Komponente Partition und Probe
Dieser Artikel beschreibt eine Komponente im Azure Machine Learning Designer.
Verwenden Sie die Komponente "Partitionierung und Stichprobe", um Stichproben in einem Datensatz durchzuführen oder um Partitionen aus Ihrem Datensatz zu erstellen.
Die Stichprobenentnahme ist ein wichtiges Tool beim maschinellen Lernen. Sie ermöglicht es Ihnen, ein Dataset zu verkleinern, gleichzeitig aber dasselbe Verhältnis von Werten beizubehalten. Diese Komponente unterstützt mehrere verwandte Aufgaben, die beim maschinellen Lernen wichtig sind:
Unterteilen Ihrer Daten in mehrere Unterabschnitte derselben Größe.
Sie könnten die Partitionen für Kreuzvalidierung verwenden oder um zufälligen Gruppen Fälle zuzuweisen.
Aufteilen von Daten in Gruppen und anschließendes Arbeiten mit Daten aus einer bestimmten Gruppe.
Nachdem Sie verschiedenen Gruppen Fälle nach dem Zufallsprinzip zugewiesen haben, müssen Sie möglicherweise die Features ändern, die nur einer einzigen Gruppe zugeordnet sind.
Stichprobenentnahme.
Sie können einen Prozentsatz der Daten extrahieren, eine zufällige Stichprobenentnahme anwenden oder eine Spalte auswählen, um sie zum Ausgleichen des Datasets und zur Durchführung einer geschichteten Stichprobenentnahme an dessen Werten zu verwenden.
Erstellen eines kleineren Datasets zum Testen.
Bei einer großen Datenmenge möchten Sie beim Einrichten der Pipeline möglicherweise nur die ersten n Zeilen verwenden und dann beim Erstellen Ihres Modells zur Verwendung des vollständigen Datasets wechseln. Sie können die Stichprobenentnahme auch verwenden, um ein kleineres Dataset für den Einsatz in der Entwicklung zu erstellen.
Konfigurieren Sie die Komponente
Diese Komponente unterstützt die folgenden Methoden zur Aufteilung Ihrer Daten in Partitionen oder für Stichproben. Wählen Sie zuerst die Methode, und legen Sie dann zusätzliche Optionen fest, die für diese Methode erforderlich sind.
- Head
- Stichproben
- Zuweisen zu Folds
- Fold aussuchen
Abrufen der obersten n Zeilen aus einem Dataset
Verwenden Sie diesen Modus, um nur die ersten n Zeilen abzurufen. Diese Option ist hilfreich, wenn Sie eine Pipeline für eine kleine Anzahl von Zeilen testen möchten und die Daten nicht ausgeglichen oder in irgendeiner Form für eine Stichprobenentnahme verfügbar sein müssen.
Fügen Sie die Komponenten Partition und Sample zu Ihrer Pipeline in der Schnittstelle hinzu und verbinden Sie das Dataset.
Partition or sample mode (Partitions- oder Stichprobenmodus): Legen Sie diese Option auf Head (Anfang) fest.
Number of rows to select (Anzahl der auszuwählenden Zeilen): Geben Sie die Anzahl der zurückzugebenden Zeilen ein.
Die Anzahl der Zeilen muss eine nicht negative ganze Zahl sein. Wenn die Anzahl der ausgewählten Zeilen größer als die Anzahl der Zeilen im Dataset ist, wird das ganze Dataset zurückgegeben.
Übermitteln Sie die Pipeline.
Die Komponente gibt einen einzelnen Datensatz aus, der nur die angegebene Anzahl von Zeilen enthält. Die Zeilen werden immer aus dem Anfang des Datasets gelesen.
Erstellen einer Stichprobe von Daten
Diese Option unterstützt einfache Zufallsstichproben oder geschichtete Zufallsstichproben. Dies ist hilfreich, wenn Sie ein kleineres repräsentatives Stichproben-Dataset zum Testen erstellen möchten.
Fügen Sie die Komponenten Partition und Sample zu Ihrer Pipeline hinzu, und verbinden Sie den Datensatz.
Partition or sample mode (Partitions- oder Stichprobenmodus): Legen Sie diese Option auf Sampling (Stichprobenentnahme) fest.
Rate of Sampling (Stichprobenrate): Geben Sie einen Wert zwischen 0 und 1 ein. Dieser Wert gibt den Prozentsatz von Zeilen aus dem Quelldataset an, der in das Ausgabedataset einbezogen werden soll.
Wenn Sie beispielsweise nur die Hälfte des ursprünglichen Datasets einbeziehen möchten, geben Sie durch Eingabe von
0.5an, dass die Stichprobenrate 50 % betragen soll.Die Zeilen des Eingabedatasets werden gemischt und – entsprechend der angegebenen Rate – selektiv in das Ausgabedataset eingefügt.
Random seed for sampling (Zufälliger Ausgangswert für Stichprobenentnahme): Geben Sie optional eine Ganzzahl ein, die als Ausgangswert verwendet werden soll.
Diese Option ist wichtig, wenn die Zeilen immer auf dieselbe Weise unterteilt werden sollen. Der Standardwert ist 0, was bedeutet, dass ein Ausgangswert anhand der Systemuhr generiert wird. Dieser Wert kann bei jeder Ausführung der Pipeline zu geringfügig unterschiedlichen Ergebnissen führen.
Stratified split for sampling (Geschichtete Aufteilung für die Stichprobenentnahme): Wählen Sie diese Option aus, wenn es wichtig ist, dass die Zeilen im Dataset vor der Stichprobenentnahme anhand einer Schlüsselspalte gleichmäßig aufgeteilt werden sollen.
Wählen Sie für Stratification key column for sampling (Schichtungsschlüsselspalte für Stichprobenentnahme) eine einzelne strata column (Schichtspalte) aus. Die Zeilen im Dataset werden dann folgendermaßen unterteilt:
Alle Eingabezeilen werden nach den Werten in der angegebenen Schichtspalte gruppiert (geschichtet).
Zeilen werden in den einzelnen Gruppen gemischt.
Jede Gruppe wird dem Ausgabedataset selektiv hinzugefügt, um das angegebene Verhältnis zu erfüllen.
Übermitteln Sie die Pipeline.
Mit dieser Option gibt die Komponente einen einzigen Datensatz aus, der eine repräsentative Stichprobe der Daten enthält. Der verbleibende Teil ohne Stichprobenentnahme des Datasets wird nicht ausgegeben.
Aufteilen von Daten in Partitionen
Verwenden Sie diese Option, wenn Sie das Dataset in Teilmengen der Daten unterteilen möchten. Diese Option ist auch hilfreich, wenn Sie eine benutzerdefinierte Anzahl von Folds für Kreuzvalidierung erstellen oder Zeilen in mehrere Gruppen aufteilen möchten.
Fügen Sie die Komponenten Partition und Sample zu Ihrer Pipeline hinzu, und verbinden Sie den Datensatz.
Wählen Sie für Partition or sample mode (Partitions- oder Stichprobenmodus) die Option Assign to Folds (Zu Folds zuweisen) aus.
Use replacement in the partitioning (Ersetzung bei der Partitionierung verwenden): Wählen Sie diese Option aus, wenn die Zeile nach der Stichprobenentnahme wieder in den Pool von Zeilen (für eine mögliche Wiederverwendung) eingefügt werden soll. Dies kann dazu führen, dass dieselbe Zeile möglicherweise mehreren Folds zugewiesen wird.
Wenn Sie keine Ersetzung (die Standardoption) verwenden, wird die Zeile nach der Stichprobenentnahme nicht wieder in den Pool von Zeilen (für eine mögliche Wiederverwendung) eingefügt. Infolgedessen kann jede Zeile nur einem einzigen Fold zugewiesen werden.
Randomized split (Aufteilung in Zufallsreihenfolge): Wählen Sie diese Option aus, wenn Zeilen Folds in Zufallsreihenfolge zugewiesen werden sollen.
Wenn Sie diese Option nicht auswählen, werden Zeilen Folds mit der Roundrobin-Methode zugewiesen.
Random seed (Zufälliger Ausgangswert): Geben Sie optional eine ganze Zahl ein, die als Ausgangswert verwendet werden soll. Diese Option ist wichtig, wenn die Zeilen immer auf dieselbe Weise unterteilt werden sollen. Andernfalls bedeutet der Standardwert 0, dass ein zufälliger Ausgangswert verwendet wird.
Specify the partitioner method (Die Partitionierermethode angeben): Geben Sie mit den folgenden Optionen an, wie Daten auf jede Partition aufgeteilt werden sollen:
Partition evenly (Gleichmäßig partitionieren): Verwenden Sie diese Option, um in jeder Partition die gleiche Anzahl von Zeilen zu platzieren. Wenn Sie die Anzahl der Ausgabepartitionen angeben möchten, geben Sie im Feld Specify number of folds to split evenly into (Anzahl der Folds, in die gleichmäßig aufgeteilt werden soll) eine ganze Zahl ein.
Partition with customized proportion (Mit angepassten Anteilen partitionieren): Verwenden Sie diese Option, um die Größe jeder Partition als eine durch Trennzeichen getrennte Liste anzugeben.
Angenommen, Sie möchten drei Partitionen erstellen. Die erste Partition enthält 50 % der Daten. Die verbleibenden zwei Partitionen enthalten jeweils 25 % der Daten. Geben Sie in das Feld List of proportions separated by comma (Liste der durch Komma getrennten Anteile) diese Werte ein: 0,5, 0,25, 0,25.
Die Summe aller Partitionsgrößen muss genau „1“ ergeben.
Wenn Sie Zahlen eingeben, deren Summe kleiner als 1 ist, wird eine zusätzliche Partition zur Aufnahme der verbleibenden Zeilen erstellt. Wenn Sie beispielsweise die Werte 0,2 und 0,3 eingeben, wird eine dritte Partition zur Aufnahme der verbleibenden 50 % aller Zeilen erstellt.
Wenn Sie Zahlen eingeben, deren Summe größer als 1 ist, wird bei Ausführung der Pipeline ein Fehler ausgelöst.
Stratified split (Geschichtete Aufteilung): Wählen Sie diese Option aus, wenn die Zeilen beim Aufteilen geschichtet werden sollen, und wählen Sie dann die strata column (Schichtspalte) aus.
Übermitteln Sie die Pipeline.
Mit dieser Option gibt die Komponente mehrere Datensätze aus. Die Datasets werden gemäß den von Ihnen angegebenen Regeln partitioniert.
Verwenden von Daten aus einer vordefinierten Partition
Wählen Sie diese Option, wenn Sie ein Dataset in mehrere Partitionen unterteilt haben und jetzt jede Partition zur weiteren Analyse oder Verarbeitung laden möchten.
Fügen Sie der Pipeline die Komponenten Partition und Sample hinzu.
Verbinde die Komponente mit dem Ausgang einer vorherigen Instanz von Partition und Sample. Diese Instanz muss die Option Assign to Folds (Zu Folds zuweisen) verwendet haben, um eine Anzahl von Partitionen zu generieren.
Partition or sample mode(Partitions- oder Stichprobenmodus): Wählen Sie Pick Fold (Fold auswählen) aus.
Specify which fold to be sampled from (Angeben, aus welchem Fold Stichproben entnommen werden sollen): Wählen Sie die gewünschte Partition aus, indem Sie deren Index eingeben. Partitionsindizes sind 1-basiert. Wenn Sie das Dataset beispielsweise in drei Teile unterteilt haben, hätten die Partitionen die Indizes „1“, „2“ und „3“.
Wenn Sie einen ungültigen Indexwert eingeben, wird der folgende Entwurfszeitfehler ausgelöst: „Error 0018: Dataset contains invalid data.“ (Fehler 0018: Dataset enthält ungültige Daten.)
Zusätzlich zum Gruppieren des Datasets nach Folds können Sie es in zwei Gruppen aufteilen: einen Zielfold und alles andere. Geben Sie dazu den Index eines einzelnen Folds ein, und wählen Sie die Option Pick complement of the selected fold (Komplement des ausgewählten Folds aussuchen) aus, um alles außer den Daten in den angegebenen Fold abzurufen.
Wenn Sie mit mehreren Partitionen arbeiten, müssen Sie mehrere Instanzen der Komponenten Partition und Sample hinzufügen, um jede Partition zu behandeln.
Zum Beispiel wird die Komponente Partition and Sample in der zweiten Reihe auf Zuweisung zu Falten und die Komponente in der dritten Reihe auf Auswahl Falten gesetzt.
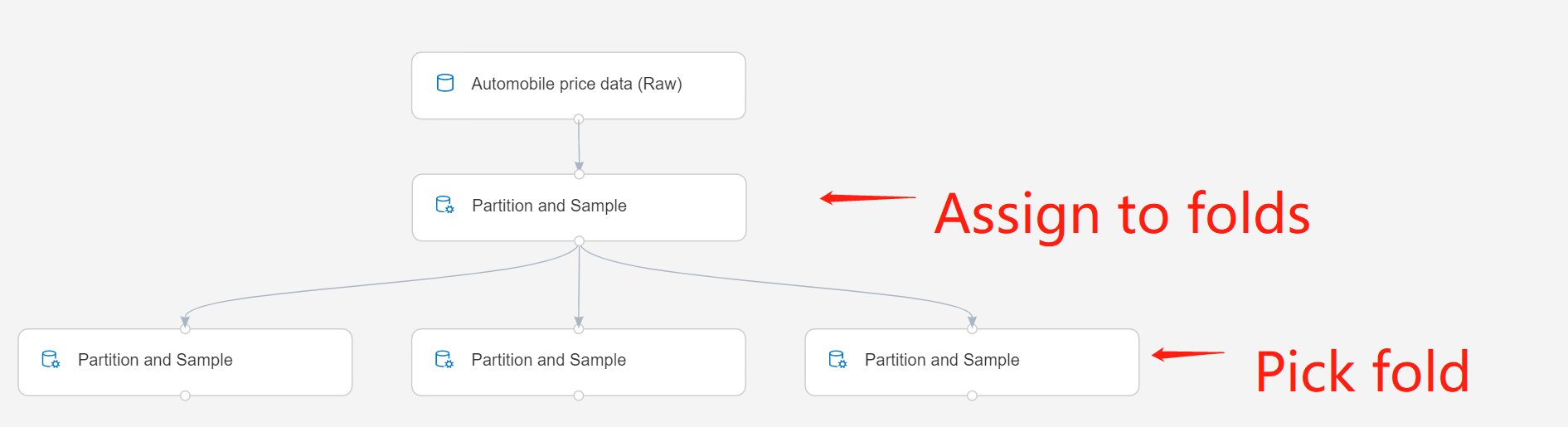
Übermitteln Sie die Pipeline.
Mit dieser Option gibt die Komponente einen einzigen Datensatz aus, der nur die Zeilen enthält, die dieser Falte zugeordnet sind.
Hinweis
Die Foldbezeichnungen können nicht direkt angezeigt werden. Sie sind nur in den Metadaten vorhanden.
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.