R-Skript-Komponente ausführen
In diesem Artikel wird beschrieben, wie Sie die Komponente Execute R Script verwenden, um R-Code in Ihrer Azure Machine Learning Designer-Pipeline auszuführen.
Mit R können Sie Aufgaben erledigen, die von den vorhandenen Komponenten nicht unterstützt werden, z. B:
- Erstellen benutzerdefinierter Datentransformationen
- Verwenden eigener Metriken zum Auswerten von Vorhersagen
- Modelle mit Algorithmen erstellen, die nicht als eigenständige Komponenten im Designer implementiert sind
Unterstützte Versionen von R
Der Azure Machine Learning-Designer verwendet die CRAN-Distribution (Comprehensive R Archive Network) von R. Die derzeit verwendete Version ist CRAN 3.5.1.
Unterstützte R-Pakete
Die R-Umgebung wird mit mehr als 100 Paketen vorinstalliert. Eine vollständige Liste finden Sie im Abschnitt Vorinstallierte R-Pakete.
Sie können auch den folgenden Code zu jeder Execute R Script Komponente hinzufügen, um die installierten Pakete anzuzeigen.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Hinweis
Wenn Ihre Pipeline mehrere Execute R Script-Komponenten enthält, die Pakete benötigen, die nicht in der vorinstallierten Liste enthalten sind, installieren Sie die Pakete in jeder Komponente.
Installieren von R-Paketen
Um zusätzliche R-Pakete zu installieren, verwenden Sie die install.packages()-Methode. Für jede Komponente von Execute R Script werden Pakete installiert. Sie werden nicht von anderen Execute R Script-Komponenten gemeinsam genutzt.
Hinweis
Es wird NICHT empfohlen, das R-Paket aus dem Skriptpaket zu installieren. Installieren Sie Pakete besser direkt im Skript-Editor.
Geben Sie das CRAN-Repository an, wenn Sie Pakete installieren, z. B. install.packages("zoo",repos = "https://cloud.r-project.org").
Warnung
Die Excute R Script Komponente unterstützt nicht die Installation von Paketen, die eine native Kompilierung erfordern, wie z.B. qdap Paket, das JAVA erfordert und drc Paket, das C++ erfordert. Dies liegt daran, dass diese Komponente in einer vorinstallierten Umgebung mit Nicht-Administratorrechten ausgeführt wird.
Installieren Sie keine Pakete, die auf/für Windows vorgebaut sind, da die Designerkomponenten auf Ubuntu laufen. Wenn Sie überprüfen möchten, ob ein Paket unter Windows vorbereitet wurde, können Sie zu CRAN navigieren und nach Ihrem Paket suchen. Laden Sie dann eine Binärdatei entsprechend Ihrem Betriebssystem herunter, und überprüfen Sie den Abschnitt Built: in der Datei DESCRIPTION. Dies ist ein Beispiel: 
Dieses Beispiel zeigt die Installation von Zoo:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Hinweis
Bevor Sie ein Paket installieren, prüfen Sie, ob es bereits vorhanden ist, sodass Sie eine Installation nicht wiederholen. Wiederholte Installationen können dazu führen, dass bei Webdienstanforderungen Timeouts auftreten.
Zugreifen auf ein registriertes Dataset
Verwenden Sie den folgenden Beispielcode, um auf die in Ihrem Arbeitsbereich registrierten Datasets zuzugreifen:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Konfigurieren von Execute R Script
Die Komponente Execute R Script enthält Beispielcode als Ausgangspunkt.
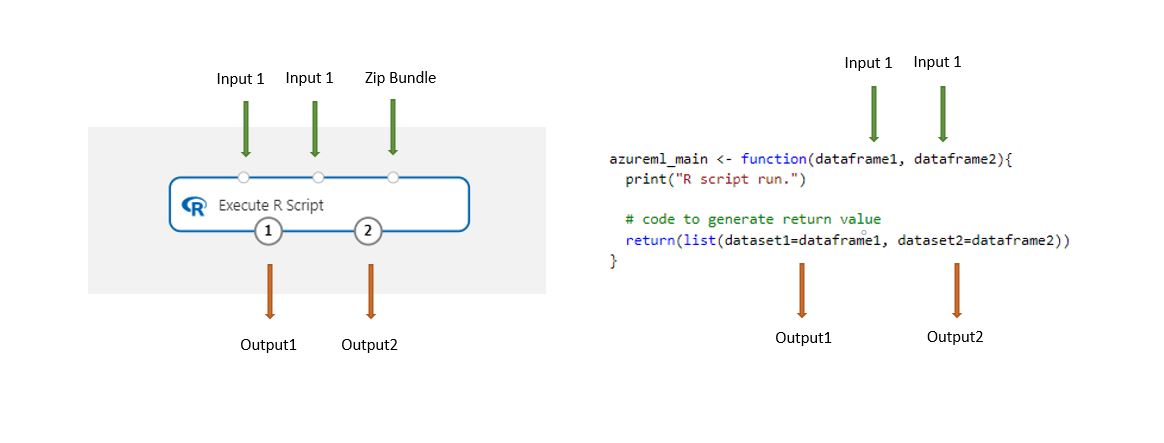
Im Designer gespeicherte Datensätze werden beim Laden mit dieser Komponente automatisch in einen R-Datenrahmen konvertiert.
Fügen Sie die Komponente Execute R Script zu Ihrer Pipeline hinzu.
Stellen Sie Verbindungen mit sämtlichen Eingaben her, die das Skript benötigt. Eingaben sind optional und können Daten sowie zusätzlichen R-Code enthalten.
Dataset1: Verweisen Sie auf die erste Eingabe als
dataframe1. Das eingegebene Dataset muss als CSV-, TSV- oder ARFF-Datei formatiert sein. Oder Sie können eine Verbindung mit einem Azure Machine Learning-Dataset herstellen.Dataset2: Verweisen Sie auf die zweite Eingabe als
dataframe2. Dieses Dataset muss auch das Format CSV, TSV oder ARFF aufweisen oder ein Azure Machine Learning-Dataset sein.Script Bundle: Die dritte Eingabe akzeptiert ZIP-Dateien. Eine ZIP-Datei kann mehrere Dateien und Dateitypen enthalten.
Geben oder fügen Sie in das Textfeld R script (R-Skript) ein gültiges R-Skript ein.
Hinweis
Gehen Sie beim Schreiben Ihres Skripts mit Bedacht vor. Vergewissern Sie sich, dass keine Syntaxfehler vorliegen, wie z. B. die Verwendung nicht deklarierter Variablen oder nicht importierter Komponenten oder Funktionen. Achten Sie besonders auf die Liste der vorinstallierten Pakete am Ende dieses Artikels. Um nicht aufgelistete Pakete zu verwenden, installieren Sie sie in Ihrem Skript. z. B.
install.packages("zoo",repos = "https://cloud.r-project.org").Um Ihnen den Einstieg zu erleichtern, ist das Textfeld R Script mit Beispielcode vorab ausgefüllt, den Sie bearbeiten oder ersetzen können.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }Die Einstiegspunktfunktion muss über die Eingabeargumente
Param<dataframe1>undParam<dataframe2>verfügen. Dies gilt auch, wenn diese Argumente nicht in der Funktion verwendet werden.Hinweis
Die an die Komponente Execute R Script übergebenen Daten werden als
dataframe1unddataframe2referenziert, was sich vom Azure Machine Learning Designer unterscheidet (die Designer-Referenz lautetdataset1,dataset2). Stellen Sie sicher, dass auf die Eingabedaten in Ihrem Skript ordnungsgemäß verwiesen wird.Hinweis
Vorhandener R-Code kann kleinere Änderungen erfordern, damit er in einer Designer-Pipeline ausgeführt werden kann. Beispielsweise müssen Eingabedaten, die Sie im CSV-Format bereitstellen, explizit in ein Dataset konvertiert werden, bevor Sie sie in Ihrem Code verwenden können. Daten- und Spaltentypen, die in der Sprache R verwendet werden, unterscheiden sich ebenfalls durch einige Besonderheiten von den im Designer verwendeten Daten- und Spaltentypen.
Wenn Ihr Skript größer als 16 KB ist, verwenden Sie den Script Bundle-Port, um Fehler wie CommandLine überschreitet das Limit von 16.597 Zeichen zu vermeiden.
- Bündeln Sie das Skript und andere benutzerdefinierte Ressourcen in einer ZIP-Datei.
- Laden Sie die ZIP-Datei als Dateidataset in Studio hoch.
- Ziehen Sie die Dataset-Komponente aus der Datensätze in das linke Komponentenfenster auf der Designer Dokumenterstellung seite.
- Verbinden Sie die Dataset-Komponente mit dem Port Script Bundle der Komponente Execute R Script.
Im Folgenden finden Sie den Beispielcode zum Verwenden des Skripts im Script Bundle:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }Geben Sie für Random Seed (zufälliger Ausgangswert) einen Wert ein, der in der R-Umgebung als zufälliger Ausgangswert verwendet werden soll. Dieser Parameter entspricht dem Aufrufen von
set.seed(value)im R-Code.Übermitteln Sie die Pipeline.
Ergebnisse
Execute R Script-Komponenten können mehrere Ausgaben zurückgeben, die jedoch als R-Datenrahmen bereitgestellt werden müssen. Der Designer konvertiert Datenrahmen automatisch in Datasets, um die Kompatibilität mit anderen Komponenten zu gewährleisten.
Standard meldungen und Fehler von R werden in das Protokoll der Komponente zurückgegeben.
Wenn Sie die Ergebnisse im R-Skript ausdrucken möchten, finden Sie die gedruckten Ergebnisse in 70_driver_log unter der Registerkarte Outputs+logs in der rechten Leiste der Komponente.
Beispielskripts
Es gibt viele Möglichkeiten, wie Sie Ihre Pipeline mithilfe eines benutzerdefinierten R-Skripts erweitern können. Dieser Abschnitt enthält Beispielcode für allgemeine Aufgaben.
Hinzufügen eines R-Skripts als Eingabe
Die Komponente Execute R Script unterstützt beliebige R-Skriptdateien als Eingaben. Sie müssen sie als Teil der ZIP-Datei in Ihren Arbeitsbereich hochladen, um sie verwenden zu können.
Wechseln Sie zur Ressourcenseite Datasets, um eine ZIP-Datei, die R-Code enthält, in Ihren Arbeitsbereich hochzuladen. Wählen Sie Dataset erstellen aus. Anschließend wählen Sie Aus lokaler Datei und die Option Datei für den Datasettyp aus.
Überprüfen Sie, ob die gezippte Datei in Meine Datensätze unter der Kategorie Datensätze in der linken Komponentenstruktur erscheint.
Verbinden Sie das Dataset mit dem Eingabeport Script Bundle.
Alle Dateien in der ZIP-Datei sind während der Laufzeit der Pipeline verfügbar.
Wenn die Script Bundle-Datei eine Verzeichnisstruktur enthält, bleibt die Struktur erhalten. Sie müssen aber Ihren Code so ändern, dass das Verzeichnis ./Script Bundle dem Pfad vorangestellt wird.
Verarbeiten von Daten
Das folgende Beispiel zeigt, wie Eingabedaten skaliert und normalisiert werden:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Lesen einer ZIP-Datei als Eingabe
Dieses Beispiel zeigt, wie man einen Datensatz in einer .zip-Datei als Eingabe für die Komponente R-Skript ausführen verwendet.
- Erstellen Sie die Datendatei im CSV-Format, und nennen Sie sie mydatafile.csv.
- Erstellen Sie eine ZIP-Datei, und fügen Sie die CSV-Datei dem Archiv hinzu.
- Laden Sie die ZIP-Datei in Ihren Azure Machine Learning-Arbeitsbereich hoch.
- Verbinden Sie den resultierenden Datensatz mit dem Eingang ScriptBundle Ihrer Komponente Execute R Script.
- Verwenden Sie den folgenden Code, um die CSV-Daten aus der ZIP-Datei zu lesen.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Replizieren von Zeilen
Dieses Beispiel zeigt, wie positive Datensätze in einem Dataset repliziert werden können, um die Stichprobe auszugleichen:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
Übergabe von R-Objekten zwischen Komponenten von Execute R Script
Sie können R-Objekte zwischen Instanzen der Komponente "R-Skript ausführen" übergeben, indem Sie den internen Serialisierungsmechanismus verwenden. In diesem Beispiel wird davon ausgegangen, dass Sie das R-Objekt mit dem Namen A zwischen zwei Execute R Script-Komponenten verschieben möchten.
Fügen Sie die erste Komponente Execute R Script zu Ihrer Pipeline hinzu. Geben Sie dann den folgenden Code in das Textfeld R Script ein, um ein serialisiertes Objekt
Aals Spalte in der Ausgabedatentabelle der Komponente zu erstellen:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }Die explizite Konvertierung in den Typ Integer erfolgt, da die Serialisierungsfunktion Daten im
Raw-Format von R ausgibt, das vom Designer nicht unterstützt wird.Fügen Sie eine zweite Instanz der Komponente Execute R Script hinzu, und verbinden Sie sie mit dem Ausgabeport der vorherigen Komponente.
Geben Sie den folgenden Code in das Textfeld R Script ein, um das Objekt
Aaus der Eingabedatentabelle zu extrahieren.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Vorinstallierte R-Pakete
Die folgenden vorinstallierten R-Pakete sind zurzeit verfügbar:
| Paket | Version |
|---|---|
| askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| starten | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| caret | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| class | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| datasets | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| Evaluieren | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| fs | 1.3.1 |
| gdata | 2.18.0 |
| generics | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| graphics | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0,8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1.23 |
| labeling | 0,3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| Matrix | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0,7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| Fortschritt | 1.2.2 |
| ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0,1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0,13 |
| Tools | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0,8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| Zoo | 1.8-6 |
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.