Select Columns Transform
In diesem Artikel wird die Verwendung der Komponente „Select Columns Transform“ (Auswählen der Spaltentransformation) im Azure Machine Learning-Designer beschrieben. Der Zweck der Komponente „Select Columns Transform“ besteht darin sicherzustellen, dass für alle weiteren Machine Learning-Vorgänge ein vorhersagbarer, einheitlicher Satz von Spalten verwendet wird.
Diese Komponente ist nützlich für Aufgaben wie Bewertungen, für die spezifische Spalten erforderlich sind. Änderungen in den verfügbaren Spalten können die Pipeline unterbrechen oder die Ergebnisse ändern.
Sie verwenden das Modul „Select Columns Transform“, um einen Satz von Spalten zu erstellen und zu speichern. Danach verwenden Sie die Komponente Apply Transformation (Anwenden einer Transformation), um diese Auswahl auf neue Daten anzuwenden.
Verwenden von „Select Columns Transform“
In diesem Szenario wird davon ausgegangen, dass Sie die Featureauswahl verwenden möchten, um einen dynamischen Satz von Spalten zu generieren, die zum Trainieren eines Modells verwendet werden sollen. Um sicherzustellen, dass die Spaltenauswahl für den Bewertungsprozess identisch ist, verwenden Sie die Komponente „Select Columns Transform“, um die Spaltenauswahl zu erfassen und diese Auswahl an anderer Stelle in der Pipeline anzuwenden.
Fügen Sie Ihrer Pipeline im Designer ein Eingabedataset hinzu.
Fügen Sie eine Instanz von Filter Based Feature Selection (Filterbasierte Featureauswahl) hinzu.
Verbinden Sie die Komponenten und konfigurieren Sie die Komponente „Feature Selection“, damit im Eingabedataset automatisch eine Reihe von optimalen Features gefunden wird.
Fügen Sie eine Instanz von Train Model (Trainieren eines Modells) hinzu, und verwenden Sie die Ausgabe von Filter Based Feature Selection als Eingabe für das Training.
Wichtig
Weil die Featurerelevanz auf den Werten in der Spalte basiert, können Sie nicht im Voraus wissen, welche Spalten unter Umständen als Eingabe für Train Model verfügbar sind.
Fügen Sie eine Instanz der Komponente „Select Columns Transform“ hinzu.
Mit diesem Schritt wird eine Spaltenauswahl als Transformation generiert, die gespeichert oder auf andere Datasets angewendet werden kann. In diesem Schritt wird sichergestellt, dass die Spalten, die bei der Featureauswahl ermittelt wurden, gespeichert werden, damit sie von anderen Komponenten wiederverwendet werden können.
Hinzufügen der Komponente Score Model (Modell bewerten).
Stellen Sie keine Verbindung mit dem Eingabedataset her. Fügen Sie stattdessen die Komponente Apply Transformation hinzu und verbinden Sie die Ausgabe der Featureauswahl-Transformation.
Die Pipelinestruktur sollte wie folgt aussehen:
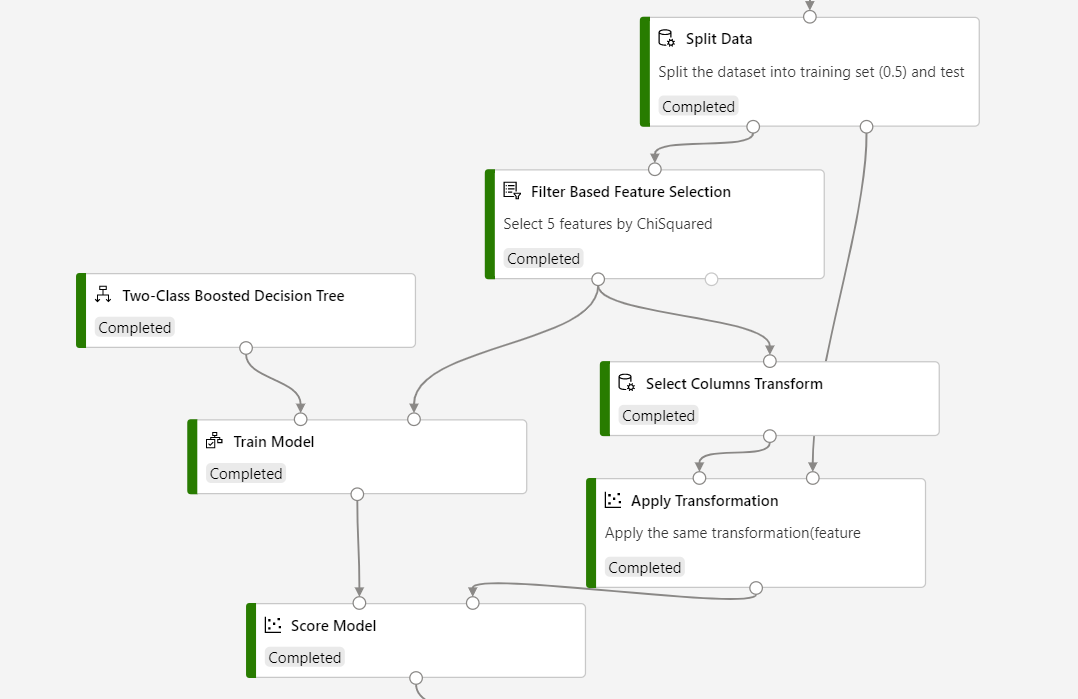
Wichtig
Wenn Sie Filter Based Feature Selection auf das Bewertungsdataset anwenden, können Sie nicht erwarten, dass dieselben Ergebnisse erzielt werden. Da die Featureauswahl auf Werten basiert, wird dabei unter Umständen ein anderer Satz von Spalten ausgewählt, was dazu führt, dass der Bewertungsvorgang fehlschlägt.
Übermitteln Sie die Pipeline.
Durch diese Vorgehensweise mit Speichern und anschließendem Anwenden einer Spaltenauswahl wird sichergestellt, dass für das Training und die Bewertung dasselbe Datenschema verfügbar ist.
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.