Filter Based Feature Selection
In diesem Artikel wird die Verwendung der Komponente „Filter Based Feature Selection“ (Filterbasierte Featureauswahl) im Azure Machine Learning-Designer beschrieben. Diese Komponente unterstützt Sie bei der Identifizierung der Spalten mit der größten Vorhersagekraft in Ihrem Eingabedataset.
Grundsätzlich bezieht sich Feature Selection (Featureauswahl) auf die Anwendung statistischer Tests auf Eingaben, wenn eine Ausgabe angegeben ist. Das Ziel besteht in der Bestimmung der Spalten, die für die Ausgabe aussagekräftiger sind. Die Komponente „Filter Based Feature Selection“ (Filterbasierte Featureauswahl) stellt mehrere Algorithmen für die Featureauswahl bereit. Die Komponente umfasst Korrelationsmethoden wie die Pearson-Korrelation und Chi-Quadrat-Werte.
Bei der Komponente „Filter Based Feature Selection“ (Filterbasierte Featureauswahl) stellen Sie ein Dataset bereit und identifizieren die Spalte, die die Bezeichnung oder die abhängige Variable enthält. Anschließend geben Sie eine einzelne Methode an, die zum Messen der Featurerelevanz verwendet werden soll.
Die Komponente gibt ein Dataset aus, das die Spalten mit den bestgeeigneten Features (Merkmale) enthält, eingestuft nach Vorhersagekraft. Außerdem gibt das Modul die Namen der Merkmale und deren Scores aus der ausgewählten Metrik aus.
Grundlegende Informationen zur filterbasierten Featureauswahl
Diese Komponente für die Featureauswahl wird als „filterbasiert“ bezeichnet, da anhand der ausgewählten Metrik nach irrelevanten Attributen gesucht wird. Die redundanten Spalten werden dann aus Ihrem Modell herausgefiltert. Sie wählen eine einzelne statistisches Maßzahl aus, die Ihren Daten entspricht, und die Komponente berechnet einen Score (Bewertung) für jede Merkmalsspalte (Featurespalte). Die Spalten werden entsprechend der Einstufung ihrer Merkmalscores zurückgegeben.
Durch Auswahl der richtigen Merkmale können Sie möglicherweise die Genauigkeit und Effizienz der Klassifizierung verbessern.
In der Regel verwenden Sie nur die Spalten mit den besten Scores, um Ihr Vorhersagemodell zu erstellen. Spalten mit schwachen Merkmalauswahlscores können im Dataset verbleiben und beim Erstellen eines Modells ignoriert werden.
Auswählen einer Metrik zur Merkmalauswahl (Featureauswahl)
Die Komponente „Filter-Based Feature Selection“ (Filterbasierte Featureauswahl) stellt eine Vielzahl von Metriken zur Bewertung des Informationswerts jeder Spalte bereit. In diesem Abschnitt finden Sie eine allgemeine Beschreibung der einzelnen Metriken sowie Informationen zu deren Anwendung. Weitere Anforderungen für die Verwendung jeder Metrik finden Sie im Abschnitt Technische Hinweise und in der Anleitung zum Konfigurieren der jeweiligen Komponente.
Pearson-Korrelation
Die Pearson-Korrelation, auch der Korrelationskoeffizient, wird in statistischen Modellen auch als
r-Wert bezeichnet. Für zwei beliebige Variablen gibt er einen Wert zurück, der die Stärke der Korrelation angibt.Der Korrelationskoeffizient wird berechnet, indem die Kovarianz zweier Variablen durch das Produkt ihrer Standardabweichungen dividiert wird. Größenänderungen der beiden Variablen wirken sich nicht auf den Koeffizienten aus.
Chi-Quadrat
Der bidirektionale Chi-Quadrat-Test ist eine statistische Methode, die misst, wie nahe erwartete Werte den tatsächlichen Ergebnissen kommen. Für die Methode wird vorausgesetzt, dass Variablen zufällig sind und aus einer geeigneten Stichprobe unabhängiger Variablen entnommen werden. Das Ergebnis des Chi-Quadrat-Tests gibt an, wie weit Ergebnisse vom erwarteten (zufälligen) Ergebnis entfernt sind.
Tipp
Wenn Sie eine andere Option für eine benutzerdefinierte Featureauswahlmethode benötigen, verwenden Sie die Komponente Execute R Script (R-Skript ausführen).
Konfigurieren von „Filter Based Feature Selection“
Sie wählen eine standardmäßige Statistikmetrik aus. Die Komponente berechnet die Korrelation zwischen einem Spaltenpaar (Bezeichnungsspalte und Featurespalte).
Fügen Sie Ihrer Pipeline die Komponente „Filter-Based Feature Selection“ (Filterbasierte Featureauswahl) hinzu. Sie finden dieses Modul in der Kategorie Feature Selection (Featureauswahl) im Designer.
Stellen Sie eine Verbindung mit einem Eingabedataset her, das mindestens zwei Spalten enthält, die mögliche Merkmale (Features) sind.
Um sicherzustellen, dass eine Spalte analysiert und eine Featurebewertung generiert wird, verwenden Sie die Komponente Edit Metadata (Metadaten bearbeiten), um das Attribut IsFeature festzulegen.
Wichtig
Achten Sie darauf, dass es sich bei den Spalten, die Sie als Eingabe bereitstellen, um potenzielle Features handelt. Beispielsweise hat eine Spalte, die einen einzigen Wert enthält, keinen Informationswert.
Wenn Sie wissen, dass sich einige Spalten nicht als Features eignen, können Sie diese Spalten aus der Spaltenauswahl entfernen. Sie können auch die Komponente Edit Metadata (Metadaten bearbeiten) verwenden, um sie als Categorical (Kategorisch) zu kennzeichnen.
Wählen Sie für Feature scoring method (Featurebewertungsmethode) eine der folgenden bewährten statistischen Methoden aus, die für das Berechnen von Bewertungen (Scores) verwendet werden soll.
Methode Requirements (Anforderungen) Pearson-Korrelation Die Bezeichnung kann ein Text- oder numerischer Wert sein. Merkmale müssen numerisch sein. Chi-Quadrat Bezeichnungen und Merkmale können Text- oder numerische Werte sein. Verwenden Sie diese Methode, um die Featurerelevanz für zwei Kategoriespalten zu berechnen. Tipp
Wenn Sie die ausgewählte Metrik ändern, werden alle anderen Optionen zurückgesetzt. Legen Sie diese Option daher zuerst fest.
Aktivieren Sie die Option Operate on feature columns only (Nur Featurespalten verarbeiten), um nur für die Spalten, die zuvor als Features gekennzeichnet wurden, einen Score zu generieren.
Wenn Sie diese Option deaktivieren, erstellt die Komponente einen Score für jede Spalte, die die Kriterien ansonsten erfüllt – bis zur Anzahl von Spalten, die in Number of desired features (Anzahl gewünschter Features) angegeben ist.
Wählen Sie unter Target column (Zielspalte) die Option Launch column selector (Spaltenauswahl starten) aus, um die Bezeichnungsspalte entweder anhand des Namens oder anhand des Index auszuwählen. (Indizes sind einsbasiert.)
Eine Bezeichnungsspalte ist für alle Methoden erforderlich, die eine statistische Korrelation einschließen. Die Komponente gibt einen Entwurfszeitfehler zurück, wenn Sie keine Bezeichnungsspalte oder mehrere Bezeichnungsspalten auswählen.Geben Sie für Number of desired features (Anzahl gewünschter Features) die Anzahl von Featurespalten ein, die als Ergebnis zurückgegeben werden sollen:
Die kleinste zulässige Anzahl von Features ist „1“, es empfiehlt sich aber, diesen Wert zu erhöhen.
Ist die angegebene Anzahl gewünschter Features größer als die Anzahl von Spalten im Dataset, werden alle Features zurückgegeben. Dies schließt auch Features mit dem Score „0“ ein.
Wenn Sie weniger Ergebnisspalten angeben, als Featurespalten vorhanden sind, werden die Features nach absteigendem Score sortiert. In diesem Fall werden nur die Features mit dem höchsten Score zurückgegeben.
Übermitteln Sie die Pipeline.
Wichtig
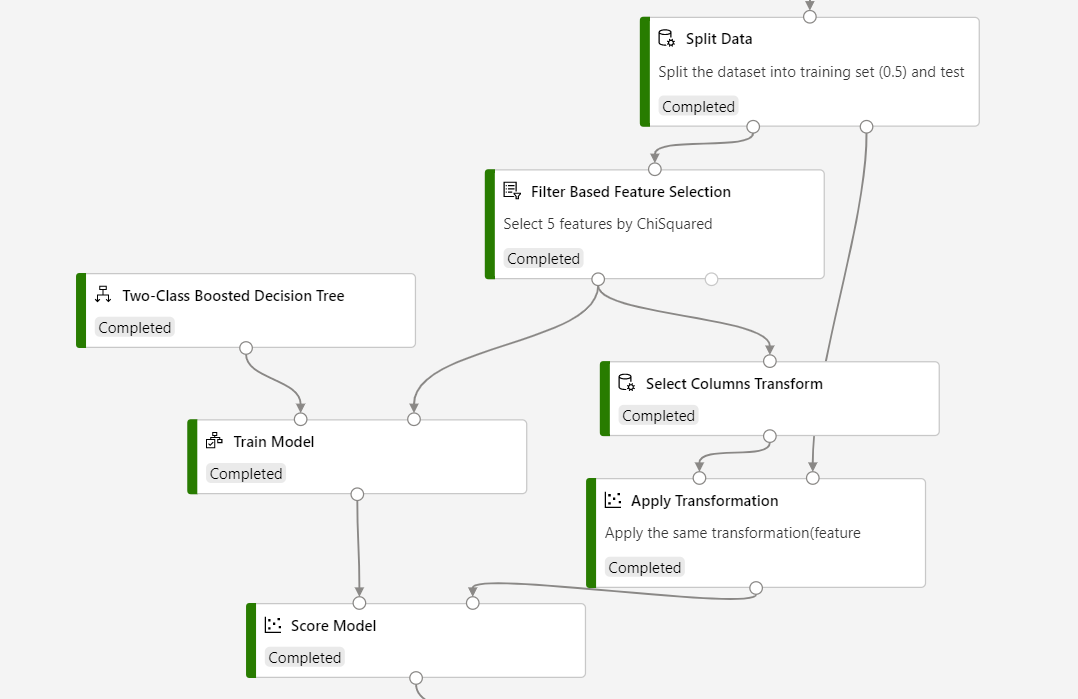
Wenn Sie für den Rückschluss die Filter Based Feature Selection (Filterbasierte Featureauswahl) verwenden möchten, müssen Sie Select Columns Transform (Auswählen der Spaltentransformation) verwenden, um das vom Feature ausgewählte Ergebnis zu speichern, sowie Apply Transformation (Anwenden einer Transformation), um die vom Feature ausgewählte Transformation auf das Bewertungsdataset anzuwenden.
Auf dem folgenden Screenshot finden Sie Informationen zum Erstellen Ihrer Pipeline, um sicherzustellen, dass die Spaltenauswahl für den Bewertungsprozess identisch ist.
Ergebnisse
Nach Abschluss der Verarbeitung:
Sollen die vollständige Liste der analysierten Featurespalten sowie deren Scores angezeigt werden, klicken Sie mit der rechten Maustaste auf die Komponente, und wählen Sie Visualisieren aus.
Soll das Dataset angezeigt werden, das auf Ihren Featureauswahlkriterien basiert, klicken Sie mit der rechten Maustaste auf die Komponente, und wählen Sie Visualisieren aus.
Enthält das Dataset weniger Spalten als erwartet, überprüfen Sie die Komponenteneinstellungen. Überprüfen Sie außerdem die Datentypen der Spalten, die als Eingabe bereitgestellt wurden. Wenn Sie beispielsweise Number of desired features auf 1 festgelegt haben, enthält das Ausgabedataset nur zwei Spalten: die Bezeichnungsspalte und die Featurespalte mit der höchsten Einstufung.
Technische Hinweise
Details zur Implementierung
Wenn Sie eine Pearson-Korrelation für ein numerisches Feature und eine Kategoriebezeichnung verwenden, wird der Featurescore wie folgt berechnet:
Für jede Ebene in der Kategoriespalte wird der bedingte Erwartungswert der numerischen Spalte berechnet.
Die Spalte der bedingten Erwartungswerte wird mit der numerischen Spalte korreliert.
Requirements (Anforderungen)
Ein Featureauswahlscore kann nicht für eine Spalte generiert werden, die als Spalte vom Typ Bezeichnung oder Score festgelegt ist.
Wenn Sie versuchen, eine Bewertungsmethode mit einer Spalte eines Datentyps zu verwenden, der von der Methode nicht unterstützt wird, löst die Komponente einen Fehler aus. oder der Spalte wird ein Score mit einem Nullwert zugewiesen.
Enthält eine Spalte logische Werte (true/false), werden diese als
True = 1bzw.False = 0verarbeitet.Eine Spalte kann kein Feature sein, wenn sie als Spalte vom Typ Bezeichnung oder Score festgelegt wurde.
Vorgehensweise, wenn Werte fehlen
Eine Spalte, die keine Werte enthält, kann nicht als Zielspalte (Bezeichnungsspalte) angegeben werden.
Enthält eine Spalte fehlende Werte, ignoriert die Komponente sie beim Berechnen der Bewertung für die Spalte.
Wenn eine Spalte, die als Featurespalte festgelegt ist, alle fehlenden Werte aufweist, weist die Komponente eine Bewertung von 0 (null) zu.
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.