Komponente „Train Model“ (Modell trainieren)
In diesem Artikel wird eine Komponente im Azure Machine Learning-Designer beschrieben.
Verwenden Sie diese Komponente, um ein Klassifizierungs- oder Regressionsmodell zu trainieren. Das Training findet statt, nachdem Sie ein Modell definiert und die zugehörigen Parameter festgelegt haben. Für das Training werden markierte Daten benötigt. Darüber hinaus können Sie Train Model auch verwenden, um ein bestehendes Modell erneut anhand neuer Daten zu trainieren.
So funktioniert der Trainingsprozess
In Azure Machine Learning werden Machine Learning-Modelle in der Regel in einem dreistufigen Prozess erstellt und verwendet.
Um ein Modell zu konfigurieren, wählen Sie einen bestimmten Algorithmustyp aus und definieren dann die zugehörigen Parameter oder Hyperparameter. Wählen Sie einen der folgenden Modelltypen:
- Klassifizierungsmodelle auf der Basis neuronaler Netze, Entscheidungsstrukturen und Entscheidungswälder sowie weitere Algorithmen
- Regressionsmodelle, die lineare Standardregressionen umfassen können, oder die andere Algorithmen wie neuronale Netze und bayessche Regressionen verwenden
Geben Sie ein Dataset an, das mit einer Bezeichnung versehen wurde und über Daten verfügt, die mit dem Algorithmus kompatibel sind. Verbinden Sie sowohl die Daten als auch das Modell mit Train Model.
Beim Training wird ein bestimmtes Binärformat namens iLearner erstellt, in dem die aus den Daten abgeleiteten Statistikmuster gekapselt sind. Es ist nicht möglich, dieses Format direkt zu ändern oder zu lesen. Das trainierte Modell kann jedoch von anderen Komponenten verwendet werden.
Darüber hinaus können Sie die Eigenschaften des Modells anzeigen. Weitere Informationen finden Sie im Abschnitt „Ergebnisse“.
Nach Abschluss des Trainings verwenden Sie das trainierte Modell mit einer der Bewertungskomponenten, um Vorhersagen für neue Daten zu treffen.
Gewusst wie: Verwenden von „Train Model“
Fügen Sie der Pipeline die Komponente Train Model (Modell trainieren) hinzu. Sie finden diese Komponente unter der Kategorie Machine Learning. Erweitern Sie Trainieren, und ziehen Sie dann die Komponente Train Model (Modell trainieren) in Ihre Pipeline.
Fügen Sie den untrainierten Modus an die linke Eingabe an. Fügen Sie das Trainingsdataset an die rechte Eingabe von Train Model an.
Das Trainingsdataset muss eine Bezeichnungsspalte enthalten. Zeilen ohne Bezeichnung werden ignoriert.
Klicken Sie für Label column (Bezeichnungsspalte) im rechten Bereich der Komponente auf Launch column selector (Spaltenauswahl starten), und wählen Sie eine einzelne Spalte mit Ergebnissen aus, die vom Modell zu Trainingszwecken verwendet werden können.
Bei Klassifizierungsproblemen muss die Bezeichnungsspalte entweder kategorische oder diskrete Werte enthalten. Einige Beispiele sind: Ja/keine Bewertung, ein Code oder ein Name zur Klassifizierung von Krankheiten oder eine Gehaltsgruppe. Wenn Sie eine Spalte mit nicht kategorischen Werten auswählen, gibt die Komponente während des Trainings einen Fehler zurück.
Bei Regressionsproblemen muss die Bezeichnungsspalte numerische Daten enthalten, die die Antwortvariable darstellen. Im Idealfall stellen die numerischen Daten eine fortlaufende Skala dar.
Beispiele sind: eine Kreditrisikobewertung, die prognostizierte Zeit bis zum Ausfall einer Festplatte oder die vorausgesagte Anzahl von Call-Center-Anrufen an einem bestimmten Tag oder zu einer bestimmten Uhrzeit. Wenn Sie keine numerische Spalte auswählen, kann dies zu einem Fehler führen.
- Wenn Sie die zu verwendende Bezeichnungsspalte nicht angeben, versucht Azure Machine Learning, die geeignete Bezeichnungsspalte anhand der Metadaten des Datasets abzuleiten. Wenn die falsche Spalte ausgewählt wird, korrigieren Sie dies mithilfe der Spaltenauswahl.
Tipp
Tipps zur richtigen Verwendung der Spaltenauswahl finden Sie im Artikel zum Auswählen von Spalten im Dataset. Dort werden einige häufige Szenarien beschrieben, und Sie erhalten Tipps zur Verwendung der Optionen WITH RULES und BY NAME.
Übermitteln Sie die Pipeline. Wenn Sie über eine große Datenmenge verfügen, kann dies eine Weile dauern.
Wichtig
Wenn Sie über eine ID-Spalte mit den IDs aller Zeilen oder eine Textspalte mit zu vielen eindeutigen Werten verfügen, tritt bei Train Model möglicherweise ein Fehler wie dieser auf: Anzahl der eindeutigen Werte in der Spalte "{Spaltenname}" ist größer als zulässig.
Dies liegt daran, dass -Spalte den Schwellenwert für eindeutige Werte erreicht hat und möglicherweise den Arbeitsspeicher überlastet. Sie können Metadaten bearbeiten verwenden, um diese Spalte als Feature bereinigen zu markieren, sodass sie im Training nicht verwendet wird. Sie können auch die Komponente Extract N-Gram Features from Text (N-Gramm-Features aus Text extrahieren) verwenden, um eine Vorverarbeitung der Textspalte durchzuführen. Weitere Fehlerinformationen finden Sie unter Designer-Fehlercodes.
Interpretierbarkeit von Modellen
Die Interpretierbarkeit von Modellen bietet die Möglichkeit, das ML-Modell zu verstehen und die zugrunde liegende Basis für die Entscheidungsfindung auf eine Weise darzustellen, die für Menschen verständlich ist.
Derzeit unterstützt die Komponente Train Model (Modell trainieren) die Verwendung des Interpretierbarkeitspakets zum Erläutern von ML-Modellen. Folgende integrierte Algorithmen werden unterstützt:
- Lineare Regression
- Regression mit neuronalen Netzwerken
- Regression mit verstärkter Entscheidungsstruktur
- Entscheidungswaldregression
- Poisson-Regression
- Logistische Regression mit zwei Klassen
- Two-Class Support Vector Machine
- Verstärkte Entscheidungsstruktur mit zwei Klassen
- Entscheidungswald mit zwei Klassen
- Entscheidungswald mit mehreren Klassen
- Logistische Regression mit mehreren Klassen
- Neuronales Netz mit mehreren Klassen
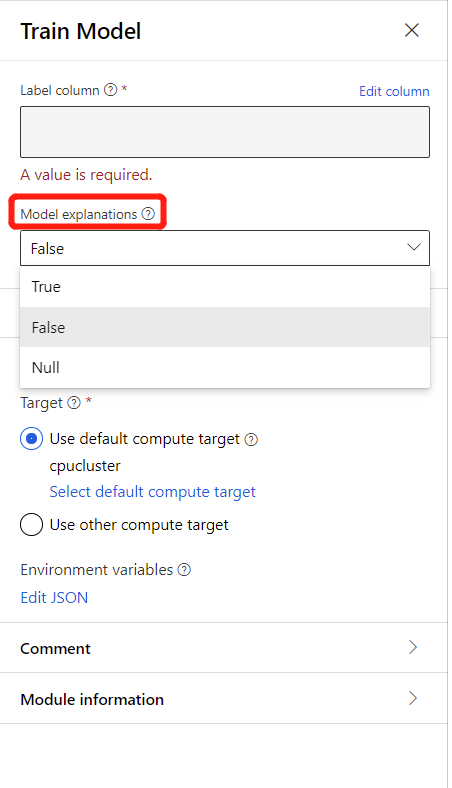
Zum Generieren von Modellerklärungen können Sie in der Dropdownliste Model Explanation (Modellerklärung) in der Komponente „Train Model“ (Modell trainieren) die Option True auswählen. Standardmäßig ist der Wert in der Komponente Train Model (Modell trainieren) auf FALSE festgelegt. Hinweis: Durch die Generierung von Erklärungen entstehen zusätzliche Computekosten.
Nach Abschluss der Pipelineausführung können Sie auf der rechten Seite der Komponente Train Model (Modell trainieren) die Registerkarte Erklärungen aufrufen und sich die Informationen zur Modellleistung, zum Dataset und zur Featurerelevanz ansehen.
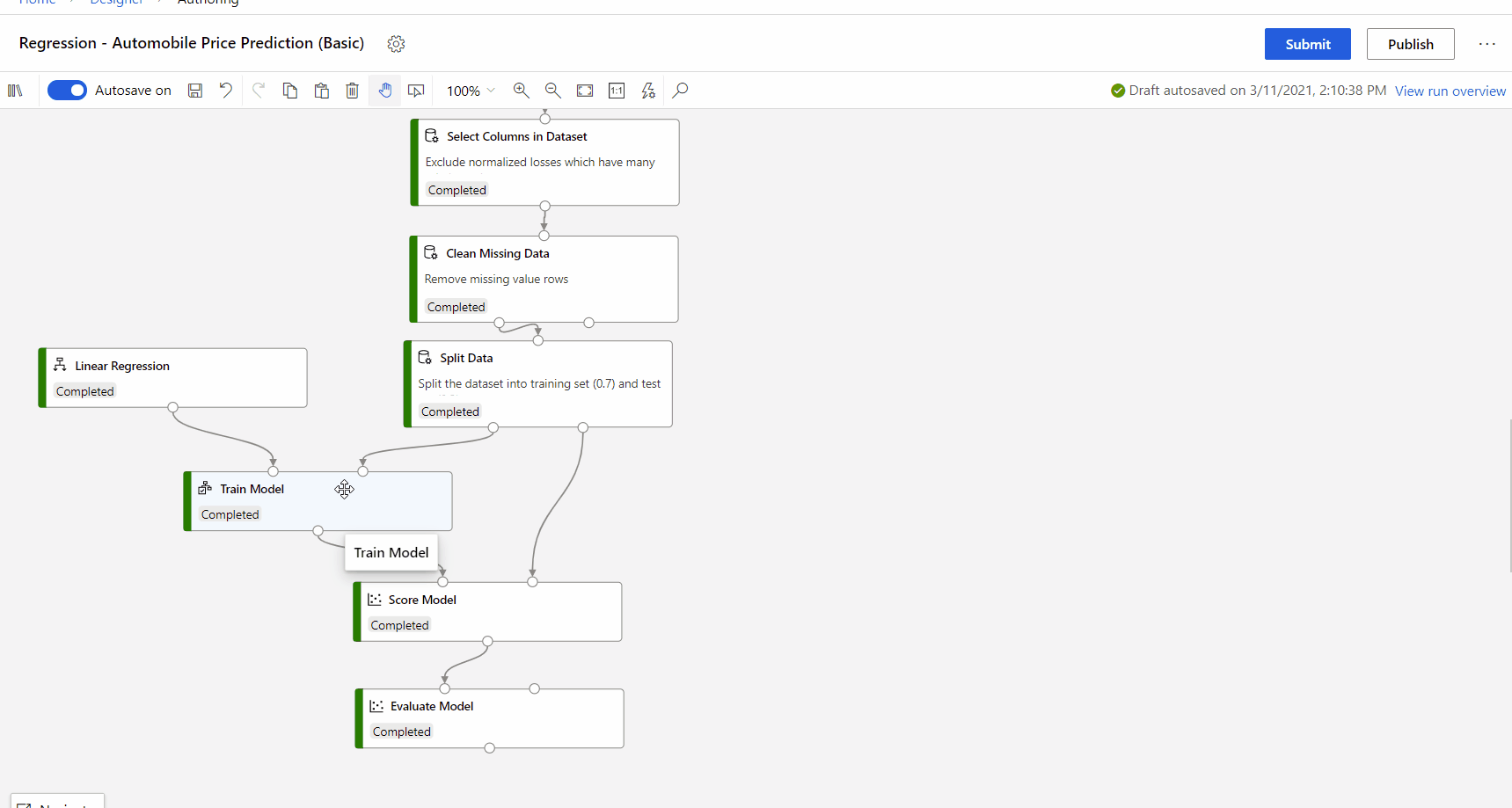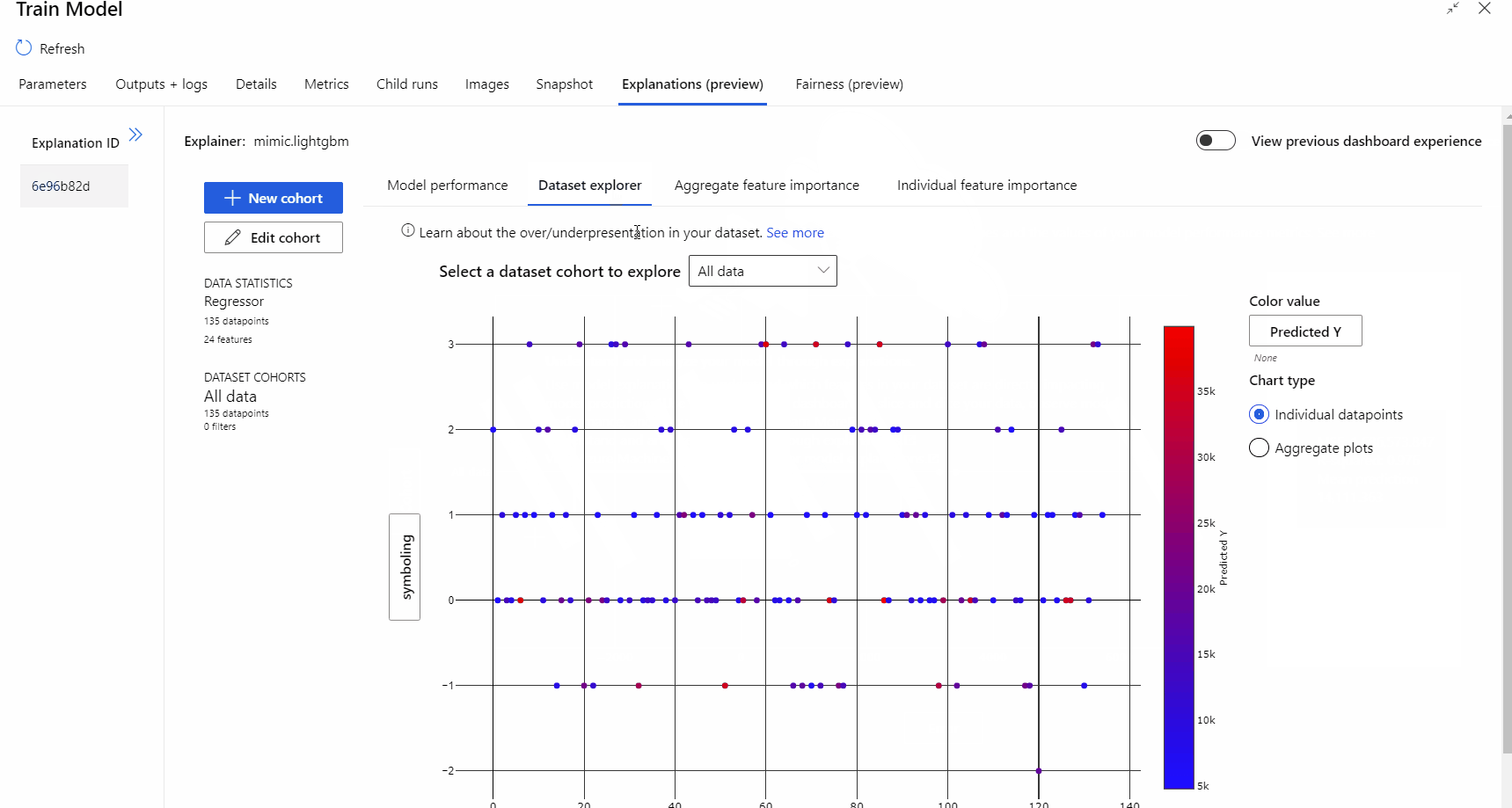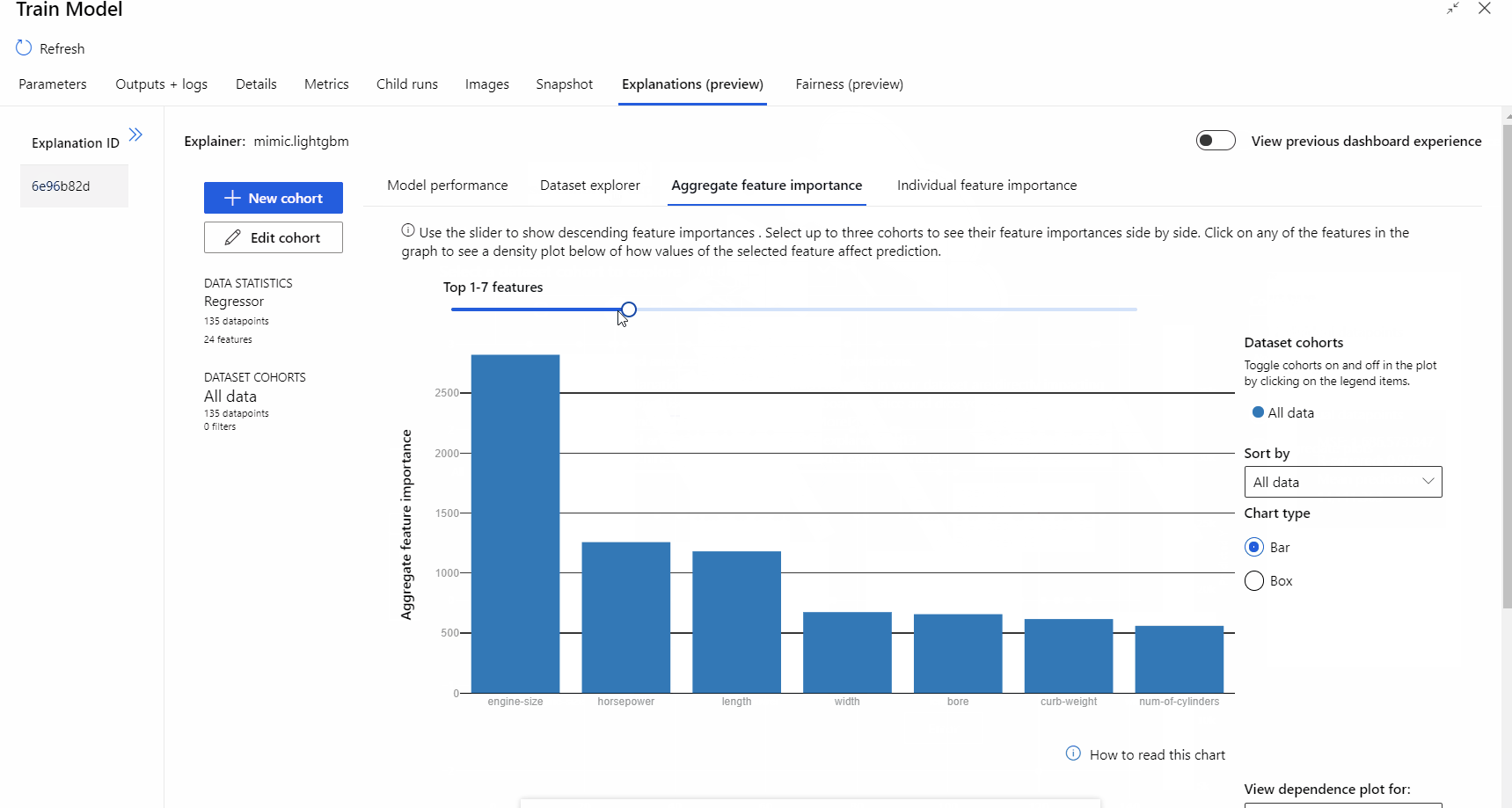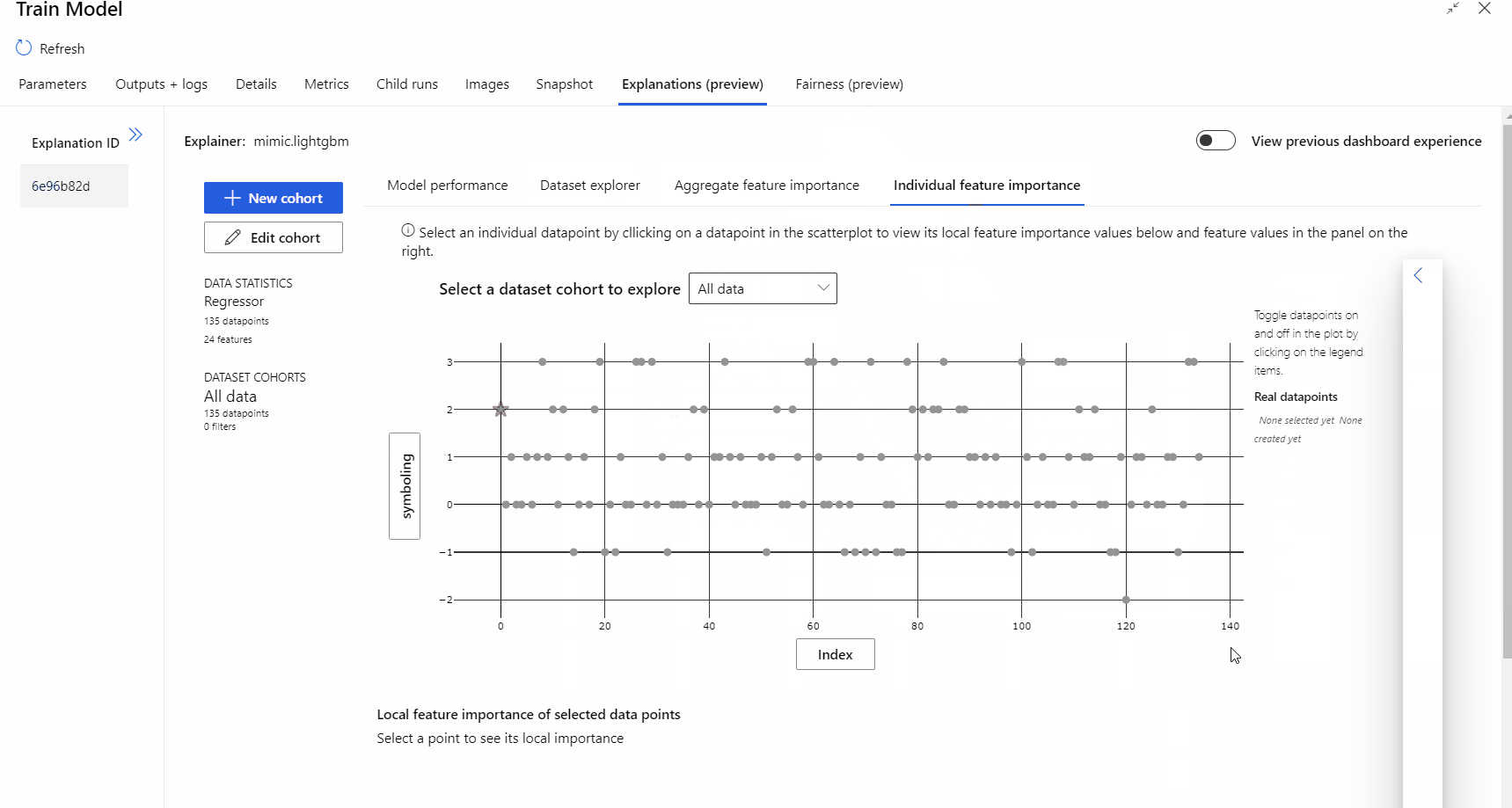
Weitere Informationen zur Verwendung von Modellerklärungen in Azure Machine Learning finden Sie im Artikel zum Interpretieren von ML-Modellen.
Ergebnisse
Nachdem das Modell trainiert wurde:
Um das Modell in anderen Pipelines zu verwenden, wählen Sie die Komponente aus, und wählen Sie dann im rechten Bereich unter der Registerkarte Ausgaben das Symbol Register dataset (Dataset registrieren) aus. Sie können in der Komponentenpalette unter Datasets auf gespeicherte Modelle zugreifen.
Um das Modell zur Vorhersage neuer Werte zu verwenden, verbinden Sie es mit der Komponente Score Model (Modell bewerten) sowie mit neuen Eingabedaten.
Nächste Schritte
Hier finden Sie die für Azure Machine Learning verfügbaren Komponenten.