Tutorial 2: Trainieren von Kreditrisikomodellen – Machine Learning Studio (Classic)
GILT FÜR: Azure Machine Learning Studio (Classic)
Azure Machine Learning Studio (Classic)  Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
Dieses Tutorial befasst sich eingehend mit der Entwicklung einer Predictive Analytics-Lösung. Hierzu wird in Machine Learning Studio (klassisch) ein einfaches Modell entwickelt. Stellen Sie das Model anschließend als Machine Learning-Webdienst bereit. Dieses bereitgestellte Modell kann auf der Grundlage neuer Daten Vorhersagen generieren. Dieses Tutorial ist der zweite Teil einer dreiteiligen Reihe.
Stellen Sie sich vor, Sie müssen das Kreditrisiko von Personen anhand der Daten auf einem Kreditantrag vorhersagen.
Die Bewertung des Kreditrisikos ist allerdings ein komplexes Problem und wurde daher in diesem Tutorial etwas vereinfacht. Diese Aufgabenstellung dient als Beispiel dafür, wie Sie eine Predictive Analytics-Lösung mit Machine Learning Studio (Classic) erstellen können. Für diese Lösung werden Sie Machine Learning Studio (Classic) und ein Machine Learning-Webdienst verwendet.
In diesem dreiteiligen Tutorial werden zunächst öffentlich verfügbare Kreditrisikodaten verwendet. Als Nächstes entwickeln und trainieren Sie ein Vorhersagemodell. Abschließend stellen Sie das Modell als Webdienst bereit.
Im ersten Teil des Tutorials haben Sie einen Arbeitsbereich in Machine Learning Studio (klassisch) erstellt, Daten hochgeladen und ein Experiment erstellt.
In diesem Teil des Tutorials führen Sie die folgenden Schritte aus:
- Trainieren mehrerer Modelle
- Bewerten und Auswerten der Modelle
Im dritten Teil des Tutorials stellen Sie das Modell als Webdienst bereit.
Voraussetzungen
Schließen Sie den ersten Teil des Tutorials ab.
Trainieren mehrerer Modelle
Einer der Vorteile von Azure Machine Learning Studio (Classic) zum Erstellen von Machine Learning-Modellen ist die Möglichkeit, mehr als einen Typ von Modell gleichzeitig in einem einzelnen Experiment zu testen und die Ergebnisse zu vergleichen. Dieser Typ von Experiment hilft Ihnen, die beste Lösung für Ihr Problem zu finden.
In dem Experiment, das wir in diesem Tutorial entwickeln, werden zwei verschiedene Modelltypen erstellt und anschließend deren Bewertungsergebnisse verglichen, um zu entscheiden, welcher Algorithmus im endgültigen Experiment verwendet werden soll.
Es stehen verschiedene Modelle zur Auswahl. Um die verfügbaren Modelle anzuzeigen, erweitern Sie den Knoten Machine Learning in der Modulpalette, und erweitern Sie dann Initialize Model und die darunter liegenden Knoten. Für dieses Experiment werden die Module Two-Class Support Vector Machine (SVM) und Two-Class Boosted Decision Tree verwendet.
Diesem Experiment werden sowohl das Modul Two-Class Boosted Decision Tree als auch das Modul Two-Class Support Vector Machine hinzugefügt.
Two-Class Boosted Decision Tree
Zuerst wird das Boosted Decision Tree-Modell eingerichtet.
Suchen Sie das Modul Two-Class Boosted Decision Trees in der Modulpalette, und ziehen Sie es in den Experimentbereich.
Suchen Sie das Modul Train Model, ziehen Sie es in den Bereich, und verbinden Sie die Ausgabe des Moduls Two-Class Boosted Decision Tree mit dem linken Eingabeport des Moduls Train Model.
Das Modul Two-Class Boosted Decision Tree initialisiert das allgemeine Modell. Das Modul Train Model nutzt Trainingsdaten zum Trainieren des Modells.
Verbinden Sie die linke Ausgabe des linken Moduls Execute R Script mit dem rechten Eingabeport des Moduls Train Model. (In diesem Tutorial haben Sie die Daten von der linken Seite des Moduls „Split Data“ für das Training verwendet.)
Tipp
Zwei der Eingaben und eine der Ausgaben des Moduls Execute R Script werden für dieses Experiment nicht benötigt und daher nicht angefügt.
Dieser Teil des Experiments sieht jetzt in etwa wie folgt aus:
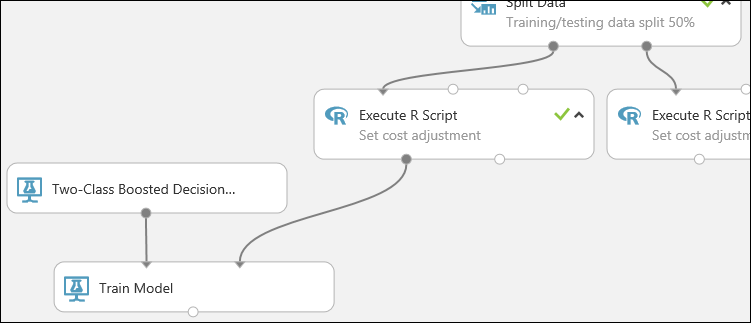
Nun müssen Sie dem Modul Train Model mitteilen, dass das Modell den Wert des Kreditrisikos vorhersagen soll.
Wählen Sie das Modul Train Model (Modell trainieren) aus. Klicken Sie im Bereich Properties auf Launch column selector.
Geben Sie im Dialogfeld Select a single column in das Suchfeld unter Available Columns „Credit risk“ ein. Wählen Sie unten „Credit risk“ aus, und klicken Sie auf den nach rechts zeigenden Pfeil ( > ), um „Credit risk“ in Selected Columns zu verschieben.
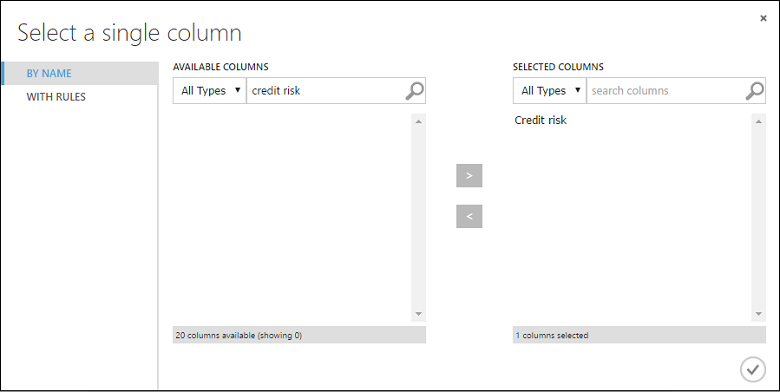
Klicken Sie auf das Häkchen OK.
Two-Class Support Vector Machine
Als Nächstes wird das SVM-Modell eingerichtet.
Zunächst soll SVM ein wenig erläutert werden. Boosted Decision Trees funktionieren hervorragend mit allen Arten von Merkmalen. Da das SVM-Modul jedoch einen linearen Klassifikator generiert, hat das entsprechende generierte Modell den besten Testfehler, wenn alle numerischen Merkmale dieselbe Skala verwenden. Um alle numerischen Features zur gleichen Skala zu konvertieren, verwenden Sie das Modul Normalize Data mit einer Tanh-Transformation. Diese transformiert unsere Zahlen in den Bereich [0,1]. Zeichenfolgenfeatures werden vom SVM-Modul in kategorische Features und anschließend in binäre 0/1-Features konvertiert. Daher müssen Zeichenfolgenfeatures nicht manuell transformiert werden. Zudem darf die Spalte „Credit Risk“ (Spalte 21) nicht transformiert werden. Diese ist zwar numerisch, da es sich dabei aber um den Wert handelt, für dessen Vorhersage das Modell trainiert wird, darf er nicht verändert werden.
Um das SVM-Modell einzurichten, führen Sie folgende Schritte aus:
Suchen Sie das Modul Two-Class Support Vector Machine in der Modulpalette, und ziehen Sie es in den Experimentbereich.
Klicken Sie mit der rechten Maustaste auf das Modul Train Model, und wählen Sie Copy (Kopieren) aus. Klicken Sie anschließend mit der rechten Maustaste auf die Canvas, und wählen Sie Paste (Einfügen) aus. Beachten Sie, dass die Kopie des Moduls Train Model die gleiche Spaltenauswahl wie das Original hat.
Verbinden Sie die Ausgabe des Moduls Two-Class Support Vector Machine mit dem linken Eingabeport des zweiten Moduls Train Model.
Suchen Sie das Modul Normalize Data, und ziehen Sie es in den Experimentbereich.
Verbinden Sie die Eingabe dieses Moduls mit der linken Ausgabe des linken Moduls Execute R Script (beachten Sie, dass der Ausgabeport eines Moduls mit mehr als einem anderen Modul verbunden sein kann).
Verbinden Sie den linken Ausgabeport des Moduls Normalize Data mit dem rechten Eingabeport des Moduls Train Model.
Dieser Teil des Experiments sieht jetzt in etwa wie folgt aus:
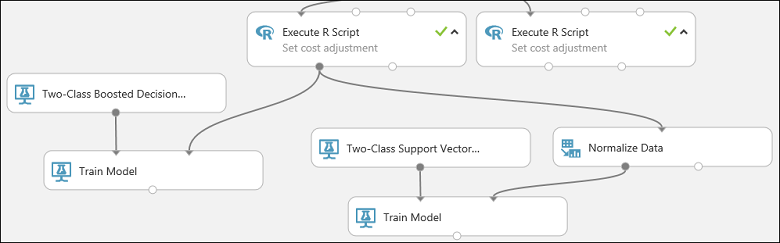
Konfigurieren Sie jetzt das Modul Normalize Data:
Klicken Sie, um das Modul Normalize Data auszuwählen. Wählen Sie im Bereich Properties den Wert Tanh für den Parameter Transformation method aus.
Klicken Sie auf Launch column selector, wählen Sie für Begin With „No columns“, und wählen Sie in der ersten Dropdownliste Include, in der zweiten Dropdownliste column type und in der dritten Dropdownliste Numeric aus. Damit wird festgelegt, dass alle numerischen Spalten (und nur die numerischen Spalten) transformiert werden.
Klicken Sie auf das Pluszeichen (+) rechts neben dieser Zeile. Dadurch wird eine neue Zeile mit Dropdownlisten erstellt. Wählen Sie in der ersten Dropdownliste Excludeaus. Wählen Sie in der zweiten Dropdownliste column names aus, und geben Sie „Credit risk“ in das Textfeld ein. Dadurch wird angegeben, dass die Spalte „Credit Risk“ ignoriert werden soll. (Dies ist erforderlich, da diese Spalte numerisch ist und transformiert wird, wenn Sie sie nicht ausschließen.)
Klicken Sie auf das Häkchen OK.
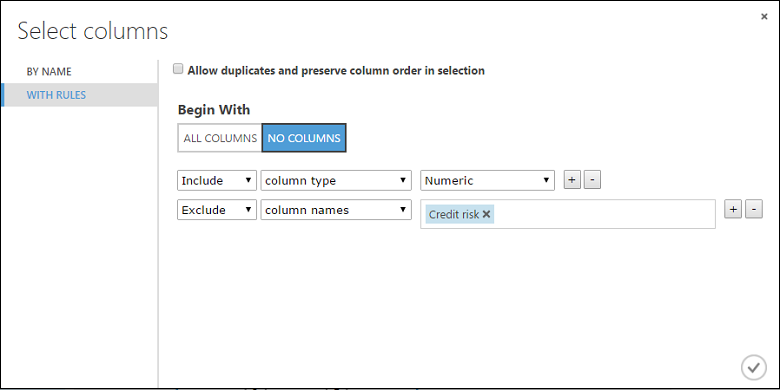
Das Modul Normalize Data ist jetzt für eine Tanh-Transformation aller numerischen Spalten mit Ausnahme der Spalte „Credit Risk“ (Kreditrisiko) eingerichtet.
Bewerten und Auswerten der Modelle
Sie verwenden die Testdaten, die durch das Modul Split Data getrennt wurden, um die trainierten Modelle zu bewerten. Danach können die Ergebnisse der beiden Modelle verglichen werden, um zu ermitteln, welches Modell die besseren Ergebnisse liefert.
Hinzufügen der „Score Model“-Module
Suchen Sie das Modul Score Model, und ziehen Sie es in den Bereich.
Verbinden Sie das Modul Train Model, das mit dem Modul Two-Class Boosted Decision Tree verbunden ist, mit dem linken Eingabeport des Moduls Score Model.
Verbinden Sie das rechte Modul Execute R Script (unsere Testdaten) mit dem rechten Eingabeport des Moduls Score Model.
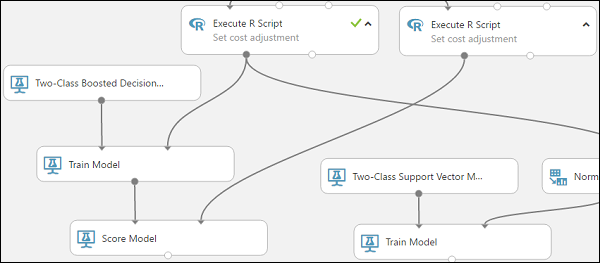
Das Modul Score Model kann nun die Kreditinformationen aus den Testdaten entnehmen, sie durch das Modell laufen lassen und vom Modell generierte Vorhersagen mit der Spalte mit dem tatsächlichen Kreditrisiko in den Testdaten vergleichen.
Kopieren Sie das Modul Score Model, und fügen Sie es ein, um eine zweite Kopie zu erstellen.
Verbinden Sie die Ausgabe des SVM-Modells (d. h. den Ausgabeport des Moduls Train Model, der mit dem Modul Two-Class Support Vector Machine verbunden ist) mit dem Eingabeport des zweiten Moduls Score Model.
Für das SVM-Modell muss die gleiche Transformation für die Testdaten durchgeführt werden wie für die Trainingsdaten. Kopieren Sie also das Modul Normalize Data, und fügen Sie es ein, um eine zweite Kopie zu erstellen, und verbinden Sie es mit dem rechten Modul Execute R Script.
Verbinden Sie die linke Ausgabe des zweiten Moduls Normalize Data mit dem rechten Eingabeport des zweiten Moduls Score Model.
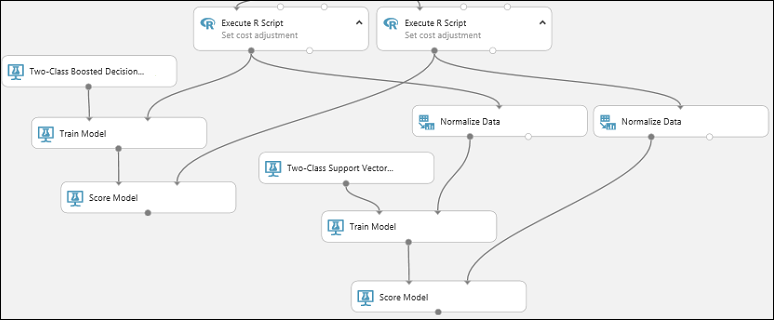
Hinzufügen des Moduls „Evaluate Model“
Zum Evaluieren und Vergleichen der beiden Bewertungsergebnisse wird das Modul Evaluate Model verwendet.
Suchen Sie das Modul Evaluate Model, und ziehen Sie es in den Bereich.
Verbinden Sie den Ausgabeport des Moduls Score Model, der dem Modell „Boosted Decision Tree“ zugeordnet ist, mit dem linken Eingabeport des Moduls Evaluate Model.
Verbinden Sie das andere Modul Score Model mit dem rechten Eingabeport.
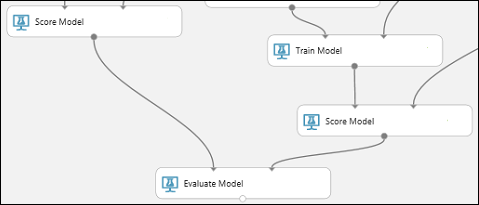
Ausführen des Experiments und Überprüfen der Ergebnisse
Klicken Sie auf die Schaltfläche RUN unter dem Bereich, um das Experiment auszuführen. Dies kann einige Minuten dauern. Für jedes Modul wird ein Drehzeiger angezeigt, um anzugeben, dass es ausgeführt wird. Wenn das Modul abgeschlossen ist, wird ein grünes Häkchen angezeigt. Wenn alle Module ein Häkchen aufweisen, ist die Ausführung des Experiments beendet.
Das Experiment sollte in etwa wie folgt aussehen:
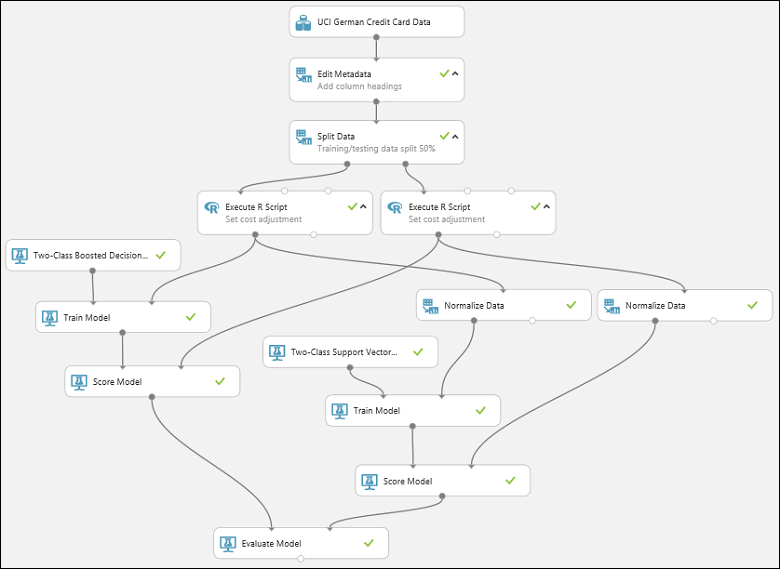
Um die Ergebnisse zu prüfen, klicken Sie auf den Ausgabeport des Moduls Evaluate Model, und wählen Sie Visualize aus.
Das Modul Evaluate Model erzeugt ein Paar aus Kurven und Metriken, mit denen die Ergebnisse der beiden bewerteten Modelle verglichen werden können. Sie können die Ergebnisse als ROC-Kurven (Receiver Operator Characteristic), Genauigkeits-/Trefferkurven oder Prognosegütekurven anzeigen. Zu den zusätzlich angezeigten Daten zählen eine Wahrheitsmatrix, kumulative Werte für den Bereich unter der Kurve (AUC) sowie weitere Metriken. Sie können den Schwellwert ändern, indem Sie den Schieberegler nach links oder rechts bewegen und beobachten, wie sich dies auf den Metriksatz auswirkt.
Klicken Sie rechts neben dem Graph auf Scored dataset oder auf Scored dataset to compare, um die zugeordnete Kurve zu markieren und die zugeordneten Metriken darunter anzuzeigen. In der Legende für die Kurven entspricht „Bewertetes Dataset“ dem linken Eingabeport des Moduls Evaluate Model – in unserem Fall ist dies das Boosted Decision Tree-Modell. "Scored dataset to compare" entspricht dem rechten Eingabeport – in unserem Fall dem SVM-Modell. Wenn Sie auf eine dieser Beschriftungen klicken, werden die Kurve für das betreffende Modell markiert und die entsprechenden Metriken darunter angezeigt (siehe die folgende Abbildung).
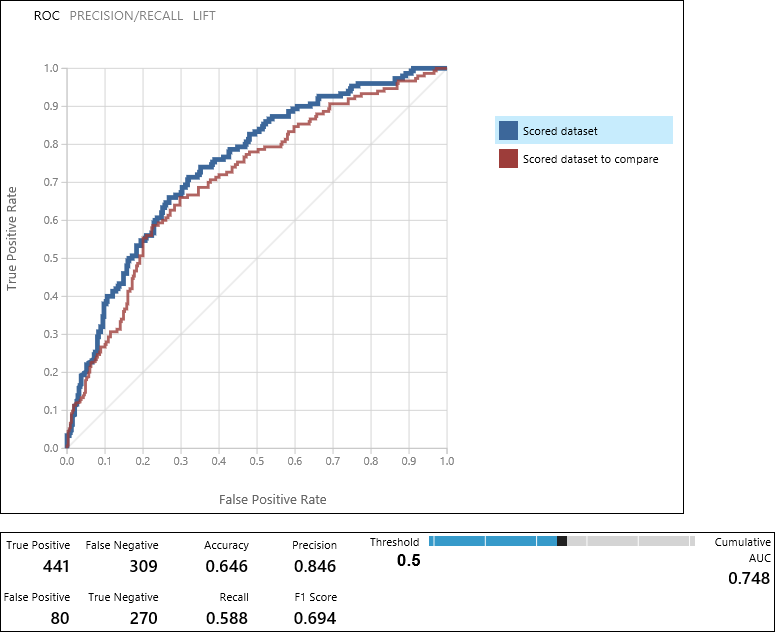
Wenn Sie diese Werte prüfen, können Sie entscheiden, welches Modell am ehesten den gewünschten Ergebnissen entspricht. Sie können zurückgehen und das Experiment erneut ausführen, indem Sie Parameterwerte in den verschiedenen Modellen ändern.
Die wissenschaftliche Vorgehensweise und Kunst der Interpretation dieser Ergebnisse und das Optimieren der Modellleistung werden in diesem Tutorial nicht behandelt. Weitere Hilfe erhalten Sie in den folgenden Artikeln:
- Gewusst wie: Auswerten der Modellleistung in Azure Machine Learning Studio (Classic)
- Auswählen von Parametern zur Optimierung von Algorithmen in Azure Machine Learning Studio (Classic)
- Interpretieren von Modellergebnissen in Machine Learning Studio (Classic)
Tipp
Jedes Mal, wenn Sie das Experiment ausführen, wird im Ausführungsverlauf ein Dataset für diese Iteration aufbewahrt. Sie können die Iterationen anzeigen und zu jeder von ihnen zurückkehren, indem Sie unter dem Bereich auf VIEW RUN HISTORY klicken. Sie können auch im Fenster Properties auf Prior Run klicken, um zur Iteration unmittelbar vor der geöffneten Iteration zurückzukehren.
Sie können eine Kopie jeder Iteration des Experiments anfertigen, indem Sie unter dem Bereich auf SAVE AS klicken. Verwenden Sie die Eigenschaften Summary und Description des Experiments, um nachzuhalten, was Sie in den Iterationen Ihres Experiments versucht haben.
Weitere Informationen finden Sie unter Verwalten von Experimentiterationen in Machine Learning-Studio (Classic).
Bereinigen von Ressourcen
Wenn Sie die in diesem Artikel erstellten Ressourcen nicht mehr benötigen, löschen Sie sie, um eventuell anfallende Kosten zu vermeiden. Informationen dazu finden Sie im Artikel Exportieren und Löschen von im Produkt enthaltenen Benutzerdaten.
Nächste Schritte
In diesem Tutorial haben Sie die folgenden Schritte ausgeführt:
- Erstellen eines Experiments
- Trainieren mehrerer Modelle
- Bewerten und Auswerten der Modelle
Als Nächstes können Sie Modelle für diese Daten bereitstellen.