Automatisiertes maschinelles Lernen (AutoML)?
GILT FÜR: Python SDK azureml v1
Python SDK azureml v1
Automatisiertes maschinelles Lernen, auch als automatisiertes ML oder AutoML bezeichnet, ist der Prozess der Automatisierung von zeitaufwändigen, iterativen Aufgaben bei der Entwicklung eines Machine Learning-Modells. Es versetzt Data Scientists, Analysten und Entwickler in die Lage, ML-Modelle mit hoher Skalierbarkeit, Effizienz und Produktivität zu erstellen und gleichzeitig die Modellqualität zu erhalten. Automatisiertes maschinelles Lernen in Azure Machine Learning basiert auf einem Durchbruch der Microsoft Research-Abteilung.
Die Entwicklung traditioneller Machine Learning-Modelle ist ressourcenintensiv und erfordert viel Fachwissen und Zeit, um Dutzende von Modellen zu erstellen und zu vergleichen. Mit automatisiertem maschinellem Lernen verkürzen Sie die Zeit, die benötigt wird, um produktionsbereite ML-Modelle mit großer Leichtigkeit und Effizienz zu erhalten.
Möglichkeiten zur Verwendung des automatisierten maschinellen Lernens in Azure Machine Learning
Azure Machine Learning bietet die folgenden beiden Möglichkeiten für die Arbeit mit automatisiertem maschinellen Lernen. In den folgenden Abschnitten finden Sie Informationen zur Featureverfügbarkeit in der jeweiligen Erfahrung (v1).
Für Kunden mit Programmiererfahrung: Azure Machine Learning Python SDK. Erste Schritte mit dem Tutorial: Vorhersagen von Preisen für Taxifahrten mit automatisiertem maschinellen Lernen (v1).
Für Kunden mit begrenzten oder keinen Programmiererfahrungen: Azure Machine Learning Studio unter https://ml.azure.com. Erste Schritte mit folgenden Tutorials:
Einstellungen für das Experiment
Mit den folgenden Einstellungen können Sie Ihr Experiment für automatisiertes maschinelles Lernen konfigurieren.
| Python SDK | Die Studioweboberfläche | |
|---|---|---|
| Aufteilen der Daten in Trainings-/Validierungssätze | ✓ | ✓ |
| Unterstützt Aufgaben für maschinelles Lernen: Klassifizierung, Regression und Vorhersage | ✓ | ✓ |
| Unterstützt Aufgaben für maschinelles Sehen: Bildklassifizierung, Objekterkennung, und Instanzsegmentierung | ✓ | |
| Optimiert auf Grundlage der primären Metrik | ✓ | ✓ |
| Unterstützt Azure Machine Learning-Compute als Computeziel | ✓ | ✓ |
| Konfigurieren des Vorhersagehorizonts, der Zielverzögerungen und des rollierenden Fensters | ✓ | ✓ |
| Festlegen der Beendigungskriterien | ✓ | ✓ |
| Festlegen gleichzeitiger Iterationen | ✓ | ✓ |
| Löschen von Spalten | ✓ | ✓ |
| Blockieren von Algorithmen | ✓ | ✓ |
| Kreuzvalidierung im Vergleich | ✓ | ✓ |
| Unterstützt das Training für Azure Databricks-Cluster | ✓ | |
| Anzeigen der Namen der technischen Features | ✓ | |
| Featurezusammenfassung | ✓ | |
| Featurisierung für Feiertage | ✓ | |
| Ausführlichkeitsgrade der Protokolldatei | ✓ |
Modelleinstellungen
Diese Einstellungen können auf das beste Modell als Ergebnis Ihres Experiments für das automatisierte maschinelle Lernen angewendet werden.
| Python SDK | Die Studioweboberfläche | |
|---|---|---|
| Registrierung, Bereitstellung, Erklärbarkeit des besten Modells | ✓ | ✓ |
| Aktivieren von Abstimmungsensemble- und Stapelensemble-Modellen | ✓ | ✓ |
| Anzeigen des besten Modells auf der Basis von nicht primärer Metrik | ✓ | |
| Aktivieren/Deaktivieren der Kompatibilität des ONNX-Modells | ✓ | |
| Testen des Modells | ✓ | ✓ (Vorschau) |
Einstellungen der Auftragssteuerung
Mit diesen Einstellungen können Sie Ihre Experimentaufträge und die Aufträge der ihnen untergeordneten Elemente überprüfen und steuern.
| Python SDK | Die Studioweboberfläche | |
|---|---|---|
| Zusammenfassungstabelle für Aufträge | ✓ | ✓ |
| Aufträge und untergeordnete Aufträge abbrechen | ✓ | ✓ |
| Abrufen von Schutzmaßnahmen | ✓ | ✓ |
| Anhalten und Fortsetzen von Aufträgen | ✓ |
Anwendungsfälle für automatisiertes maschinelles Lernen: Klassifizierung, Regression, Vorhersage und maschinelles Sehen, und NLP
Sie arbeiten mit automatisiertem ML, wenn Sie möchten, dass Azure Machine Learning mit der von Ihnen angegebenen Zielmetrik ein Modell für Sie trainiert und optimiert. Automatisiertes ML demokratisiert den Entwicklungsprozess eines Machine Learning-Modells und befähigt seine Benutzer, unabhängig von deren Data Science-Kenntnissen, eine durchgängige Machine Learning-Pipeline für jedes Problem zu bestimmen.
Spezialisten für maschinelles Lernen und Entwickler aus den verschiedensten Branchen können automatisiertes maschinelles Lernen für Folgendes verwenden:
- Implementieren von ML-Lösungen ohne umfangreiche Programmierkenntnisse
- Sparen von Zeit und Ressourcen
- Nutzen von bewährten Methoden aus der Data Science
- Bereitstellen flexibler Problemlösungen
Klassifizierung
Die Klassifizierung ist ein gängiger Machine Learning-Task. Klassifizierung ist eine Art des überwachten Lernens, bei der Modelle anhand von Trainingsdaten lernen und diese Erkenntnisse auf neue Daten anwenden. Azure Machine Learning bietet Featurebereitstellungen speziell für diese Aufgaben, z. B. Textfeaturizer für Deep Neural Network zur Klassifizierung. Erfahren Sie mehr über die Optionen für die Featurisierung (v1).
Das Hauptziel von Klassifizierungsmodellen besteht darin, auf der Grundlage der Erkenntnisse aus den Trainingsdaten vorherzusagen, in welche Kategorien neue Daten fallen werden. Zu den gängigen Klassifizierungsbeispielen gehören Betrugserkennung, Handschrifterkennung und Objekterkennung. Weitere Informationen und ein Beispiel finden Sie unter Erstellen eines Klassifizierungsmodells mit automatisiertem maschinellem Lernen (v1).
Weitere Beispiele für Klassifizierung und automatisiertes Machine Learning finden Sie in den folgenden Python-Notebooks: Fraud Detection (Betrugserkennung), Marketing Prediction (Marketingprognose) und Newsgroup Data Classification (Klassifizierung von Diskussionsgruppendaten)
Regression
Ähnlich der Klassifizierung sind Regressionsaufgaben auch ein gängiger überwachter Lerntask.
Anders als bei der Klassifizierung, bei der die vorhergesagten Ausgabewerte kategorisch sind, sagen Regressionsmodelle numerische Ausgabewerte auf der Grundlage unabhängiger Vorhersagefaktoren voraus. Bei der Regression besteht das Ziel darin, die Beziehung zwischen diesen unabhängigen Vorhersagevariablen herzustellen, indem geschätzt wird, wie eine Variable die anderen beeinflusst. Beispiel: Der Fahrzeugpreis basierend auf Merkmalen wie Kraftstoffverbrauch, Sicherheitseinstufung, usw. Hier erhalten Sie weitere Informationen und ein Beispiel für die Regression mit automatisiertem maschinellen Lernen (v1).
Weitere Beispiele für Regression und automatisiertes Machine Learning für Vorhersagen finden Sie in den folgenden Python-Notebooks: CPU-Leistungsvorhersage,
Zeitreihenvorhersagen
Die Erstellung von Vorhersagen ist ein integraler Bestandteil jedes Unternehmens, unabhängig davon, ob es sich um Einnahmen, Lagerbestände, Umsätze oder Kundennachfrage handelt. Sie können automatisiertes maschinelles Lernen verwenden, um verschiedene Techniken und Ansätze zu kombinieren. Außerdem erhalten Sie dabei eine beliebte und hochwertige Zeitreihenprognose. Hier erhalten Sie weitere Informationen zur Vorgehensweise: Automatisches Trainieren eines Modells für die Zeitreihenprognose (v1).
Automatisierte Zeitreihenexperimente werden als multivariate Regressionsprobleme behandelt. Zeitreihenwerte aus der Vergangenheit werden „pivotiert“ und dienen so zusammen mit anderen Vorhersageelementen als zusätzliche Dimensionen für den Regressor. Dieser Ansatz hat im Gegensatz zu klassischen Zeitreihenmethoden den Vorteil, dass mehrere kontextbezogene Variablen und deren Beziehungen zueinander beim Training auf natürliche Weise integriert werden. Beim automatisierten maschinellen Lernen wird ein zwar einfaches, aber häufig in interne Verzweigungen unterteiltes Modell für alle Elemente im Dataset und in den Vorhersagehorizonten erlernt. Dadurch sind mehr Daten verfügbar, um Modellparameter zu schätzen, und die Generalisierung von unbekannten Reihen wird möglich.
Die erweiterte Vorhersagekonfiguration umfasst Folgendes:
- Feiertagserkennung und Erstellen zusätzlicher Merkmale (Featurization)
- Zeitreihen und DNN-Lernmodule (Auto-ARIMA, Prophet, ForecastTCN)
- Unterstützung vieler Modelle mithilfe von Gruppierungen
- Kreuzvalidierung mit rollierendem Ursprung (Rolling Origin Validation)
- Konfigurierbare Verzögerungen (Lags)
- Aggregierte Zeitfenstermerkmale (Rolling Window Features)
Beispiele für Regression und automatisiertes maschinelles Lernen für Vorhersagen finden Sie in diesen Python-Notebooks: Sales Forecasting (Verkaufsprognose), Demand Forecasting (Nachfrageprognose) und Forecasting GitHub's Daily Active Users (Vorhersage der täglichen aktiven GitHub-Benutzer).
Maschinelles Sehen
Die Unterstützung von maschinellem Sehen ermöglicht die einfache Erstellung von Modellen, die mit Bilddaten für Szenarien wie Bildklassifizierung und Objekterkennung trainiert wurden.
Diese Funktion ermöglicht Folgendes:
- Nahtlose Integration mit der Funktion zur Azure Machine Learning-Datenbeschriftung
- Verwenden von beschrifteten Daten zum Generieren von Bildmodellen
- Optimieren der Modellleistung durch Angabe des Modellalgorithmus und durch Abstimmen der Hyperparameter
- Herunterladen oder Bereitstellen des resultierenden Modells als Webdienst in Azure Machine Learning
- Operationalisierung im großen Stil durch Nutzung der MLOps- und ML Pipelines (v1)-Funktionen von Azure Machine Learning.
Das Erstellen von AutoML-Modellen für Aufgaben des maschinellen Sehens wird über das Azure Machine Learning Python SDK unterstützt. Auf die resultierenden Versuchsaufträge, Modelle und Ergebnisse kann über die Benutzeroberfläche von Azure Machine Learning Studio zugegriffen werden.
Erfahren Sie, wie Sie das AutoML-Training für Modelle des maschinellen Sehens einrichten.

Automatisiertes ML für Bilder unterstützt die folgenden Aufgaben für maschinelles Sehen:
| Aufgabe | BESCHREIBUNG |
|---|---|
| Bildklassifizierung mit mehreren Klassen | Aufgaben, bei denen ein Bild nur mit einer einzelnen Bezeichnung aus einer Reihe von Klassen klassifiziert wird – z. B. wird jedes Bild entweder als Bild einer „Katze“ oder eines „Hundes“ oder einer „Ente“ klassifiziert. |
| Bildklassifizierung mit mehreren Beschriftungen | Aufgaben, bei denen ein Bild eine oder mehrere Beschriftungen aus einer Reihe von Beschriftungen besitzen könnte – z. B. könnte ein Bild sowohl mit „Katze“ als auch mit „Hund“ beschriftet werden. |
| Objekterkennung | Aufgaben zur Identifizierung von Objekten in einem Bild und Lokalisierung der einzelnen Objekte mit einem Begrenzungsrahmen, z. B. die Lokalisierung aller Hunde und Katzen in einem Bild und Zeichnen eines Begrenzungsrahmens um jedes Objekt. |
| Instanzsegmentierung | Aufgaben zur Identifizierung von Objekten in einem Bild auf Pixelebene, indem ein Polygon um jedes Objekt im Bild gezeichnet wird. |
Linguistische Datenverarbeitung: NLP (Natural Language Processing)
Die Unterstützung von Aufgaben zur Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) in automatisiertem ML ermöglicht ihnen das einfache Generieren von Modellen, die mit Textdaten für Textklassifizierungsszenarios und Szenarios zum Erkennen benannter Entitäten trainiert wurden. Die Erstellung von durch automatisiertes ML trainierten NLP-Modellen wird über das Azure Machine Learning Python-SDK unterstützt. Auf die resultierenden Versuchsaufträge, Modelle und Ergebnisse kann über die Benutzeroberfläche von Azure Machine Learning Studio zugegriffen werden.
Die NLP-Funktion unterstützt:
- End-to-End-Deep Neural Network-NLP-Training mit den neuesten vortrainierten BERT-Modellen
- Nahtlose Integration mit Azure Machine Learning Datenbeschriftung
- Verwenden von beschrifteten Daten zum Generieren von NLP-Modellen
- Mehrsprachige Unterstützung für 104 Sprachen
- Verteiltes Training mit Horovod
Erfahren Sie, wie Sie das Automatisierte ML-Training für NLP-Modelle einrichten (v1).
Funktionsweise von automatisiertem ML
Während des Trainings erstellt Azure Machine Learning parallel eine Reihe von Pipelines, die unterschiedliche Algorithmen und Parameter für Sie ausprobieren. Der Dienst durchläuft die ML-Algorithmen iterativ im Zusammenspiel mit der jeweiligen Featureauswahl, wobei für jede Iteration ein Modell mit einer Trainingsbewertung erzeugt wird. Je höher die Bewertung ist, desto besser wird das Modell als „passend“ für Ihre Daten angesehen. Die Ausführung wird beendet, sobald die im Experiment definierten Beendigungskriterien erreicht werden.
Mithilfe von Azure Machine Learning können Sie automatisierte ML-Trainingsexperimente mit den folgenden Schritten entwerfen und ausführen:
Bestimmen Sie das zu lösende ML-Problem: Klassifizierung, Vorhersage, Regression oder maschinelles Sehen.
Wählen Sie, ob Sie das Python SDK oder die Studioweboberfläche verwenden möchten: Erfahren Sie mehr über die Parität zwischen dem Python SDK und der Studioweboberfläche.
- Wenn Sie nur über eingeschränkte oder gar keine Erfahrung mit Code verfügen, testen Sie die Studioweboberfläche von Azure Machine Learning unter https://ml.azure.com.
- Informieren Sie sich als Python-Entwickler über das Python SDK (v1) von Azure Machine Learning.
Angeben der Quelle und des Formats der bezeichneten Trainingsdaten: NumPy-Arrays oder Pandas-Datenrahmen.
Konfigurieren des Computeziels für das Modelltraining, z. B. lokaler Computer, Azure Machine Learning Computes, Remote-VMs oder Azure Databricks mit SD v1.
Konfigurieren der automatisierten Machine Learning-Parameter, die die Anzahl der Iterationen über verschiedene Modelle, die Hyperparametereinstellungen, erweiterte Vorverarbeitung/Featurebereitstellung und die Metriken bestimmen, die bei der Ermittlung des besten Modells zu berücksichtigen sind.
Übermitteln des Trainingsauftrags
Überprüfen der Ergebnisse
Dieser Prozess wird anhand des folgenden Diagramms veranschaulicht.
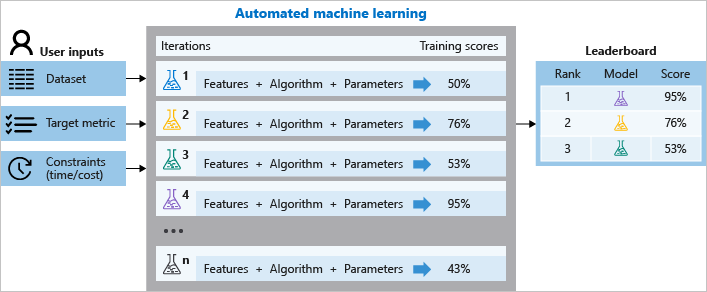
Sie können die protokollierten Auftragsinformationen auch untersuchen. Sie enthalten die während des Auftrags erfassten Metriken. Bei dem Trainingsauftrag wird ein serialisiertes Python-Objekt (.pkl-Datei) generiert, das die Vorabverarbeitung des Modells und der Daten enthält.
Obwohl die Modellerstellung automatisiert ist, können Sie auch ermitteln, wie wichtig oder relevant Features für die generierten Modelle sind.
Leitfaden zu lokal verwalteten ML-Computezielen im Vergleich zu remote verwalteten ML-Computezielen
Die Weboberfläche für automatisiertes ML verwendet immer ein Remotecomputeziel. Wenn Sie jedoch das Python SDK verwenden, wählen Sie entweder ein lokales Computeziel oder ein Remotecomputeziel für automatisiertes ML-Training aus.
- Lokales Computeziel: Das Training erfolgt auf Ihrem lokalen Computer oder VM-Compute.
- Remotecomputeziel: Das Training erfolgt auf Azure Machine Learning-Computeclustern.
Auswählen eines Computeziels
Berücksichtigen Sie die folgenden Faktoren bei der Auswahl Ihres Computeziels:
- Wählen Sie ein lokales Computeziel aus: Wenn Ihr Szenario anfängliche Untersuchungen oder Demos mithilfe weniger Daten und kurzen Trainingsprozessen (d. h. Sekunden oder wenige Minuten pro untergeordnetem Auftrag) umfasst, kann sich das Training auf Ihrem lokalen Computer als besser erweisen. Es gibt keine Einrichtungszeit, die Infrastrukturressourcen (Ihr Computer oder Ihre VM) sind sofort verfügbar.
- Wählen Sie ein Remote-ML-Computecluster aus: Wenn Sie wie beim Erstellen von Modellen für Produktionstraining Training mit größeren Datasets durchführen, die längere Trainingszeiträume erfordern, bietet ein Remotecomputeziel eine bessere Gesamtdauer, da
AutoMLTrainingsprozesse über Clusterknoten hinweg parallelisiert. Auf einem Remotecomputeziel werden etwa 1,5 Minuten pro untergeordnetem Auftrag durch die Startzeit für die interne Infrastruktur hinzugefügt. Außerdem werden weitere Minuten für die Clusterinfrastruktur addiert, wenn die VMs noch nicht ausgeführt werden.
Vor- und Nachteile
Wägen Sie die folgenden Vor- und Nachteile gegeneinander ab, wenn Sie zwischen einem lokalen und einem Remotecomputeziel entscheiden.
| Vorteile | Nachteile | |
|---|---|---|
| Lokales Computeziel | ||
| Remote-ML-Computecluster |
Verfügbarkeit von Funktionen
Wie in der folgenden Tabelle gezeigt stehen Ihnen mehr Features zur Verfügung, wenn Sie Remotecompute verwenden.
| Funktion | Remote | Lokal |
|---|---|---|
| Datenstreaming (Unterstützung großer Datenmengen, bis zu 100 GB) | ✓ | |
| DNN-BERT-basierte Textfeaturisierung und -training | ✓ | |
| Direkt einsatzbereite GPU-Unterstützung (Training und Rückschlüsse) | ✓ | |
| Unterstützung von Bildklassifizierung und Bezeichnungen | ✓ | |
| Auto-ARIMA-, Prophet- und ForecastTCN-Modelle für Vorhersagen | ✓ | |
| Mehrere parallele Aufträge/Iterationen | ✓ | |
| Erstellen von Modellen mit Interpretierbarkeit in der AutoML Studio-Webbenutzeroberfläche | ✓ | |
| Anpassung des Feature Engineering in der AutoML Studio-Webbenutzeroberfläche | ✓ | |
| Optimierung von Azure Machine Learning-Hyperparametern | ✓ | |
| Unterstützung des Azure Machine Learning-Pipeline-Workflows | ✓ | |
| Fortsetzen eines Auftrags | ✓ | |
| Vorhersagen | ✓ | ✓ |
| Erstellen und Ausführen von Experimenten in Notebooks | ✓ | ✓ |
| Registrieren und Visualisieren der Informationen und Metriken von Experimenten auf der Benutzeroberfläche | ✓ | ✓ |
| Schutzmaßnahmen für Daten | ✓ | ✓ |
Trainieren, Überprüfen und Testen von Daten
Mit automatisierten ML Sie die Trainingsdaten zum Trainieren ML Und Sie können angeben, welche Art von Modellvalidierung sie ausführen soll. Automatisiertes ML führt die Modellvalidierung im Rahmen des Trainings aus. Das heißt, dass automatisiertes ML Validierungsdaten verwendet, um Modellhyperparameter basierend auf dem angewendeten Algorithmus zu optimieren, um die beste Kombination zu finden, die am besten zu den Trainingsdaten passt. Allerdings werden dieselben Validierungsdaten für jede Iteration der Optimierung verwendet, was zu einer Voreingenommenheit bei der Modellauswertung führt, da das Modell sich weiter verbessert und an die Validierungsdaten anpasst.
Um zu bestätigen, dass diese Verzerrungen nicht auf das endgültige empfohlene Modell angewendet werden, unterstützt das automatisierte ML die Verwendung von Testdaten, um das endgültige Modell zu bewerten, das automatisiertes ML am Ende Ihres Experiments empfiehlt. Wenn Sie Testdaten als Teil Ihrer Experimentkonfiguration für automatisiertes maschinelles Lernen bereitstellen, wird dieses empfohlene Modell standardmäßig am Ende des Experiments (Vorschauversion) getestet.
Wichtig
Das Testen Ihrer Modelle mit einem Testdatensatz zur Bewertung der generierten Modelle ist eine Previewfunktion. Diese Funktion ist eine experimentelle Previewfunktion, die jederzeit geändert werden kann.
Erfahren Sie, wie Sie Experimente für automatisiertes maschinelles Lernen für die Verwendung von Testdaten (Vorschauversion) mit dem SDK (v1) oder mit Azure Machine Learning Studio konfigurieren.
Sie können auch alle vorhandenen automatisierten ML-Modelle (Vorschauversion) (v1) testen, einschließlich Modellen aus untergeordneten Aufträgen, indem Sie Ihre eigenen Testdaten bereitstellen oder einen Teil Ihrer Trainingsdaten abgesehen haben.
Featureentwicklung
Beim Feature Engineering werden Domänenkenntnisse der Daten zum Erstellen von Features verwendet, mit denen ML-Algorithmen besser lernen können. In Azure Machine Learning werden für das Feature Engineering Skalierungs- und Normalisierungstechniken angewendet. Zusammen werden diese Techniken und das Feature Engineering als Featurisierung bezeichnet.
Bei automatisierten Machine Learning-Experimenten wird die Featurisierung automatisch angewendet, sie kann aber auch basierend auf Ihren Daten angepasst werden. Erfahren Sie mehr darüber, welche Featurisierung enthalten ist (v1) und wie AutoML hilft, Überanpassungen und unausgeglichene Daten in Ihren Modellen zu verhindern.
Hinweis
Die Schritte zur Featurebereitstellung bei automatisiertem maschinellen Lernen (Featurenormalisierung, Behandlung fehlender Daten, Umwandlung von Text in numerische Daten usw.) werden Teil des zugrunde liegenden Modells. Bei Verwendung des Modells für Vorhersagen werden die während des Trainings angewendeten Schritte zur Featurebereitstellung automatisch auf Ihre Eingabedaten angewendet.
Anpassen der Featurisierung
Es stehen auch weitere Feature Engineering-Techniken wie etwa Codierung und Transformationen zur Verfügung.
Diese Einstellung kann aktiviert werden über:
Azure Machine Learning Studio: Aktivieren Sie die Automatische Merkmalserstellung im Abschnitt Konfigurationsausführungmit diesen (v1) Schritten.
Python SDK: Geben Sie
"feauturization": 'auto' / 'off' / 'FeaturizationConfig'in Ihrem Objekt vom Typ AutoMLConfig an. Weitere Informationen zur Aktivierung der Featurisierung (v1).
Ensemblemodelle
Automatisiertes Machine Learning unterstützt Ensemblemodelle, die standardmäßig aktiviert sind. Das Lernen mit Ensembles verbessert die Ergebnisse des maschinellen Lernens und die Vorhersageleistung, da nicht einzelne Modelle verwendet, sondern mehrere Modelle kombiniert werden. Die Ensemble-Iterationen erfolgen als abschließende Iterationen Ihres Auftrags. Automatisiertes Machine Learning verwendet die beiden Ensemble-Methoden „voting“ (Abstimmen) und „stacking“ (Stapeln) gemeinsam, um Modelle zu kombinieren:
- Voting: Trifft Vorhersagen auf Grundlage des gewichteten Durchschnitts der vorhergesagten Klassenwahrscheinlichkeiten (für Klassifizierungsaufgaben) oder auf Grundlage der vorhergesagten Regressionsziele (für Regressionsaufgaben).
- Stacking: Stacking kombiniert heterogene Modelle und trainiert ein Metamodell, basierend auf der Ausgabe der einzelnen Modelle. Die aktuellen Standardmetamodelle sind LogisticRegression für Klassifizierungsaufgaben und ElasticNet für Regressions-/Vorhersageaufgaben.
Der Caruana-Algorithmus für die Ensembleauswahl mit sortierter Ensembleinitialisierung wird verwendet, um zu entscheiden, welche Modell innerhalb des Ensembles verwendet werden sollen. Generell initialisiert dieser Algorithmus das Ensemble mit bis zu fünf Modellen mit den besten Einzelbewertungen und überprüft, ob diese Modelle innerhalb des 5 %-Schwellenwerts der besten Bewertung liegen, um ein schlechtes Ausgangsensemble zu vermeiden. Dann wird für jede Ensemble-Iteration ein neues Modell zum vorhandenen Ensemble hinzugefügt, und die resultierende Bewertung wird berechnet. Wenn ein neues Modell die vorhandene Ensemblebewertung verbessert hat, wird das Ensemble so aktualisiert, dass es das neue Modell aufnimmt.
Informationen zum Ändern der Standard-Ensembleeinstellungen beim automatisierten Machine Learning finden Sie unter Gewusst wie (v1):.
AutoML und ONNX
Mit Azure Machine Learning können Sie automatisiertes ML verwenden, um ein Python-Modell zu erstellen und in das ONNX-Format zu konvertieren. Sobald die Modelle im ONNX-Format vorliegen, können sie auf einer Vielzahl von Plattformen und Geräten ausgeführt werden. Erfahren Sie mehr über das Beschleunigen von ML-Modellen mit ONNX.
Informationen zum Konvertieren in das ONNX-Format finden Sie in diesem Jupyter Notebook-Beispiel. Erfahren Sie, welche Algorithmen in ONNX unterstützt werden (v1).
Die ONNX-Runtime unterstützt auch C#, sodass Sie das erstellte Modell automatisch in Ihren C#-Apps verwenden können, ohne es neu codieren oder die Netzwerklatenzen in Kauf nehmen zu müssen, die REST-Endpunkte mit sich bringen. Erfahren Sie mehr über die Verwendung eines AutoML ONNX-Modells in einer .NET-Anwendung mit ML.NET und das Rückschließen von ONNX-Modellen mit der C#-API für die ONNX-Runtime.
Nächste Schritte
Es gibt mehrere Ressourcen, um Sie mit AutoML vertraut zu machen.
Tutorials/Anleitungen
Tutorials sind einführende End-to-End-Beispiele für AutoML-Szenarien.
Für das codegesteuerte Verfahren befolgen Sie das Tutorial: Trainieren eines Regressionsmodells mit AutoML und Python (v1).
Für die Herangehensweise mit wenig/keinem Code sehen Sie sich das Tutorial: Trainieren eines Klassifizierungsmodells mit AutoML ohne Schreiben von Code in Azure Machine Learning Studio an.
Informationen zum Verwenden von AutoML zum Trainieren von Modellen für maschinelles Sehen finden Sie im Tutorial: Trainieren eines Objekterkennungsmodells mit AutoML und Python (v1).
Anleitungen bieten zusätzliche Einzelheiten zu den Funktionen des automatisierten maschinellen Lernens. Beispiel:
Konfigurieren der Einstellungen für automatische Trainingsexperimente
Erfahren Sie, wie Sie Vorhersagemodelle mit Zeitreihendaten trainieren (v1).
Erfahren Sie, wie Sie Modelle für maschinelles Sehen mit Python trainieren (v1).
Erfahren Sie, wie Sie den generierten Code aus Ihren Modellen für automatisiertes maschinelles Lernen anzeigen.
Jupyter Notebook-Beispiele
Überprüfen Sie detaillierte Codebeispiele und Anwendungsfälle im GitHub-Notebook-Repository für Beispiele zum automatisierten maschinellen Lernen.
Referenz zum Python SDK
Vertiefen Sie Ihre Kenntnisse über SDK-Entwurfsmuster und Klassenspezifikationen mit der AutoML-Klassenreferenzdokumentation.
Hinweis
Die Funktionen des automatisierten maschinellen Lernens sind auch in anderen Lösungen von Microsoft verfügbar: ML.NET, HDInsight, Power BI und SQL Server