Format wie z.B. ARFF importieren, das Metadaten enthält, verwendet Studio (klassisch) diese Metadaten, um die Kopfzeile und den Datentyp der einzelnen Spalten zu definieren.
Wenn Sie Daten im TSV- oder CSV-Format importieren, das diese Metadaten nicht enthält, leitet Studio (klassisch) den Datentyp für jede Spalte durch Entnahme von Datenstichproben ab. Wenn die Daten zudem keine Spaltenüberschriften aufweisen, legt Studio (klassisch) Standardnamen fest.
Sie können die Überschriften und Datentypen für Spalten mit dem Modul Edit Metadata (Metadaten bearbeiten) explizit angeben oder ändern.
Die folgenden Datentypen werden von Studio (klassisch) erkannt:
- String
- Integer
- Double
- Boolean
- Datetime
- TimeSpan
Von Studio wird ein interner Datentyp namens Datentabelle verwendet, um Daten zwischen Modulen zu übergeben. Mit dem Modul Convert to Dataset (In Dataset konvertieren) können Sie Daten explizit in das data table-Format konvertieren.
Jedes Modul, das andere Formate als data table akzeptiert, konvertiert die Daten im Hintergrund vor der Übergabe an das nächste Modul in das data table-Format.
Bei Bedarf können Sie das data table-Format mit anderen Konvertierungsmodulen wieder in die Formate CSV, TSV, ARFF oder SVMLight konvertieren. Suchen Sie im Abschnitt Data Format Conversions der Modulpalette nach Modulen, die diese Funktionen ausführen.
Datenkapazitäten
Module in Machine Learning Studio (klassisch) unterstützen in normalen Anwendungsfällen Datasets bis zu einer Größe von 10 GB an dichten numerischen Daten. Wenn ein Modul mehrere Eingaben akzeptiert, entspricht der Wert von 10 GB der Summe aller Eingabegrößen. Sie können Teile größerer Datasets übernehmen, indem Sie Abfragen aus Hive oder Azure SQL-Datenbank verwenden, oder Sie können die Vorverarbeitung per Lernen nach Anzahl vor dem Importieren der Daten nutzen.
Die folgenden Typen von Daten können während der Featurenormalisierung in größere Datasets erweitert werden und sind auf weniger als 10 GB beschränkt:
- Platzsparend
- Kategorisch
- Zeichenfolgen
- Binärdaten
Die folgenden Module sind auf Datasets mit einer Größe von unter 10 GB beschränkt:
- Empfohlene Module
- Modul „Synthetic Minority Oversampling Technique (SMOTE)“
- Skriptingmodule: R, Python, SQL
- Module, bei denen die Größe der Ausgabedaten die der Eingabedaten überschreiten kann, z.B. Join oder Feature-Hashing.
- Kreuzvalidierung, Tune Model Hyperparameters, Ordinal Regression und One-vs-All Multiclass, wenn eine sehr große Anzahl von Iterationen durchgeführt wird.
Laden Sie die Daten für Datasets, die größer als einige GB sind, in Azure Storage oder Azure SQL-Datenbank hoch, oder verwenden Sie Azure HDInsight, anstatt die Daten direkt aus einer lokalen Datei hochzuladen.
Informationen zu Bilddaten finden Sie in der Modulreferenz Import Images (Importieren von Bildern).
Importieren aus einer lokalen Datei
Sie können eine Datendatei von der Festplatte zur Verwendung als Trainingsdaten in Studio (klassisch) hochladen. Wenn Sie eine Datei importieren, erstellen Sie ein Datasetmodul, das direkt in Experimenten in Ihrem Arbeitsbereich verwendet werden kann.
Sie können wie folgt Daten von einer lokalen Festplatte importieren:
- Klicken Sie unten im Fenster von Studio (klassisch) auf +NEU.
- Wählen Sie DATASET und FROM LOCAL FILE aus.
- Navigieren Sie im Dialogfeld Upload a new dataset (Neues Dataset hochladen) zu der Datei, die Sie hochladen möchten.
- Geben Sie einen Namen ein, identifizieren Sie den Datentyp, und geben Sie optional eine Beschreibung ein. Eine Beschreibung wird empfohlen: Damit können Sie beliebige Merkmale der Daten erfassen, die Sie bei zukünftiger Nutzung der Daten berücksichtigen möchten.
- Mit dem Kontrollkästchen This is the new version of an existing dataset können Sie ein vorhandenes Dataset mit neuen Daten aktualisieren. Aktivieren Sie dazu dieses Kontrollkästchen, und geben Sie dann den Namen eines vorhandenen Datasets ein.
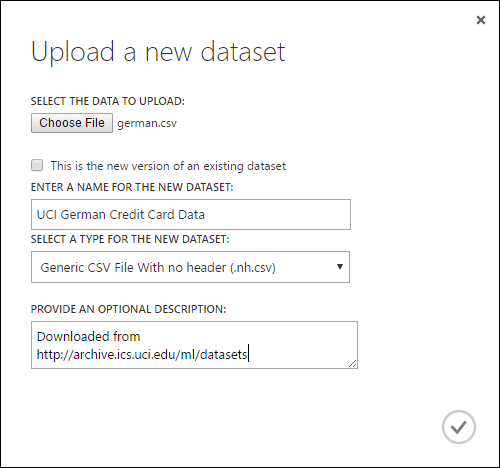
Die Dauer für das Hochladen hängt von der Größe Ihrer Daten und der Geschwindigkeit der Verbindung mit dem Dienst ab. Wenn Sie wissen, dass das Hochladen der Datei eine lange Zeit dauern kann, können Sie andere Dinge in Studio (klassisch) erledigen, während Sie warten. Wenn Sie den Browser jedoch vor Abschluss des Datenuploads schließen, tritt beim Hochladen ein Fehler auf.
Sobald Ihre Daten hochgeladen wurden, werden sie in einem Datasetmodul gespeichert und stehen für alle Experimente im Arbeitsbereich zur Verfügung.
Wenn Sie ein Experiment bearbeiten, finden Sie die hochgeladenen Datasets in der Modulpalette unter der Liste Gespeicherte Datasets in der Liste Meine Datasets. Sie können das Dataset in den Experimentbereich ziehen und dort ablegen, wenn Sie es für weitere Analysen und maschinelles Lernen verwenden möchten.
Importieren von Onlinedatenquellen
Mit dem Modul Import Data kann Ihr Experiment Daten aus verschiedenen Onlinedatenquellen importieren, während es ausgeführt wird.
Hinweis
Dieser Artikel bietet allgemeine Informationen zum Modul Import Data. Ausführlichere Informationen zu den Datentypen, auf die Sie zugreifen können, zu Formaten, Parametern und Antworten auf häufig gestellte Fragen finden Sie im Modulreferenzthema zum Modul Import Data.
Über das Modul Import Data können Sie auf Daten aus einer von mehreren Onlinedatenquellen zugreifen, während Ihr Experiment ausgeführt wird:
- Web-URL über HTTP
- Hadoop über HiveQL
- Azure Blob Storage
- Azure-Tabelle
- Azure SQL-Datenbank. SQL Managed Instance oder SQL Server
- Datenfeedanbieter (derzeit OData)
- Azure Cosmos DB
Da auf diese Trainingsdaten zugegriffen wird, während das Experiment ausgeführt wird, stehen sie nur in diesem Experiment zur Verfügung. Im Vergleich dazu stehen Daten, die in Datasetmodulen gespeichert sind, allen Experimenten in Ihrem Arbeitsbereich zur Verfügung.
Um in Ihrem (klassischen) Studio-Experiment auf Onlinedatenquellen zuzugreifen, fügen Sie dem Experiment das Modul Import Data hinzu. Wählen Sie dann Launch Import Data Wizard (Datenimport-Assistenten starten) unter Eigenschaften aus, um eine ausführliche Anleitung zum Auswählen und Konfigurieren der Datenquelle zu erhalten. Alternativ können Sie Datenquelle unter Eigenschaften manuell auswählen und die erforderlichen Parameter für den Datenzugriff angeben.
In der folgenden Tabelle werden die unterstützten Onlinedatenquellen beschrieben. Diese Tabelle enthält auch die unterstützten Dateiformate und die Parameter für den Zugriff auf die Daten.
Wichtig
Derzeit können die Module Import Data und Export Data Daten nur in Azure-Speicher lesen und schreiben, der mit dem klassischen Bereitstellungsmodell erstellt wurde. Das heißt, dass der neue Azure Blob Storage-Kontotyp, der eine „heiße“ oder „kalte“ Speicherzugriffsebene bietet, noch nicht unterstützt wird.
Im Allgemeinen sollten Azure-Speicherkonten, die Sie ggf. erstellt haben, bevor diese Dienstoption verfügbar war, nicht betroffen sein. Wenn Sie ein neues Konto erstellen müssen, wählen Sie Klassisch als Bereitstellungsmodell, oder verwenden Sie Resource Manager, und wählen Sie für Kontoart die Option Allgemein anstelle von Blobspeicher.
Weitere Informationen finden Sie unter Azure Blob Storage: „Heiße“ und „kalte“ Speicherebenen.
Unterstützte Onlinedatenquellen
Das Import Data-Modul von Machine Learning Studio (klassisch) unterstützt die folgenden Datenquellen:
| Data source | BESCHREIBUNG | Parameter |
|---|---|---|
| Web URL via HTTP | Liest Daten im CSV-Format (mit Trennzeichen getrennte Werte), im TSV-Format (mit Tabulatoren getrennte Werte), im ARFF-Format (Attribute-Relation File Format) und SVM-light-Format (Support Vector Machines) aus allen Web-URLs, die HTTP verwenden. | URL: Gibt den vollständigen Namen der Datei (einschließlich Website-URL und Dateiname) mit beliebiger Erweiterung an. Datenformat: Gibt eines der unterstützten Datenformate an: CSV, TSV, ARFF oder SVM-light. Wenn die Daten eine Kopfzeile haben, wird sie für das Zuweisen von Spaltennamen verwendet. |
| Hadoop/HDFS | Liest Daten aus verteiltem Speicher in Hadoop. Sie geben die gewünschten Daten an, indem Sie HiveQL, eine SQL-ähnliche Abfragesprache, verwenden. HiveQL kann auch für die Aggregation von Daten und die Datenfilterung verwendet werden, bevor Sie die Daten in Studio (klassisch) hinzufügen. | Hive database query: Gibt die Hive-Abfrage zum Generieren der Daten an. HCatalog server URI : Gibt den Namen Ihres Clusters im Format <Ihr Clustername>.azurehdinsight.net an. Hadoop user account name: Gibt den Hadoop-Benutzerkontonamen an, der zum Bereitstellen des Clusters verwendet wird. Hadoop user account password : Gibt die Anmeldeinformationen an, die beim Bereitstellen des Clusters verwendet werden. Weitere Informationen finden Sie unter Erstellen von Hadoop-Clustern in HDInsight. Location of output data: Gibt an, ob die Daten in einem HDFS (Hadoop Distributed File System) oder in Azure gespeichert werden.
Wenn Sie Ausgabedaten in Azure speichern, müssen Sie den Namen des Azure-Speicherkontos, den Speicherzugriffsschlüssel und Speichercontainernamen angeben. |
| SQL database | Liest Daten, die in einer Azure SQL-Datenbank-, SQL Managed Instance- oder einer SQL Server-Datenbank-Instanz gespeichert sind, die in einer Azure-VM ausgeführt wird. | Database server name: Gibt den Namen des Servers an, auf dem die Datenbank ausgeführt wird.
Geben Sie Folgendes ein, wenn eine SQL Server-Instanz auf einem virtuellen Azure-Computer gehostet wird: tcp:<DNS-Name des virtuellen Computers>, 1433. Database name : Gibt den Namen der Datenbank auf dem Server an. Server user account name: Gibt einen Benutzernamen für ein Konto an, das über Zugriffsberechtigungen für die Datenbank verfügt. Server user account password: Gibt das Kennwort für das Benutzerkonto an. Database query: Geben Sie eine SQL-Anweisung ein, die die Daten beschreibt, die Sie lesen möchten. |
| On-premises SQL database | Liest Daten, die in einer SQL-Datenbank gespeichert sind. | Data gateway: Gibt den Namen des Datenverwaltungsgateways an, das auf einem Computer installiert ist, auf dem es auf Ihre SQL Server-Datenbank zugreifen kann. Informationen zum Einrichten des Gateways finden Sie unter Durchführen von Analysen mit Machine Learning Studio (Classic) mit einer SQL Server-Datenbank. Database server name: Gibt den Namen des Servers an, auf dem die Datenbank ausgeführt wird. Database name : Gibt den Namen der Datenbank auf dem Server an. Server user account name: Gibt einen Benutzernamen für ein Konto an, das über Zugriffsberechtigungen für die Datenbank verfügt. User name and password: Klicken Sie auf Enter values, und geben Sie Ihre Datenbank-Anmeldeinformationen ein. Je nach Ihrer SQL Server-Konfiguration können Sie die integrierte Windows-Authentifizierung oder die SQL Server-Authentifizierung verwenden. Database query: Geben Sie eine SQL-Anweisung ein, die die Daten beschreibt, die Sie lesen möchten. |
| Azure Table | Liest Daten aus dem Tabellenspeicherdienst in Azure Storage. Wenn große Mengen von Daten selten gelesen werden, verwenden Sie den Azure-Tabellenspeicherdienst. Dieser Dienst bietet eine flexible, nicht relationale (NoSQL), überaus skalierbare, kostengünstige und hochverfügbare Speicherlösung. |
Die Optionen im Import Data-Modul ändern sich je nachdem, ob Sie auf öffentliche Informationen oder ein privates Speicherkonto zugreifen, das Anmeldeinformationen erfordert. Dies wird anhand der Option Authentication Type bestimmt, die den Wert „PublicOrSAS“ oder „Account“ haben kann, der jeweils über einen eigenen Satz von Parametern verfügen kann. Öffentlicher oder SAS-URI (Shared Access Signature): Die Parameter lauten wie folgt:
Gibt die Zeilen an, die nach Eigenschaftennamen durchsucht werden sollen: Die Werte sind TopN zum Ermitteln der angegebenen Anzahl von Zeilen und ScanAll zum Abrufen aller Zeilen der Tabelle. Wenn die Daten homogen und vorhersagbar sind, wird empfohlen, TopN auszuwählen und eine Zahl für N einzugeben. Für große Tabellen kann dies zu kürzeren Lesedauern führen. Wenn die Daten mit Sätzen von Eigenschaften strukturiert sind, die abhängig von der Tiefe und Position der Tabelle variieren, wählen Sie die Option ScanAll, um alle Zeilen zu überprüfen. Dadurch wird die Integrität der resultierenden Eigenschafts- und Metadatenkonvertierung sichergestellt.
Account key: Gibt den Speicherschlüssel an, der dem Konto zugeordnet ist. Table name : Gibt den Namen der Tabelle an, die die zu lesenden Daten enthält. Rows to scan for property names: Die Werte sind TopN zum Ermitteln der angegebenen Anzahl von Zeilen und ScanAll zum Abrufen aller Zeilen der Tabelle. Wenn die Daten homogen und vorhersagbar sind, wird empfohlen, TopN auszuwählen und eine Zahl für N einzugeben. Für große Tabellen kann dies zu kürzeren Lesedauern führen. Wenn die Daten mit Sätzen von Eigenschaften strukturiert sind, die abhängig von der Tiefe und Position der Tabelle variieren, wählen Sie die Option ScanAll, um alle Zeilen zu überprüfen. Dadurch wird die Integrität der resultierenden Eigenschafts- und Metadatenkonvertierung sichergestellt. |
| Azure Blob Storage | Liest im Blob-Dienst in Azure Storage gespeicherte Daten, so z. B. Bilder, unstrukturierten Text oder Binärdaten. Mithilfe des Blob-Diensts können Sie Daten öffentlich verfügbar machen oder Anwendungsdaten privat speichern. Über HTTP oder HTTPS-Verbindungen können Sie von überall auf Ihre Daten zugreifen. |
Die Optionen im Import Data -Modul ändern sich je nachdem, ob Sie auf öffentliche Informationen oder ein privates Speicherkonto zugreifen, das Anmeldeinformationen erfordert. Dies wird anhand der Option Authentication Type bestimmt, die den Wert "PublicOrSAS" oder "Account" haben kann. Öffentlicher oder SAS-URI (Shared Access Signature): Die Parameter lauten wie folgt:
File Format: Gibt das Format der Daten im Blob-Dienst an. Die unterstützten Formate sind CSV, TSV und ARFF.
Account key: Gibt den Speicherschlüssel an, der dem Konto zugeordnet ist. Path to container, directory, or blob : Gibt den Namen des Blobs an, das die zu lesenden Daten enthält. Blob file format: Gibt das Format der Daten im Blobdienst an. Die unterstützten Datenformate sind CSV, TSV, ARFF, CSV mit einer angegebenen Codierung und Excel.
Sie können die Excel-Option zum Lesen von Daten aus Excel-Arbeitsmappen verwenden. Bei der Option Excel data format geben Sie an, ob die Daten in einem Excel-Arbeitsblattbereich oder einer Excel-Tabelle enthalten sind. Bei der Option Excel sheet or embedded table geben Sie den Namen des Blatts oder der Tabelle an, das bzw. die Sie lesen möchten. |
| Data Feed Provider | Liest Daten aus einem unterstützten Feedanbieter. Derzeit wird nur das OData-Format (Open Data Protocol) unterstützt. | Data content type: Gibt das OData-Format an. Source URL: Gibt die vollständige URL für den Datenfeed an. Beispielsweise liest die folgende URL aus der Northwind-Beispieldatenbank: https://services.odata.org/northwind/northwind.svc/ |
Importieren aus einem anderen Experiment
Hin und wieder wird ein Zwischenergebnis aus einem Experiment benötigt, um es als Teil eines anderen Experiments zu verwenden. Dazu speichern Sie das Modul als Dataset:
- Klicken Sie auf die Ausgabe des Moduls, die Sie als Dataset speichern möchten.
- Klicken Sie auf Save as Dataset.
- Wenn Sie dazu aufgefordert werden, geben Sie einen Namen und eine Beschreibung ein, mit denen das Dataset leicht wiederzuerkennen ist.
- Klicken Sie auf das Häkchen OK .
Wenn der Speichervorgang abgeschlossen ist, ist das Dataset für die Verwendung in allen Experimenten in Ihrem Arbeitsbereich verfügbar. Sie finden es in der Liste Saved Datasets in der Modulpalette.