Referenz der Komponente „Extract N-Gram Features from Text“
Dieser Artikel beschreibt eine Komponente im Azure Machine Learning Designer. Verwenden Sie die Komponente „Extract N-Gram Features from Text“ (N-Gramm-Merkmale aus Text extrahieren), um unstrukturierte Textdaten in Merkmale zu zerlegen.
Konfiguration der Komponente „Extract N-Gram Features from Text“
Die Komponente unterstützt die folgenden Szenarien für die Verwendung eines N-Gramm-Wörterbuchs:
Erstellen eines neuen N-Gramm-Wörterbuchs aus einer Spalte mit freiem Text.
Verwenden einer vorhandenen Sammlung von Textmerkmalen, um eine Spalte mit freiem Text in Merkmale zu zerlegen.
Bewerten oder Bereitstellen eines Modells, das N-Gramme verwendet
Erstellen eines neuen N-Gramm-Wörterbuchs
Fügen Sie die Komponente Extract N-Gram Features from Text Ihrer Pipeline hinzu, und verbinden Sie das Dataset, das den zu verarbeitenden Text enthält.
Verwenden Sie Text column (Textspalte), um eine Spalte des Typs „string“ auszuwählen, die den zu extrahierenden Text enthält. Weil die Ergebnisse ausführlich sind, können Sie immer nur jeweils eine Spalte verarbeiten.
Legen Sie Vocabulary mode (Vokabularmodus) auf Create (Erstellen) fest, um anzugeben, dass Sie eine neue Liste von N-Gramm-Merkmalen erstellen.
Legen Sie N-Grams size (N-Gramm-Größe) fest, um die maximale Größe der zu extrahierenden und zu speichernden N-Gramme anzugeben.
Wenn Sie z.B. 3 eingeben, werden Unigramme, Bigramme und Trigramme erstellt.
Weighting function (Gewichtungsfunktion) gibt an, wie der Dokumentmerkmalsvektor erstellt und Vokabular aus Dokumenten extrahiert wird.
Binary Weight (Binäre Gewichtung): Weist den extrahierten N-Grammen einen binären Wert für das Vorhandensein zu. Der Wert für jedes N-Gramm ist gleich 1, wenn es im Dokument vorhanden ist, andernfalls ist der Wert gleich 0.
TF Weight (TF-Gewichtung): Weist den extrahierten N-Grammen eine Begriffshäufigkeit (Term Frequency, TF) zu. Der Wert für jedes N-Gramm ist dessen Vorkommenshäufigkeit im Dokument.
IDF Weight (IDF-Gewichtung): Weist den extrahierten N-Grammen eine Bewertung für die inverse Dokumenthäufigkeit (Inverse Document Frequency, IDF) zu. Der Wert für jedes N-Gramm ist das Protokoll der Korpusgröße geteilt durch die Häufigkeit seines Vorkommens im gesamten Korpus.
IDF = log of corpus_size / document_frequencyTF-IDF Weight (TF-IDF-Gewichtung): Weist den extrahierten N-Grammen eine Bewertung für die Begriffshäufigkeit/inverse Dokumenthäufigkeit (TF/IDF) zu. Der Wert für jedes N-Gramm ist die TF-Bewertung multipliziert mit seiner IDF-Bewertung.
Legen Sie Minimum word length (Minimale Wortlänge) auf die minimale Anzahl von Buchstaben fest, die in jedem Einzelwort in einem N-Gramm verwendet werden können.
Verwenden Sie Maximum word length (Maximale Wortlänge), um die maximale Anzahl von Buchstaben festzulegen, die in jedem Einzelwort in einem N-Gramm verwendet werden können.
Standardmäßig sind bis zu 25 Zeichen pro Wort oder Token zulässig.
Verwenden Sie Minimum n-gram document absolute frequency (Minimale absolute N-Gramm-Dokumenthäufigkeit), um die minimalen Vorkommen festzulegen, die erforderlich sind, damit ein N-Gramm in das N-Gramm-Wörterbuch aufgenommen werden kann.
Wenn Sie beispielsweise den Standardwert 5 verwenden, muss jedes N-Gramm mindestens fünf Mal im Korpus vorkommen, um in das N-Gramm-Wörterbuch aufgenommen zu werden.
Legen Sie Maximum n-gram document ratio (Maximales N-Gramm-Dokumentverhältnis) auf das maximale Verhältnis der Anzahl der Zeilen fest, die ein bestimmtes N-Gramm im Vergleich zur Anzahl der Zeilen im Gesamtkorpus enthalten darf.
Ein Verhältnis von 1 gibt beispielsweise an, dass das N-Gramm dem N-Gramm-Wörterbuch selbst dann hinzugefügt werden kann, wenn in jeder Zeile ein bestimmtes N-Gramm vorhanden ist. In der Regel wird ein Wort, das in jeder Zeile vorkommt, als Füllwort betrachtet und entfernt. Um fachgebietsabhängige Füllwörter auszufiltern, verringern Sie dieses Verhältnis.
Wichtig
Die Häufigkeit des Vorkommens bestimmter Wörter ist nicht einheitlich. Sie variiert von Dokument zu Dokument. Wenn Sie beispielsweise Kundenkommentare zu einem bestimmten Produkt analysieren, kann der Produktname sehr häufig vorkommen und ähnlich einem Füllwort sein, aber in anderen Kontexten als wichtiger Begriff gelten.
Wählen Sie die Option Normalize n-gram feature vectors (N-Gramm-Merkmalsvektoren normalisieren) aus, um die Merkmalsvektoren zu normalisieren. Wenn diese Option aktiviert ist, wird jeder N-Gramm-Merkmalsvektor durch seine L2-Norm dividiert.
Übermitteln Sie die Pipeline.
Verwenden eines vorhandenen N-Gramm-Wörterbuchs
Fügen Sie die Komponente Extract N-Gram Features from Text Ihrer Pipeline hinzu, und verbinden Sie das Dataset, das den zu verarbeitenden Text enthält, mit dem Dataset-Port.
Verwenden Text column (Textspalte), um die Textspalte auszuwählen, die den Text enthält, den Sie in Merkmale zerlegen möchten. Standardmäßig wählt die Komponente alle Spalten des Typs string aus. Um optimale Ergebnisse zu erzielen, verarbeiten Sie jeweils eine einzelne Spalte.
Fügen Sie das gespeicherte Dataset hinzu, das ein zuvor generiertes N-Gramm-Wörterbuch enthält, und verbinden Sie es mit dem Input vocabulary-Port (Eingabevokabular). Sie können auch die Ausgabe Result vocabulary (Ergebnisvokabular) einer Upstreaminstanz der Komponente „Extract N-Gram Features from Text“ (N-Gramm-Merkmale aus Text extrahieren) verbinden.
Wählen Sie unter Vocabulary mode (Vokabularmodus) in der Dropdownliste die Aktualisierungsoption ReadOnly (Schreibgeschützt) aus.
Die Option ReadOnly stellt den Eingabekorpus für das Eingabevokabular dar. Anstatt die Häufigkeiten von Begriffen aus dem neuen Textdataset (für die linke Eingabe) zu berechnen, werden die N-Gramm-Gewichtungen aus dem Eingabevokabular unverändert übernommen.
Tipp
Verwenden Sie diese Option, wenn Sie einen Textklassifizierer bewerten.
Informationen zu allen anderen Optionen finden Sie in den Eigenschaftenbeschreibungen im vorherigen Abschnitt.
Übermitteln Sie die Pipeline.
Erstellen von Rückschlusspipelines, die N-Gramme zum Bereitstellen eines Echtzeitendpunkts verwenden
Eine Trainingspipeline mit Extract N-Grams Feature From Text und Score Model für Vorhersagen über das Testdataset wird in der folgenden Struktur erstellt:
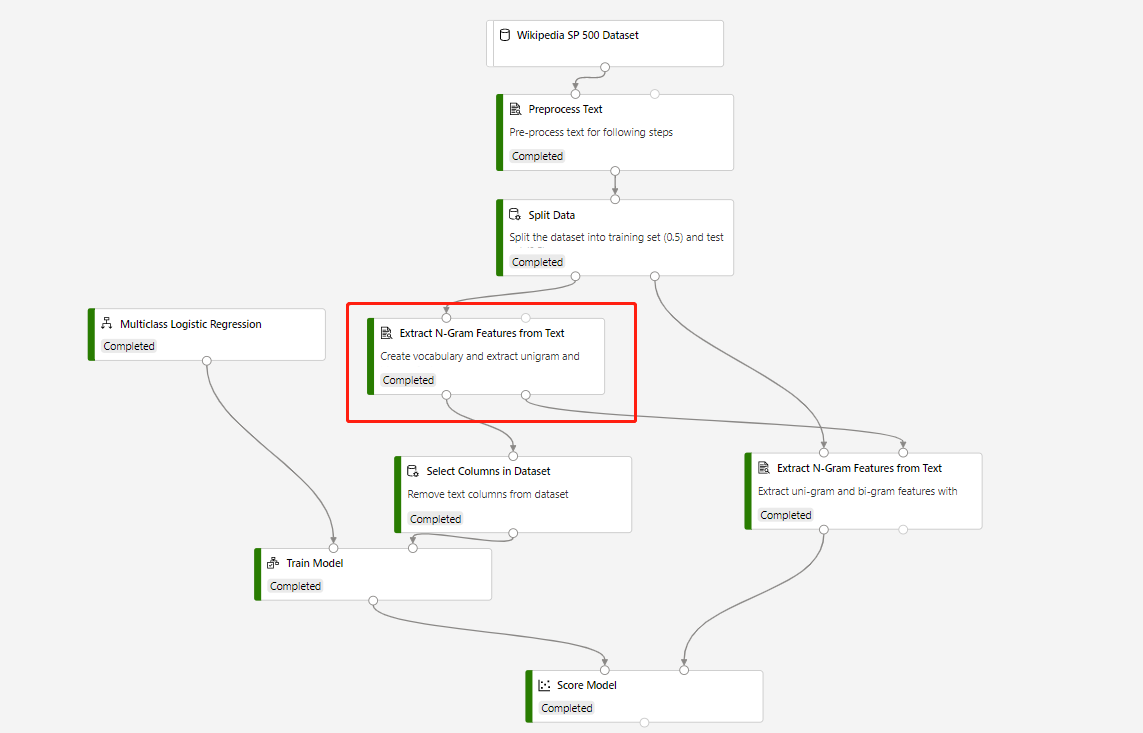
Der Vokabularmodus der Komponente Extract N-Grams Feature From Text lautet Create (Erstellen), und der Vokabularmodus der Komponente, die mit der Komponente Score Model verbunden ist, lautet ReadOnly (Schreibgeschützt).
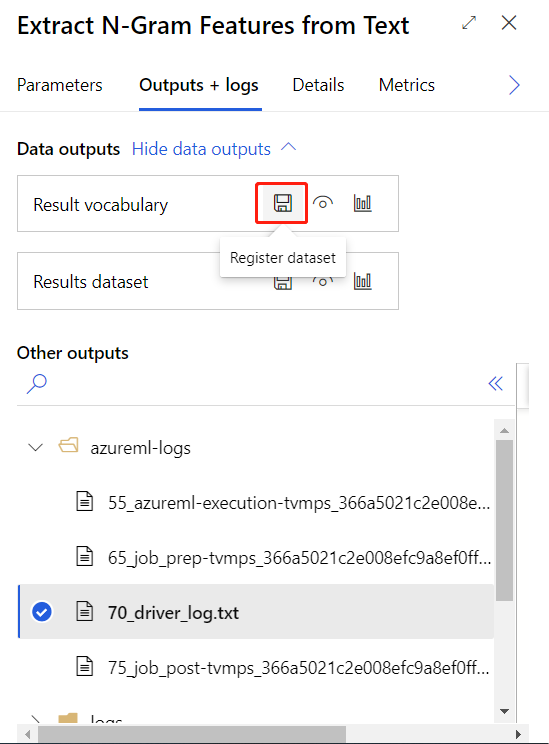
Nachdem Sie die obige Trainingspipeline erfolgreich übermittelt haben, können Sie die Ausgabe der eingekreisten Komponente als Dataset registrieren.
Danach können Sie eine Echtzeit-Rückschlusspipeline erstellen. Nachdem Sie die Rückschlusspipeline erstellt haben, müssen Sie diese manuell wie folgt anpassen:
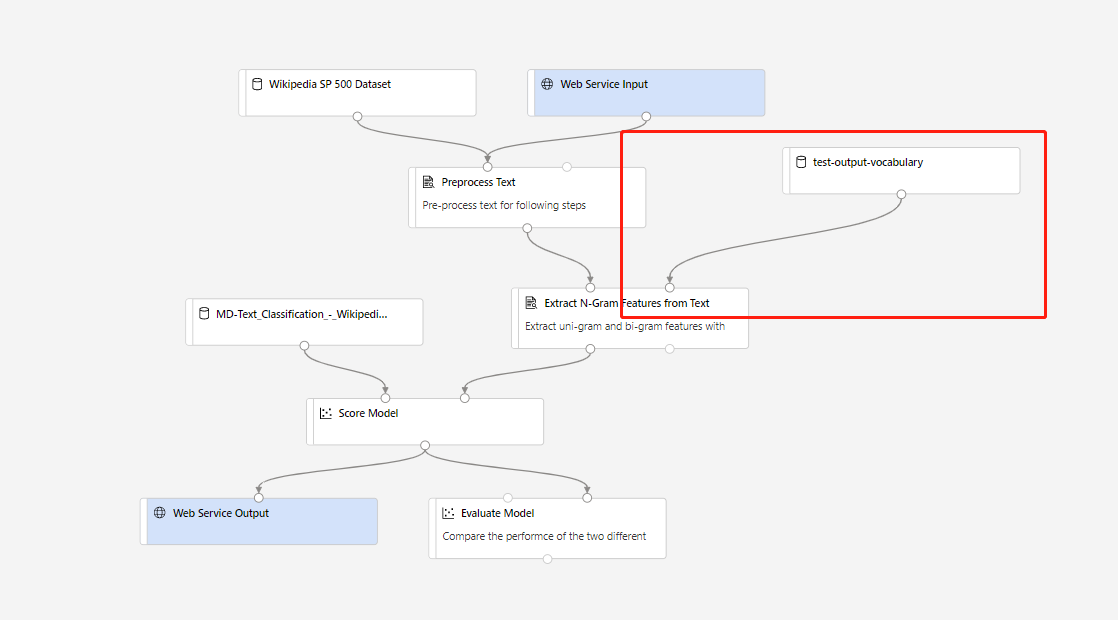
Übermitteln Sie dann die Rückschlusspipeline, und stellen Sie einen Echtzeitendpunkt bereit.
Ergebnisse
Die Komponente „Extract N-Gram Features from Text“ erstellt zwei Arten von Ausgabe:
Result Dataset (Ergebnisdataset): Diese Ausgabe ist eine Zusammenfassung des analysierten Texts in Kombination mit den N-Grammen, die extrahiert wurden. Spalten, die Sie nicht in der Option Text column (Textspalte) ausgewählt haben, werden an die Ausgabe übergeben. Für jede Textspalte, die Sie analysieren, generiert die Komponente diese Spalten:
- Matrix mit N-Gramm-Vorkommen: Die Komponente generiert eine Spalte für jedes im Gesamtkorpus gefundene N-Gramm und fügt in jeder Spalte eine Bewertung hinzu, um die Gewichtung des N-Gramms für diese Zeile anzugeben.
Ergebnisvokabular: Das Vokabular enthält das tatsächliche N-Gramm-Wörterbuch zusammen mit den Bewertungen für die Häufigkeit von Begriffen, die als Teil der Analyse generiert werden. Sie können das Dataset für die Wiederverwendung mit einer anderen Sammlung von Eingaben oder für eine spätere Aktualisierung speichern. Sie können das Vokabular auch für Modellierung und Bewertung wiederverwenden.
Ergebnisvokabular
Das Vokabular enthält das N-Gramm-Wörterbuch mit den Bewertungen für die Begriffshäufigkeit, die als Teil der Analyse generiert werden. Die DF- und die IDF-Bewertung werden unabhängig von anderen Optionen generiert.
- ID: Ein Bezeichner, der für jedes eindeutige N-Gramm generiert wird.
- NGram: Das N-Gramm. Leerzeichen oder andere Worttrennzeichen werden durch Unterstriche ersetzt.
- DF: Die Bewertung für die Begriffshäufigkeit für das N-Gramm im ursprünglichen Korpus.
- IDF: Die Bewertung für die inverse Dokumenthäufigkeit für das N-Gramm im ursprünglichen Korpus.
Sie können dieses Dataset manuell aktualisieren. Es könnte aber sein, dass Sie dabei Fehler einführen. Beispiel:
- Wenn die Komponente doppelt vorhandene Zeilen mit demselben Schlüssel im Eingabevokabular findet, wird ein Fehler ausgelöst. Stellen Sie sicher, dass keine zwei Zeilen im Vokabular dasselbe Wort aufweisen.
- Das Eingabeschema der Vokabulardatasets muss genau übereinstimmen, einschließlich der Spaltennamen und Spaltentypen.
- Die Spalte ID und die Spalte DF müssen den Typ „integer“ haben.
- Die Spalte IDF muss den Typ „float“ haben.
Hinweis
Verbinden Sie die Datenausgabe nicht direkt mit der Komponente „Train Model“ (Modell trainieren). Sie müssen freie Textspalten entfernen, bevor Sie in das Modul „Train Model“ eingespeist werden. Andernfalls werden die freien Textspalten als kategorische Features (Kategoriemerkmale) behandelt.
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.